Paper Review: BloombergGPT: A Large Language Model for Finance

The authors introduce BloombergGPT, a 50-billion parameter language model specialized for the financial domain. It is trained on a 363 billion token dataset from Bloomberg’s data sources, supplemented by 345 billion tokens from general-purpose datasets. The model significantly outperforms existing models on financial tasks while maintaining performance on general LLM benchmarks.
Dataset
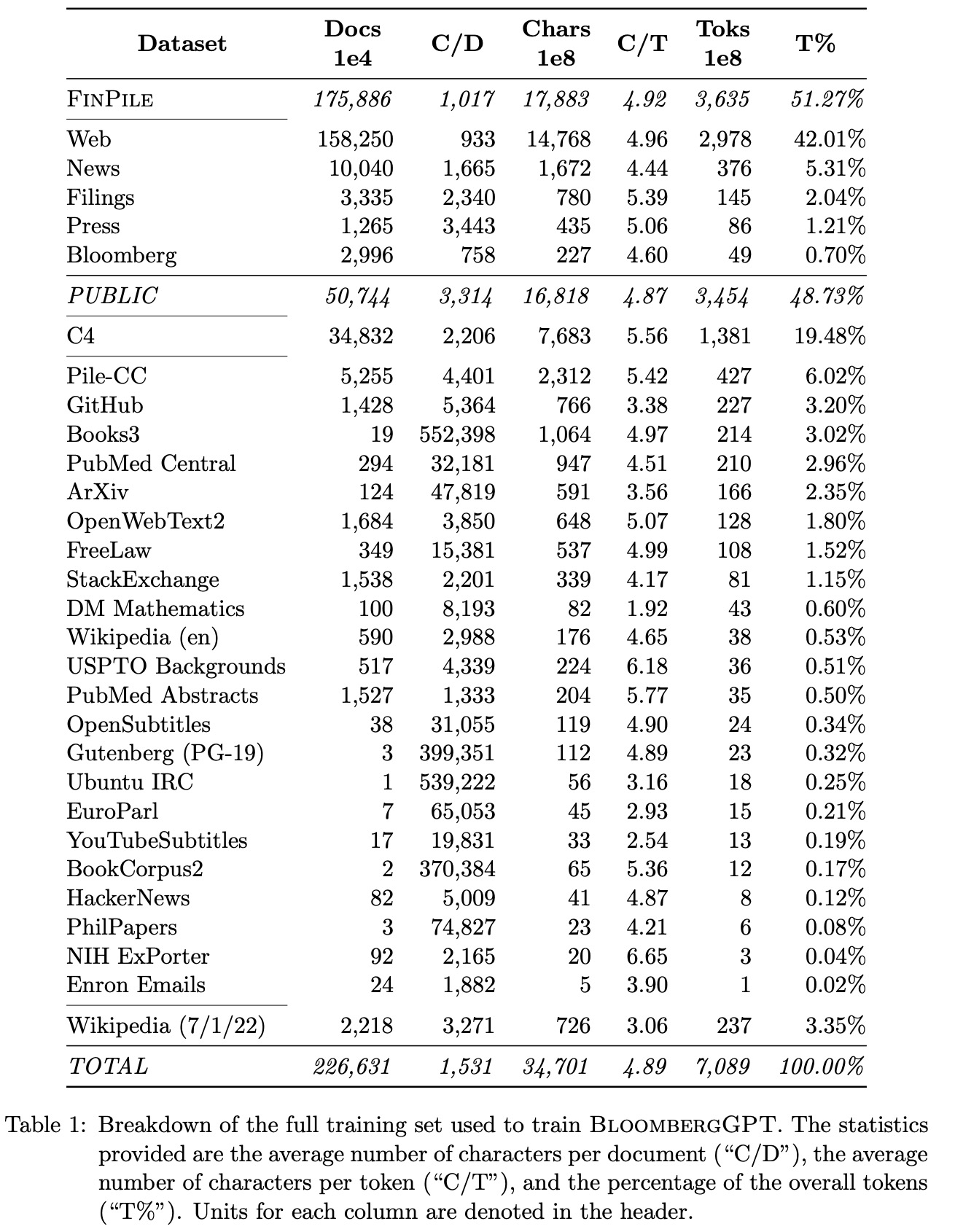
The authors create “FinPile,” a dataset for training BloombergGPT, consisting of English financial documents from various sources, including news, filings, press releases, and social media from Bloomberg archives. This dataset comprises company filings, financial news, and other market-relevant data, with some publicly available and others requiring purchase or exclusive access through the Bloomberg Terminal. The data is cleaned to remove markup, special formatting, and templates. Each document is time-stamped from 2007-03-01 to 2022-07-31, with improved quality and quantity over time. While FinPile cannot be released, the authors aim to share insights on building a domain-specific model, particularly in the financial domain, and plan to utilize date information in future work.
The authors combine FinPile with public data commonly used for training LLMs, resulting in a training corpus with equal parts of domain-specific and general-purpose text. To improve data quality, they de-duplicate each dataset, which may cause differences in statistics reported in other papers.
Tokenization
The authors choose the Unigram tokenizer over greedy merge-based sub-word tokenizers like BPE or Wordpiece due to its promising results in previous research. They treat data as a sequence of bytes instead of Unicode characters and employ a pretokenization step that follows GPT-2 in breaking the input into chunks. This allows multi-word tokens to be learned, increasing information density and reducing context lengths. They train their tokenizer on The Pile, a diverse dataset that suits their use case.
The authors use a parallel tokenizer training method to handle the large Pile dataset, implementing a split and merge approach. They train a Unigram tokenizer on each chunk and merge them hierarchically to create a final tokenizer. The resulting tokenizer has 7 million tokens, which is then reduced to 131,072 tokens. Various considerations, such as fitting more information into the context window and overhead, influence the choice of vocabulary size. They select 131,072 tokens based on experiments with different vocabulary sizes and the smallest encoded representation of the C4 dataset. This tokenizer is relatively large compared to the standard vocabulary size of approximately 50,000 tokens.
