Paper Review: Reverse Thinking Makes LLMs Stronger Reasoners
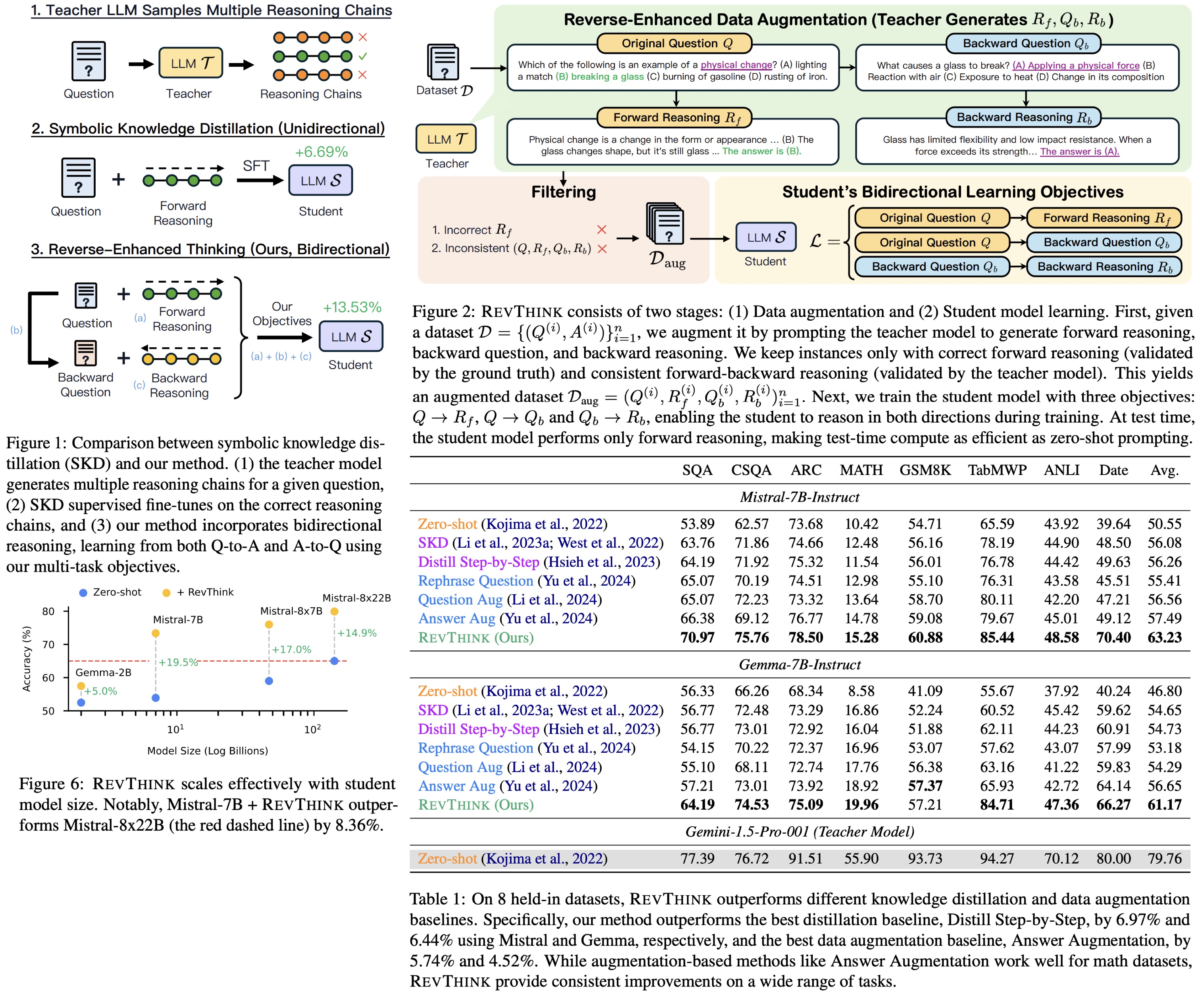
Reverse-Enhanced Thinking (RevThink) enables LLMs to reason backward by using structured forward-backward reasoning data. A teacher model generates questions, forward reasoning, backward questions, and backward reasoning. A student model is then trained on tasks to generate forward reasoning, backward questions, and backward reasoning. RevThink improves reasoning performance by 13.53% on average, requires less data for training, and generalizes well to new datasets.
