Originally posted here.
Taking part in kaggle competitions is a serious challenge. You need to spend a lot of time and efforts, study new things and try many tricks to get a high score. And often this isn’t enough because there are a lot of great people, who have more experience, more free time, more hardware or some other advantages (maybe they even have all the advantages).
Previously I was able to get only silver medals in competitions. Sometimes it was thanks to luck (after shake up), sometimes it was due to a lot of work. Also there were multiple competitions where I got bronze medals (or no medals) despite all the time spent on them.
Competition description
When I saw that a new competition started at the end of May, I was immediately interested in it. It was a domain specific competition aimed at predicting interactions between atoms in molecules.
This challenge aims to predict interactions between atoms. Nuclear Magnetic Resonance (NMR) is a technology which uses the principles similar to MRI to understand the structure and dynamics of proteins and molecules.
Researchers around the world conduct NMR experiments to further understanding of the structure and dynamics of molecules, across areas like environmental science, pharmaceutical science, and materials science.
In this competition, we try to predict the magnetic interaction between two atoms in a molecule (the scalar coupling constant). State-of-the-art methods from quantum mechanics can calculate these coupling constants given only a 3D molecular structure as input. But these calculations are very resource intensive, so can’t be always used. If machine learning approaches could predict these values, it would really help medicinal chemists to gain structural insights faster and cheaper.
A start of the competition
I usually write EDA kernels for new Kaggle competitions and this one wasn’t an exception. While I was doing it, I realized that the competition was very interesting and unique. We had information about molecules and their atoms, so molecules could be represented as graphs. Common approach for tabular data in Kaggle competitions is an extensive feature engineering and using gradient boosting models.

I also used LGB in my early attempts, but knew that there should be better ways to work with graphs. This was quite fascinating and I decided to seriously take part in this competition.
First steps
I had no domain knowledge (last time I paid attention to chemical formulas was in school), so I decided to start with pure ML technics: a lot of feature engineering, creating out-of-fold meta-features and so on. As usual I published my work in kernels. As you can see in the screenshot, they were quite popular :)
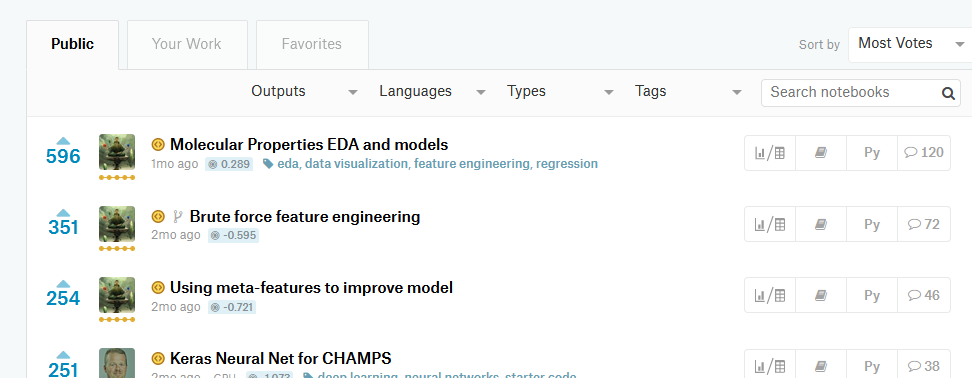
At that time this approach gave quite a good score on the leaderboard and I was able to stay in the silver zone.
On the importance of being up to date
One of the things which really helped me was reading forums and kernels. From the start of the competition and until the very end I read all the kernels and forum threads. They contain a lot of useful information which could be missed otherwise. Even less popular kernels can contain new interesting features. And small threads could contain insights, which could help increasing the score.
Starting a team
Almost since the beginning I realized that domain expertise will provide a serious advantage, so I hunted for every piece of such information. Of course I noticed that there were several active experts, who wrote on the forum and created kernels, so I read everything from them.
