Paper Review: Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion

Producing quality segmentation masks in computer vision is a key challenge, especially for zero-shot segmentation across various image styles without specific training. The new method utilizes self-attention layers in pre-trained stable diffusion models, which have learned to recognize objects, to address this challenge. This approach involves an iterative merging process using KL divergence to combine attention maps into valid segmentation masks. It requires no additional training or language input and significantly outperforms previous state-of-the-art unsupervised zero-shot methods in pixel accuracy and mean IoU on the COCO-Stuff-27 dataset.
Method
Stable Diffusion Model Review

The stable diffusion model operates by adding and then removing Gaussian noise from images. It enhances traditional diffusion models with an encoder-decoder and U-Net design, incorporating self-attention and cross-attention mechanisms in its Transformer layers. This model compresses images into a latent space and then decompresses them, with diffusion processes occurring in this latent space.
The U-Net architecture consists of modular blocks with ResNet and Transformer layers. The self-attention layer within these blocks is hypothesized to contain inherent object grouping information, which can be used for producing segmentation masks without text inputs. Attention maps in the model capture semantic correlations and focus on object groups, with their resolution affecting the granularity of object grouping.
For experimentation, pre-trained models from Huggingface are adapted to extract attention maps for existing images. This involves using an unconditioned latent and running the diffusion process only once with a large time-step value. The goal is to aggregate weights from different resolutions and develop a method to merge all attention maps into valid segmentation.
DiffSeg
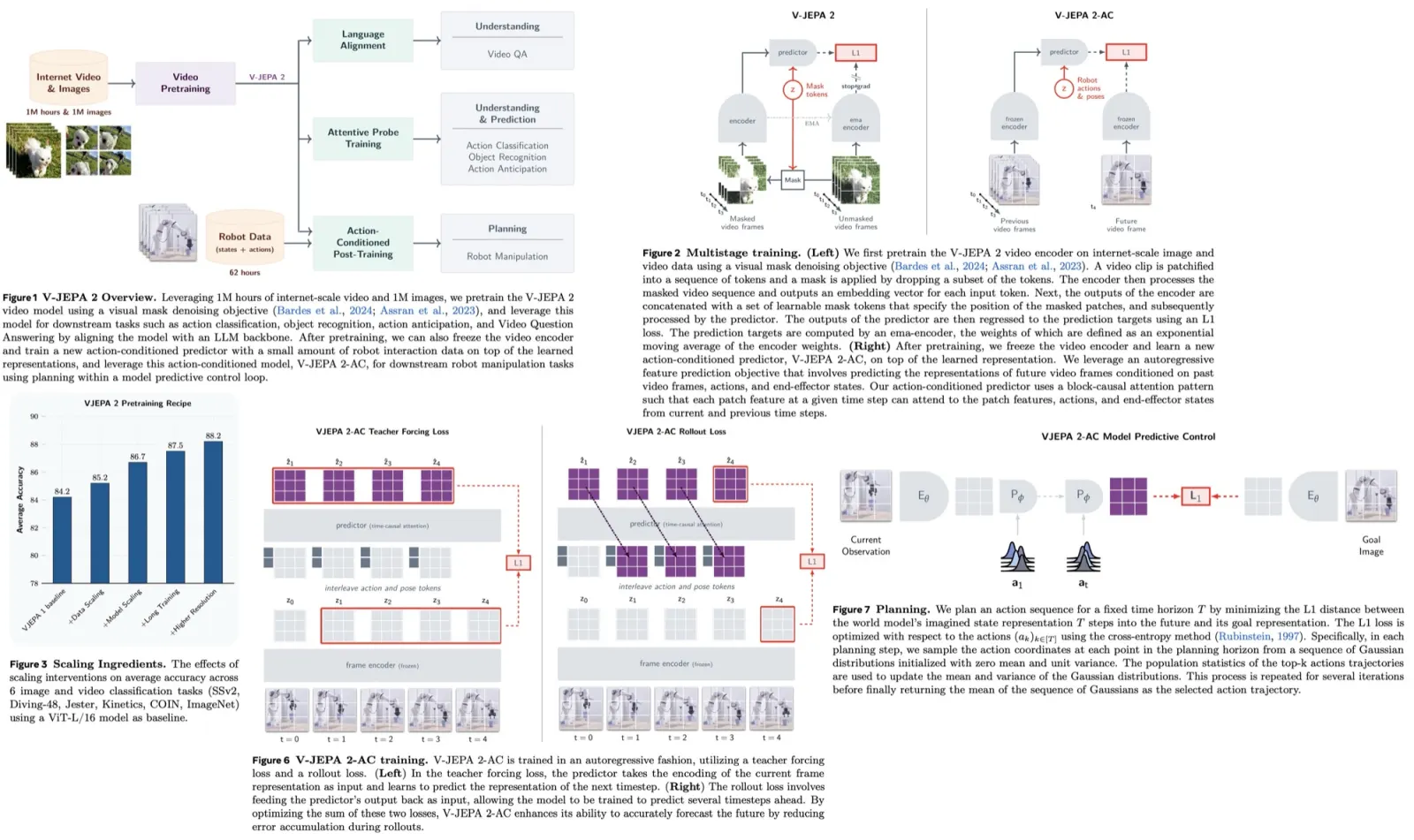
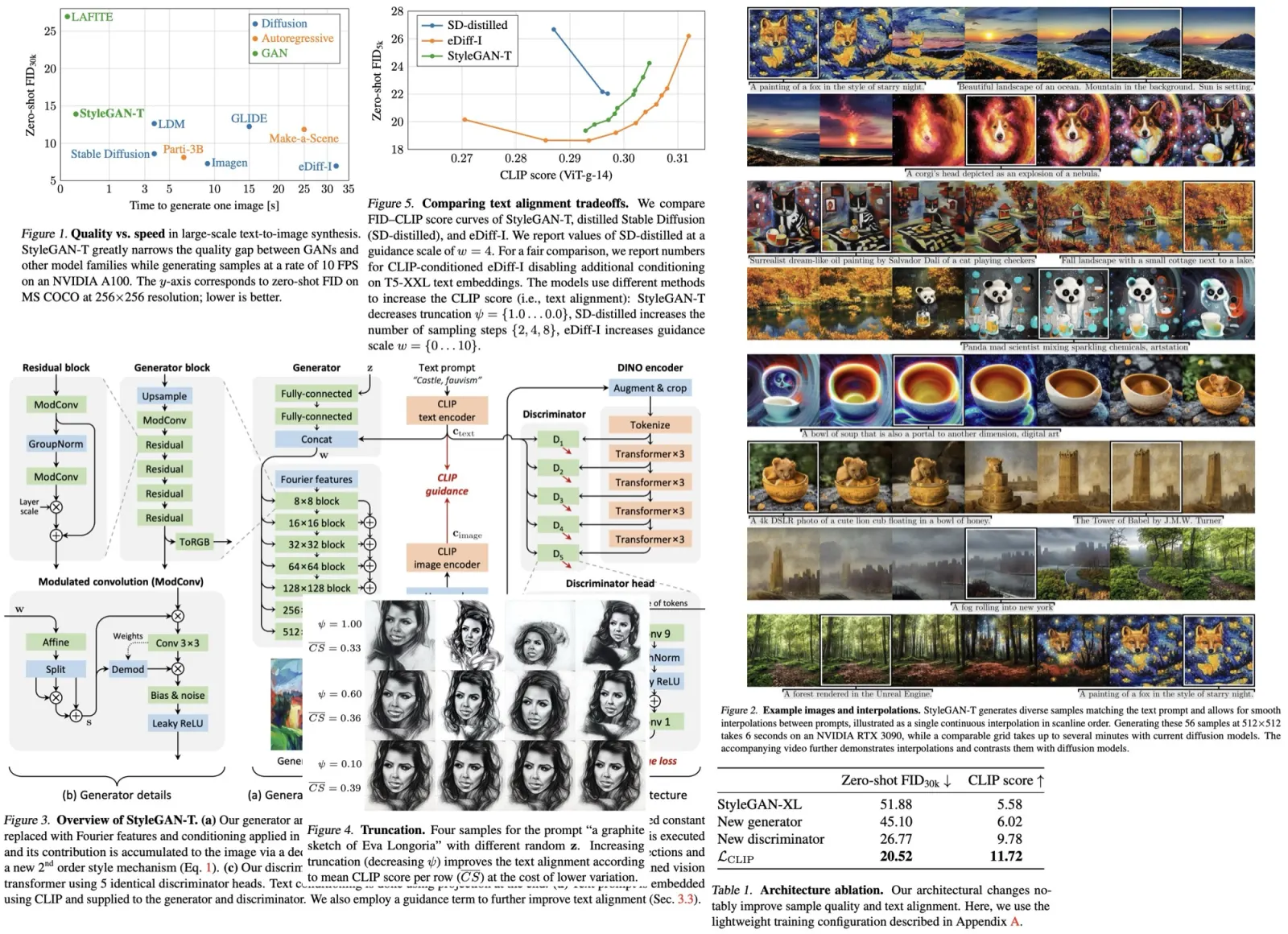
DiffSeg is a post-processing technique to convert attention tensors from a stable diffusion model into valid segmentation masks. It involves three main components: attention aggregation, iterative attention merging, and non-maximum suppression.
