Paper Review: Chameleon: Mixed-Modal Early-Fusion Foundation Models
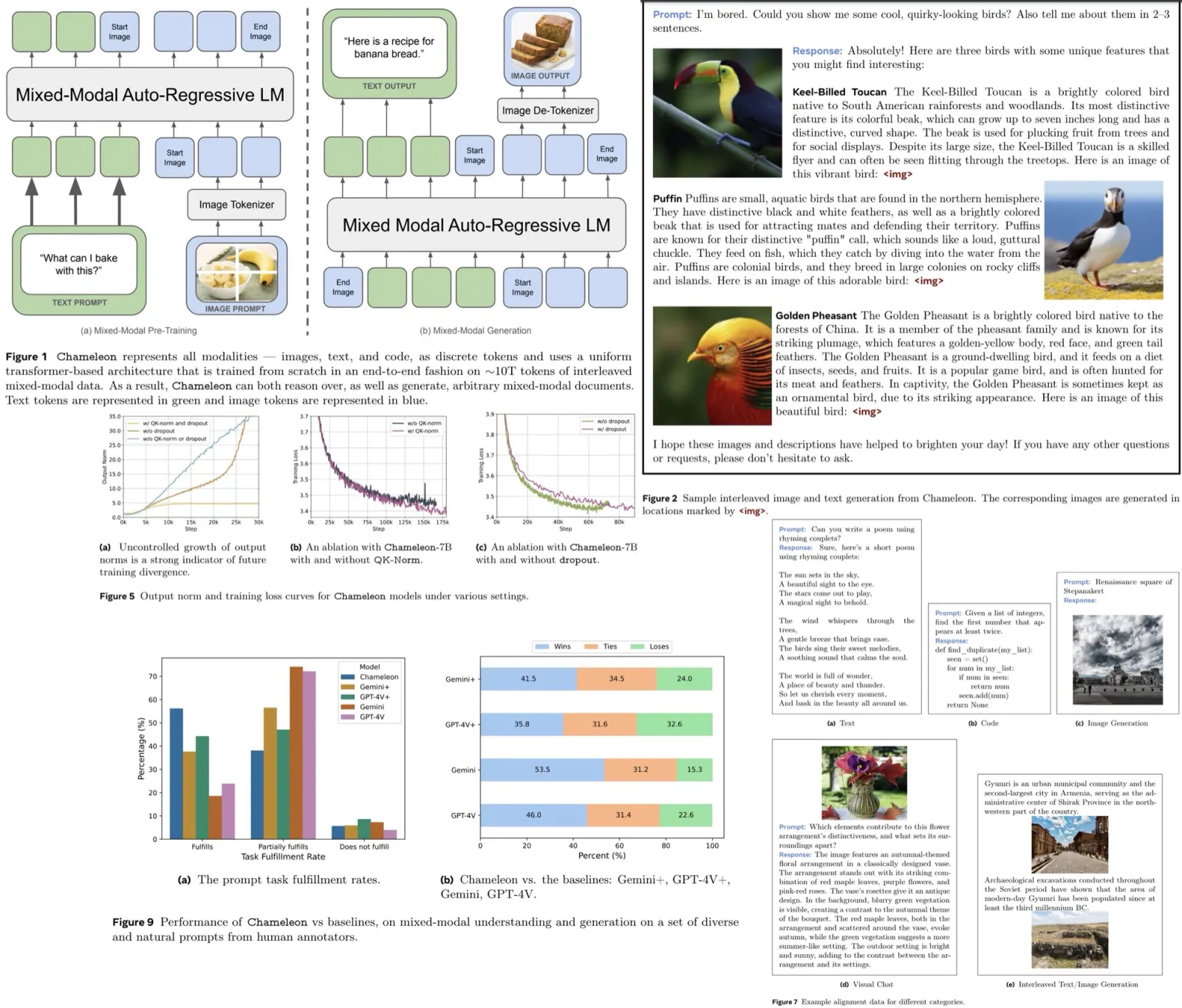
Chameleon is a family of early-fusion, token-based models designed for mixed-modal understanding and generation of images and text. The authors share their approach for stable training and alignment strategy, tailored for their unique architecture. The models excel in tasks like visual question answering, image captioning, text generation, and image generation. Chameleon achieves state-of-the-art performance in image captioning, outperforms Llama-2 in text-only tasks, and competes well with models like Mixtral 8x7B and Gemini-Pro. It also performs complex image generation and matches or surpasses larger models, including Gemini Pro and GPT-4V, in human-judged long-form mixed-modal generation tasks.
