Originally posted here.
Several weeks ago one more Kaggle Competition has ended — Bengali.AI Handwritten Grapheme Classification.
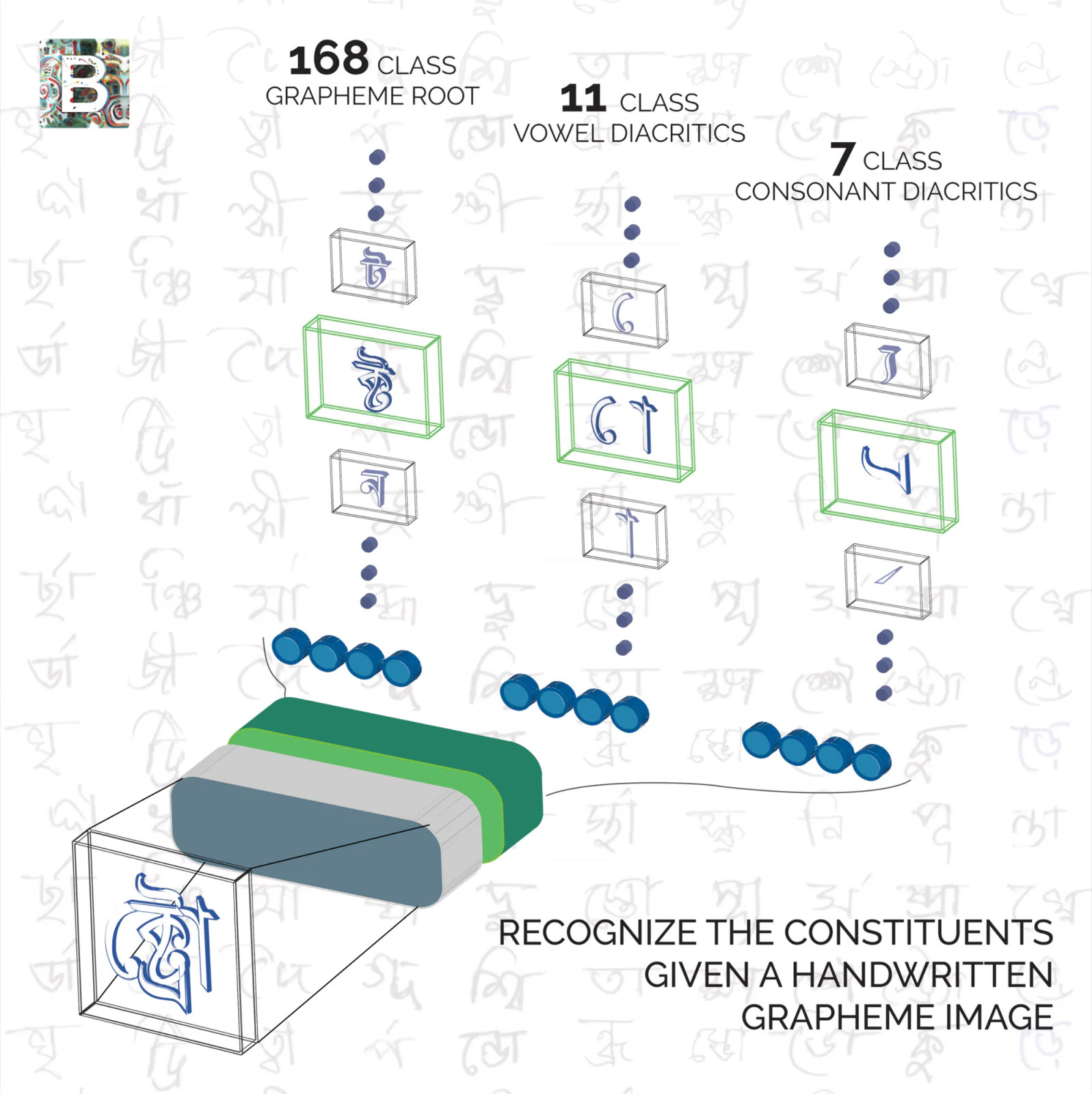
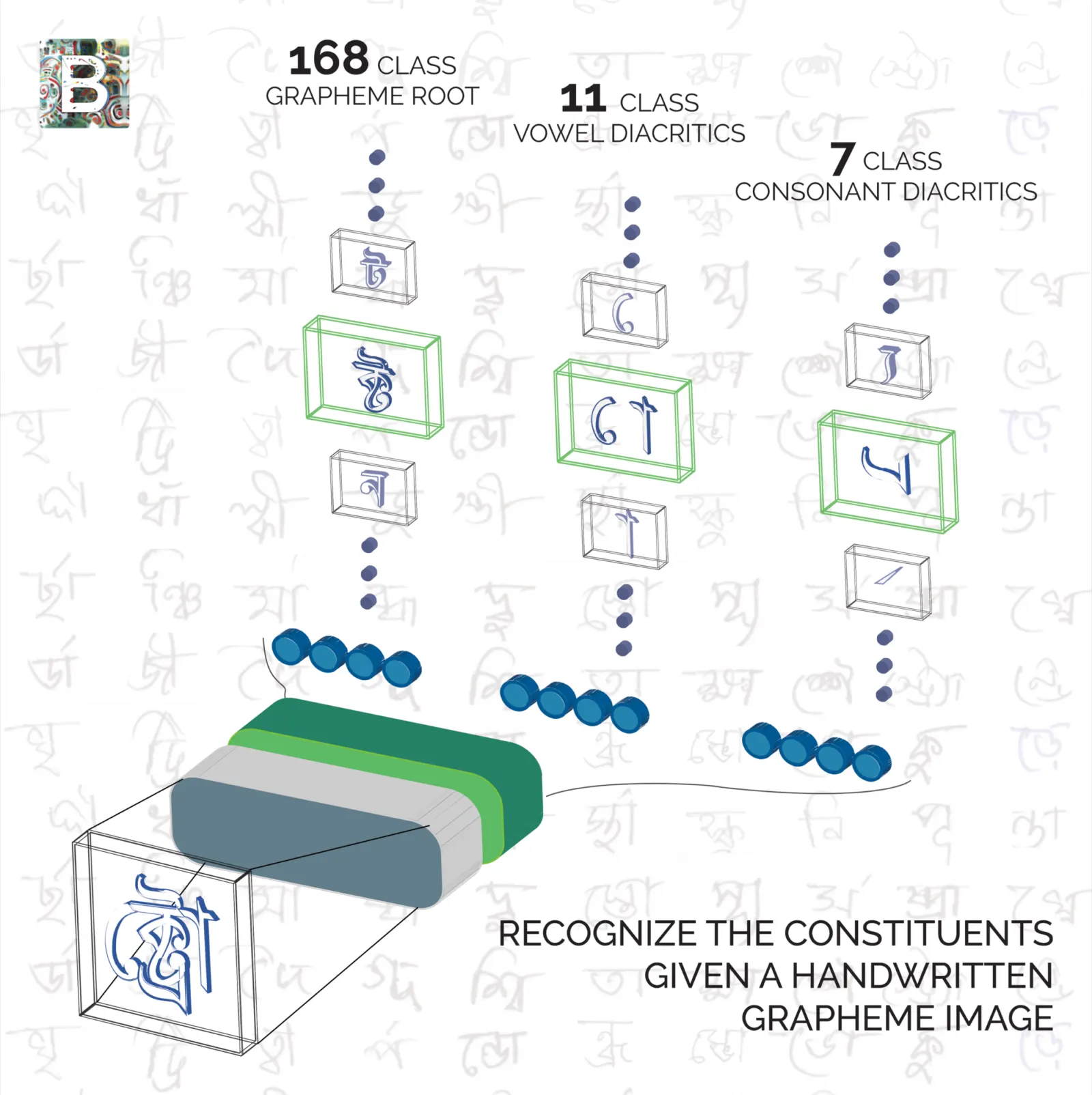
Bengali is the 5th most spoken language in the world. This challenge hoped to improve on approaches to Bengali recognition. Its alphabet has 49 letters and 18 diacritics, which means there are a lot of possible graphemes (the smallest units in a written language).
