Paper Review: Diffusion Feedback Helps CLIP See Better

CLIP excels at abstracting openworld representations across domains and modalities, but has limitations in distinguishing orientation, quantity, color, and structure due to biased image-text pairs used in training. DIVA (uses the DIffusion model as a Visual Assistant for CLIP), a post-training approach using a self-supervised diffusion process, enhances CLIP’s visual representations by leveraging generative feedback from text-to-image diffusion models. This method improves CLIP’s performance on the MMVP-VLM benchmark (which assesses fine-grained visual abilities), multimodal understanding, and segmentation tasks, while preserving its strong zero-shot capabilities, as confirmed by evaluations on 29 image classification and retrieval benchmarks.
The approach
Preliminaries
CLIP’s visual deficiencies
CLIP demonstrates strong generalization capabilities but struggles with detailed visual distinctions due to its training paradigm and data format. Its contrastive learning strategy focuses on high-level semantics, often missing visual details like orientation, quantity, color, and structure, resulting in similar embeddings for visually distinct images. Additionally, the text in image-text pairs used for training is limited in length (effective text length is 20), lacking descriptions of visual details, which further hinders CLIP’s ability to perceive fine visual distinctions.
Generative diffusion models
A diffusion model learns to model a probability distribution by reversing a process that progressively adds noise to an image. Starting from an image sample, a forward diffusion process adds random Gaussian noise in steps defined by a Markov chain. The noise addition follows a time-dependent variance schedule. As the number of steps increases, the image becomes pure noise. The model then reverses this process, starting from noise to generate an image sample.
Overall structure of DIVA
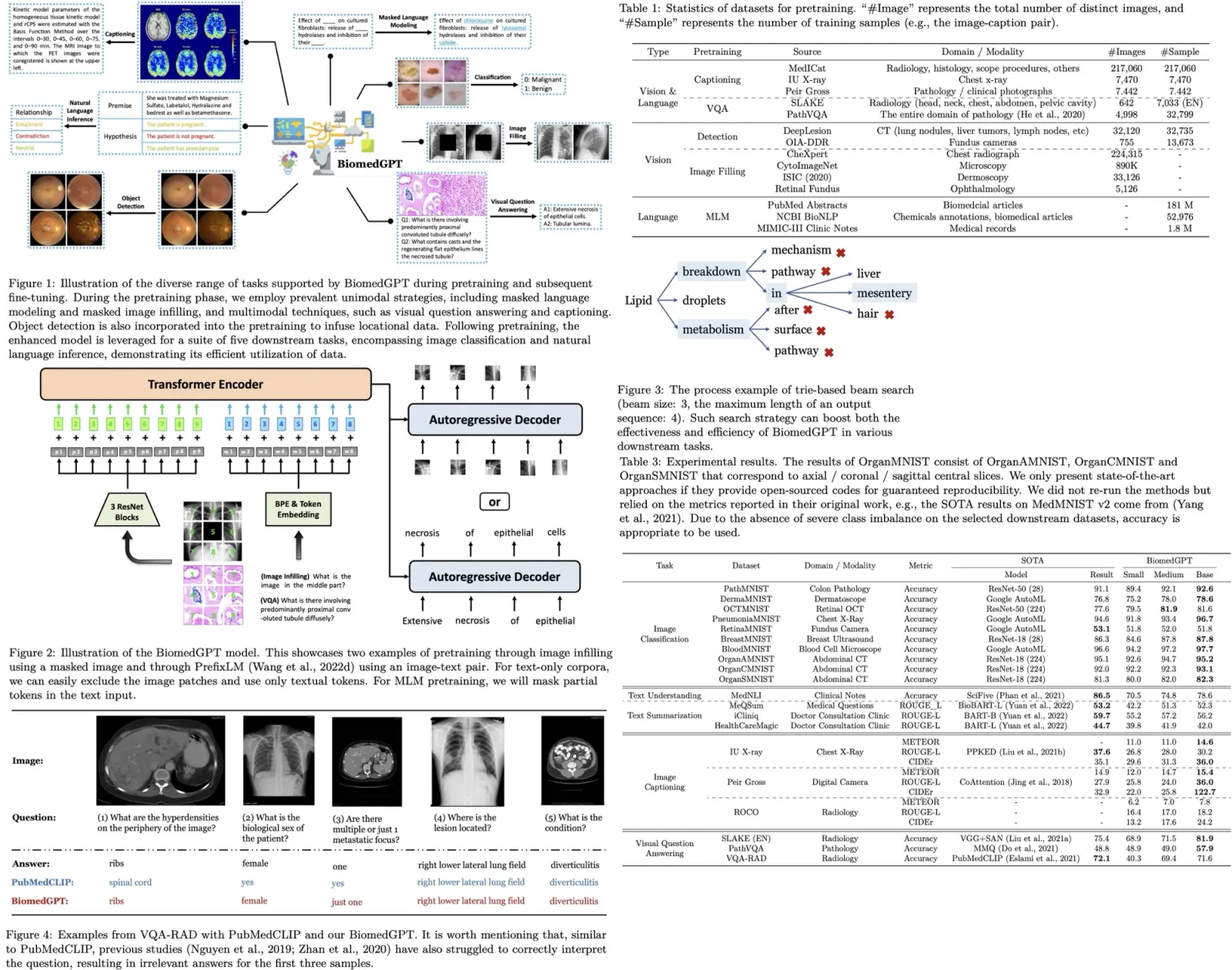
DIVA consists of two main components: the CLIP model and a pre-trained diffusion model. The CLIP model takes an original image and an empty text as inputs. The visual features encoded by CLIP are combined with the empty text’s embeddings from the diffusion model’s text encoder. The diffusion model then predicts the noise added at each step in a process repeated N times, optimizing randomly selected states. The training objective minimizes the reconstruction loss, keeping all weights except the CLIP model frozen. This process refines CLIP’s semantic representations to include more visual details without significantly harming its zero-shot performance.