The model
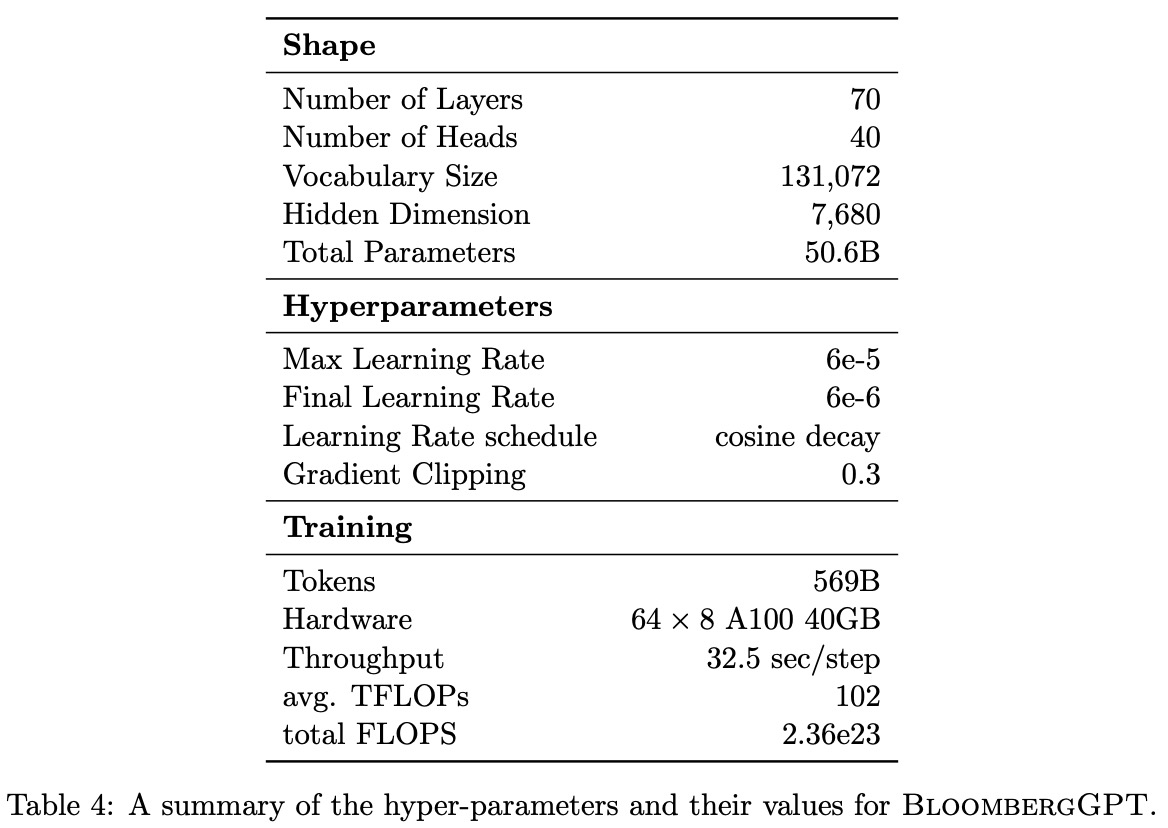
The authors base their BloombergGPT model on BLOOM, using a decoder-only causal language model with 70 layers of transformer decoder blocks. The architecture includes multi-head self-attention, layer normalization, and a feed-forward network with a single hidden layer using GELU as the non-linear function. ALiBi positional encoding (Attention with Linear Biases) is applied, and input token embeddings are tied to the linear mapping before the final softmax. The model has an additional layer normalization after token embeddings.
Model scaling
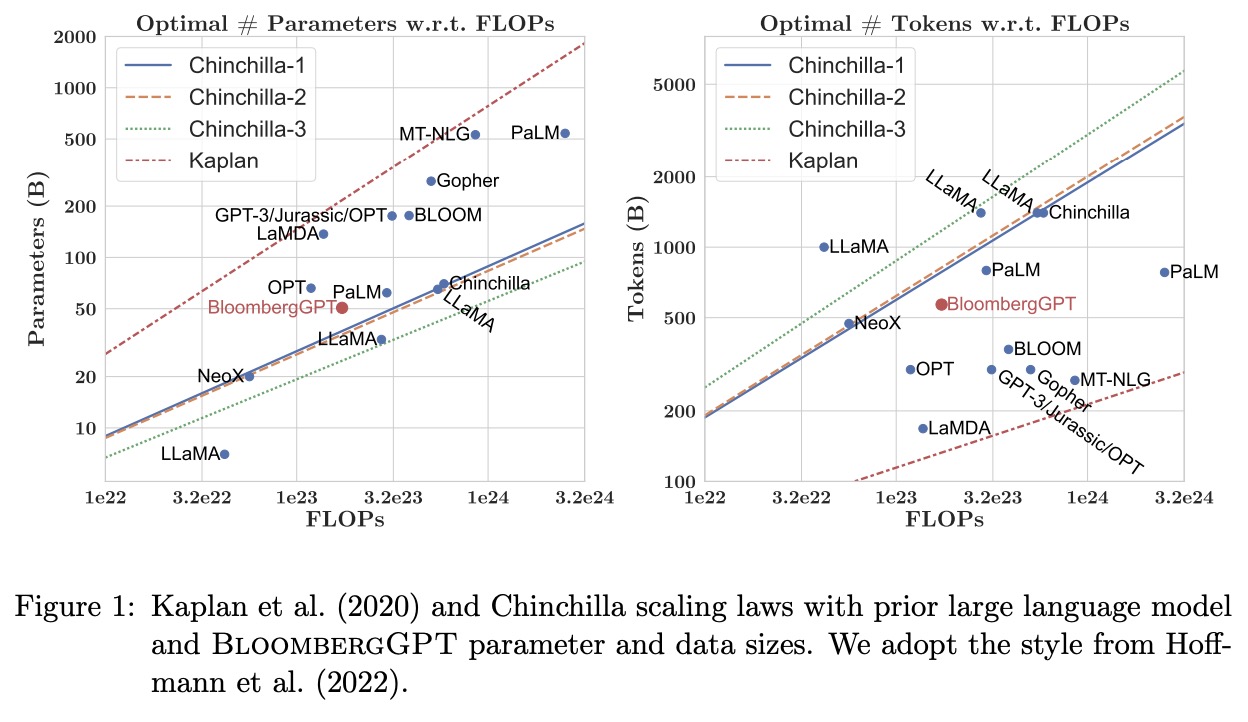
The authors determine the size of their BloombergGPT model using Chinchilla scaling laws, with a total compute budget of 1.3 million GPU hours on 40GB A100 GPUs. They adjust for activation checkpointing costs and use the Chinchilla equations to calculate the optimal number of parameters and tokens. Their dataset of approximately 700 billion tokens is considered too small for an optimal configuration given their compute budget. To address this limitation, they choose the largest model possible, with 50 billion parameters, while leaving about 30% of the total compute budget as a buffer for potential issues.
