Paper Review: DINOv2: Learning Robust Visual Features without Supervision
This paper demonstrates that pretraining computer vision models on large, diverse, and curated datasets can produce all-purpose visual features that perform well across various tasks without fine-tuning. The study combines existing approaches and focuses on scaling data and model size. An automatic pipeline is proposed to create a dedicated, diverse, and curated image dataset. The researchers train a 1 billion parameter ViT model and distill it into smaller models, which outperform the previously best all-purpose features, OpenCLIP, on most benchmarks at image and pixel levels.
Data Processing
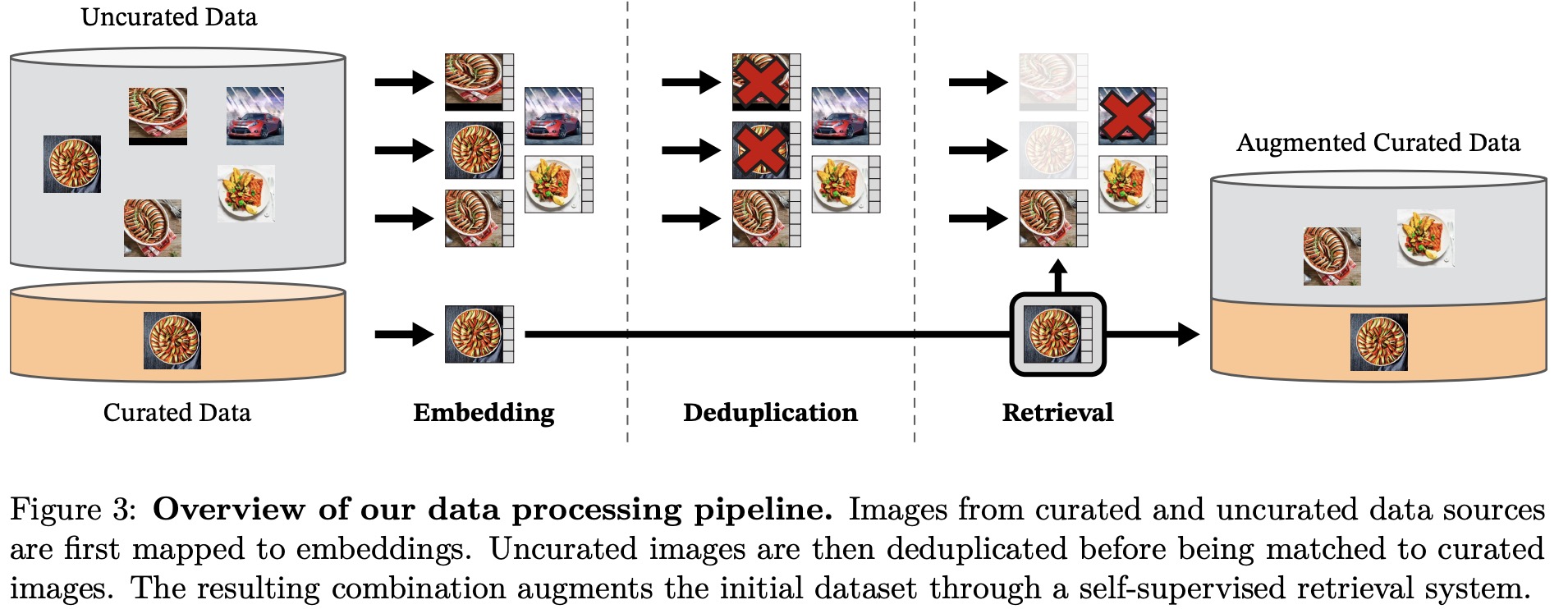
The researchers assemble a curated dataset called LVD-142M by retrieving images from uncurated sources that are similar to those in several curated datasets (ImageNet-22k, the train split of ImageNet-1k, Google Landmarks, and several fine-grained datasets). They use publicly available web data to create a raw unfiltered dataset of 1.2 billion unique images, and apply a copy detection pipeline to remove near-duplicates. To build the curated pretraining dataset, they compute image embeddings using a self-supervised ViT-H/16 network and perform k-means clustering on the uncurated data. Nearest neighbors or images from corresponding clusters are retrieved based on the query dataset. The deduplication and retrieval stages use the Faiss library for efficient indexing and batch searches. The entire process is distributed on a compute cluster of 20 nodes with 8 V100 each and takes less than two days to produce the LVD-142M dataset.
Discriminative Self-supervised Pre-training
The researchers employ a discriminative self-supervised method to learn features, combining elements from DINO, iBOT, and SwAV approaches. Their method includes an image-level objective, a patch-level objective, untied head weights, Sinkhorn-Knopp centering, the KoLeo regularizer, and an adaptive resolution.
- The image- and patch-level objectives involve cross-entropy loss between student and teacher networks.
- Untying head weights improves performance at both scales.
- Sinkhorn-Knopp centering replaces the teacher softmax-centering step.
- The KoLeo regularizer encourages a uniform span of features within a batch.
- Lastly, they adapt the resolution, increasing it to 518x518 for a short period at the end of pretraining to better handle pixel-level downstream tasks.
Efficient implementation
The researchers implement several improvements to train models at a larger scale:
- They develop a faster and more memory-efficient version of FlashAttention, optimizing the ViT-g architecture for better compute efficiency. Due to the GPU hardware specifics, the efficiency is best when the embedding dimension per head is a multiple of 64, and the matrix operations are even better when the full embedding dimension is a multiple of 256.
- Nested tensors in self-attention are used for global and local crops, resulting in significant compute efficiency gains.
- An improved version of stochastic depth (shuffling samples over batch dimensions and slicing some first samples for the computations in the block) is implemented to save memory and compute (in proportion approximately equal to the drop rate (40% in this paper), thanks to specific fused kernels).
- The Fully-Sharded Data Parallel (FSDP) technique is employed to reduce memory footprint per GPU and to save on cross-GPU communication costs. This leads to more efficient scaling with the number of GPU nodes compared to DistributedDataParallel.
- For smaller models, they use knowledge distillation, distilling them from the largest model, the ViT-g, instead of training from scratch. This approach achieves better performance and leverages the same training loop with some modifications (use a larger model as a frozen teacher, keep a spare EMA of the student as a final model, remove the masking and stochastic depth, and, apply the iBOT loss on the two global crops).