Pre-Training
Tokenization
The tokenizer encodes a 512 × 512 image into 1024 discrete tokens from a codebook of 8192 entries, using only licensed images. Given the significance of generating human faces, the training process includes an increased proportion of images featuring faces, doubling their representation during pre-training. However, a notable limitation of this tokenizer is its difficulty in reconstructing images containing substantial amounts of text, which affects the model’s performance in tasks that heavily rely on OCR.
In addition to the image tokenizer, a new BPE tokenizer is trained on a subset of the training data, featuring a vocabulary size of 65536 that incorporates the 8192 image codebook tokens.
Pre-training data
The pre-training of Chameleon is divided into two distinct stages. The first stage, constituting 80% of the training process, uses a mixture of large-scale, unsupervised datasets. The text-only datasets include a combination of the pre-training data for LLaMa-2 and CodeLLaMa, totaling 2.9 trillion text-only tokens. The text-image dataset comprises 1.4 billion text-image pairs, resulting in 1.5 trillion text-image tokens, with images resized and center-cropped to 512 × 512 for tokenization. Additionally, there are 400 billion tokens of interleaved text and image data, sourced from publicly available web data, excluding Meta’s products or services.
In the second stage, the data from the first stage is down-weighted by 50%, and higher quality datasets are introduced, while maintaining a similar ratio of image to text tokens.
Stability
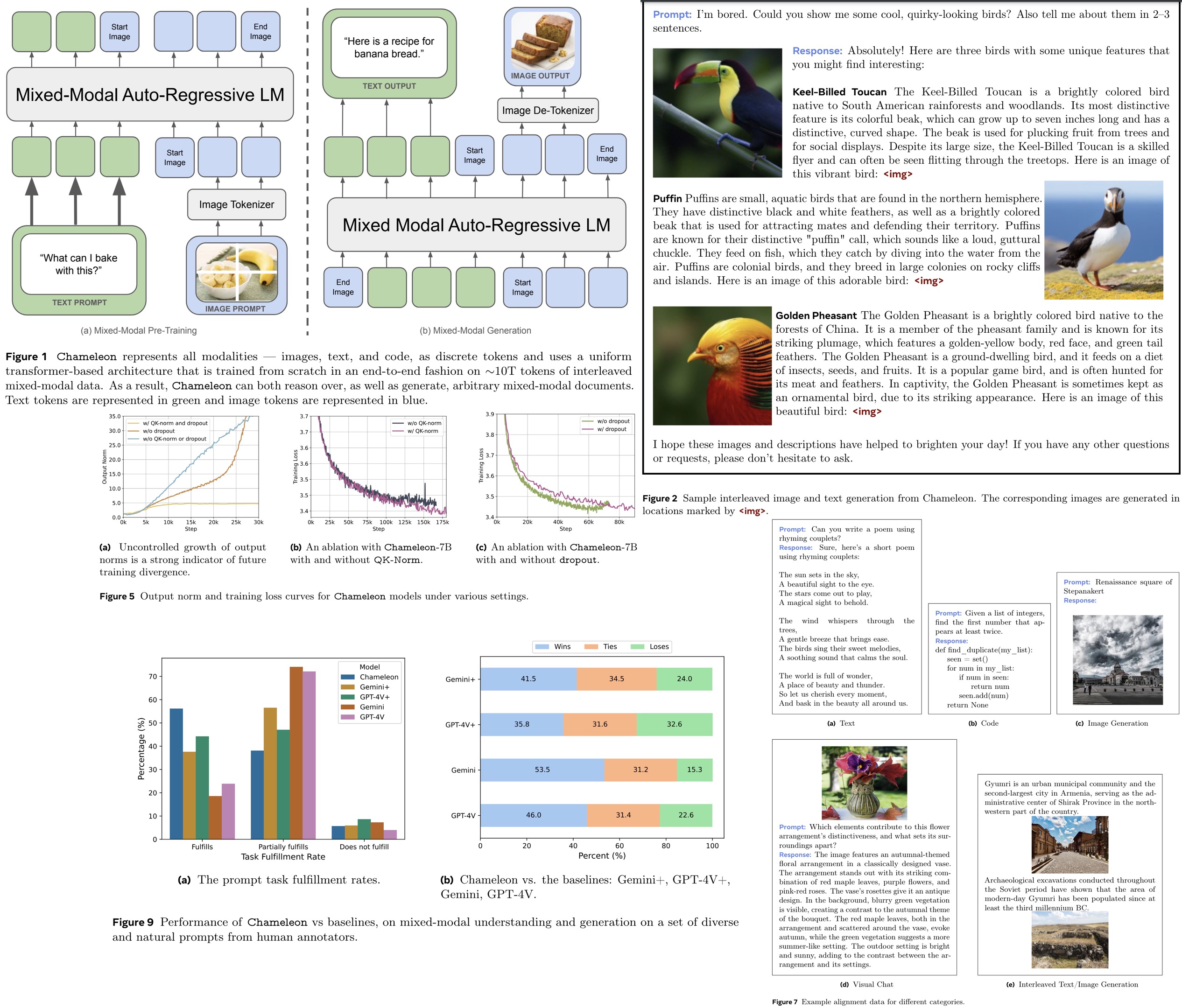
Scaling the Chameleon models beyond 8 billion parameters and 1 trillion tokens proved challenging due to stability issues that typically surfaced late in training. The authors share their recipe for architecture and optimization to achieve stability.
