Paper Review: End-to-End Object Detection with Transformers
Code link (PyTorch)

A paper on object detection by Facebook!
They treat this task as a direct set prediction problem and use a transformer.
Their basic model gets 42 AP on COCO!
Baseline model trains 3 days on 16 V100!
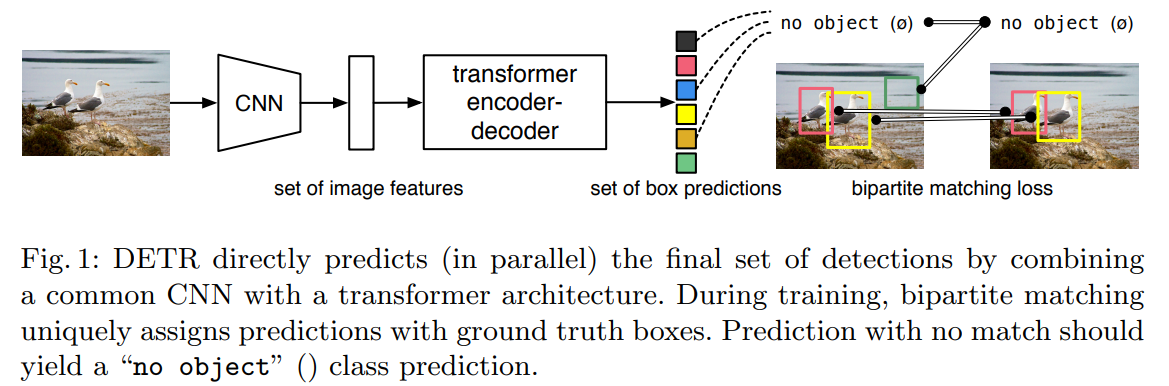
DETR predicts all objects at once and trains on a set loss function which performs bipartite matching between predicted and ground-truth objects. There is no need for anchors or non-maximal suppression.
Important no note: DETR is better than Faster R-CNN on large objects but worse on small objects.
The model requires (quoting) extra-long training schedule and needs auxiliary losses.
The model can be extended to other tasks, like segmentation.
DETR Model
For direct set predictions in detection, we need two things: a set prediction loss that forces unique matching between predicted and ground-truth boxes and an architecture that predicts a set of objects and models their relation in a single pass.
Object detection set prediction loss
DETR predicts a fixed-size set of N predictions in a single path through the decoder. N is usually set to be very high.
The loss produces an optimal bipartite matching between predicted and ground-truth objects and then optimizes losses for bounding boxes.
y - ground truth (set), y-hat - predictions (also set). As the number of predictions is intentionally higher than the number of true labels, y is padded with “no object” values.
To find a bipartite matching between these two sets, we search for a permutation of elements with the lowest cost.
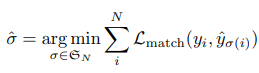
Lmatch - pair-wise matching cost between ground truth and prediction. It is computed efficiently with the Hungarian algorithm.

This matching cost takes into account the class and similarity between bounding boxes.
This is similar to match proposals or anchors to ground truth, but here we look for matching without duplicates.
Now we need to calculate Hungarian loss for all pairs, which were matched in the previous step. For “no object”, class log-probability is divided by 10 to account for class imbalance.
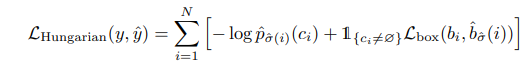
Bounding box loss
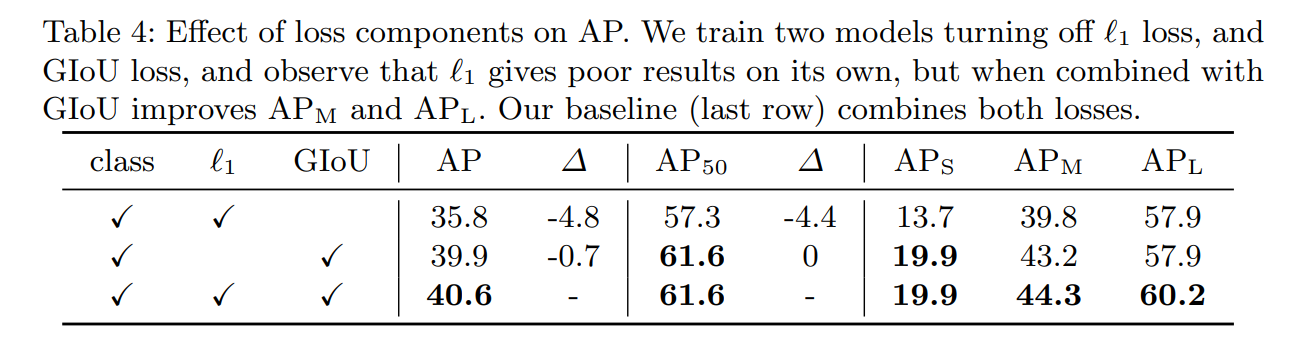
Using l1 loss isn’t a good idea for comparing boxes as the loss will have different scales for small and big boxes. So they use a combination of L1 and IoU.
