Paper Review: ByT5: Towards a token-free future with pre-trained byte-to-byte models
A new interesting paper by Google Research. The authors suggest an alternative to using a tokenizer - training a model on the texts converted into bytes. Token-free models can work with any language, are more robust to the noise, and don’t require preprocessing. They use a modified mT5 architecture and show that their approach is competitive with token-level models.
On the tokenization and the alternatives
The most common way of representing the text for using in models is by creating a tokenizer. The main issue of this approach is dealing with out-of-vocabulary words. In the case of word tokenizing, we usually replace unknown words with a special <UNK> token, thus not being able to distinguish different new words.
A more advanced approach is subword tokenizing. The downside of this approach is that typos, variants in spelling and capitalization, and morphological changes can result in different representations. And unknown subwords for new languages will be out-of-vocabulary.
The idea of token-free models isn’t the novel - it was explored in CANINE, for example. Converting the text into a sequence of bytes allows the model to work on arbitrary sequences of texts. Another benefit is that we don’t need a huge vocabulary matrix and thus can use more parameters in the model itself. A byte-level model, by definition, only requires 256 embeddings.
The main drawback of byte-level models is that byte sequences are longer than text sequences. Nevertheless, Transformers can be used without huge computational costs.
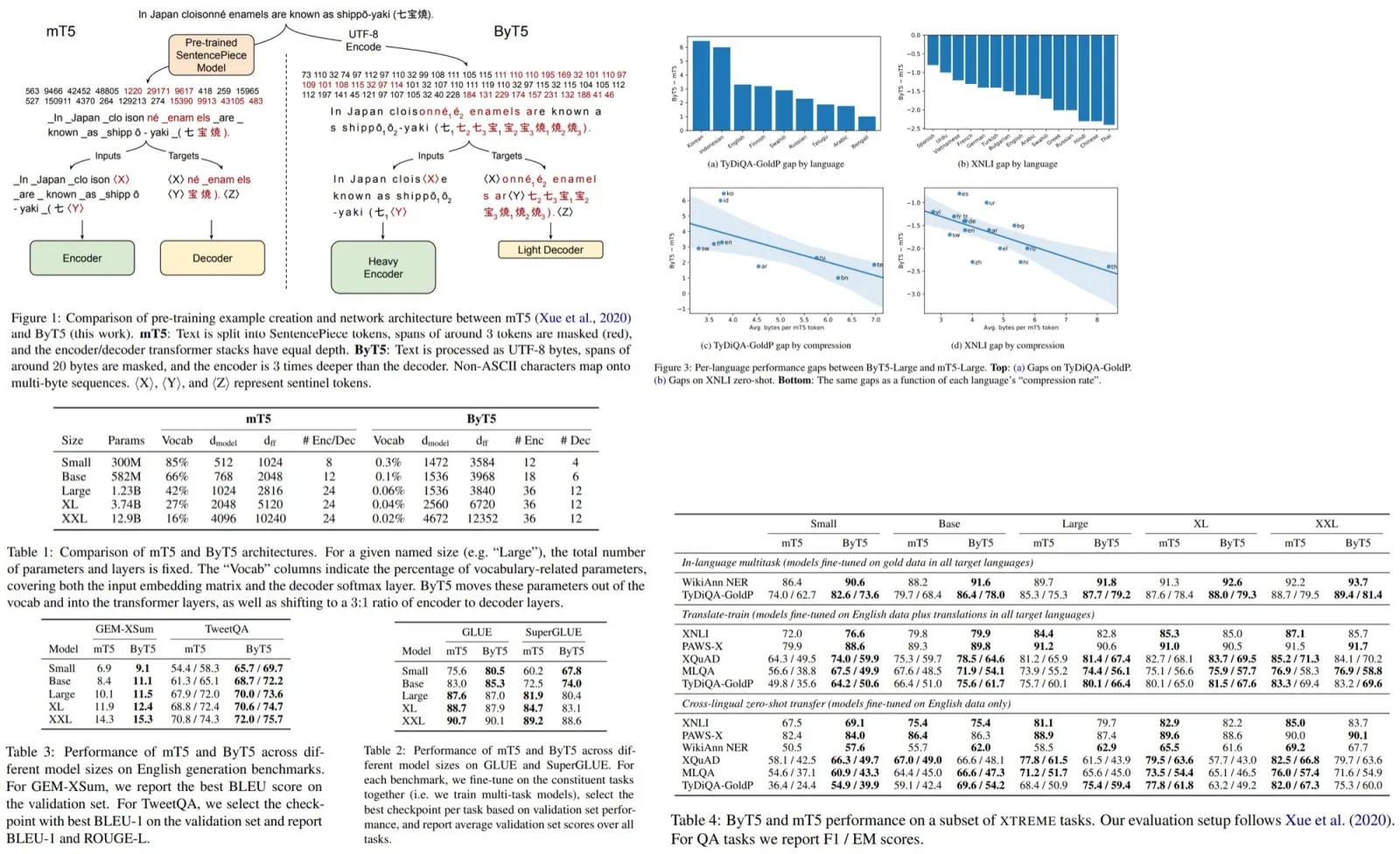
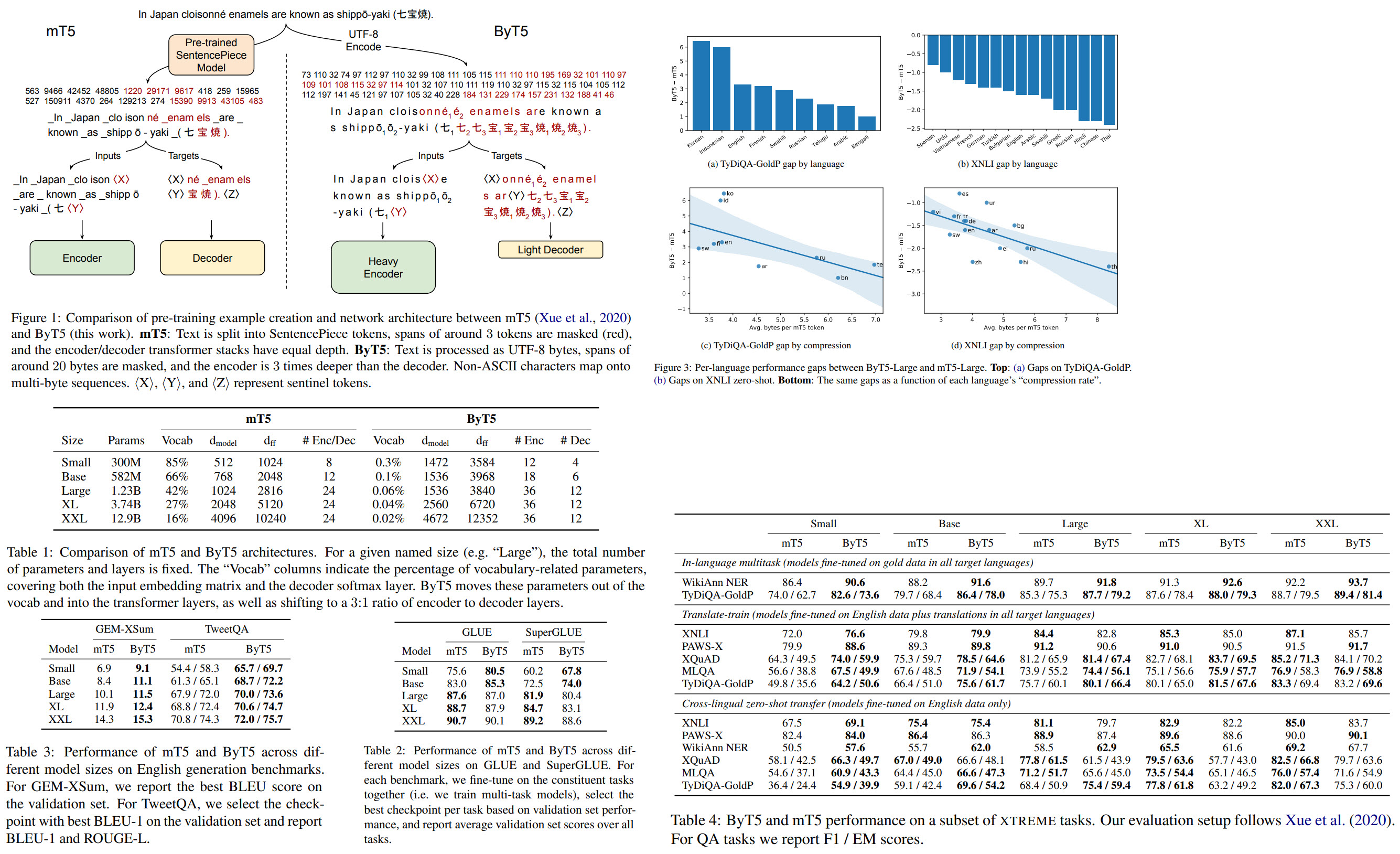
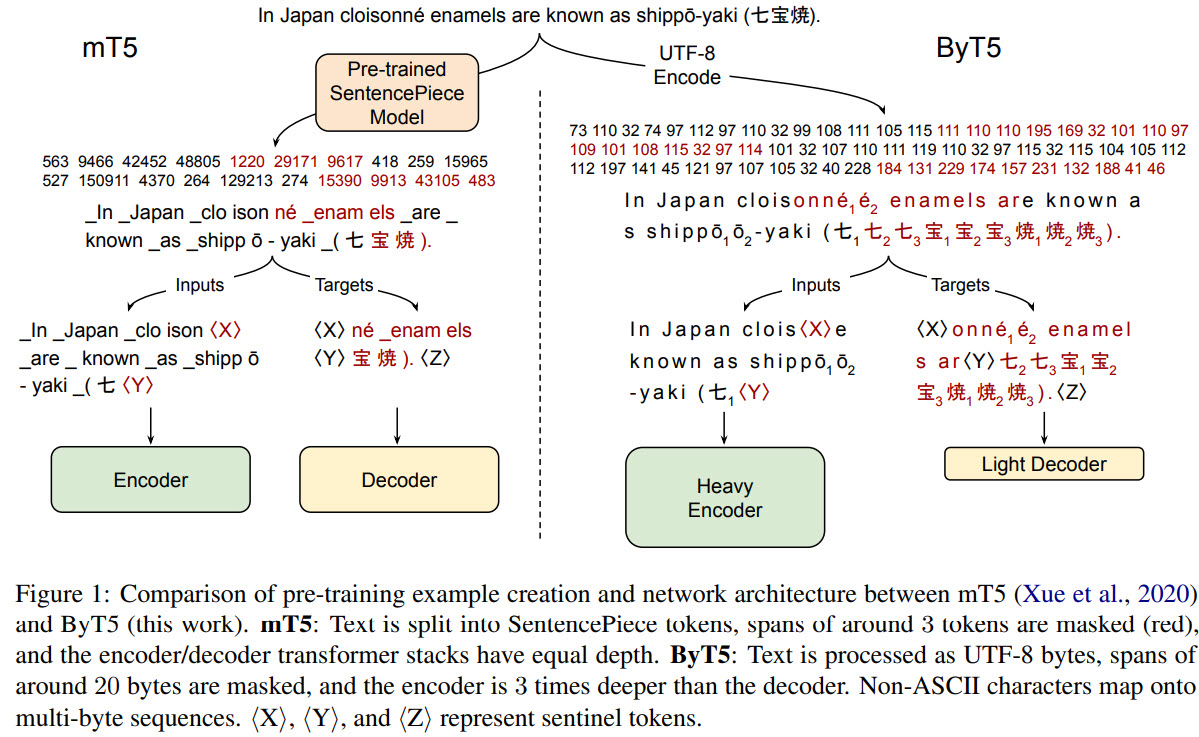
The authors use a modified mT5 architecture, as the T5 model works on tasks in text-to-text format.
