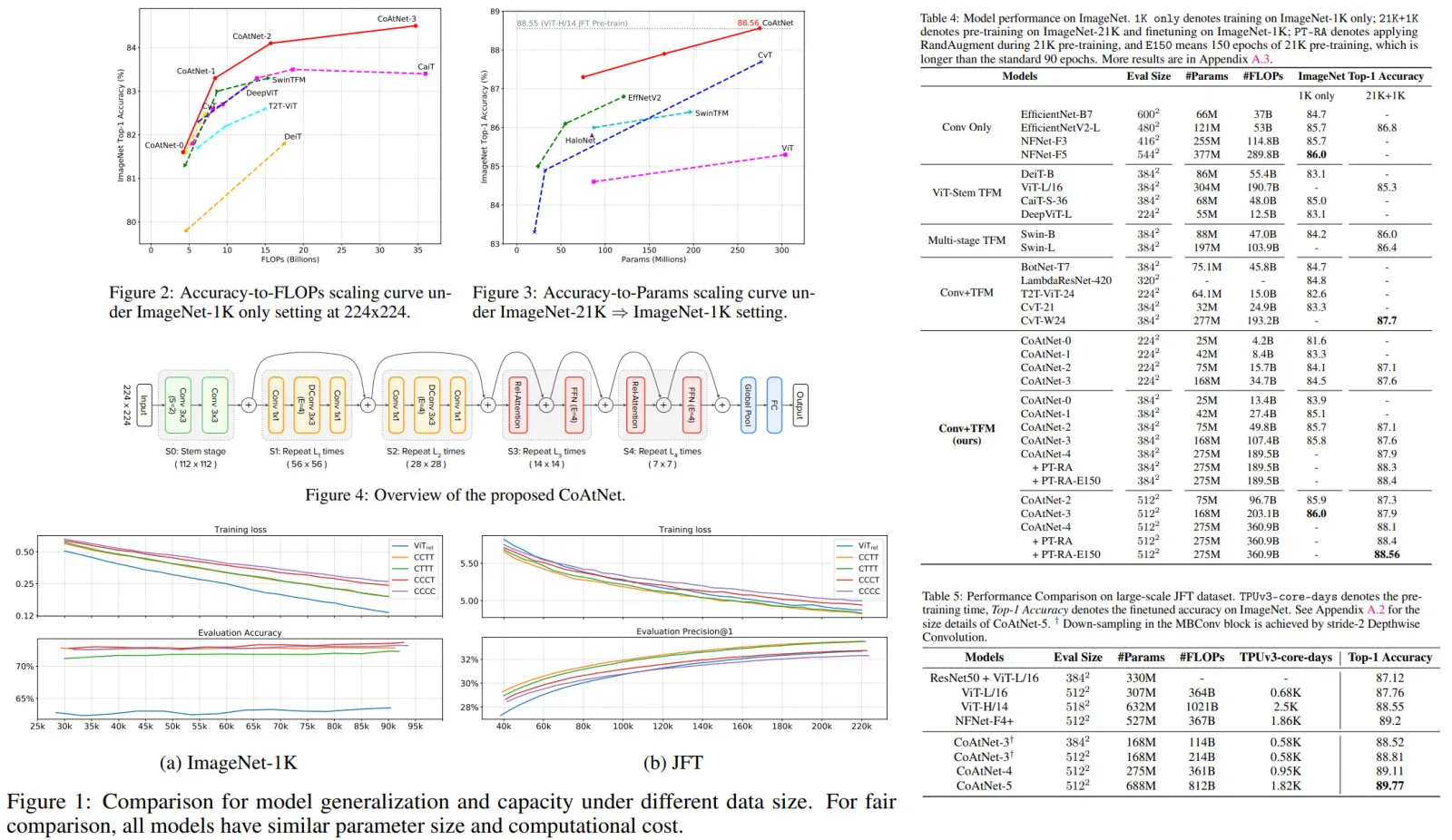
Paper Review: Adversarial Diffusion Distillation
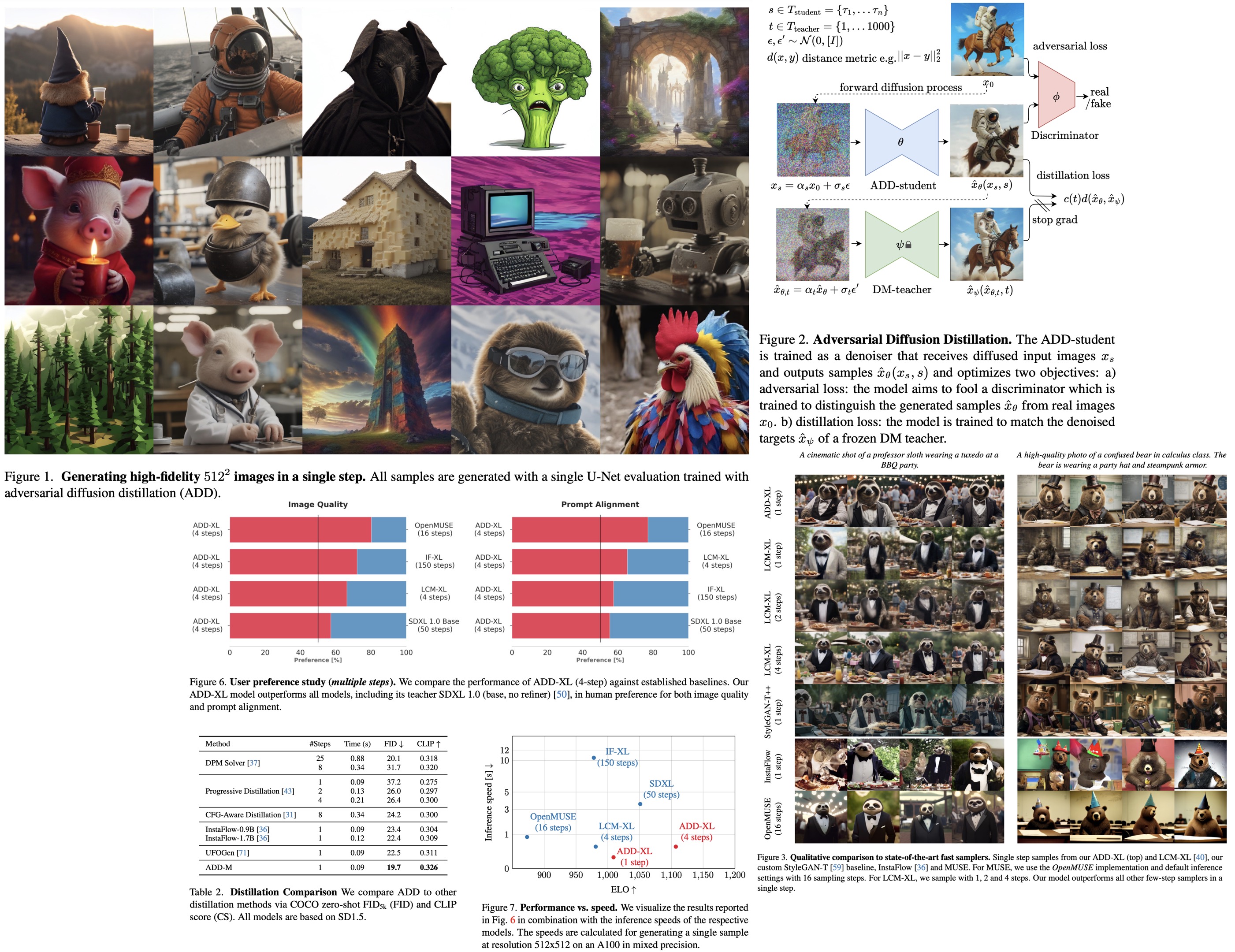
Adversarial Diffusion Distillation (ADD) is a new training approach that samples large-scale foundational image diffusion models efficiently in 1-4 steps while maintaining high image quality. It combines score distillation, using existing image diffusion models as a teaching signal, with an adversarial loss to ensure fidelity in low-step sampling. ADD surpasses existing few-step methods like GANs and Latent Consistency Models in a single step and equals the performance of SDXL in just four steps, marking a significant advancement in single-step, real-time image synthesis with foundation models.
