Paper Review: Scalable Pre-training of Large Autoregressive Image Models
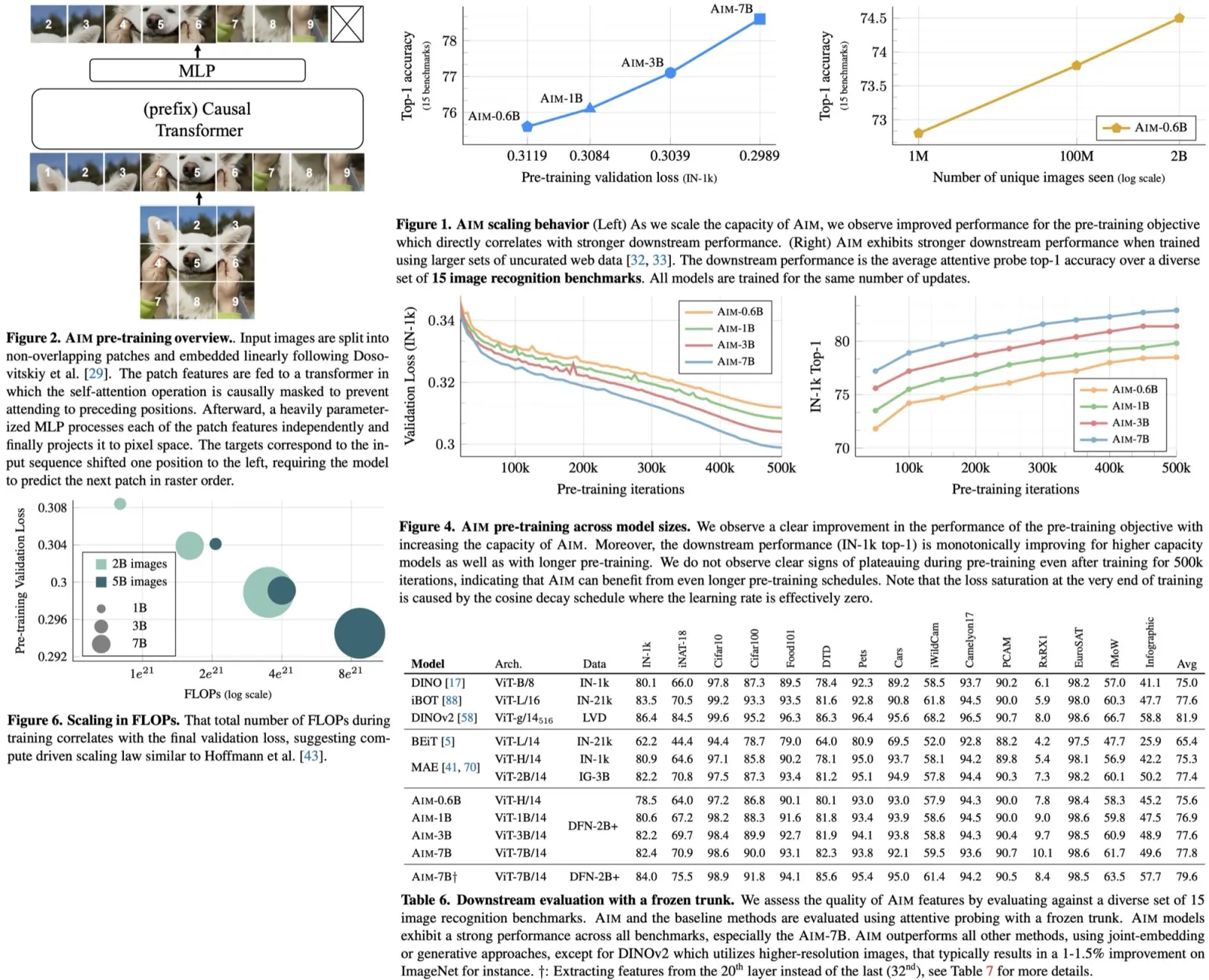
AIM is a collection of vision models pre-trained with an autoregressive objective inspired by LLMs and demonstrating similar scaling properties. The authors’ findings include the scaling of visual feature performance with model capacity and data quantity and a correlation between the objective function value and model performance in downstream tasks. 7B AIM pre-trained on 2 billion images achieves 84.0% on ImageNet1k with a frozen trunk without showing performance saturation, indicating a potential new frontier in large-scale vision model training. AIM’s pre-training process mirrors that of LLMs and doesn’t require unique image-specific strategies for stable scaling.
