Paper Review: Multilingual End to End Entity Linking
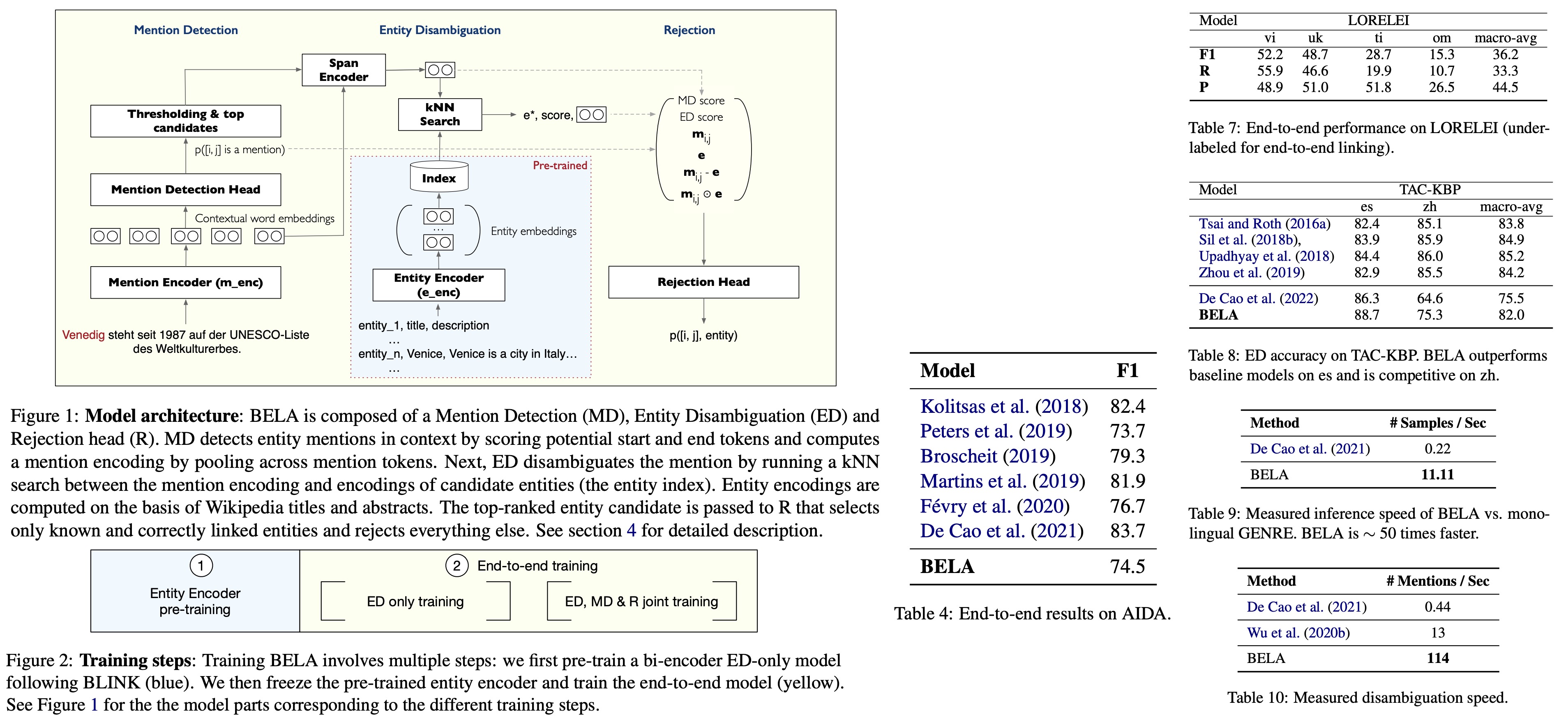
The authors have developed and open-sourced BELA, the first fully end-to-end multilingual entity linking model, capable of detecting and linking entities in texts across 97 different languages. This fills a notable gap in the field of Natural Language Processing, where efficient and comprehensive multilingual solutions have been missing, often resulting in complex model assemblies. The authors have evaluated BELA’s performance using four entity linking datasets for both high- and low-resource languages.