Lambdas are hyperparameters. Two parts of the loss are normalized by the number of objects in the batch.
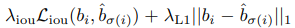
DETR Architecture
CNN backbone + transformer + FNN.
Backbone: any backbone can be used. Usually, the resulting feature maps have 2048 channels, and height and width are 32 times less than in the original images.
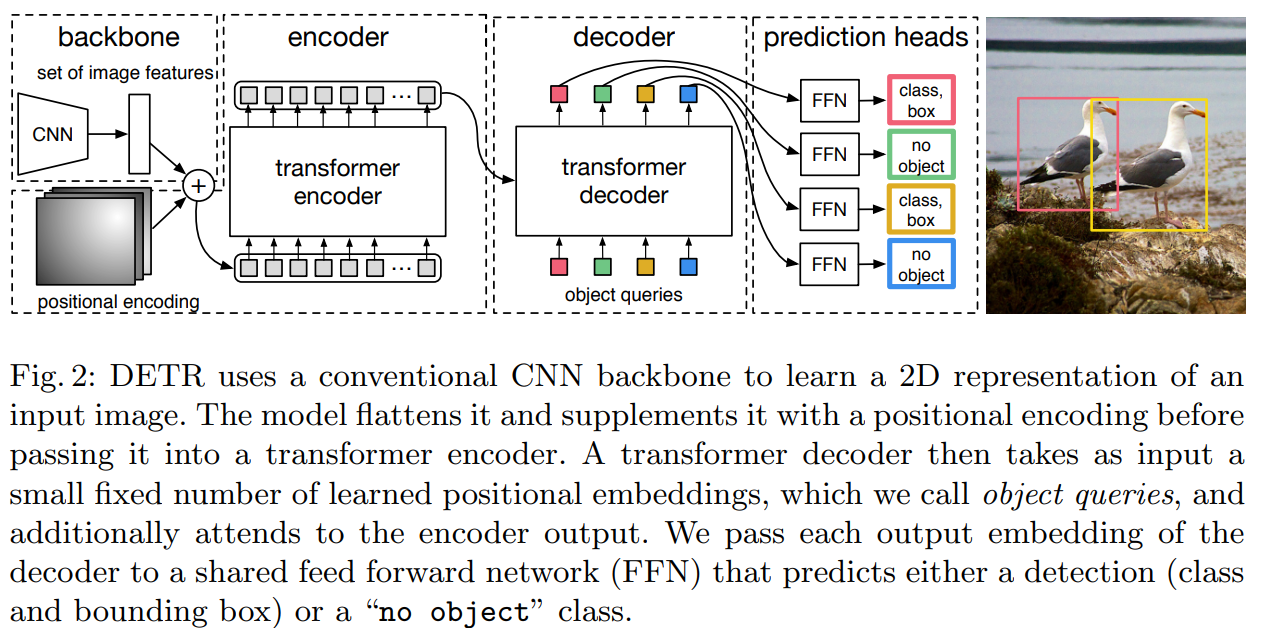
Transformer.
Encoder and decoder are permutation-invariant.
Encoder. At first 1x1 convolution to decrease the number of channels to d. The encoder needs a sequence as an input, so spatial dimensions are collapsed, and we have feature map dxHW. The ncoder has multi-head attention + FNN and positional embeddings are added in each attention layer.
Decoder. It decodes objects in parallel at each decoder layer. The decoder gets N embeddings - they are learned positional encodings (object queries) and added at each attention layer.
