Paper Review: Contrastive Feature Masking Open-Vocabulary Vision Transformer

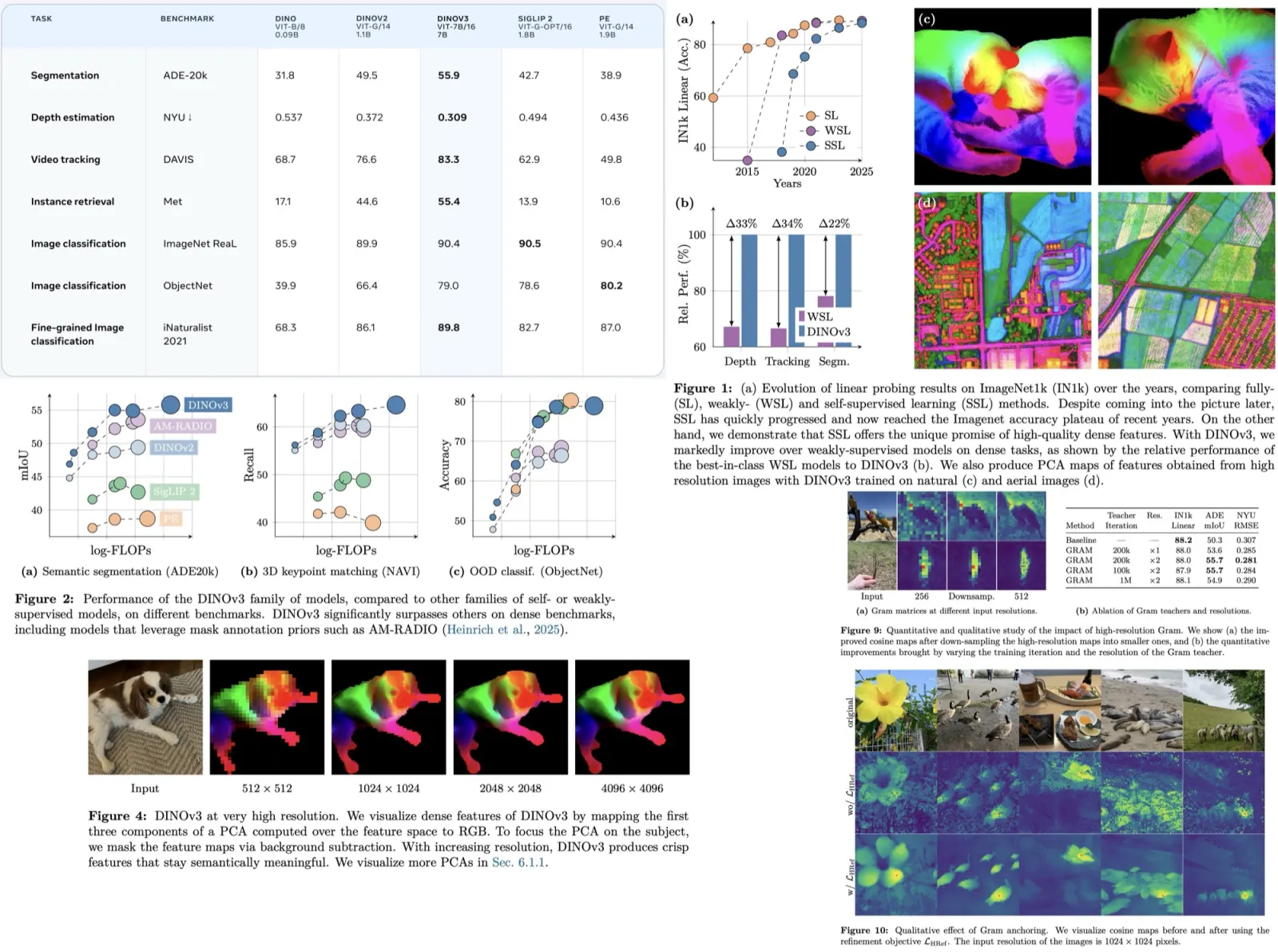
Contrastive Feature Masking Vision Transformer (CFM-ViT) is a new method for image-text pretraining that enhances open-vocabulary object detection. CFM-ViT integrates the masked autoencoder with contrastive learning, focusing on joint image-text embedding reconstruction instead of typical pixel space, which benefits region-level semantics understanding. The model also features Positional Embedding Dropout to manage scale differences between pretraining and finetuning. This prevents the loss of learned vocabulary during fine-tuning and enhances detection performance.
