Paper Review: CoAtNet: Marrying Convolution and Attention for All Data Sizes
Code is not available yet.
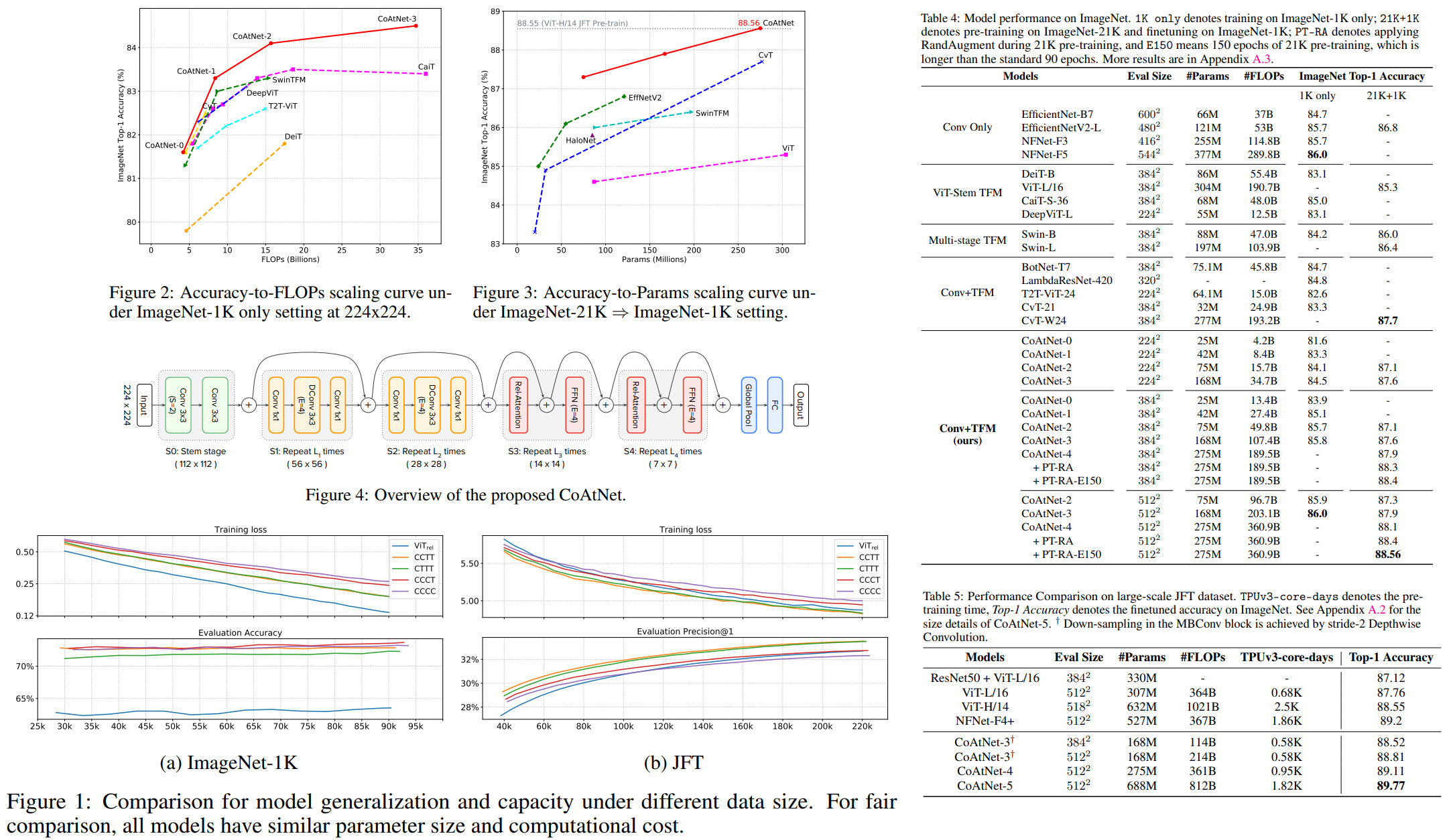
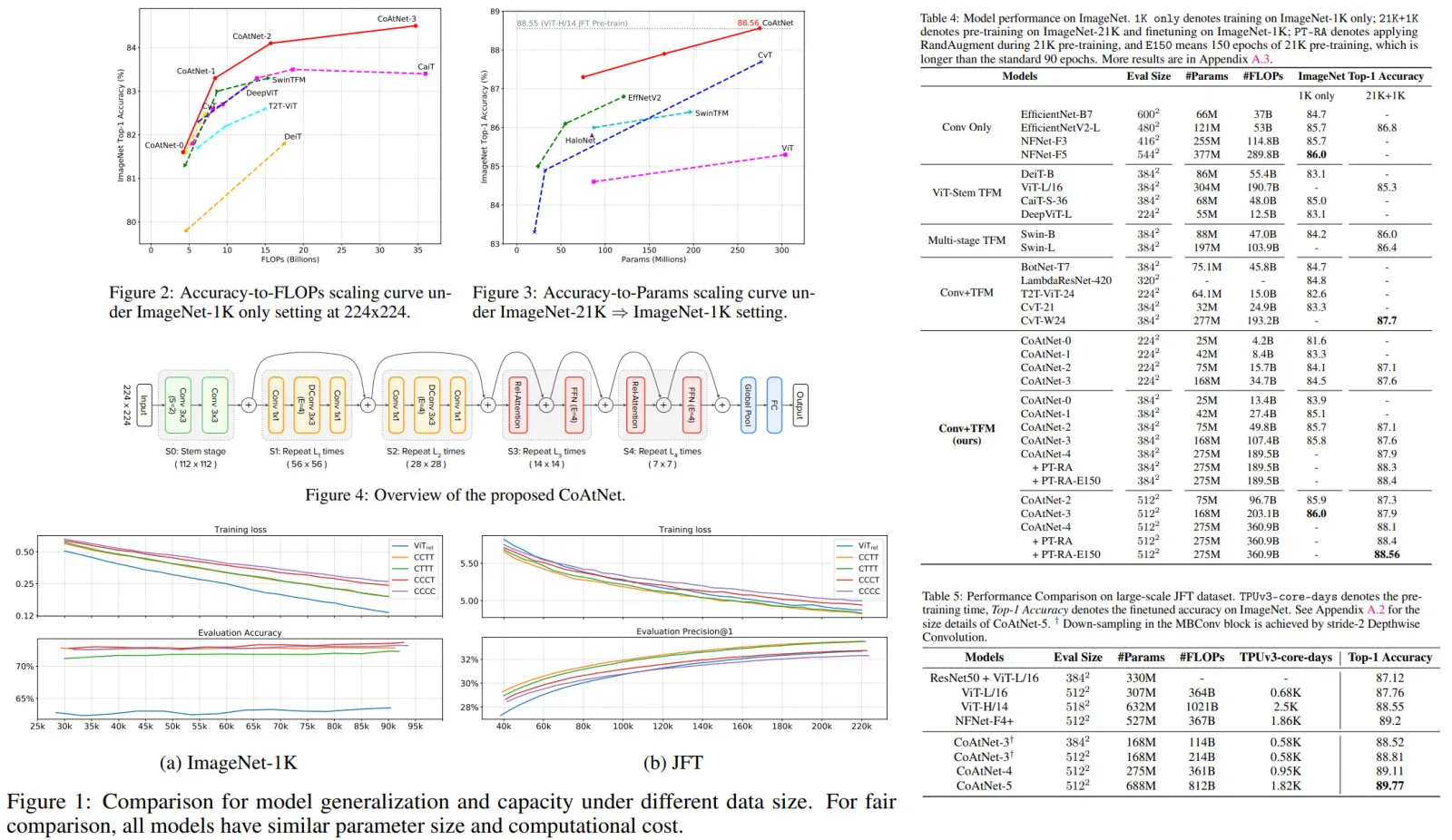
This is one more paper on combining CNN and attention for Computer Vision tasks. The authors (from Google Research) unify depthwise convolutions with self-attention and vertically stack attention and convolutional layers. Resulting CoAtNets work well both in low- and abundant data settings. They achieve 86.0% ImageNet top-1 accuracy without using additional data; using JFT data, these architectures can reach 89.77%.