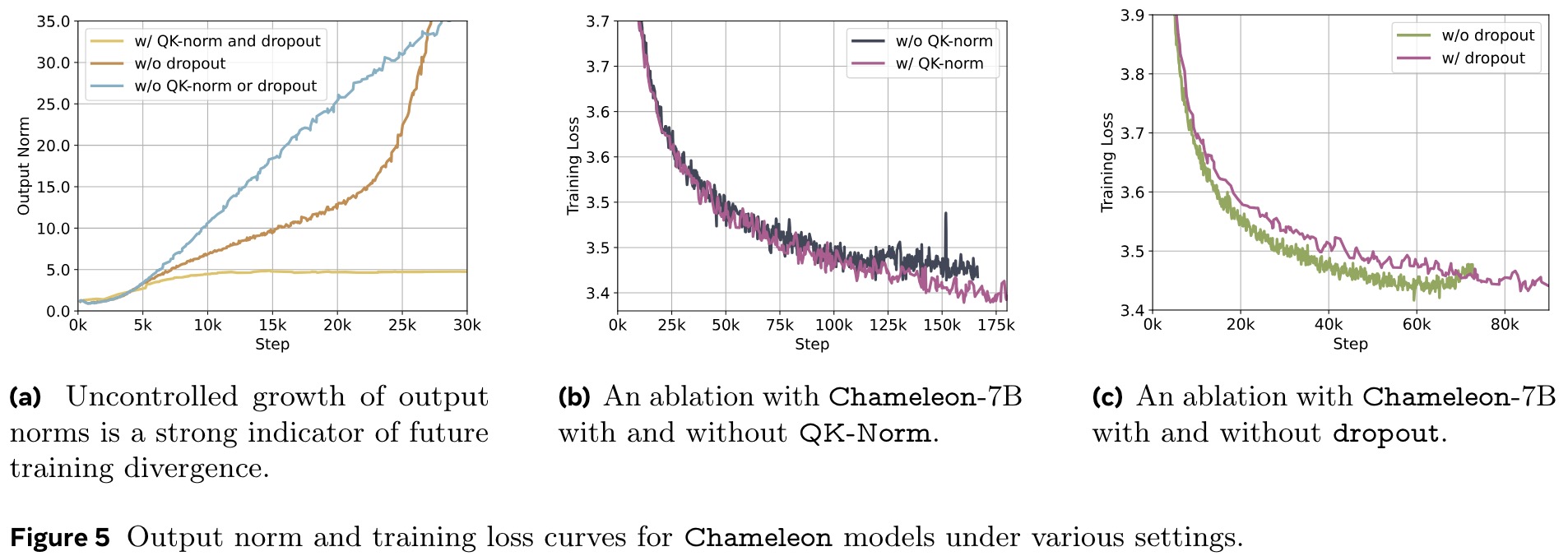
The architecture of Chameleon is largely based on LLaMa-2, incorporating RMSNorm for normalization, the SwiGLU activation function, and rotary positional embeddings. However, the standard LLaMa architecture exhibited instability due to slow norm growth in the mid-to-late stages of training, particularly because the softmax operation struggled with the varying entropy of different modalities. This resulted in complex divergences and norm growth outside the effective representation range of bf16. This issue, also known as the logit drift problem, was addressed by incorporating query-key normalization QK-Norm, which applies layer norm to the query and key vectors within the attention mechanism to control norm growth.