To determine the shape of the BloombergGPT model with 50 billion parameters, the authors follow Levine et al. (2020), who proposes an optimal hidden dimension D based on the number of self-attention layers L. They choose L = 70 and D = 7510 as their target shape parameters. To achieve higher performance in Tensor Core operations, they settle on 40 heads, each with a dimension of 192, leading to a total hidden dimension of D = 7680 and a total of 50.6 billion parameters.
Training
BloombergGPT is a PyTorch model trained with a standard left-to-right causal language modeling objective. The training sequences are set to 2,048 tokens long to maximize GPU utilization. The model uses the AdamW optimizer, the learning rate follows a cosine decay schedule with linear warmup, and batch size warmup is employed as well.
The model is trained and evaluated using Amazon SageMaker on 64 p4d.24xlarge instances, each with 8 NVIDIA 40GB A100 GPUs. To ensure quick data access, Amazon FSX for Lustre is used, supporting up to 1000 MB/s read and write throughput per TiB storage unit.
Large scale optimization
To train the large BloombergGPT model with limited GPU memory, several optimization techniques are used:
- ZeRO Optimization (stage 3): Shards the training state across a group of GPUs, with 128 GPUs used for sharding and four copies of the model during training.
- MiCS: Decreases training communication overhead and memory requirements for cloud training clusters using hierarchical communication, 2-hop gradient update, and scale-aware model partitioning.