On convolutions and attention
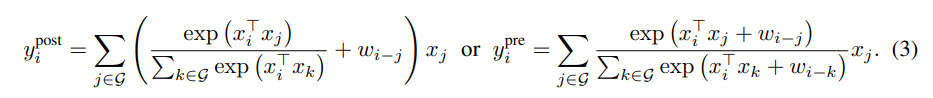

CNN and transformer-based architectures have different advantages. There were some attempts to combine them, but the authors systematically analyze various approaches to doing this and suggest they own one. The main ideas are the following:
- Relative attention is a special variant of attention. There are two main categories: input-dependent and input-independent version. Input-independent is quite fast and requires less memory;
- Convolutional layers converge faster and generalize better thanks to their strong prior of inductive bias;
- Attention layers have a better capacity, thus benefiting from training on large datasets;
- MBConv is combined with relative attention; the idea is to sum a global static convolution kernel with the adaptive attention matrix, either after or before the Softmax normalization (they chose the pre-normalization);
Vertical Layout Design
The first problem which needs to be solved is that applying relative attention to the raw input image will be computationally expensive. The authors try two general approaches:
- convolutional stem with 16x16 stride (like in ViT) and then L Transformer blocks with relative attention
- a multi-stage (five) network with gradual pooling. The authors try four variants: C-C-C-C, C-C-C-T, C-C-T-T and C-T-T-T, where C and T denote Convolution and Transformer, respectively.
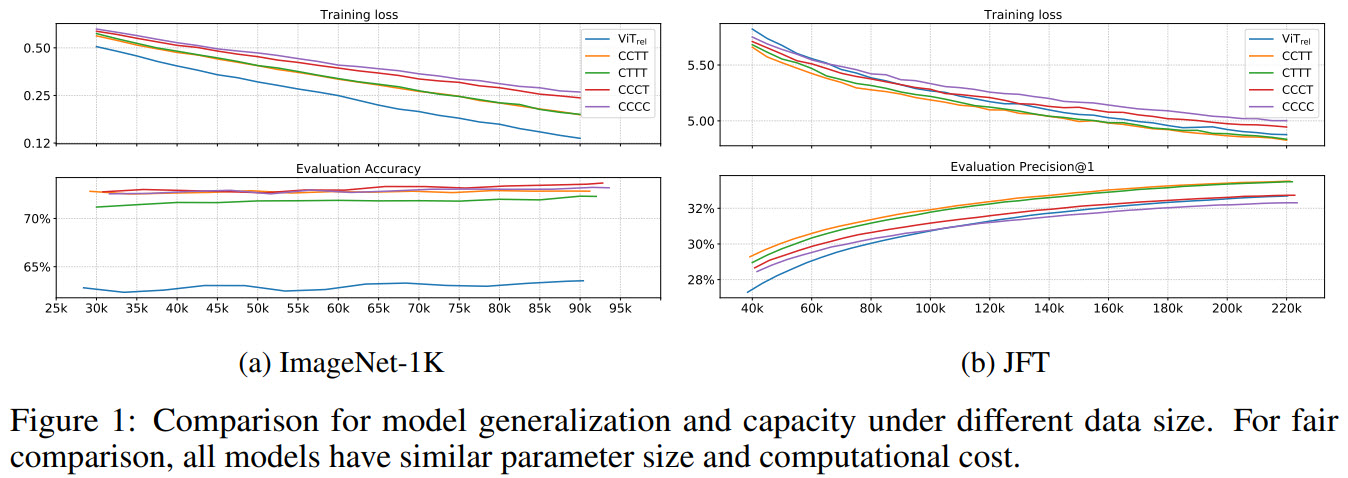
These approaches are evaluated based on two criteria:
- generalization: a minimal gap between scores on train and validation. A pure transformer works the worst; the more convolutional layers, the better;
- capacity: better performance on the same number of epochs. Pure transformer is okay, but one or two convolutional blocks are better;
There was an additional test: C-C-T-T and C-T-T-T were pretrained on JFT and fine-tuned on ImageNet-1K for 30 epochs, C-C-T-T was better.