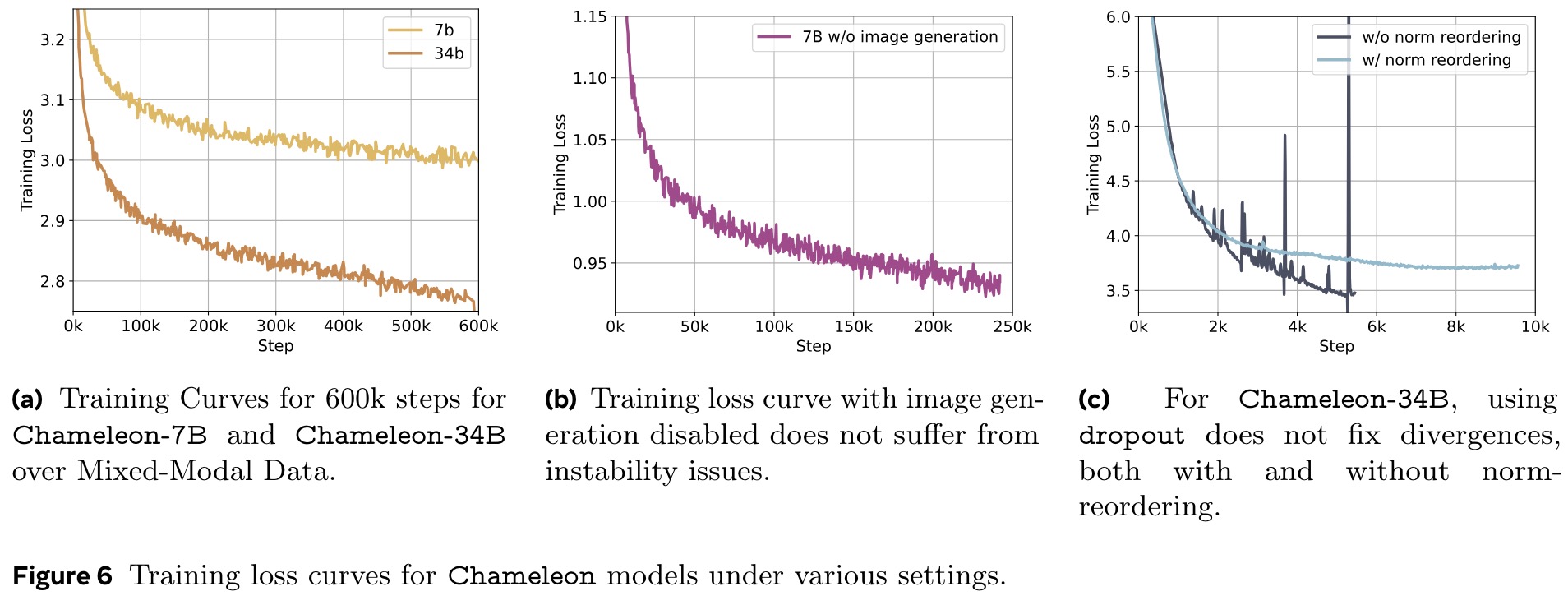
For Chameleon-7B, stability was achieved by using dropout after the attention and feed-forward layers, in addition to QK-Norm. However, Chameleon-34B required an additional reordering of normalization within the transformer block (applied normalization before the attention and feed-forward layers instead of after). This reordering helped bound the norm growth in the feed-forward block, which was problematic due to the multiplicative nature of the SwiGLU activation function.

Optimization involved the AdamW optimizer, a linear warm-up, an exponential decay schedule for the learning rate, gradient clipping and z-loss regularization.
Pre-training was conducted on Meta’s Research Super Cluster with NVIDIA A100 80 GB GPUs and NVIDIA Quantum InfiniBand for interconnect technology. Alignment was performed on internal research clusters with Elastic Fabric technology.
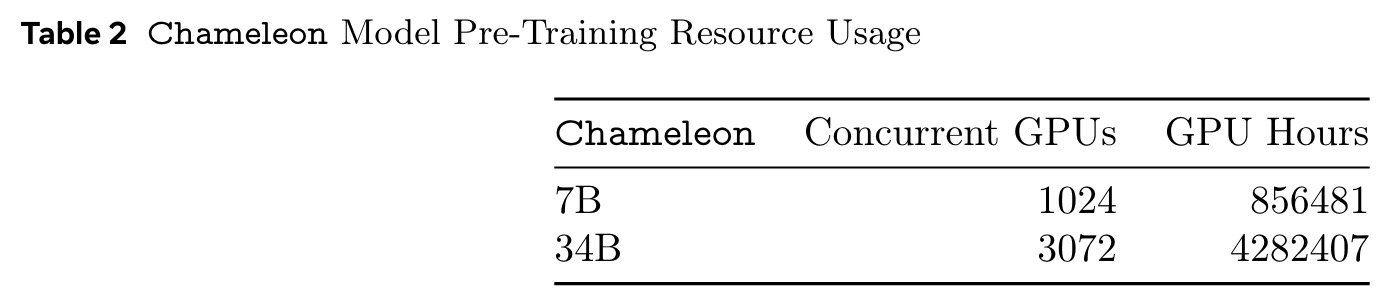
Inference
To support both automated and human alignment and evaluation, and to showcase the practical readiness of the approach, the authors have enhanced the inference strategy for interleaved generation, aiming to boost throughput and minimize latency. Autoregressive mixed-modal generation presents distinct performance challenges during inference, such as data dependencies at each step, modality-constrained generation masking, and fixed-sized text units for token-based image generation.