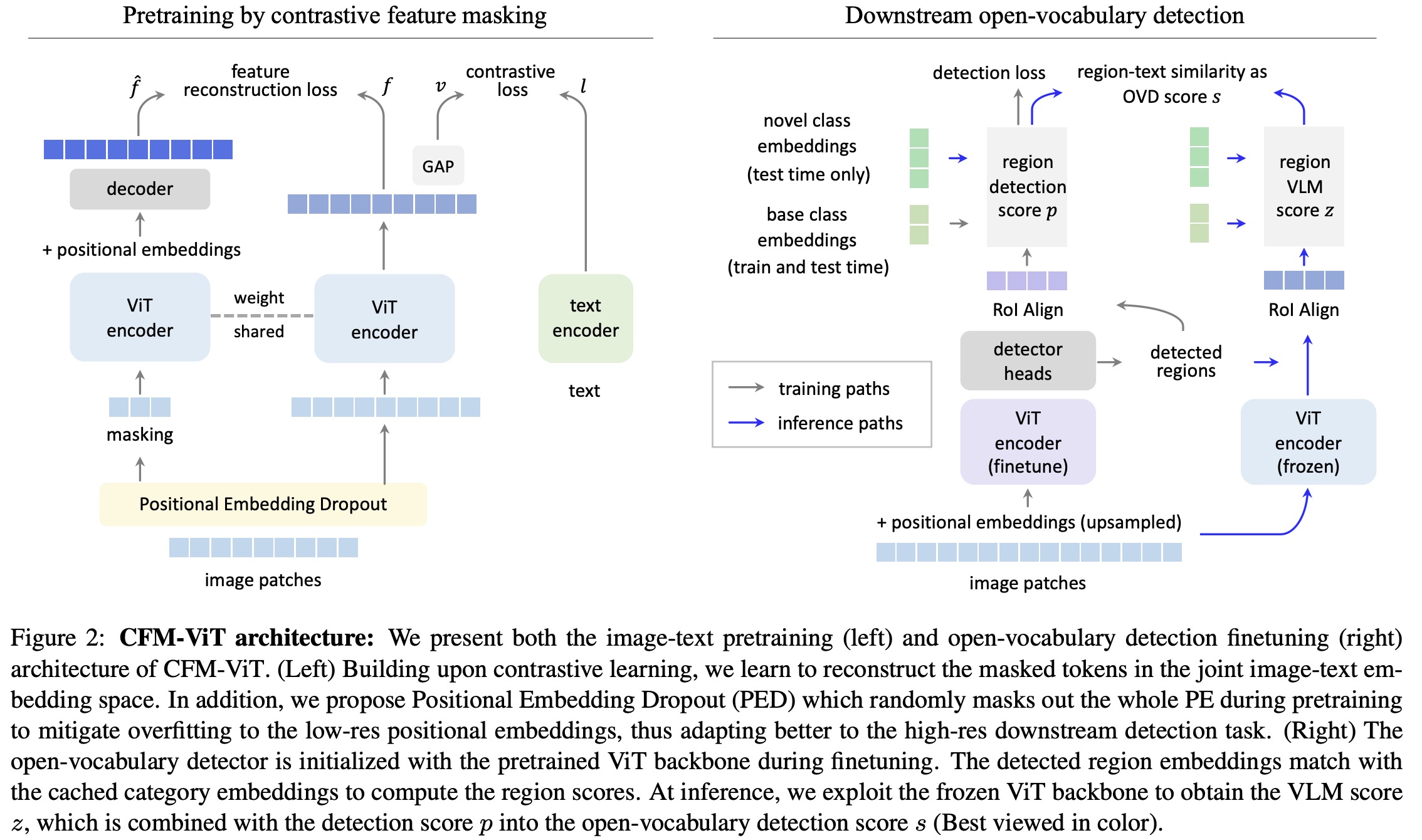
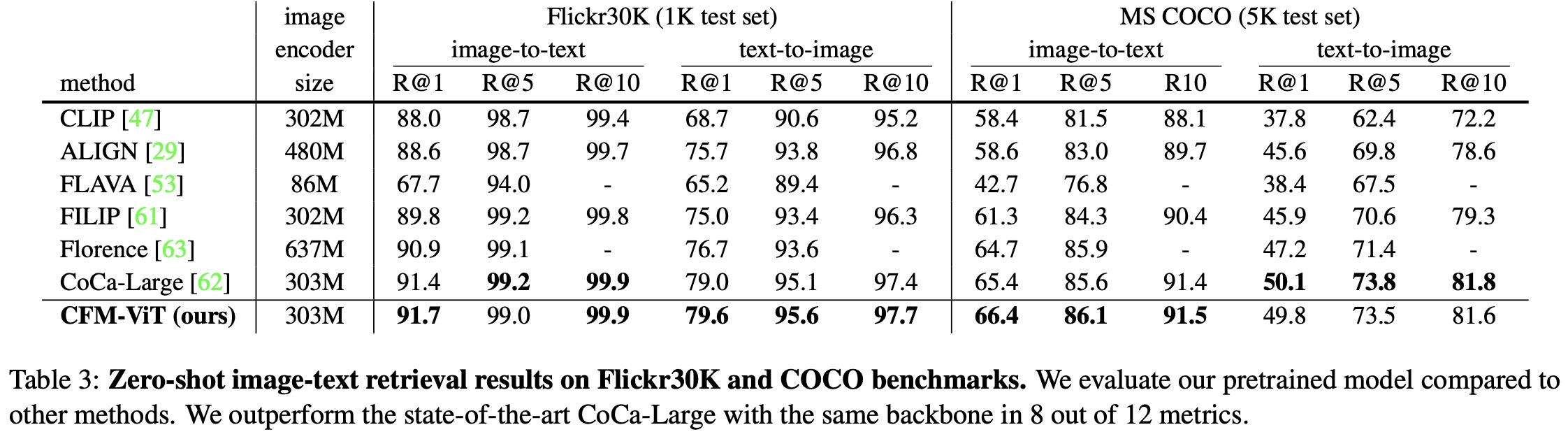
On the LVIS open-vocabulary detection benchmark, CFM-ViT sets a new state-of-the-art with a 33.9 APr score, outperforming the previous best by 7.6 points. The method also excels in zero-shot detection transfer and performs exceptionally well on zero-shot image-text retrieval benchmarks, surpassing the state of the art in 8 out of 12 metrics.
Method
Overall Pipeline
Pretraining Phase:
- A dual-encoder image-text contrastive model is used, where image and text embeddings are obtained through global average pooling at the last layers of their respective encoders.
- The model uses InfoNCE loss, and the contrastive loss is the average of image-to-text and text-to-image components.
Downstream Object Detection:
- The model uses Region of Interest-Align features as region embeddings.
- The detection score is calculated as the cosine similarity between these region embeddings and the text embeddings for the base categories, all passed through a softmax layer.
- At test time, the text embeddings are expanded to include both base and novel categories, as well as a “background” category. A Visual Language Model score is also calculated at test time based on the same text embeddings.
Ensemble Scoring:
- An ensemble score is obtained using geometric means, with weight factors controlling the influence of base and novel categories, respectively.
- The background score comes directly from the detection score, as VLM scores for the “background” category are considered less reliable.
Contrastive Feature Masking
Masked feature reconstruction. An auxiliary objective to the primary contrastive learning task involves reconstructing features in the joint image-text embedding space. Unlike Masked AutoEncoder, which reconstructs raw pixels, CFM-ViT focuses on reconstructing joint image-text embeddings to better learn semantics. Reconstruction loss calculates the cosine distance between reconstructed and unmasked image features. The total loss is the sum of this loss and the contrastive loss.
