Paper Review: CoTracker: It is Better to Track Together

In the paper, a new video motion prediction method called CoTracker is introduced. Traditional methods either estimate motion for all points in a video frame simultaneously using optical flow or track each point’s motion separately throughout the video. However, tracking points individually may overlook the correlation between points, possibly reducing performance.
CoTracker addresses this by jointly tracking multiple points throughout a video. This approach blends ideas from both optical flow and tracking studies. CoTracker is built on a transformer network, using specialized attention layers to model the correlation of different points over time. This transformer continually refines multiple trajectory estimates and can be used for extended videos through a sliding-window technique and an unrolled training loop. The system can track multiple points simultaneously and can add new points to track at any moment. CoTracker surpasses most existing methods in performance across various benchmarks.
CoTracker
The objective is to track 2D points across a video’s duration. A video consists of T RGB frames. Tracking involves creating a trajectory for each of the N points in these frames. Each point’s track starts at a specific time during the video. A visibility flag indicates if a point is visible or occluded in a frame. A point must be visible at its starting time. A tracker’s role is to process the video and the starting locations and times of the N tracks. It then estimates the trajectory of each point and predicts its visibility throughout the video. Only the initial trajectory and visibility (which is always 1 at the start) are known to the tracker, and the rest are to be predicted.
Transformer formulation
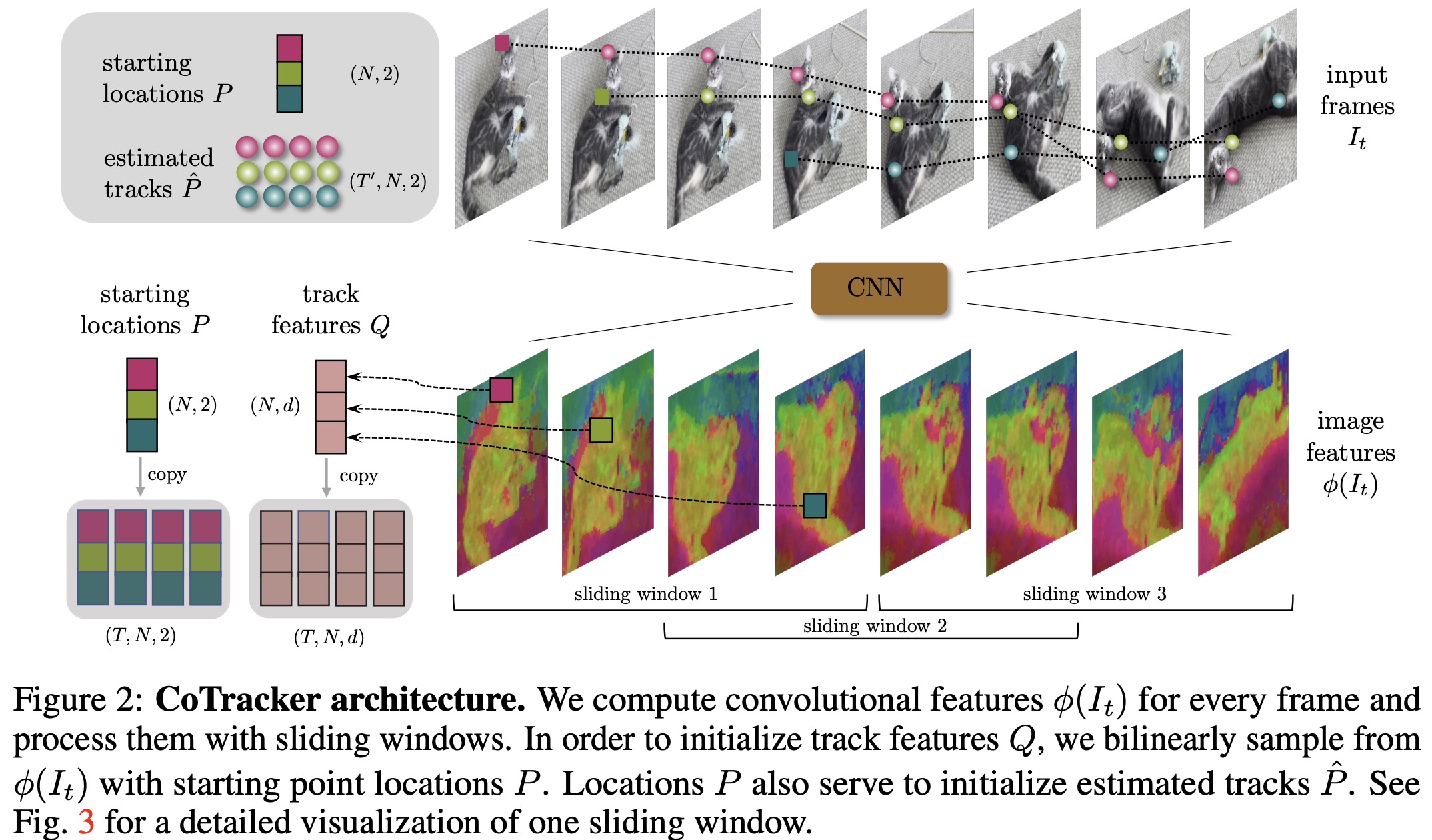
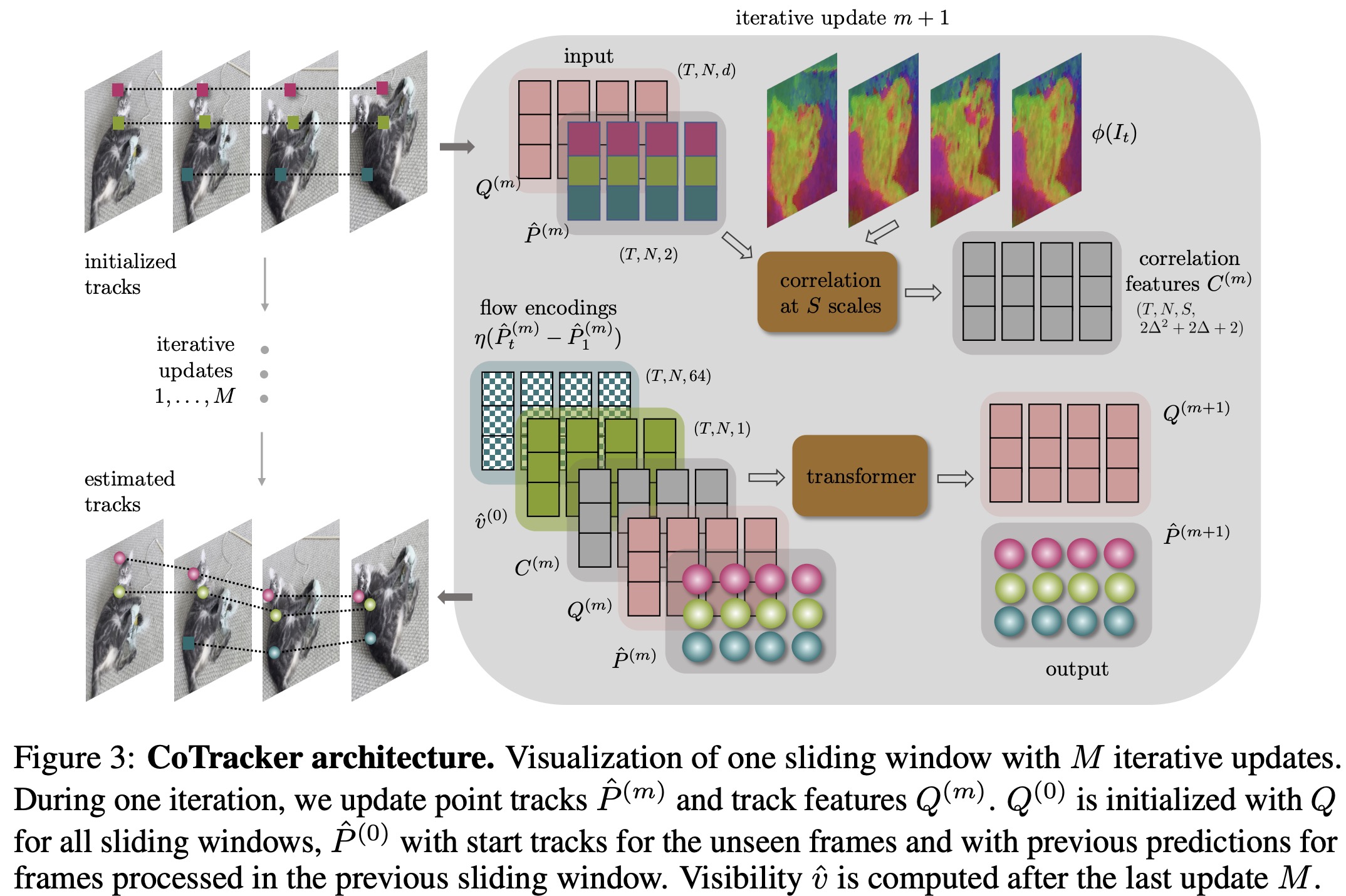
The CoTracker algorithm aims to predict the motion of 2D points across a video using a transformer network. Each track of a point is represented as a grid of input tokens, updated to output tokens by the transformer.
- Image Features: Appearance features are extracted from each video frame using CNN, trained end-to-end with the transformer. These features are downsampled for efficiency.
- Track Features: Each track is initialized with feature vectors that capture its appearance. These vectors are time-dependent and are updated as the video progresses.
- Correlation Features: These are obtained by comparing the image features with track features around the estimated current location. This helps in matching the track to corresponding points in the video frames.
- Tokens: Input tokens code for position, visibility, appearance, and correlation of the tracks. A sinusoidal positional encoding relative to the initial location is also included. Output tokens contain updated locations and appearance features only.
- Iterations: The transformer is applied multiple times to refine the track estimates. The visibility flag is not updated iteratively by the transformer but is updated once at the end based on a sigmoid activation function.
Initial values for the track features, position, and visibility are derived from the starting location and time of the track.
Windowed inference
The CoTracker algorithm is designed to handle very long videos through a windowed application approach. For a video longer than the maximum window length supported by the architecture, the video is divided into overlapping windows. The tracking process is iterative, and the transformer is applied multiple times to each window. The output of one window serves as the input for the next, creating a grid of quantities across transformer iterations and windows. The apptoach allows for the addition of new tracks at any time by extending the token grids using initial values.
Unrolled learning
The CoTracker algorithm employs a special training approach to handle semi-overlapping windows effectively. Two types of losses are used for this purpose:
- Track regression loss, which measures the difference between the predicted and ground-truth positions of points. This loss is summed over both the multiple transformer updates and windows, and it is discounted for early transformer iterations.
- Cross-entropy loss for the visibility flags is computed at the final transformer iteration across all windows.
Due to computational constraints, only a moderate number of windows are included in the loss calculation during training. However, at test time, the algorithm can handle videos of any length by unrolling the windowed transformer applications. The algorithm is designed to start tracking points only from the window where they first appear. To ensure robust training, points that appear later in the video are included in the training data by sampling from the middle frame of sequences.