In this competition we are supposed to predict classes for three separate parts of these graphemes — grapheme root, vowel diacritics, and consonant diacritics.
More than 2 thousands teams took part in the competition. At first I was taking part in the competition alone, but after some time a team of five people was formed. We have spent a lot of time and resources on this competition… and finished at 254th place without any medals.
I was quite depressed with these results and was moping around for some time.
After this I have organized my thoughts, reflected on the things I have done, read the solutions by top teams and learnt several lessons, which I want to share. These lessons are general and can be applied to any competition. They can be broadly split in several topics: the mindset and general approaches, coding practices, being prepared.
Set up your working environment

Training models is the main part of kaggle competitions, so it is necessary to be prepared for it. Kaggle Notebooks are good, but GPU time limit is harsh — only 30h per week. As a result experiments are usually run on our own hardware or in clouds. First of all it is necessary to set a working environment. It could be done using pip, conda or in some other way. It is worth checking libraries version on kaggle and install the same version in your environment -different versions could have different API or different logic.
Hardware

Another important thing is the hardware itself of course. If we have a lot of data (as in this competition) training a single model could take a day or even more on a single video card. It is worth mentioning that running experiments usually will take much more time than training the final models, as we need to try a lot of different things.
I have 2 x 1080ti on my Windows PC and it is really not enough. I have rented GPU on Google Cloud multiple times, but it is quite expensive, so I started looking for other approaches.
Recently I had heard about Hostkey — they provide web services and you can rent their servers.
They had a promo program:
We offer free GPU servers to the winners of grants at large competition venues for their use in further competitions, for training or for personal projects related to data science.
In exchange the participants should share their feedback and experience in social media.
At first I got a server with 4 x 1080ti. There was no problem with setting up the environment and soon I started training the models. Training on a single GPU worked well and I started gradually increasing the number of cards used. 2, 3 GPU worked well, but using all 4 GPU failed — nothing was happening. Technical support reacted fast and investigated the problem within a couple of days. It turned out there was some problem with the server itself — the processor wasn’t able to keep up with the full utilization of 4 x 1080ti. As a result I switched to another server — with 2x2080ti. At first there was a small problem as power supply wasn’t powerful enough (pun intended), but the engineers added another power supply and the problem was solved.
Since that time I run a lot of models on the server and everything worked great. I liked the experience and plan to continue using servers from Hostkey in the future.
Have a working pipeline
It is quite important to have a good working pipeline. By pipeline I mean the whole code which is used to prepare data for training, the training itself and inference. It could be worth using some high-level frameworks, but it is also a good idea to write your own code from scratch. The main benefit is the possibility to change things fast and being sure that all basic things work correctly and you can focus on the advanced things.
In this competition I started with using Jupyter API in Catalyst, but stopped soon due to some problems with it. After some time I switched to Config API of Catalyst thanks to my teammates. It worked better for me, but it took a lot of time to get used to it. One of my teammates was using fastai, alas it was difficult for me to understand it due to the unique style of fastai.
As a result I think that it would be better to select a single approach (a certain framework or your own pipeline) and stick to it.
