Paper Review: Chronos: Learning the Language of Time Series
Chronos is a framework for pretraining probabilistic models on time series data by tokenizing these values for use with transformer-based models like T5. It achieves this through scaling and quantization into a fixed vocabulary and is trained on both public and synthetic datasets created via Gaussian processes. With models ranging from 20M to 710M parameters, Chronos models outperform traditional and deep learning models on seen datasets and show competitive to superior zero-shot performance on new datasets.
The approach
Tokenization
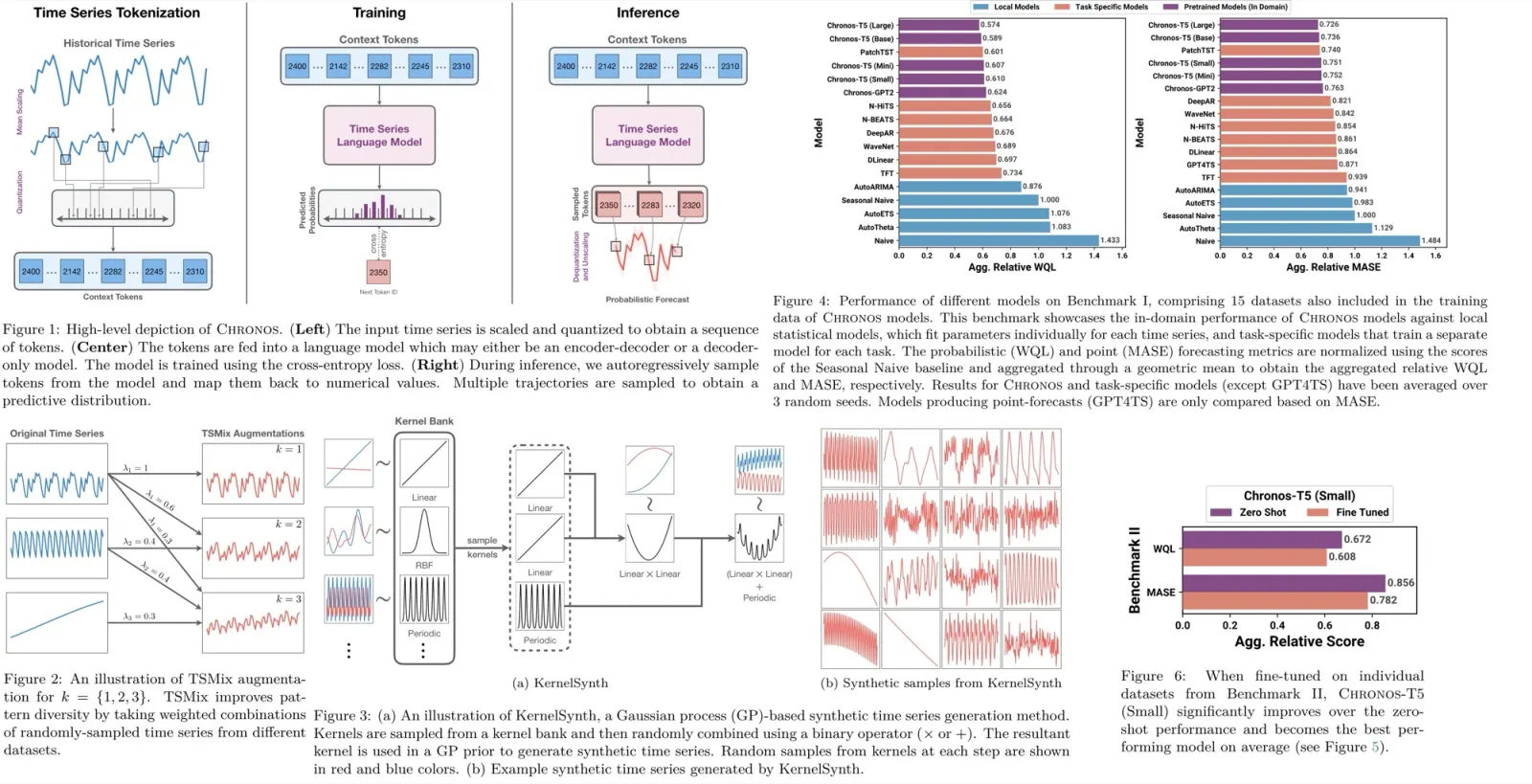
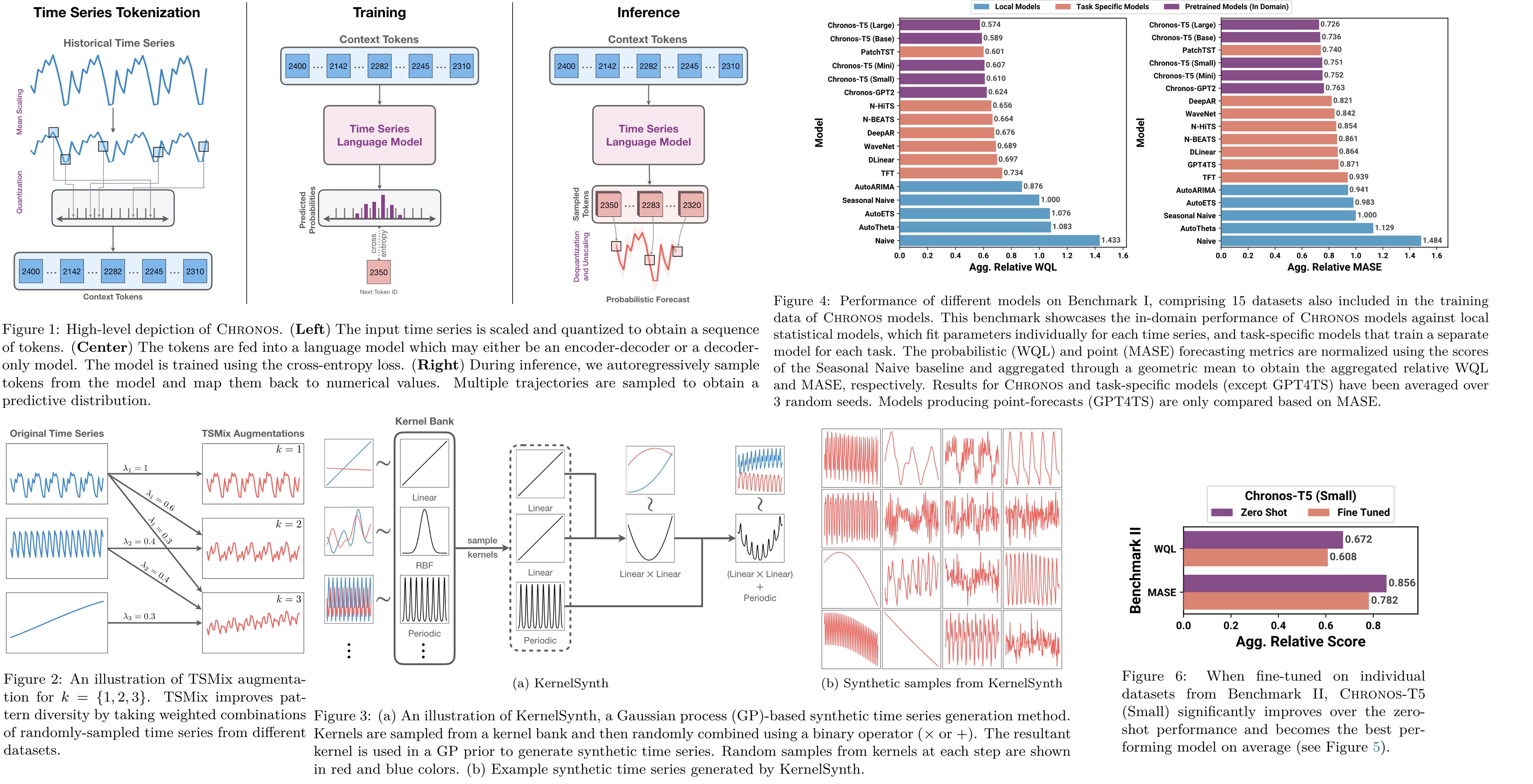
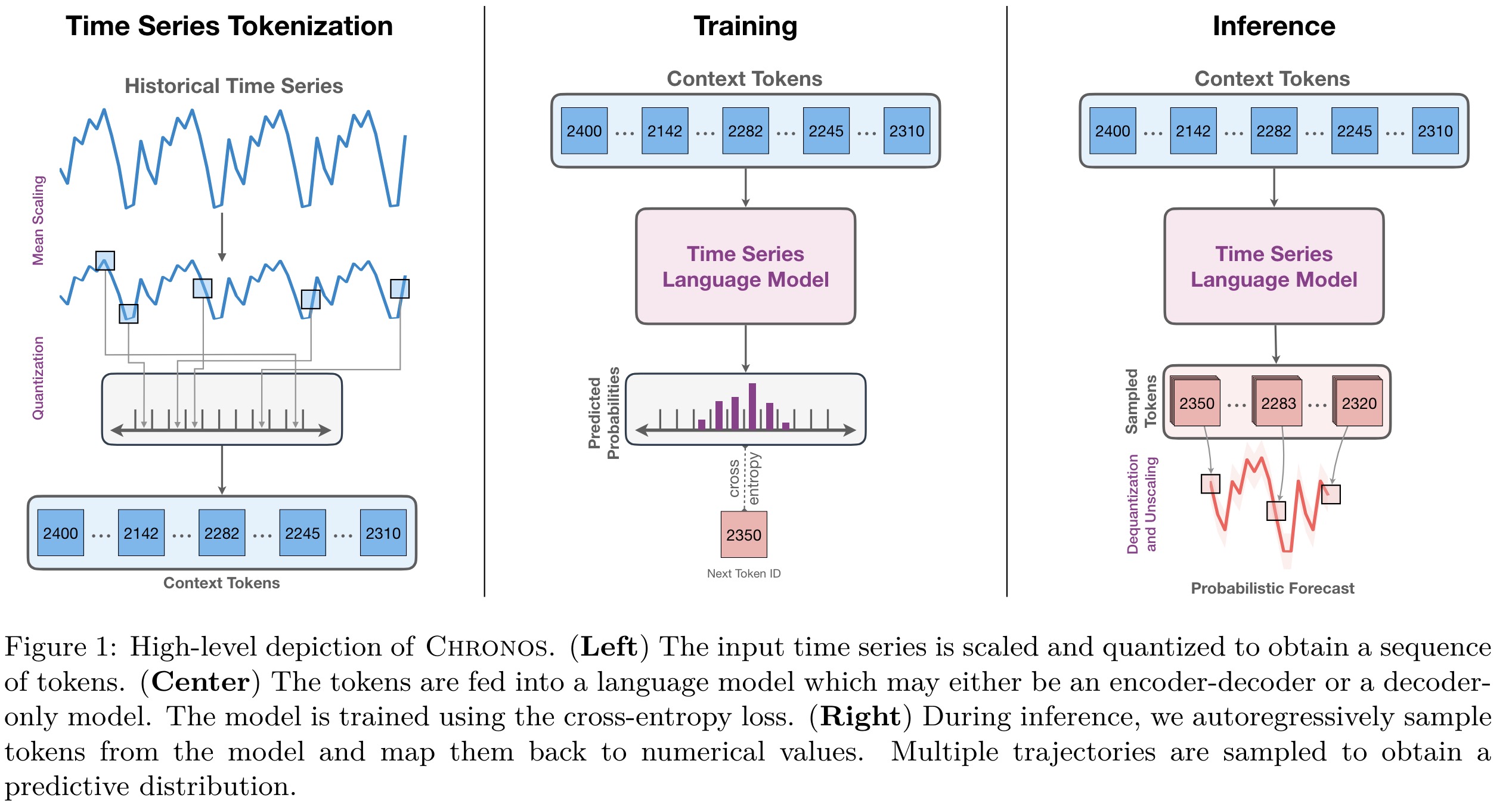
To adapt time series data for transformer-based language models, two steps are used: scaling and quantizing. Scaling normalizes the data to a common range using mean scaling, where each point is adjusted by the mean of the absolute values in the historical context. Following