Paper Review: Collaborative Large Language Model for Recommender Systems
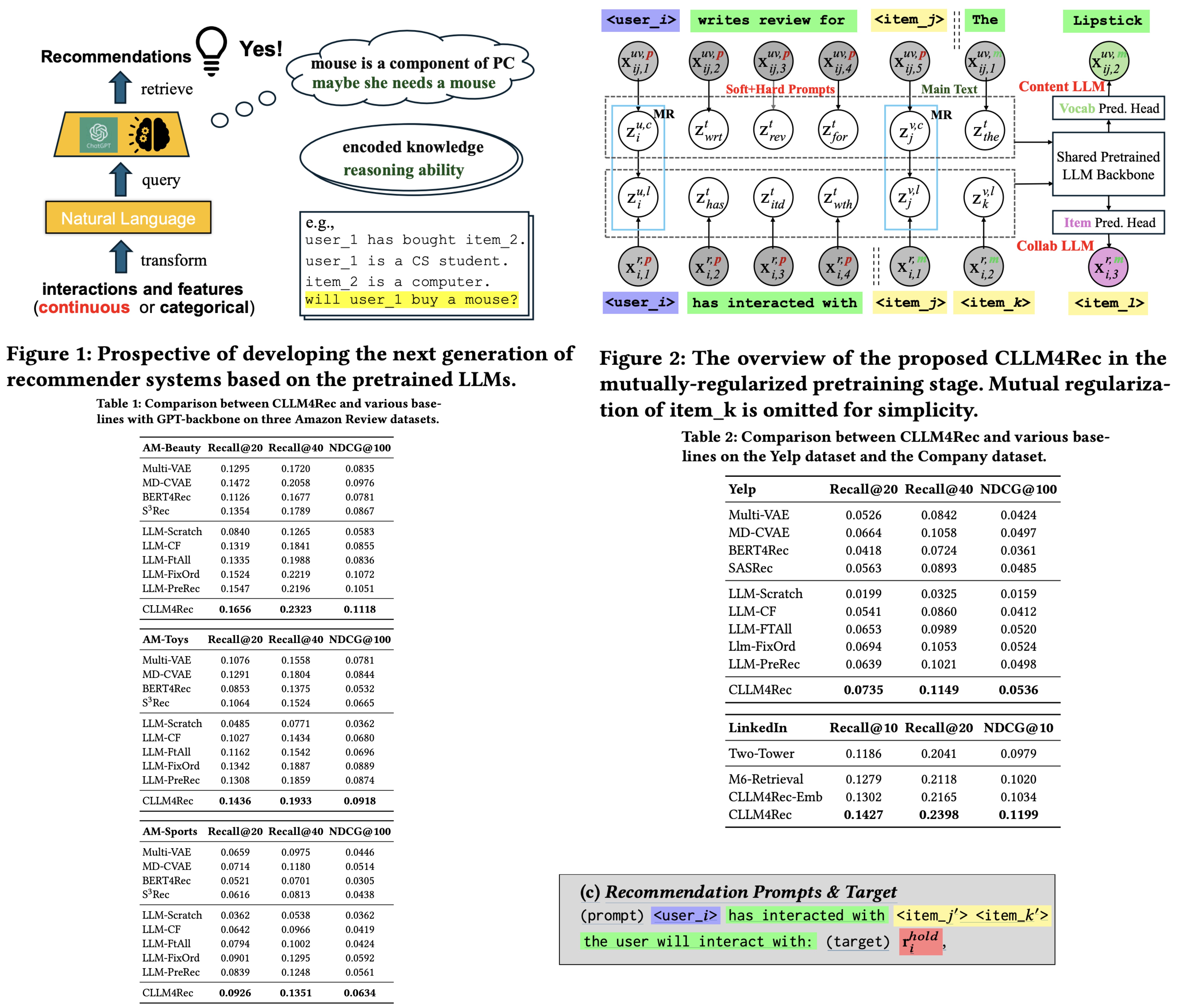
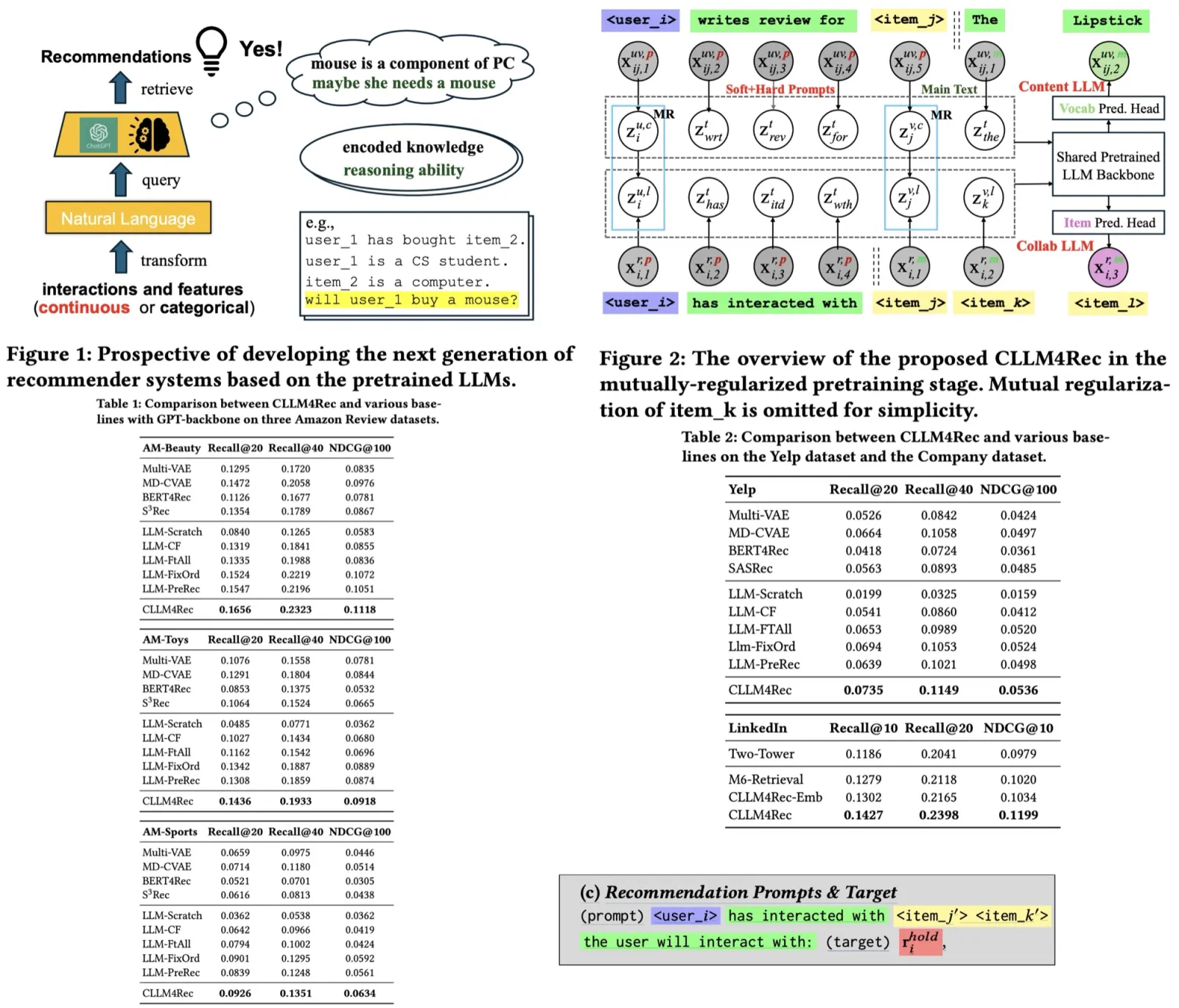
CLLM4Rec is a new generative recommendation system that merges the capabilities of pretrained large language models with traditional recommender systems. It tackles common issues like spuriously-correlated user/item descriptors, ineffective language modeling on user/item contents, and inefficient recommendations via auto-regression, by extending the vocabulary of language models to include user and item IDs, ensuring more accurate user-item interaction modeling. During pretraining, it employs a novel soft+hard prompting method, using a mix of user/item and vocabulary tokens to enhance language modeling on recommendation-specific data. Additionally, a mutual regularization strategy helps the system to learn from user and item content more effectively. For fine-tuning, CLLM4Rec adds an item prediction head, enabling efficient generation of multiple item recommendations using prompts derived from masked user-item interaction histories.
