Paper Review: Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
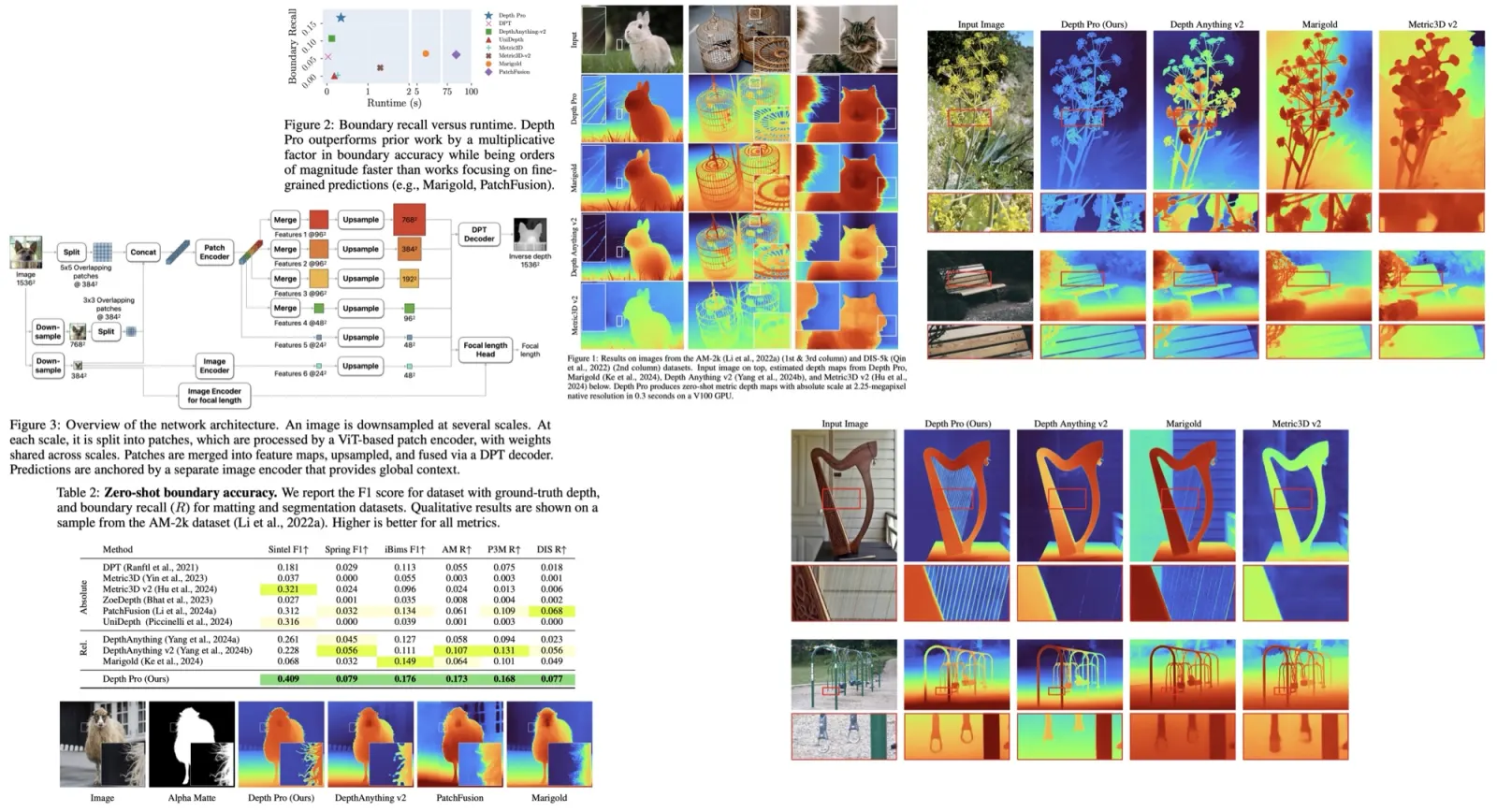
Depth Pro is a foundation model designed for zero-shot metric monocular depth estimation, producing high-resolution depth maps with sharp details and accurate scale, without needing metadata like camera intrinsics. It generates 2.25-megapixel depth maps in 0.3 seconds on V100 GPU. Key innovations include a multi-scale vision transformer for dense prediction, a training approach combining real and synthetic data for high accuracy, new evaluation metrics for boundary accuracy in depth maps, and SOTA focal length estimation from a single image. Depth Pro surpasses previous models across various performance metrics.
