Paper Review: Contrastive Semi-supervised Learning for ASR

Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
The main idea of the approach
Cross-Entropy loss is replaced by a contrastive loss in the pseudo-labeling pre-training. The representations are optimized so that audio segments with the same pseudo-labels are closer and audio segments with different pseudo-labels are far from each other.
The method
The method itself consists of three parts.
Pseudo-labeling
They use a supervised ASR model to generate pseudo-labels. This model makes predictions on frames and produces the probabilities of chenones (context-dependent graphemes) using softmax.

Contrastive Semi-supervised Learning
Usually, for contrastive learning, positive and negative samples are selected based on the anchors: negative samples are selected randomly, and positive samples are based on the anchor. CSL makes it easier to choose positive and negative samples: in each mini-batch, pairs are positive if they have the same pseudo-labels and negative if their pseudo-labels are different.
The technical steps are the following:
- During CSL pre-training model consists of the encoder (encodes audio into latent representations) and the projection network (maps these representations into new space, in which contrastive loss works). The new representations are normalized by the unit length.
- A hybrid-NN model generates pseudo-labels.
- A span of audio with the same pseudo-labels is named a segment. A single time step is sampled from each segment to be used in the loss calculation.
- After the pre-training, the projection network is replaced with the prediction network for the supervised fine-tuning.
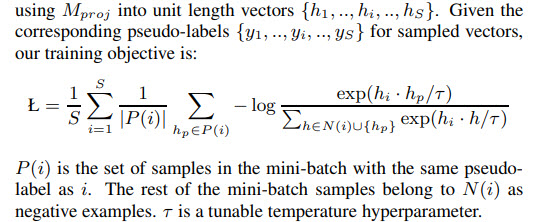
Label-Aware Batching (LAB)
Naturally, large mini-batches work better for contrastive losses as they have a more diverse set of negative samples. For CSL, it is necessary to have at least two instances of each class in the mini-batch.
To ensure it, the authors propose LAB:
- at first, we sample a rare label and add two random utterances with this label to the mini-batch
- the process is repeated until we have a complete mini-batch
- during training, gradients are aggregated over several mini-batches to perform a single model update for stable learning
The experiments
The data
The authors use two in-house data sources.
The first one has five-minute videos from Facebook in English and Italian. During training, segments of 10 seconds are used. To simulate a low-resource condition, they use 10 hours of labeled data for both teacher training and the final fine-tuning stage. Also, they test a more extreme setup with 1 hour.
Pre-training is done on 75000 hours of unlabeled videos, evaluating is done on 14 hours.
The second source contains recordings of crowd-sourced workers responding to artificial prompts with mobile devices.
They also collect two evaluation datasets to test out-of-domain generalization: 15hr of short message dictation and 13hr of long-form conversations of up to 144 second long.
The model
The encoder is VGG and 12 transformer blocks. For CSL pre-training, the projection network is a single hidden layer network of size 1024 and 128 output dimensions. Input speech features are 80 dimensional, speed perturbed Mel-scale log filterbank coefficients computed every 10ms over 25ms windows.
The results
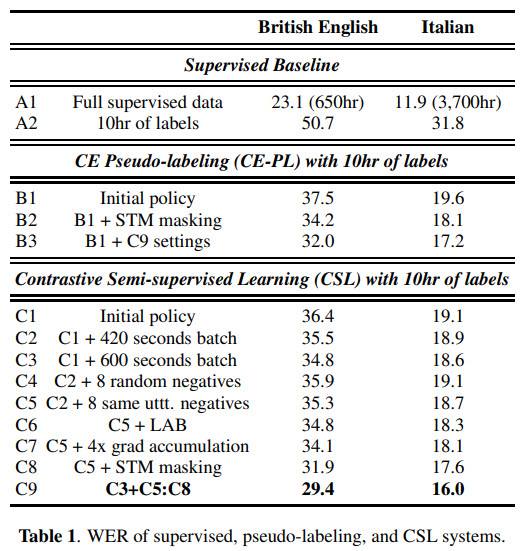
They report a lot of experiments showing the increased quality of the models by using different parameters. For example, we can see that increased batch size, gradient accumulation, and LAB all contribute. Using negative samples from the same utterance offers better WER than a random sampling of negative examples across utterances.
It is interesting that applying the same improvements to the CE-PL also improves performance.
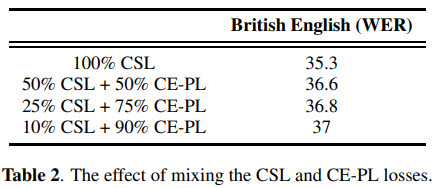
Combining (different losses on different mini-batches) CE-PL and CSL doesn’t improve the results.
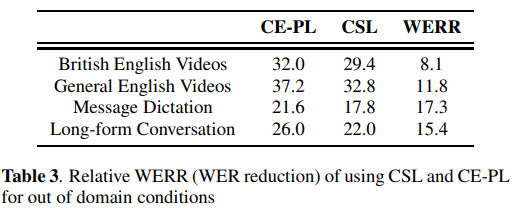
If we compare the performance on the out-of-domain data, we can see that CSL provided more stable and better representations.
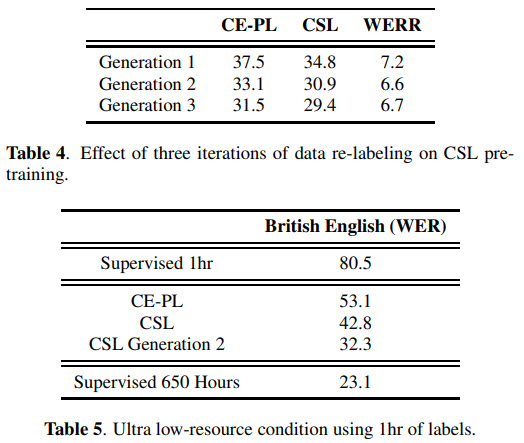
Iteratively running pseudo-labeling works well, but CSL gets less improvement because the learned representations were already better.
And in ultra-low resource conditions, CSL is much better.
I think that these results are interesting and very good. Contrastive learning already worked well in many cases, and successful implementation is ASR proves that this approach is promising.
paperreview asr contrastivelearning semisupervised speech