The approach
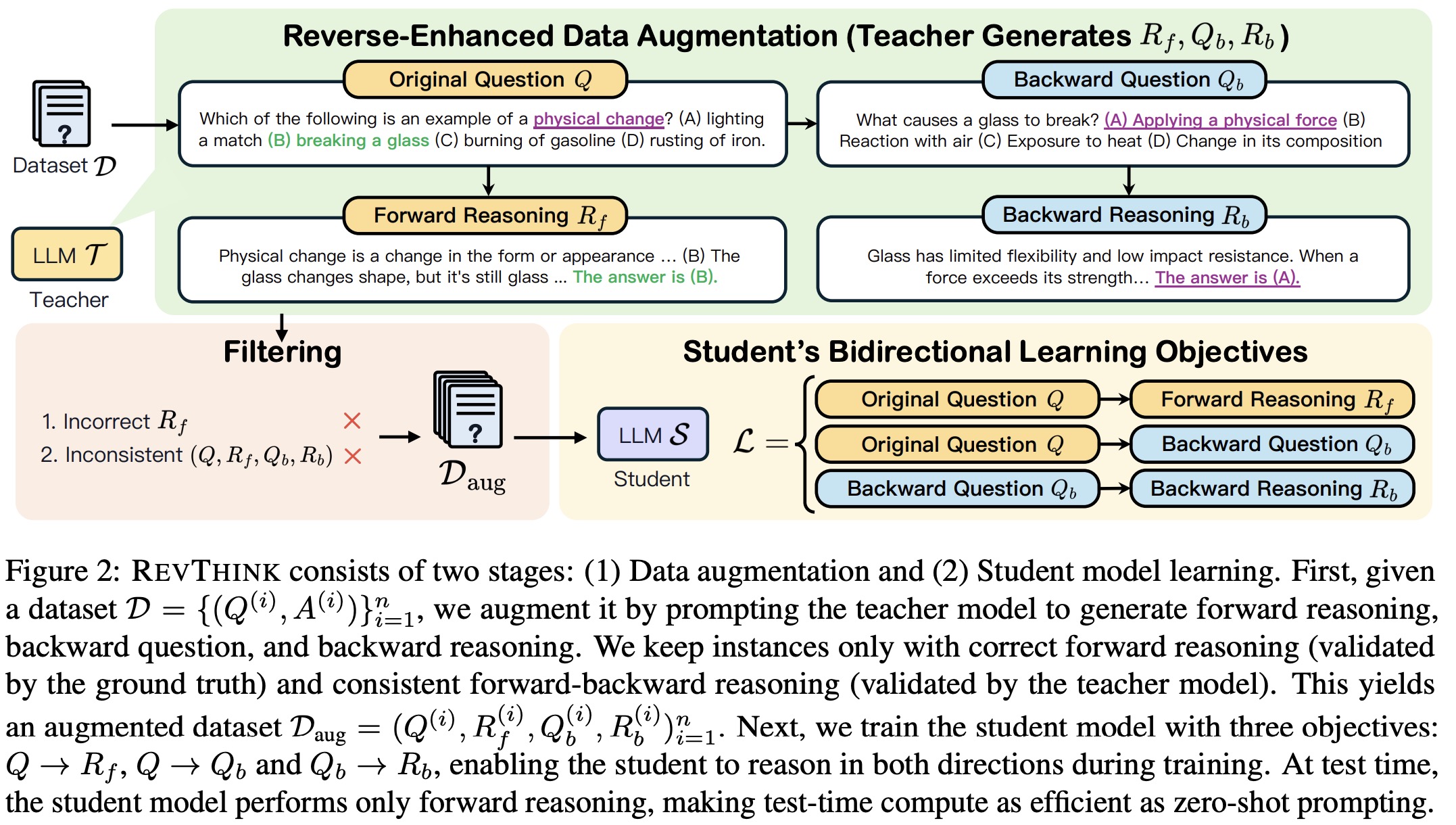
A dataset with questions and answers is augmented using a teacher model that provides forward reasoning, backward questions (reversed forms of original questions) and backward reasoning. For example, a math problem “John has 3 apples, and Emma has 2; how many apples do they have in total?” is reversed like this: “ John and Emma have 5 apples in total. If Emma has 2, how many does John have?”. The augmented dataset trains a smaller student model to enhance reasoning. During testing, the student model is prompted with only the original questions.