- In attention aggregation, DiffSeg processes 16 attention tensors generated by the stable diffusion model from an input image. These tensors are of different resolutions, and the goal is to aggregate them into the highest resolution tensor. This involves upsampling the spatial dimensions of all attention maps to match the highest resolution and then aggregating them while treating the first two dimensions, which indicate reference locations, differently. The final aggregated attention tensor is normalized to ensure it represents a valid distribution.
- Iterative attention merging aims to transform the aggregated attention tensor into a stack of object proposals, each potentially containing a single object or stuff category. At first, a sampling grid of evenly spaced anchor points is generated and corresponding attention maps are samples. The similarity between maps is measured using KL divergence, and maps with high similarity are merged iteratively. This process continues until a set of object proposals is obtained.
- NMS is used to convert the list of object proposals into a valid segmentation mask. Each proposal is a probability distribution map, and the NMS process involves upsampling these maps to the original resolution and then assigning each pixel to the proposal with the highest probability at that location. The result is a final segmentation mask that represents the segmented objects in the input image.
Experiments
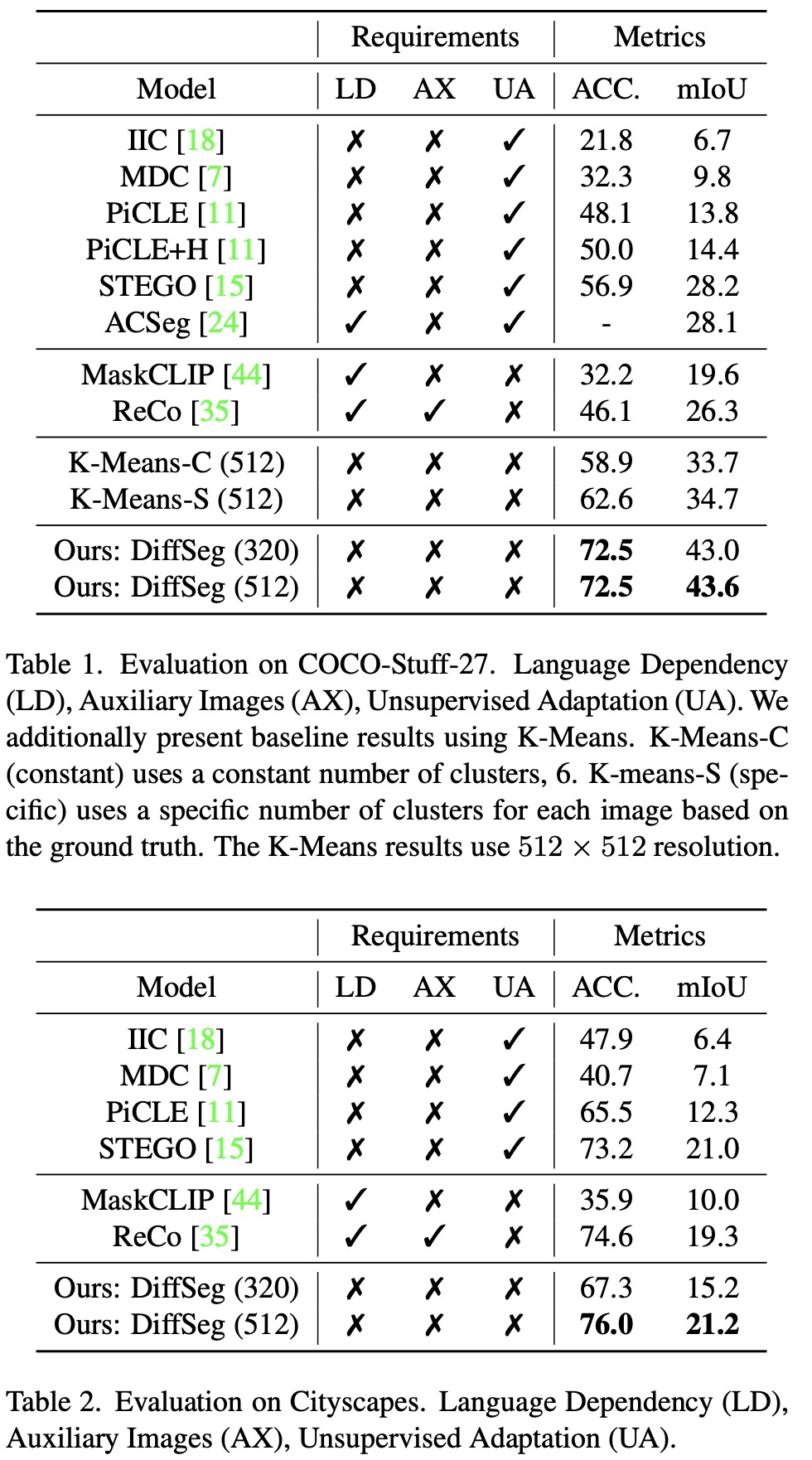
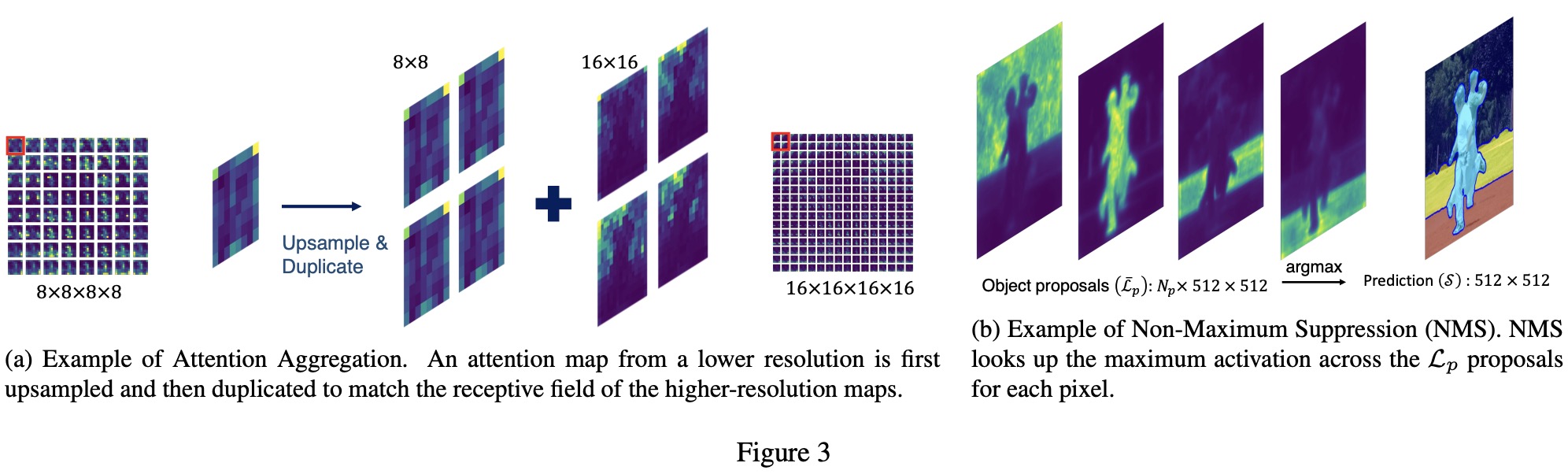
On the COCO benchmark, two k-means baselines, K-Means-C (using a constant number of clusters) and K-Means-S (using a specific number of clusters based on ground truth for each image), were included. Both variants outperformed previous methods, highlighting the effectiveness of using self-attention tensors. K-Means-S performed better than K-Means-C, indicating the importance of tuning the number of clusters for each image. However, DiffSeg, utilizing the same attention tensors, significantly outperformed both K-Means baselines, demonstrating its superior segmentation capability without the drawbacks of K-Means.