scaling, quantization transforms the real-valued series into discrete tokens by dividing the data range into bins, each represented by a token. The authors prefer the uniform binning over quantile binning, aiming to accommodate the variability across different datasets. A possible limitation is that the prediction range is restricted by the predefined min and max values of the bins. Additionally, special tokens for padding and sequence ending are added.
Objective Function
Chronos is trained on time series data by treating forecasting as a classification problem, using a categorical cross-entropy loss function. The model predicts a distribution over a tokenized vocabulary representing quantized time series data and minimizes the discrepancy between this distribution and the true distribution of the ground truth. Unlike distance-aware metrics, this approach doesn’t directly account for the proximity between bins, relying on the model to learn bin relationships from the data. It offers two advantages: seamless integration with existing language model architectures and training methods, and the ability to learn arbitrary, potentially multimodal output distributions, making it versatile across different domains without necessitating changes to the model structure or training objective.
Chronos models generate probabilistic forecasts by autoregressively sampling from their predicted token distributions for future time steps. The resulting tokens are then converted back to real values using a dequantization function and inverse scaling.
Data Augmentation
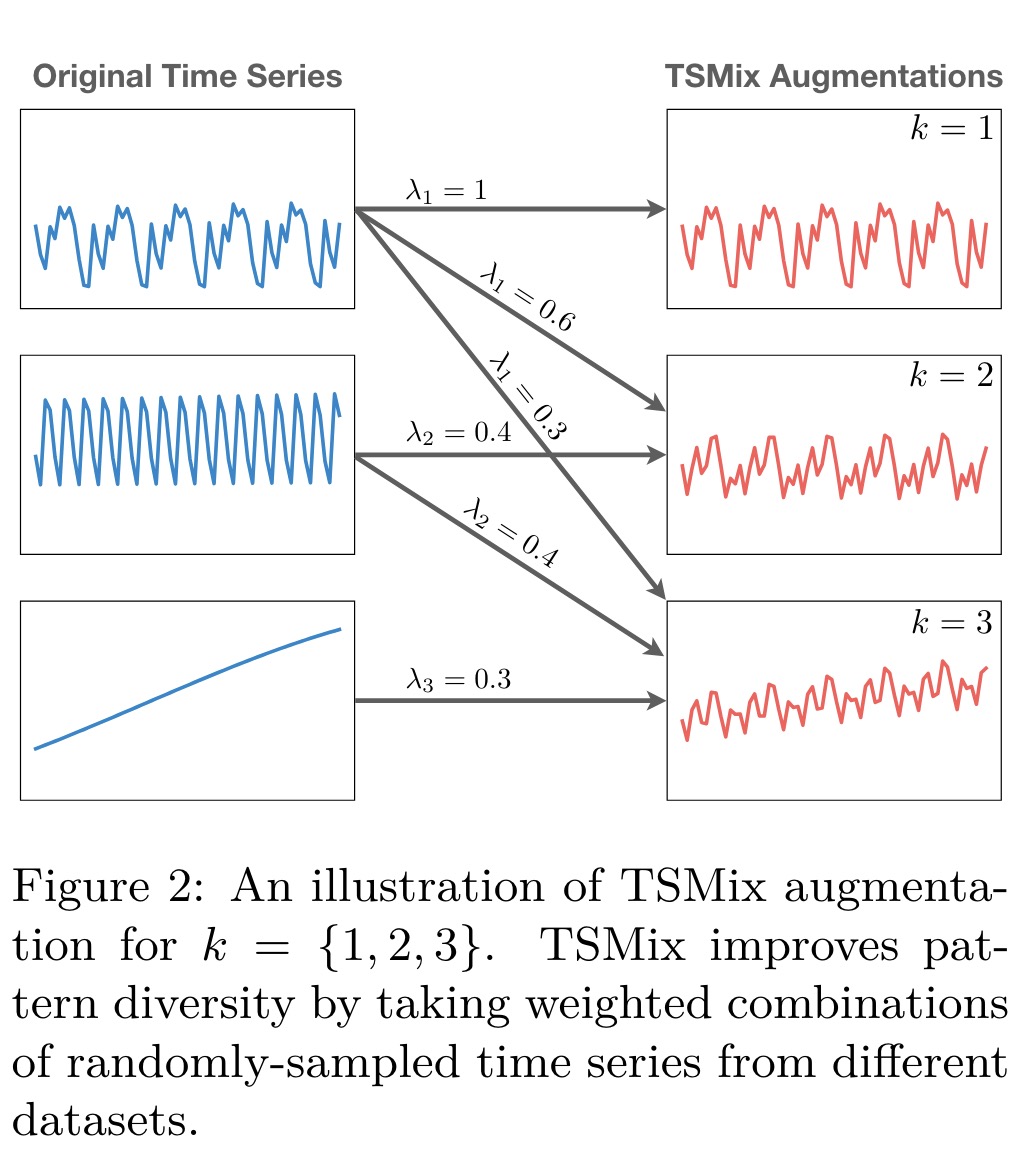
TSMix: Time Series Mixup. TSMix extends the Mixup data augmentation concept, originally developed for image classification, to time series data by combining more than two data points. It randomly selects a number of time series of varying lengths from the training dataset, scales them, and creates their convex combination. The weights for this combination are drawn from a symmetric Dirichlet distribution.