Model and training
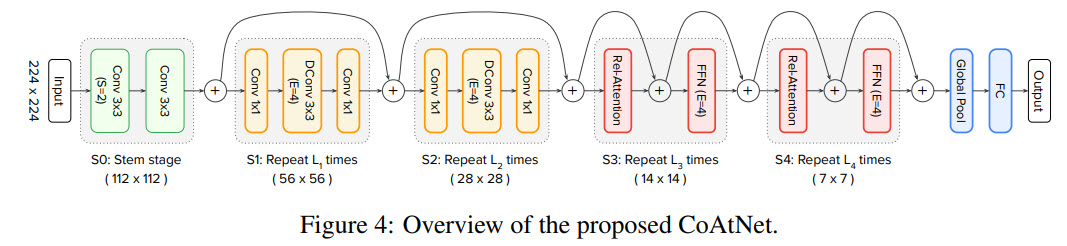
- There are several models in the CoAtNet family with increasing size;
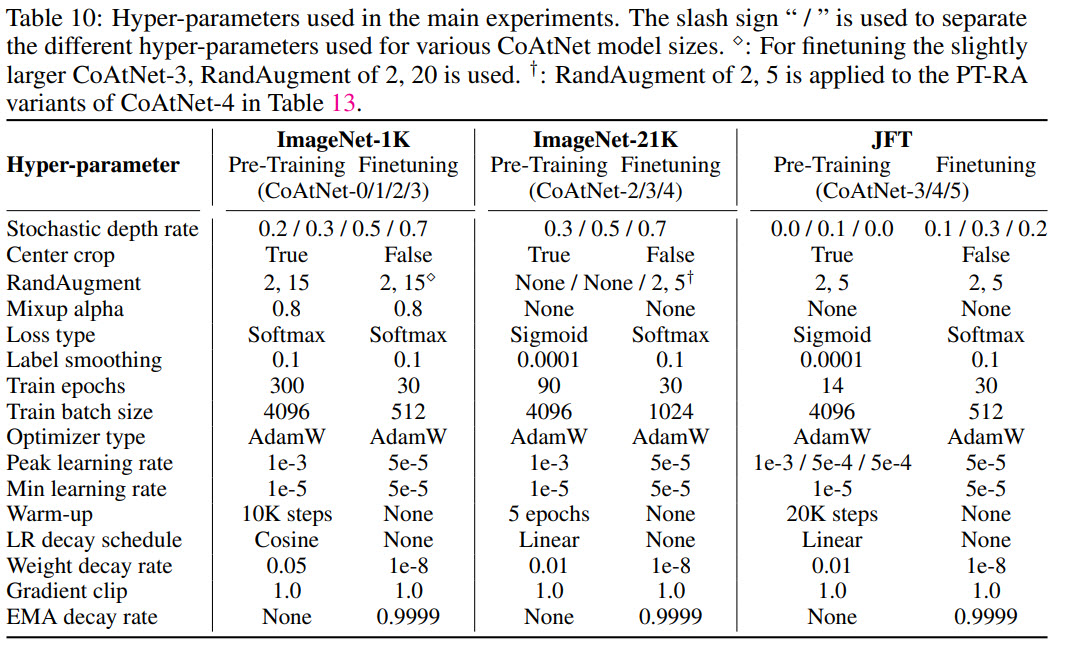
- The models are pretrained on ImageNet-1K (1.28M images), ImageNet-21K (12.7M images) and JFT (300M images) at 224x224 resolution for 300, 90 and 14 epochs respectively. Then they are fine-tuned on ImageNet-1K for 30 epochs on the necessary resolution;
- RandAugment, Mixup, stochastic depth, label smoothing, weight decay;