Method
The goal is to generate high-fidelity samples quickly while achieving the quality of top-tier models. The adversarial objective enables fast generation by producing samples in a single step, but scaling GANs to large datasets has shown the importance of not solely relying on the discriminator. Incorporating a pretrained classifier or CLIP network enhances text alignment, however, overuse of discriminative networks can lead to artifacts and reduced image quality.
To address this, the authors leverage the gradient of a pretrained diffusion model through score distillation to improve text alignment and sample quality. The model is initialized with pretrained diffusion model weights, known to enhance training with adversarial loss. Finally, rather than a decoder-only architecture typical in GAN training, a standard diffusion model framework is adapted, allowing for iterative refinement.
Training Procedure

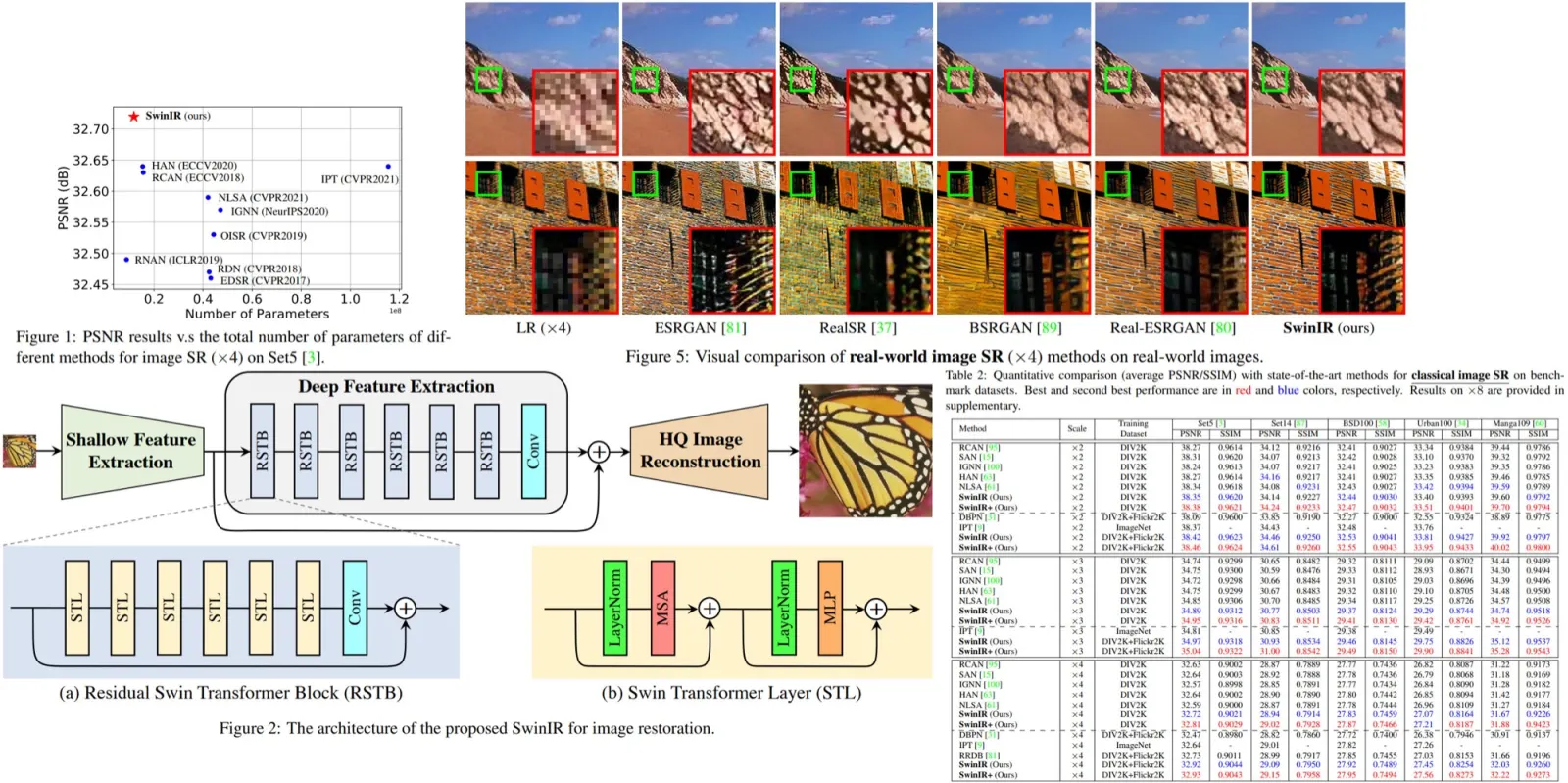
The training procedure involves three networks: the ADD-student initialized from a pretrained UNet-DM, a discriminator with trainable weights, and a DM teacher with frozen weights. The ADD-student generates samples from noisy data, which are produced from real images through a forward diffusion process. The process uses coefficients and samples timesteps uniformly from a chosen set, typically four timesteps, starting from pure noise.
For the adversarial objective, the discriminator distinguishes between generated samples and real images. Knowledge is distilled from the DM teacher by diffusing student samples with the teacher’s process and using the teacher’s denoising prediction as a reconstruction target for the distillation loss. The overall objective combines the adversarial loss and distillation loss.