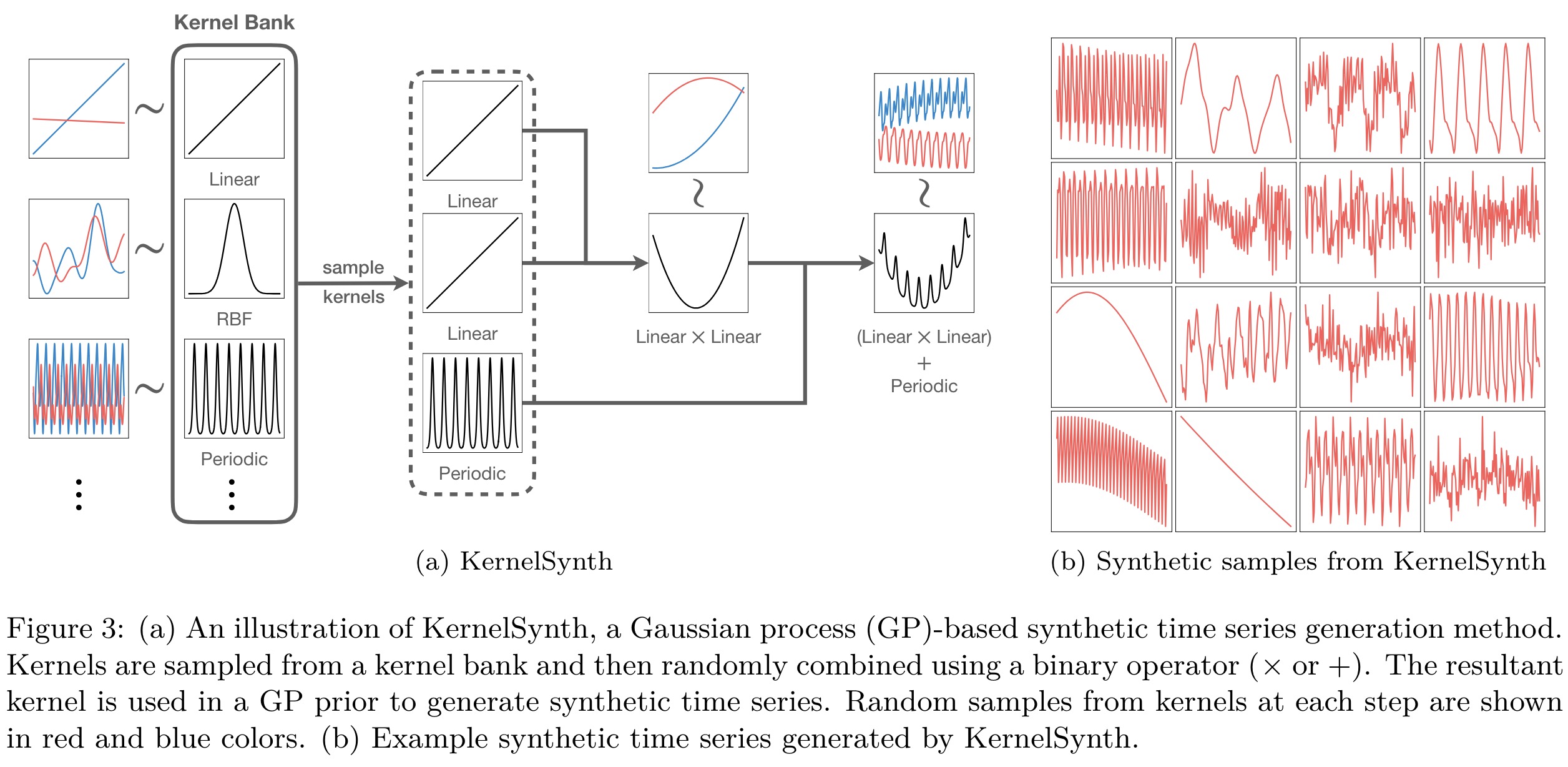
KernelSynth: Synthetic Data Generation using Gaussian Processes. KernelSynth is a method designed to generate synthetic time series data using Gaussian processes. KernelSynth assembles GP kernels to create new time series, leveraging a bank of basis kernels for common time series patterns like trends, smooth variations, and seasonalities. By randomly selecting and combining these kernels through addition or multiplication, it produces diverse time series data.