- Activation Checkpointing: Minimizes training memory consumption by removing activations and recomputing intermediate tensors during backward passes when necessary.
- Mixed Precision Training: Reduces memory requirements by performing forward and backward passes in BF16 while storing and updating parameters in full precision (FP32).
- Fused Kernels: Combines multiple operations into a single GPU operation, reducing peak memory usage by avoiding storage of intermediate results and improving speed.
These optimizations allow the model to achieve an average of 102 TFLOPs, with each training step taking 32.5 seconds.
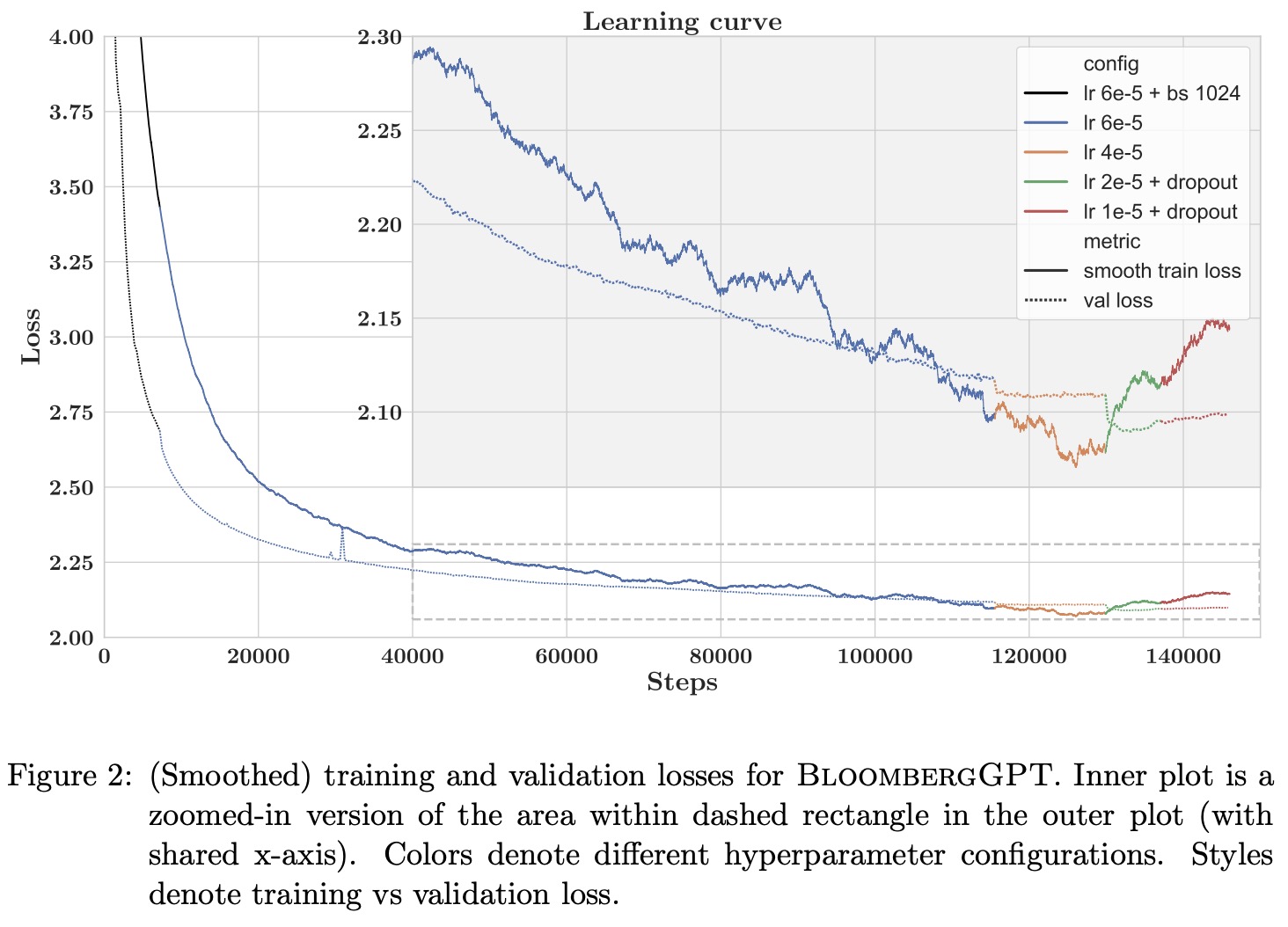
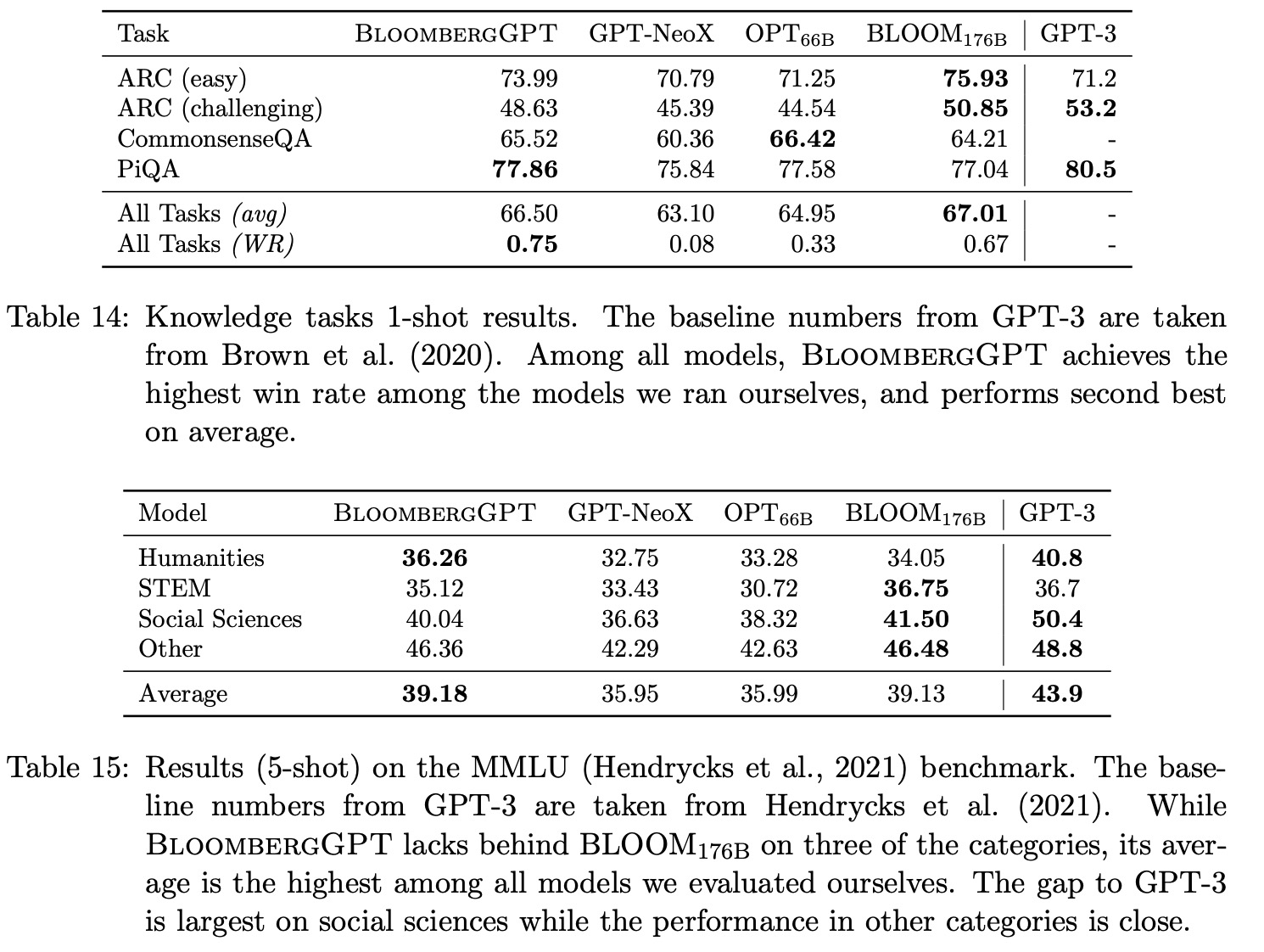
Evaluation
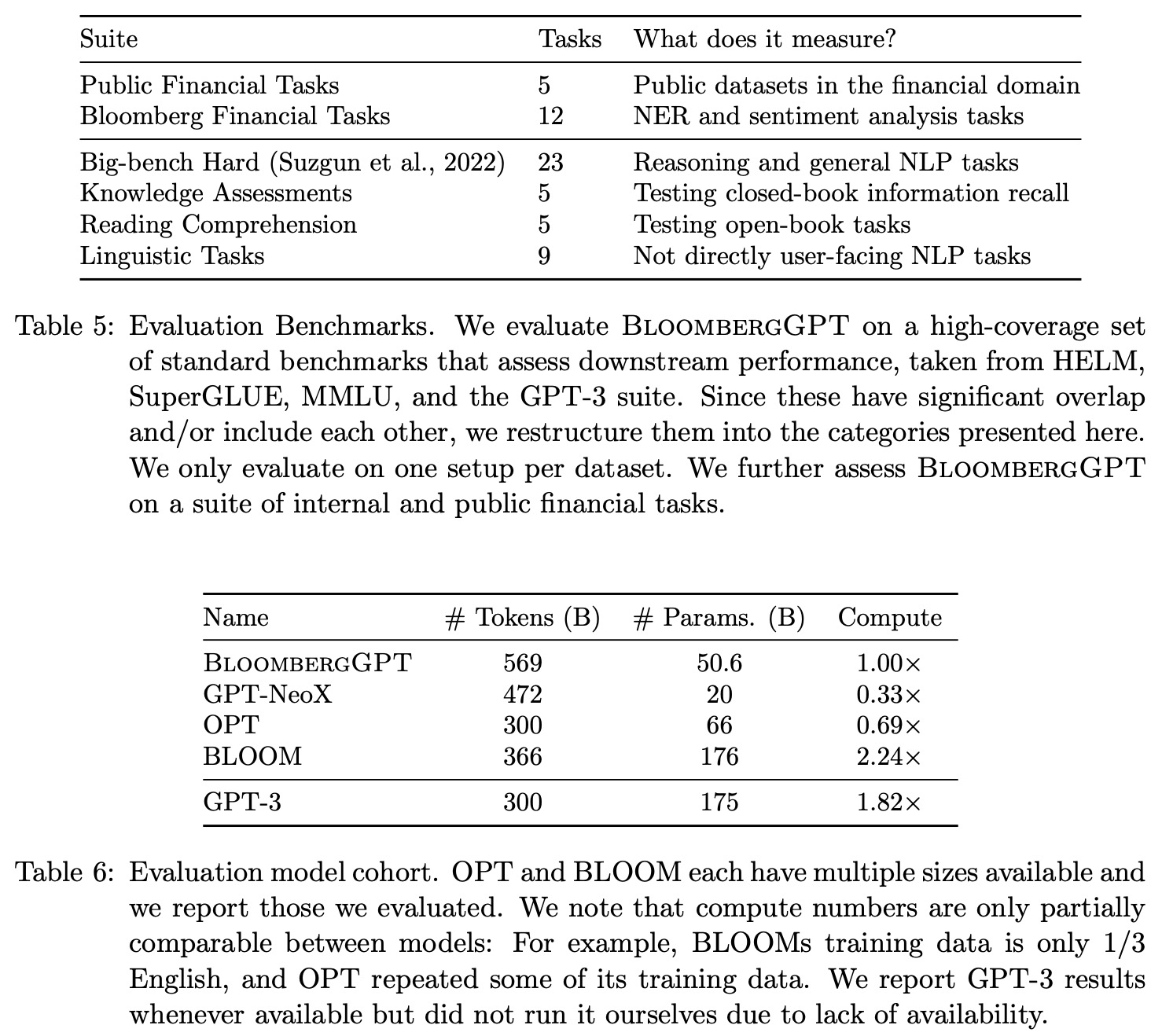
Few-shot Methodology
For tasks with a set of candidates, three methods of classification are used: regular, calibration, and normalization. The best method for each model and task is reported. For other tasks, greedy decoding is used for generation. Official splits are used when available, and performance is reported on the test set; if not available, the dev set is used. If no official split exists, a train-test split is created by selecting 20% of examples for testing. To reduce variance in few-shot evaluation, different shots are sampled for each test example, unless otherwise specified. All models have identical surface form as input for consistency during evaluation.