Output embeddings are independently decoded into box coordinates and class labels using FNN Using self- and encoder-decoder attention over these embeddings, the model globally reasons about all objects together using pair-wise relations between them while being able to use the whole image as context.
FNN. The final prediction is made using a 3-layer perceptron with ReLU. The FFN predicts the normalized center coordinates, height, and width of the box, and the linear layer predicts the class label using a softmax function.
Auxiliary decoding losses
Prediction FFNs and Hungarian loss are added after each decoder layer. All predictions FFNs share their parameters. An additional shared layer-norm is used to normalize the input to the prediction FFNs from different decoder layers.
The Experiments
COCO dataset.
AdamW, initial transformer LR 10^-4, backbone’s - 10^-5, weight decay 10^-4. Tried ResNet-50 and ResNet-101 as backbones - DETR and DETR-101.
Another approach: increase the feature resolution by adding a dilation to the last stage of the backbone and removing a stride from the first convolution of this stage - DETR-DC5 and DETR-DC5-R101. This improved performance for small objects but lead to a 2x increase in computation cost.
Scale augmentation - resizing images so that shortest side is in range 480-800 and longest is <=1333.
Random crop augmentation (+1 AP).
Model sometimes predicts empty class. Replacing them with the second highest scoring class gives +2 AP.
300 epochs - 3 days on 16 V100. Training for 500 epochs gives + 1.5 AP. :pepe_wide_eyes:
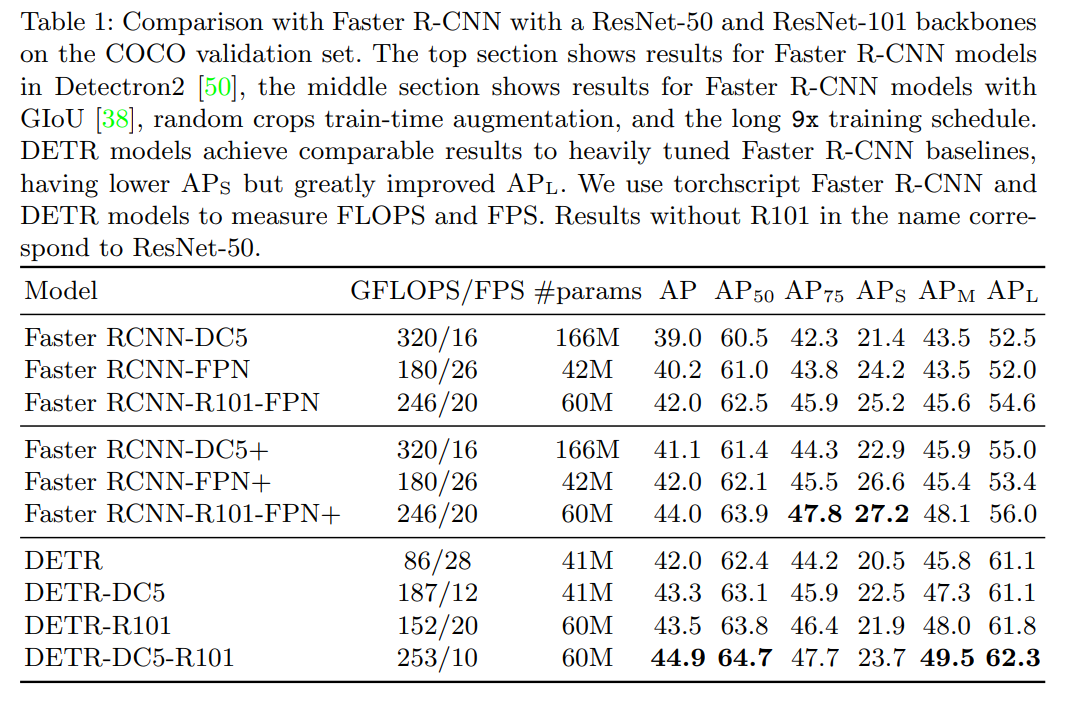
Comparison with Faster R-CNN
They tried to improve Faster R-CNN:
- adding generalized IoU to box losses
- random crop augmentations
- longer training
In this table, Faster R-CNN is trained 3x longer than usual. “+” sign means it was trained 9x longer (109 epochs).
DETR is better at most variants of AP except AP75 and APs
Ablation
By using global scene reasoning, the encoder is important for disentangling objects.