The approach
The architecture
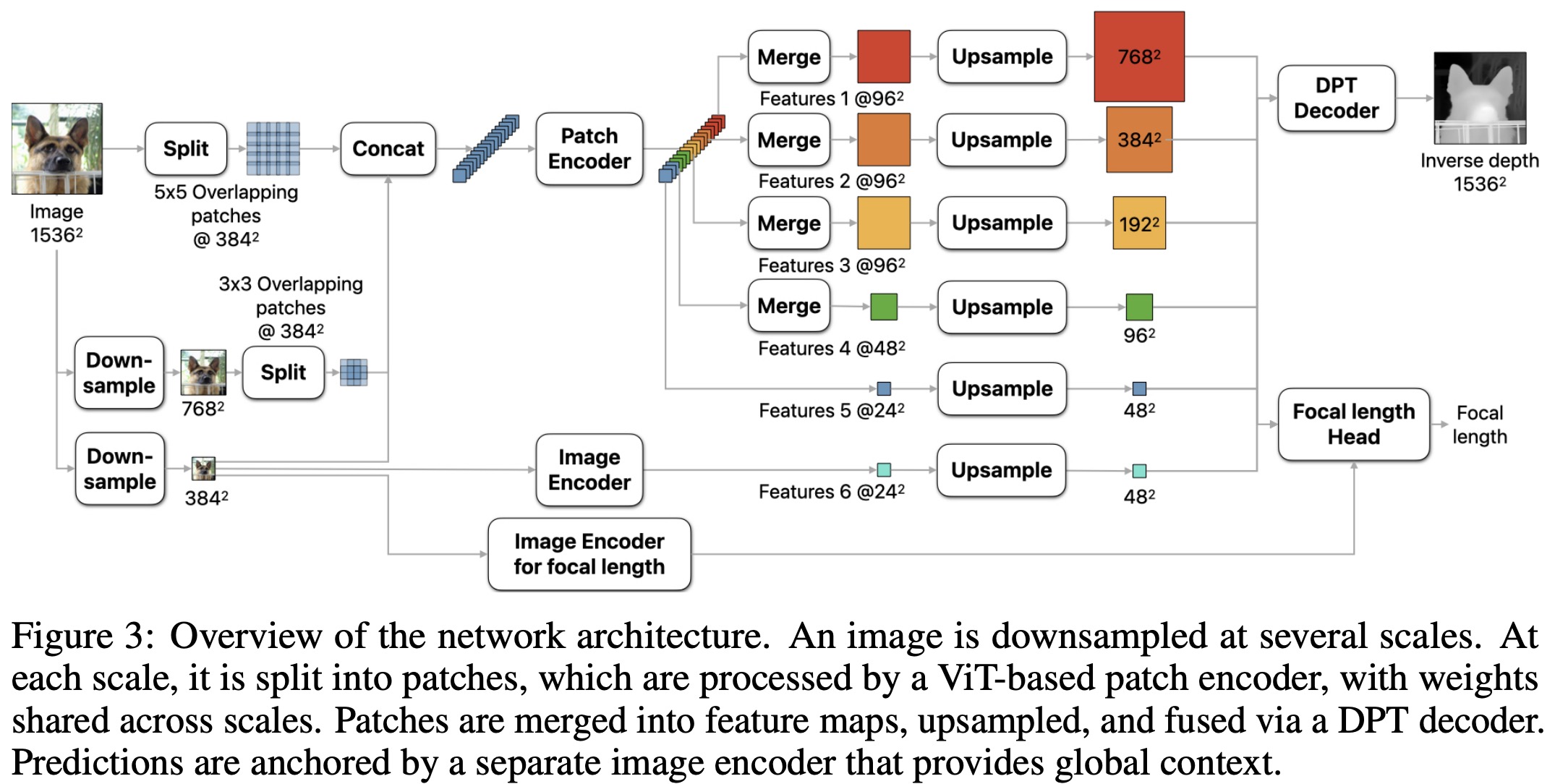
Depth Pro uses ViT encoders to process image patches at multiple scales and fuse the predictions into a single high-resolution depth map. It employs two ViT encoders: a patch encoder for scale-invariant learning and an image encoder for global context. The network operates at a fixed resolution of 1536×1536 to balance large receptive fields with stable runtimes and prevent memory errors. The input image is downsampled and divided into 384×384 patches, with overlapping patches at finer scales to avoid seams. These patches are processed independently, enabling parallelization and computational efficiency. The network’s patch-based design is more efficient than scaling the ViT directly, as multi-head self-attention’s complexity scales quadratically with input pixels.
