Paper Review: CogVLM: Visual Expert for Pretrained Language Models
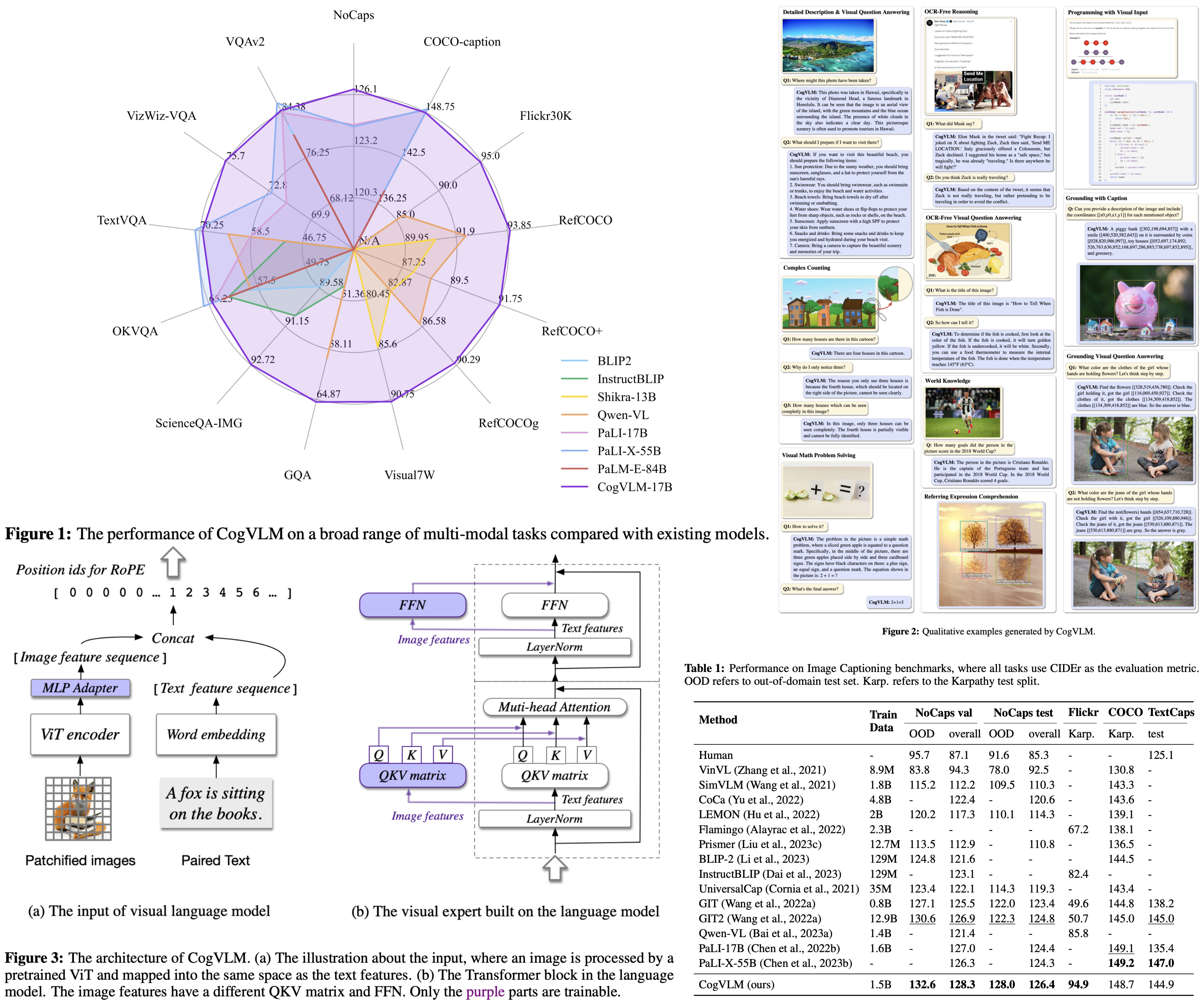
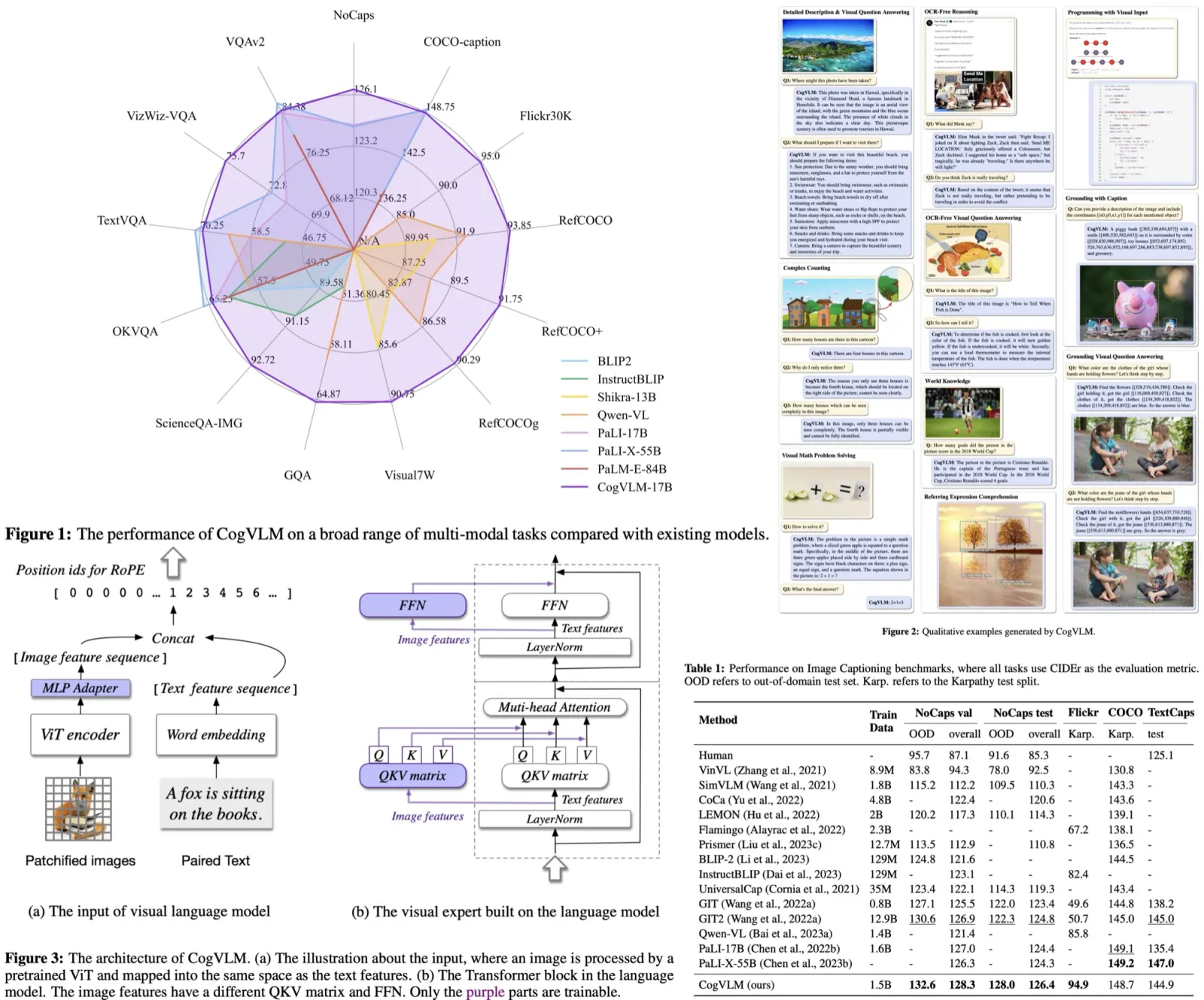
CogVLM is a new open-source visual language model noted for its deep integration of visual and language features. It surpasses conventional models that align image features superficially with language model inputs. This integration is achieved through a trainable module within the attention and FFN layers, allowing the model to maintain its NLP performance. CogVLM-17B has delivered top-tier results on various cross-modal benchmarks, outperforming or equaling the performance of other leading models like PaLI-X 55B in most but not all cases.