To address these challenges, the authors developed a dedicated inference pipeline based on PyTorch, utilizing GPU kernels from xformers. This pipeline supports streaming generation for both text and images, which involves token-dependent conditional logic at each generation step. When not streaming, image tokens can be generated in blocks without conditional computation, simplifying the process. Token masking helps eliminate branching on the GPU, ensuring efficient operation. However, even in non-streaming mode, generating text requires inspecting each output token for potential image-start tokens to apply image-specific decoding adjustments.
Alignment

To enhance the alignment and evaluation of the Chameleon models, a lightweight supervised fine-tuning stage was implemented using carefully curated, high-quality datasets. This stage is designed to both demonstrate the model’s capabilities and improve its safety. The SFT datasets are divided into several categories: Text, Code, Visual Chat, Image Generation, Interleaved Text/Image Generation, and Safety.
The Text SFT dataset is inherited from LLaMa-2, while the Code SFT dataset comes from CodeLLaMa. For the Image Generation SFT dataset, highly aesthetic images were selected and filtered from licensed data using an aesthetic classifier. Images rated at least six by the classifier were chosen, and from these, the top 64000 images closest in size and aspect ratio to 512 × 512 pixels were selected.
The Safety dataset comprises prompts designed to provoke potentially unsafe content, paired with refusal responses like “I can’t help with that.” These prompts span a wide range of sensitive topics, including violence, controlled substances, privacy, and sexual content. The safety tuning data includes examples from LLaMa-2-Chat, synthetic examples generated with Rainbow Teaming, manually selected prompts for image generation from Pick-A-Pic, examples for cybersecurity safety, and mixed-modal prompts collected internally. This mixed-modal data is crucial as it addresses potential multi-modal attack vectors, which are not covered by text-only and text-to-image safety tuning datasets.
During the fine-tuning stage, balancing the different modalities was crucial to ensure high-quality alignment. An imbalance could lead to the model developing an unconditional bias towards a particular modality, either muting or exaggerating its generation. Each instance in the dataset consisted of a paired prompt and its corresponding answer. To enhance efficiency, multiple prompts and answers were packed into each sequence, separated by a distinct token.
Human Evaluations and Safety Testing
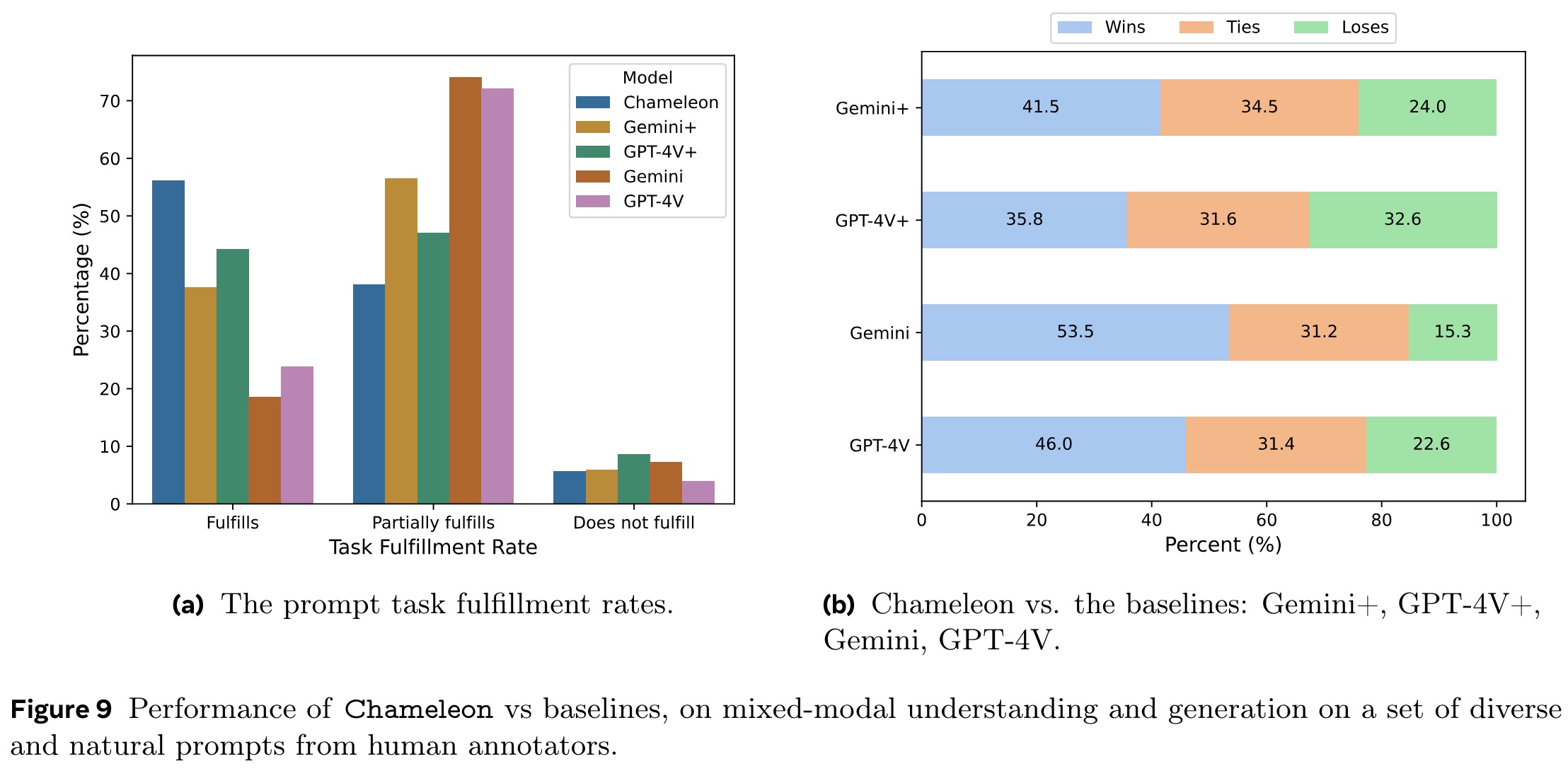
