Paper Review: Chain of Hindsight Aligns Language Models with Feedback
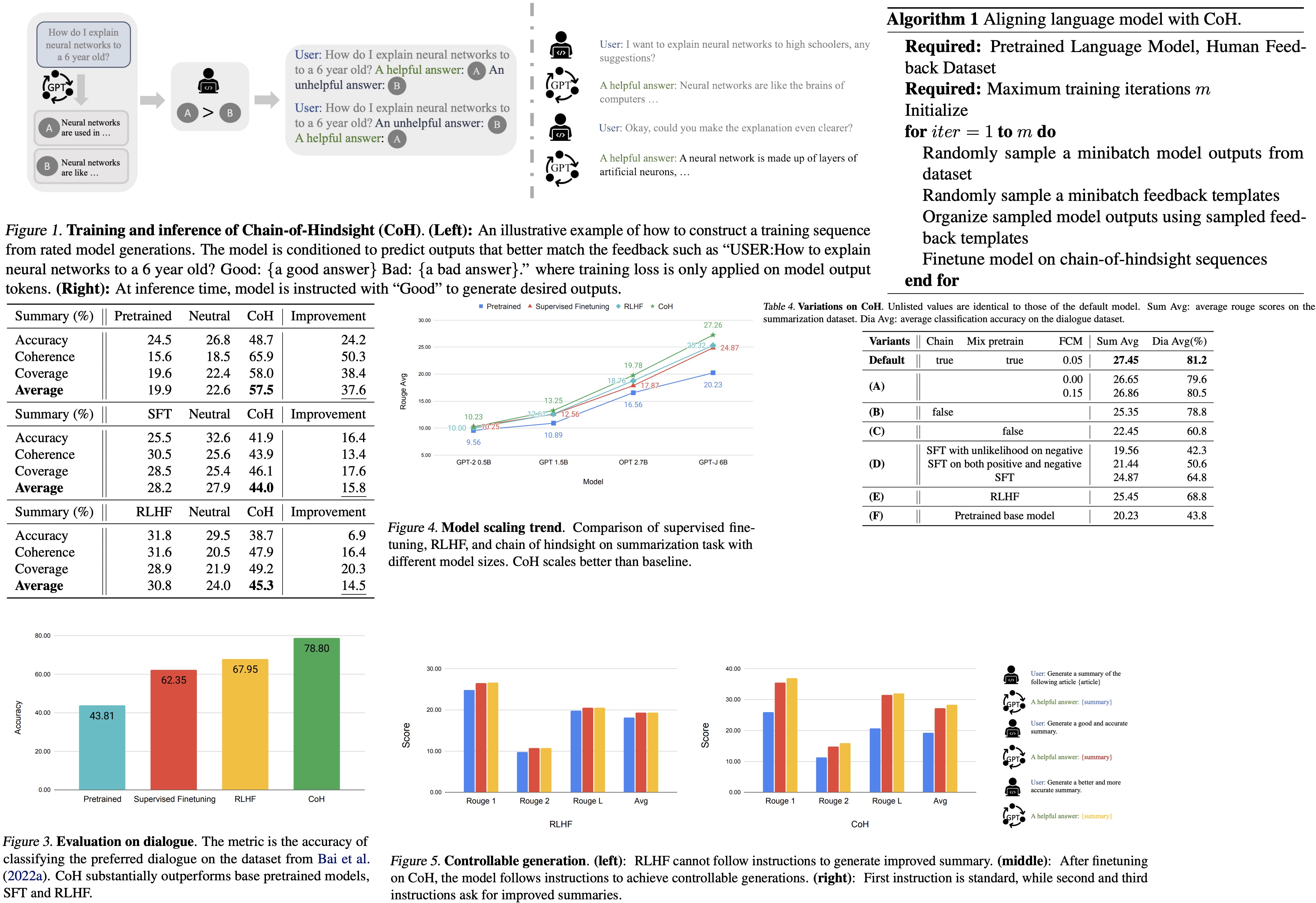
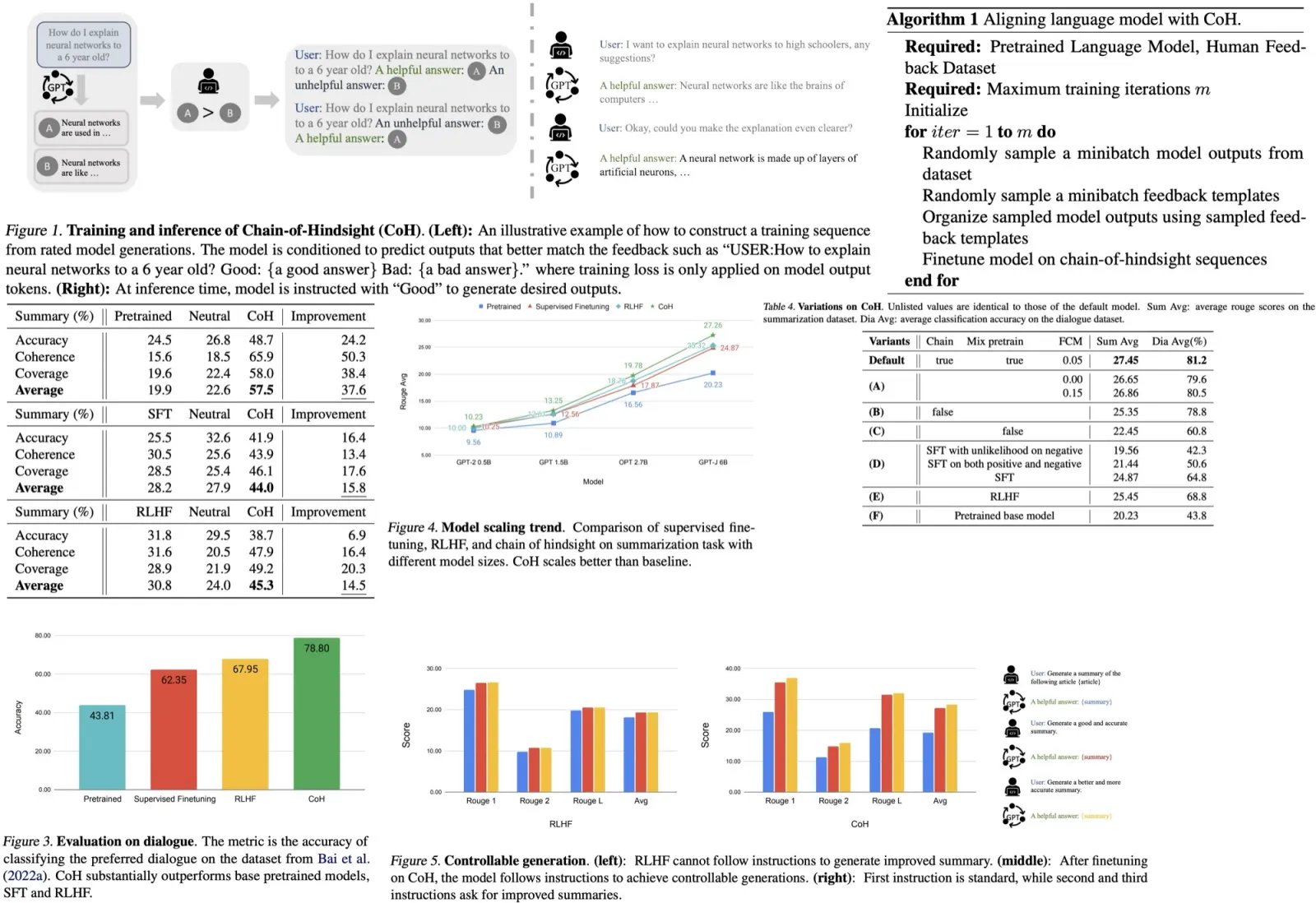
The authors propose a new method called “Chain of Hindsight” to help language models learn from human feedback more effectively. Traditional methods are limited due to dependency on selected model generations favored by humans or reliance on imperfect reward functions. Chain of Hindsight transforms all types of feedback into sentences, which are then used to fine-tune the model, capitalizing on the language understanding capabilities of language models. The model is trained on a sequence of model generations paired with feedback, enabling it to generate outputs based on feedback and to identify and correct errors or negative aspects. This approach greatly outperforms previous methods in aligning language models with human preferences, showing marked improvements on summarization and dialogue tasks and being strongly favored in human evaluations.