Method
Architecture
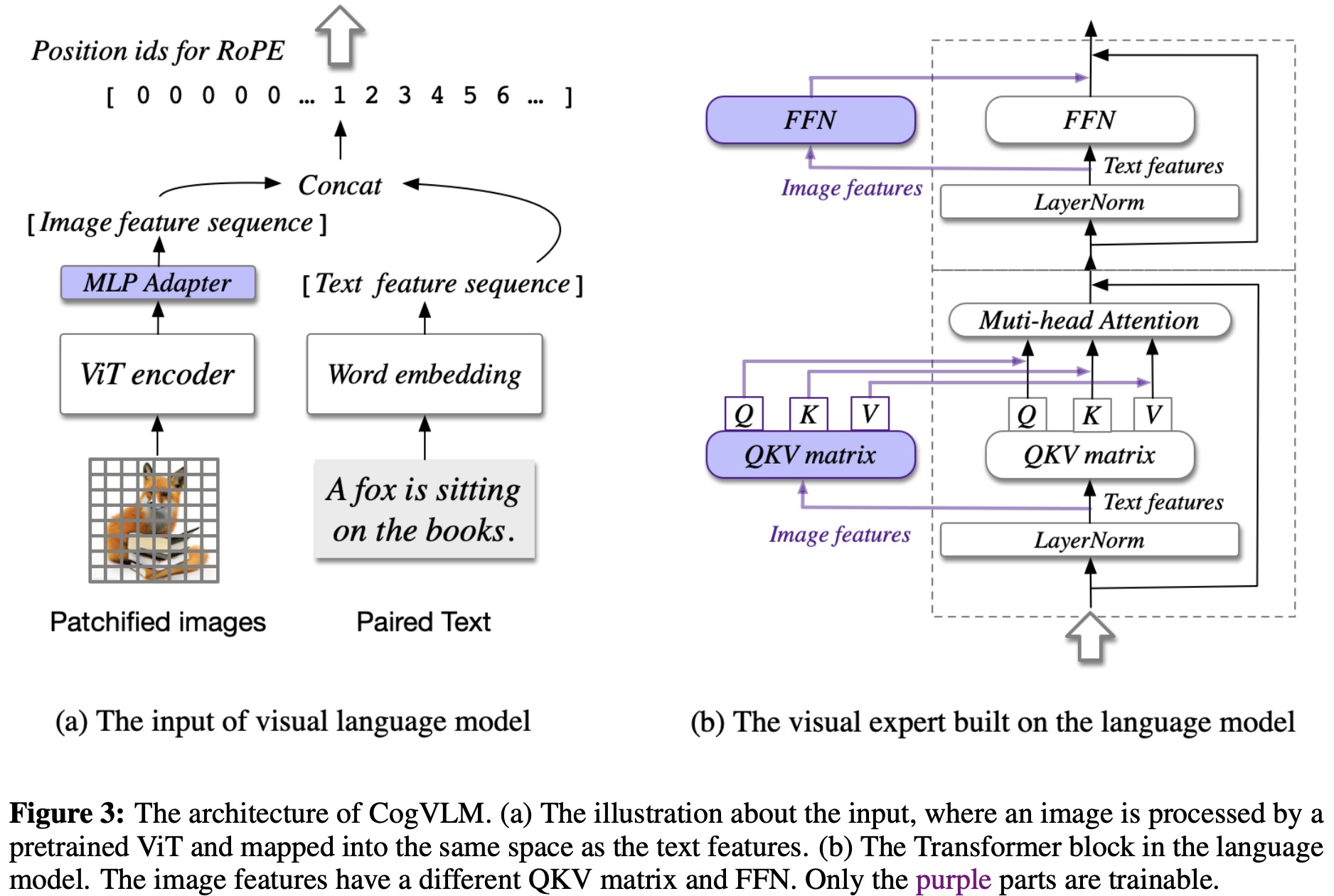
The CogVLM model is a visual language foundation model integrating four key components:
- The ViT encoder, specifically EVA2-CLIP-E, has its final layer removed to better align image features with text features;
- The MLP adapter then maps these image features into the text feature space;
- The language model component, which can be any GPT-style model (Vicuna-7Bv1.5 in CogVLM-17B), applies a causal mask for attention operations
- The visual expert module is added to each layer of the model, comprising a QKV matrix and an MLP, to deeply align visual-language features by transforming image features to match the semantic aspects captured by the attention heads. This allows for a sophisticated fusion of visual and language features, facilitating the model’s state-of-the-art performance on cross-modal benchmarks.
Pretraining
For pretraining CogVLM, the dataset comprised 1.5 billion image-text pairs sourced from public datasets LAION-2B and COYO-700M, after filtering out unsuitable content. Additionally, a custom visual grounding dataset with 40 million images was created, where nouns in captions are linked to bounding boxes within images.