Code optimization
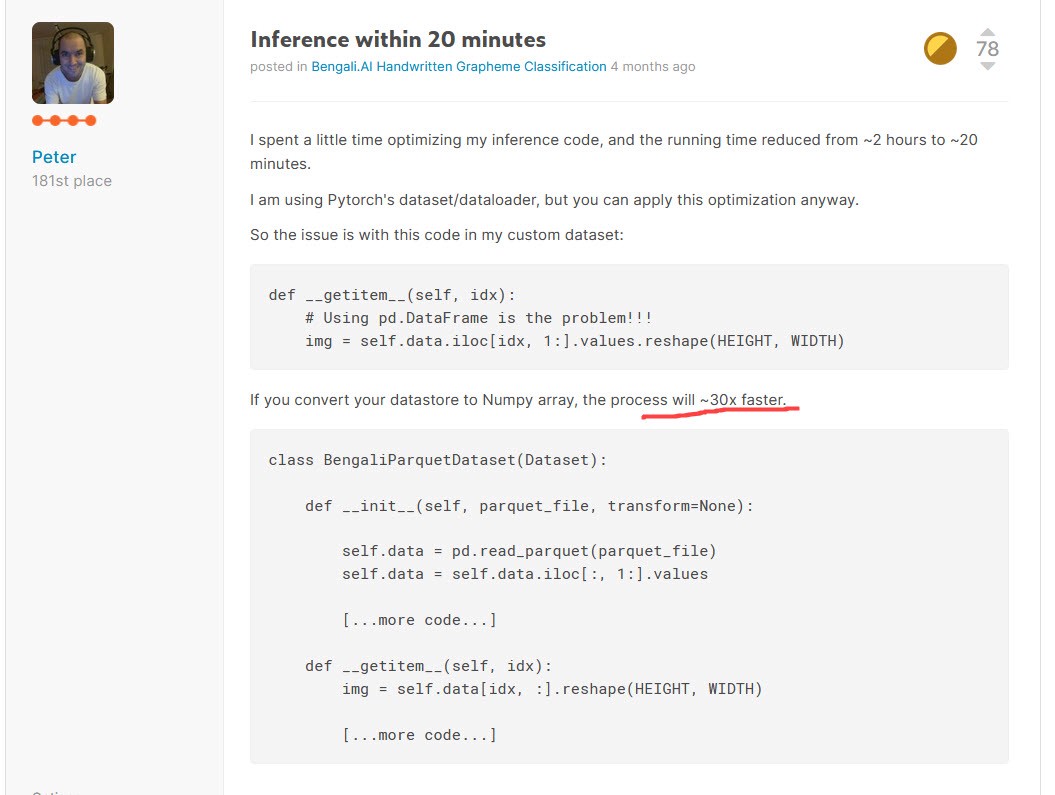
A lot of people say that the code which people write it kaggle competitions is abysmal. In fact it is often true, one of the main reasons is the necessary to iterate fast, so usually it is better to try some new ideas instead of writing better code. But this isn’t always correct.
Sometimes small code optimizations can have a huge impact. As you see in the screenshot, it is possible to make inference 30x times faster. The training also would be much faster, so it is important to do things right.
On the other hand…
Don’t blindly trust code and ideas from forums/kernels

Kaggle is great, there are a lot of great notebooks, which you can use, and there are forums where you can find cool ideas, right? No, well, not exactly.
While there are a lot of high-quality notebooks and outstanding ideas on forums, there are also some problems:
- there are some notebooks with little mistakes in code, with wrong code practices, with incorrect validation, with wrong implementations of some ideas and many other possible problems;
- some ideas in forums could be misleading. It isn’t because people wanted to do something bad, no, one of the reasons is that a lot of ideas don’t work on their own — some work only together with other ideas, some require models of good enough score and so on;
So, if you want to use some code or some ideas, first check and validate them.
As a continuation of this point:
Always look for new ideas and try them
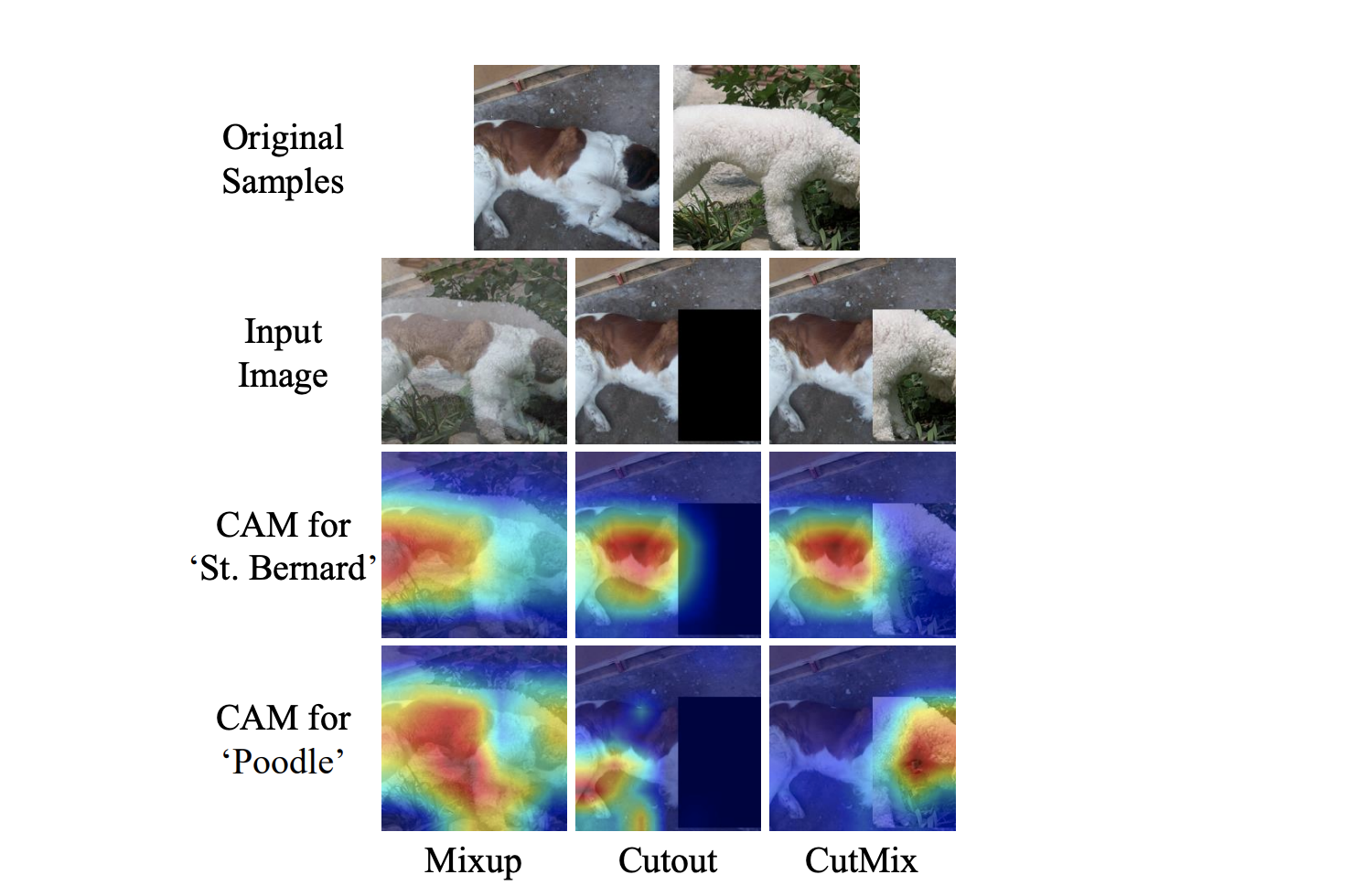