Heldout Loss
BloombergGPT is tested on in-distribution finance data to evaluate its performance on held-out datasets containing examples from all sections of FinPile. A temporally held-out dataset is used to limit data leakage and simulate real-world usage. For documents longer than 2,048 tokens, a sliding window approach is used. BloombergGPT consistently outperforms other models, providing insights into the generalization capabilities of other models. The performance gap is most significant in the Filings category, likely because these documents are typically in PDF format and not included in existing datasets.
Financial Tasks
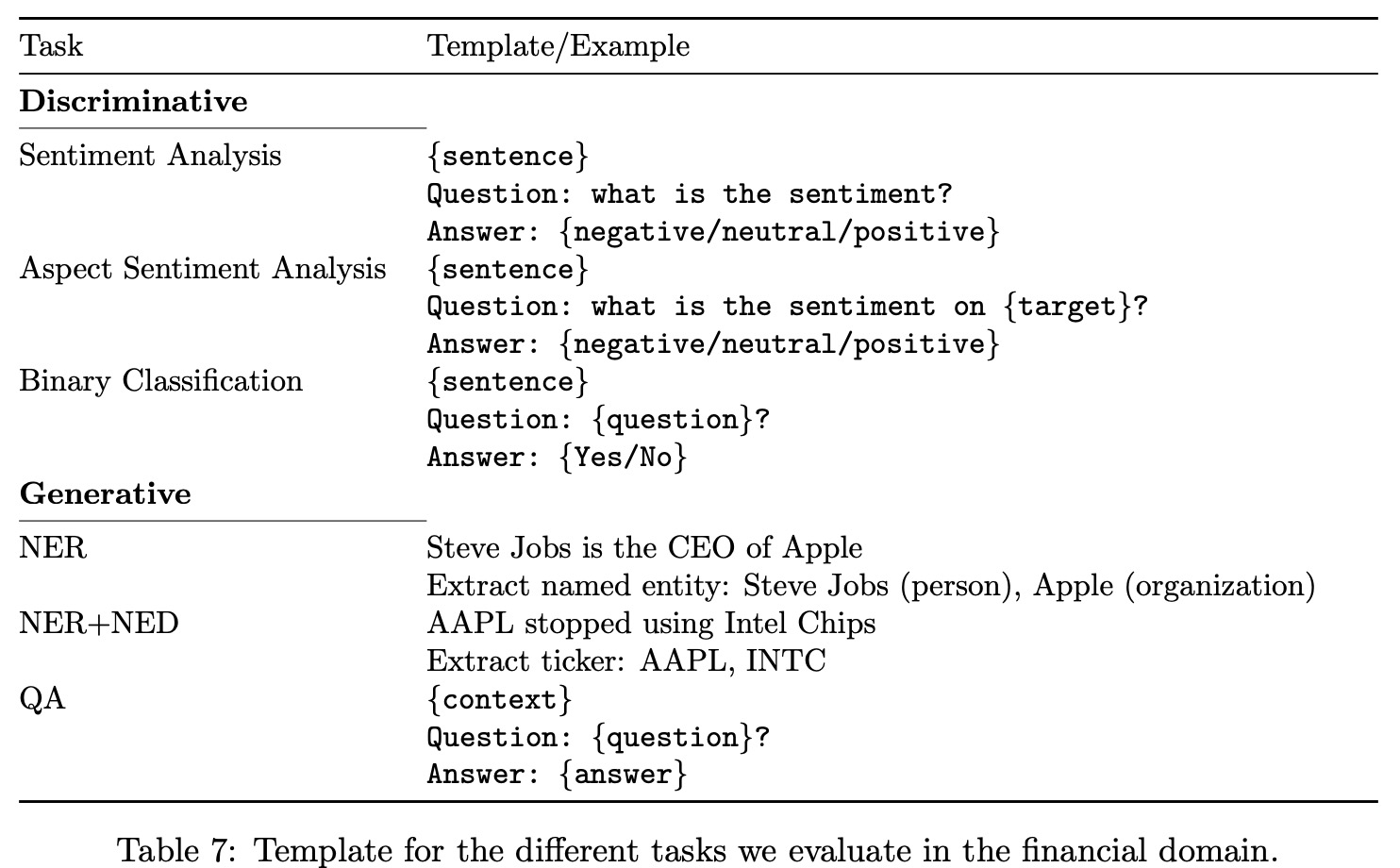
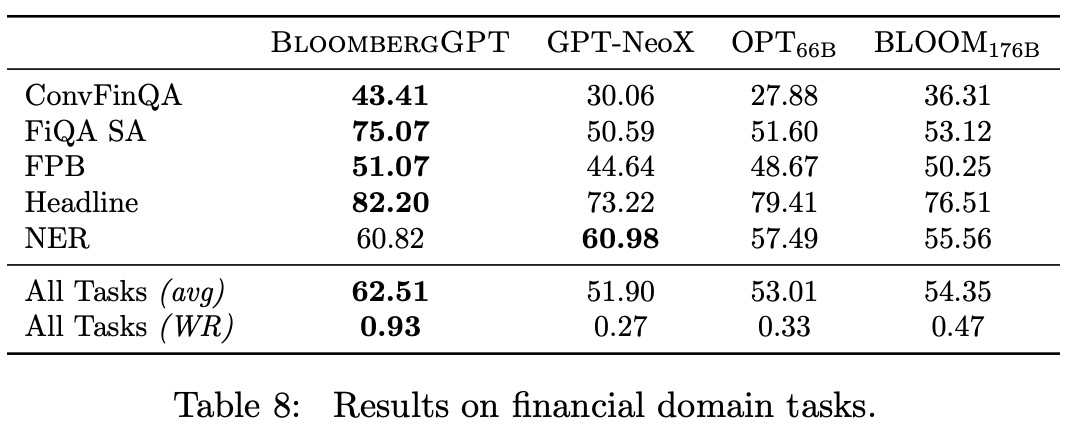