Methodology
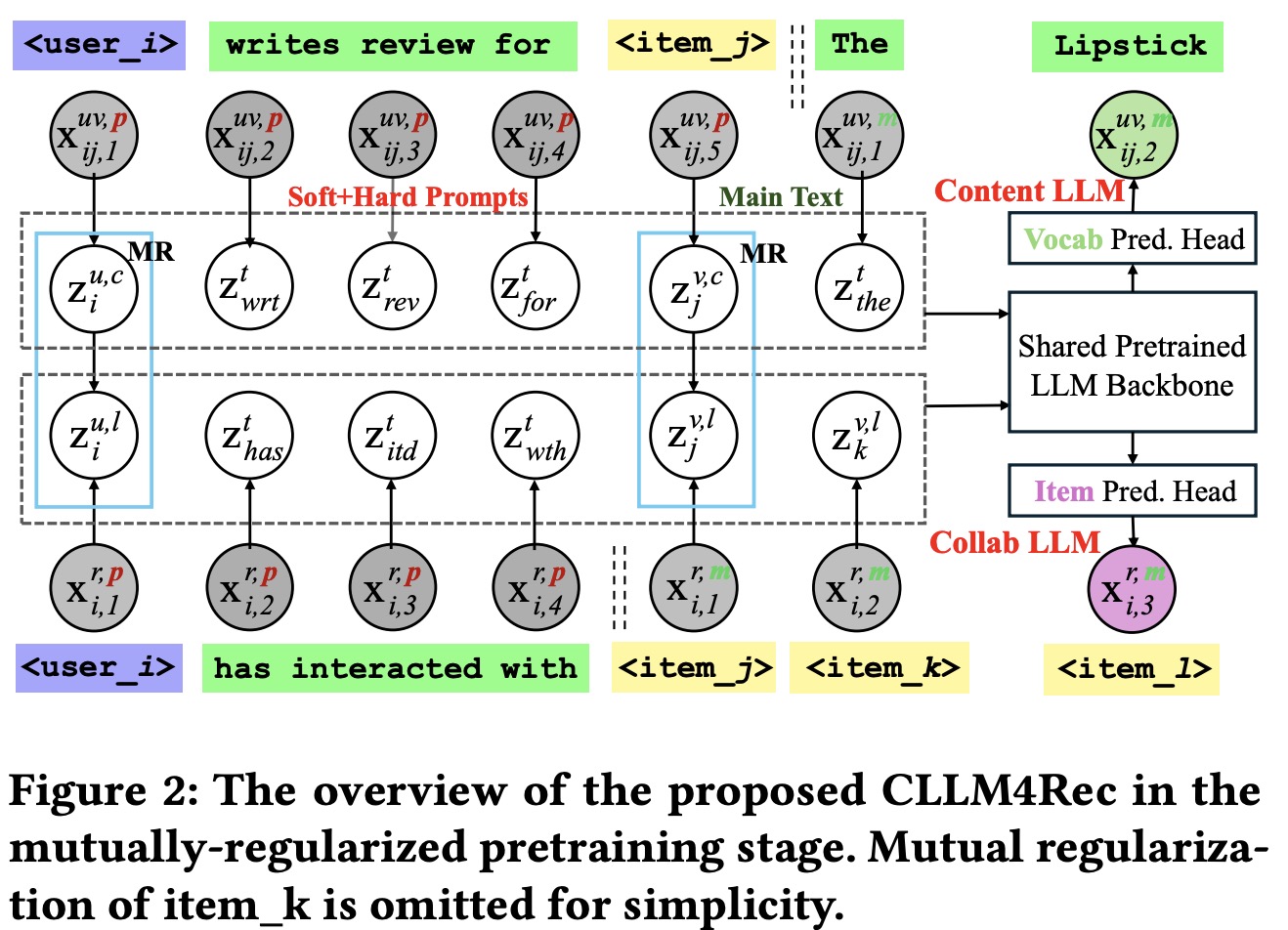
The focus is on designing a recommendation system that uses implicit feedback from users, such as whether they have interacted with items, represented by binary rating vectors. Textual features of users and items, like user bios or item descriptions, as well as user-item specific interactions like reviews, are encoded as one-hot vectors for tokens in textual sequences. A pretrained LLM is used to process these sequences, transforming them into latent sequences through self-attention modules.
Extension of User/Item Tokens
LLM is integrated with the recommendation system by expanding the LLM’s vocabulary to include special tokens <user_𝑖>and <item_𝑗> for users and items. These tokens are designed not to be broken down further. The embeddings for these tokens are generated to represent collaborative and content semantics. Collaborative token embeddings are sampled from a latent space of the same size as the LLM’s vocabulary embeddings, with a defined prior precision. Content token embeddings are then sampled conditionally based on the collaborative embeddings to align content semantics with collaborative semantics, which is crucial for content-oriented recommendation modeling.