The approach
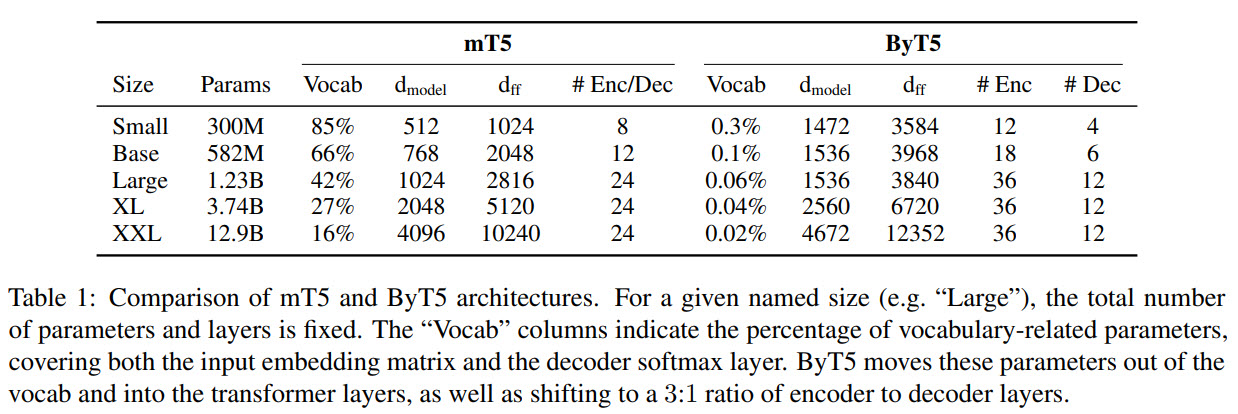
- ByT5 has 5 sizes (as do T5 and mT5): Small, Base, Large, XL, XXL;
- ByT5 should work best for short-to-medium length text sequences (a few sentences or less);
- The main change is that UTF-8 bytes are fed into the model without preprocessing. There are 256 possible values and 3 additional: padding, EOS and UNK (unused, left for convention);
- Changes to the pre-training task: masking spans of 20 bytes and trying to predict the missing values;
- In T5 and mT5, the decoder and the encoder usually have the same depth. The experiments have shown that ByT5 works better with the encoder that has 3 times more depth than the decoder;
