Book Review: 50 ML Projects to Understand LLMs

I was offered to read 50 ML Projects To Understand LLMs by Mike X Cohen in exchange for an honest review. Rather than building, fine-tuning, or prompting LLMs, the book treats GPT-2 as a scientific specimen and teaches you to investigate it with code, statistics, and controlled experiments across 50 hands-on projects. As I have spent a lot of time working on model validation and LLM evaluation, I liked that the author focuses on the statistical discipline throughout the book — permutation tests, multiple-comparison corrections, control baselines, manipulation checks. That kind of validation rigor is what separates a real result from a lucky one, both at work and in ML competitions.

The overall structure

The 50 projects are organized into six chapters that loosely follow the flow of data through a transformer model:
- Tokenization: how text becomes integers, whether tokenization is really compression, and how strongly tokenizers favor English.
- Embeddings: cosine similarity, comparing models with representational similarity analysis, semantic axes, and analogy vectors.
- Output logits: softmax, sampling strategies, the loss function, perplexity, evaluation with HellaSwag, and measuring language bias.
- Transformer outputs: the residual stream, hidden states, the logit lens, and patching hidden states to find where a capability lives.
- Attention: query-key-value weights and activations, raw versus softmax attention scores, head silencing, and patching attention heads.
- MLP: neuron characteristics, grammar tuning, lesioning neurons, supervised probing with XGBoost, and a deliberately silly recommender-system capstone.
Each project has a similar structure: a bit of background, a task box telling you what to build, a figure to reproduce, and an interpretation of what you found. Every project includes two notebooks, a “helper” with gaps to fill and a complete solution, so you can pick your difficulty: code from a blank notebook, fill in the helper, or read the solution. Cohen explicitly tells you it is not cheating to look at the solutions. The whole book uses GPT-2, which is small enough to run on a laptop and open enough to inspect completely.
What I liked