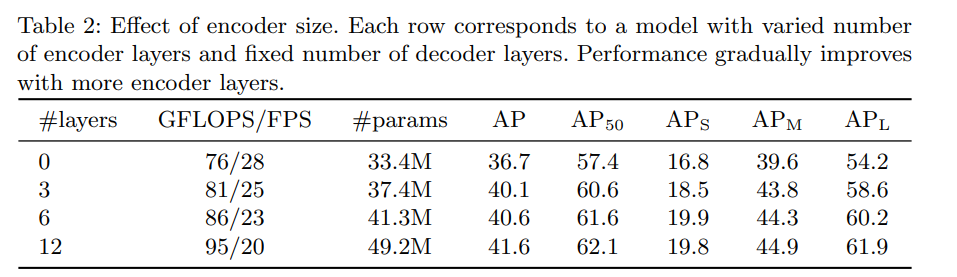
Increasing the number of decoder layers helps.

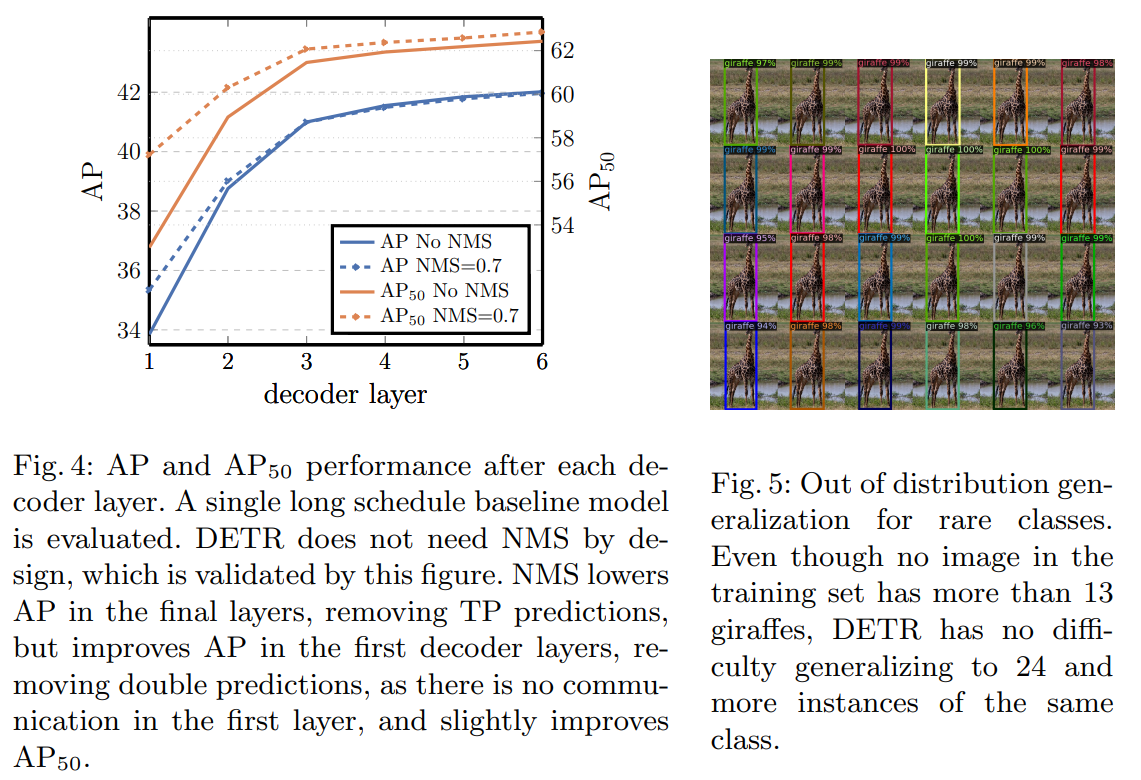
FFN inside transformers can be seen as 1 × 1 convolutional layers, making encoder similar to attention augmented convolutional networks. Without it, we have a decrease of 2.3 AP.