- As not all byte sequences are legal according to the UTF-8 standard, they drop the illegal combinations
bytes.decode("utf-8", errors="ignore") - To make ByT5 comparable to the previous models, the authors try to match the number of model parameters and train on 4 times less text (due to the increase because of byte length and the fixed number of training steps);
The results
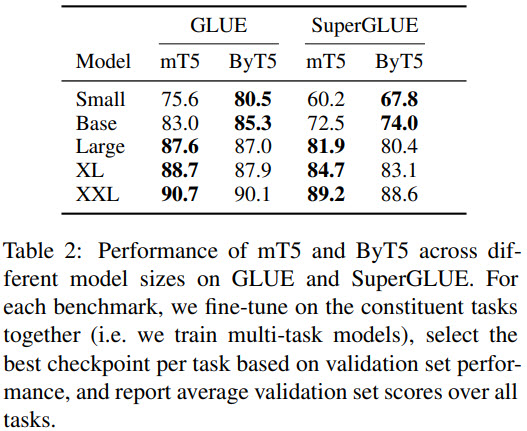
- On GLUE and SuperGLUE, ByT5 is better on small and base sizes but is worse on bigger sizes. One of the possible reasons - mT5 models of smaller sized dedicate a too high percentage of parameters to vocabulary, and thus the model itself is a bit worse;
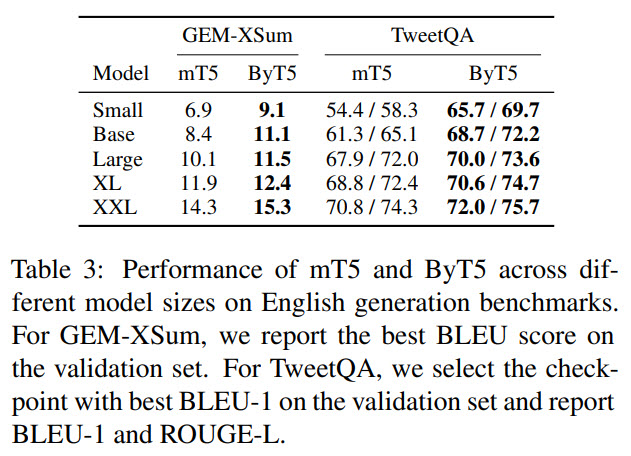