Diffusion’s Condition Design
DIVA’s Visual Dense Recap Scheme enhances CLIP’s visual capabilities by incorporating local patch token features along with the class token into the diffusion model’s condition. This strategy enriches the visual information used for reconstruction, overcoming the limitations of using only the class token, which lacks sufficient detail.
The density of the visual recap is crucial: too high a density simplifies the task and limits optimization, while too low a density makes reconstruction overly difficult. Optimal densities depend on specific models. For example, the authors randomly select local token features at 15% probability from 224 resolution images and 30% from 336 resolution from CLIP.
Experiments
DIVA is trained on 8 NVIDIA-A100 80GB GPUs.
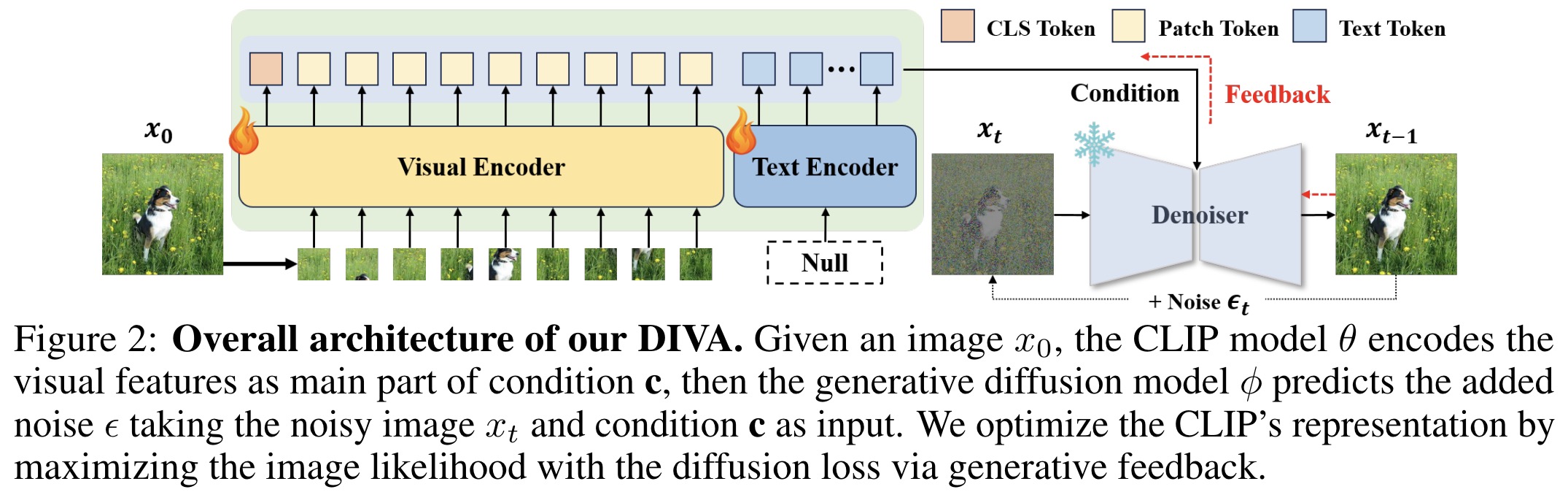
DIVA effectively addresses the visual capability deficiencies of various CLIP models, consistently enhancing their performance on the MMVP-VLM benchmark by 3-7%. The improved CLIP vision encoders boost multimodal understanding tasks, showing significant accuracy gains in benchmarks like LLaVA and MMBench. Additionally, DIVA enhances segmentation tasks, showing considerable performance improvements on ADE20K and Pascal Context benchmarks. Finally, DIVA improves fine-grained visual perception without compromising the original generalization abilities of CLIP models, maintaining strong zero-shot performance in image classification and retrieval tasks.