Task
The authors define multilingual, end-to-end Entity Linking (EL) as the task of identifying and linking specific entities within a given text sample, in any language. Given a paragraph in any language and an entity index composed of various entities with their names, titles, and descriptions, the goal is to produce a list of tuples, each representing an identified entity and its location within the text. Importantly, BELA can recognize an entity in a language even if the descriptions are in different languages, indicating a lack of language overlap is not a limitation.
Entity Index
The authors construct the entity index using Wikipedia and WikiData as their primary sources. WikiData, closely tied to Wikipedia, provides a vast set of entities across multiple languages. The entity index comprises around 16 million entities, reflecting the combination of all Wikipedia entities in 97 languages. Entity titles are derived from Wikipedia titles, and the first paragraph of the corresponding article is used for the entity description. The authors adopt the data-driven selection method (by Botha) to determine a single description language for each entity based on the frequency of entity mentions in different languages.
Model
BELA consists of the following parts:
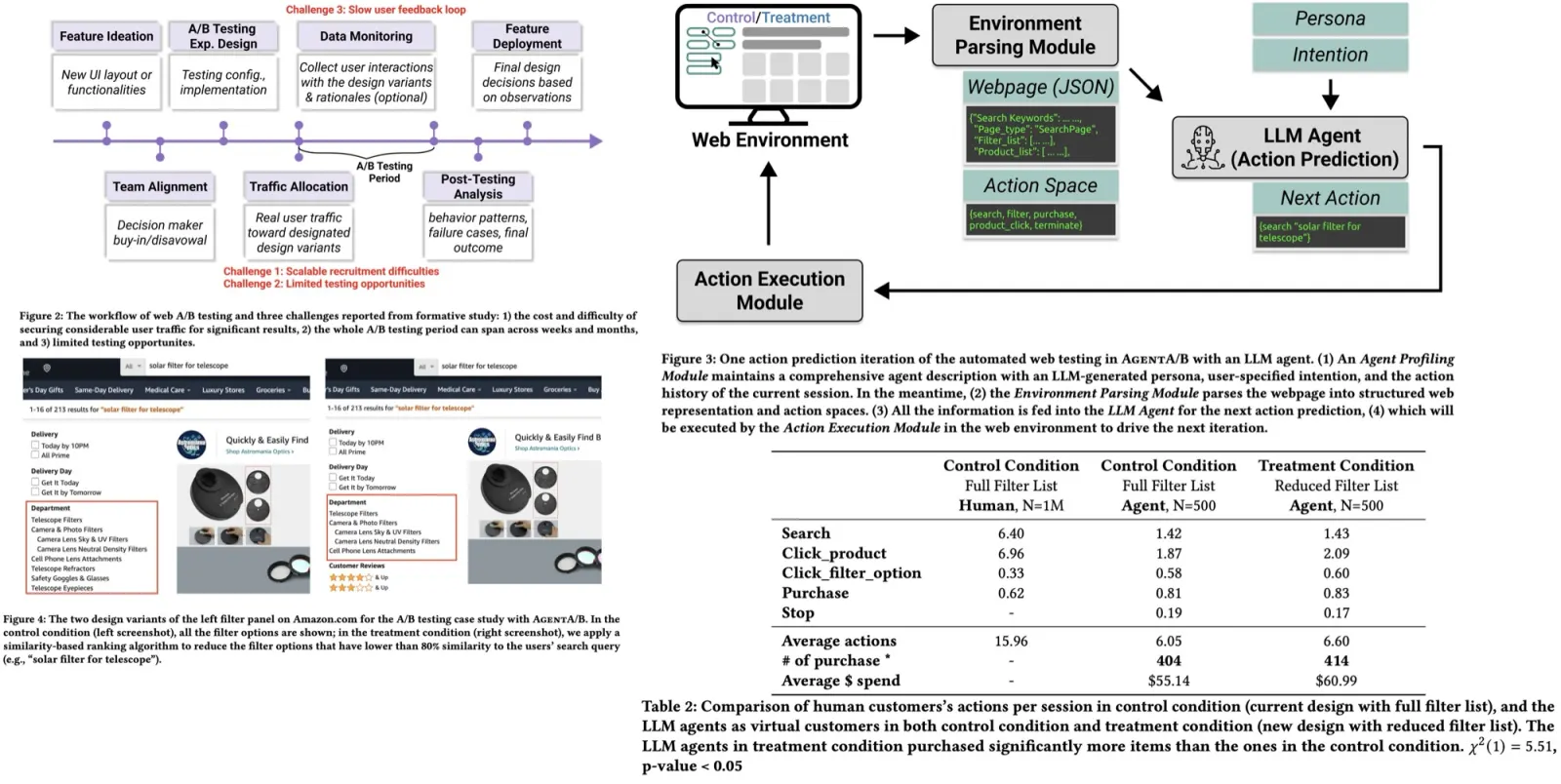
- The authors calculate the probability of a span being a mention of an entity, through a Mention Detection (MD) head. This computation involves scoring the start position, end position, and the tokens within that span as part of the mention. These scores are based on learnable vectors and token representations from a mention encoder. The MD probability scores are computed, and any candidates with a probability greater than a threshold are selected as mention candidates.