- On generative tasks (summarization and QA) ByT5 is much better;
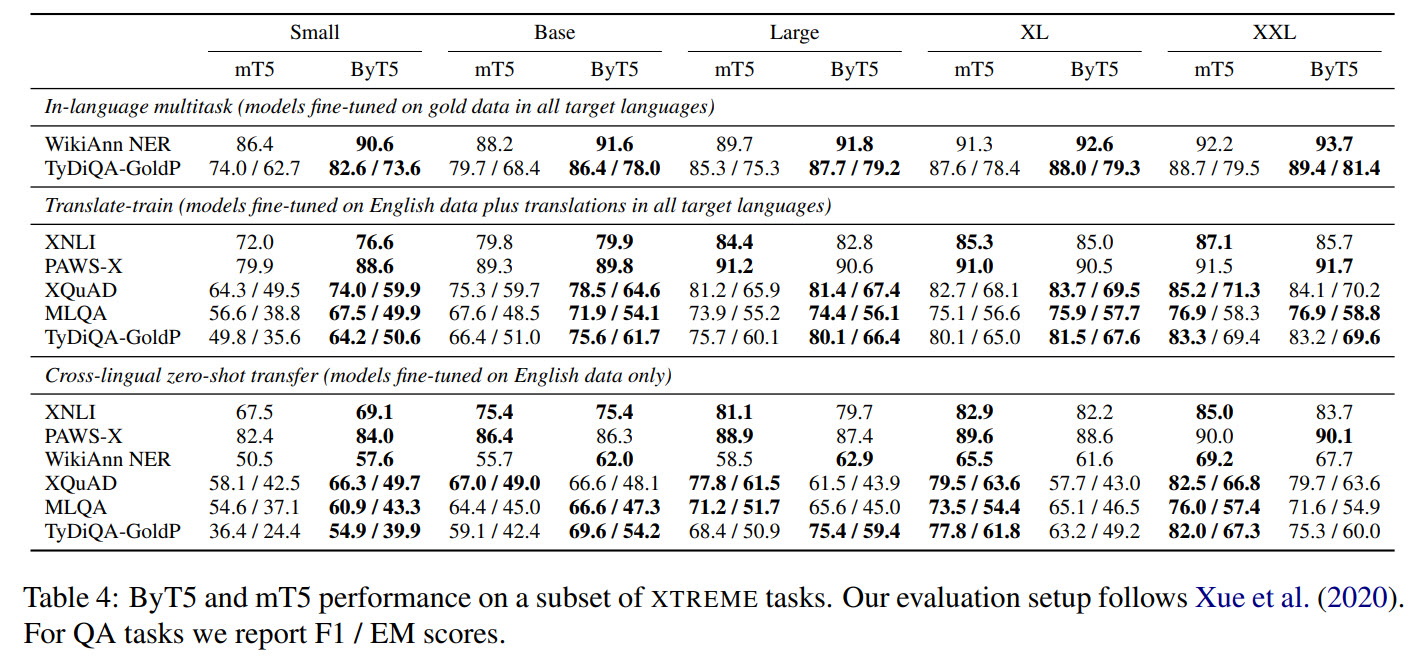
- Cross-language benchmarks show mixed results. For in-language tasks ByT5 is better, for translate-train setting it is better only on smaller sizes;
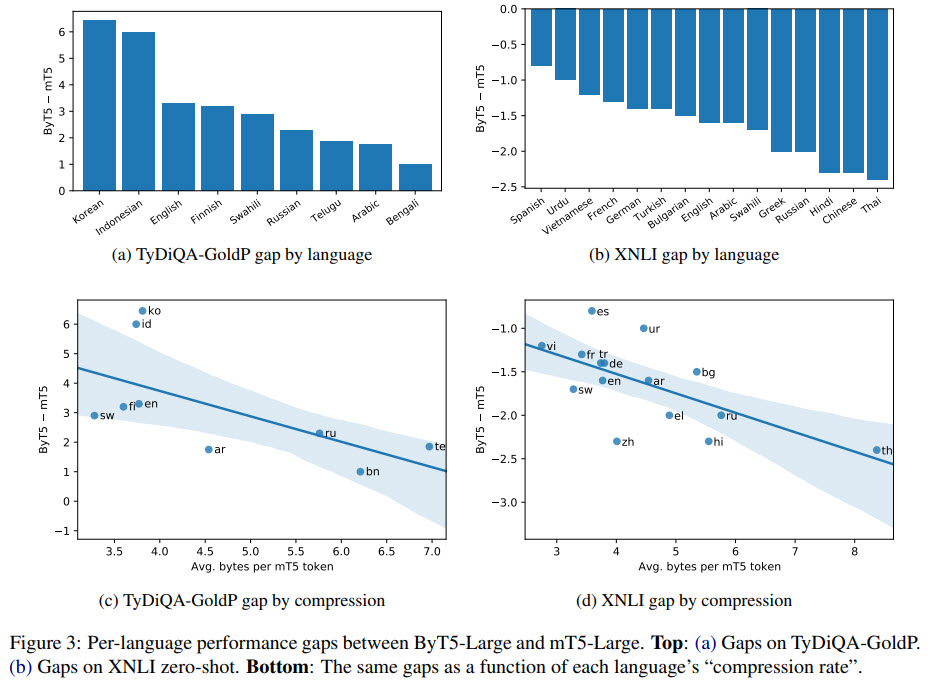
- Another experiment is to see which languages benefit or hurt more from switching to byte-level processing. It seems that languages with a higher SentencePiece token compression rate favor mT5, and those with lower compression rate favor ByT5;
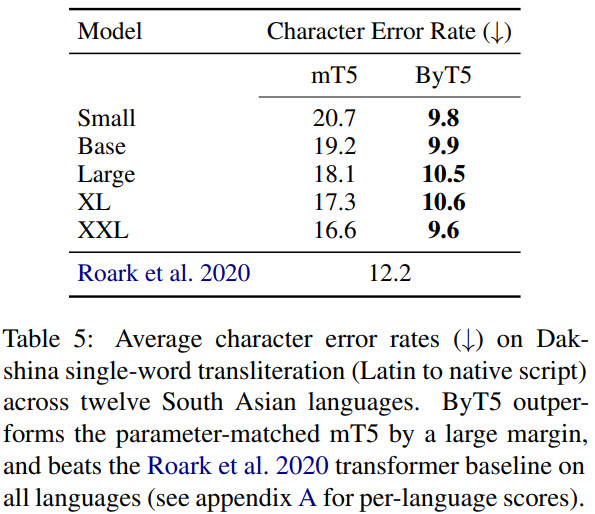
- ByT5 works quite good for tasks sensitive to the spelling or pronunciation - for example, transliteration;
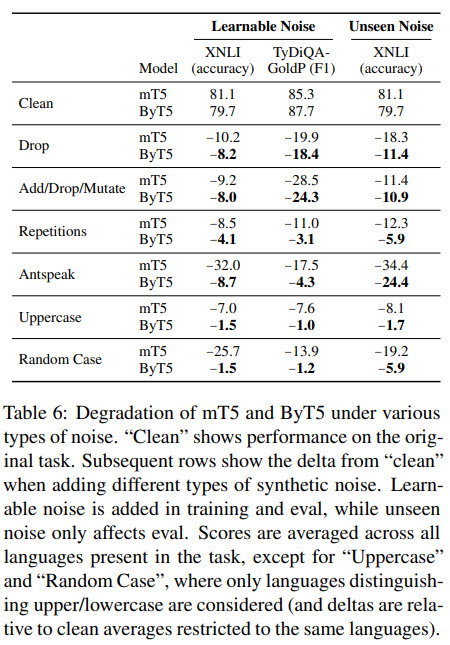