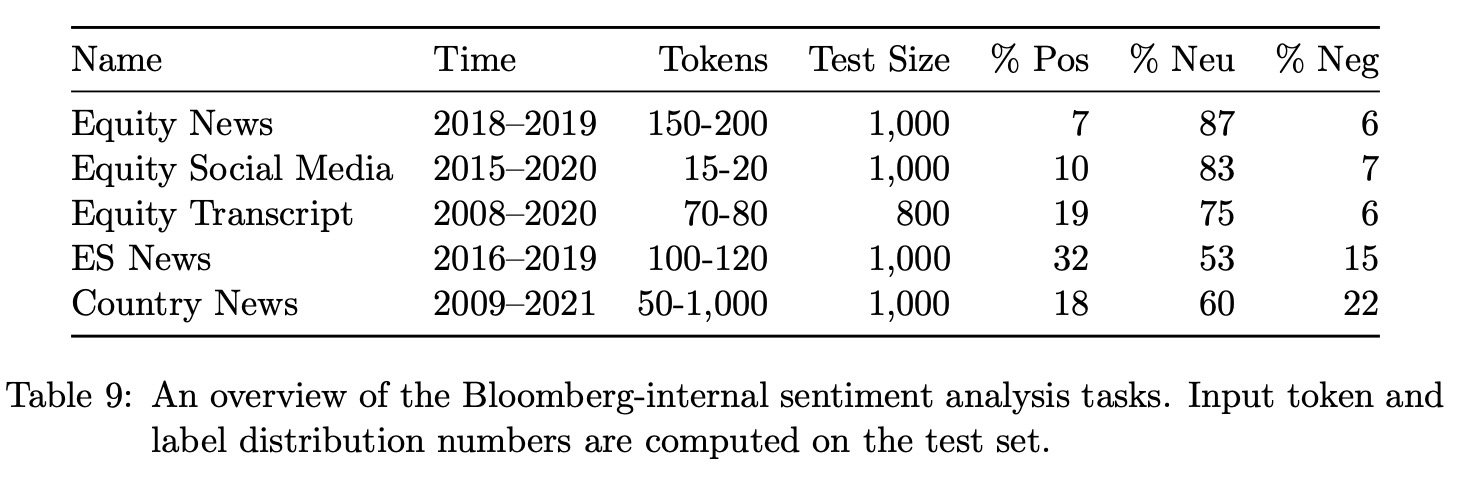
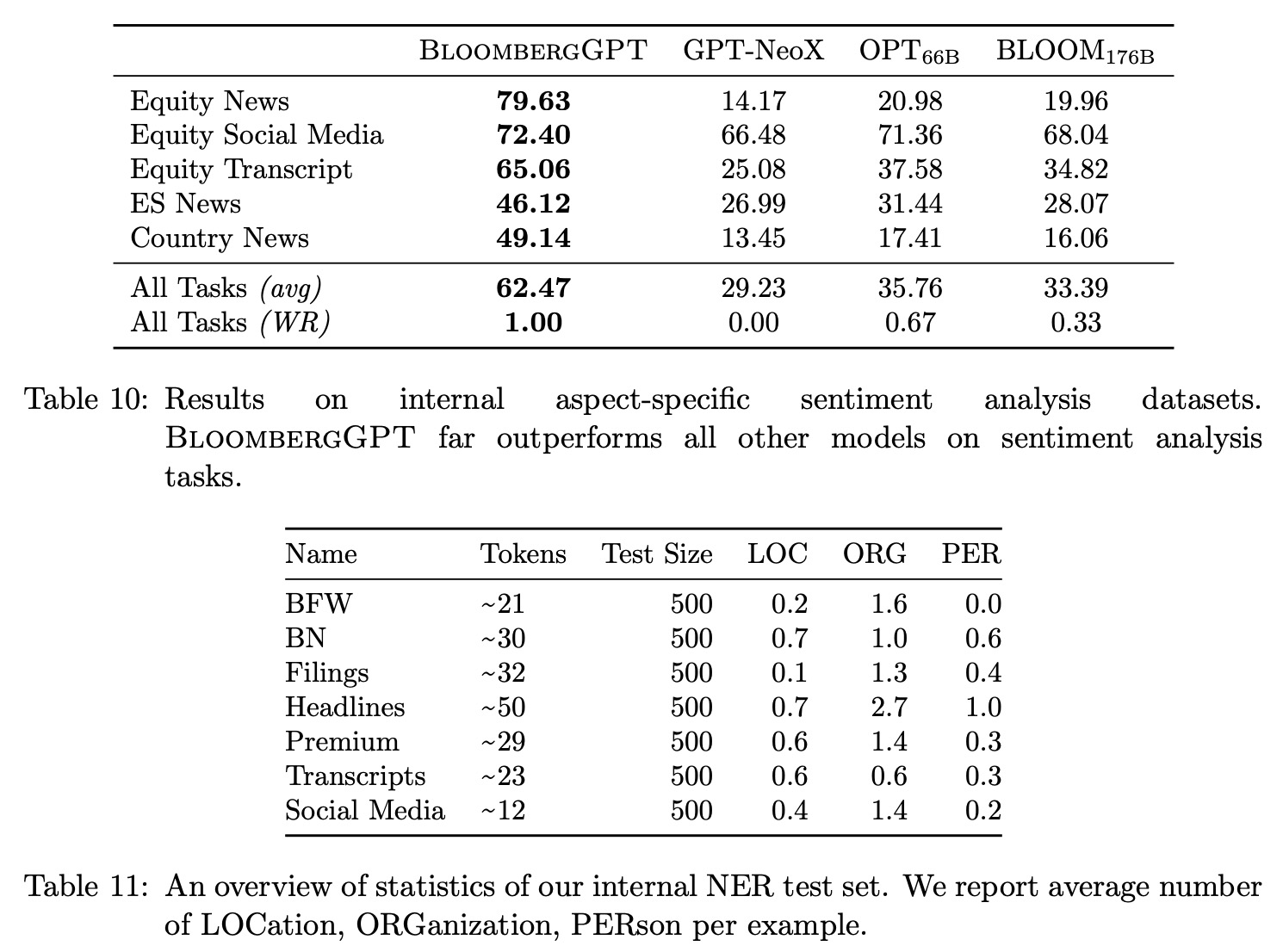
In the finance domain, common NLP tasks like sentiment analysis can have different characteristics and challenges compared to their general counterparts. To assess the performance of BloombergGPT, BLOOM176B, GPT-NeoX, and OPT66B, a combination of public and internal benchmarks are used. These include four tasks from the FLUE benchmark and the ConvFinQA dataset. Since there is no standard testing framework for these tasks, they are adapted to a few-shot setting. The number of shots is chosen to maximize the average performance across all models. However, the evaluation is restricted to comparing LLMs, as non-LLM custom models have different evaluation setups.