Forward reasoning is validated to ensure it leads to the correct answer. Consistency checks ensure the forward and backward reasoning align. Only samples with correct forward reasoning and consistent backward reasoning are retained for the augmented dataset.
The student model is trained with three objectives to enhance reasoning:
- generating forward reasoning from the original question,
- generating backward questions from the original question,
- generating backward reasoning from the backward question.
These tasks are integrated into a multi-task learning framework using cross-entropy loss. While the second and the third objectives are auxiliary tasks, they improve test-time performance when the model is prompted only with the original question.
Experiments
The teacher model is Gemini-1.5-Pro-001, Mistral-7B-Instruct-v0.3 and Gemma-7B-Instruct are the student models.
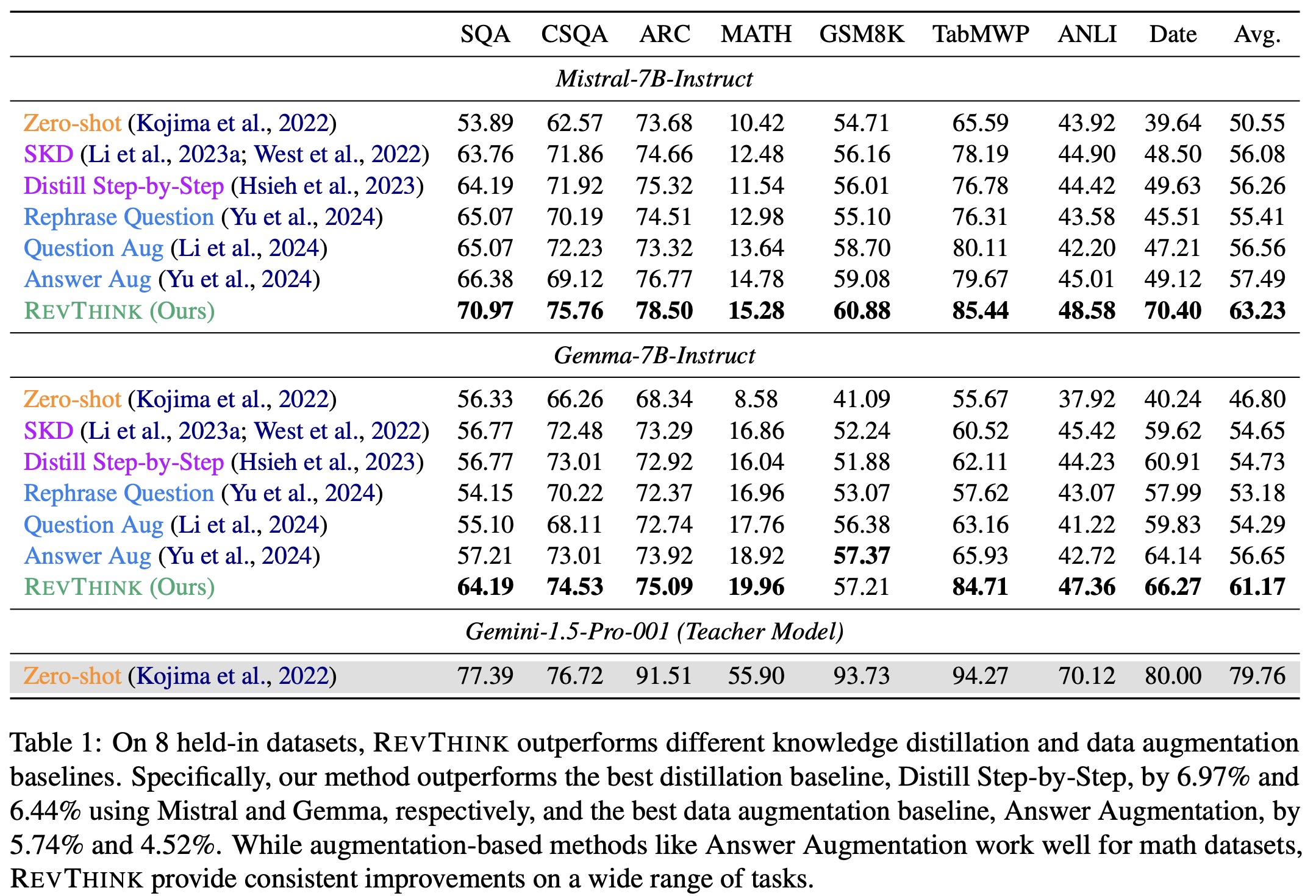
- RevThink demonstrates strong sample efficiency, consistently outperforming the SKD baseline across varying training data sizes, even achieving better results with just 10% of the data. Using all components of the augmented dataset—original question, forward reasoning, backward question, and backward reasoning—yields the best performance. While backward question generation improves results, focusing solely on reverse questions harms performance due to distributional shifts. Adding backward reasoning alongside backward question generation provides the most significant improvement.