- The Entity Detection (ED) head receives an encoded candidate mention and searches for the best match in the entity index, using a process similar to the BLINK model, based on dense retrieval. Here, the encoded mention is used as a query in a k-Nearest Neighbors (kNN) search among entity embeddings, which are created by encoding the canonical entity names and descriptions. The mention representations are constructed without mention boundary tokens in one pass of the encoder, using a feed-forward layer. A similarity score (the ED score) is then computed between the mention candidate and each entity candidate in the index. The system then selects the entity that maximizes this similarity score, and this entity is paired with the mention span to form a candidate tuple. This tuple is subsequently passed to a rejection head for further processing.
- The MD and ED stages are designed to achieve high recall and, as a result, may generate an excess of candidates. To manage this, the authors introduce a rejection head (R) that examines each pair and decides whether to accept it, allowing for control over the precision-recall trade-off. Input features to R include the MD score, the ED score, the mention representation, the top-ranked candidate representation, as well as the difference and Hadamard product of these representations. These features are concatenated and fed through a feed-forward network to output the final entity linking score. All entity-mention pairs with a score above a threshold are accepted.
Training

Pre-trained entity encodings
The authors pre-train their bi-encoder ED model on a Wikipedia dataset composed of 661 million samples. This dataset is derived from cross-article hyperlinks in Wikipedia, mapping the anchor text to mentions and the linked target to the corresponding entity, across articles in 97 languages.
The entity and mention encoders are initialized with XLM-R and trained to maximize the similarity between the encoding of the mention and the correct entity using a softmax loss function. The training process involves two iterations: the first iteration uses in-batch random negatives, while the second employs hard-negative training.
Training the end-to-end model
The authors further refine the model by freezing the pre-trained entity encoder and adjusting the end-to-end model. The mention encoder is modified for end-to-end linking through two additional steps. Firstly, another round of ED training is conducted on a Wikipedia dataset with 104 million samples. After this, MD, ED, and R heads are jointly trained on another subset of Wikipedia data comprising 27 million samples.
Outputs from one component feed into the next, and losses from all components are summed. Negative log-likelihood serves as the ED loss, with a likelihood distribution computed for each mention over positive and hard negative entities. The use of pre-trained entity encodings facilitates quick kNN search by allowing the indexing of entity embeddings using quantization algorithms.
The MD loss is calculated as the binary cross-entropy between all possible valid spans and gold mentions in the training set. A valid span is defined as a span with a beginning point less than the end point, length shorter than 256 tokens, and does not start or end in the middle of a word.
Finally, the Rejection head loss is the binary cross-entropy between retrieved and gold mention-entity pairs.