Faster training by contrastive branch masking. The feature reconstruction adds computational burden during pretraining. To offset this, the authors introduce contrastive branch masking: feed only masked tokens to the contrastive branch, allowing for computational efficiency without sacrificing performance.
Positional embedding dropout. Vision Transformers usually use positional embeddings to give the model information about the location of each patch in the image. However, these embeddings can overfit to lower-resolution images and struggle with high-res images typically used in detection tasks. To solve this, PED randomly masks out the positional embeddings during training, making the model less dependent on them for tasks like high-res image and region-level object detection.
Open-vocabulary Detection
Object detector is trained on a set of base categories, but it is also expected to identify a combination of base and novel categories during testing. The baseline architecture of the detector incorporates elements like feature pyramids and windowed attention to manage high-resolution images, drawing inspiration from ViTDet. It also employs Mask R-CNN heads along with class-agnostic box regression and mask heads. Additionally, a novel object proposal method based on centerness-based objectness is integrated, contributing to the final Open Vocabulary Detection score.
The model is initialized with a pretrained ViT and then finetuned along with the newly added detector heads. Unlike in pretraining, Positional Embedding Dropout is not used during this finetuning phase, as location data is vital for the task of object detection.
To manage a balance between retaining pretrained knowledge and allowing the model to adapt to the detection tasks, the learning rate for the backbone is set to be lower than that for the other layers of the detector. For the inference stage, the model switches to a separate, frozen ViT backbone, which helps in maintaining the open-vocabulary knowledge that tends to be lost during finetuning. This frozen backbone is particularly effective when it has been pretrained with Positional Embedding Dropout, enhancing the model’s capabilities in zero-shot region classification.
Experiments
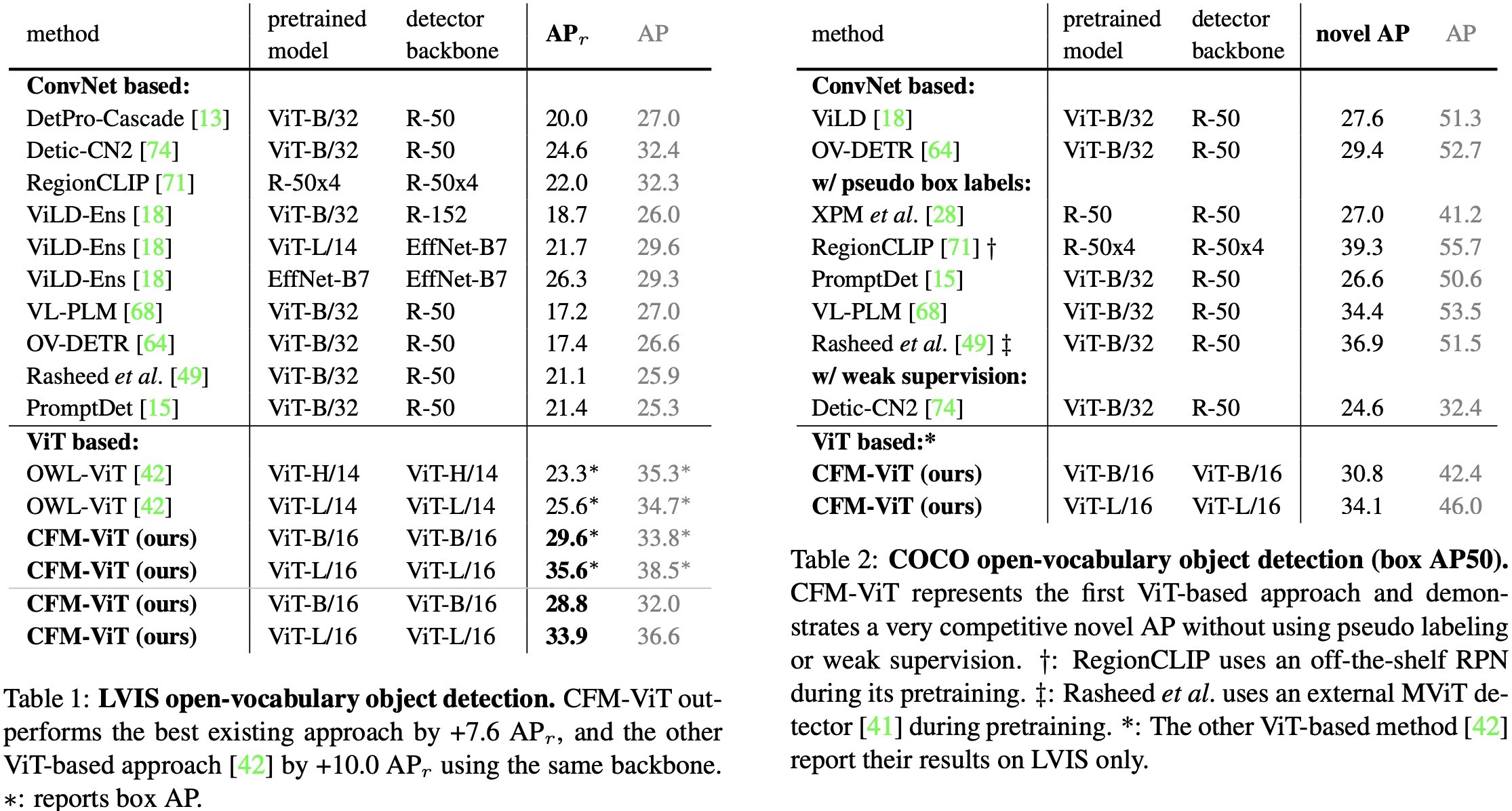