Ablation Studies
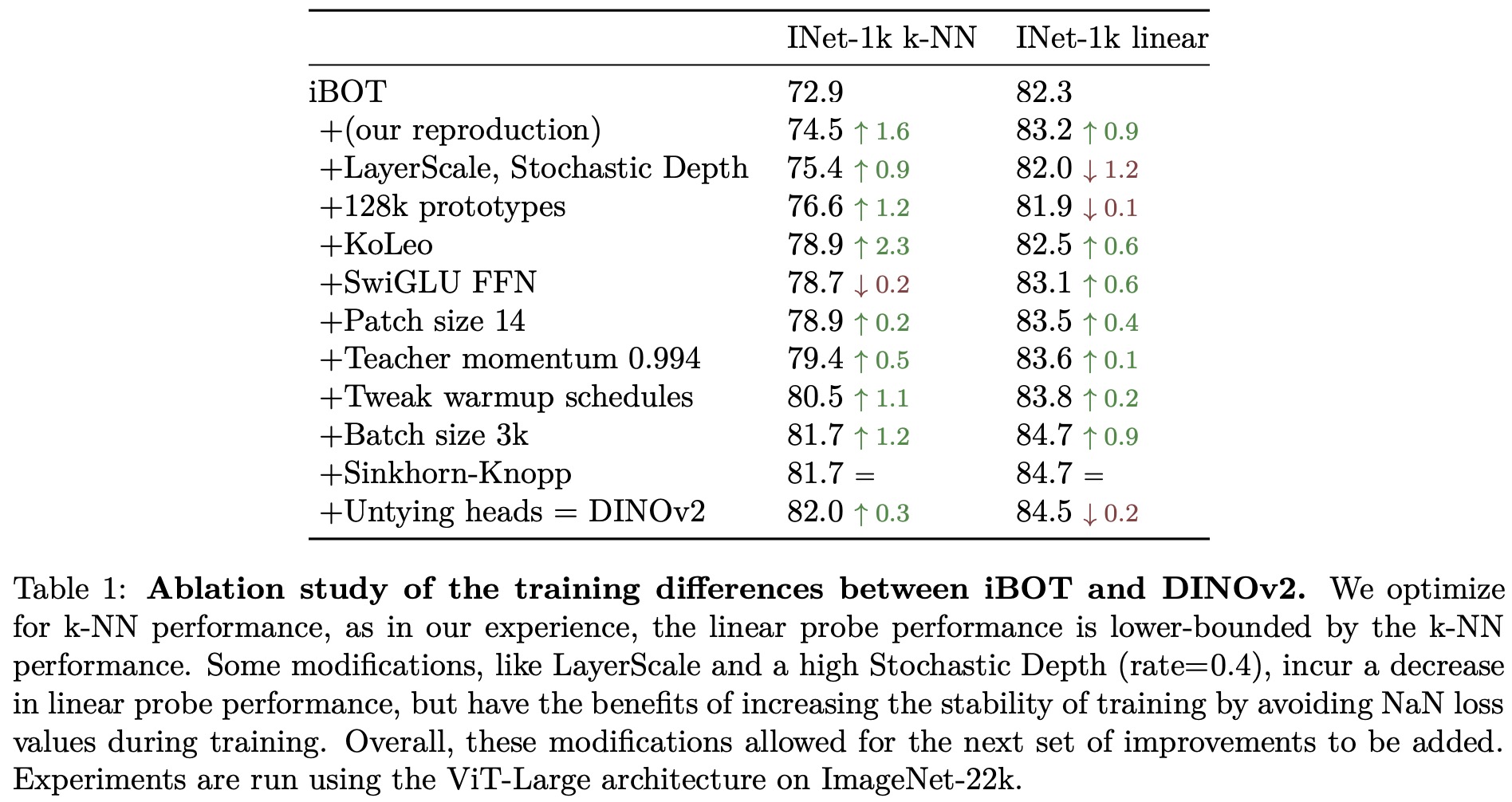
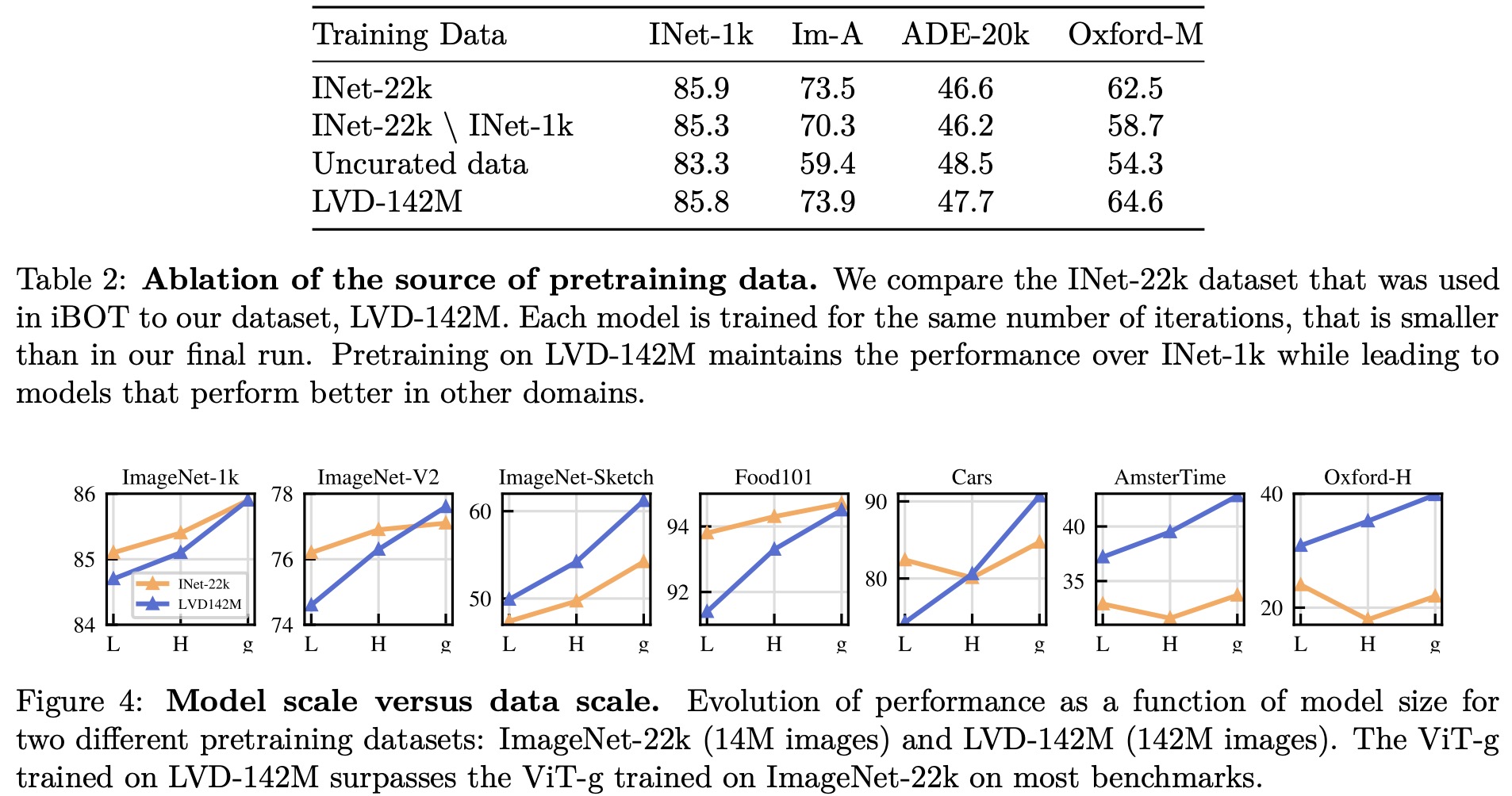
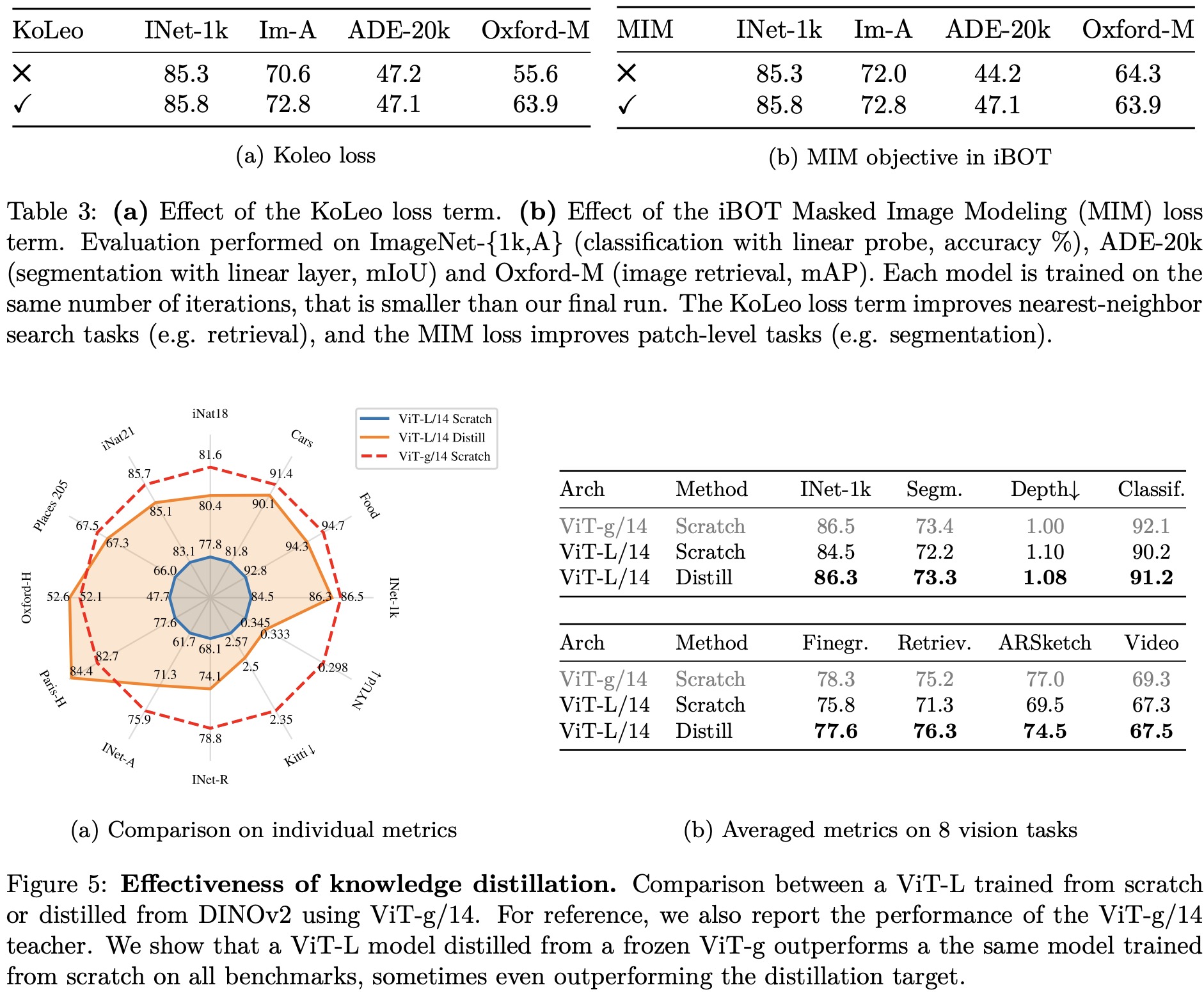
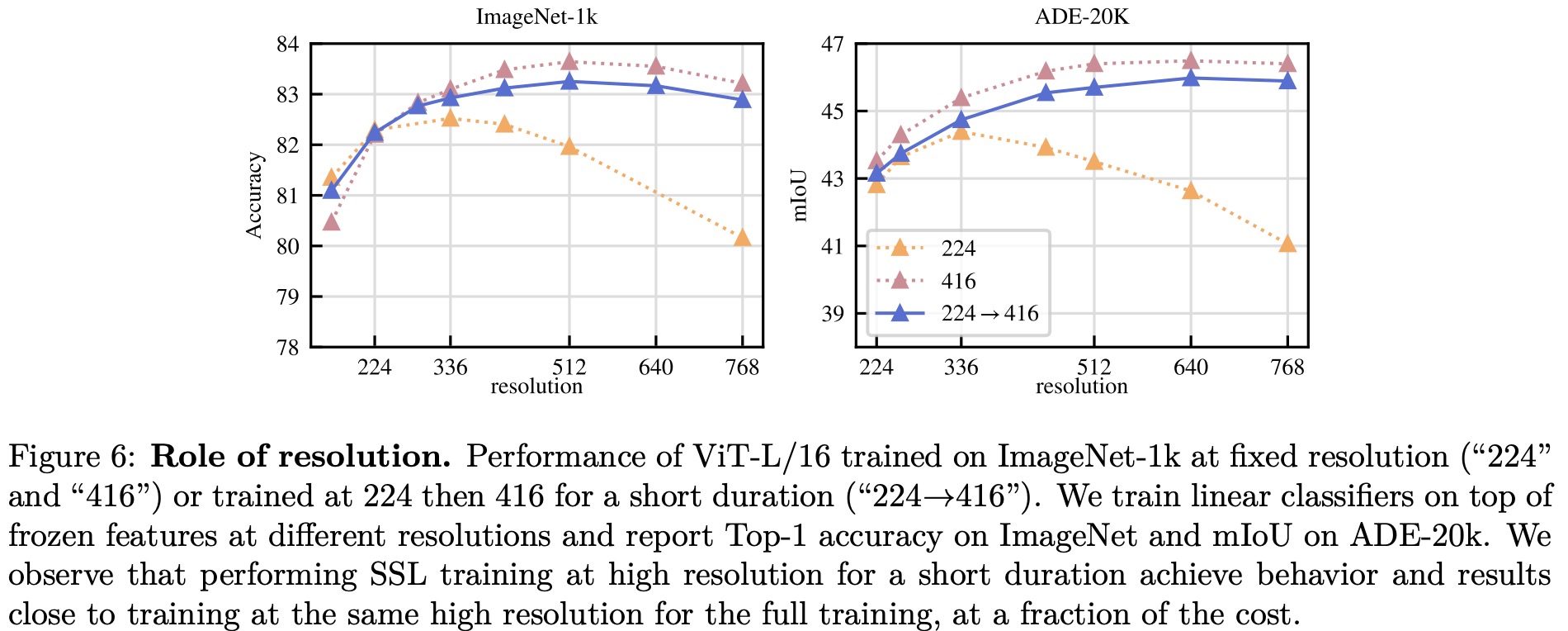
In this section, the researchers evaluate the importance of each component of their improved training recipe by training multiple models and observing their performance. Generally, each component improves the performance on either k-NN or linear probing, and in most cases, both.