- ByT5 also works well on texts with various types of noise;
Ablation study
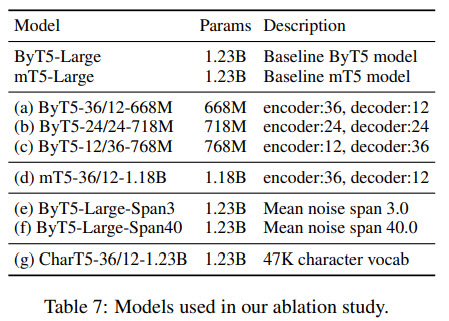
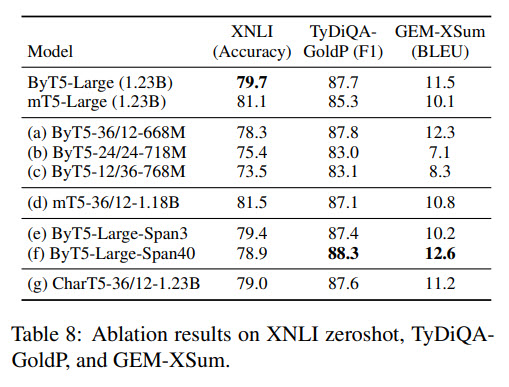
- increasing the decoder doesn’t help;
- lower masked span length (20) is better for downstream classification tasks, longer (40) - for downstream generation tasks;
Speed comparison
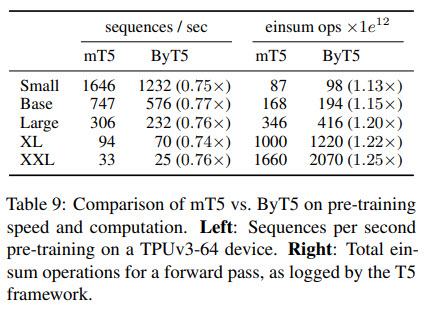
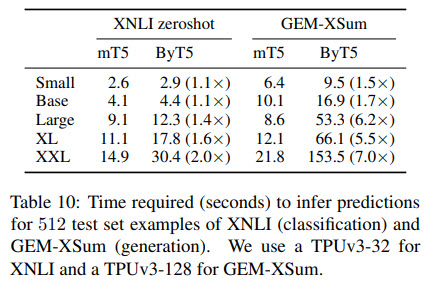
ByT5 is a little slower while training and much slower while making predictions.
Overall, the authors think that this slowdown could be justified by the benefits of reduced system complexity, better robustness to noise, and improved task performance on many benchmarks.
paperreview deeplearning nlp pretraining