There were many things I liked in this book, and I want to highlight several in particular:
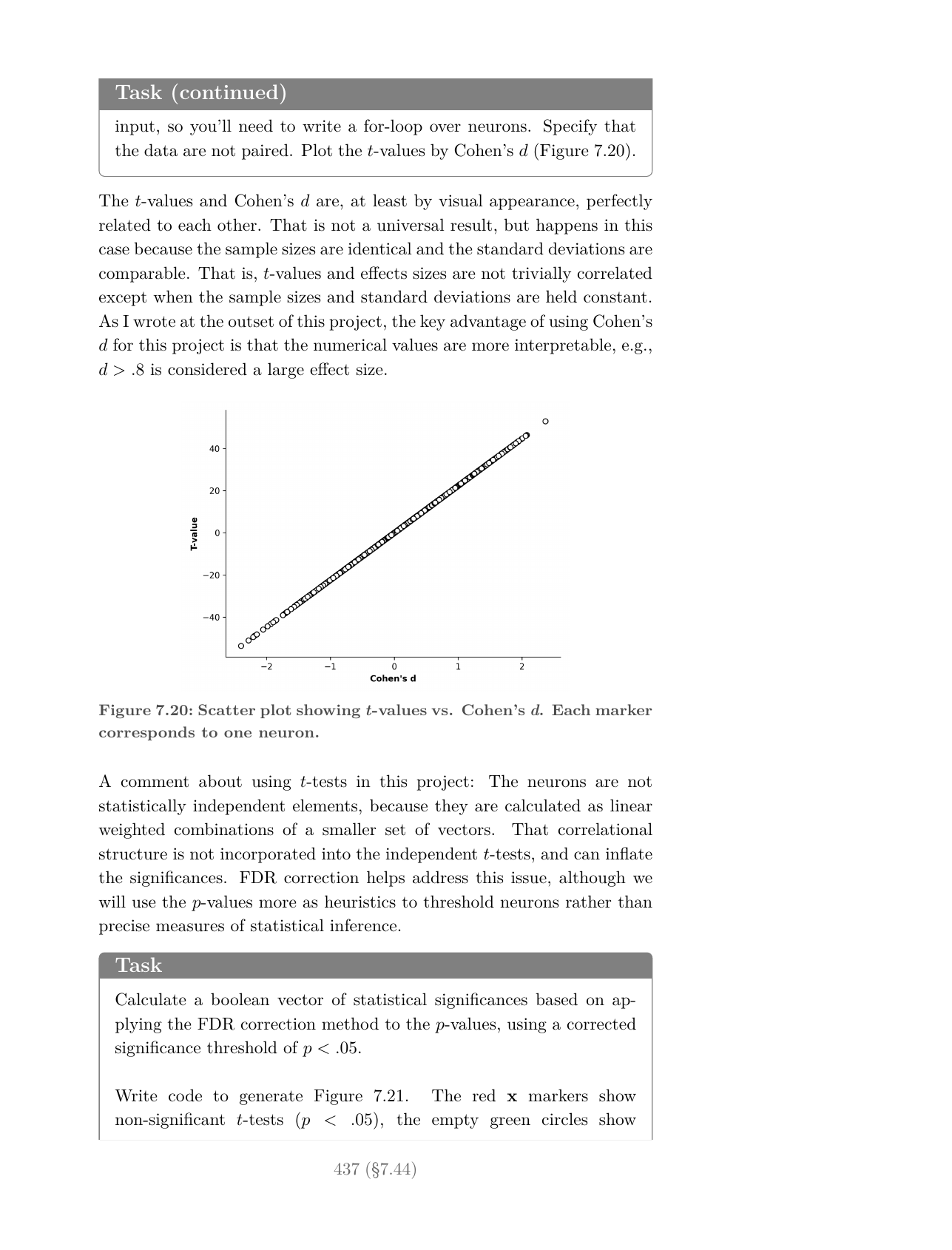
- The statistical rigor is a part of analysis: Cohen’s d for effect sizes, permutation testing with a proper discussion of exchangeability, FDR and Bonferroni corrections, split-half cross-validation, and manipulation checks.
- The controls and ablations are thorough and precise. One project ablates the least-tuned neurons as a baseline before moving the interesting ones; another compares real hidden states against shuffled ones to estimate effective dimensionality. Without that kind of baseline, it is far too easy to convince yourself that a meaningless number means something.
- The “try the obvious thing, watch it fail, learn the right approach” structure. You compare embeddings across two models with plain cosine similarity, see why it cannot work, and arrive at representational similarity analysis. You fit a linear regression to categorical token positions, watch it misbehave, and switch to logistic regression.
- GPT-2 by itself. Because the model is small, you actually run every experiment yourself instead of reading about someone else’s results.
- I liked the conversational tone of the book. “Are you disappointed in the results? I was when I first saw them!” appears more than once, and one whole project ends with the weight distributions being “not terribly interesting.” That is an unusual and welcome thing in a teaching book.
- The tokenizer-bias project, where the same sentence needs 36 GPT-2 tokens in English but 557 in Tamil.
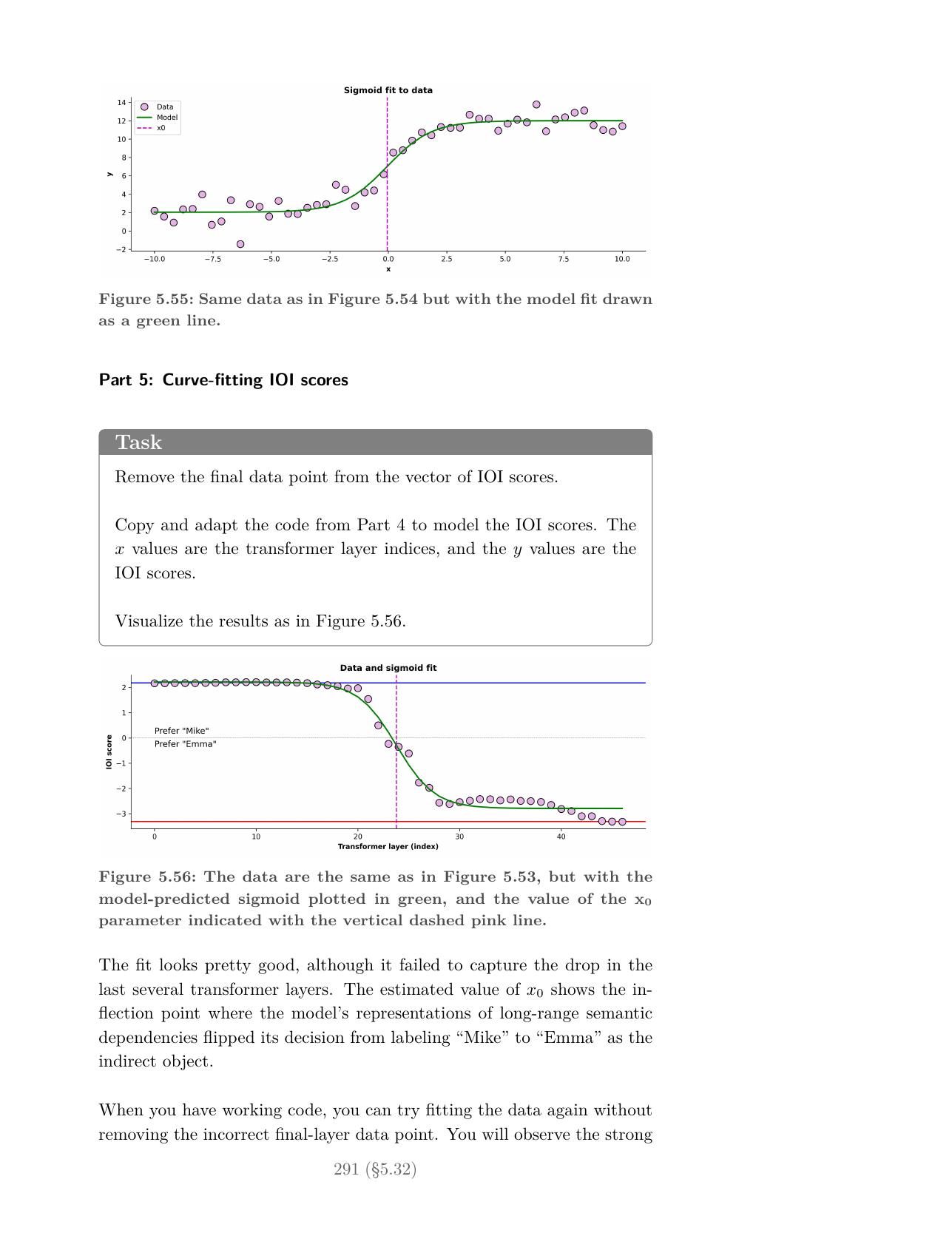
The projects I had most fun with are the ones that go deep into model internals. In Project 32, you patch hidden states inside an indirect-object-identification task and fit a sigmoid to find the layer where the model settles on the answer. In Project 44, you go looking for grammar in MLP projections: at the population level, nouns and verbs look identical, but if we drill down to the level of individual neurons, we can notice the difference. In Project 35, you analyze why negative raw attention scores enforce sparsity after softmax. These are real interpretability experiments, and you come out able to run your own.