CLLM4Rec incorporates these new user/item tokens and their embeddings into the LLM. This model uses self-attention modules to map token sequences into a hidden space, representing the input for either vocabulary, user, or item tokens. The CLLM4Rec model allows for the user/item token embeddings to be trainable while keeping the vocabulary embeddings and the rest of the LLM’s structure fixed. This ensures the preservation of the LLM’s prelearned knowledge while adapting the model for recommendation purposes.
Mutually-Regularized Pretraining

Recommendation-Specific Corpora. To integrate user behavior and item details into a language model for recommendations, data is usually turned into sequences that mix specific user and item identifiers with regular words. These sequences record which items a user has engaged with and include personal and product descriptions, as well as reviews. However, this approach faces a challenge because the added user and item identifiers, which start with no specific meaning, can overwhelm the language model’s existing vocabulary, making it harder for the model to learn effectively.

Soft+Hard Prompting. Soft+hard prompting strategy separates documents into a context-providing prompt consisting of user/item identifiers and regular vocabulary tokens, and a main text part with a uniform sequence of item/vocabulary tokens. The soft+hard prompt, which includes identifiers and some vocabulary tokens, serves as a context for the main text, allowing the model to concentrate on collaborative and content information. This is expected to improve the stability and effectiveness of language modeling.
In practical terms, the model includes an item prediction component that uses the last hidden representation to predict the probability of the next item token, aligning user and item embeddings to capture collaborative semantics. Similarly, for content generation, a vocabulary prediction head is added to the model to encode content information within token embeddings, thereby leveraging the pretrained knowledge of the language model. For instance, the model can understand a user’s preferences and the characteristics of an item, like a lipstick’s color and potential side effects, based on reviews.
The “hard” part of the prompts, which contains vocab tokens, helps trigger the reasoning capabilities of the pre-trained language model by using its existing knowledge. For instance, phrases like “has interacted with” signal to the collaborative language model that it should understand <user_i> as the user, and the following tokens as the items the user has interacted with. Similarly, the phrase “write the review for” in a different type of prompt helps the content language model comprehend that the main text will contain a user’s review of an item based on personal experience.
Mutually-Regularization. Mutually-regularized pretraining is designed to enhance recommendation systems by refining the pretraining of language models. It helps to filter out irrelevant noise and counteract overfitting caused by sparse data. This is achieved by having two types of language models, collaborative and content, which guide each other to focus on recommendation-specific information and incorporate auxiliary data for better filtering.
The method involves breaking down the joint distribution of the data into three parts: language modeling for both LLM types, mutual regularization to link the user/item embeddings, and a prior that is usually ignored due to mutual regularization. This approach uses conditional Gaussians for mutual regularization, leading to MSE regulation between the embeddings.
Stochastic Item Reordering. The order in which item tokens are presented in user interaction histories is not crucial for collaborative filtering, and natural language positional embeddings may not effectively capture the meaning of interaction order. To overcome this, it is proposed to randomly shuffle item tokens during the optimization of the collaborative language model, allowing the model to ignore the item order and prevent any negative impact on the processing of vocabulary tokens in user interactions.
Recommendation-Oriented Finetuning

Pretraining alone is not sufficient for bridging the gap between natural language processing and recommendation systems, and directly using CLLM4Rec for recommendations is computationally expensive. To address this, a recommendation-oriented finetuning strategy is proposed, which refines the pretraining model for efficient recommendation. This involves a masked prompting strategy where a portion of user-interacted items is masked to create prompts aimed at making recommendations. These prompts stimulate the model’s reasoning by relating past interactions to future predictions.
The finetuned model, called RecLLM, adopts the base CLLM4Rec model and adds a new item prediction head with a multinomial likelihood, which is also linked to the item token embeddings. This allows for generating recommendations in a single forward-propagation step. Finetuning includes a regularizing step that aligns the user’s latent variable with the collaborative embeddings of interacted items and uses stochastic item reordering to avoid overfitting to a specific item order
Predictions with CLLM4Rec
After the pretraining and finetuning processes of CLLM4Rec are completed, to make a recommendation for a user, the entire history of that user’s interactions is used to create a recommendation prompt. This prompt is then fed into the RecLLM model without masking any items. Through a single forward propagation in the model, a multinomial probability distribution over all items is calculated, which represents the likelihood of each item being of interest to the user. The model then selects the top-scoring items that the user has not yet interacted with as its recommendations.