The method is formulated in pixel space but can be adapted to Latent Diffusion Models operating in latent space. For LDMs with a shared latent space between teacher and student, the distillation loss can be computed in either pixel or latent space, with pixel space providing more stable gradients for distilling latent diffusion models.
Adversarial Loss
The discriminator design and training procedure use a frozen pretrained feature network, typically ViTs, and a set of trainable lightweight discriminator heads applied to features at different layers of the network. The discriminator can be conditioned on additional information, such as text embeddings in text-to-image settings, or on a given image, especially useful when the ADD-student receives some signal from the input image. In practice, an additional feature network extracts an image embedding to condition the discriminator, enhancing the ADD-student’s use of input effectively. The hinge loss is used as the adversarial objective function.
Score Distillation Loss
The distillation loss measures the mismatch between samples generated by the ADD-student and the outputs from the DM-teacher, using a distance metric. The teacher model is applied to diffused outputs of the student’s generations, not directly to the non-diffused student outputs, as these would be out-of-distribution for the teacher.
The distance function used is the squared L2 norm. The weighting function has two options: exponential weighting, where higher noise levels contribute less, and score distillation sampling weighting. With specific choices for the distance function and weighting function, the distillation loss becomes equivalent to the SDS objective.
This formulation allows for direct visualization of reconstruction targets and facilitates consecutive denoising steps. Additionally, the approach also evaluates a noise-free score distillation objective, a recent variant of SDS.