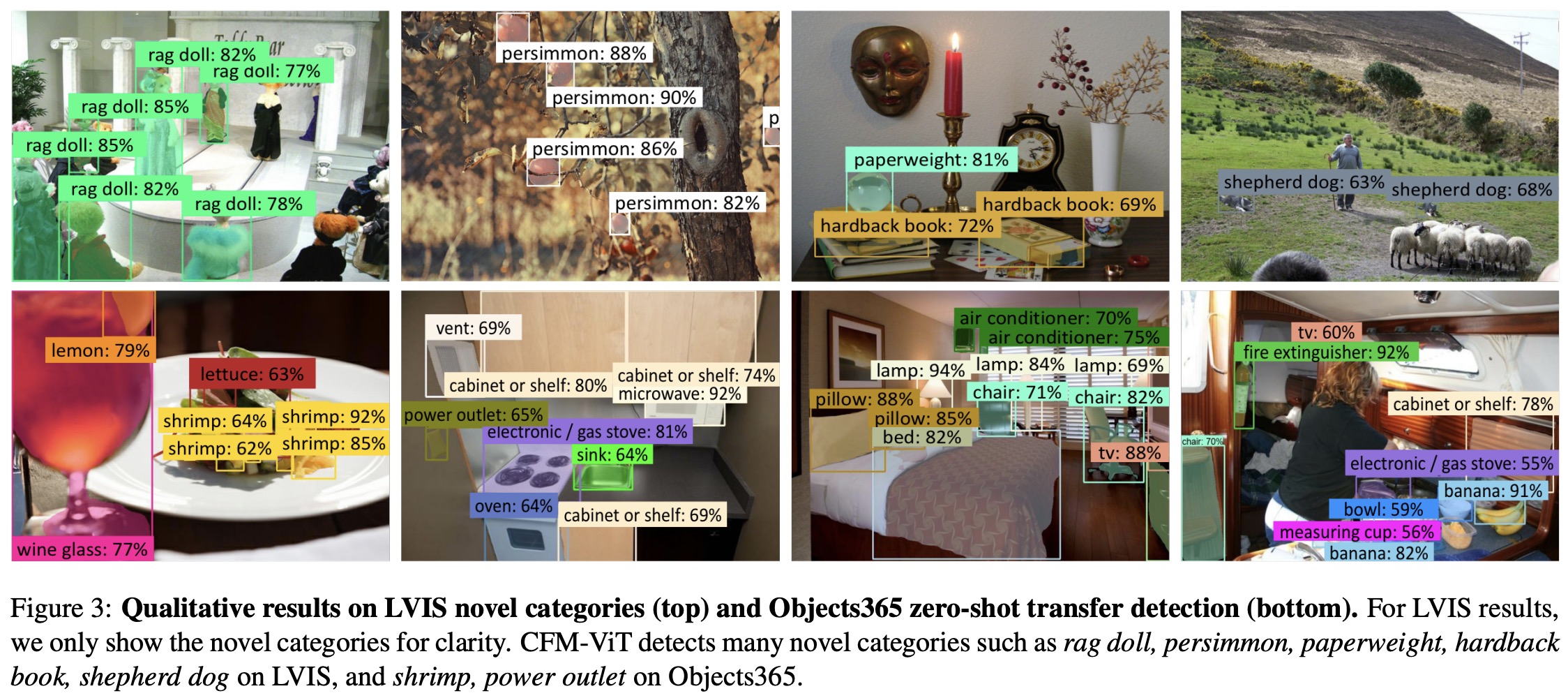
- On the LVIS open-vocabulary detection benchmark, which includes a diverse set of 1,203 object categories, CFM-ViT significantly outperforms existing methods scoring 33.9 APr. Notably, CFM-ViT achieves this high score using simpler fine-tuning techniques without employing long-tail recognition losses, knowledge distillation, weak supervision, or pseudo box/mask labels that are commonly used in current methods.
- In the COCO open-vocabulary detection benchmark, CFM-ViT remains competitive despite a tendency to overfit to fewer training categories, as it does not use auxiliary objectives to counter-balance overfitting. It is also the first ViT-based method to be benchmarked on COCO.
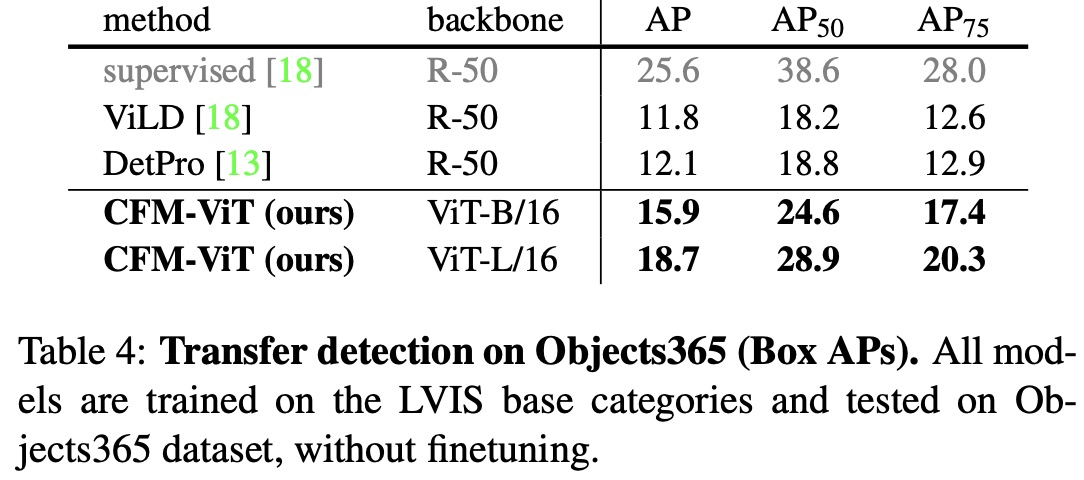
- The model also excels in zero-shot image-text retrieval, outperforming state-of-the-art methods on 8 out of 12 metrics when tested on Flickr30K and MS COCO benchmarks. Furthermore, in a zero-shot transfer detection test on the Objects365-v1 validation split, CFM-ViT outperforms other models, indicating strong cross-dataset generalization capabilities.