Point Selection

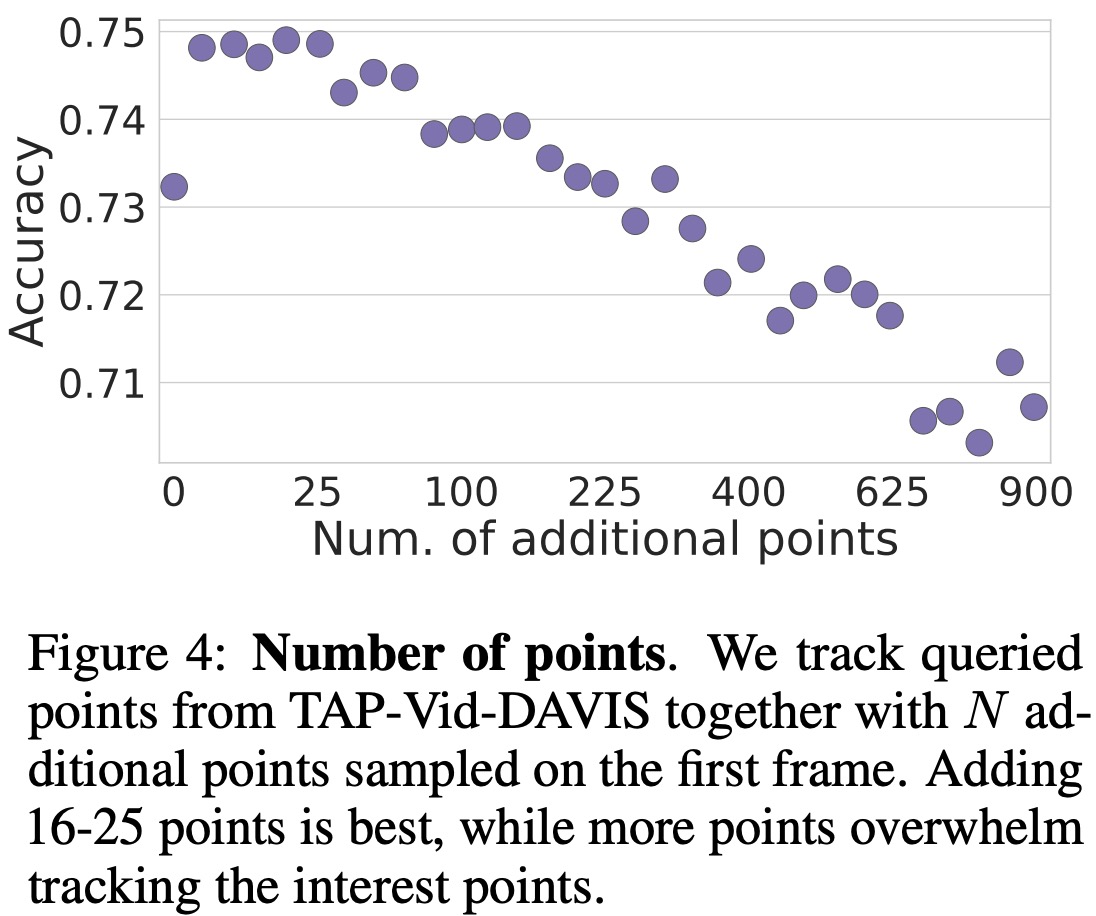
Tracking multiple points simultaneously allows the model to better understand motion in the video and the correlation between tracks. However, when evaluating performance on benchmark datasets, the model is tested using only a single target ground-truth point at a time. This is to ensure a fair comparison with existing methods and to decouple the model’s performance from the point distribution in the dataset.
Two point selection strategies are experimented with:
- Global strategy: Additional points are selected on a regular grid across the entire image.
- Local strategy: Additional points are selected close to the target point using a regular grid around it.
These point selection strategies are applied only during inference time.