Pretraining occurred in two stages: first, for image captioning loss on the 1.5 billion pairs for 120,000 iterations with batches of 8192, and second, mixing captioning with Referring Expression Comprehension tasks for another 60,000 iterations, with batches of 1024, with a final phase increasing image resolution. The model has 6.5 billion trainable parameters, and the pretraining process used 4096 A100 GPU days.
Alignment
CogVLM was further refined to become CogVLM-Chat, a model designed for more flexible human interaction by aligning with free-form instructions across various topics. This finetuning involved using high-quality SFT data from multiple sources, totaling around 500,000 VQA pairs.
During the finetuning process, particular attention was given to the quality of the data, with manual corrections made to the LLaVA-Instruct dataset, which had been generated by a GPT-4 pipeline and contained errors. The SFT was conducted over 8,000 iterations with a batch size of 640 and a learning rate of 10^-5, including a warm-up phase of 50 iterations.
Experiments
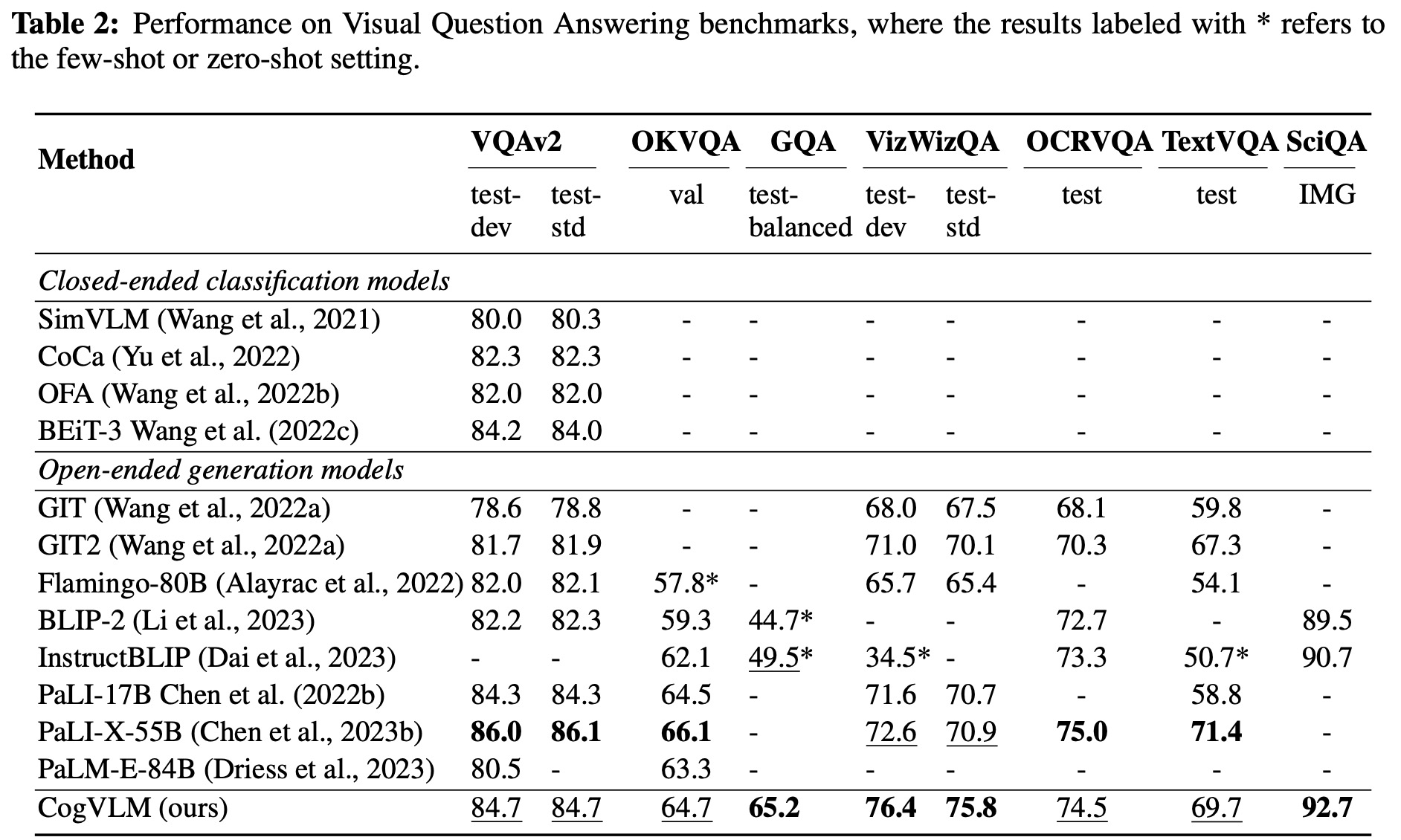

- The CogVLM model demonstrated SOTA or comparable performance in image captioning on multiple benchmarks, outperforming the previous best methods and showing robust long-tail visual concept descriptions. Notably, it achieved high scores on the NoCaps and Flickr benchmarks with less pretraining data.