The approach

The authors aim to enhance the performance of Transformer-based language models using human-rated data and feedback. They propose a new approach called the Chain of Hindsight (CoH), going beyond traditional Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methods.
Their approach treats all feedback as a sequence and presents the model with a series of model outputs along with corresponding human feedback. The method employs a standard Transformer model architecture, and the objective is to maximize the log likelihood of a text represented by tokens.
In CoH, the text is constructed by combining multiple model outputs with feedback. The model is prompted to produce several responses, which are then combined into a sequence, paired with feedback based on human ratings.
Models learn from feedback by predicting each token they generate, avoiding loss application on other tokens to prevent hindering model generation at inference time. This is achieved through a masking process.

Two techniques are applied to fine-tune models using human feedback: preventing overfitting and avoiding shortcuts. Overfitting is mitigated by maximizing the log likelihood of the pre-training dataset, thus improving model performance. Shortcuts, wherein the model only focuses on missed words leading to reduced output quality, are prevented by randomly masking between 0% and 5% of past tokens during training.
For training, a dataset of model outputs and corresponding human preferences is used. Feedback in natural language is generated, and this feedback, along with model outputs, forms the chain of hindsight. The objective is to predict the input sequence autoregressively, using cross-entropy loss for optimization.
Evaluation
The authors use th following datasets: WebGPT comparisons (dataset of questions, model answers and metadata), Human Preference (human rated dialogues between humans and chatbots), Summarize from feedback (human feedback on model summaries).
They evaluate the models on the following tasks: few-shot learning, summarization, dialogue.
Results
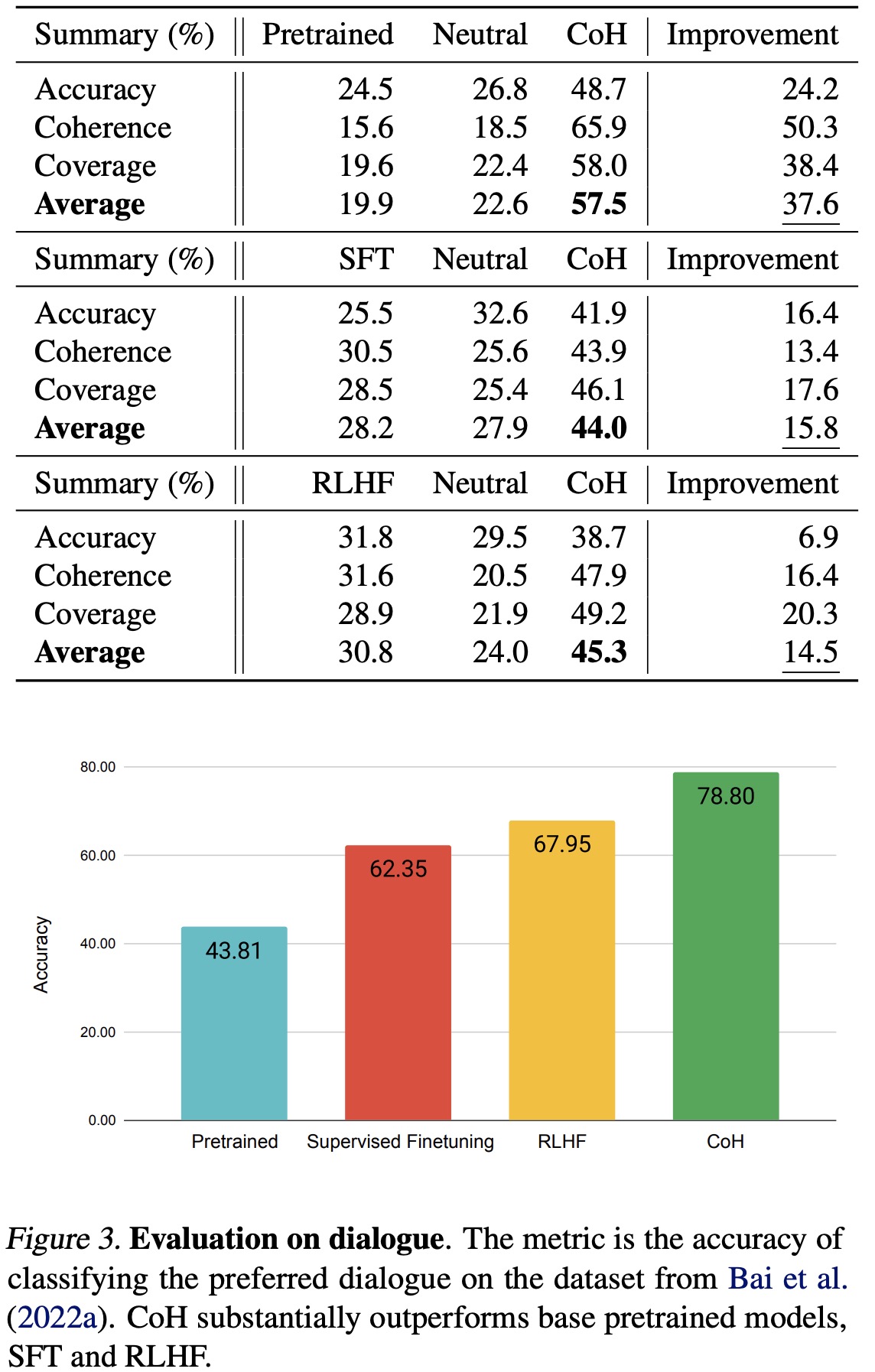
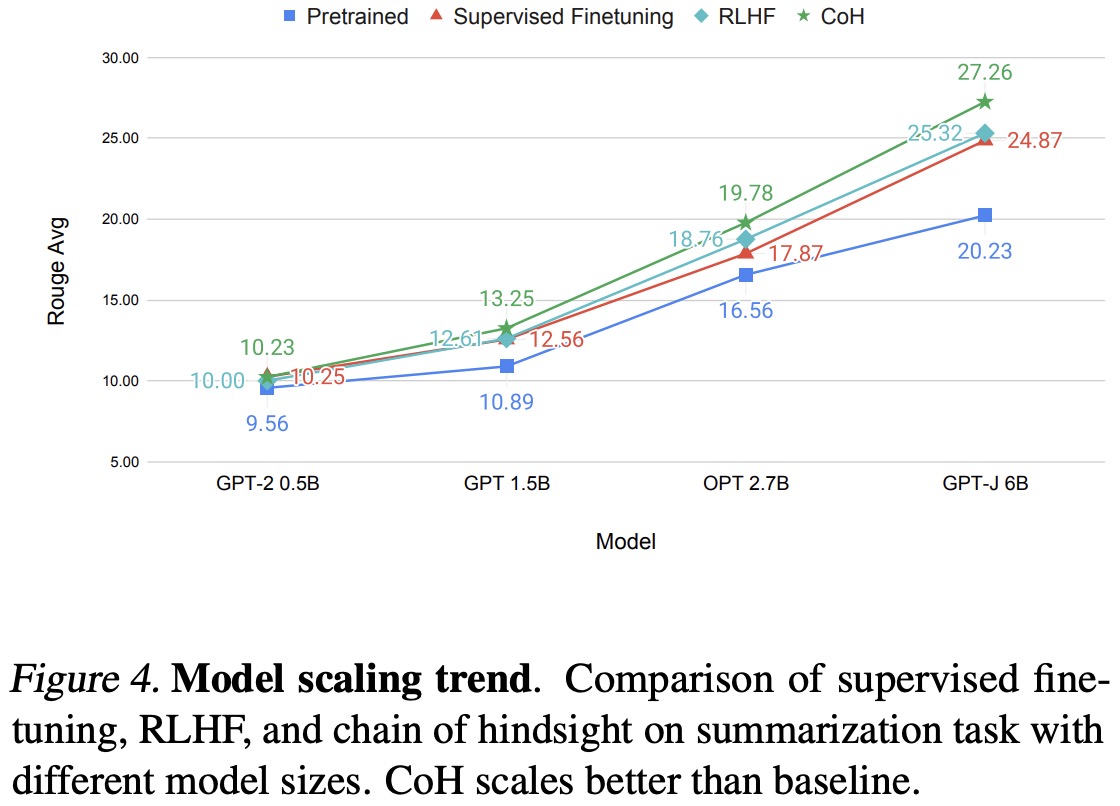
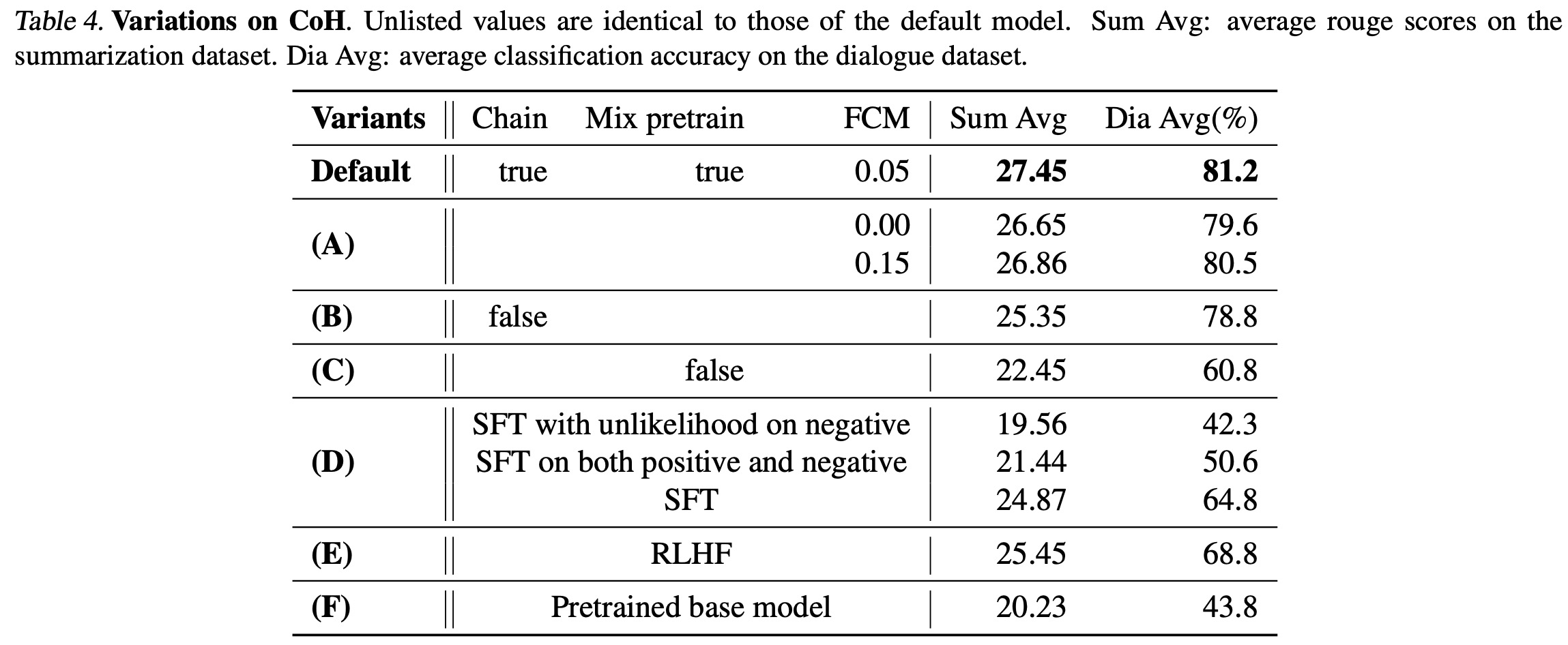
The researchers evaluated their Chain of Hindsight (CoH) model using both automated metrics (ROUGE scores) and human evaluation, and found that CoH significantly outperformed baseline models, including pretrained models, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF).