And one day I received an e-mail from Boris, who was an expert in this domain and thought that our skills could complement each other. Usually I prefer to work on a competition by myself for some time, but in this case combining forces seemed to be a good idea to me. And this decision turned out to be a great one :)
Merging approaches
Our approaches were quite different at the beginning: I did technical feature engineering and Boris worked on creating descriptors. After some time we realized that my models worked better on some atom pair types, and his on others — so we trained different models for different types.
We were lucky to also team up with Philip Margolis. And after little time his models showed much better results than ours.
Another member of our team became Bojan and we were able to improve our result even further.
They were really great ML experts, it was a great experience working with them on this competition.
Graph Neural Nets
At that time we already saw a potential of neural nets in the competition: a well known kaggler Heng posted an example of MPNN model.
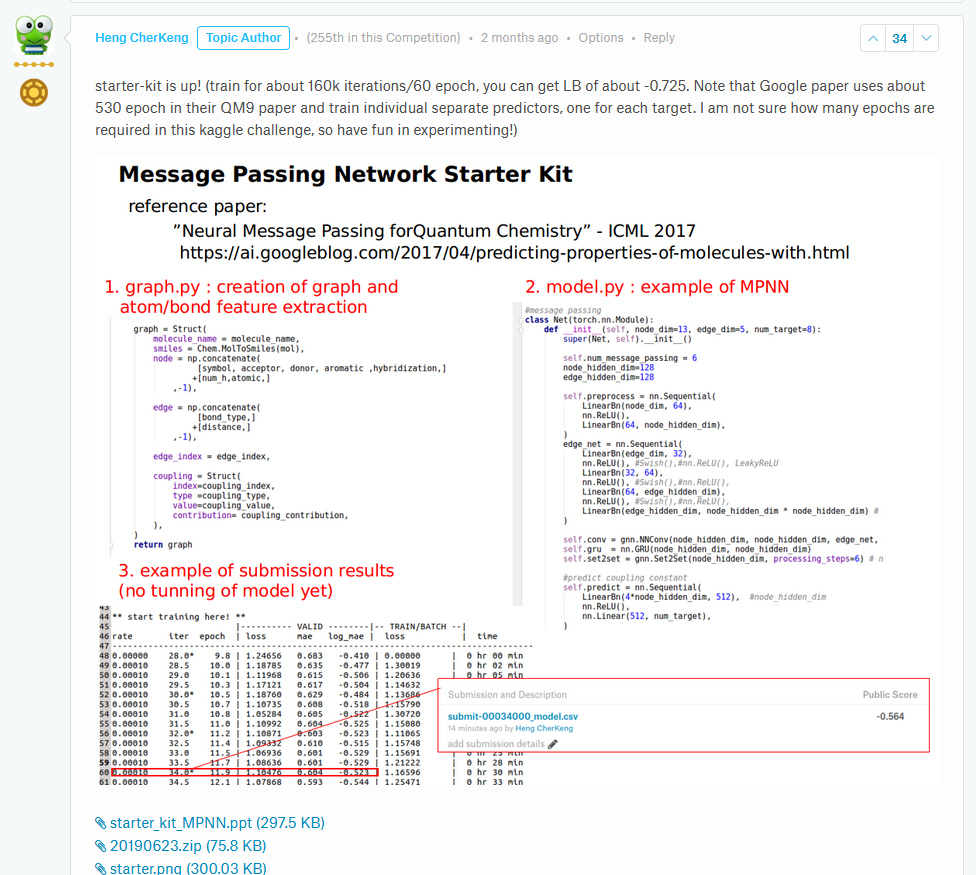
After some time I was even able to make it run on my PC, but the results were worse compared to our LGB models. Nevertheless our team knew that we would need to work with these Neural Nets if we wanted to aim high.
Some debates ensured and as a result we asked Christof to join our team. It was amazing to see how he was able to build a new neural nets extremely fast. Soon we stopped training LGB because they were far behind Christof’s neural nets.
The era of Neural Nets
Since that time my role switched to a support one. I did a lot of experiments with our neural nets: trying various hyperparameters, different architectures, various little tweaks to training schedule or losses and so on. Sometimes I did EDA on our predictions to find our interesting or wrong cases and later we used this information to improve our models even further.
