Paper Review: Diffusion Model Alignment Using Direct Preference Optimization

DiffusionDPO is a new method for aligning text-to-image diffusion models with human preferences, adapted from Direct Preference Optimization. Unlike traditional approaches that use high-quality images and captions for fine-tuning, DiffusionDPO optimizes models based on human comparison data. It modifies DPO to fit diffusion models by incorporating a likelihood concept and a differentiable objective derived from the evidence lower bound.
Fine-tuned on the base of Stable Diffusion XL 1.0 model with the Pick-a-Pic dataset of over 851,000 crowdsourced preferences, DiffusionDPO significantly improved the model’s performance in visual appeal and prompt alignment compared to both the base and a larger variant of SDXL-1.0. The method also includes an AI feedback-based variant, which shows comparable results to human-based training, indicating a scalable way to align diffusion models without heavily relying on human data.
Background
- Diffusion Models generate data by reversing a process that gradually adds noise to the data. The reverse process has a Markov structure, and training involves minimizing the evidence lower bound.
- DPO, originally used for language models, is adapted here for diffusion models. The method assumes access to pairs of generated samples (one preferred over the other) given some condition. The Bradley-Terry model is used to express human preferences, where the preference probability is modeled using a sigmoid function of the difference in rewards (as estimated by a neural network) for the two samples.
- Reward Modeling involves estimating human preference for a generated sample given some condition. However, the actual reward model is latent and not directly accessible. The approach uses ranked pairs (winning and losing samples) to estimate this preference.
- RLHF aims to optimize a conditional distribution of the generated data such that the latent reward model is maximized. It involves a balance between maximizing this reward and maintaining similarity to a reference distribution.
- DPO Objective rewrites the reward function in terms of the probability distributions of the generated and reference data. The method directly optimizes the conditional distribution of the generated data, rather than first optimizing a reward function and then using reinforcement learning.
DPO for Diffusion Models
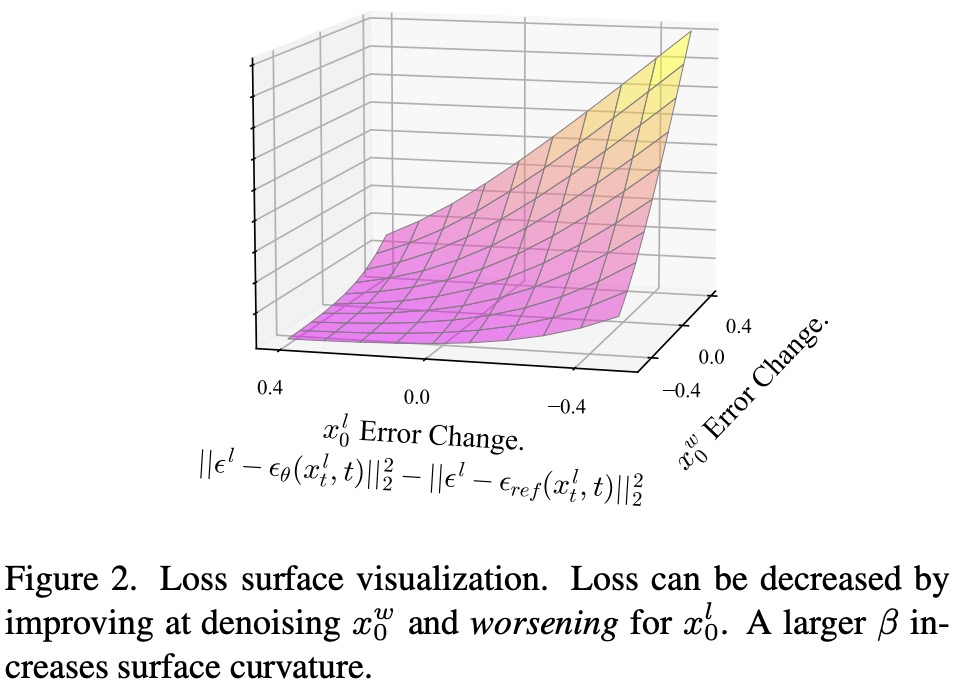
- Dataset and Goal: The dataset consists of prompts and pairs of images, where each pair includes one image preferred over the other according to human judgment. The aim is to train a new model that better aligns with these human preferences compared to an existing reference model.
- Challenge in Diffusion Models: A significant challenge in this process is the complexity of the model’s distribution, which involves considering all possible paths that could lead to a generated image. To tackle this, the authors use the evidence lower bound, which involves introducing additional latent variables and defining a reward function over the entire path of image generation.
- Objective Formulation: The main objective is to maximize the reward for generating images in reverse (from noisy to clear) while ensuring that the new model’s image generation process remains similar to that of the original reference model.