Positional encoding:
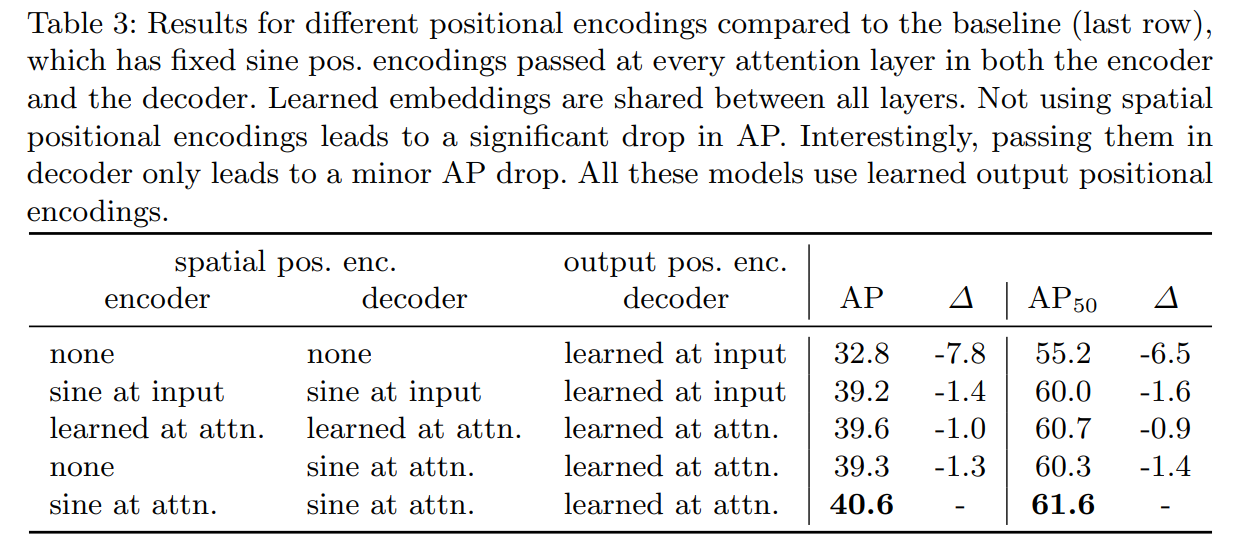
Loss ablation:
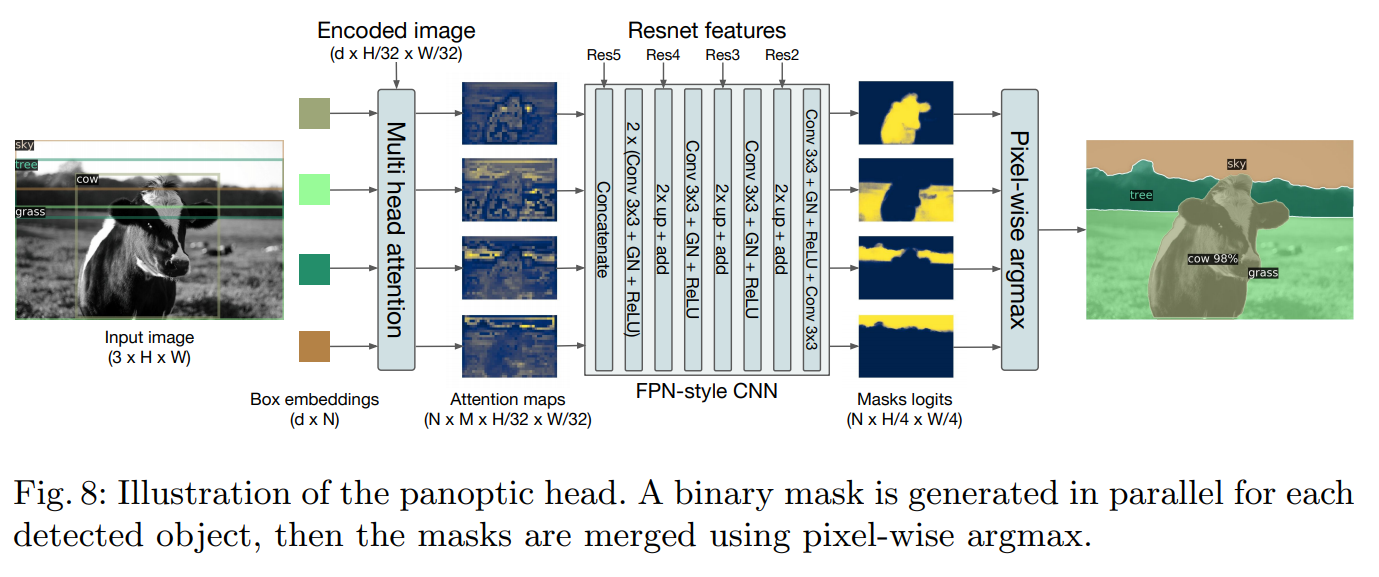
DETR for panoptic segmentation
We can simply add mask head after decoder.