Experiments
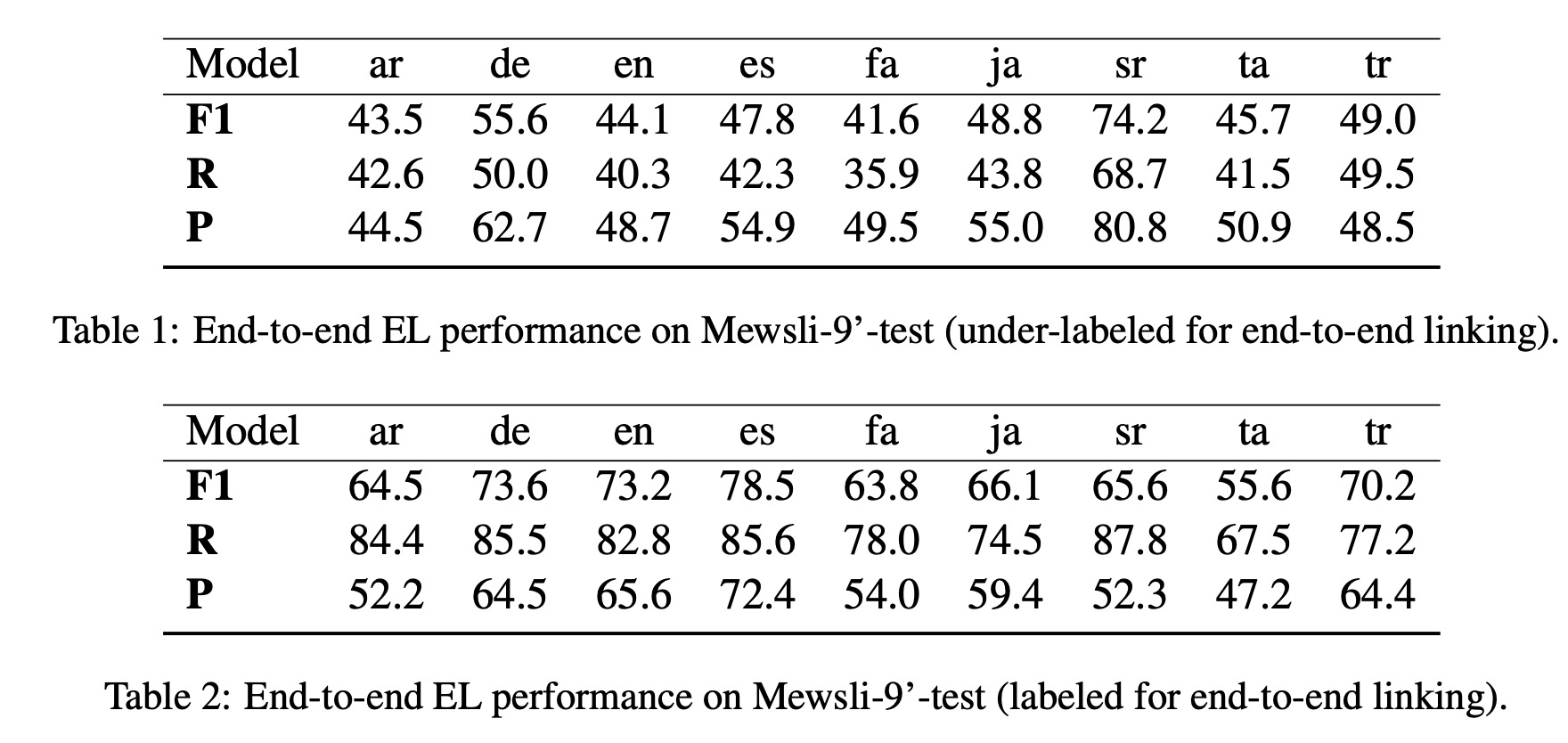
End-to-end Results
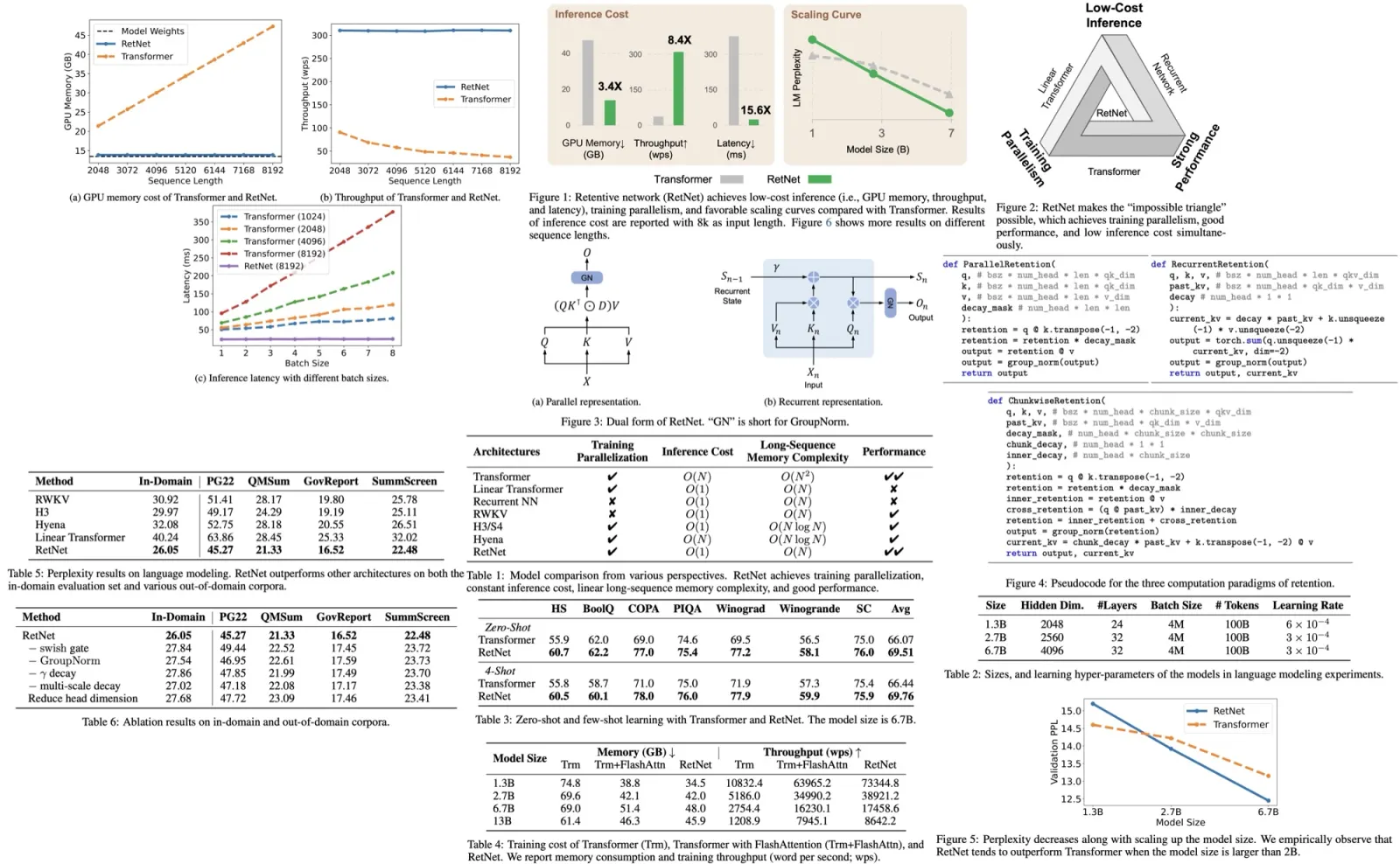
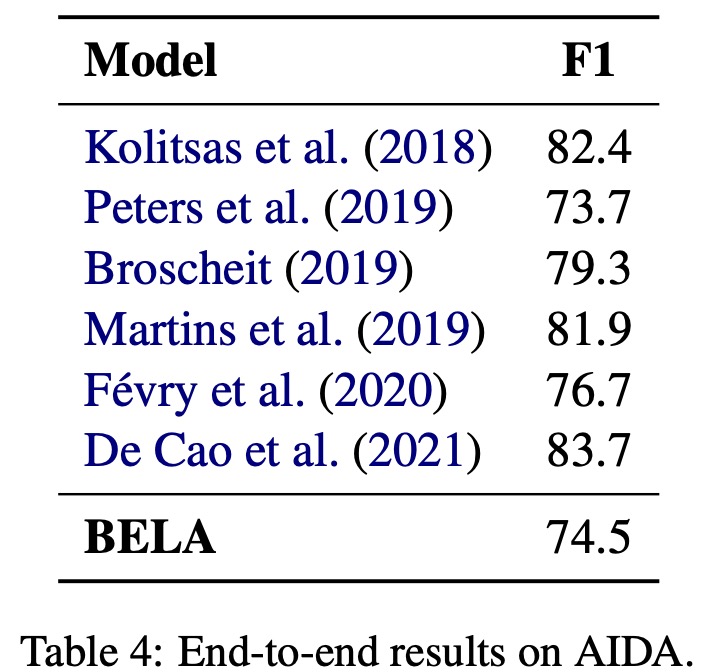
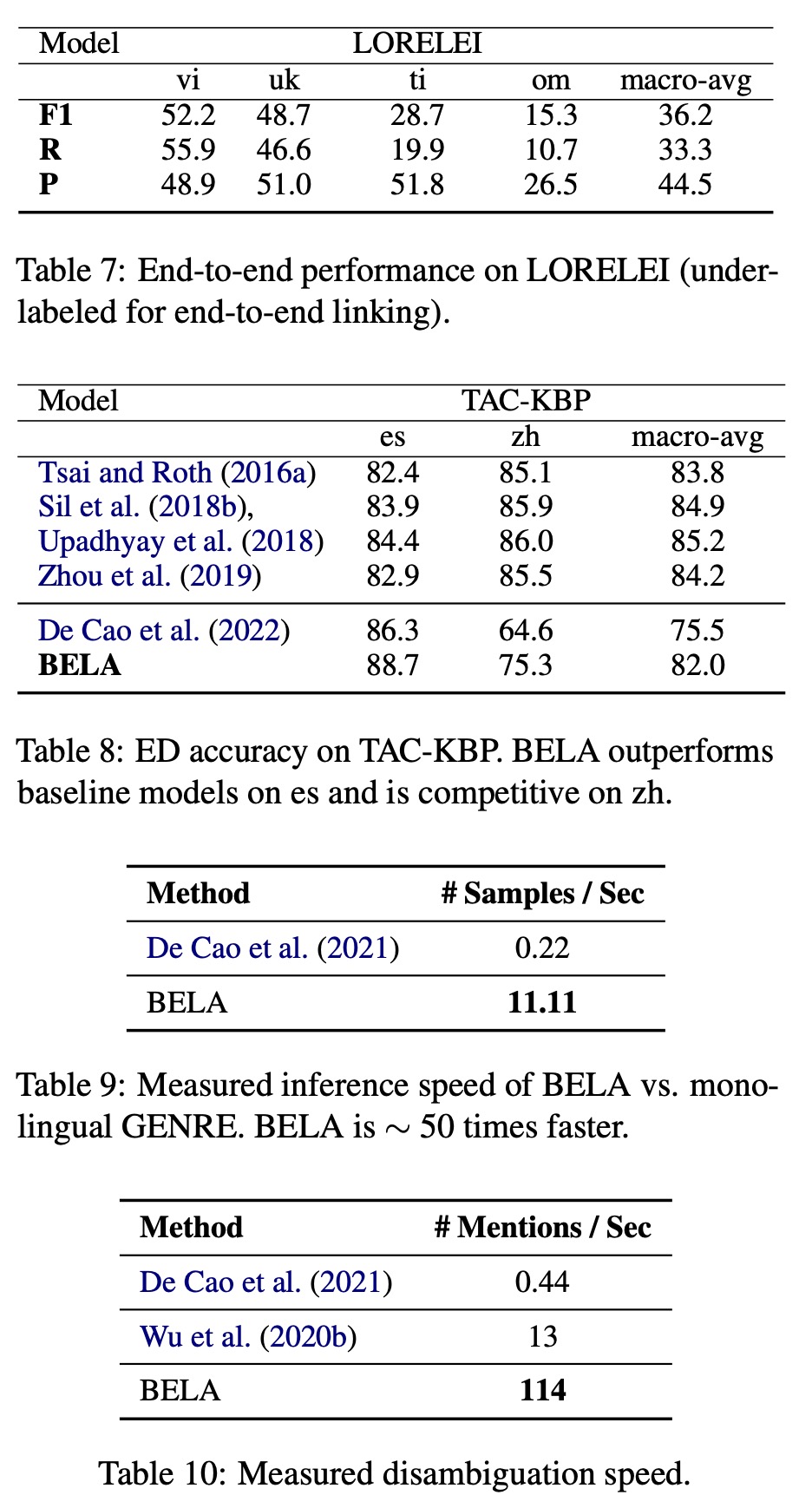
The authors reported their model’s performance on several datasets. The model’s effectiveness varied across languages, with F1 scores ranging between 15 to 74. This large variance could be due to factors such as varying language coverage during training, the tokenizer’s skewed performance towards certain scripts, and inherent performance differences related to the underlying language model.