Pre-training Dataset
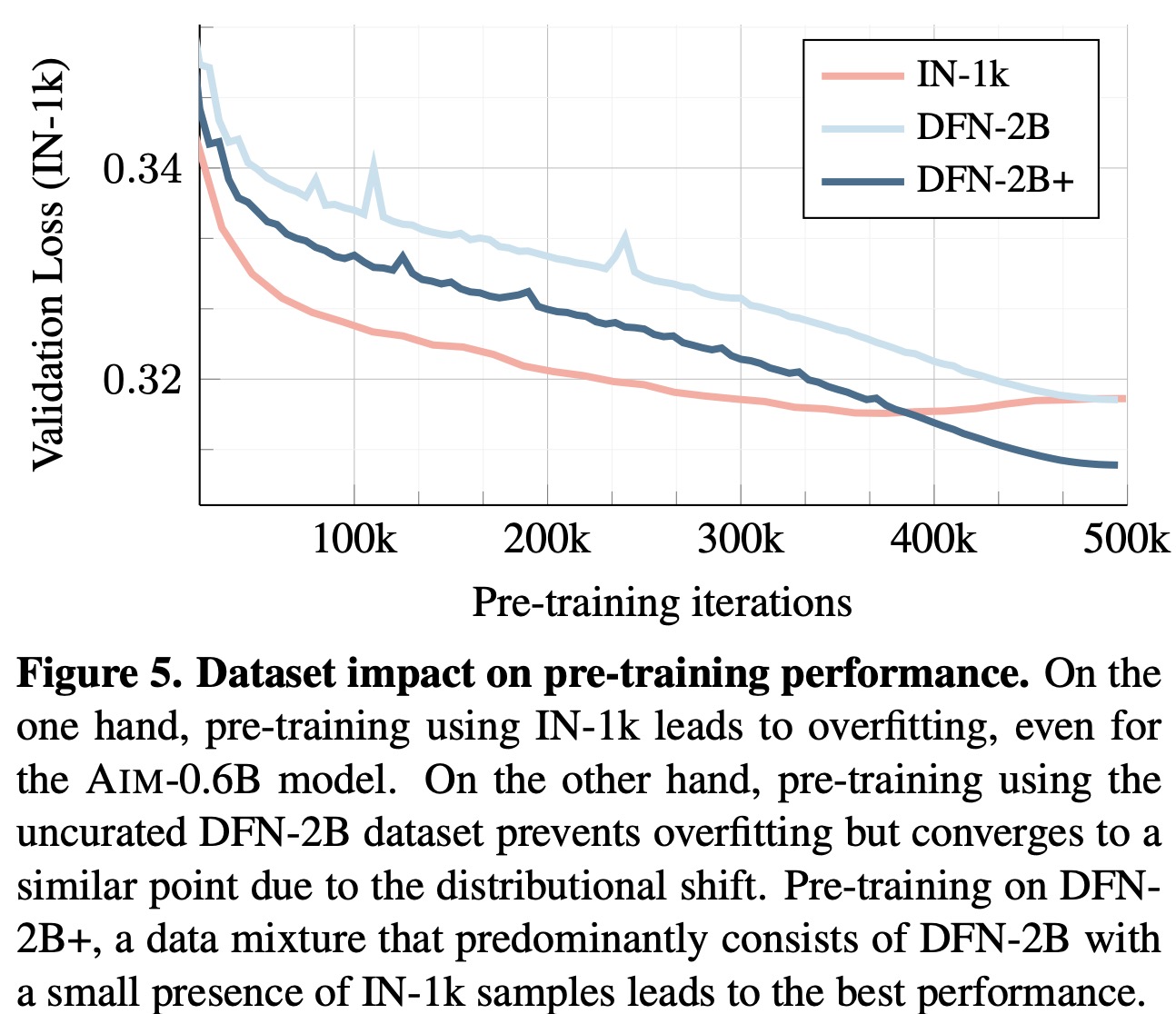
The models are pre-trained on the DFN dataset, a subset of 12.8B image-text pairs from Common Crawl, refined to 2B high-quality images by removing inappropriate content, blurring faces, deduplicating, and ranking based on image-caption alignment. No content-based curation is involved, allowing the potential use of larger, less aligned image collections. For pre-training, a blend of DFN-2B (80%) and ImageNet-1k (20%) is used, emulating the LLM practice of oversampling high-quality data, creating the DFN-2B+ dataset.
Approach
Training Objective
The training objective uses an autoregressive model on image patches, treating each image as a sequence of non-overlapping patches. The probability of an image is the product of conditional probabilities of each patch, given previous patches. The training loss is the negative log-likelihood of these probabilities, aiming to learn the true image distribution. The basic loss is a normalized pixel-level regression, minimizing the L2 distance between predicted and actual patch values. A cross-entropy loss variant with discrete tokens is also tested, but pixel-wise loss yields stronger features.