- An interesting observation: if a certain augmentation is disabled during pre-training, then using it during fine-tuning is likely to decrease performance instead of improving it. It is better to use these augmentations with a very small degree instead of disabling them: it may decrease pre-training metrics but could result in better performance on downstream tasks;
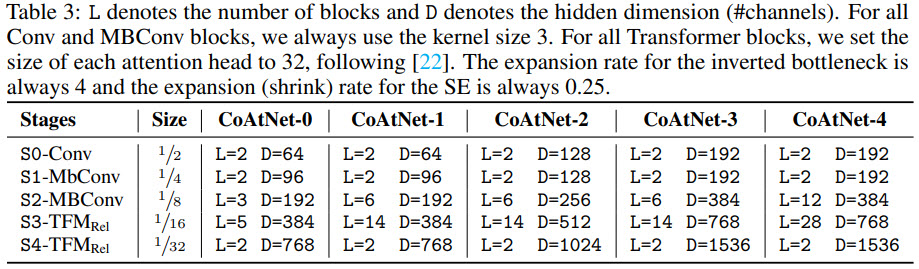
Results
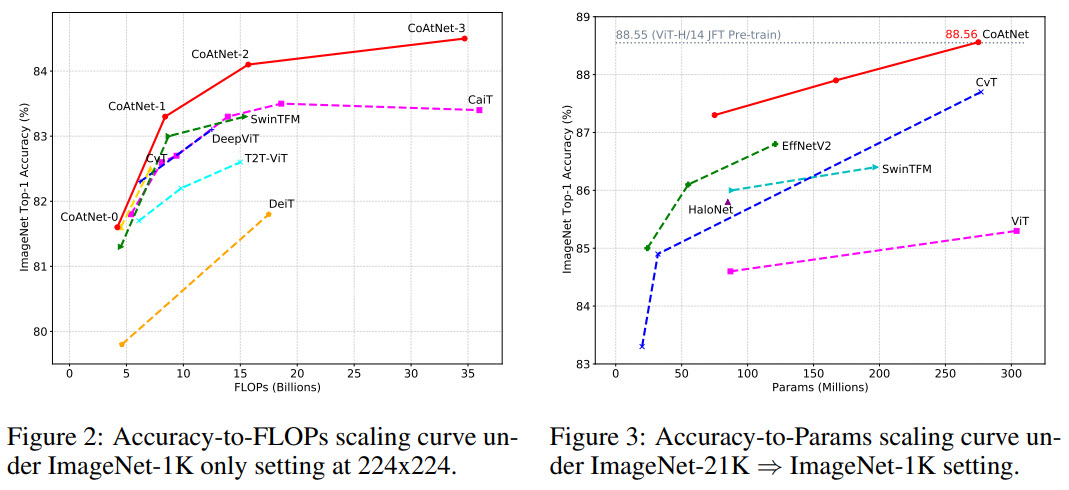
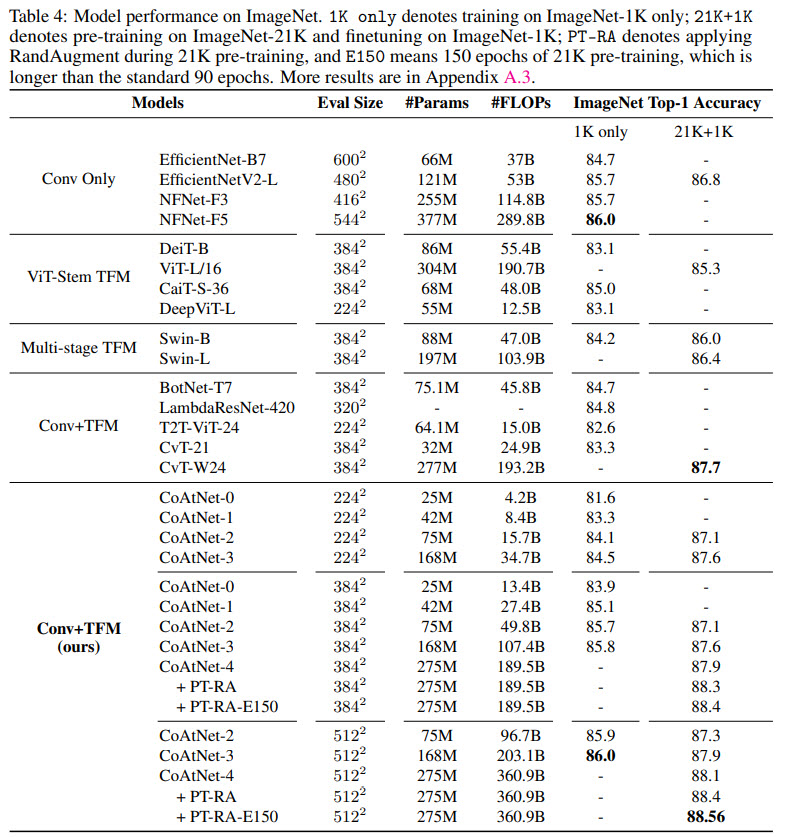
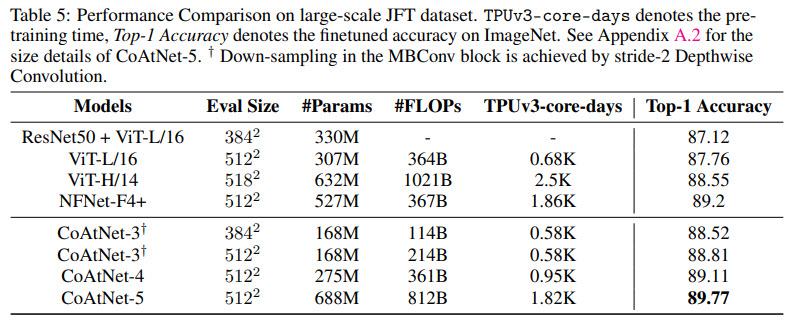
- When CoAtNet is pre-trained only on ImageNet-1K, it matches EfficientNet-V2 and NFNets and outperforms ViT;