Certain issues were identified in the evaluation process. Datasets such as Mewsli-9’, LORELEI, and TAC-KBP, which only label a subset of the mentions, can overestimate false positives, underestimating precision when evaluating end-to-end Entity Linking (EL). The authors note that under-labeling, due to the incompleteness of Wikipedia hyperlinks, can also impact training, leading the model to underestimate the base rate of mention detection, and thus affecting recall.
Performance was found to improve significantly when the model was trained on data exhaustively labeled with linked mentions. For this purpose, the authors created an end-to-end benchmark dataset based on Wikipedia and Mewsli-9’.
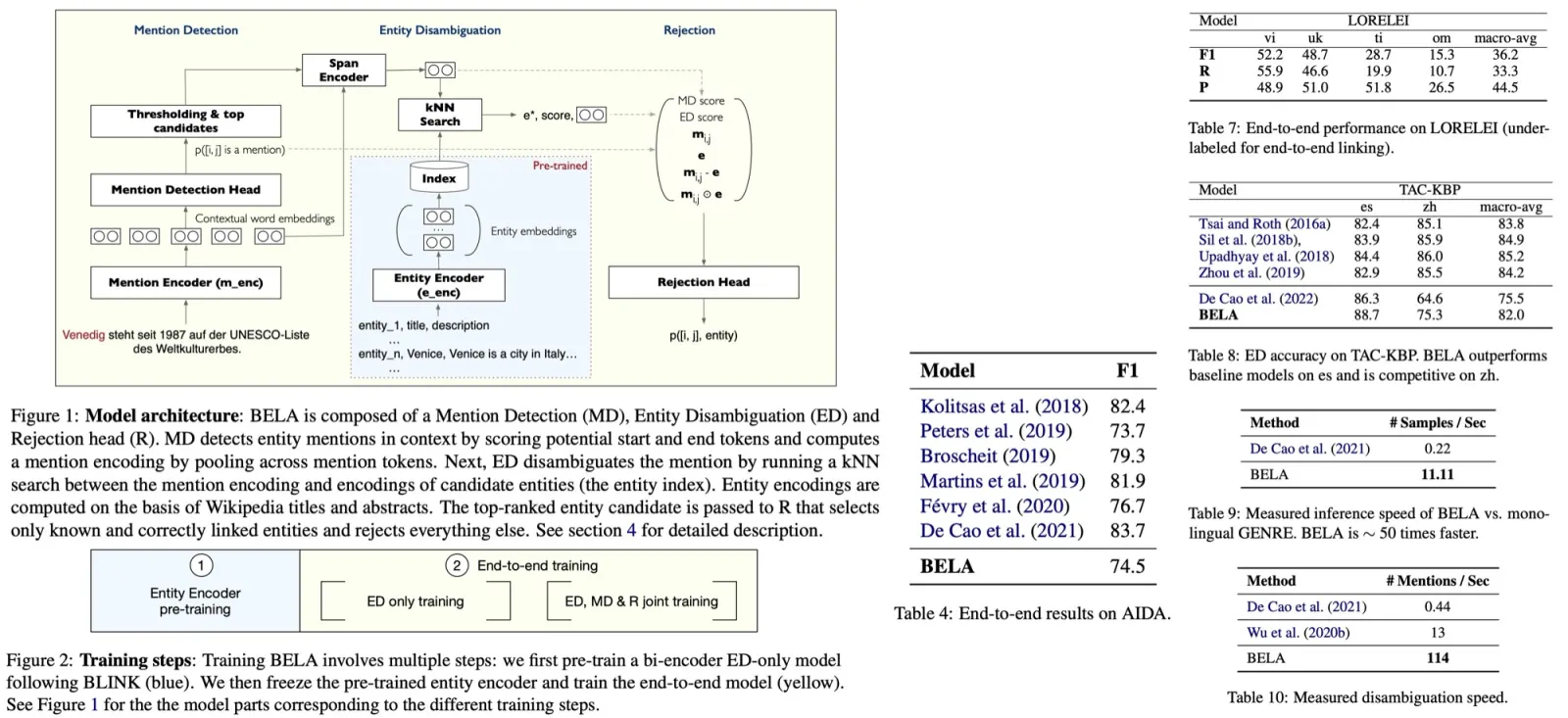
Although the BELA model is the first multilingual end-to-end EL system and cannot be compared with other multilingual baselines, it was found to perform competitively with English-only models on the English end-to-end EL dataset AIDA. This performance was achieved despite BELA’s broad multilingual capabilities and the absence of sophisticated cross-attention mechanisms between mentions and entity descriptions.