The authors used the TL;DR dataset for automated evaluation and found CoH performed significantly better. They also hired 75 proficient English speakers for a human evaluation where labelers chose between summaries generated by CoH and baselines. CoH was substantially preferred across multiple metrics, showing its effectiveness in learning from human feedback.
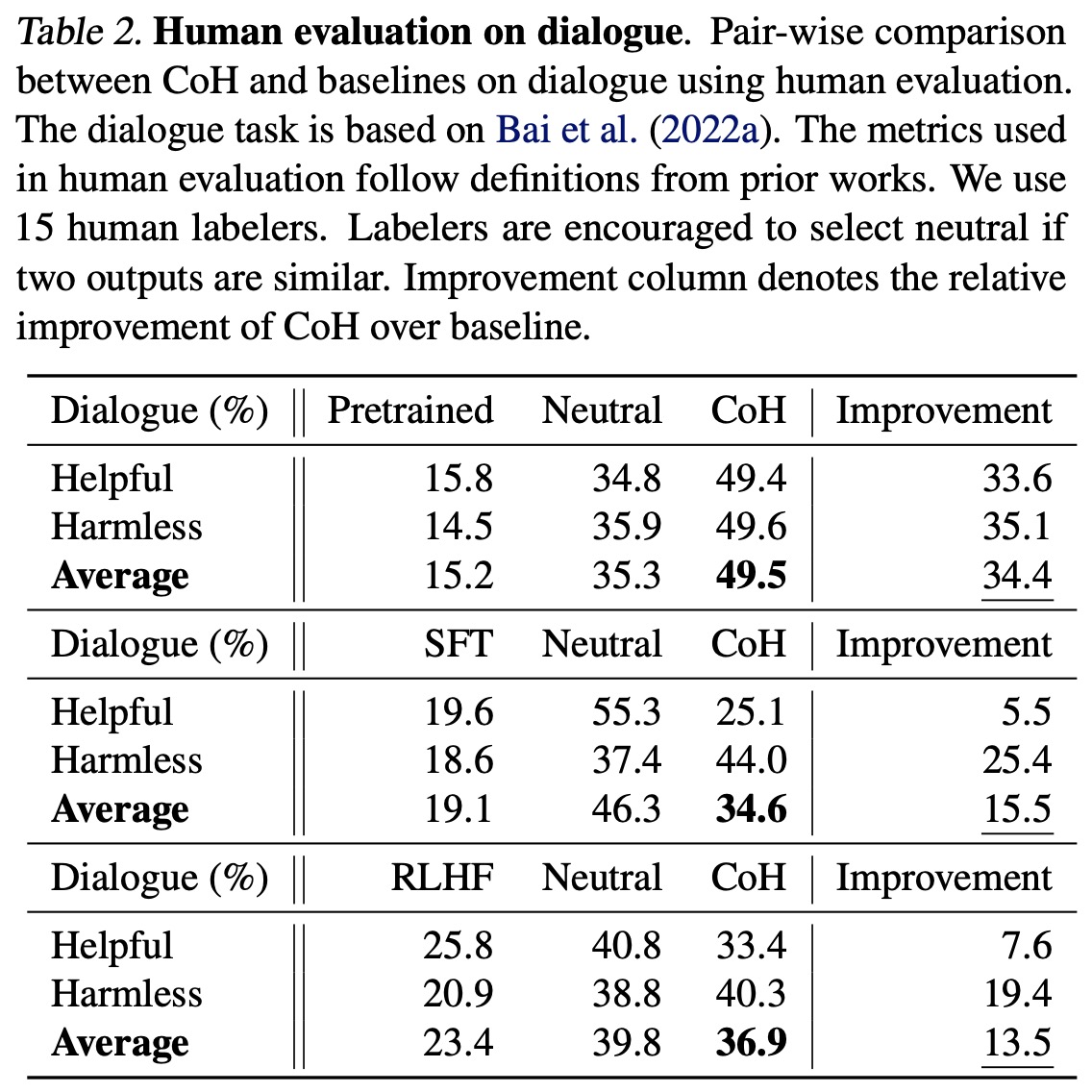
- The model’s ability to understand human preferences was further tested using dialogue datasets, where CoH was found to achieve the highest accuracy, outperforming all baselines and the second-best RLHF by a substantial margin.