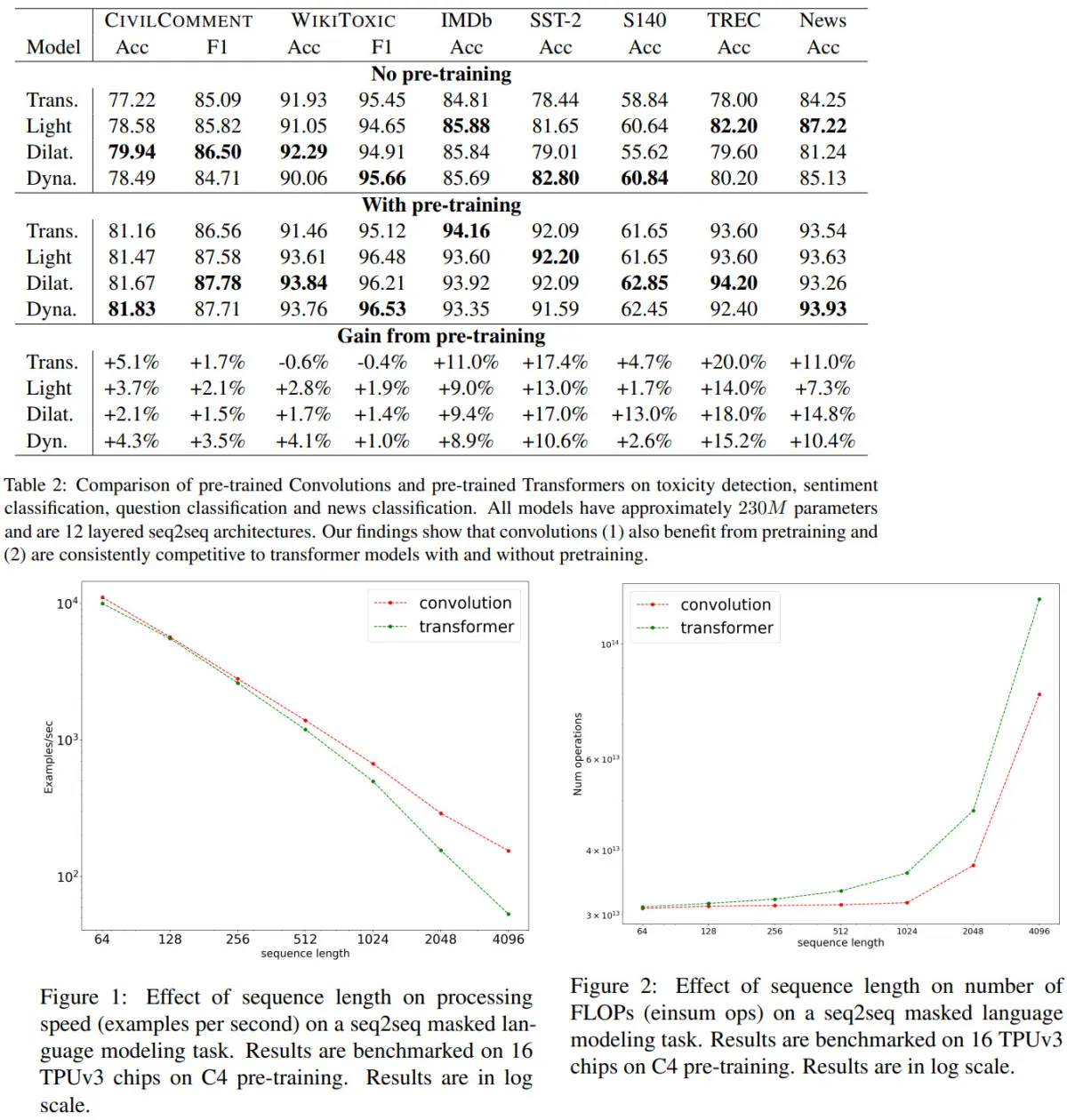
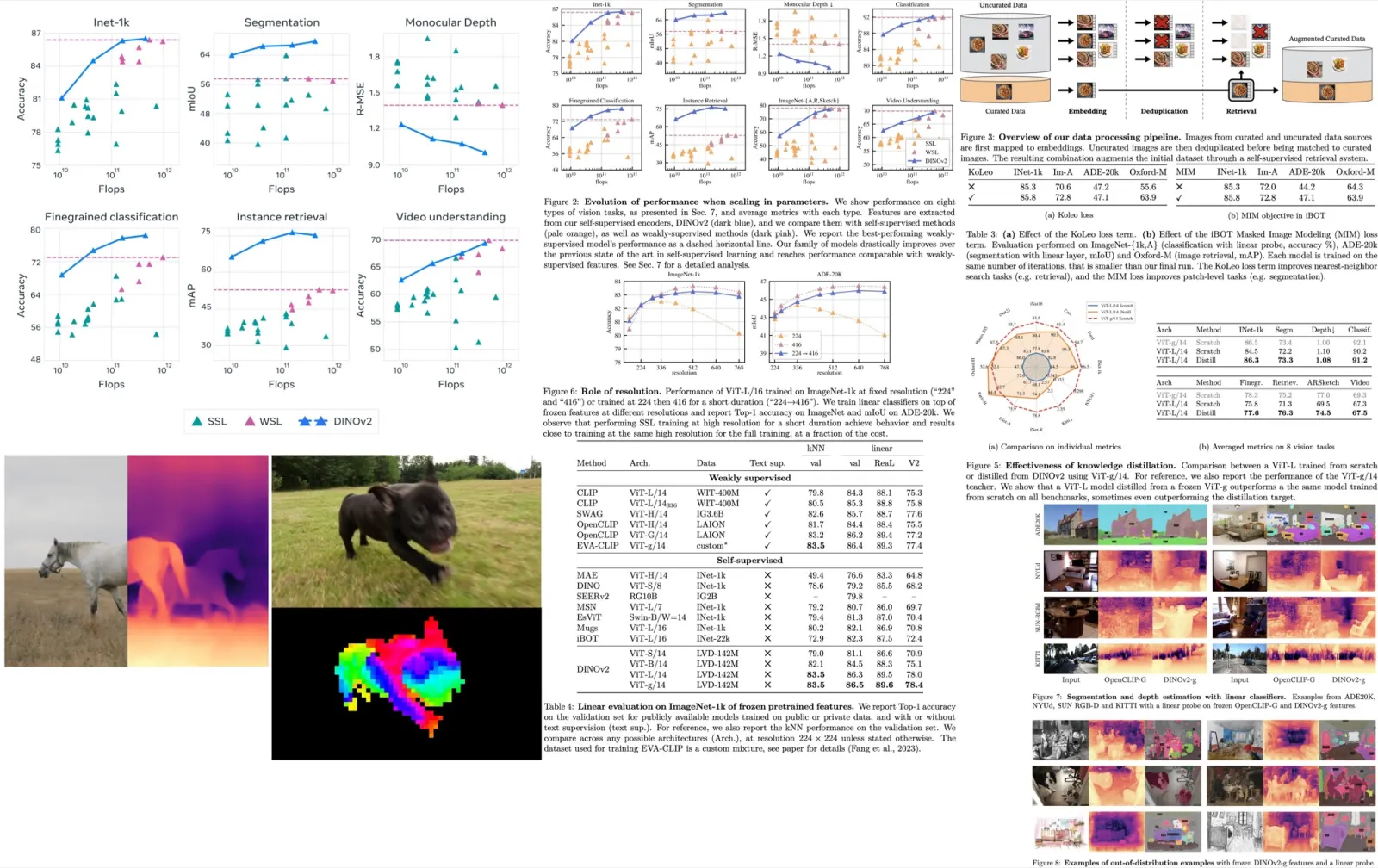
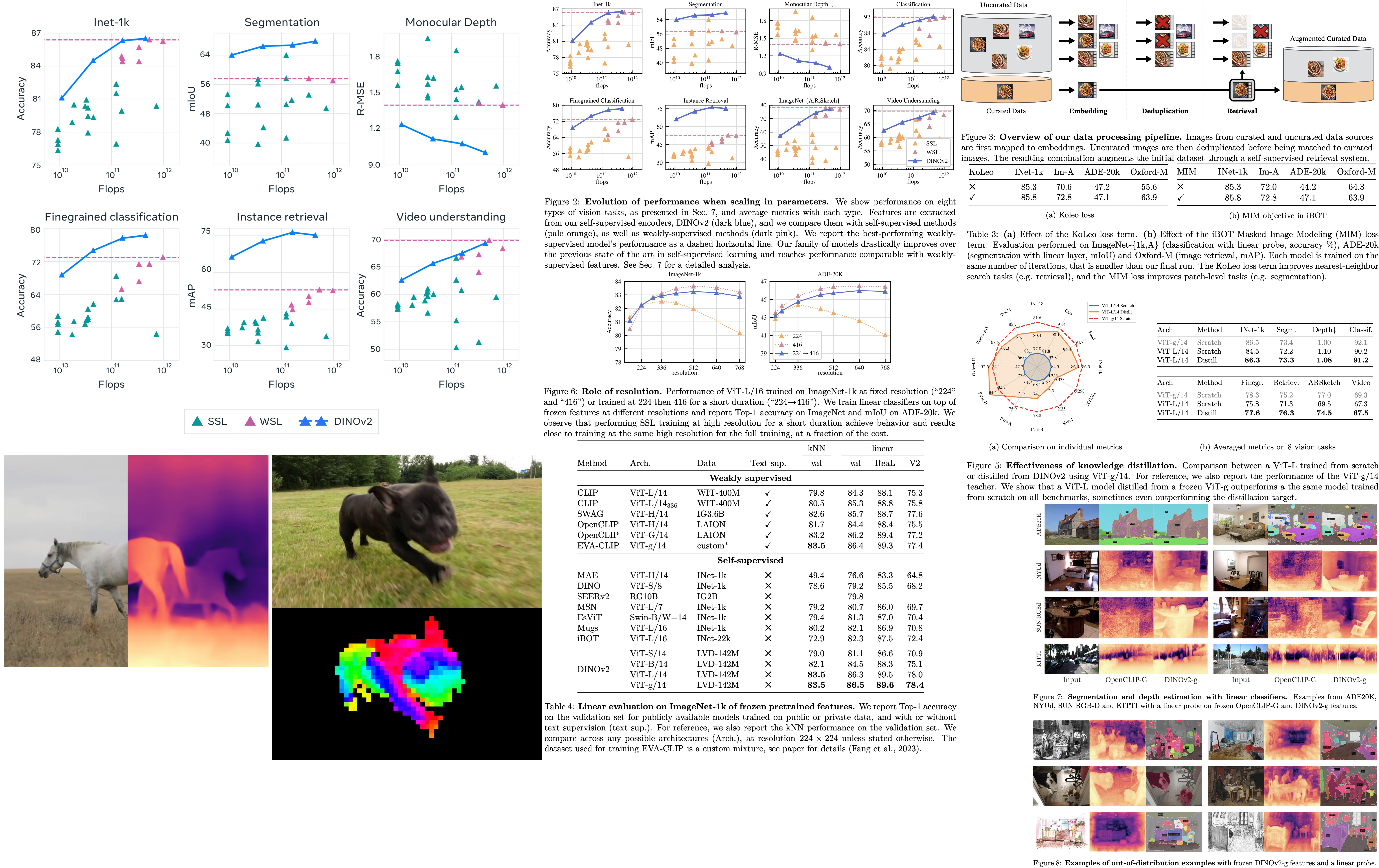
Pretraining Data Source. The quality of features is directly related to the quality of the pretraining data. They compare the performance of models trained on LVD-142M, ImageNet-22k, and an uncurated dataset. The results show that training on a curated set of images works better on most benchmarks than training on uncurated data, confirming the benefit of curating data for self-supervised pretraining. Training on LVD-142M is superior on all benchmarks except ImageNet-1k compared to models trained on ImageNet-22k, indicating that a more diverse set of images improves feature quality. Overall, the LVD-142M dataset provides a good balance of different types of images, leading to the best performance.