- For VQA, CogVLM excelled across several benchmarks, surpassing models of similar and larger scales, indicating strong multi-modal capabilities.
- A generalist approach to training CogVLM with data from a wide range of multi-modal datasets showed that multi-task learning did not significantly impact individual task performance, maintaining leadership across tasks.
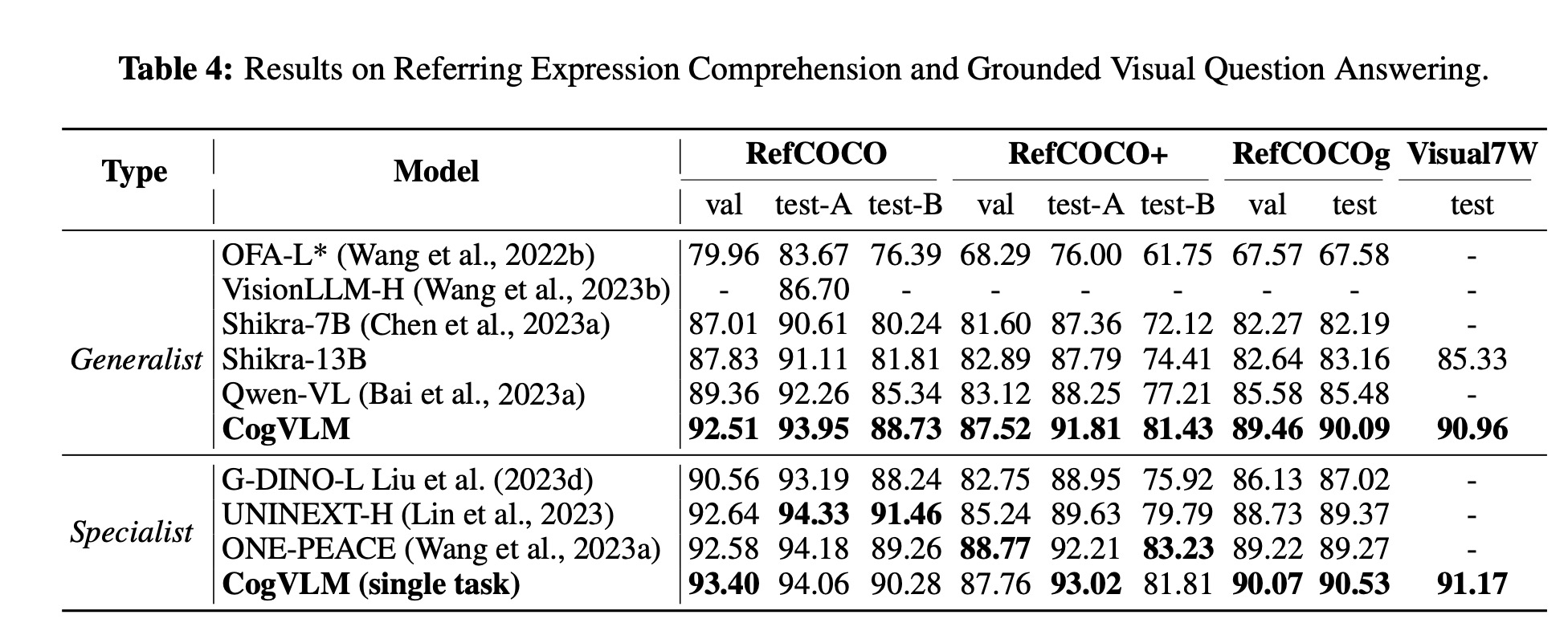
- Visual grounding capabilities were enhanced by training on a high-quality dataset, with CogVLM-Grounding achieving top performance across various grounding tasks, demonstrating flexibility and potential for real-world applications.
