
Paper Review: Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
CM3Leon is a new multi-modal language model introduced in this paper that is capable of generating both text and images. Building on the CM3 multi-modal architecture, CM3Leon utilizes the power of diverse instructional data, demonstrating benefits from increased scaling and tuning. The training approach is inspired by text-only language models, consisting of retrieval-augmented pretraining followed by supervised fine-tuning. A key capability of CM3Leon is its flexibility in bi-directional generation, converting text to images and vice versa. To enable high-quality outputs, it introduces self-contained contrastive decoding techniques.
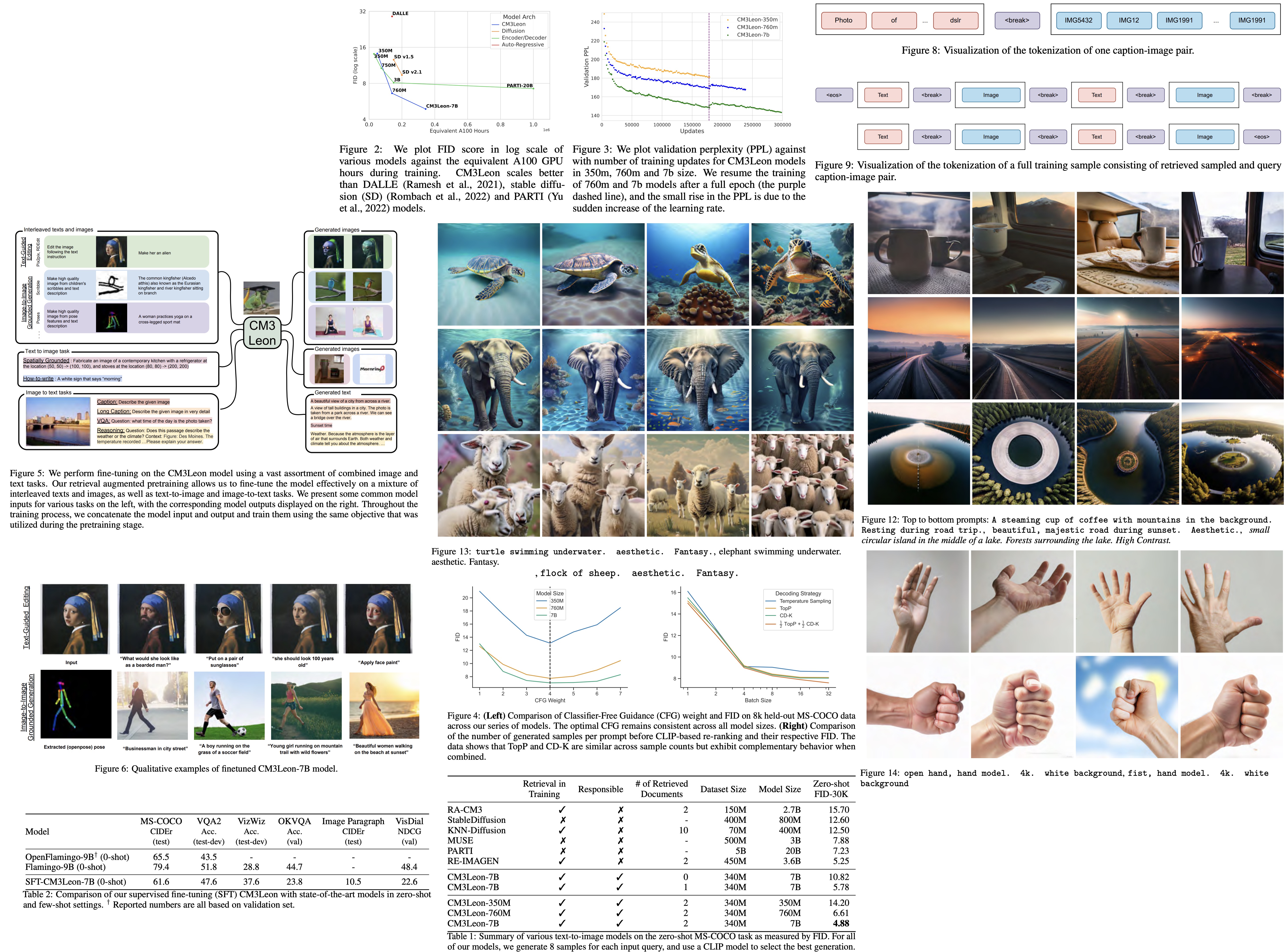
CM3Leon achieves state-of-the-art results in text-to-image generation, requiring 5x less compute than similar models and obtaining a zero-shot MS-COCO FID of 4.88. Moreover, after supervised fine-tuning, it showcases extraordinary controllability on tasks ranging from language-guided image editing to image-controlled generation and segmentation.