Sharp monocular depth estimation
The training process focuses on predicting a metric depth map from an inverse depth image, scaled by the camera’s field of view. The model is trained using multiple objectives, prioritizing areas close to the camera to enhance visual quality, especially for tasks like novel view synthesis. The training uses both real-world and synthetic datasets, with a focus on canonical inverse depth to handle potentially noisy real-world data. A two-stage training curriculum is applied: the first stage focuses on generalization across domains using a mix of all labeled datasets, while the second stage fine-tunes on synthetic datasets to sharpen boundaries and capture finer details.
Key loss functions include MAE for depth predictions, as well as gradient and Laplace errors to refine boundary details. The training leverages a combination of first- and second-order derivative losses to improve sharpness, particularly in synthetic data.
Focal length estimation
To address potential inaccuracies or missing EXIF metadata in images, Depth Pro includes a focal length estimation head. This small convolutional module uses frozen features from the depth estimation network and additional features from a separate ViT image encoder to predict the horizontal angular field of view. The focal length head is trained separately from the depth estimation network, using L2 as the loss function. This separation avoids conflicts between depth and focal length objectives and allows for training on a different set of datasets: it excludes narrow-domain, single-camera datasets and incorporates large-scale image datasets that provide focal length supervision but lack depth supervision.
Experiments
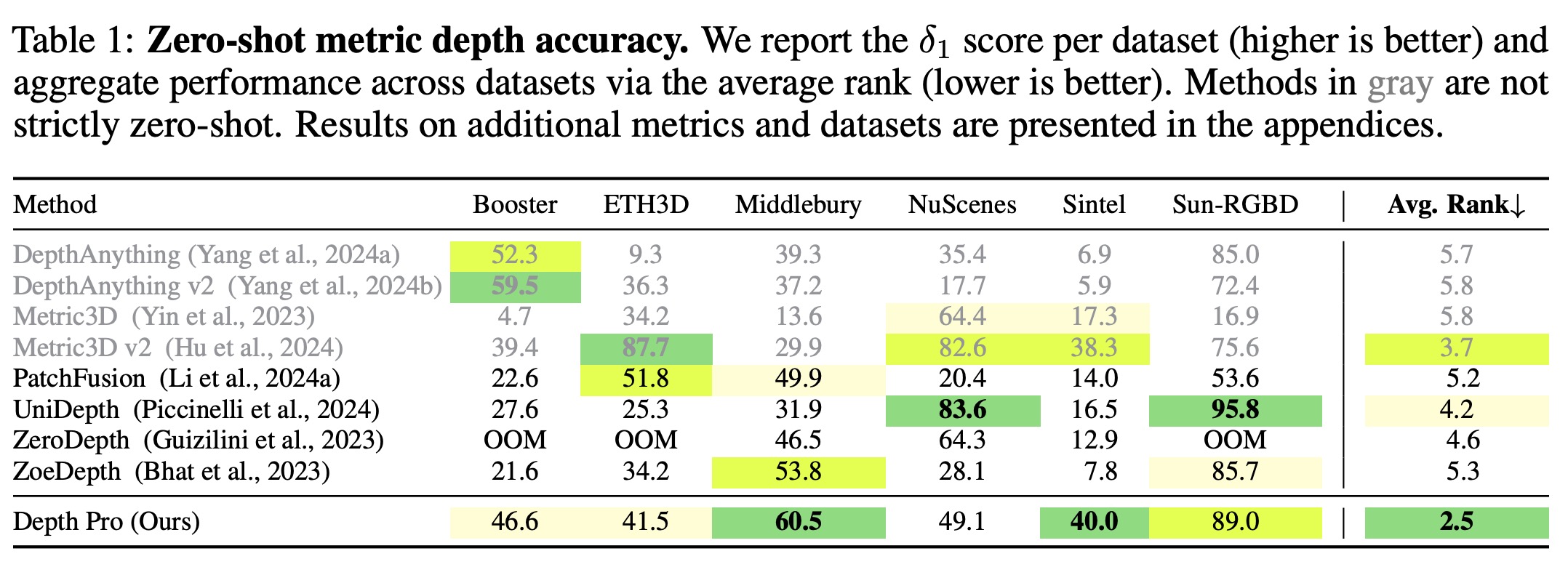
Depth Pro outperforms many competitors, consistently ranking high across various datasets like Booster, Middlebury, SunRGBD, ETH3D, nuScenes, and Sintel. The evaluation uses the δ1 metric, which measures the percentage of inlier pixels where predicted and ground-truth depths are within 25% of each other.