Experiments
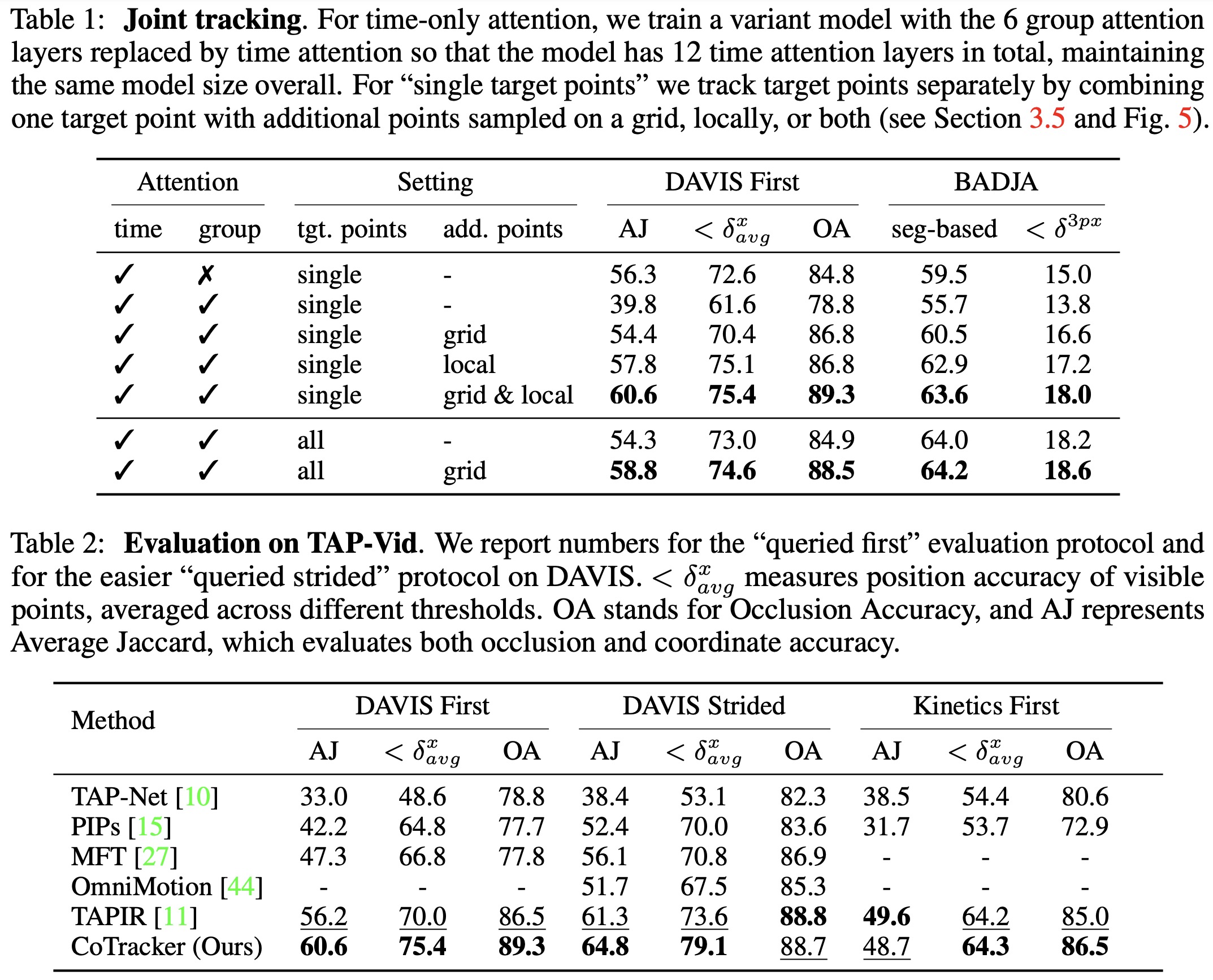
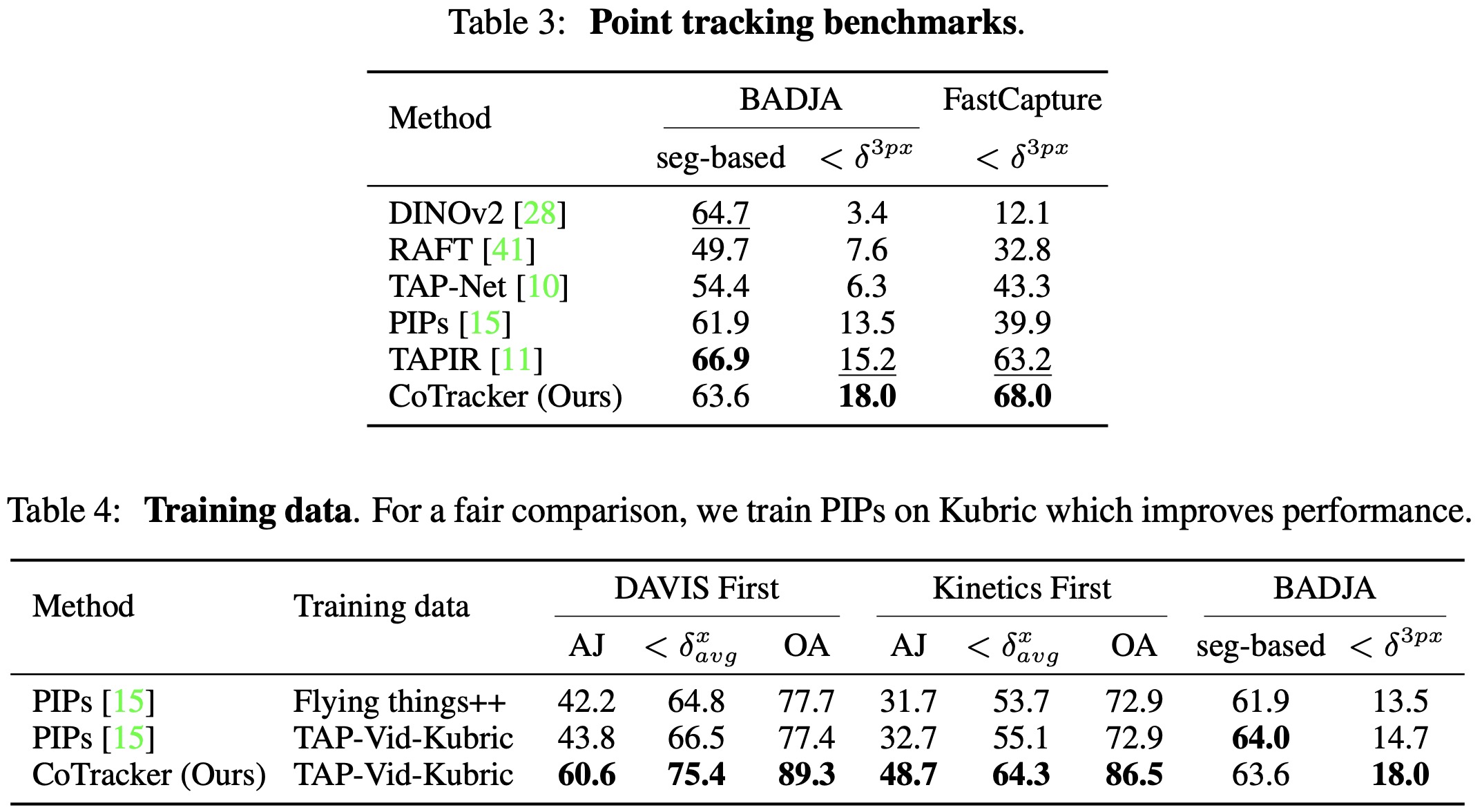

The models are trained on 32 V100 32GB GPUs.
- When considering both types of attention and using a combination of local and global grids, the model performs best. This is especially true when tracking multiple correlated target points. However, to maintain fairness in evaluation compared to prior work, only a ‘single target point’ protocol is used.
- When compared to existing state-of-the-art methods on four benchmark datasets, CoTracker is more effective in tracking points and their visibility. This supports the notion that long-term tracking of points in groups is advantageous compared to models focusing only on single points or short-term optical flow methods like RAFT.
- In terms of training data, the Kubric dataset is found to be better suited for CoTracker than the FlyingThings++ dataset. This is because Kubric is more realistic and better supports the model’s requirement for longer sequences, which is essential for training with sliding windows.
- Finally, the model gains substantial benefits from learning to propagate information between sliding windows during training. This feature is crucial for handling benchmark sequences that are often much longer than what the model was trained on.
The main limitations of the model are:
- Its sliding-window approach limits its ability to track points through long-term occlusions that exceed the size of a single window.
- The computational complexity of the transformer used in CoTracker is quadratic with respect to the number of points being tracked, which makes it challenging to apply the model to scenarios requiring dense prediction.