DiffSeg also significantly outperformed the previous state-of-the-art zero-shot method, ReCo, on COCO-Stuff-27, showing a 26% improvement in accuracy and 17% in mIoU for both 320 and 512 resolutions. On the Cityscapes self-driving segmentation task, DiffSeg matched prior works at a 320-resolution input and outperformed them at a 512-resolution input in both accuracy and mIoU. The performance on Cityscapes was more affected by input resolution due to the presence of smaller classes like light poles and traffic signs.
DiffSeg achieves this high level of performance in a purely zero-shot manner, without any language dependency or auxiliary images, enabling it to segment any image effectively.
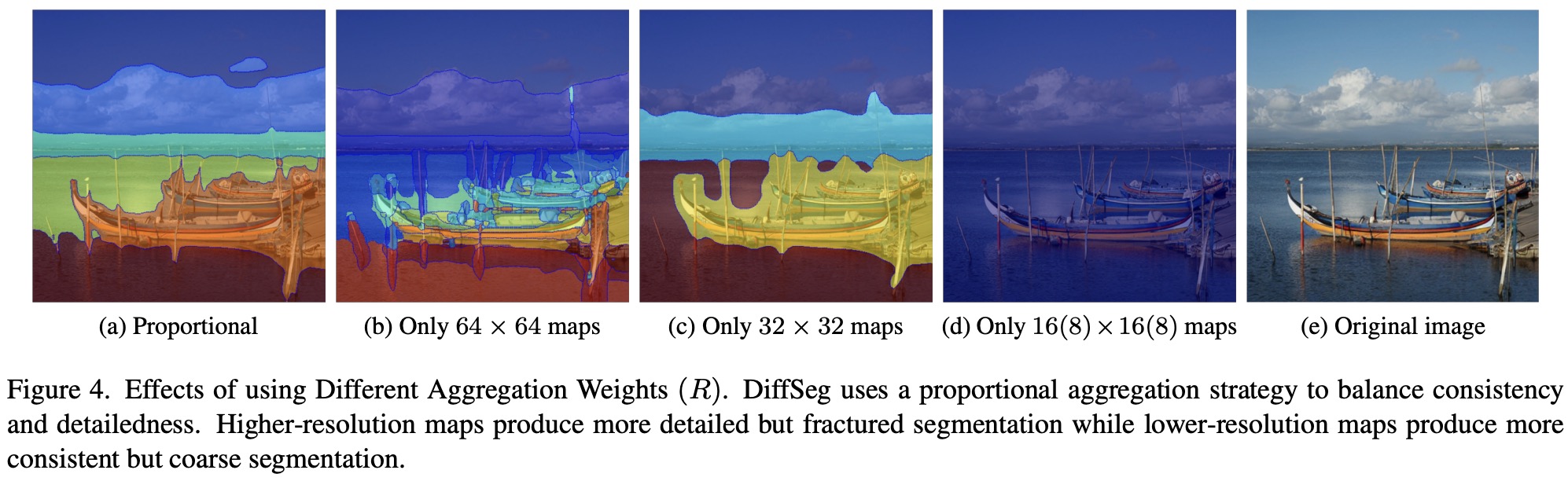
In DiffSeg, several hyper-parameters play crucial roles. One key aspect is the aggregation weights used in the attention aggregation step, where attention maps of four different resolutions are combined. The aggregation weight for each map is proportional to its resolution, meaning higher-resolution maps are given more importance. This approach is based on the observation that higher-resolution maps, having smaller receptive fields relative to the original image, provide more detailed information.
High-resolution maps (e.g., 64×64) produce detailed but fractured segmentation, while lower-resolution maps (e.g., 32×32) offer more coherent segmentation but may over-segment details, particularly along edges. Very low resolutions result in overly simplified segmentation, merging the entire image into one object with the given hyper-parameter settings. The proportional aggregation strategy effectively balances consistency and detail in the segmentation process.