Entity Disambiguation
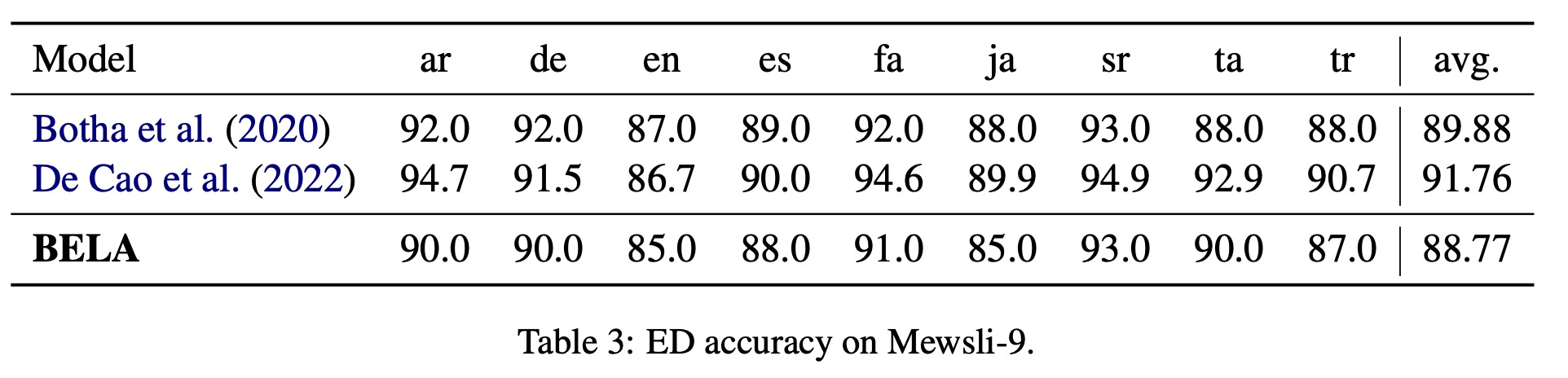
The authors compare the performance of their BELA model to other models using the Mewsli-9 and TAC-KBP datasets. On the Mewsli-9 dataset, BELA performed marginally worse than the current state-of-the-art multilingual entity disambiguation model, mGENRE, by an average of 3%. However, they highlight that mGENRE, a sequence-to-sequence model, was specifically trained for Entity Disambiguation (ED), requiring a separate pass of encoding for each mention and using special entity delimiter tokens, making it computationally more demanding and less practical for real-world applications.
On the other hand, BELA is trained end-to-end without mention delimiters, allowing it to disambiguate multiple entities in a single pass, which is more computationally efficient. Despite this, BELA’s performance is nearly as accurate as Botha et al. (2020), which also requires a mention encoding pass for each candidate mention, similar to mGENRE.
paperreview deeplearning nlp llm entitylinking