Experiments
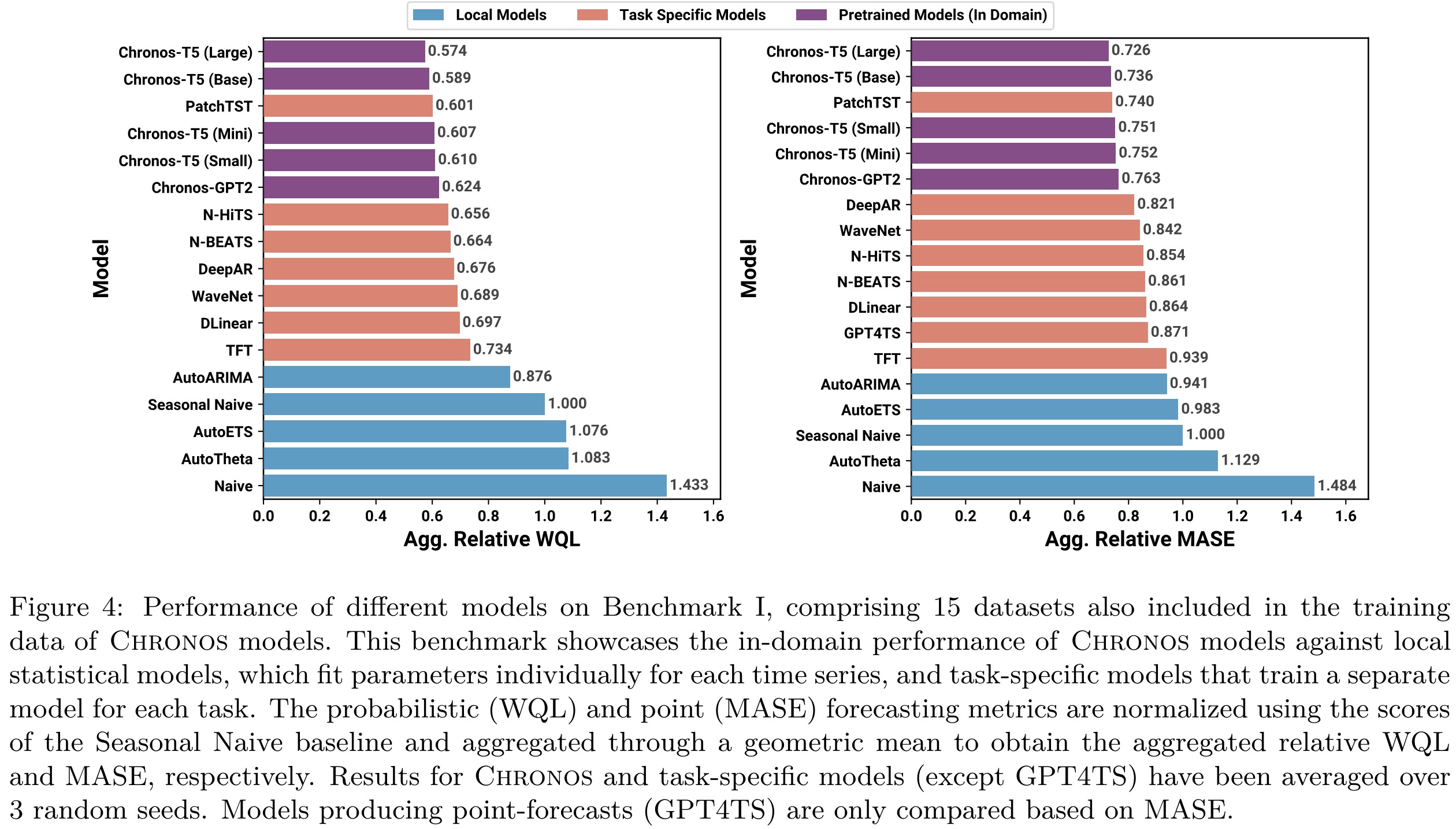
In-domain results. The larger Chronos-T5 models (Base and Large) significantly outshine the baselines, showcasing superior probabilistic and point forecasting abilities. These models surpass not only local statistical models like AutoETS and AutoARIMA but also task-specific deep learning models such as PatchTST and DeepAR. Smaller Chronos variants and Chronos-GPT2 also outperform most baselines, though PatchTST shows stronger results in some cases. The competitive performance of the Seasonal Naive model indicates that these datasets, predominantly from energy and transport sectors, have strong seasonal trends.