I also liked the short section on AI assistance in the introduction. Cohen writes that “the more time goes on, the less I use AI for coding and writing,” explains that he mainly used LLMs for code review and brainstorming, and warns readers that “if you have code you do not understand and solutions you cannot explain, then you’re probably relying too heavily on AI”.
What could have been better
There are a few small things that could have been handled differently:
- Top-p sampling is called “nuclear sampling” in a couple of places, but the common name is “nucleus sampling”. A tiny fix, but it would make it easier to find the original paper.
- The book focuses almost entirely on GPT-2, with only occasional references to BERT, RoBERTa, and Pythia. Several findings are presented as general properties of transformers, and one or two more cross-model or cross-scale comparisons would make those claims more convincing. The author flags this himself, so it is more a wish than a complaint.
- The tokenization chapter spends seven projects on tokenizers but doesn’t work through a byte-pair-encoding example by hand. A short walk-through of how BPE builds its vocabulary would round out an otherwise excellent chapter.
But these are small nitpicks that are completely overshadowed by the good sides of the book.
Conclusion
This book is a good fit for people who already use transformers and want to see inside them: ML engineers and data scientists comfortable in Python, students looking for a hands-on on-ramp into mechanistic interpretability, and anyone who learns better by running experiments than by reading papers. You do need real Python skills and some patience, but you do not need a background in LLM internals, since that is exactly what the book gives you.
GPT-2 is old by the standards of the field, and the specific numbers in any interpretability result will date quickly. The value that lasts is the way of thinking: form a hypothesis, build the right control, test it properly, and stay skeptical of your own results even when they look exciting. Those habits carry over to any model, and they are what I will keep from this book long after GPT-2 stops being a useful teaching tool.
blogpost books llm interpretability transformers