Testing MiniMax M2.7 via API on three real ML and coding workflows
I recently got access to some MiniMax M2.7 API credits, so I decided to plug this model directly into Claude Code and run it on three workflows I do regularly. The same tasks were run using Claude Opus 4.7 as the comparison baseline.
The three workflows: scaffolding an entry for an active Kaggle competition, drafting and auditing knowledge-base notes for my Obsidian vault, and updating an old PyTorch project that became outdated. I wanted to find out how well M2.7 works inside an agentic loop when the task has clear boundaries. The results were consistent across the three runs: M2.7 was useful when the constraints were explicit, and the output format was concrete. It stumbled when important context was left implicit, though some of the same gaps appeared with Opus 4.7 as well.
For the more open-ended cases, I would still keep a human review pass in the loop.
Setup
I added a claude-mm command that points Claude Code at the MiniMax API and ran M2.7 with thinking set to max in the CC interface. I ran on MiniMax’s Plus tier (High-Speed, $40/month), where the context window and per-day throughput no longer became bottlenecks for multi-step agentic work.
claude-mm() {
ANTHROPIC_BASE_URL="https://api.minimax.io/anthropic" \
ANTHROPIC_AUTH_TOKEN="$MINIMAX_API_KEY" \
ANTHROPIC_MODEL="MiniMax-M2.7" \
ANTHROPIC_DEFAULT_SONNET_MODEL="MiniMax-M2.7" \
ANTHROPIC_DEFAULT_OPUS_MODEL="MiniMax-M2.7" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="MiniMax-M2.7" \
ANTHROPIC_SMALL_FAST_MODEL="MiniMax-M2.7" \
API_TIMEOUT_MS="3000000" \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1" \
claude "$@"
}
In agentic work, the harness can be as important as the model itself. Most of the failures I describe below had similar reasons: the prompt did not explicitly state a constraint the task depended on, and the model filled the gap with a plausible default. In practice, model quality and harness design are hard to separate. A stronger model may infer missing constraints; a better harness may make those constraints explicit. I treated this as a workflow test, not a pure model benchmark.
Refactoring an old PyTorch project
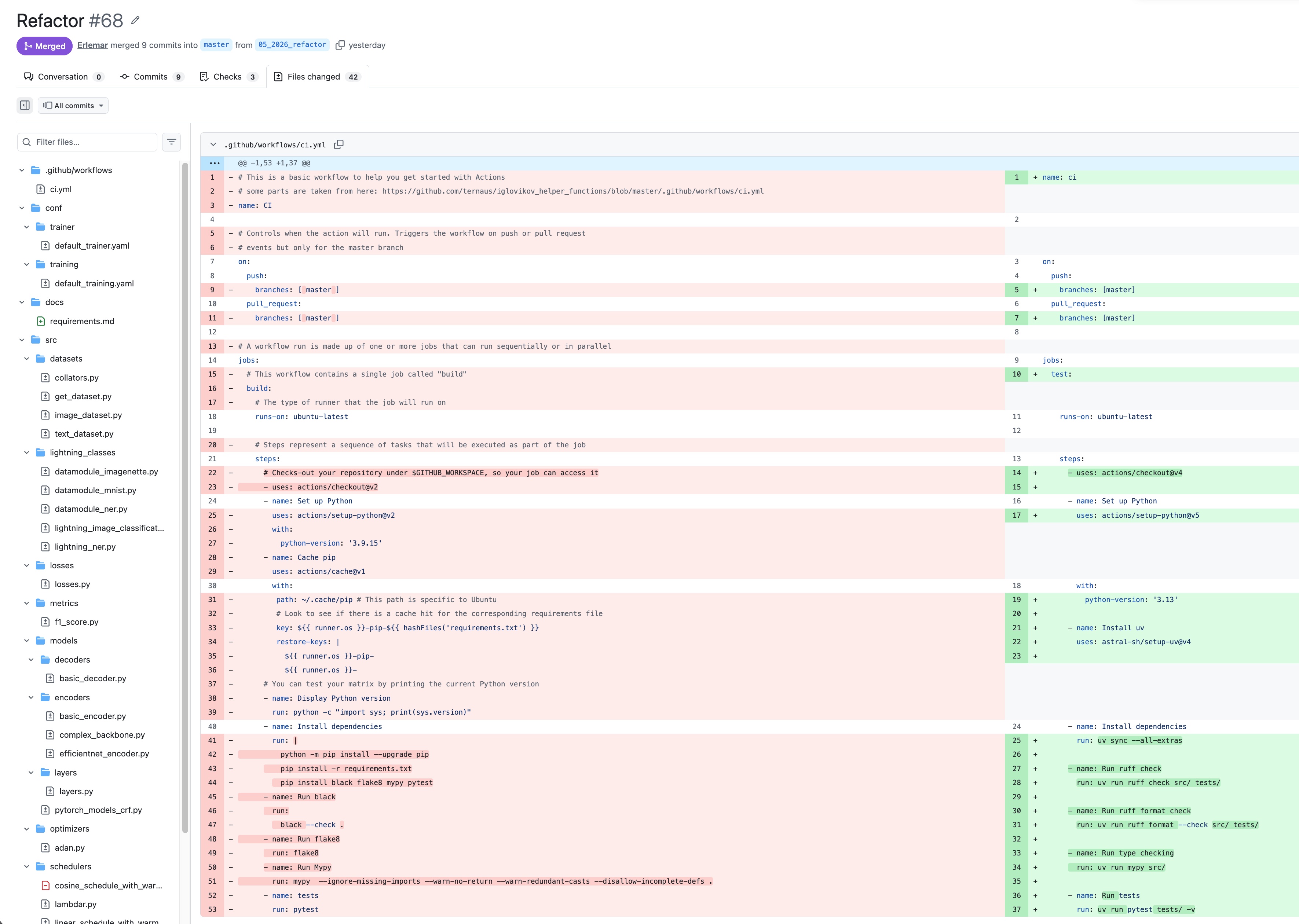