Chameleon exhibits significant advancements in mixed-modal understanding and generation, which cannot be fully assessed using existing benchmarks. To address this, the authors conducted human evaluations on the responses of large multi-modal language models to a diverse set of prompts that regular users might ask daily.
Prompt Collection for Evaluation
They collaborated with a third-party crowdsourcing vendor to gather a diverse set of natural prompts from human annotators. Annotators were asked to imagine various real-life scenarios and create prompts for a multi-modal model. For instance, in a kitchen scenario, prompts might include “How to cook pasta?” or “How should I design the layout of my island? Show me some examples.” These prompts could be text-only or include both text and images, with expected mixed-modal responses.
To ensure clarity and relevance, three random annotators reviewed each prompt to determine if the prompts were clear and whether mixed-modal responses were expected. Using a majority vote, unclear prompts or those not requiring mixed-modal responses were filtered out. The final evaluation set comprised 1,048 prompts, with 42.1% being mixed-modal and 57.9% text-only. These prompts were manually classified into 12 categories to better understand the tasks users want multi-modal AI systems to perform.
Baselines and Evaluation Methods
Chameleon 34B is compared with OpenAI GPT-4V and Google Gemini Pro using their APIs. While these models accept mixed-modal prompts, their responses are text-only. To create stronger baselines, GPT-4V and Gemini responses were augmented with images. These models were instructed to generate image captions by adding specific instructions to the prompts, then used OpenAI DALL-E 3 to generate images based on these captions. The augmented responses were labeled GPT-4V+ and Gemini+.
Absolute Evaluation
In absolute evaluations, three annotators independently judged each model’s output on its relevance and quality. Chameleon’s responses were found to fully fulfill 55.2% of tasks, compared to 37.6% for Gemini+ and 44.7% for GPT-4V+. The original text-only responses of Gemini and GPT-4V fully fulfilled only 17.6% and 23.1% of tasks, respectively, likely because the prompts expected mixed-modal outputs. Chameleon performed particularly well in categories like Brainstorming, Comparison, and Hypothetical tasks, but needed improvement in Identification and Reasoning tasks.
Relative Evaluation
In relative evaluations, annotators compared Chameleon’s responses directly with those of the baseline models in random order. Overall, Chameleon had win rates of 60.4% and 51.6% over Gemini+ and GPT-4V+, respectively.