Ablations
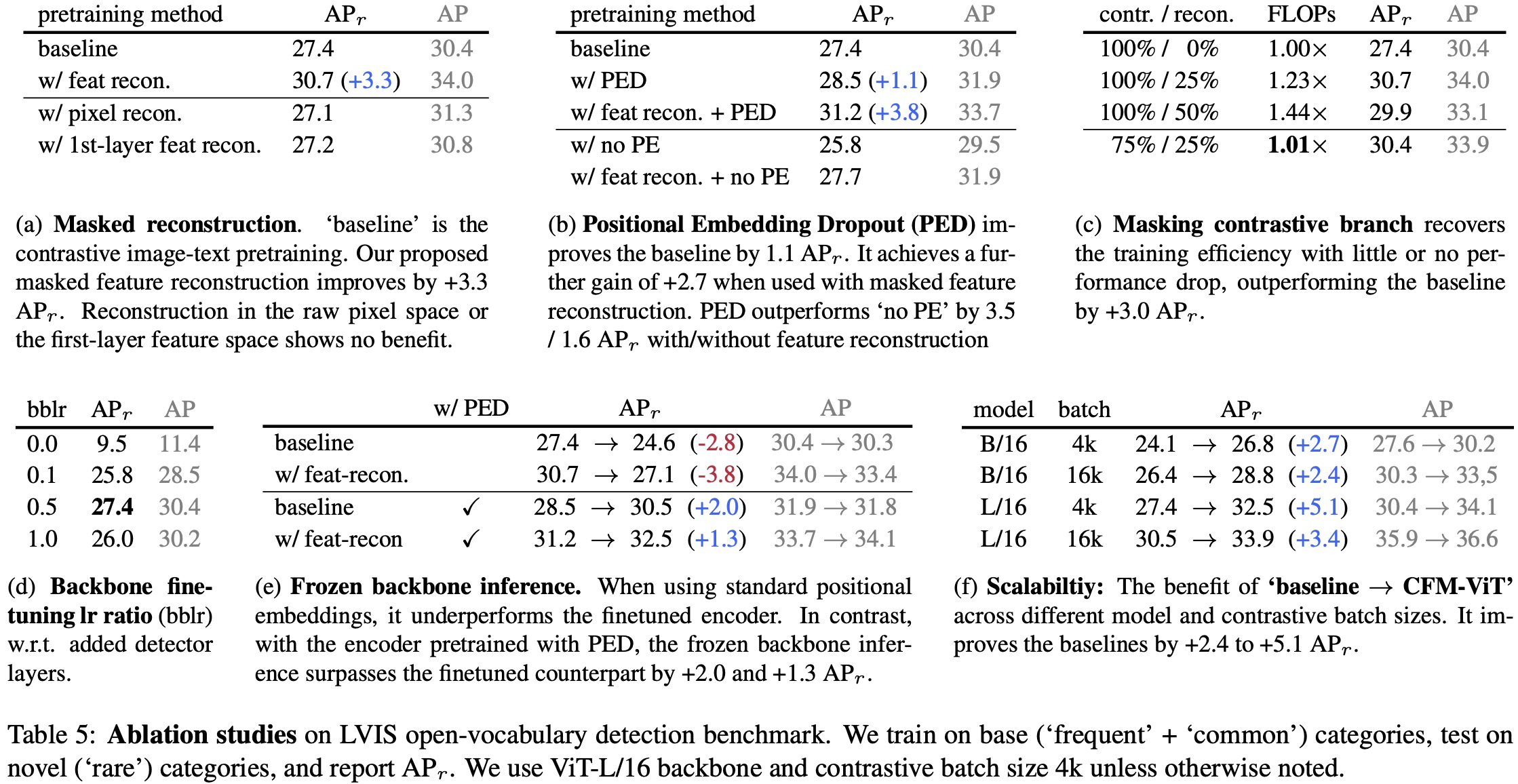
- Masked Feature Reconstruction: Introducing masked feature reconstruction during pretraining improves the model’s performance by +3.3 APr over the baseline that uses contrastive image-text pretraining. Other reconstruction targets didn’t show an improvement over the baseline.
- Positional Embedding Dropout: Employing PED during pretraining results in a +1.1 APr gain, proving effective in reducing overfitting. Further, when used alongside masked feature reconstruction, PED adds another +2.7 APr.