Experiments


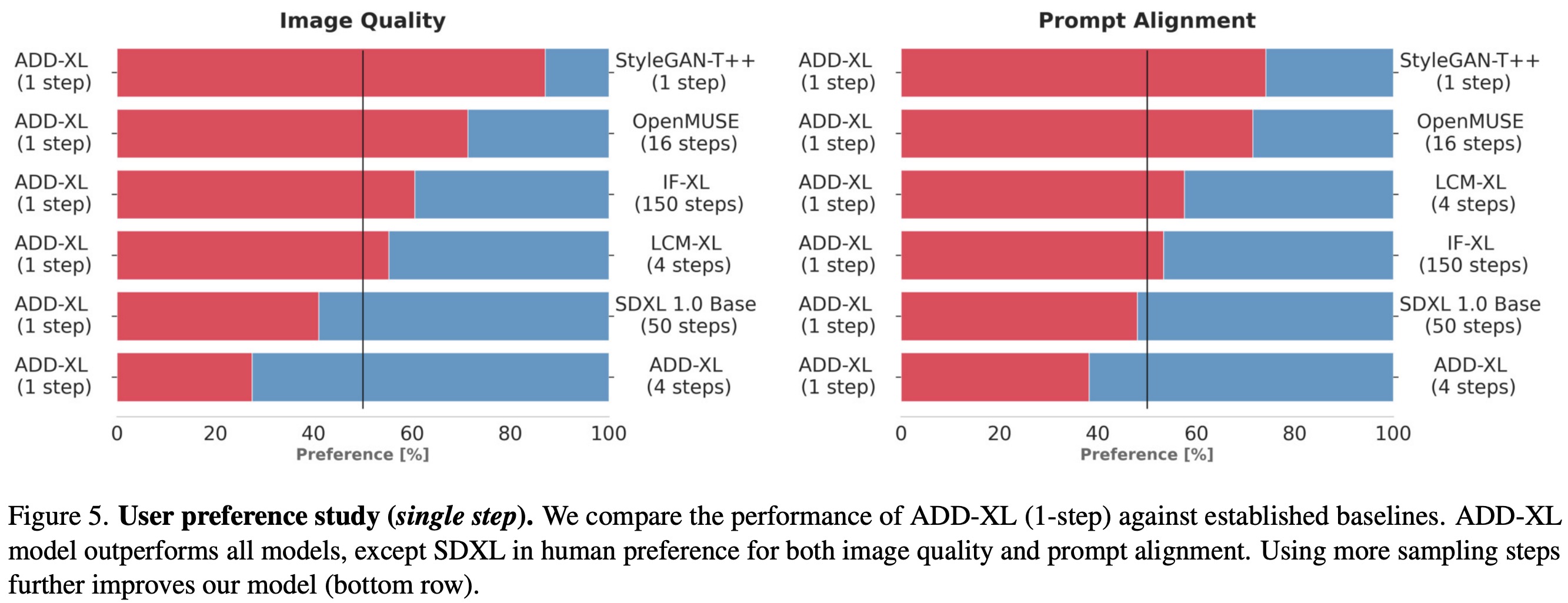
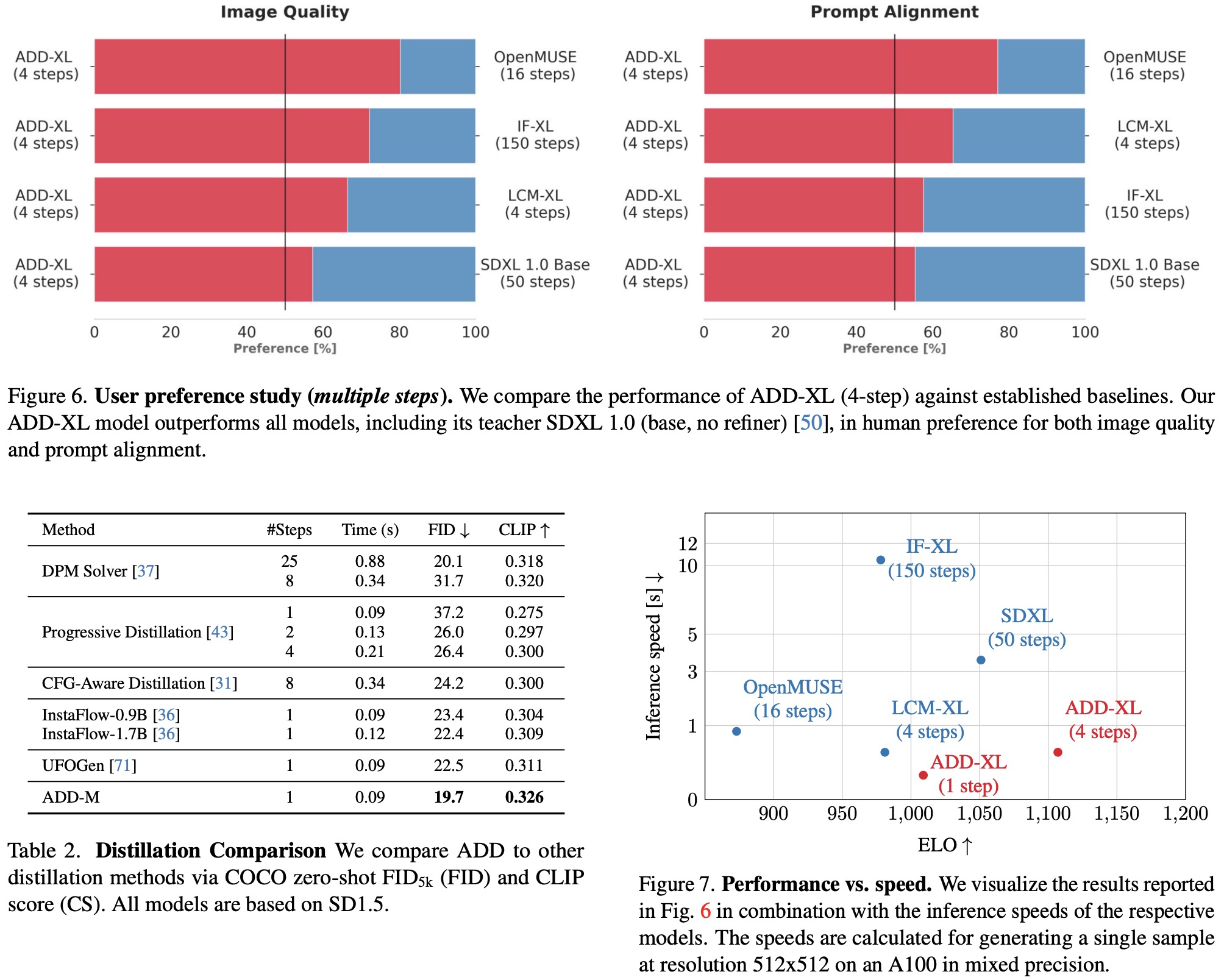
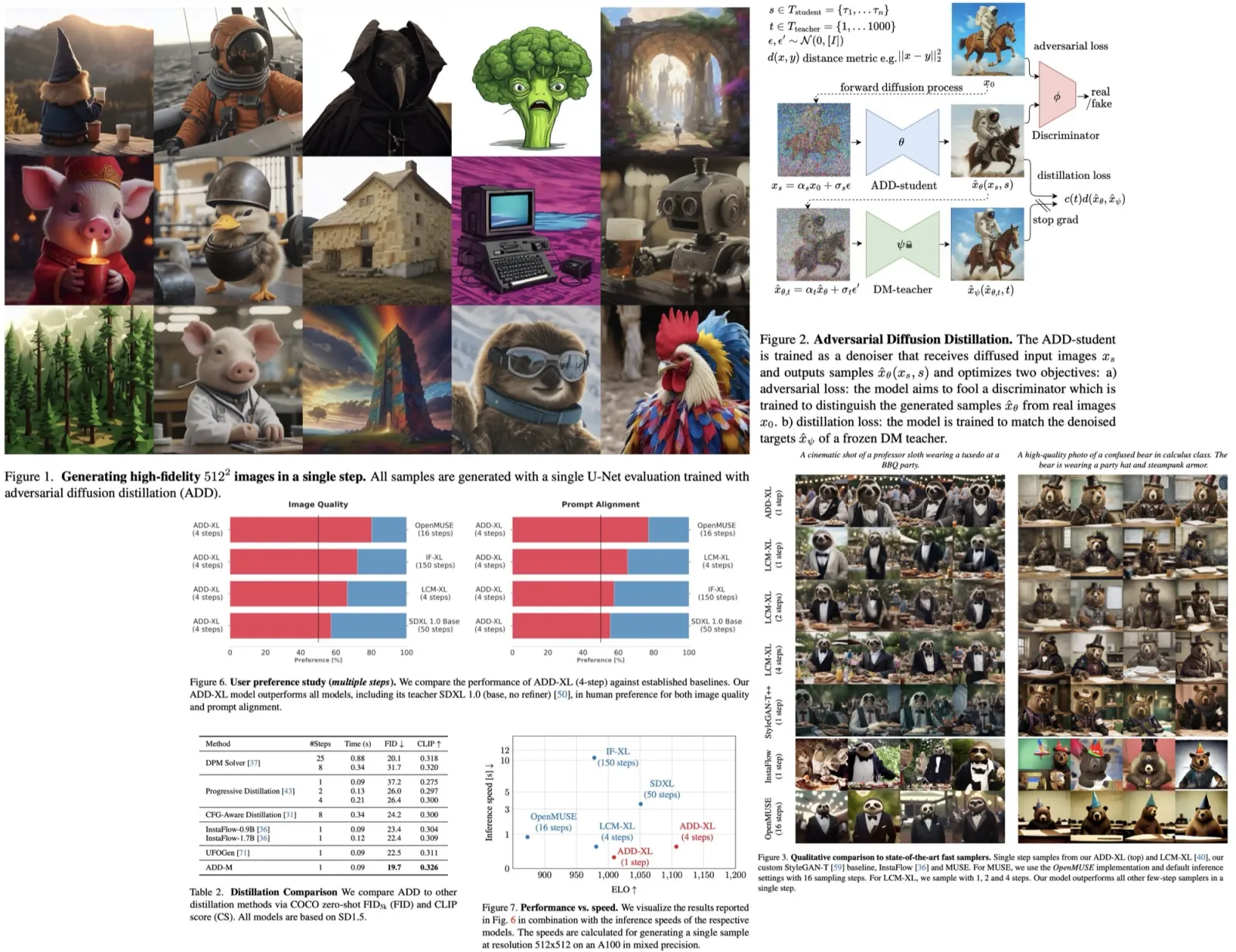
In comparing ADD with other approaches, user preference studies considered more reliable than automated metrics, were used. This study focused on assessing both prompt adherence and overall image quality. Win percentages and ELO scores were calculated for pairwise comparisons and multiple approach comparisons, respectively, taking into account both prompt following and image quality.
ADD-XL outperforms LCM-XL with just a single step and can beat SDXL (which takes 50 steps) with only four steps in most comparisons. This establishes ADD-XL as state-of-the-art in both single and multiple steps settings. ADD surpasses other approaches, including the standard DPM solver, even with fewer steps. ADD-XL is efficient in terms of the inference speed.
The iterative sampling process of ADD-XL illustrates the model’s ability to refine an initial sample, a significant advantage over pure GAN approaches like StyleGAN-T++. ADD-XL is directly compared with its teacher model, SDXL-Base, outperforming it in quality and prompt alignment but with a slight trade-off in sample diversity.