- Efficient Training and Approximations: Due to the complexity and impracticality of directly using the new model’s distribution, the method approximates it using the forward process (from clear to noisy images). This leads to a loss function that essentially measures how well the model can remove noise from images, comparing its performance on more preferred images against less preferred ones.
- Loss Function: The final loss function is designed to encourage the model to be better at “denoising” or clarifying the preferred images compared to the less preferred ones. This is done by comparing the model’s performance against a reference model across different levels of image quality.
- Multi-Step RL and Noisy Preference Model: The approach is also framed in terms of multi-step reinforcement learning and justified using an off-policy algorithm.
Experiments
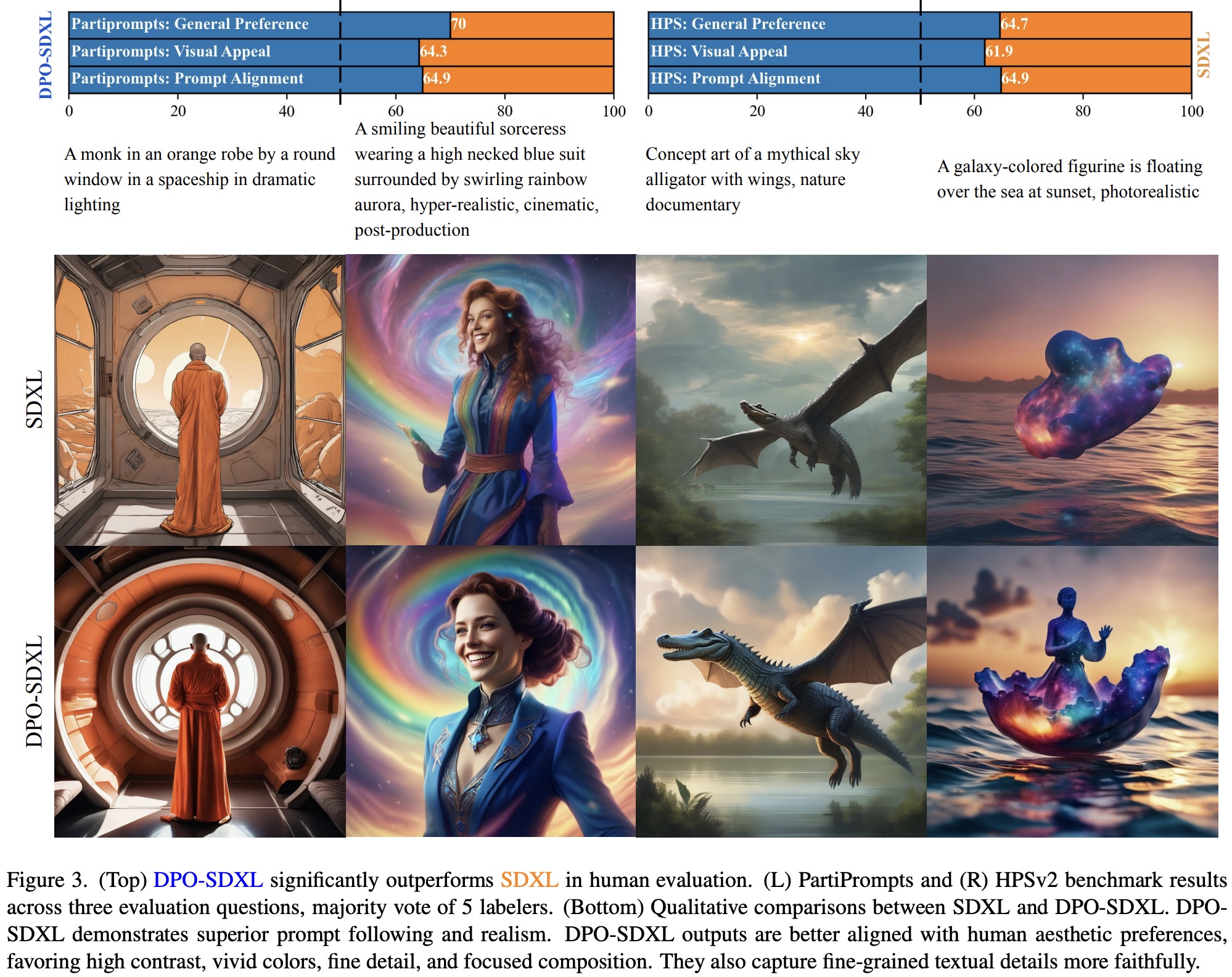
The Diffusion-DPO-finetuned SDXL model significantly outperforms the baseline SDXL-base model. In evaluations using Partiprompt and the HPS benchmark, the DPO-SDXL model is preferred for general appeal, visual appeal, and prompt alignment. The model also tops the leaderboard on the HPSv2 reward model.