Other metrics, such as AbsRel, Log10, δ2, δ3, and point-cloud metrics confirm prior findings of domain bias in some models, like Depth Anything and Metric3D, which rely on domain-specific models or crop sizes, violating the zero-shot premise. Depth Pro, in contrast, shows strong generalization and consistently ranks among the top approaches, achieving the best average rank across datasets.
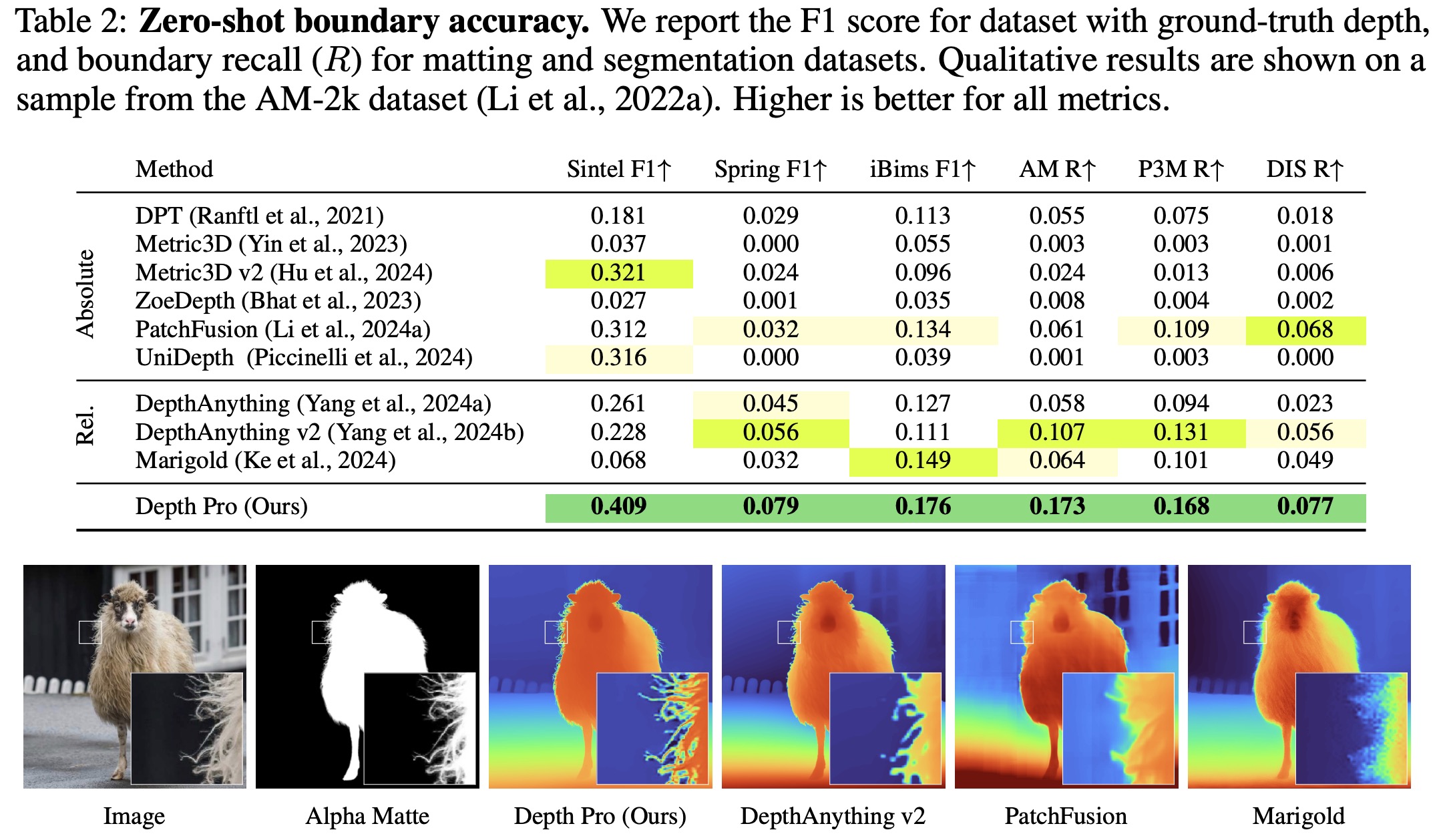
Depth Pro outperforms all baselines in boundary accuracy across datasets, particularly excelling in capturing sharp boundaries and thin structures like hair and fur. Depth Pro’s recall is consistently higher than its competitors, even when compared to diffusion-based models like Marigold, which is trained on billions of images, or variable-resolution approaches like PatchFusion. Moreover, Depth Pro is significantly faster in runtime than Marigold and PatchFusion while maintaining superior accuracy.
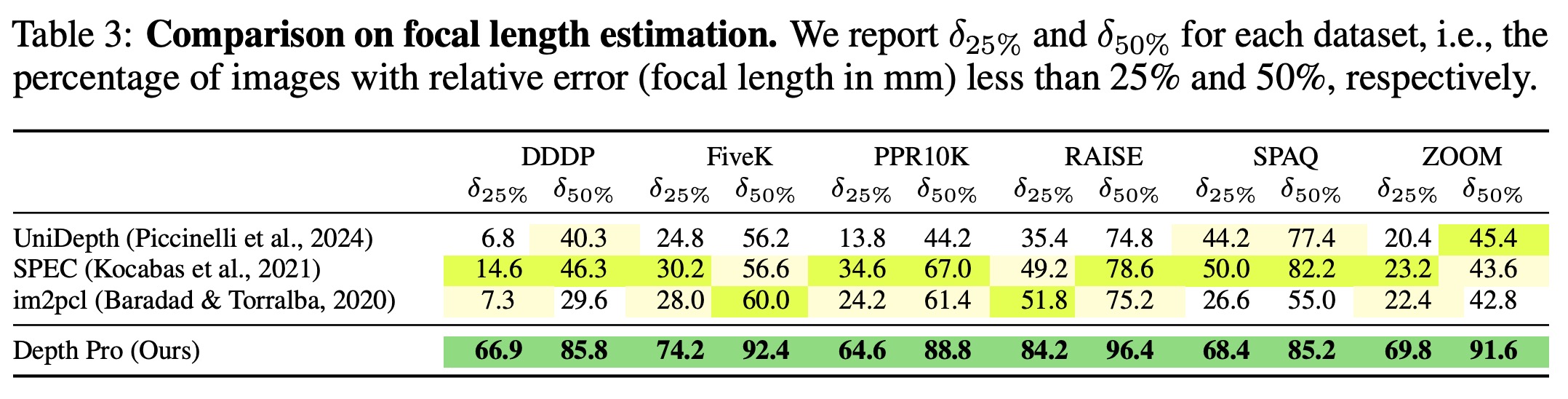
The authors address the lack of comprehensive evaluations for focal length estimators on in-the-wild images by curating a zero-shot test dataset. This dataset includes diverse image collections with intact EXIF data from sources like FiveK (SLR camera photos), SPAQ (mobile phone photos), PPR10K (portrait images), and ZOOM (scenes with varying zoom levels). Depth Pro is evaluated against state-of-the-art focal length estimators, and the results show that it outperforms competitors across all datasets. For instance, on the PPR10K dataset, 64.6% of Depth Pro’s predictions have a relative estimation error below 25%, compared to only 34.6% for the second-best method, SPEC.
Limitations
The model is limited in dealing with translucent surfaces and volumetric scattering, where the definition of single pixel depth is ill-posed and ambiguous.
paperreview deeplearning cv depthestimation