For Bloomberg-internal tasks like aspect-specific sentiment analysis, the annotation process involves establishing annotation and sampling procedures, determining the number of annotators needed, and identifying the level of training required for annotators. Annotators can be financial experts at Bloomberg, consultants, or a combination of both. Two annotators work on each dataset, with a third breaking any ties.
LLMs are evaluated on internal datasets using a five-shot evaluation, similar to external datasets. Up to 1k test examples are randomly sampled, and performance is measured using F1 scores weighted by the support of each label. It’s important to note that while BloombergGPT has access to FinPile during training, other LLMs being compared may also have been trained on unlabeled versions of the data available on the web.
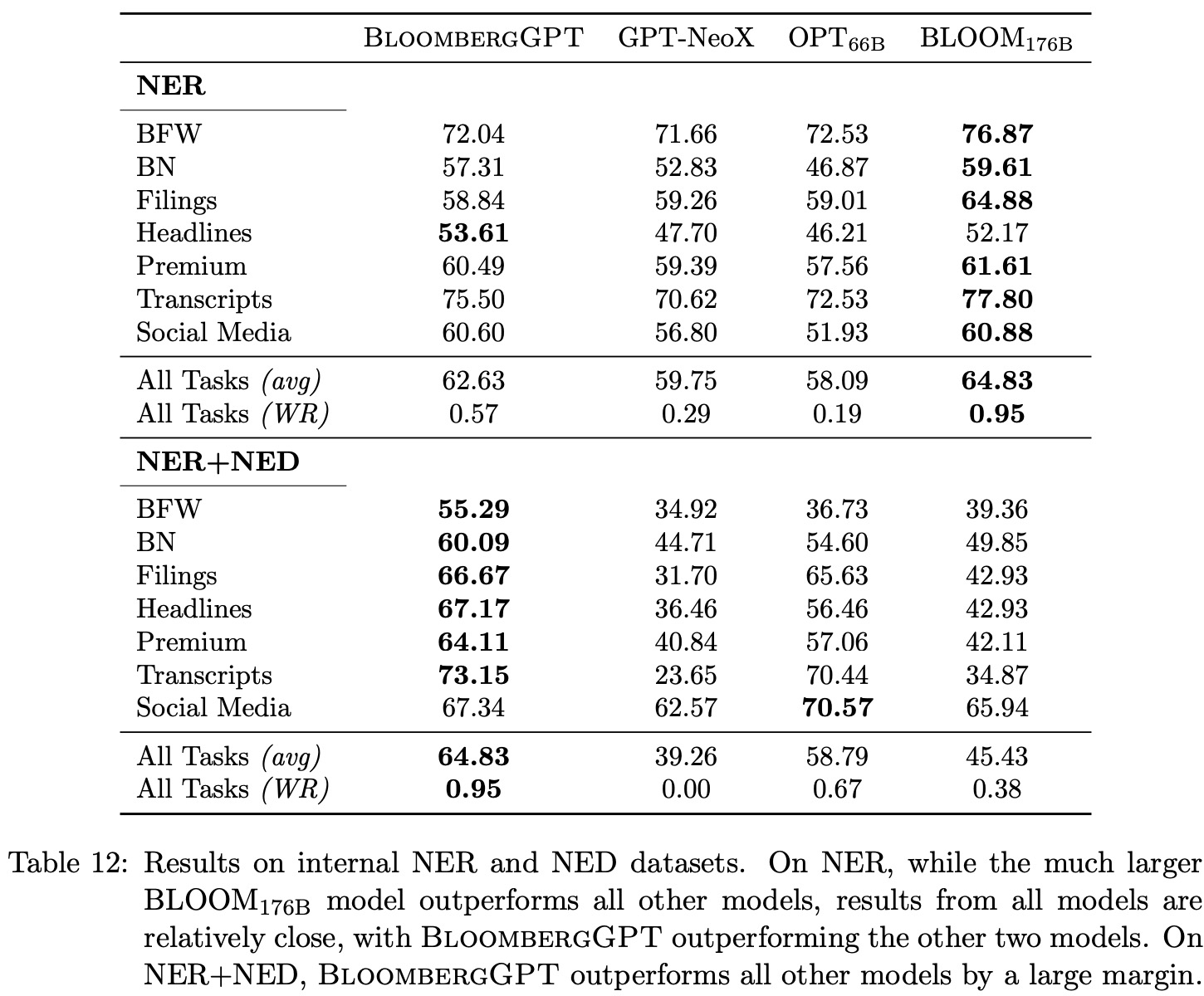
NER can be a challenging task for generative LLMs because it is an information extraction task better suited for encoder-decoder or encoder-only architectures. Finance-specific NER has unique subtleties that make it particularly difficult for zero or few-shot learning. Obtaining reasonable results for NER requires extensive prompt engineering and a higher number of shots compared to other tasks.