One of the best and coolest thing in taking part in kaggle competitions is that it pushes people to the new SOTA results. And to achieve the best score it is necessary to try new things. So read papers on arxiv, look for good blogposts and so on. But it isn’t enough to read about new approaches — it is necessary to try them. It can be difficult to write code for some new idea, but it is an amazing way to learn new things. Even if some ideas don’t work, you got a useful experience.
Don’t tune hyperparameters too much

This is a common pitfall (and I got caught it in multiple times) — some people think that tuning hyperparameters will help them get great results. There is some merit to this idea, but it isn’t completely correct.
In tabular competitions it is worth tuning hyperparameters two times: at the very beginning and at the very end.
Tuning in the beginning is important, because gradient boosting and other models have to be tuned for different problems. Different objectives, different depth, number of leaves and other things could result in very different score in different problems. But after you have found some good parameters, fix them and don’t touch until near the end of the competition. When you add new features or try new ideas, keep hyperparameters the same, so that you can compare the experiments.
And when you exhaust all the ideas, you can tune again to get a small increase of score.
For deep learning the things are a bit different. The space of hyperparameters is huge: you tune the architecture, the losses, the augmentations, pre- and post-processing and other things. So inevitable you’ll spend much more time on optimizing things. But still it is worth remembering that one good idea could improve the score much more that tuning little things.
These were the lessons which I learned from this competition. I hope they were useful and really hope I’ll be able to follow them myself :)
blogpost datascience kaggle competition fail