Ablation Study
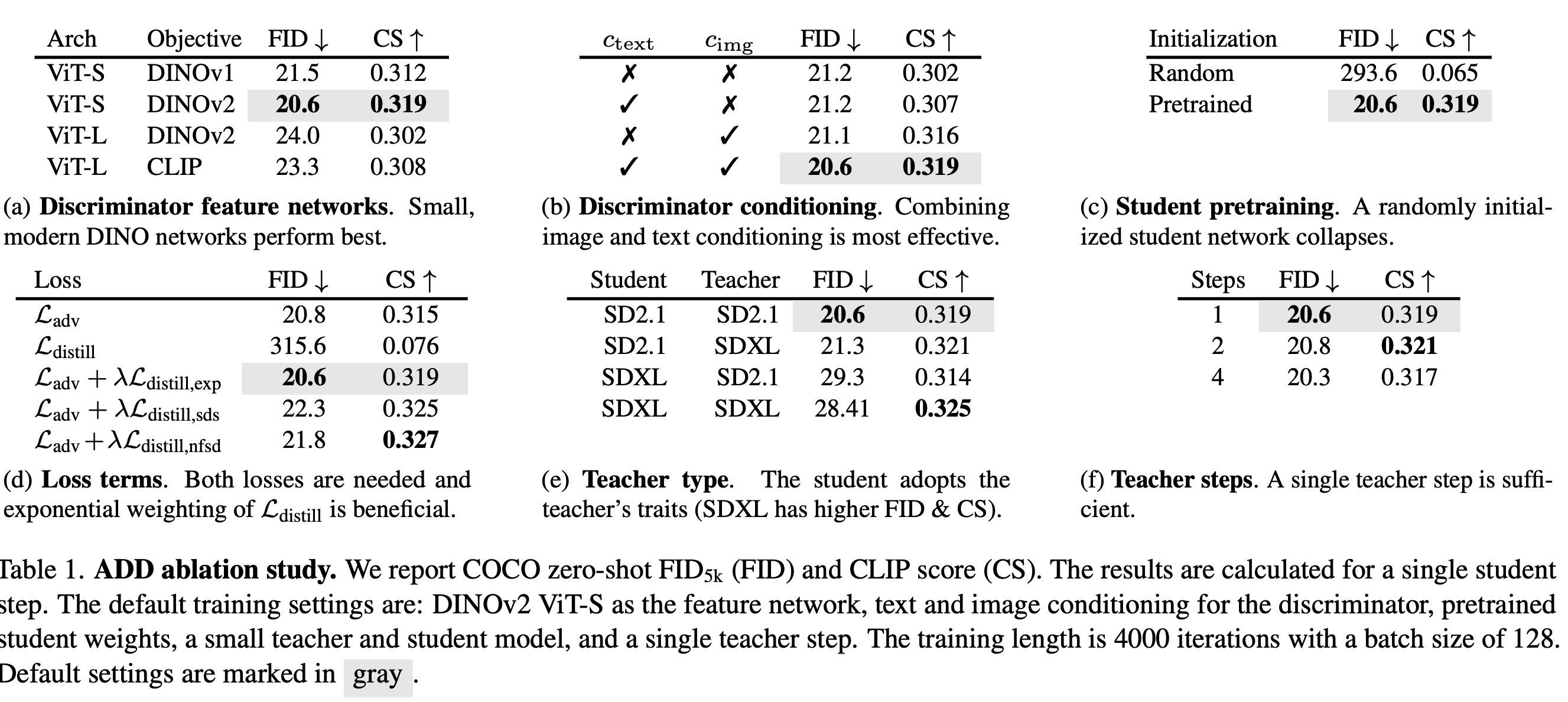
- Discriminator Feature Networks: ViTs trained with CLIP or DINO objectives are effective as discriminator feature networks, with DINOv2 emerging as the best choice.
- Discriminator Conditioning: Text conditioning of the discriminator enhances results, but image conditioning outperforms text conditioning. The best results are achieved by combining both text and image conditioning.
- Student Pretraining: Pretraining the ADD-student is crucial. Unlike GANs, which face scalability issues, ADD can leverage larger pretrained diffusion models, benefiting from stable DM pretraining.
- Loss Terms: Both the distillation and adversarial losses are essential. The distillation loss alone is ineffective, but combined with the adversarial loss, it significantly improves results. Different weighting schedules affect sample diversity and quality; the exponential schedule tends to yield more diverse samples, while SDS and NFSD schedules improve quality and text alignment. NFSD weighting is chosen for training the final model.
- Teacher Type: A larger student and teacher don’t necessarily lead to better results. The student tends to adopt the teacher’s characteristics. For instance, SDXL, while having higher FID, shows higher image quality and text alignment.
- Teacher Steps: Although the distillation loss formulation allows for multiple consecutive steps with the teacher, multiple steps do not conclusively enhance performance.