At the training, it is still necessary to predict boxes - for hungarian matching.
To predict the final panoptic segmentation, we simply use an argmax over the mask scores at each pixel. This way, there will be no overlaps.
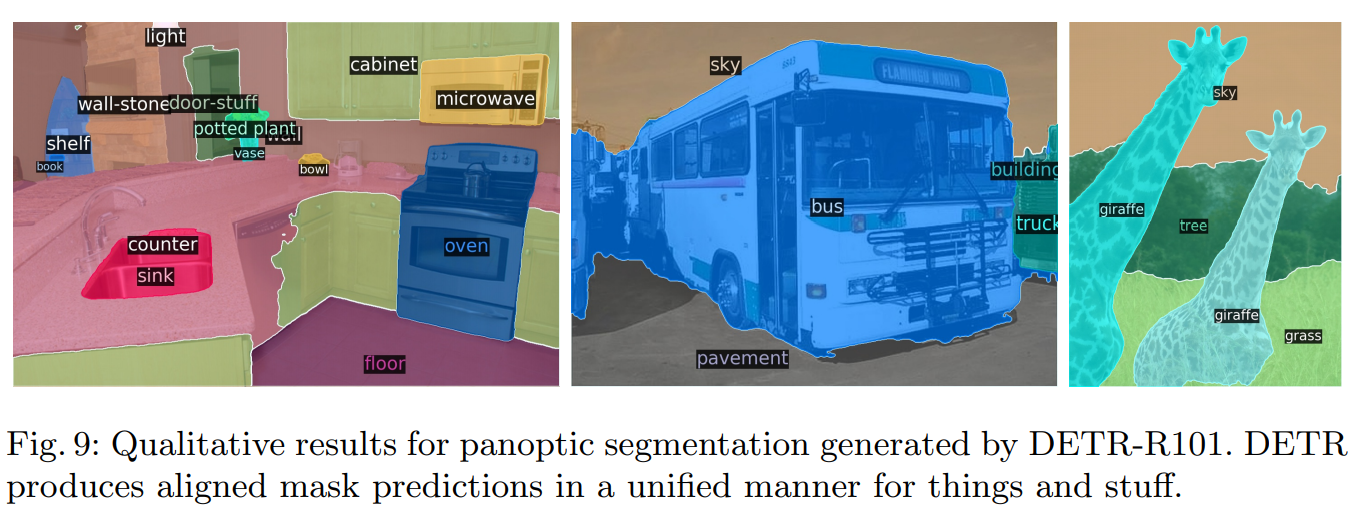
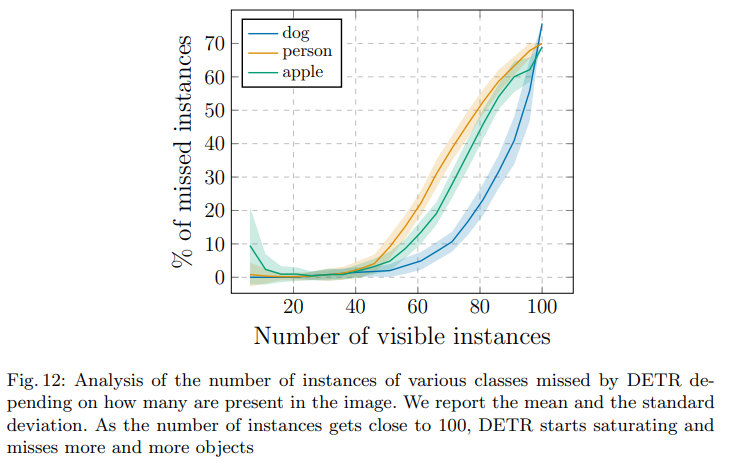
But don’t be too encouraged with the results. For now, the more objects are on the image, the worse is the model: