Paper Review: DarkBERT: A Language Model for the Dark Side of the Internet

This work presents DarkBERT, a new language model trained specifically on data from the Dark Web. Recognizing the unique language differences between the Dark Web and Surface Web, the researchers devised a method to filter and compile textual data from the Dark Web to train this model, addressing the challenges posed by its extreme lexical and structural diversity. Comparative evaluations with other popular language models, including the original BERT, indicate that DarkBERT performs better in various use cases, making it a useful tool for future Dark Web research.
DarkBERT Construction
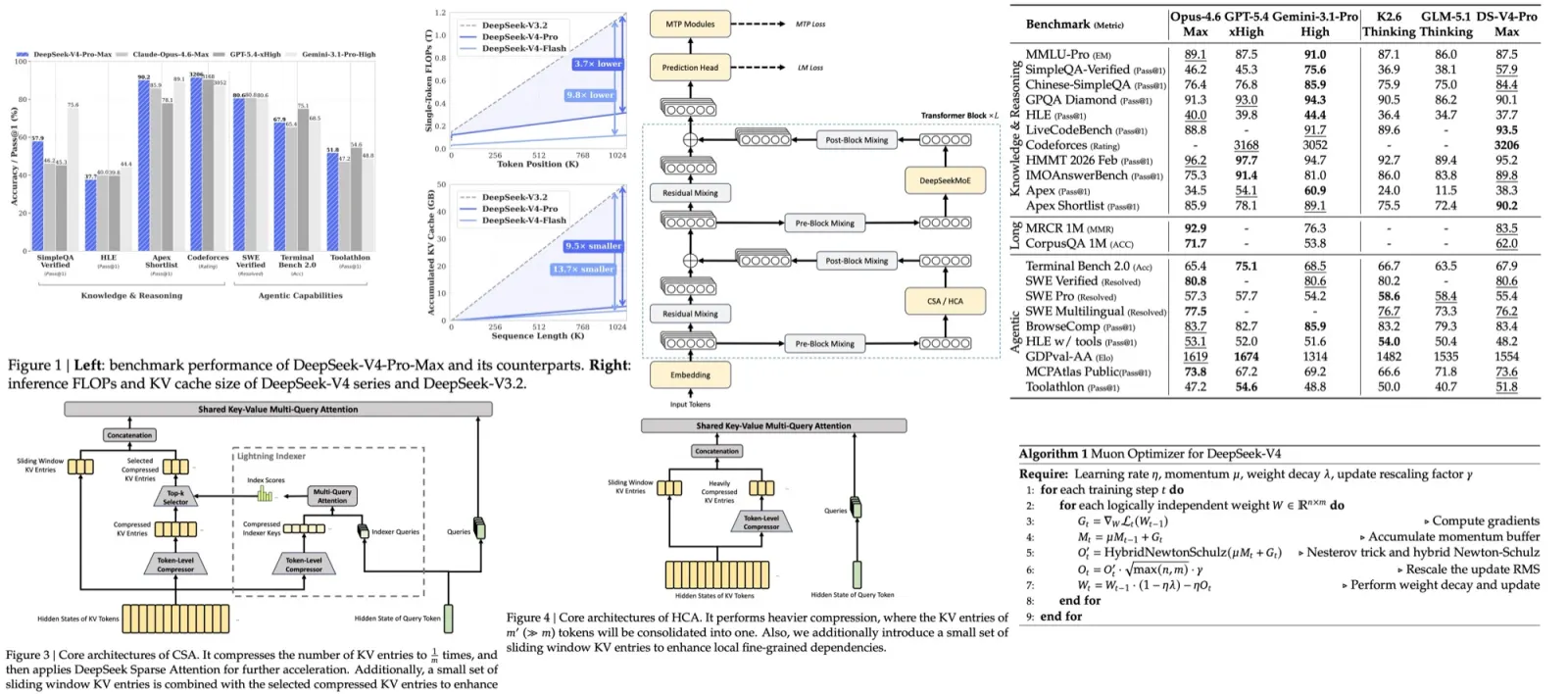
Data Collection

To pretrain DarkBERT, researchers created a large text corpus from the Dark Web. They started by collecting seed addresses from Ahmia and public repositories listing onion domains. From there, they crawled the Dark Web, expanding their domain list and storing the HTML title and body elements of each page as a text file. They classified each page’s primary language using fastText, selecting only English pages as the majority of Dark Web content is in English. This process resulted in a collection of around 6.1 million pages.