Architecture

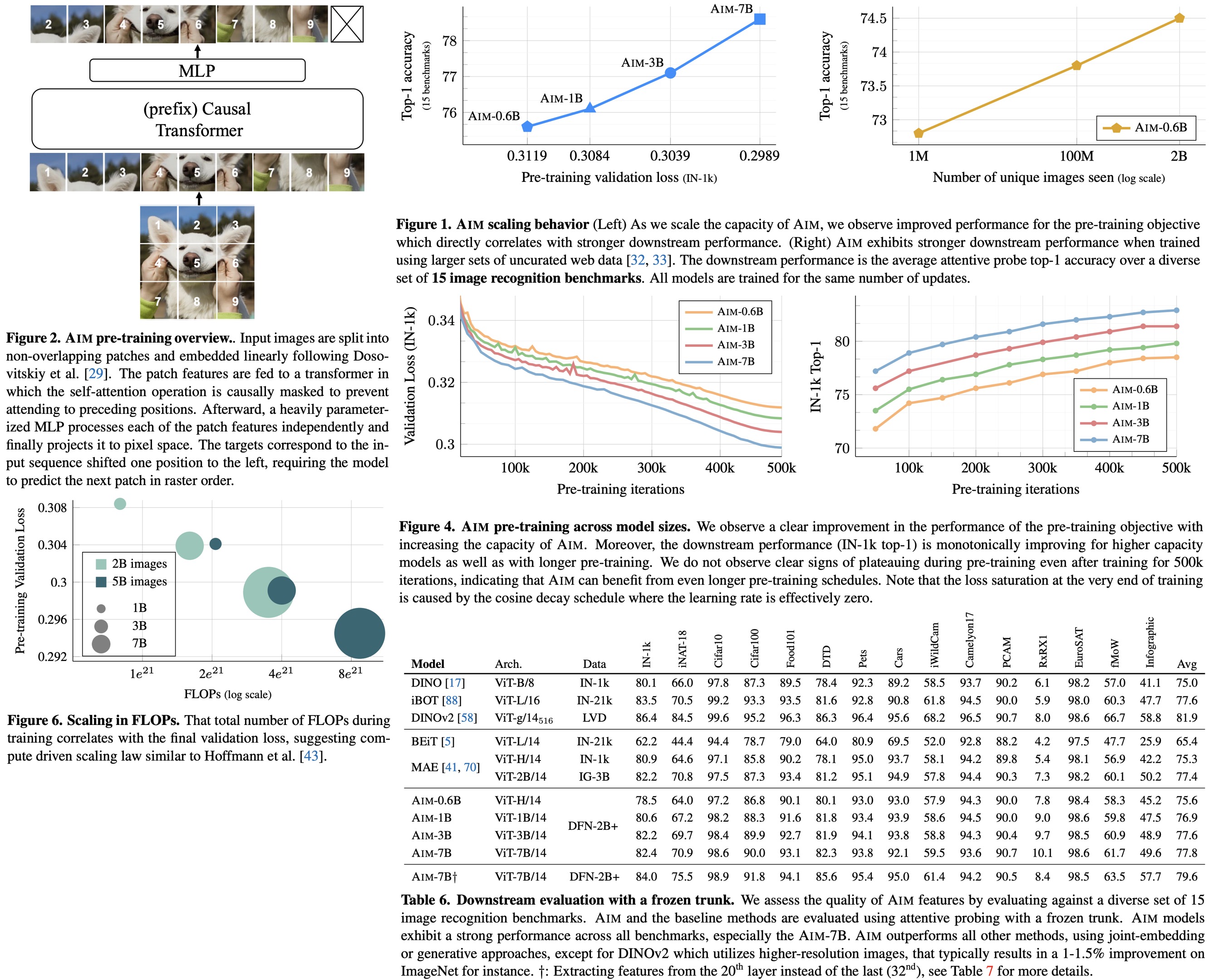
AIM uses ViT architecture, prioritizing width over depth for scaling. It employs causal masks during pre-training for autoregressive modeling of image patches, ensuring efficient computation. To bridge the gap between autoregressive pre-training and bidirectional attention in downstream tasks, a Prefix Transformer approach is introduced, treating initial patches as context. Simple MLP prediction heads are used during pre-training to maintain feature generality for downstream tasks. AIM doesn’t require optimization stability mechanisms and uses sinusoidal positional embeddings and a standard MLP design.