Safety Testing
The authors conducted a safety study by crowdsourcing prompts designed to provoke unsafe content, covering categories such as self-harm, violence, and criminal planning. The model’s responses were labeled for safety, with an “unsure” option for borderline cases. The overwhelming majority of Chameleon’s responses were safe, with only 0.39% unsafe responses for the 7B model and 0.095% for the 30B model. An internal red team also tested the 30B model with adversarial prompts, resulting in 1.6% unsafe and 4.5% unsure responses.
Discussion
Chameleon shows strong performance in handling mixed-modal prompts, generating contextually relevant images that enhance the user experience. However, the limitations of human evaluation include the artificial nature of crowdsourced prompts and the focus on mixed-modal output, which may exclude certain visual understanding tasks.
Benchmark Evaluations
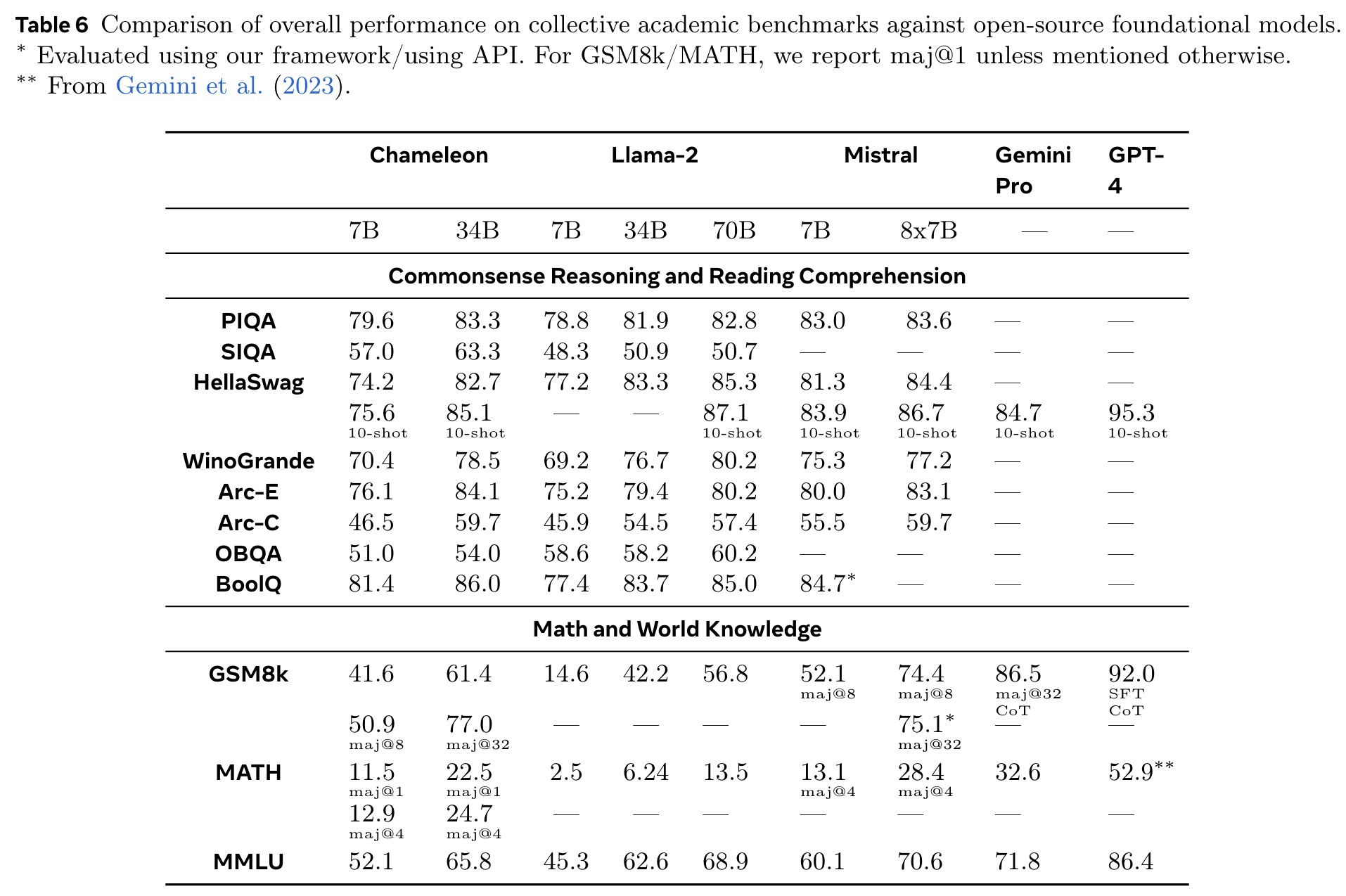
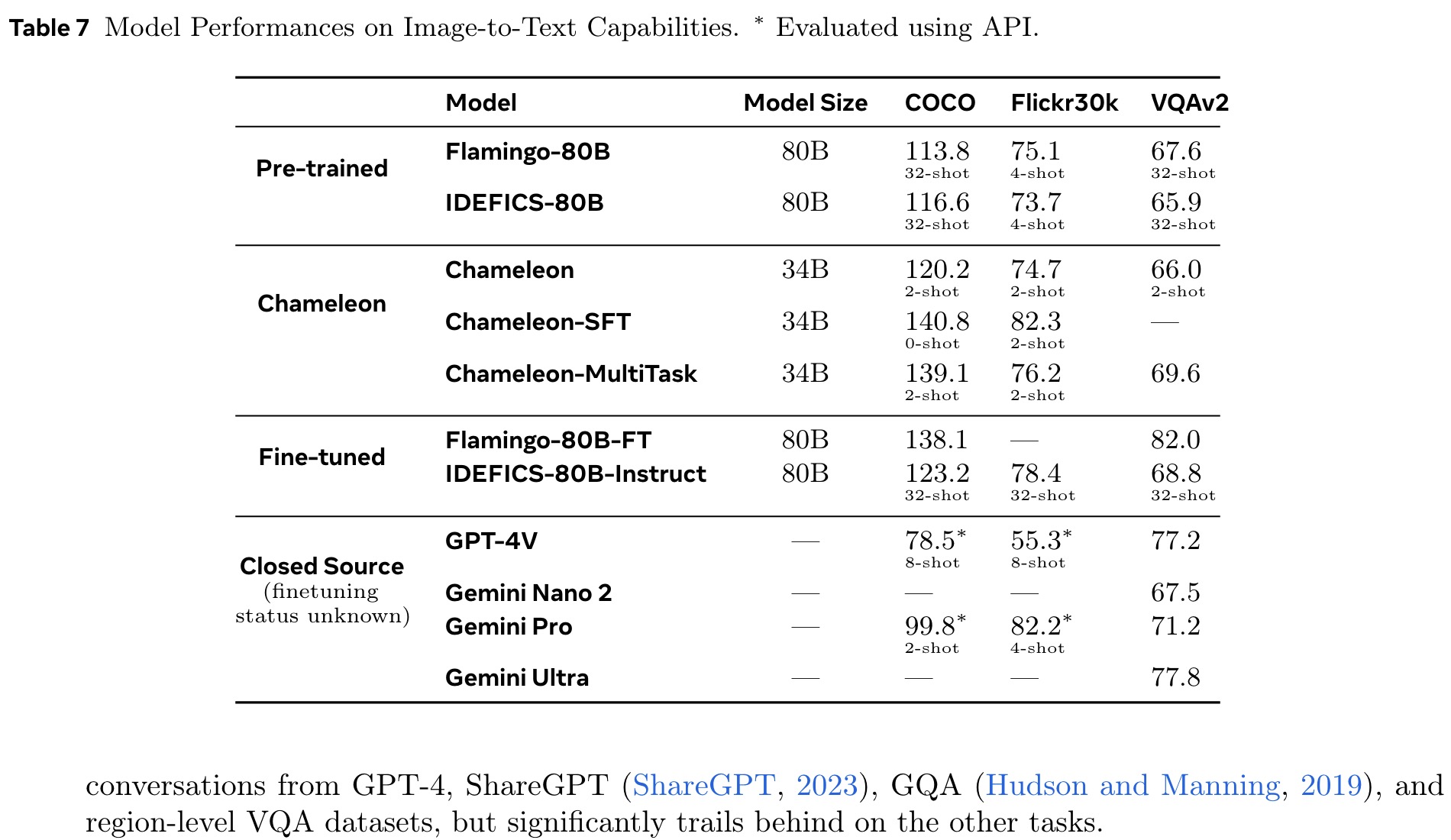
Chameleon outperforms LLaMa-2 in text tasks, with performance approaching Mistral 7B/Mixtral 8x7B on some of them. It is also competitive on both image captioning and VQA tasks. It rivals other models by using much fewer in-context training examples and with smaller model sizes, in both pre-trained and fine-tuned model evaluations.
paperreview deeplearning mllm multimodal