The first workflow was a refactor: my pytorch_tempest repo is a framework for training neural nets using Hydra + PyTorch Lightning. I wanted to update dependencies, modernize the tooling, and clean up the code issues that had accumulated over time. The merged result is PR: refactoring old code and updating dependencies.
The changes:
- Updated CI versions and pre-commit hooks.
- Replaced black and flake8 with ruff for both linting and formatting.
- Enabled
fsdp_sharding_strategy in the Lightning trainer config.
- Refreshed the documentation.
- Added uv for environment management.
- Switched to modern Python typing (
list[X] over List[X], X | None over Optional[X]).
- Removed duplicate code paths.
- Fixed a lot of small issues.

I guided M2.7 explicitly: provided step-by-step requirements (“switch black + flake8 to ruff”, “update the pre-commit config”), reviewed each change before moving to the next, and provided feedback when the diff went outside scope. I had enough tests to check whether anything broke after the changes, and rerunning model training took only several minutes. I had some challenges running CI, and the agent helped me fix them one by one.
A lot of engineers I know do not want to give an agent free rein over a codebase they care about; they want to supervise the execution and know every existing line of code. M2.7 fits this approach well. You can write short, narrow-scope prompts, conduct line-level review, and then move to the next step.
Knowledge notes for the Obsidian vault
The second workflow was writing and auditing notes for my Obsidian vault, where I keep around ML reference notes. I write most of them by hand; sometimes I have an LLM draft a parallel version to compare against and take inspiration from.
It is important to remember that different models prefer different prompt styles. A 100-line prompt tuned for Opus 4.7 does not transfer one-to-one to M2.7. To handle that, I did a small bootstrap: I asked both models to generate notes from the same starting prompt, then asked M2.7 to read both notes and propose an improved prompt for itself. The next iteration used the M2.7-tuned prompt.
I used two prompts (a writer command and a critic agent), each around 100 lines. Here is a condensed version of the first one:
Fill one broken-link stub in the DSWoK vault: research the topic, draft the note in DSWoK voice, run draft-critic-mm, save to the right folder.