One of my main contributions was looking for new approaches:
- I looked through a lot of papers on neural net architectures: EAGCN, 3DGNN and many others;
- I tried various losses, such as huber. I even found a paper with an idea of focal loss for regression, but it wasn’t feasible to implement it;
- Of course I tried new hot optimizers like RAdam and Ranger, but simple Adam was better in our case;
- And many other things;
But in the end it was Christof who implemented the architectures and it left me very impressed and inspired.
Hardware

Good hardware is really important for training these neural nets. We used a lot of hardware, trust me, really a lot :) But! We also used kaggle kernels a lot: you can train models in 4 kaggle kernels with P100 at the same time (now only 1), so we could get gold medal even without additional hardware.
The results and conclusions
Our final solution secured us the 8th place and gold medals. And I’m kaggle master now :)
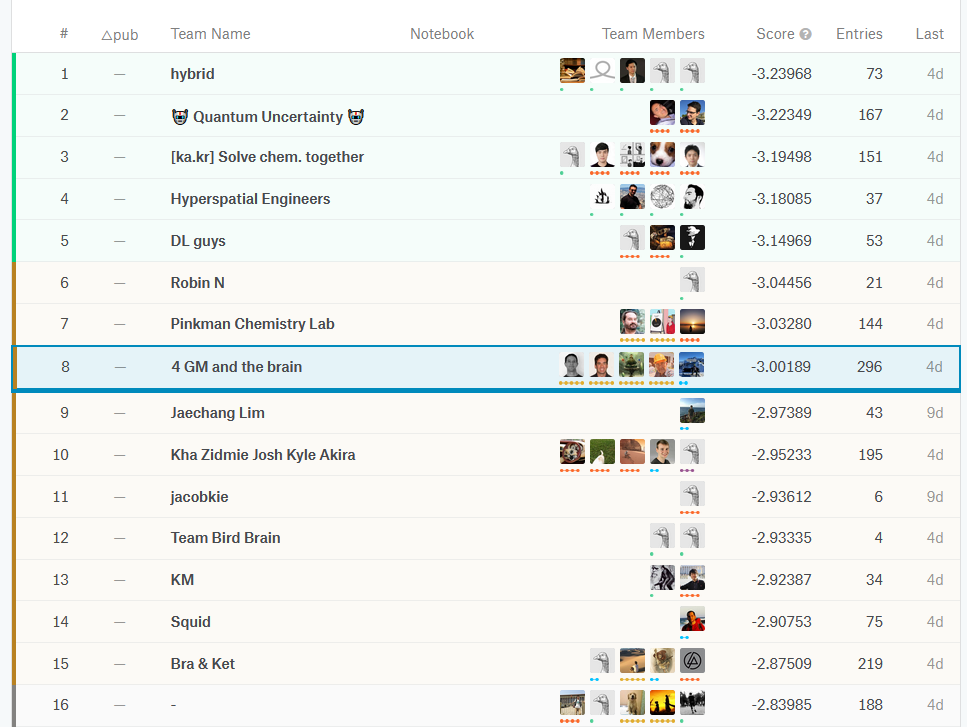
It is worth noticing that our team is among those who were able to get score better than -3 lmae (Log of the Mean Absolute Error averaged across types). In this thread competition hosts wrote that they would be excited to see scores better then -3 and we did it!
There were a lot of things I learned from this competition and here some lessons which I’d like to share:
- read kernels and forums, they provide a lot of useful information;
- be prepared to make a lot of failed experiments. While you are trying to find a next new thing which will improve your score, you’ll test a lot of ideas and most of them won’t work. Don’t be discourages;
- always look for new ideas, read new papers and articles. You never know where you find a new cool working idea;
- create a validation which will be used by the team, so that experiments are comparable;
- a great team consists of people with different skills which should cover different areas;
- Kaggle competitions are fun, even though tiring :)
I was lucky to work with these amazing people and would like to thank them for that!
blogpost datascience kaggle competition gnn