Experiments
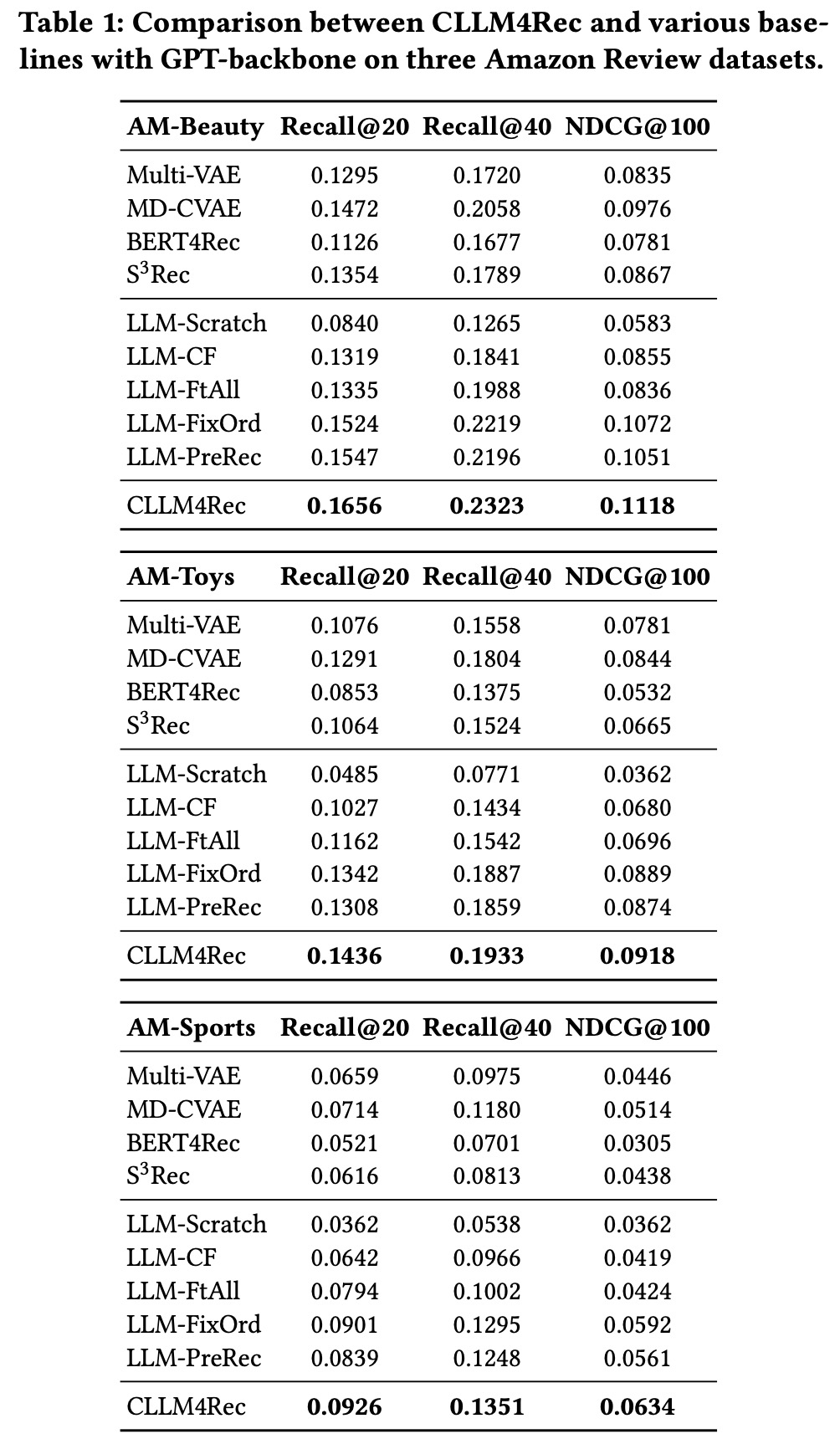
CLLM4Rec excels when large textual data is available due to CLLM4Rec’s ability to leverage the deep understanding from pretrained LLMs, which some of the other models cannot with its shallow textual features representation.