- The researchers also assessed the model’s performance by replacing model responses in dialogues with new generations from the model. Despite over 50% of the labelers showing neutrality between SFT and CoH, the CoH model was found to be more favored, demonstrating its robust performance in generating human-like responses.
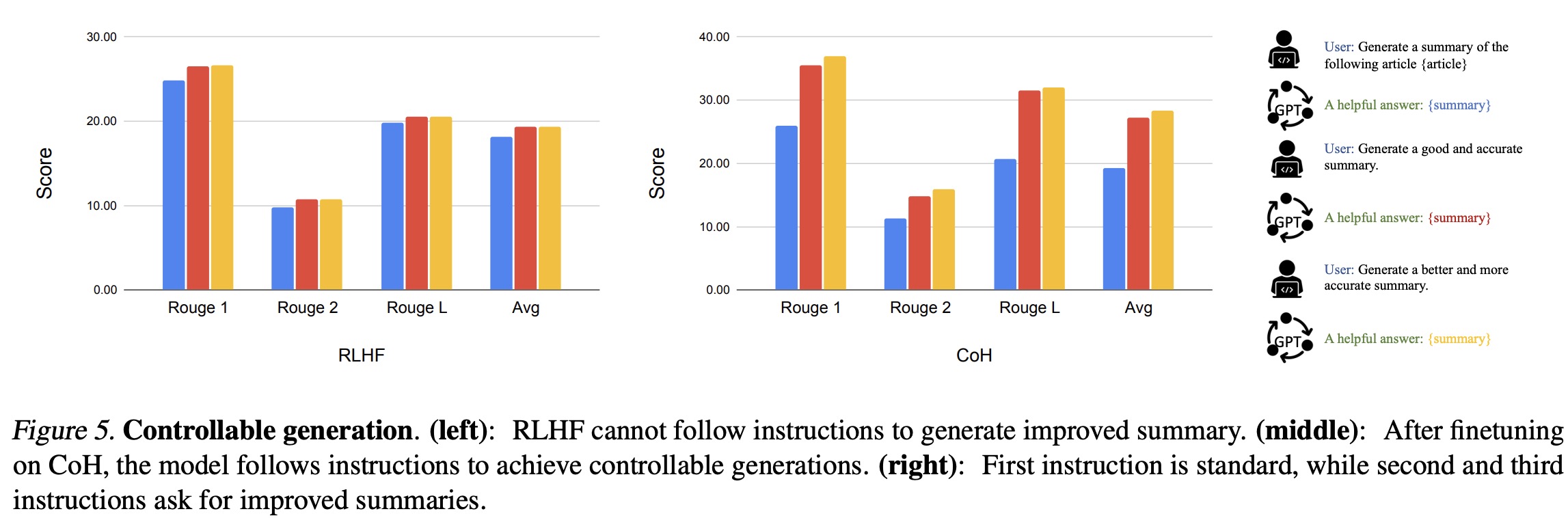
- They also tested their Chain of Hindsight (CoH) model and the Reinforcement Learning from Human Feedback (RLHF) model on a summary generation task. They provided three instructions for summary generation, each increasing in complexity. While RLHF performed well on the first instruction, it struggled to comprehend and execute the second and third. Conversely, the CoH model demonstrated a better understanding of the instructions and generated superior summaries for the more complex prompts.