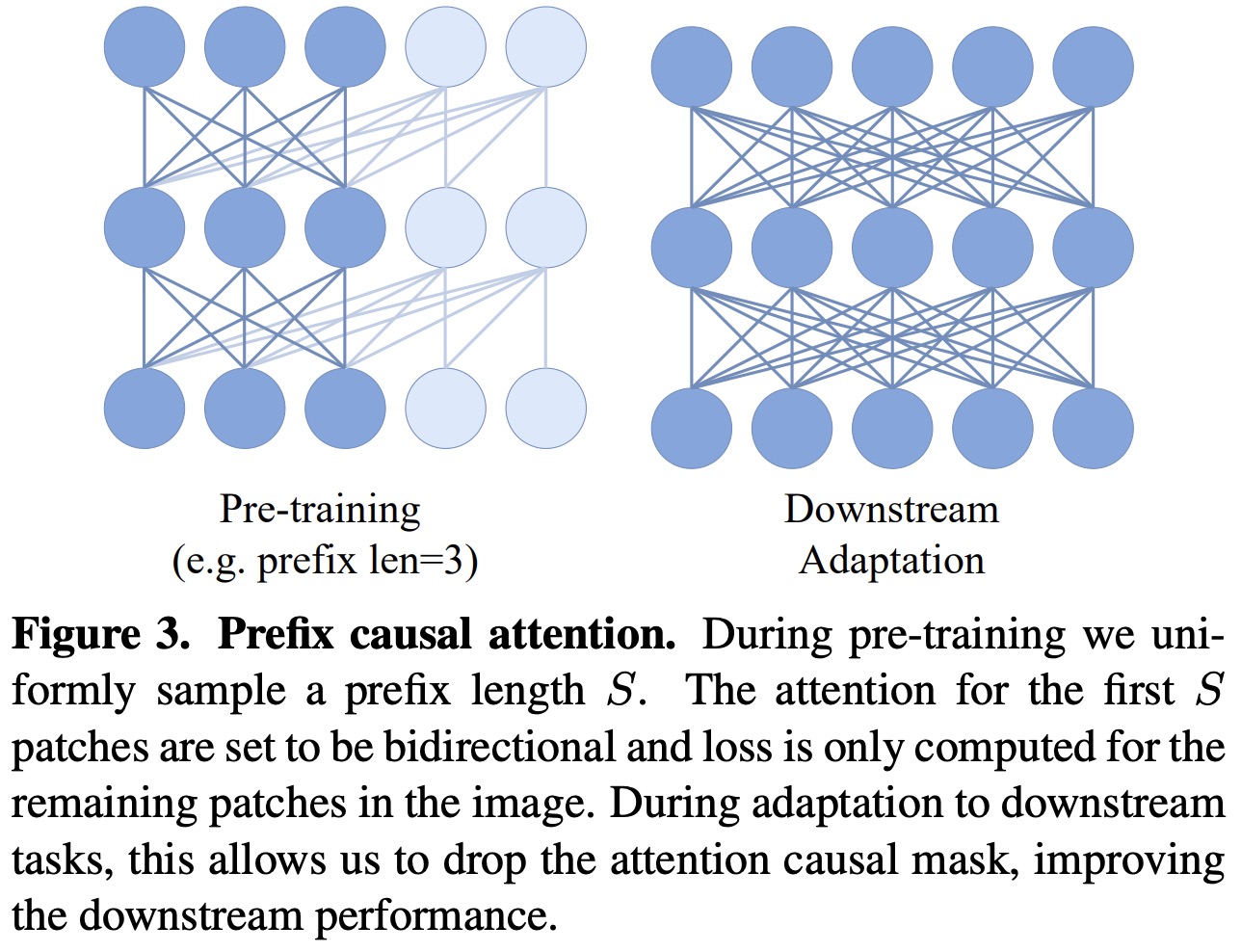
For downstream adaptation, AIM focuses on scenarios with fixed model weights, only training a classification head to minimize adaptation costs and overfitting risks. Unlike contrastive learning, AIM’s loss is computed per patch without global image descriptors. It uses attention pooling over patch features to create a global descriptor, enhancing performance with minimal parameter increase. This method (Attentive Probe) maintains the benefits of linear probing, such as low parameter count and reduced overfitting risk, while offering improved performance.
Results
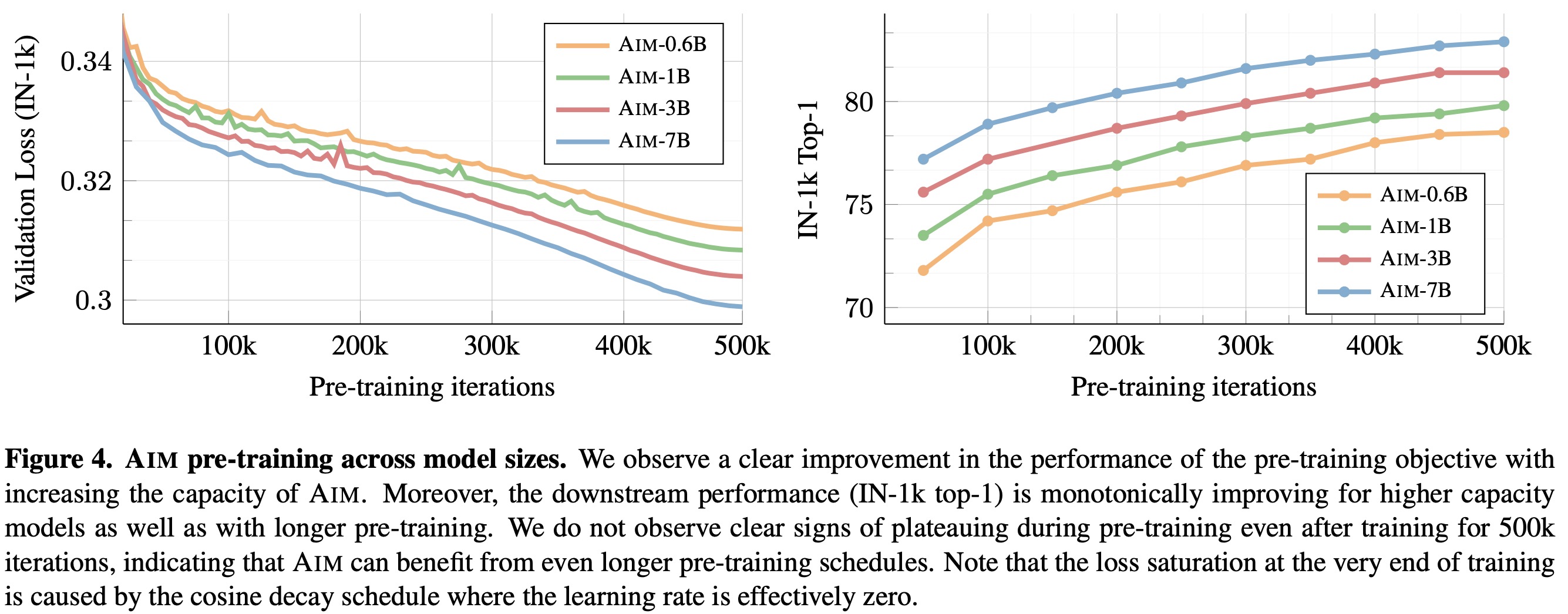
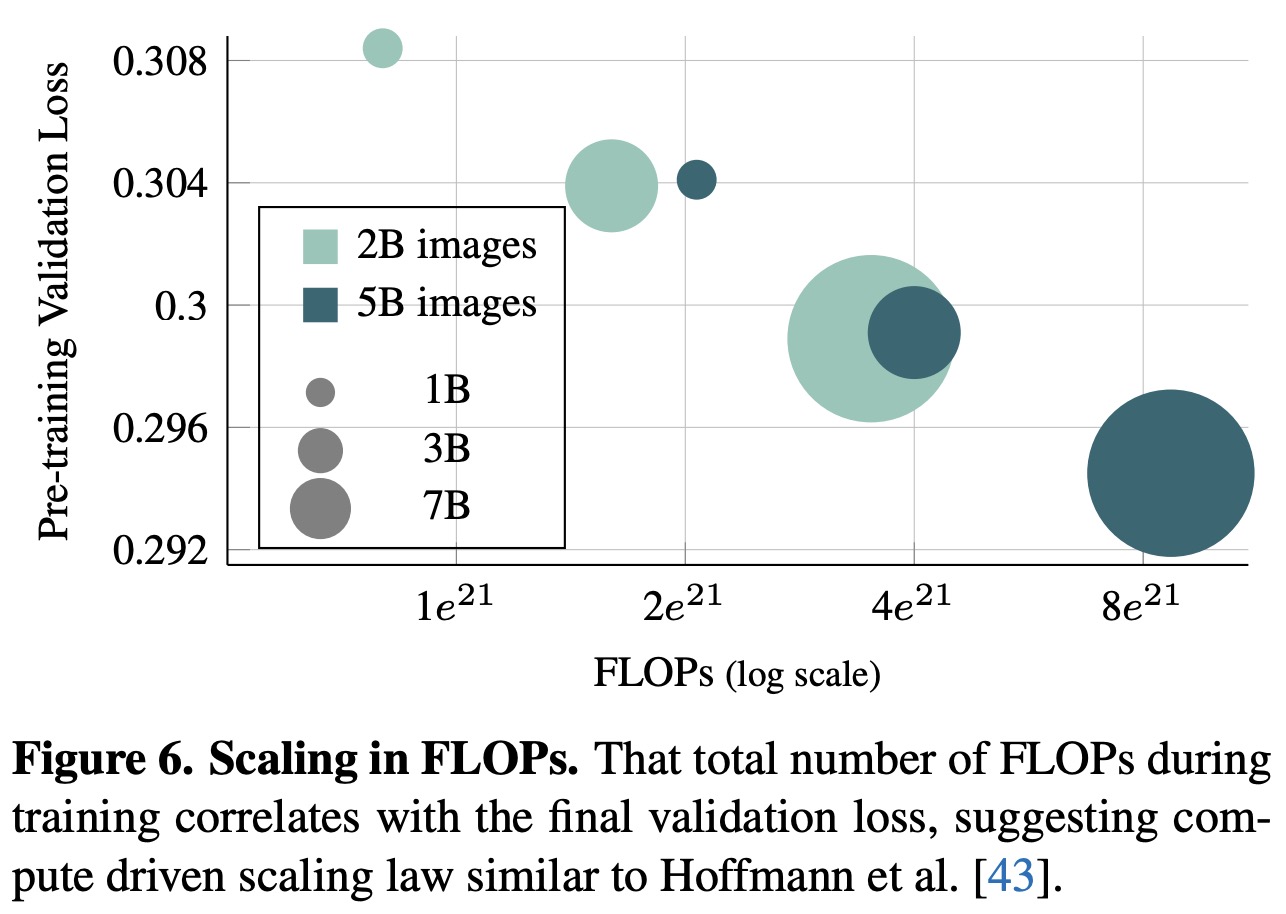
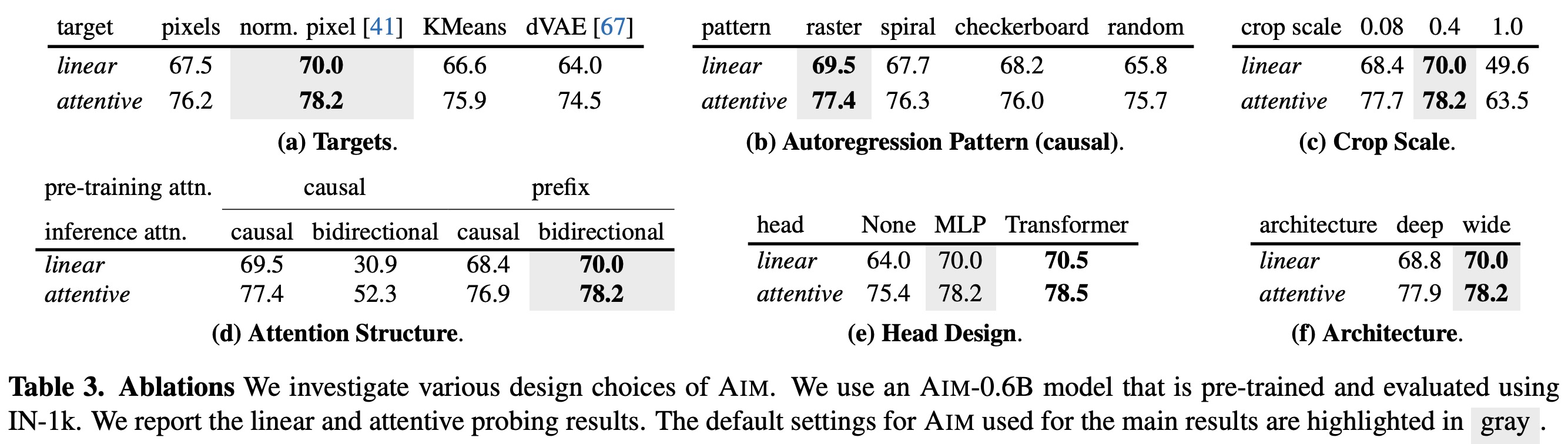
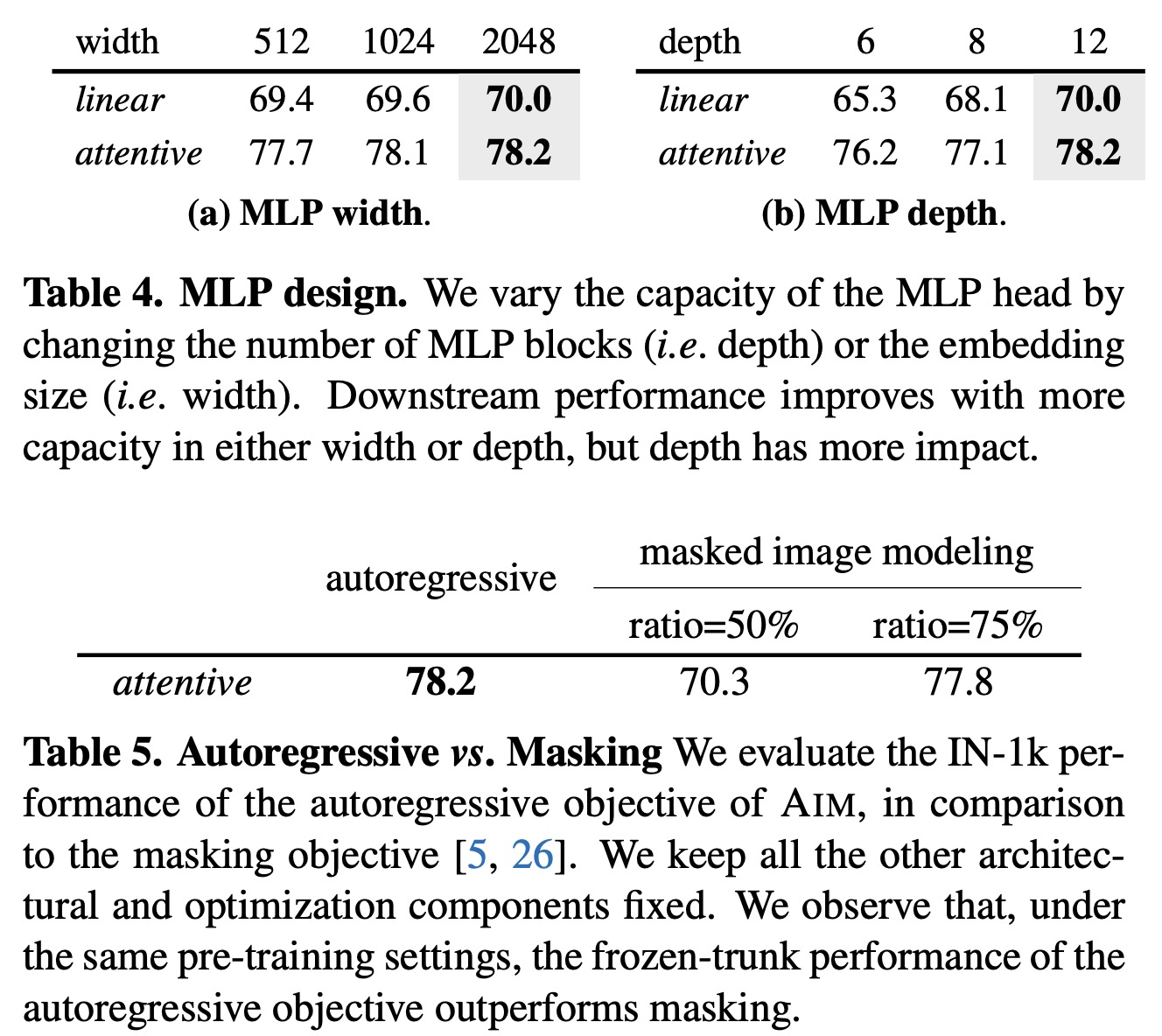
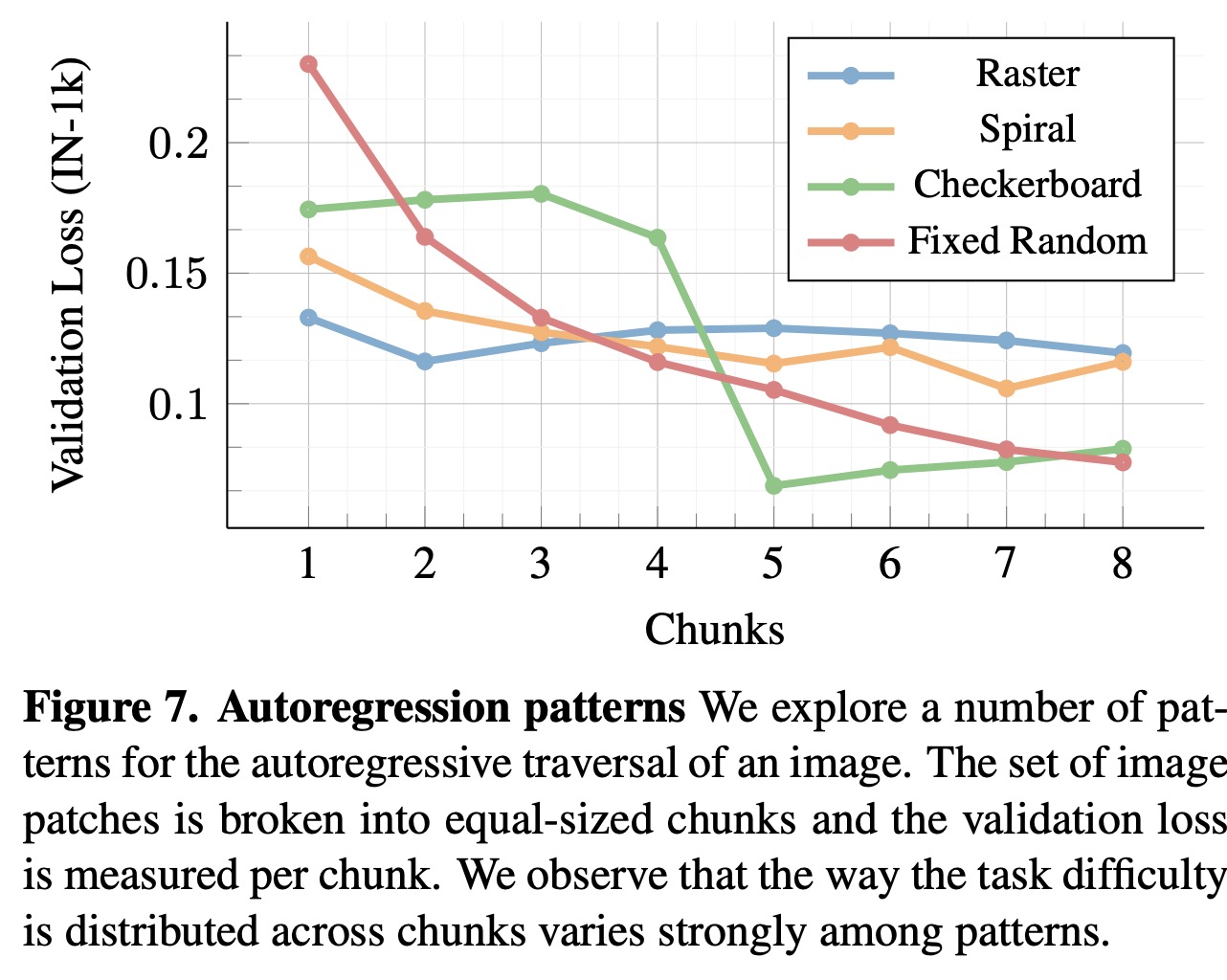
- The performance scales with the number of training iterations, model capacity, dataset size, and longer training;