For example, consider the (fabricated) headline “Bloomberg: Mr. Musk adds new features to Twitter and comments on China”. Depending on our annotation guidelines and downstream task needs: (a) the reporting news organization “Bloomberg” can be tagged or not, depending on whether we want only salient entities, (b) “Mr. Musk” or just “Musk” is the PER to be tagged, (c) “Twitter” can be tagged as an ORG or a PRD (product) as features are added to the Twitter product and not the organization, and (d) “China” can be tagged ORG or LOC, though the right tag is likely ORG. Without adding extensive annotation guidelines in the prompt, the LLM does not know the intended tagging behavior.
In order to obtain the best performance on internal NER tasks, the authors restrict the entity types to ORG, PER, and LOC, filtering out less than 1% of entities, and remove documents with no entities. These modifications aim to increase the usefulness of examples seen in few-shot prompting. Further work on prompt engineering for NER could potentially yield better results.
The authors explore a joint NER+NED task in the financial domain, which requires identifying stock tickers of companies mentioned in a document. This task is robust to variations in extracting exact text spans and evaluates a model’s knowledge of companies, their various surface forms, and company-to-ticker mappings. They create evaluation data with linked tickers by running a state-of-the-art entity linking system for companies in financial data over Bloomberg’s internal NER annotated documents. They utilize 20-shot prompts and evaluate using F1.
The results show that BloombergGPT outperforms all other models by a large margin, except on social media data, where it comes in second behind BLOOM176B. The task reverts to NER in social media data as companies are often referenced by their tickers. These results underscore the advantage of BloombergGPT for financial tasks.
BIG-bench Hard
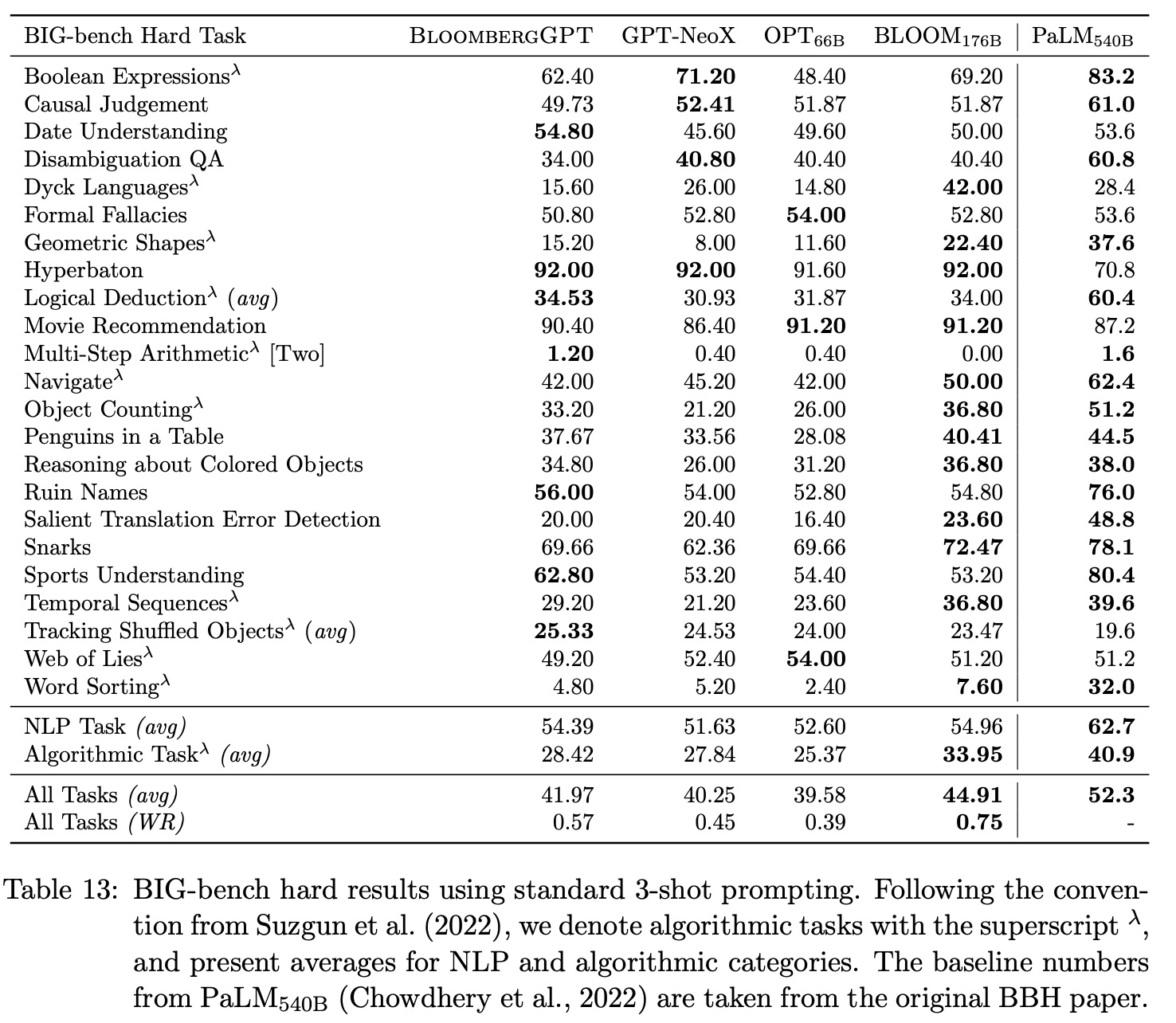
The authors evaluate BloombergGPT on standard, general-purpose NLP tasks using the BIG-bench Hard, a subset of the most challenging tasks in BIG-bench. The results show that while BloombergGPT falls behind larger models like PaLM540B and BLOOM176B, it is the best-performing among similarly sized models. In fact, its performance is closer to BLOOM176B than to GPT-NeoX or OPT66B. BloombergGPT achieves the best performance in date understanding, hyperbaton, and tracking shuffled objects. The authors conclude that developing finance-specific BloombergGPT did not come at the expense of its general-purpose abilities.
Other