The inferior performance of LLM-Scratch, which doesn’t use pretrained knowledge, underscores the importance of this knowledge. Interestingly, LLM-FTAll, which finetunes the entire model including the LLM backbone, performs worse than CLLM4Rec, which only optimizes new user/item token embeddings. This suggests that finetuning the entire LLM with a recommendation-specific corpus does not adapt it well enough for recommendation systems, and may actually degrade its generalization ability.
LLM-PreRec, using a collaborative LLM in the pretraining stage for recommendations, is a strong baseline, validating the effectiveness of combined soft and hard prompting strategies on recommendation-oriented corpora. However, CLLM4Rec still outperforms LLM-PreRec, indicating that recommendation-oriented finetuning is key for adapting collaborative LLMs to make efficient recommendations.
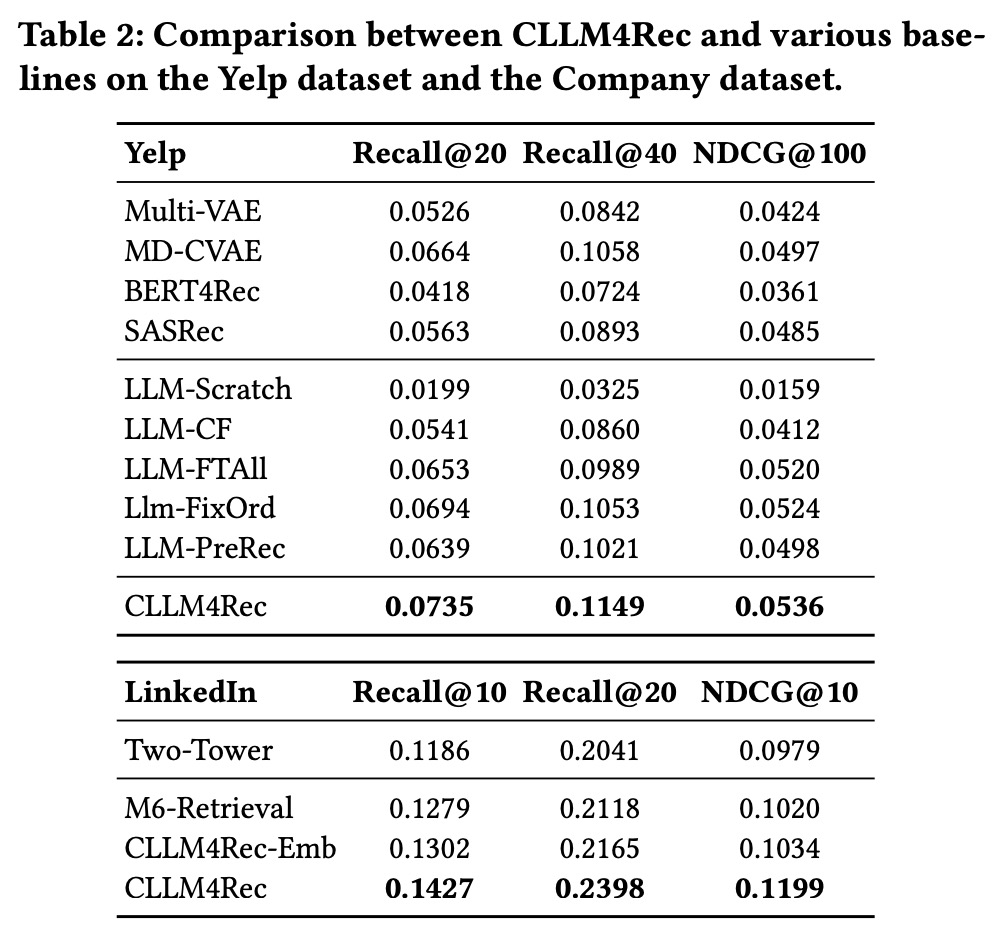
In real-world tests CLLM4Rec significantly outperformed the simpler models. Despite its better performance, CLLM4Rec’s inference latency is still too high for live online deployment, especially when compared to the TT model’s faster inference times. To address this, a new baseline model, CLLM4Rec-Emb, was created by incorporating user and item token embeddings from CLLM4Rec (projected into the size of 128) into the TT model. This hybrid approach improved performance over both the original TT model and M6-Retrieval in offline experiments, indicating that CLLM4Rec can be adapted for practical industrial use where low latency is crucial.
paperreview deeplearning llm recommender