Model Size and Data. As model size grows, training on LVD-142M becomes more beneficial than training on ImageNet-22k. A ViT-g trained on LVD-142M matches the performance of a model trained on ImageNet-22k on ImageNet-1k while outperforming it on other benchmarks.
Loss Components. The KoLeo loss improves instance retrieval performance by more than 8% without negatively impacting other metrics. The masked image modeling term from iBOT is crucial for dense prediction tasks, leading to almost 3% performance improvement.
Impact of Knowledge Distillation. For small architectures, distilling larger models is more effective than training them from scratch. A distilled ViT-L/14 outperforms the one trained from scratch on 10 out of 12 benchmarks.
Impact of Resolution. High-resolution training results in better performance across resolutions, but it is more compute-intensive. Training at high resolution for only a fraction of the training period (e.g., 10k iterations) yields nearly as good results while requiring significantly less compute. Consequently, the authors include this step at the end of the training rather than training at high resolution from scratch.
Results
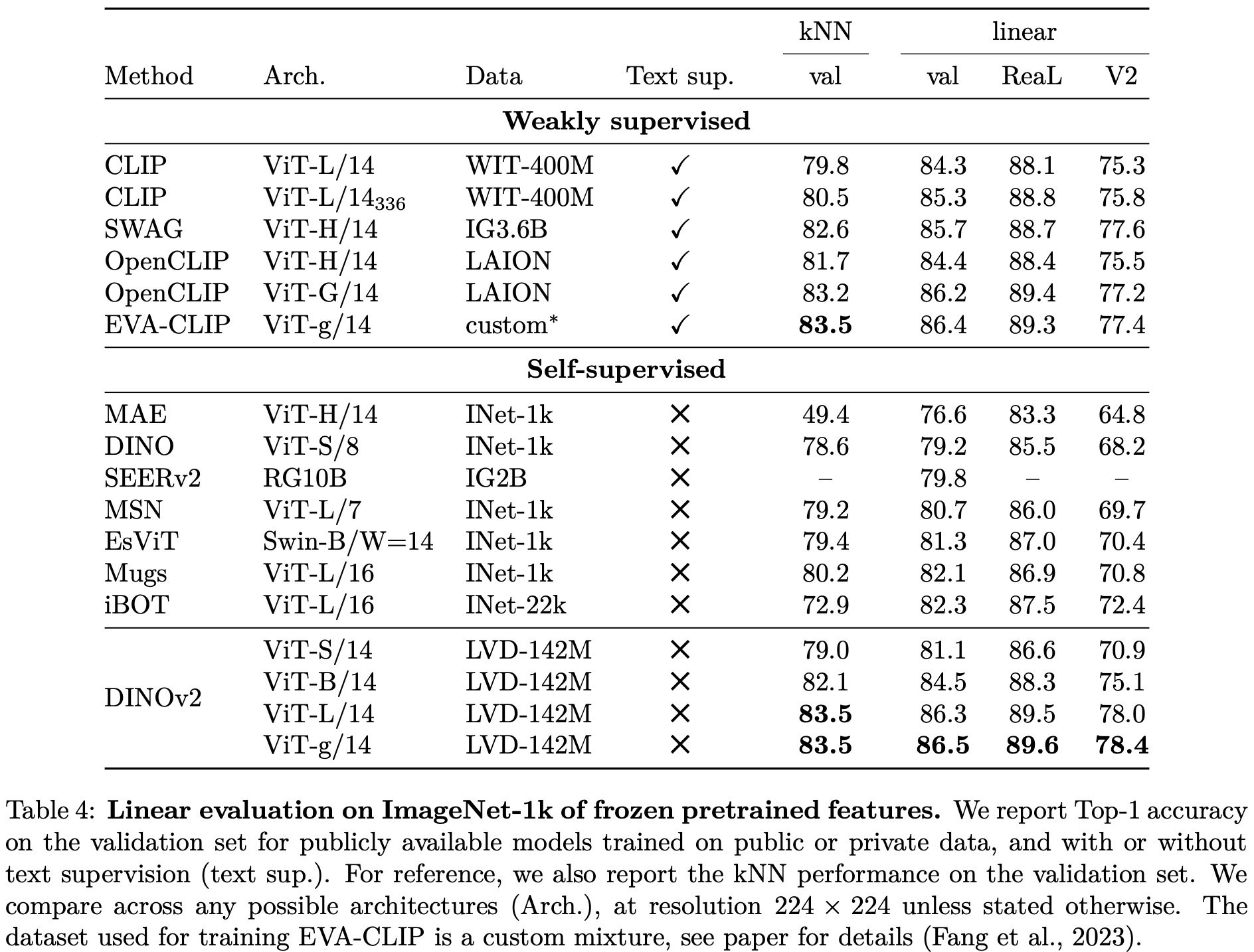
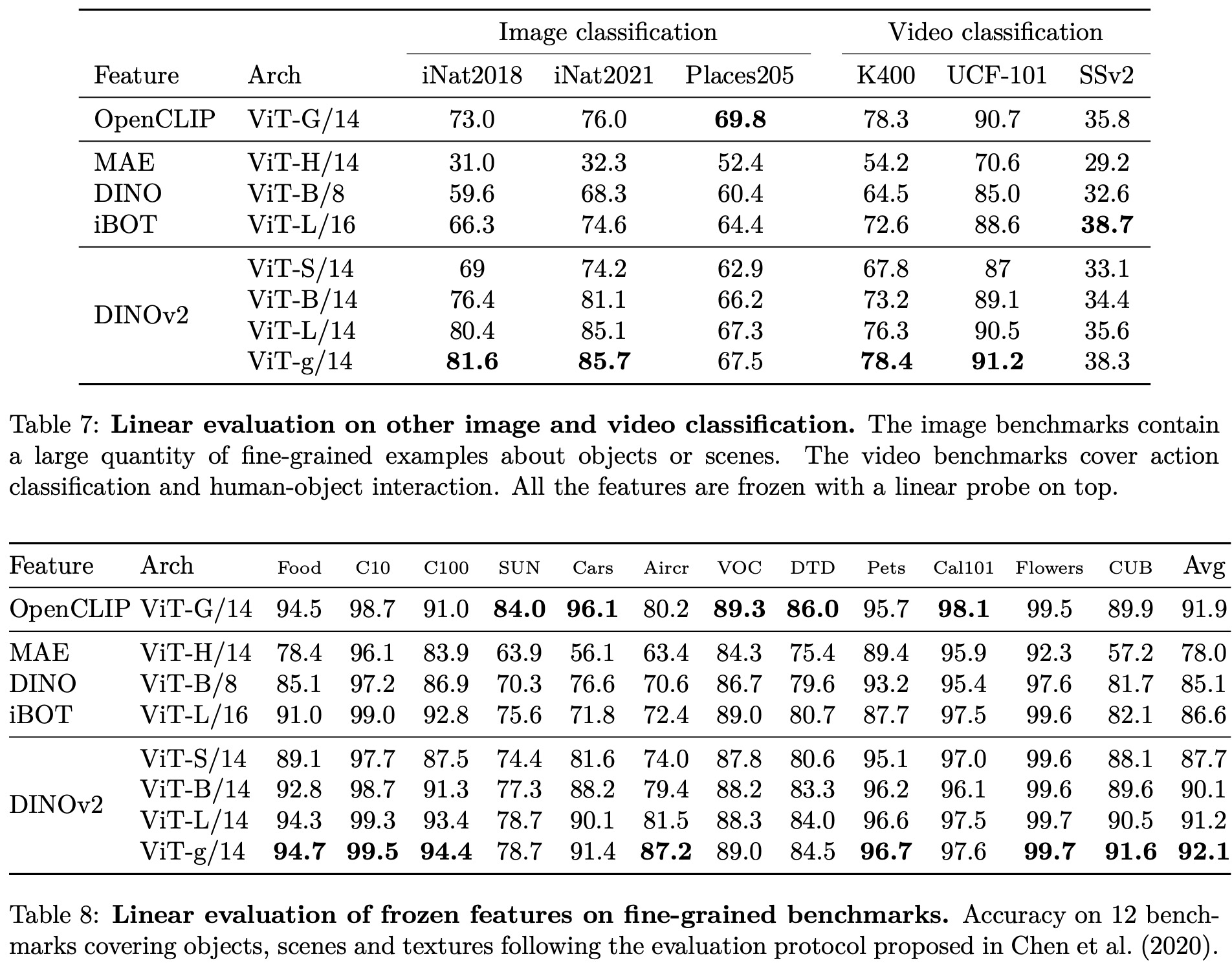
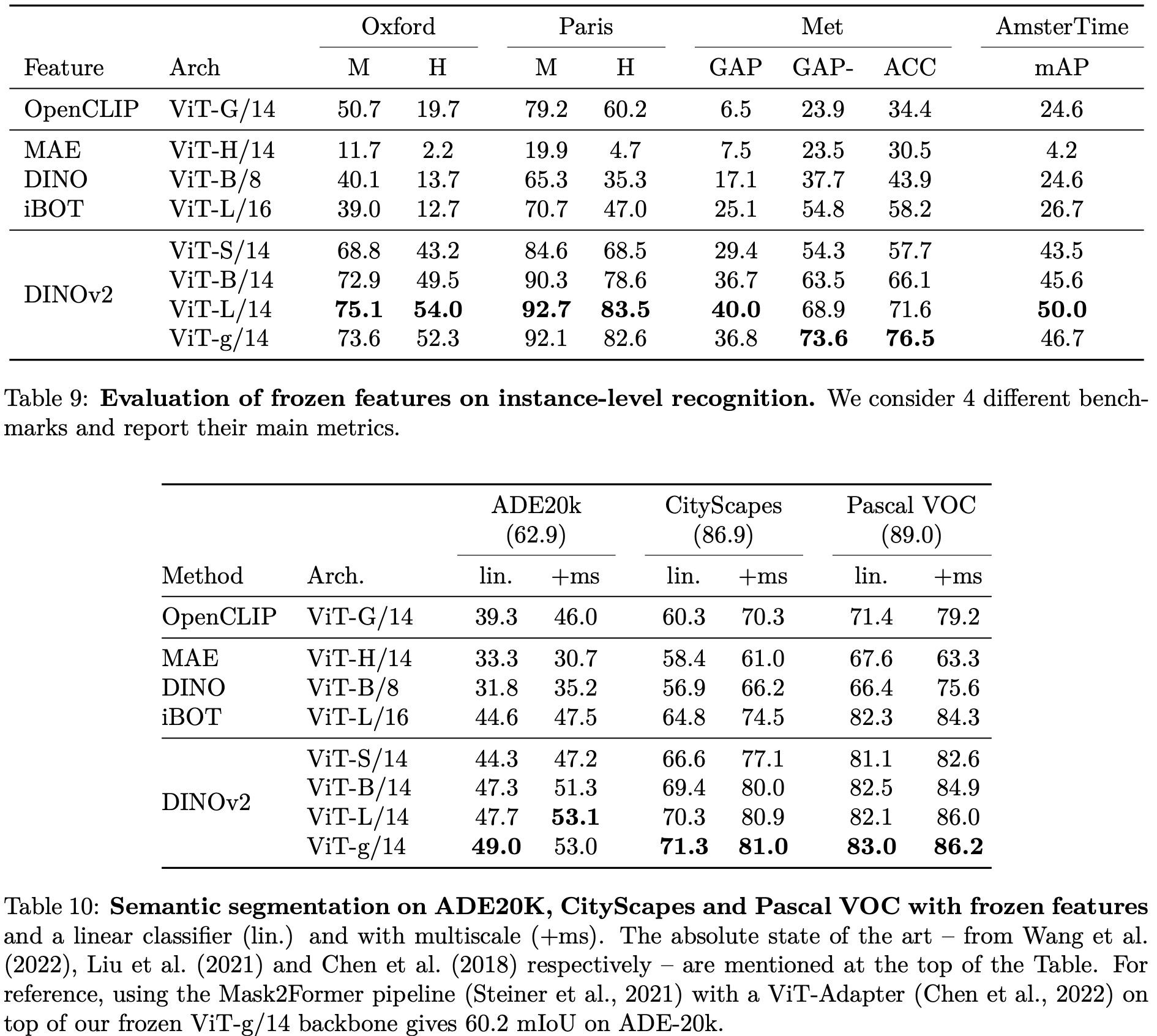
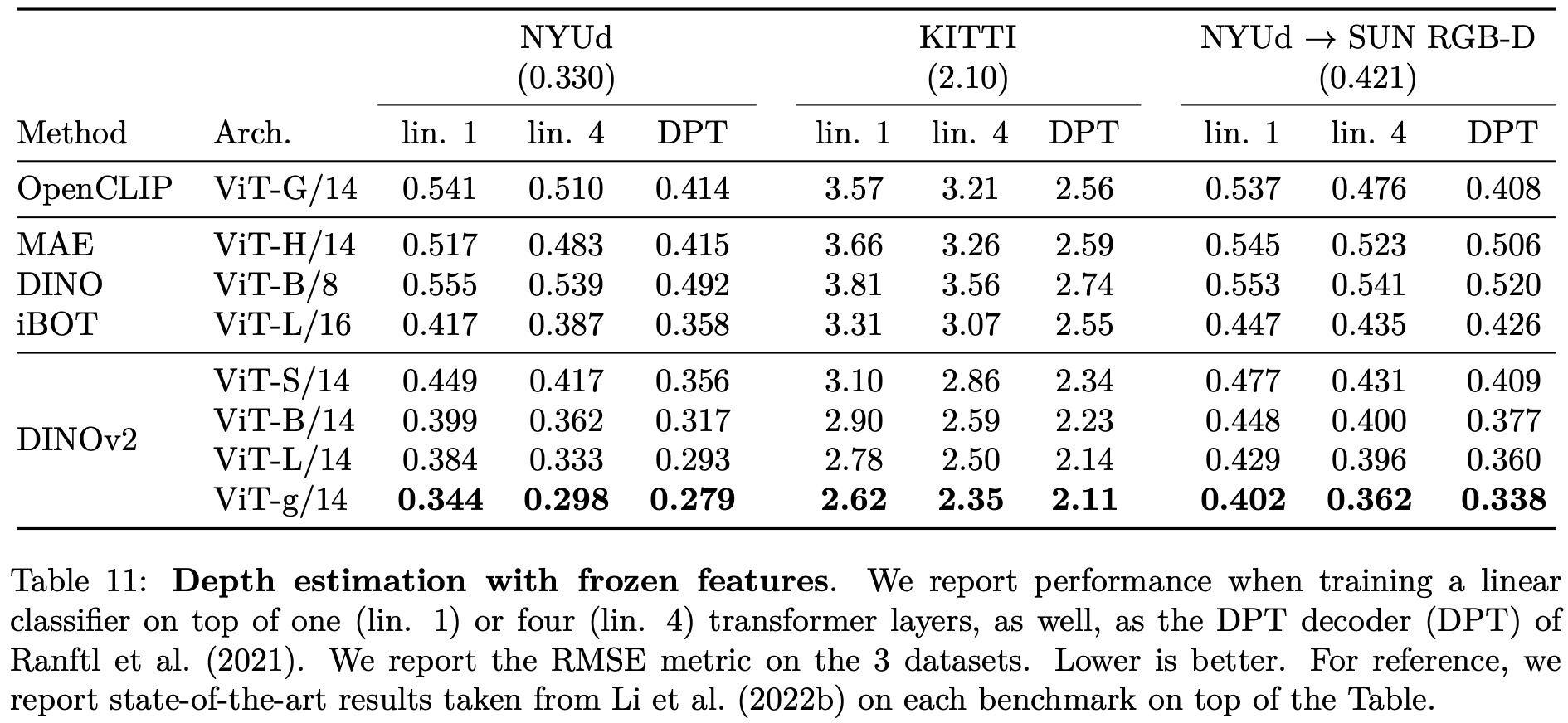

The authors test the quality of the image representation produced by the model by training a simple linear classifier on top of a frozen backbone. Their method shows a significant improvement (+4.2%) over the previous state of the art (iBOT ViT-L/16 trained on ImageNet-22k) on linear evaluation, and stronger generalization on alternative test sets.