Qualitatively, the DPO-SDXL model generates more appealing images with vivid colors, dramatic lighting, good composition, and realistic portrayal of people and animals. These improvements are confirmed by a crowdsourced study, although it’s noted that preferences can vary, with some people preferring less dramatic imagery.

When compared to the complete SDXL pipeline (which includes a base model and a refinement model), the DPO-SDXL model still performs better. Despite having fewer parameters and only using the base architecture, it achieves comparable win rates in general preference questions against the complete model. This is attributed to its ability to generate fine details and perform well across different image categories.

The DPO-SDXL model also shows improved performance in image-to-image translation tasks. Tested on the TEdBench benchmark, it is preferred over the original SDXL edits in a majority of cases. This indicates enhanced capability in text-based image editing.

The authors also explore learning from AI feedback as an alternative to human preferences. By using a pretrained scoring network for ranking generated images, the model shows improvements in visual appeal and prompt alignment. Training with AI feedback, such as using the PickScore dataset, even outperforms training on raw human labels.
Ablations and analysis
- Implicit Reward Model: The Diffusion-DPO scheme inherently learns a reward model that can estimate the differences in rewards between two images. The learned models, DPO-SD1.5 and DPO-SDXL, show strong performance in binary preference classification, with DPO-SDXL outperforming existing recognition models.
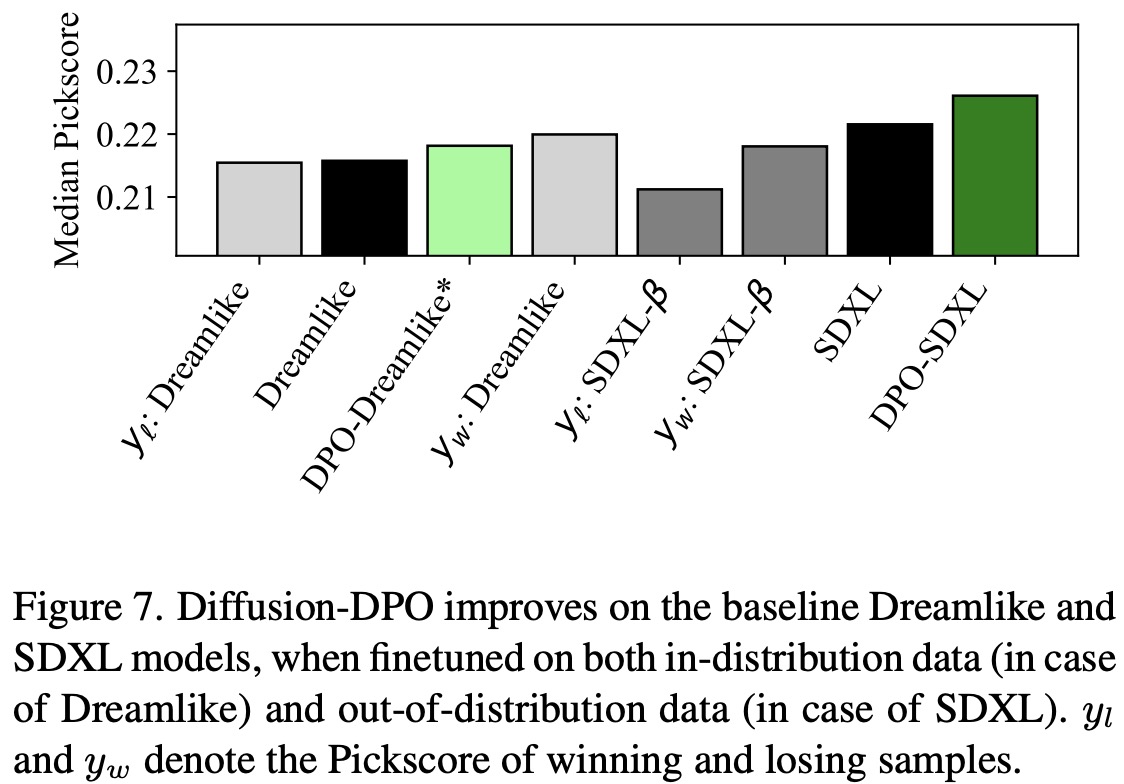
- Training Data Quality: Even though the SDXL model is superior to its training data, the DPO training still substantially improves its performance. This is further evidenced by training the Dreamlike model on a subset of the Pick-a-Pic dataset generated by the Dreamlike model itself. The improvement is notable, although limited, possibly due to the small size of the dataset used.
- Supervised Fine-Tuning: In the context of LLMs, SFT is beneficial as an initial pretraining step before preference training. However, when applied to the SDXL model, any amount of SFT actually deteriorates its performance, even at lower learning rates. This is attributed to the higher quality of the Pick-a-Pic dataset’s generations compared to the SD1.5 model. In contrast, the SDXL-1.0 base model is already superior to the models in the Pick-a-Pic dataset, which might explain why SFT is less effective in this case.