1. Read context: writing style guide, frontmatter taxonomy, alias rule.
2. Pick the stub.
3. Locate references — Grep for [[<title>]] across the vault.
4. Pick the destination folder based on topical group.
5. Find a structural template from neighbouring notes.
6. Research via 3–5 sources, search-first — don't trust memory for citations, formula conventions, or post-2024 work.
6.5. Verify each cited URL before pasting it. Hard-to-verify URLs are blocking errors.
7. Determine note type and structure.
8. Draft the note with frontmatter taxonomy + style rules.
9. Cross-link inline to adjacent notes.
10. Run draft-critic-mm and address every blocking issue.
The critic agent has a similarly explicit checklist. The point of writing two detailed prompts is to make the evaluation criteria concrete: this means the model needs to make fewer judgment calls and can self-audit its output.
I shared gists with the command and the critic.
I tested both M2.7 and Opus on four notes: Negative Sampling, MAP (Mean Average Precision), Cold Start (a recommender-systems problem), and RMSE.

In the RMSE note, M2.7 got several things right:
- It flagged that RMSE “does not decompose into bias and variance” the way MSE does, because the square root is nonlinear.
- It cited Hyndman & Koehler 2006 (the canonical forecasting paper introducing MASE and scaled errors) at the right place.
- The Properties section used inline mini-headers with bold formatting, as defined in the style guide.
- The intro was tighter than Opus’s version.
What needed editing:
- Bullet-label bold (
**Rating prediction.**, **Not robust to heavy-tailed noise.**) - this is against the style guide, but easily fixed.
- Missing Variants section: RMSLE, NRMSE, and weighted RMSE are absent. This wasn’t defined in the prompt, but it would be a very good addition to the text.
- The Willmott reference pointed to a 2006 JAM paper (DOI 10.1175/JAM2472.1) rather than the canonical 2005 Climate Research paper that practitioners usually cite.
The other three notes had the same pattern: solid first drafts, accuracy in the technical core, occasional citation mistakes, and occasional ignoring of style rules. Most of these issues (except the hallucinations) are easy to notice and to fix.
One additional experiment: I asked M2.7 to audit my existing notes and find possible problems. The audit was useful: the model found many formatting issues, including incorrect tags, typos, and missing cross-links. One flagged item was funny, though:
Metrics and losses/f1 score.md |
Only 1 tag (evaluation); missing domain tag (recsys, nlp, or cv) |
The F1 score is a general classification metric and does not need a domain tag by my taxonomy. M2.7 inferred a rule by analyzing larger notes, even though such a rule doesn’t exist. The fix was to include the tag hierarchy in the prompt next time, just as I include the writing-style guide for the drafting task.
Across the four notes and the audit run, M2.7 worked well for creating a first draft. It created useful tables and small visualizations, and the technical content was usually right, but references needed checking.
Here are the final versions of the notes after review, adding more ideas and heavy editing:
Kaggle: ROGII — Wellbore Geology Prediction
The final task was the ROGII Wellbore Geology Prediction competition: predicting geological layer tops along well paths from drilling-time measurements. Quasi-spatial data, anisotropic distances, a handful of wells with target labels, and per-well prediction error as the scoring metric.
I’m a Competition Master and Notebook Grandmaster, and I was curious to see how well an agent could perform in a new competition. I intentionally started with a high-level prompt rather than a fully specified implementation plan, because that is a realistic simulation for a first interaction with Kaggle. I’ve accumulated notes, code, and write-ups from earlier Kaggle competitions over the years; I shared them as context, along with explanations of what Kaggle is, what competitions are, and how to participate. The goal was to create a first submission that could be iterated on.
M2.7 spent a considerable time on the analysis. The first working result was this notebook rogii-wellbore-final-kriging: a 5-fold validation split by well, ~40 features, and training a gradient boosting model. The validation split was not standard:
# 5-fold GroupKFold by well_id
unique_wells = pre_ps_train["well_id"].unique()
well_to_fold = {w: i % 5 for i, w in enumerate(unique_wells)}
fold_assignments = pre_ps_train["well_id"].map(well_to_fold)
The usual approach would be to use GroupKFold from sklearn, but this “cheap” version was fine for a first pass.