The authors also compare their features to state-of-the-art weakly supervised models and find that their backbone surpasses the performance of OpenCLIP with a ViT-G/14 architecture and EVA-CLIP with a ViT-g/14. Additionally, their performance on the ImageNet-V2 test set is significantly better, indicating better generalization.
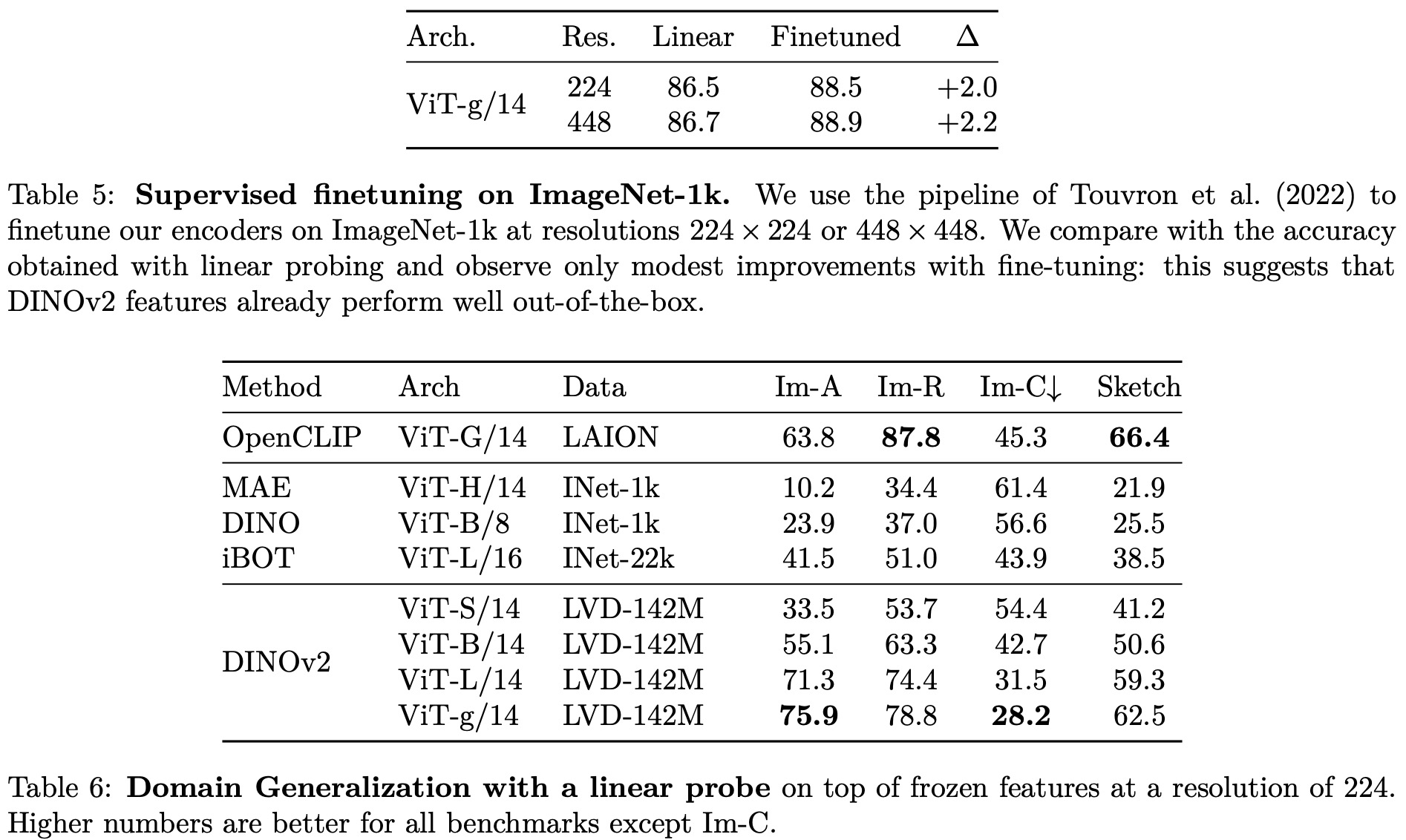
A sanity check is performed to determine if their models can be fine-tuned with supervision on a specific dataset. The Top-1 accuracy on the validation set of ImageNet-1k improves by more than +2% when the backbone is fine-tuned. Their best fine-tuned performance is only slightly below the absolute state of the art.