- When ImageNet-21K is used for pre-training, CoAtNet becomes even better;
Ablation studies
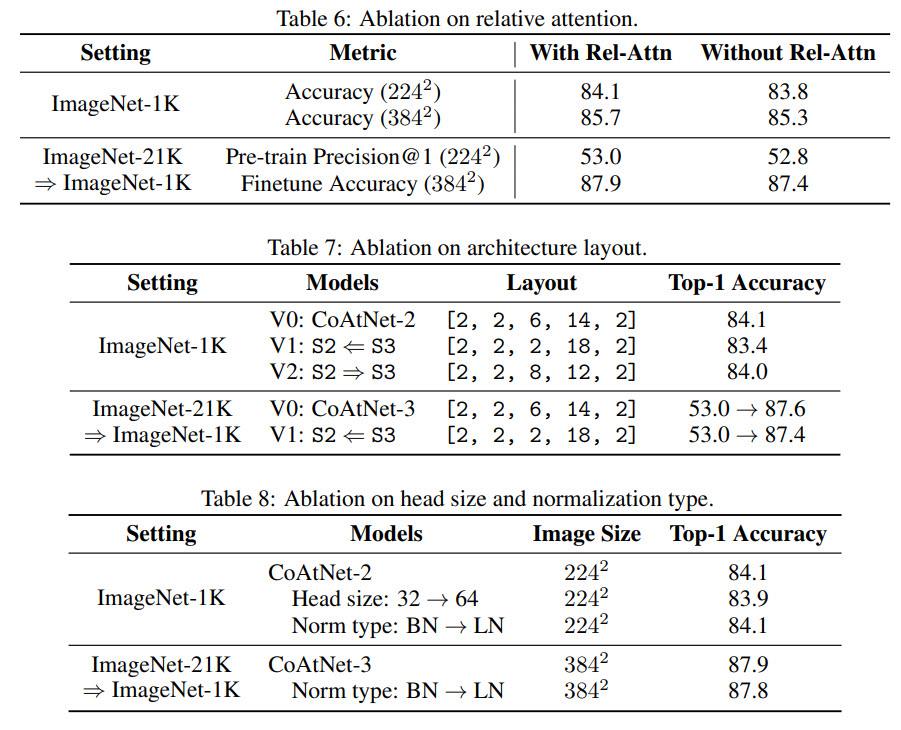
- Relative attention provides better generalization;
- We should add Transformer blocks for better capacity, but only until the number of MBConv blocks becomes too small to generalize well;
- BatchNorm and LayerNorm give similar performance, but BatchNorm is faster;
The appendixes provide additional interesting information, for example, detailed values of hyperparameters.