Pretraining
Data
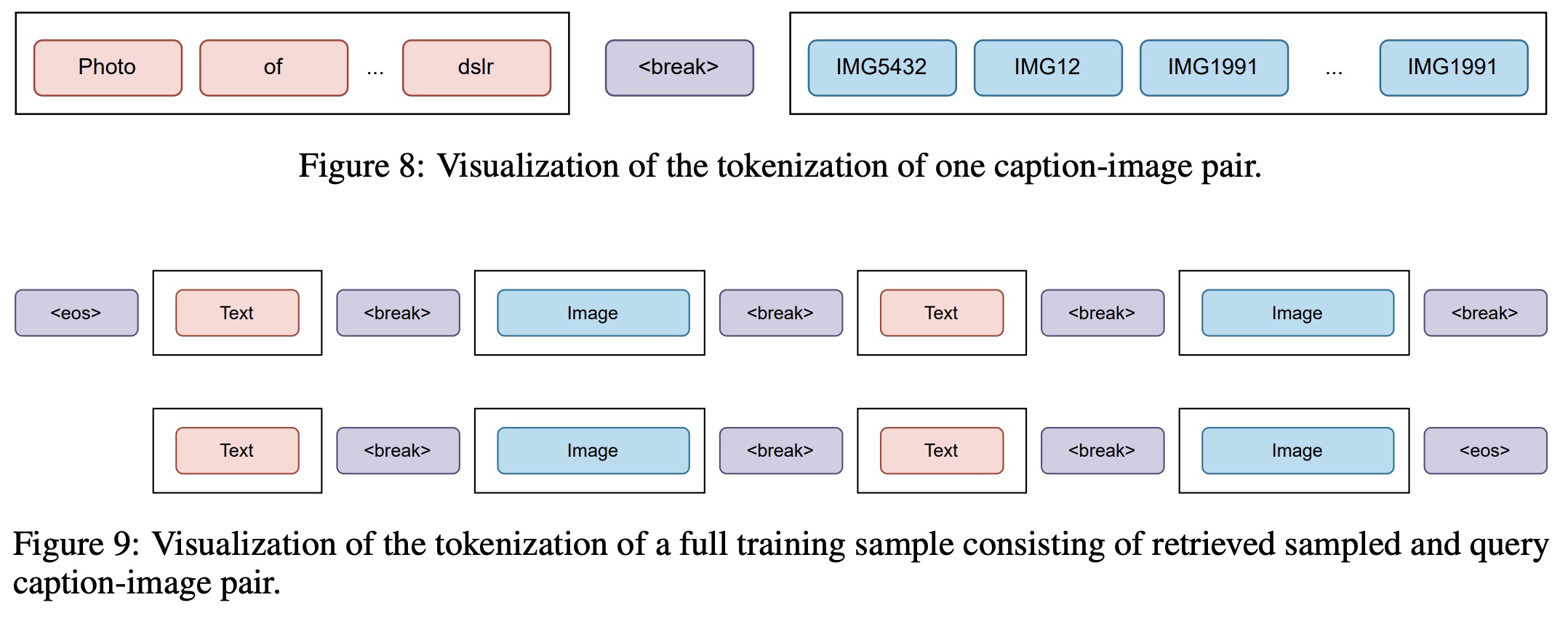
This paper uses only licensed images from Shutterstock for text-to-image generation to avoid ethical concerns related to image ownership and attribution. Images are tokenized into 1024 tokens using the image tokenizer, while text is tokenized with a custom tokenizer. A special
The retrieval approach targeted diverse multi-modal documents from a memory bank based on the input sequence. It encompassed both a dense retriever and a retrieval strategy. The dense retriever assigned a relevance score based on CPIL to a candidate document from the memory bank based on the query.