There were two issues, both due to Kaggle-specific mechanics rather than the model’s ML reasoning. ROGII is a kernel-only competition: at submission time, the test set you see (three rows with target values exposed) gets swapped out for the real test set (much larger, no target values). This means that models can miss these mechanics unless they are stated in the prompt. As a result, I noticed two problems:
- The model assumed the three exposed test rows were the entire test set and hardcoded them.
- It treated the exposed target column as a regular feature and used it during feature engineering.
The first submission didn’t succeed: with the target leaked into the feature set, the model trained against a column it would not have at inference, and the submission failed due to hardcoding the three available test samples.
Interestingly, Opus 4.7 also used the exposed target in feature engineering in the same setup. The kernel-only rules are not something either model picks up from “this is a Kaggle competition” — they have to be in the prompt. After I explicitly explained the mechanics, M2.7 fixed both bugs in one pass, and the submission worked.
It then produced a more advanced version: the rogii-idw-lightgbm-residual notebook, with inverse-distance-weighting features and a LightGBM residual model (without leaks) on top, scoring better than the first attempt.
In terms of participating in Kaggle competitions, M2.7 worked well for building a scaffold for future work: setting up basic validation, starting feature engineering, and training a model. After that, it can iteratively improve the solution if you provide strict constraints and specify the direction (e.g., improving a specific metric).
Cost and throughput
I ran this on MiniMax’s $40/month Plus plan and never came close to the rate limits across five days of intensive Claude Code sessions. The subscription dashboard showed that M2.7 processed roughly 91M total tokens, with most of them cache reads. At M2.7’s PAYG rates ($0.30/$1.20 per million input/output, $0.06 per million cache reads), that’s around $8 worth of usage. I didn’t log Opus 4.7’s token usage, but at its rates ($5/$25, $0.50 cache reads), it would cost around 10x.
In terms of speed, M2.7 returned tool calls and completed multi-step plans noticeably faster than Opus 4.7 on the same tasks — subjectively around 2x. I didn’t benchmark rigorously, but the difference was noticeable. Combined with the cost ratio, this means you can run several supervised iterations on M2.7 within the time and budget of one Opus iteration
Where I’d use M2.7 going forward, and where I wouldn’t
Across the ROGII submission, the four Obsidian notes, and the pytorch_tempest refactor, the results are similar. M2.7 works well when the task has clear boundaries, explicit evaluation criteria, and concrete output requirements. The cases where it fell short had a common cause: the prompt left a piece of context unstated, and the model filled the gap with a reasonable but wrong assumption. In some cases, the same prompt produced the same gap in Opus.
I would use M2.7 going forward for:
- Supervised refactors with a narrow scope and rapid iteration.
- First-draft technical content that I am going to review anyway: knowledge notes, drafts, or boilerplate for new repos.
- Audit of existing documents: when I explicitly provide the taxonomy or a list of checks.
- Iterating over existing machine learning code to improve the metrics given explicit constraints.
What I would not yet hand to M2.7 unsupervised:
- Open-ended ML competition strategy beyond the initial setup. The decisions should be made by humans or by an advanced model. When the direction is split into tasks, M2.7 can start implementing them.
- Reference-heavy technical writing without verification. This is not specific to M2.7 — citation hallucinations happen with most models I have tested. The workaround is the same: verify every URL, and treat it as another step in the workflow.
Across the three workflows, M2.7 was the right tool when I could define the constraints. When the task required the model to figure out the constraints itself (what “kernel-only” implies, what taxonomy applies to F1) both M2.7 and Opus failed, and Opus failed less. The trade is roughly 10x in cost per equivalent task. For supervised work with rapid iteration, using M2.7 is worth it.
This post was written in partnership with the MiniMax team. If you are interested in trying MiniMax, you can use this code for 12% discount.
UPD: Now you can read my next blogpost: Testing MiniMax M3 on real tasks: repo refactor, screenshot debugging, and Spotify recommendations.
]]>