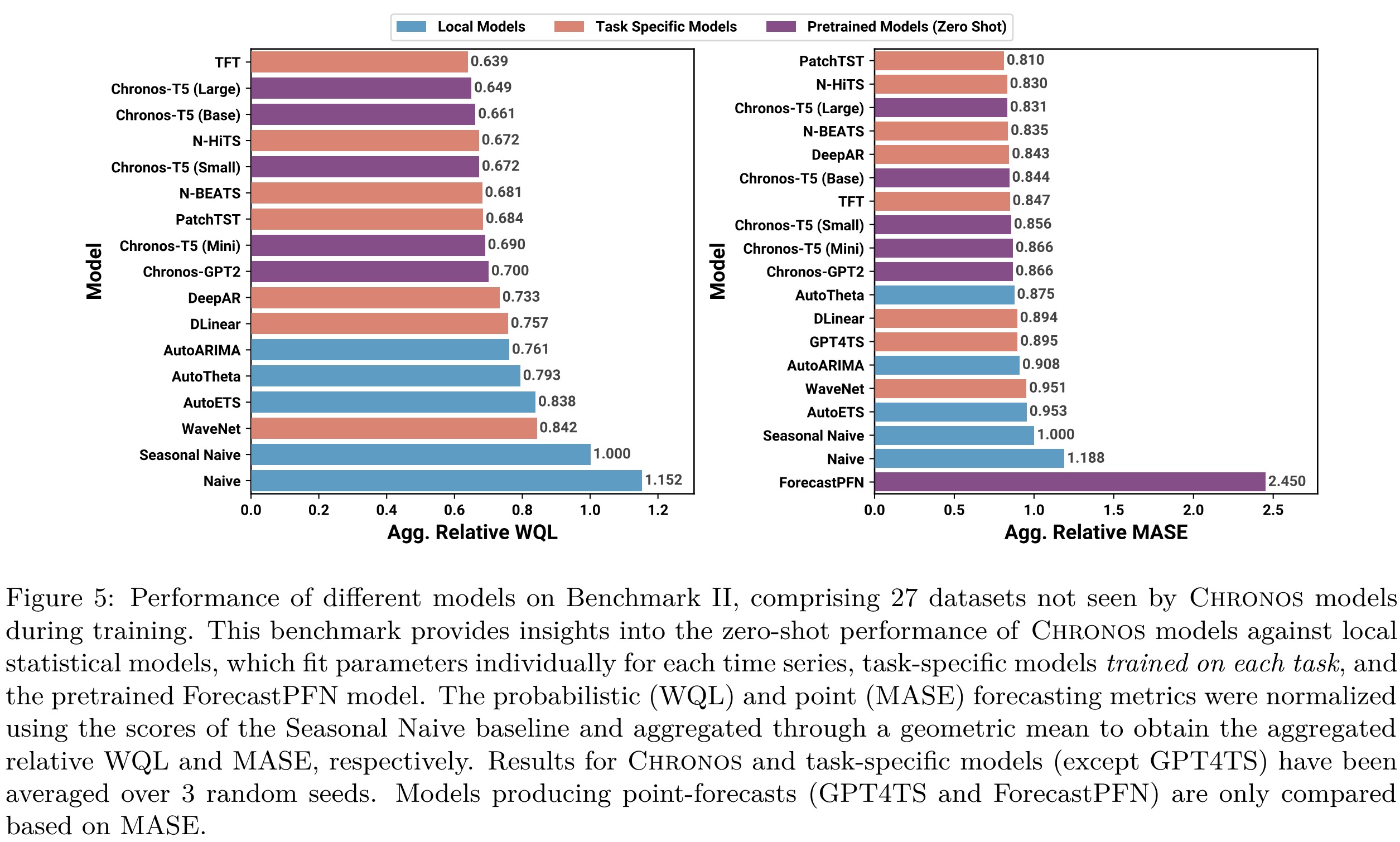
Zero-shot Results. Chronos models surpass local statistical models and most task-specific models in probabilistic forecasting, with the Chronos-T5 Large model ranking third in point forecasting. They even outperform ForecastPFN (zero-shot forecaster) and GPT4TS (fine-tuned GPT2), showing notable promise as generalist time series forecasters.