To select informative documents during training, the researchers focused on three factors: relevance, modality, and diversity. Retrieved documents needed to be relevant to the input sequence, include both images and text for optimal performance, and be diverse to avoid redundancy. Documents too similar to the query or already retrieved were discarded, and documents with a relevance score ≤ 0.9 were used. To encourage diversity, query dropout was implemented, dropping some tokens of the query used in retrieval.
Two documents each are retrieved based on image and text, and three retrieved samples are randomly selected for every input caption-image pair during training, effectively increasing pretraining data 4x.
Objective Function
The CM3 objective, used by the CM3Leon model, is designed to handle multi-modal inputs. It turns inputs into infilling instances by masking certain segments and moving them to the end, effectively transforming a multi-modal task into a text prediction one. This approach enables the model to handle infilling and autoregressive generation tasks for both images and text. For example, it can generate an image from a text prompt like “Image of a chameleon:”, or produce a caption from a masked image prompt like “Image of
This method was enhanced by Yasunaga et al. (2022), who added retrieved multi-modal documents to the training context and emphasized the image-caption pair loss. While this did improve the model’s ability to utilize retrieved samples during the generation process, it negatively affected the model’s performance in zero-shot scenarios, which involve image generation without retrieval.
To mitigate this issue, the researchers removed the weighting and made a minor adjustment to the CM3 objective to prevent masking across
Model