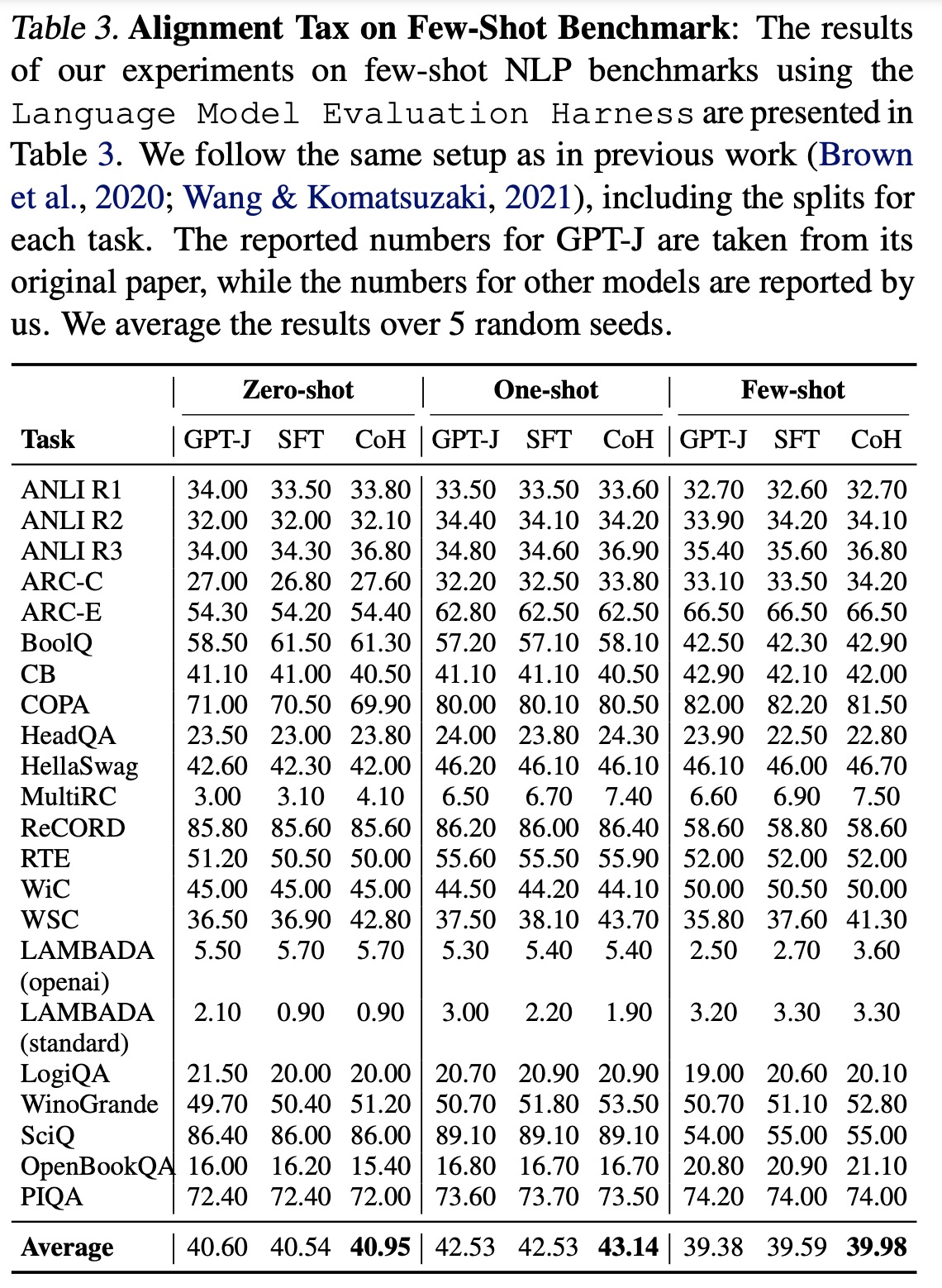
- The team also assessed the models on a variety of few-shot tasks commonly used in previous research. Surprisingly, they observed a performance decrease in models fine-tuned using Supervised Fine-Tuning (SFT) after alignment, potentially due to the well-known alignment tax issue in language models. This issue emphasizes the importance of human evaluation in assessing model performance. In contrast, their CoH model demonstrated modest improvements over both the pretrained and SFT models, suggesting that it’s less prone to the alignment tax issue.