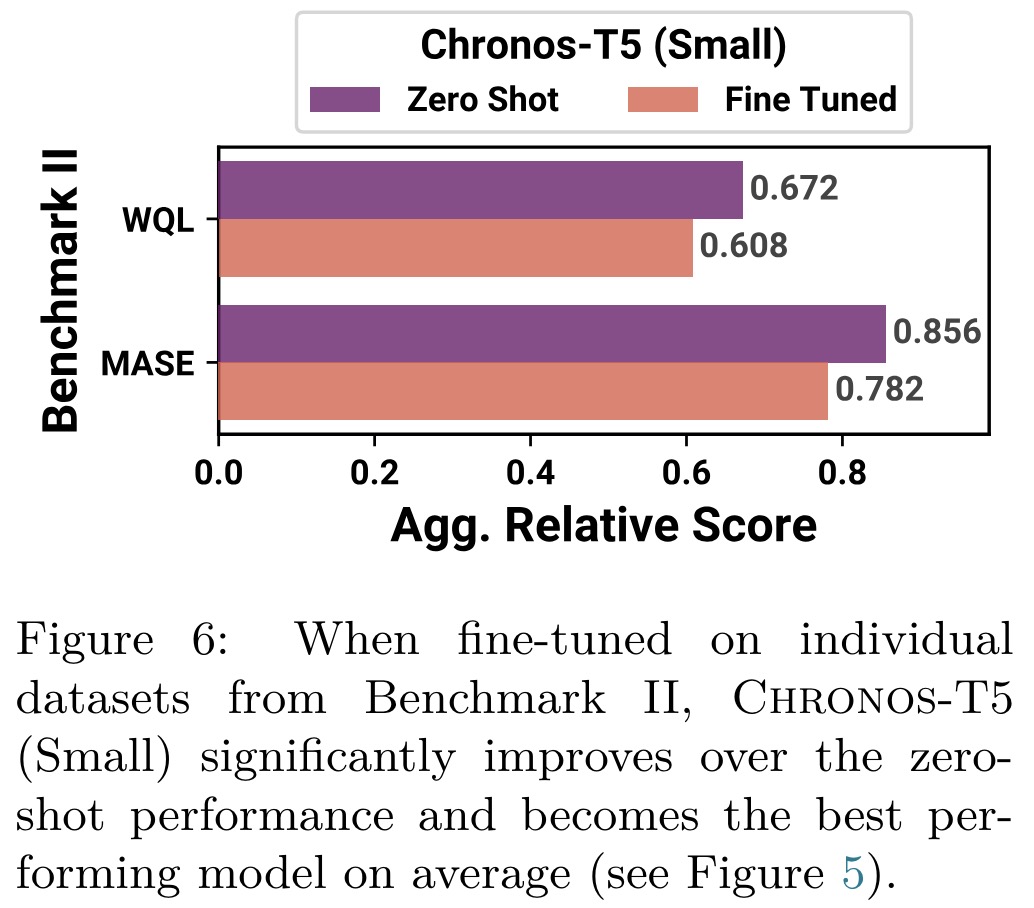
Fine-tuning small model demonstrated significant performance improvements, leading it to outperform both larger Chronos variants in a zero-shot setting and the best task-specific models.
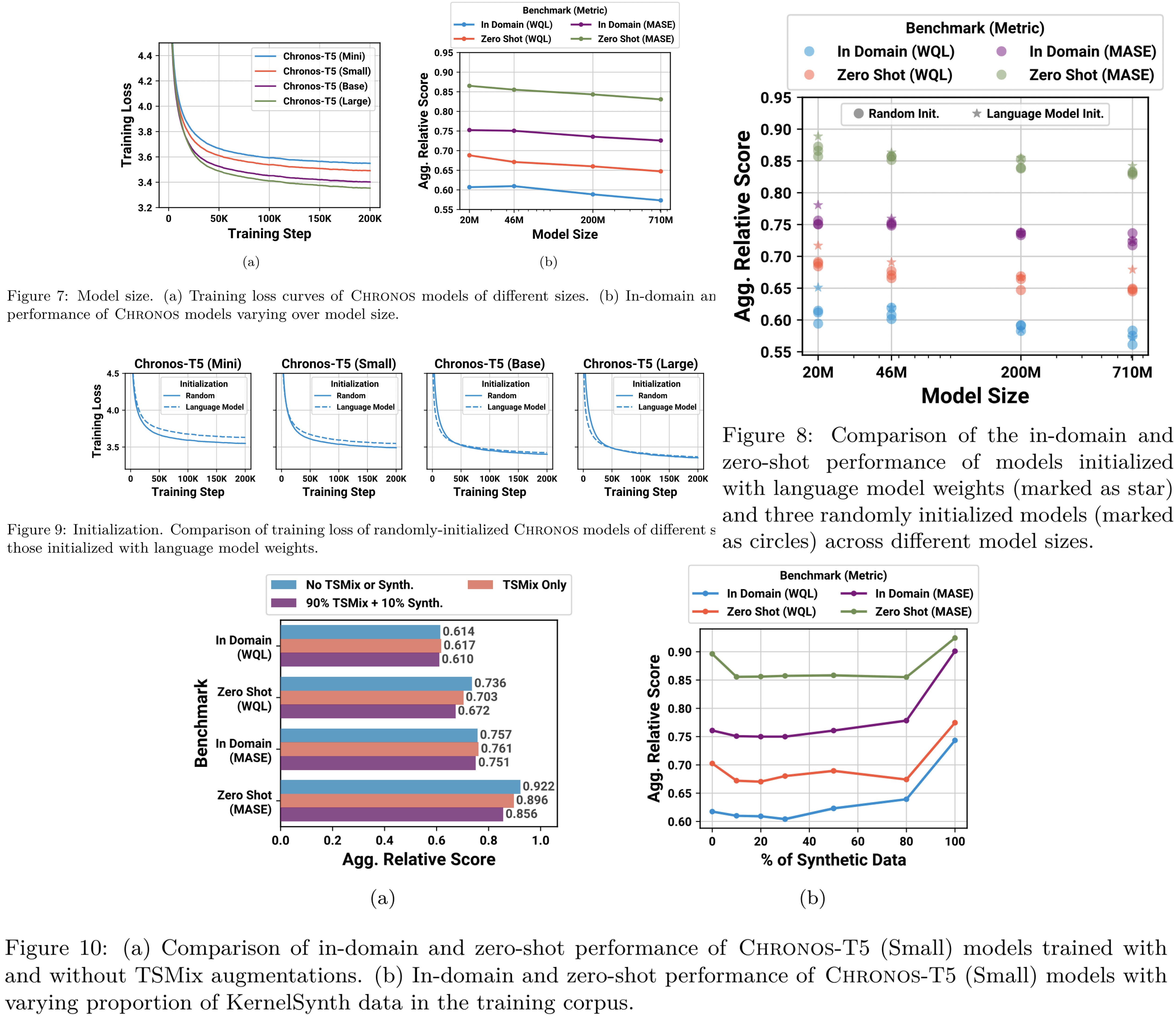
Ablations:
- Unsurprisingly, larger models are better;
- Random weight initializing is better than using LLM weights, as they may be not relevant for time-forecasting;
- TSMix improved zero-shot learning, but not in-domain;
- It is optimal to use around 10% of synthetic data;
Discussions
The research demonstrates Chronos’s capability in zero-shot forecasting across various datasets, suggesting its potential for outperforming task-specific models through fine-tuning techniques like low-rank adapters or conformal methods for task-specific calibration. Task-specific adaptors or stacking ensembles with models like LightGBM can be used to add covariates and apply to multivariate forecasting.