Finally, robustness analysis is performed on domain generalization benchmarks. The results show that their models have significantly better robustness compared to iBOT and improve upon the best weakly-supervised model on ImageNet-A while lagging behind on ImageNet-R and Sketch.
Fairness and Bias Analysis
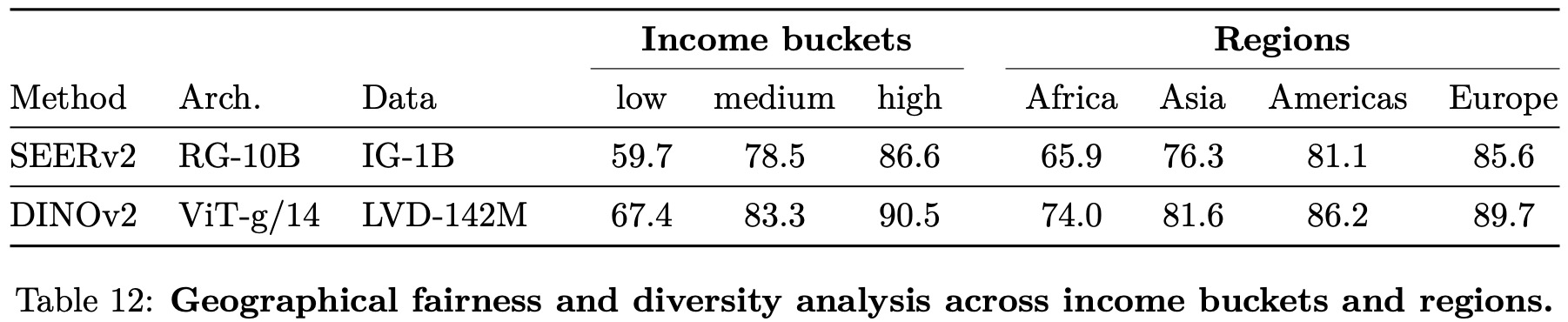
The authors evaluate geographical fairness on the Dollar Street dataset, which compares performance across countries and income levels. Their model is slightly fairer across regions and incomes than the SEERv2 model and significantly better than the supervised baseline. However, there are still significant biases in their model towards Western countries, particularly in Africa where the performance drops by 25.7% compared to Europe. The model also performs better on high-income households than low-income ones, with a difference of 31.7%. Despite improvements, the model still exhibits biases towards wealthy households from Western countries.
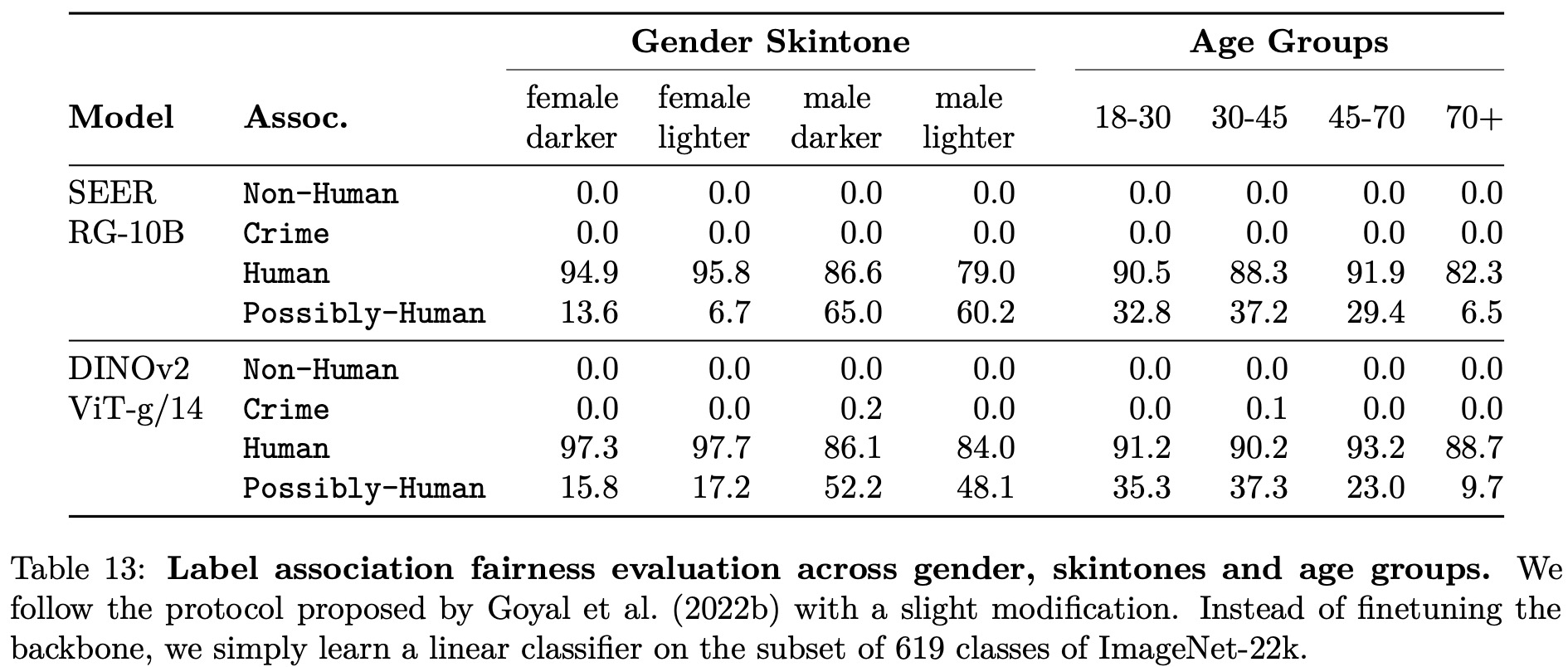
The authors evaluate their model on classifying images of people with different gender, skin tone, and age using a protocol from Goyal et al. (2022b). They train a multiclass classifier on a subset of 619 classes of ImageNet-22k and group them into broader categories. Using the Casual Conversations dataset, they compare their model to SEERv2. Their model often classifies images of all groups as Human without large deviations across skin tones and does not predict harmful labels from Non-Human or Crime meta-categories. However, the model frequently triggers the Possibly-Human class, which contains objects often related to humans. No clear pattern indicates a bias against a particular group in this study, but the authors acknowledge that a more thorough evaluation might reveal flaws in their model.
paperreview deeplearning cv pytorch imagesegmentation sota pretraining