- Faster Training: Modifying the contrastive encoder to accept only 75% of the tokens, mutually exclusive from the reconstruction branch, helps maintain training efficiency without significant loss of accuracy (+3.0 APr improvement over the baseline).
- Backbone Learning Rate: Setting a lower learning rate (0.5×) for the backbone during finetuning proves optimal. Higher rates lead to “forgetting,” while lower rates restrict adaptability.
- Frozen Backbone Inference: Using a frozen ViT backbone during inference improves performance significantly when PED is used during pretraining. This results in an overall improvement of +5.1 APr over the baseline.
- Model and Batch Size: Increasing the model and batch size also benefits performance, aligning with findings from the contrastive learning literature.
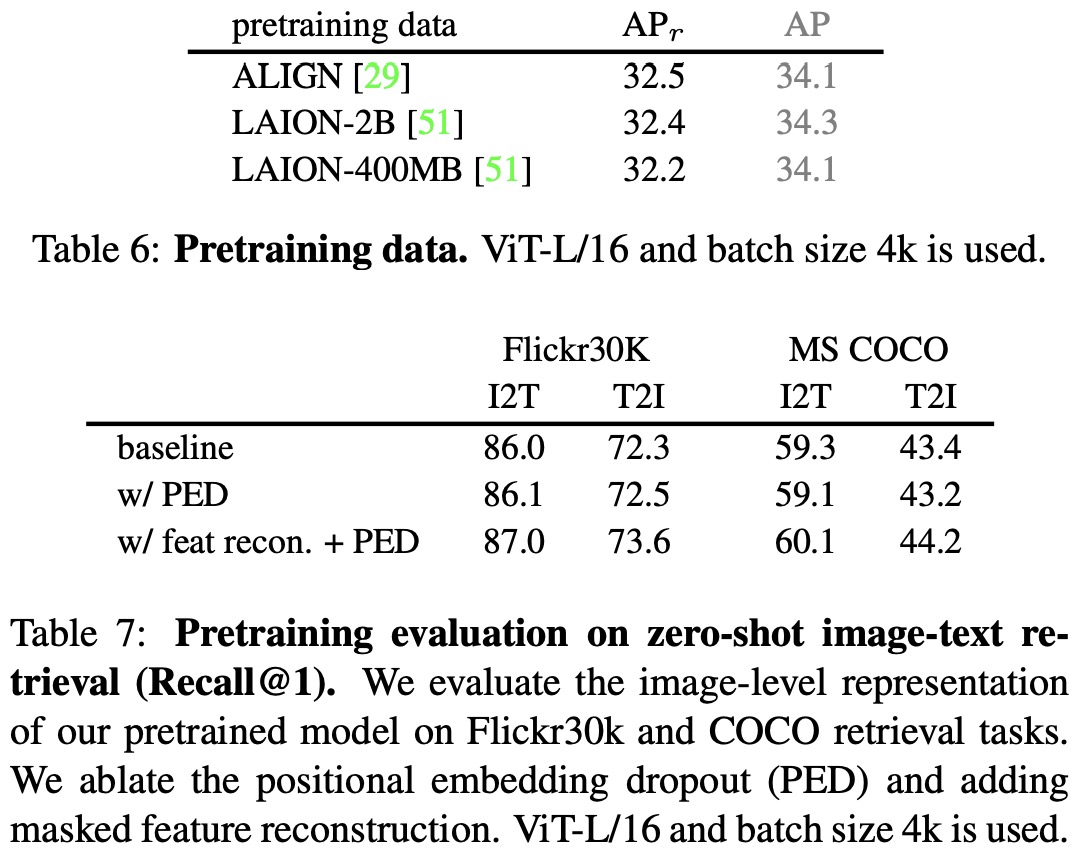
- Pretraining Data: Experimenting with different datasets for pretraining shows comparable performance, indicating that the model is not sensitive to the dataset used.
- Image-text Retrieval: Positional embedding dropout and masked feature reconstruction show positive effects in zero-shot image-level retrieval tasks.