CM3Leon models utilize a decoder-only transformer architecture. In comparison to the previous methods, the researchers removed bias terms, dropout, and learnable parameters for layer norms, and they increased the sequence length to 4096 from 2048. Weight initialization was done using a truncated normal distribution with a mean of 0 and a standard deviation of 0.006, cut off at 3 standard deviations. Output layers were initialized to 0, while learned absolute positional embedding was initialized close to zero with a standard deviation of 0.0002. The training was carried out with Metaseq2, and experiments were tracked using Aim tool.
Text-To-Image Results
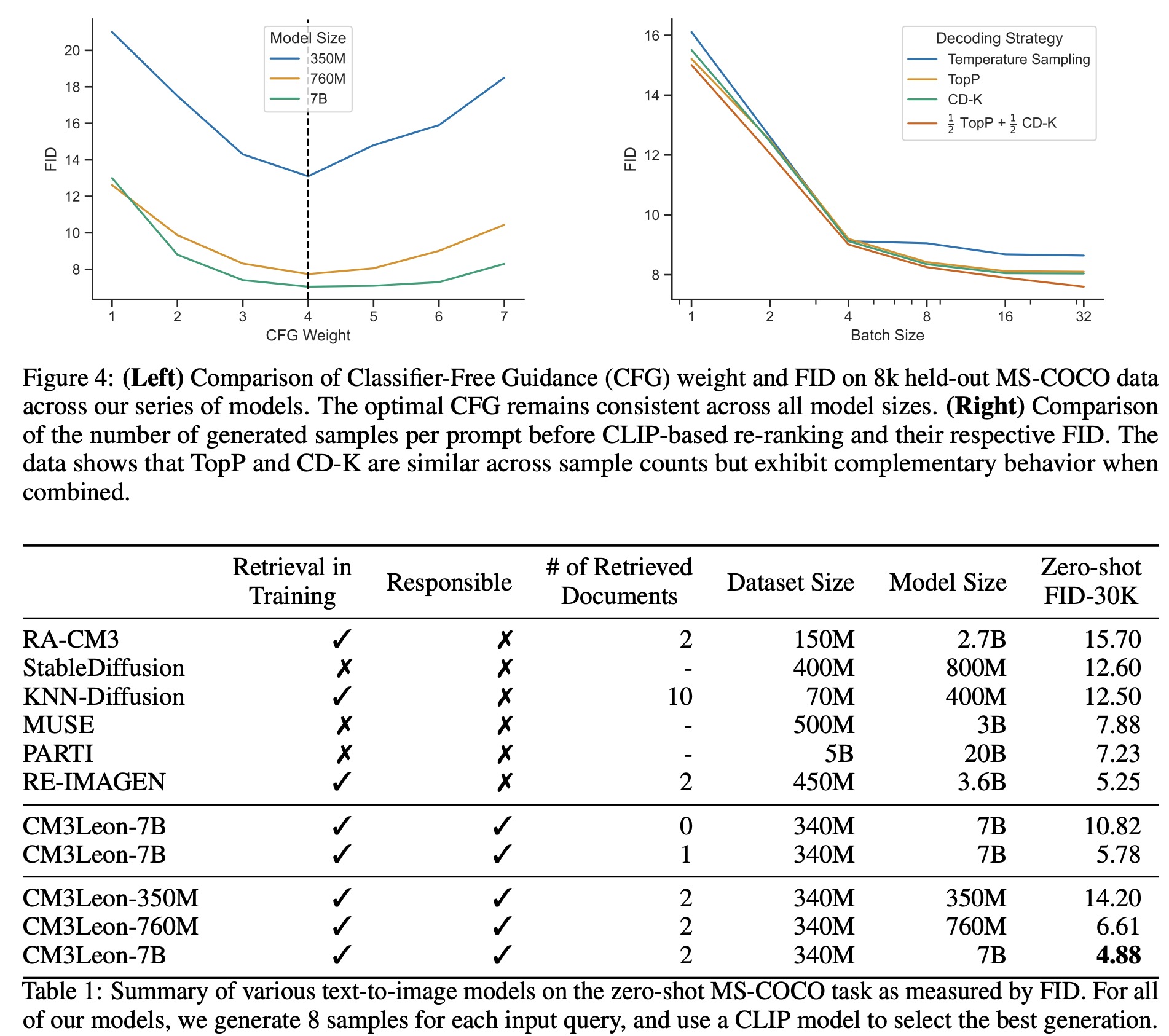
In the field of autoregressive text-to-image models, decoding algorithms play a crucial role in output quality. Various methods have been utilized by models like DALL-E, PARTI, and Make-A-Scene. This text discusses four decoding techniques:
- Temperatured Sampling: A probabilistic method used to control prediction randomness in autoregressive models by adjusting the softmax temperature. It is combined with Classifier Free Guidance.
- TopP Sampling: Also known as nucleus sampling, it involves choosing from the smallest set of top-ranked tokens with a cumulative probability exceeding a certain threshold. This is also combined with Classifier Free Guidance.
- Classifier Free Guidance (CFG): An approach directing an unconditional sample towards a conditional sample. It’s one of the main benefits of training with the CM3 objective and does not require fine-tuning.
- Contrastive Decoding TopK (CD-K): A variant of contrastive decoding (CD), which uses log probability subtraction to guide decoding. It redefines the subset of potential tokens to include the k-th largest probabilities, not just the maximum.
The results show that CD-K is competitive with CFG based sampling, offering a complementary set of generations that can continue reducing Fréchet Inception Distance (FID), a measure of model performance, as the number of generations increases.