Data Filtering and Text Processing
Despite the large text corpus collected for DarkBERT, some of the data, such as error messages or duplicate pages, had no useful information. The researchers implemented three measures to refine the dataset: removal of low-information pages, category balancing, and deduplication. They also took precautions to ensure the model did not learn from sensitive information. Although past research suggested that models pretrained on sensitive data could not easily extract such information, the researchers didn’t rule out the possibility of more sophisticated attacks. Therefore, they preprocessed the corpus to mask identifiers or entirely remove certain types of sensitive text, to address these ethical considerations.
DarkBERT Pretraining

To evaluate the effect of text preprocessing on DarkBERT’s performance, the researchers constructed two versions of the model: one using raw text data and another with preprocessed text. They leveraged an existing model, RoBERTa, for pretraining to save computational resources and retain general English representation. RoBERTa was chosen as it omits the Next Sentence Prediction (NSP) task, which can be beneficial when training on Dark Web data where sentence-like structures are less common. The Dark Web pretraining corpus was inputted into the ‘roberta-base’ model from the Hugging Face library. To ensure compatibility, the same byte-pair encoding (BPE) tokenization vocabulary used in the original RoBERTa model was used. The only difference between the two versions of DarkBERT was the pretraining corpus (raw vs. preprocessed), with all other factors, such as training hyperparameters, being equally set.
Evaluation: Dark Web Activity Classification
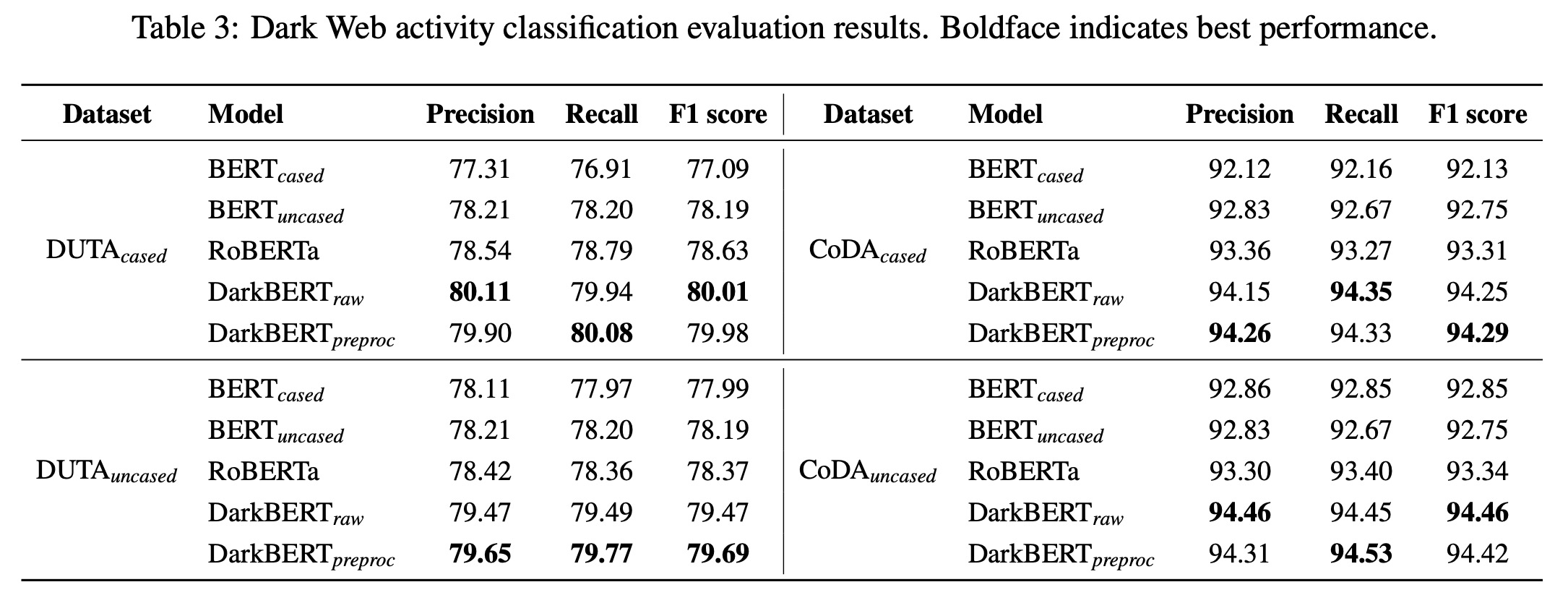
The study found that DarkBERT outperformed other language models across both datasets and their variants, though BERT and RoBERTa demonstrated performances relatively close to DarkBERT’s. This aligns with previous findings that BERT adapts well to other domains, and RoBERTa slightly outperforms BERT. All models performed better on the CoDA dataset compared to the DUTA dataset, likely due to issues with the latter’s categories and duplicate texts. Further examination of the activity classification results on the CoDA dataset revealed that DarkBERT versions generally had the best performance across most categories. However, for categories like Drugs, Electronics, and Gambling, all four models performed similarly, likely due to the high similarity of pages in these categories, making classification easier despite the Dark Web’s language differences.