- Some of the ablation studies show that the following options work the best: MST with normalized pixel values (among patches representations), raster pattern (among autoregression patterns), prefix attention (vs causal attention), wider architecture (vs deeper), attentive probe (among the probes), autoregressive objective (vs masking);
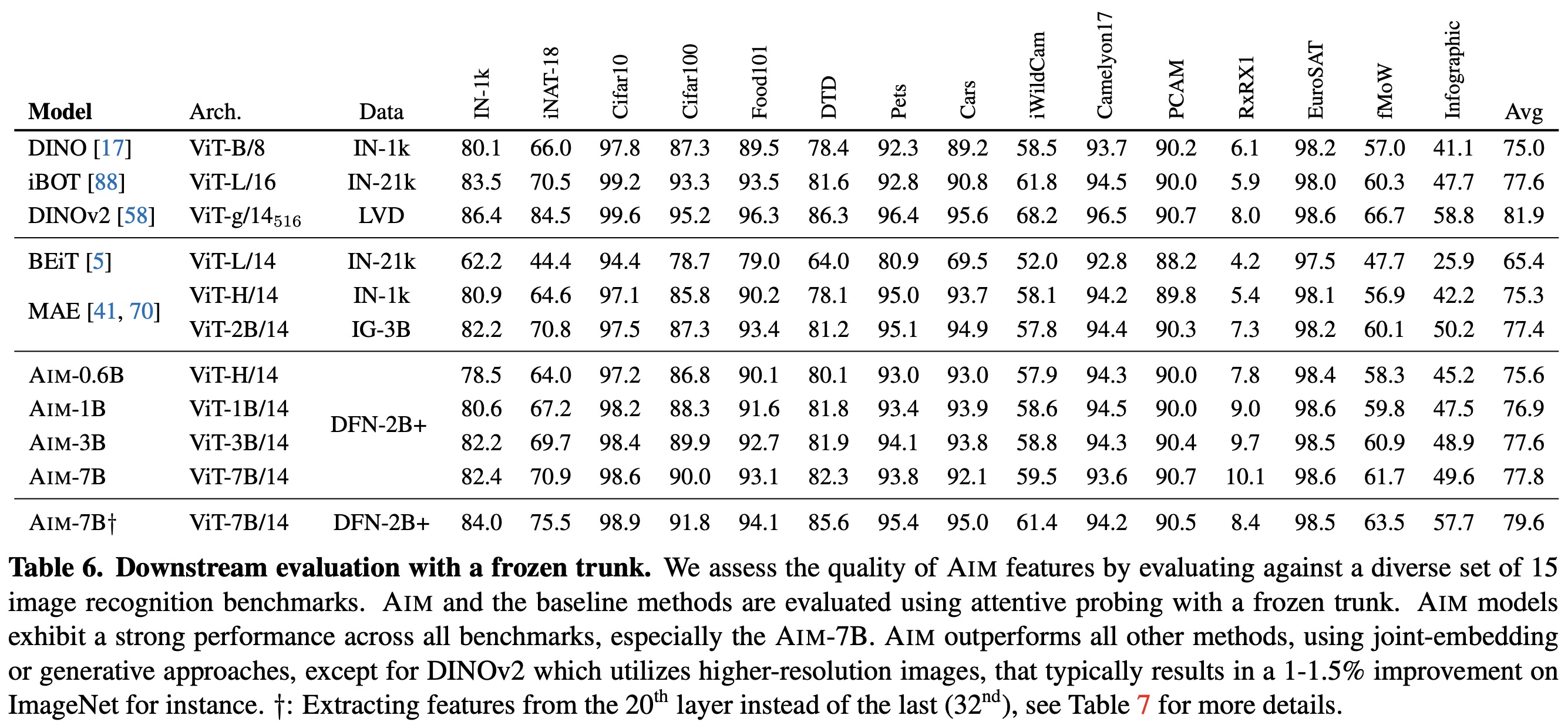
AIM demonstrates strong performance among generative methods, outperforming BEiT and MAE models of similar or larger capacities, even when the latter is trained on a large private dataset. It also shows competitive results against joint embedding methods such as DINO, iBOT, and DINOv2. Although AIM is outperformed by DINOv2, which uses higher-resolution inputs and various optimization techniques, AIM’s pre-training is simpler and more scalable in terms of parameters and data, leading to consistent improvements.
Interestingly, higher-quality features can be extracted from shallower layers of the model rather than the last layer, suggesting that the generative nature of AIM’s pre-training objective allows for the distribution of semantically rich features across different layers, not just concentrating them around the last layer.

LoRA can further improve the performance.
paperreview deeplearning cv