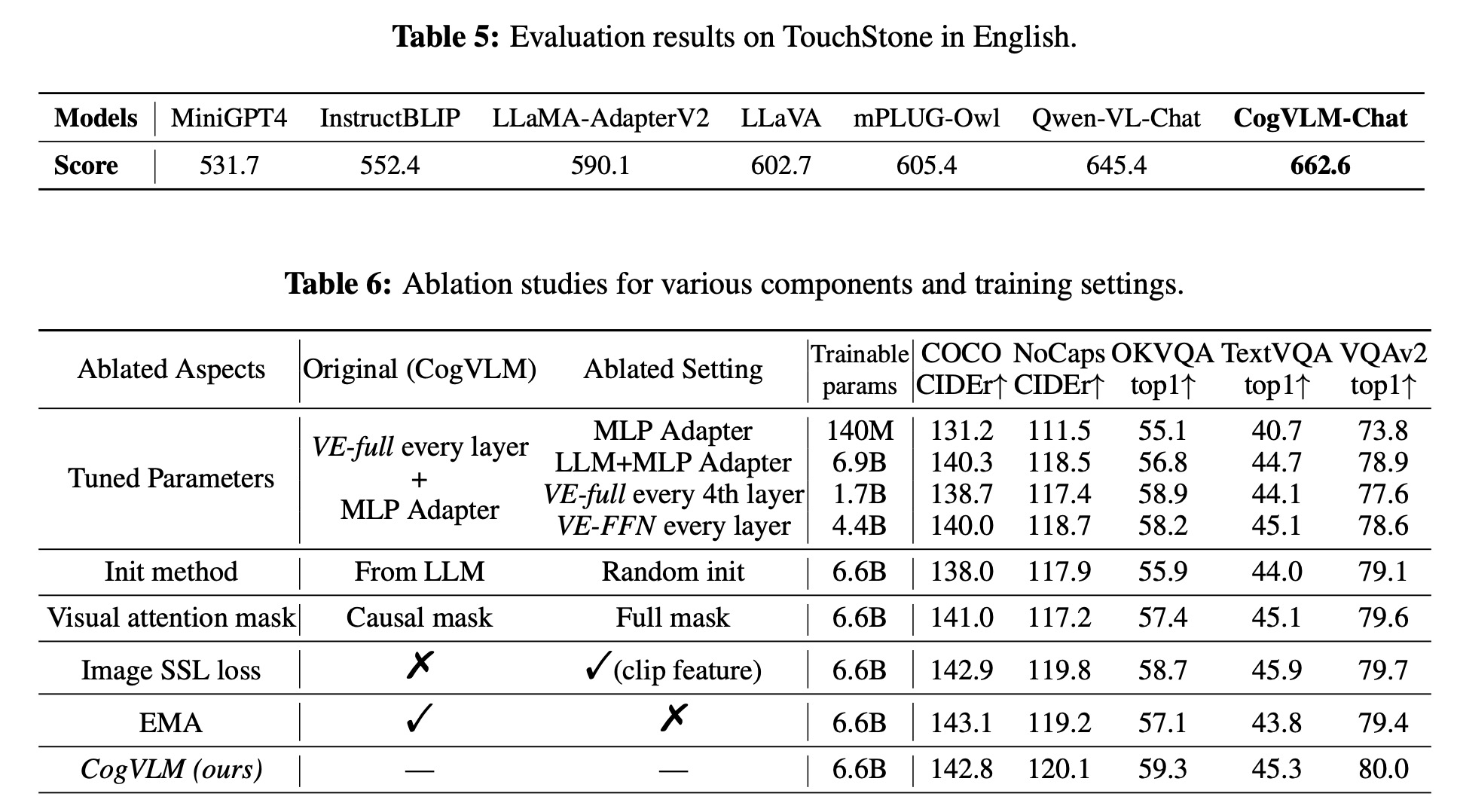
- In real-world user behavior scenarios, assessed by the TouchStone benchmark, CogVLM-Chat significantly outperformed other VLMs.
An ablation study revealed the importance of model structure and parameter tuning, particularly the impact of the visual expert module and the initialization method. It also highlighted the benefits of a causal visual attention mask and found no substantial gains from self-supervised learning loss on image features despite earlier improvements in smaller models. The use of an exponential moving average during pretraining was beneficial across tasks.
paperreview deeplearning cv pretraining