Use Cases in the Cybersecurity Domain
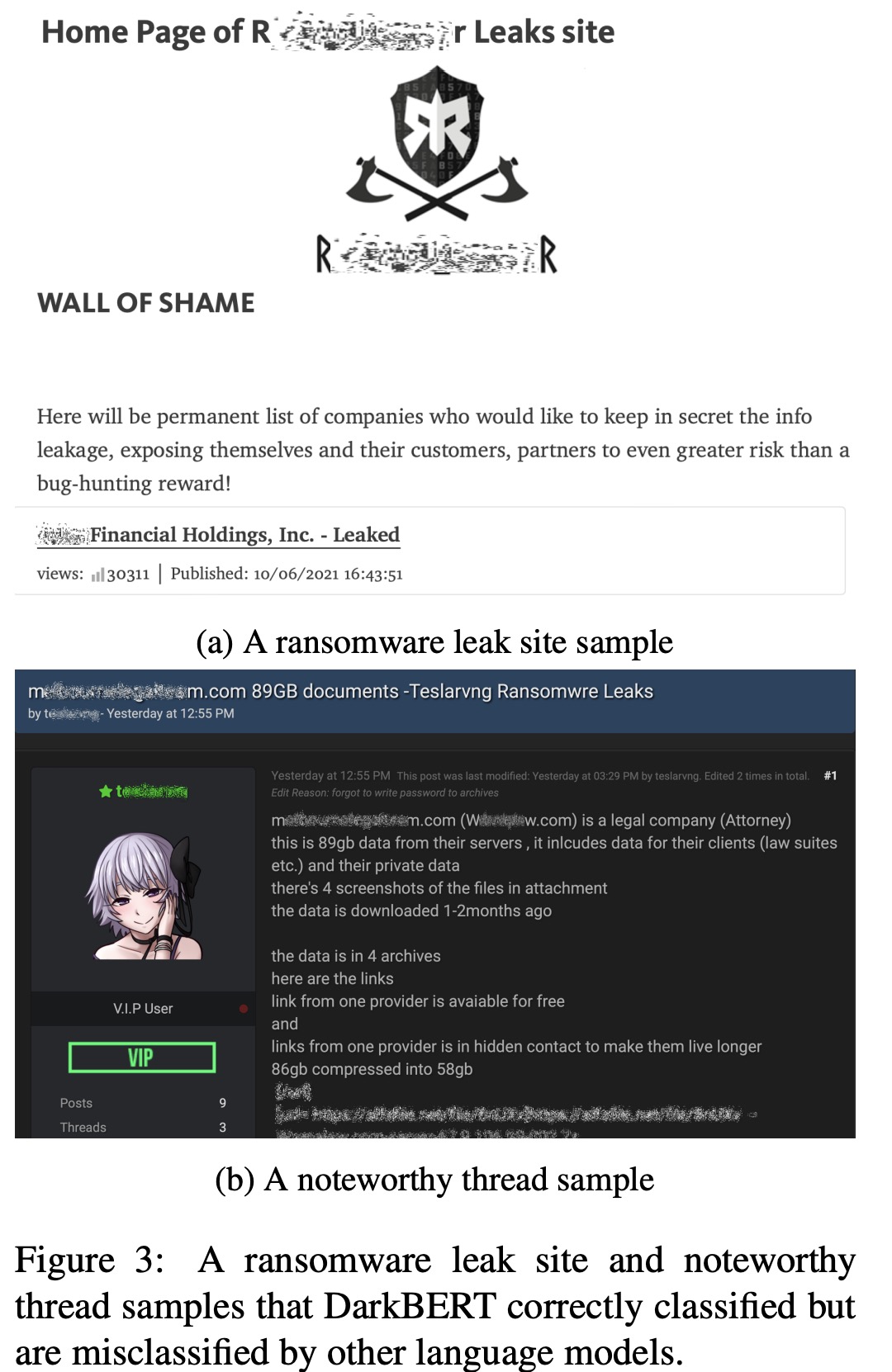
Ransomware Leak Site Detection
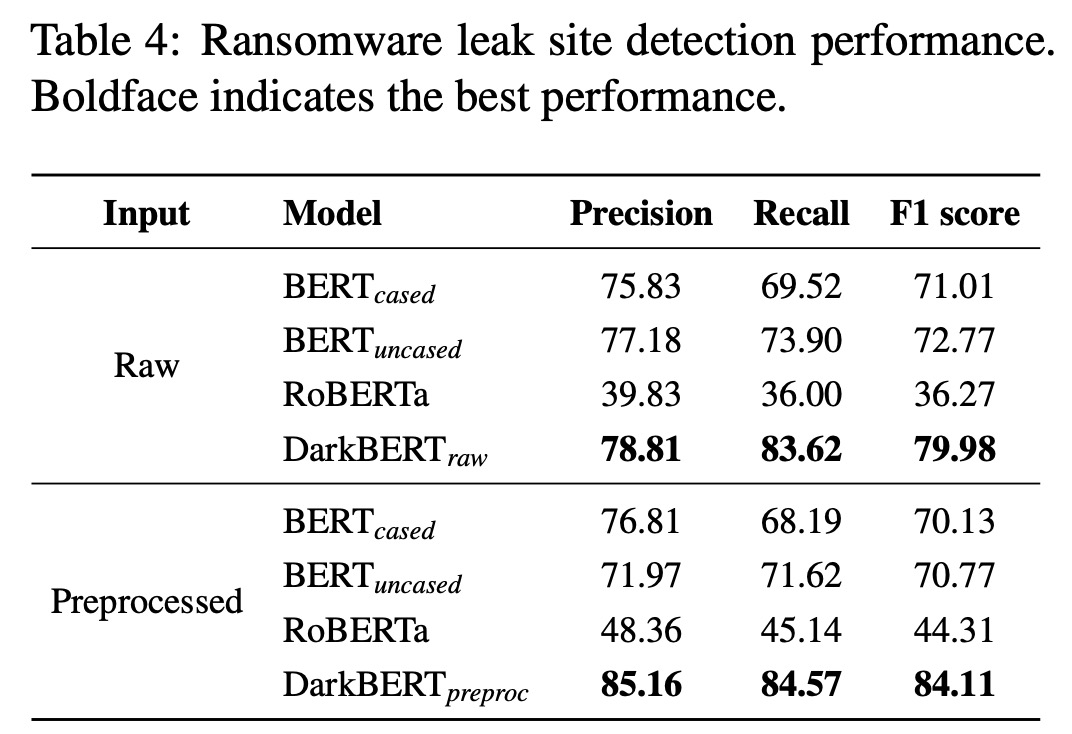
The researchers explored ransomware leak sites that publish confidential data from organizations. They formulated the detection of these sites as a binary classification problem and compared the performance of pre-trained language models in identifying these sites. They collected data from the leak sites of 54 popular ransomware groups over two years (May 2020 to April 2022). A maximum of three pages from each site with different page titles were randomly selected and labeled as positive examples. For negative data, they chose Dark Web pages with content similar to leak sites, specifically those classified under the activity categories Hacking, Cryptocurrency, Financial, and Others, as these were found to be more similar to leak sites in a pilot study. The final training dataset comprised 105 positive and 679 negative examples, and training was conducted using 5-fold cross validation.