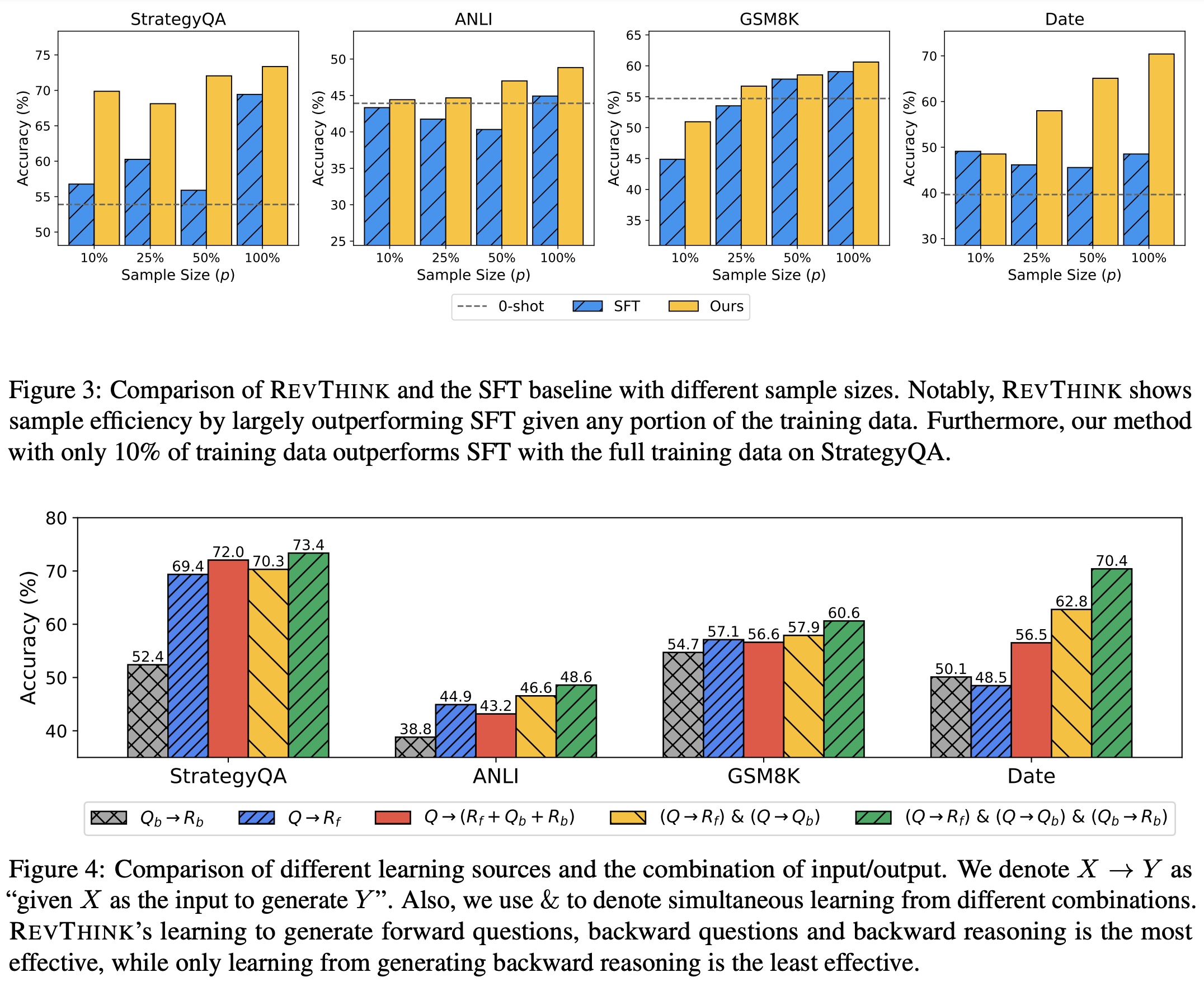
- RevThink’s joint objective approach outperforms alternative methods like instruction-based or task-prefix multi-task learning. These methods separate the dataset into distinct tasks or use task-specific prefixes, but the integrated multi-task objective used in REVTHINK is more effective.
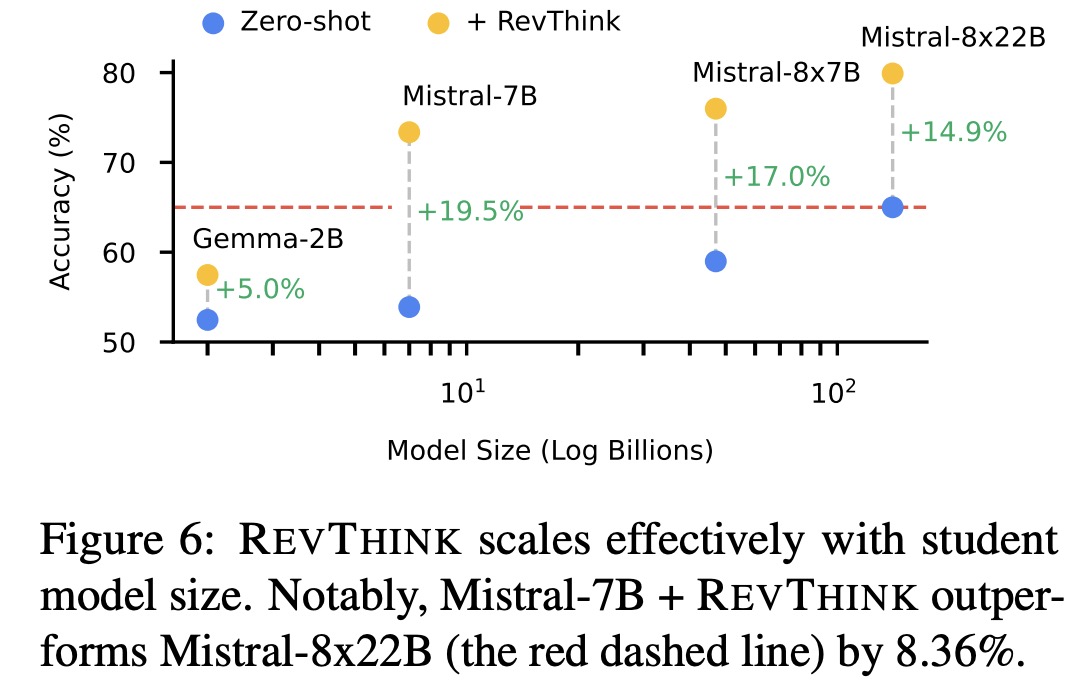
- RevThink scales effectively with model size, showing improved accuracy as model size increases. It enables smaller models, like Mistral-7B, to outperform much larger models, such as Mistral-8x22B, by 8.36%. RevThink also generalizes well to out-of-domain datasets.