Supervised Fine-Tuning
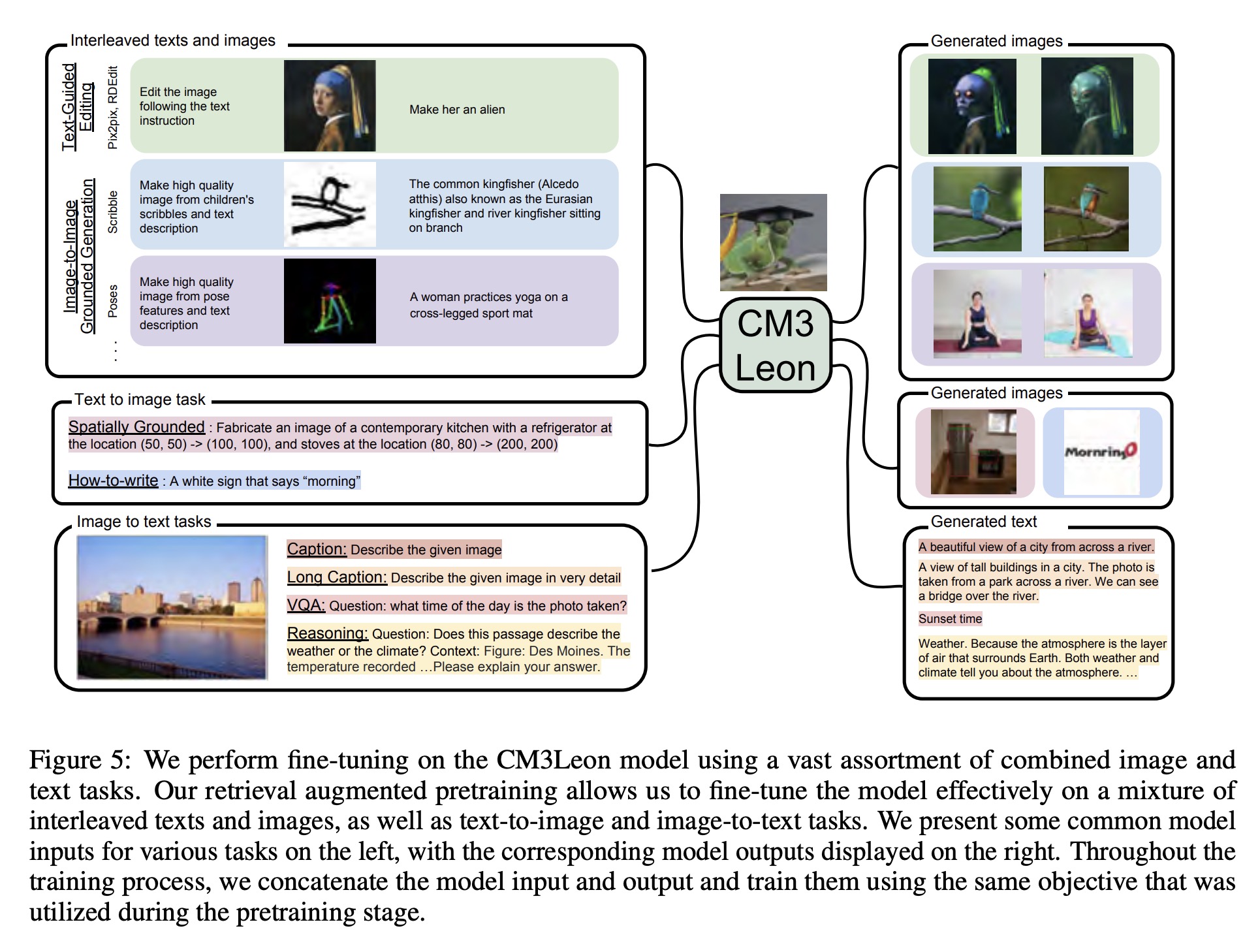


During text-guided image editing and image-image-grounded generation, a task prefix is used. For instance, text-guided editing examples start with “Edit the image following the text instruction,” and every scribble generation example with “Create a high-quality image from children’s scribble and text description,” etc. Distinct CFG (Classifier Free Guidance) values are used for image and text during decoding, helping in creating edited images in line with the original image and text editing instruction. In the case of Structure-Guided Image Editing examples, a single CFG value of 3 is used. The model can generate markedly distinct images following different text prompts while maintaining the same pose as in the input image, given identical input open-pose features.
In conditional text generation tasks, performance comparisons reveal that the SFT-CM3Leon model surpasses previous state-of-the-art models like Flamingo and OpenFlamingo in various vision-language tasks, despite significantly less exposure to text data. The model’s ability to generate captions or answer a variety of questions given an image context and instruction is demonstrated with examples. The flexibility of the model to follow instructions is evident in its capacity to generate very long captions or reason over an image based on the given instruction.
paperreview deeplearning cv nlp imagegeneration sota multimodal finetuning