DarkBERT demonstrated superior performance over other language models in understanding the language used in underground hacking forums on the Dark Web. Even though DarkBERT uses RoBERTa as a base model, RoBERTa’s performance significantly dropped compared to other models. Notably, the version of DarkBERT using preprocessed input outperformed the one using raw input. This underscores the importance of text preprocessing in reducing unnecessary information. Lengthy words or cryptocurrency addresses, replaced with mask identifier tokens in the preprocessed input, could produce uninformative tokens in the raw input and affect task performance.
Noteworthy Thread Detection
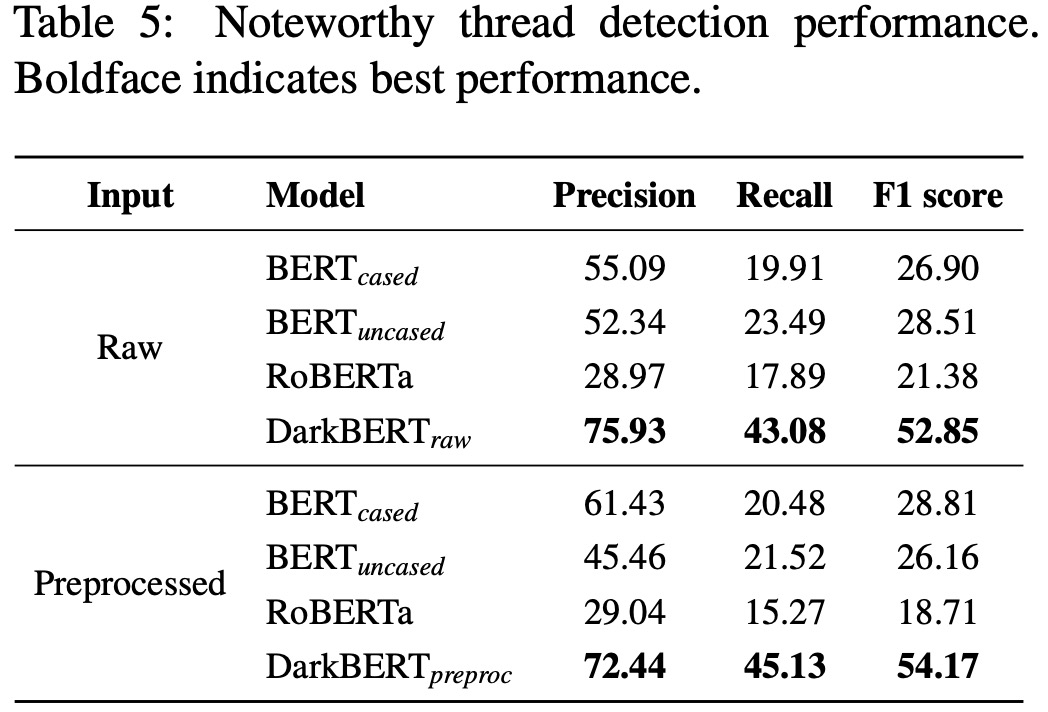
Dark Web forums, often used for illicit information exchange, require monitoring for potentially harmful threads. The manual review of these threads is time-consuming, thus automating this process can help security experts. The researchers formulated this as a binary classification problem to predict whether a given forum thread is noteworthy. They compared the performance of DarkBERT with baseline models BERT and RoBERTa.
The task of identifying noteworthy threads is subjective, hence they focused on activities in hacking forums with potentially widespread damage. Two researchers from a cyber threat intelligence company helped set annotation guidelines for noteworthy threads, which include sharing confidential company or private individual data and distributing critical malware or vulnerabilities.
The researchers used RaidForums, one of the largest hacking forums, as their data source and collected 1,873 forum threads posted between July 2021 and March 2022. The annotators achieved substantial agreement with a Cohen’s Kappa of 0.704 on the first 150 threads. After resolving disagreements, the final dataset comprised 249 noteworthy (positive) and 1,624 non-noteworthy (negative) threads.