Ablation studies
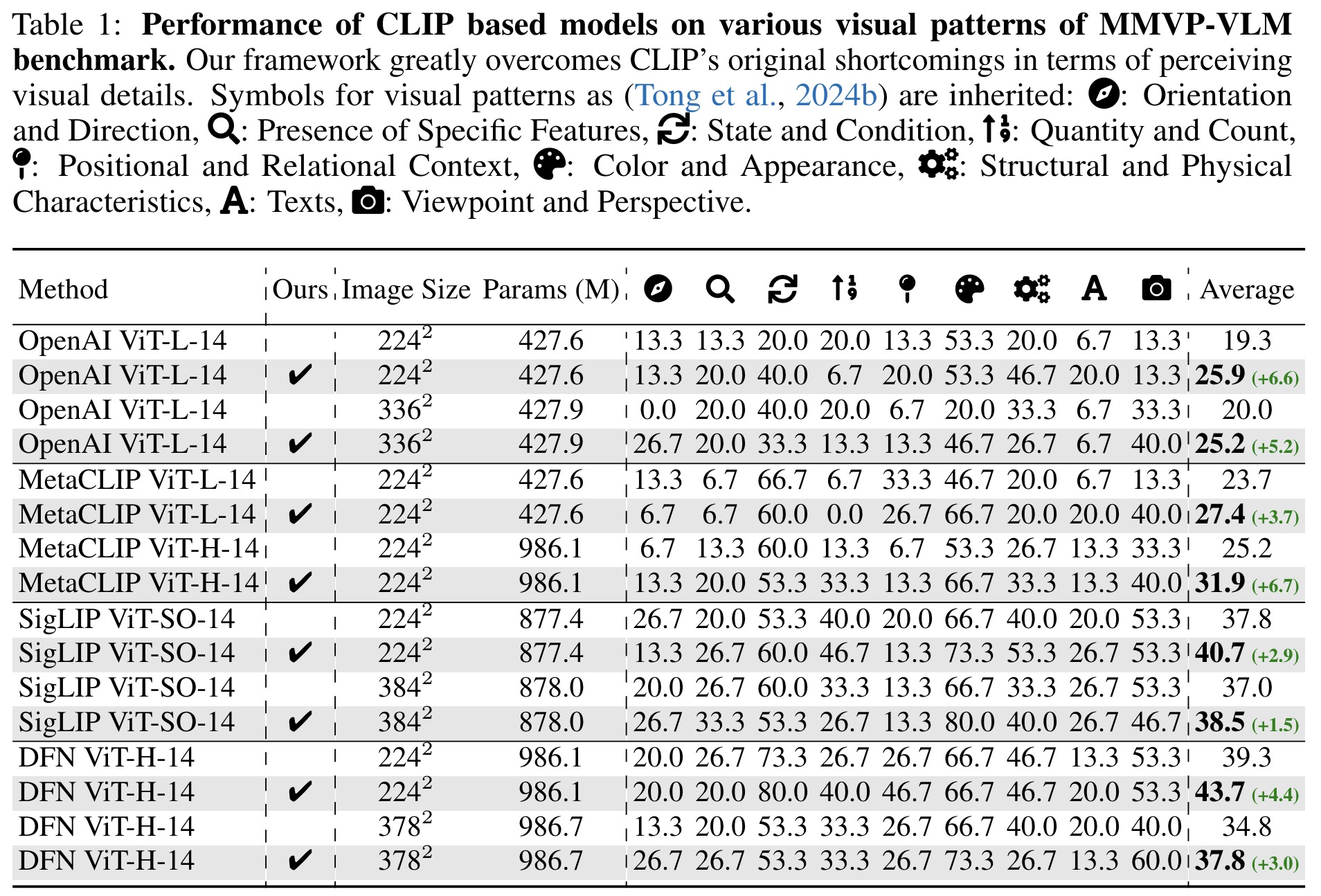
The effect of condition design for diffusion models in DIVA is crucial for enhancing CLIP’s representation quality. Two condition settings were examined: using pure text embeddings and incorporating densely recapped visual features with empty text embeddings. The latter yielded the best performance gains (up to 6.6%). The performance improvement is sensitive to the density of visual features introduced.
Data scaling with the CC-3M dataset demonstrated that DIVA consistently improves CLIP’s performance on the MMVP-VLM benchmark as the amount of training data increases. The framework showed no signs of diminishing returns, suggesting great potential for scalability. With 100% training data, DIVA significantly boosted visual perception capabilities with efficient training time.
Incorporating different diffusion models for generative guidance showed that SD-2-1-base achieved the highest performance gain (6.6%). DiT-XL/2, however, worsened CLIP’s ability to capture visual details due to its poorer representation quality.
paperreview deeplearning clip diffusion cv multimodal