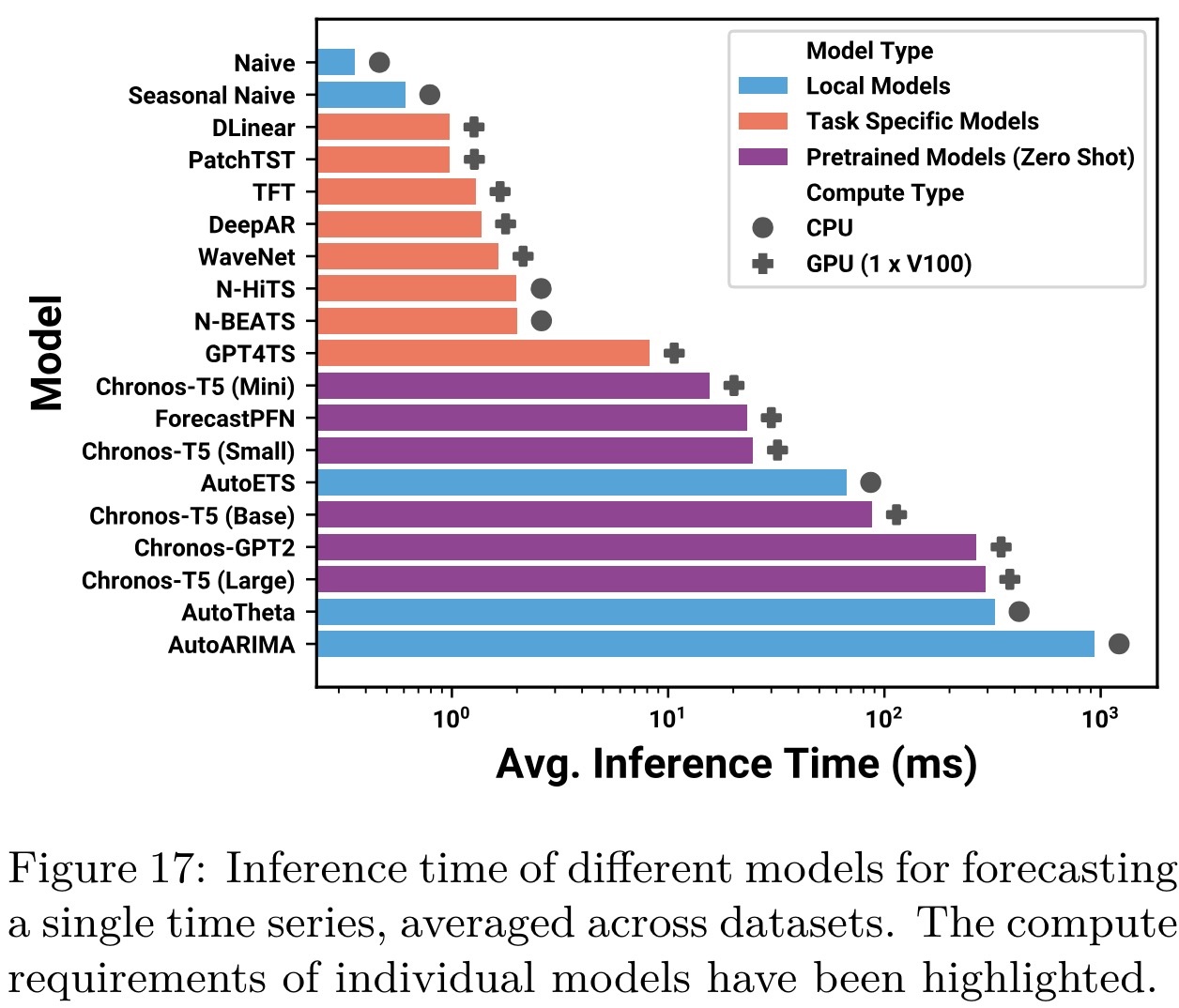
The inference speed of larger Chronos models is slower compared to task-specific deep learning models but not significantly enough to hinder practical deployment. The advantage of Chronos models lies in their versatility across various dataset characteristics without the need for individual task-specific training, streamlining forecasting pipelines. Additionally, techniques such as optimized computing kernels, quantization, and faster decoding methods, are applicable to Chronos, potentially improving inference speed and forecast quality. Approaches to handling long-context data could further enhance Chronos’s performance with high-frequency datasets, and NLP-inspired methods like temperature tuning and sampling strategies could improve the efficiency and accuracy of forecasts.
paperreview deeplearning llm timeseries