DarkBERT outperforms other language models in identifying noteworthy threads on the Dark Web, in terms of precision, recall, and F1 score. However, compared to previous evaluations and tasks, the performance of DarkBERT in real-world noteworthy thread detection is not as high, which is likely due to the difficulty of the task itself. Despite this, the results still demonstrate DarkBERT’s potential for Dark Web-specific tasks.
The performance of DarkBERT with both raw and preprocessed inputs are similar. This is because thread content is generally shorter than standard webpage content, and sensitive information like URLs and email addresses often influence the noteworthiness of threads. Such information is masked for preprocessed inputs, making noteworthy and non-noteworthy threads look similar to the language models, which could affect the performance of this task.
Threat Keyword Inference


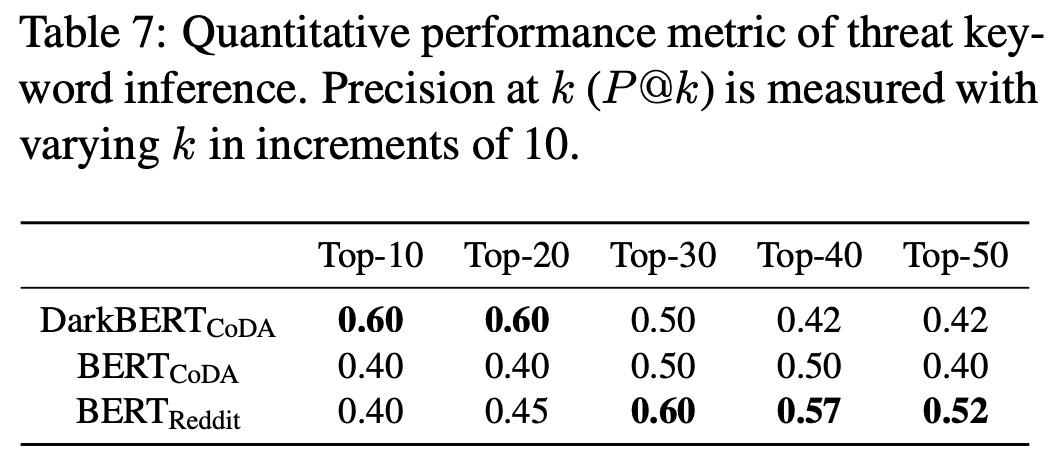
In this section, the authors illustrate how DarkBERT can be used to generate a set of keywords semantically related to threats and drug sales on the Dark Web, using the fill-mask functionality.
The authors tested DarkBERT and BERTReddit (a BERT variant fine-tuned on a subreddit corpus about drugs) by masking the word “MDMA” in the title phrase of a sample drug sales page from the Dark Web. The results showed that DarkBERT suggested drug-related words and a word closely related to drugs, while BERTReddit suggested professions such as singer, sculptor, and driver, which are not relevant to drugs. This stems from the fact that the preceding word, “Dutch”, is often followed by a vocational word on the Surface Web.
In this section, the authors compared three language models: DarkBERTCoDA, BERTCoDA, and BERTReddit for their ability to generate semantically related keywords to a given drug name. The models were fine-tuned on different datasets: DarkBERTCoDA and BERTCoDA on a subset of CoDA documents classified as drugs, and BERTReddit on a subreddit corpus about drugs. The results indicated that DarkBERTCoDA outperformed BERTReddit for k values from 10 to 20, but was overtaken for higher k values.
Despite DarkBERTCoDA’s better performance when k is small, the authors note that the ground truth dataset contains euphemisms mainly derived from the Surface Web, and the words inferred by DarkBERTCoDA as semantically related are not included in the dataset. For example, “Tesla” and “Champagne” are drug names often seen on the Dark Web, but are not recognized as such in the ground truth dataset used. However, both DarkBERTCoDA and BERTReddit were able to detect words like “crystal” and “ice” because they are used in both the Surface Web and the Dark Web.
paperreview deeplearning nlp pretraining llm pytorch