Paper Review: Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold

This research introduces DragGAN, a new method for controlling the output of generative adversarial networks (GANs), used for generating realistic images. Traditional methods for control in GANs typically rely on manually annotated training data or prior 3D models, which often lack precision, flexibility, and general applicability. DragGAN overcomes these limitations by allowing users to “drag” any points in an image to reach target positions, offering interactive, precise control over generated images.
The system consists of two key parts: a feature-based motion supervisor to guide a handle point towards a target position, and a point tracking approach which utilizes distinctive generator features to continuously pinpoint the position of the handle points. This enables users to deform an image with precision, manipulating the pose, shape, expression, and layout of various objects in the image.
Because manipulations are performed within the learned generative image space of the GAN, they tend to produce realistic results even in difficult scenarios. Comparisons show that DragGAN outperforms previous methods in image manipulation and point tracking tasks. The research also demonstrates that real images can be manipulated using GAN inversion.
Method
The approach is based on StyleGAN2.
Interactive Point-based Manipulation
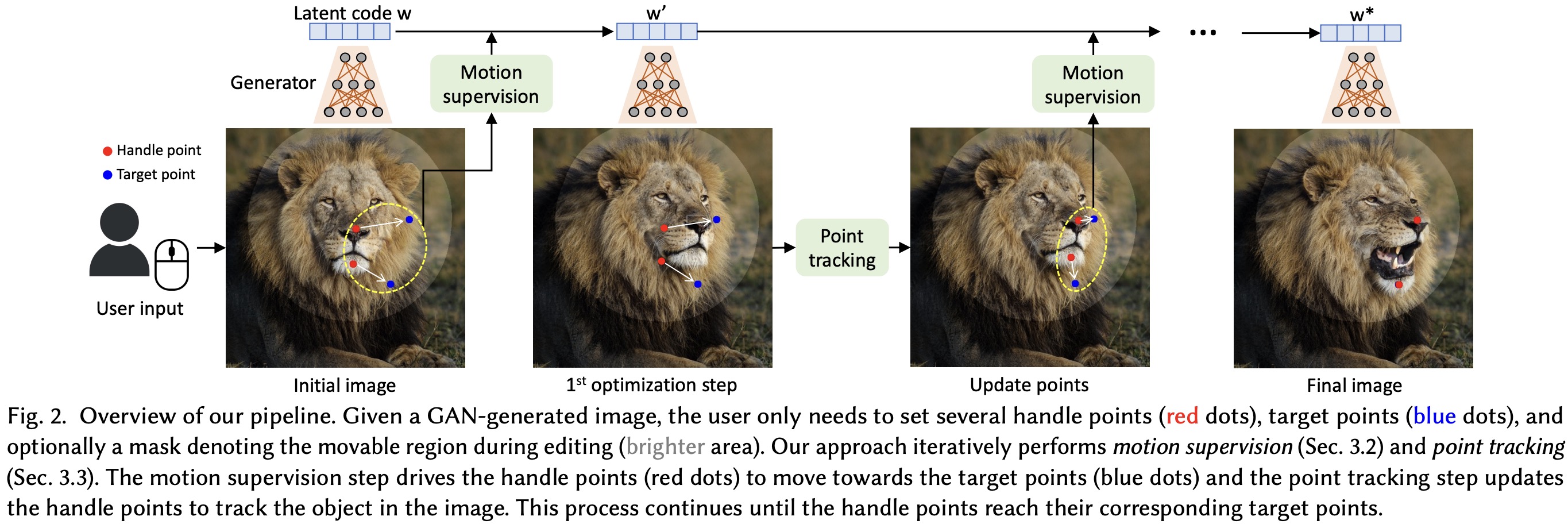
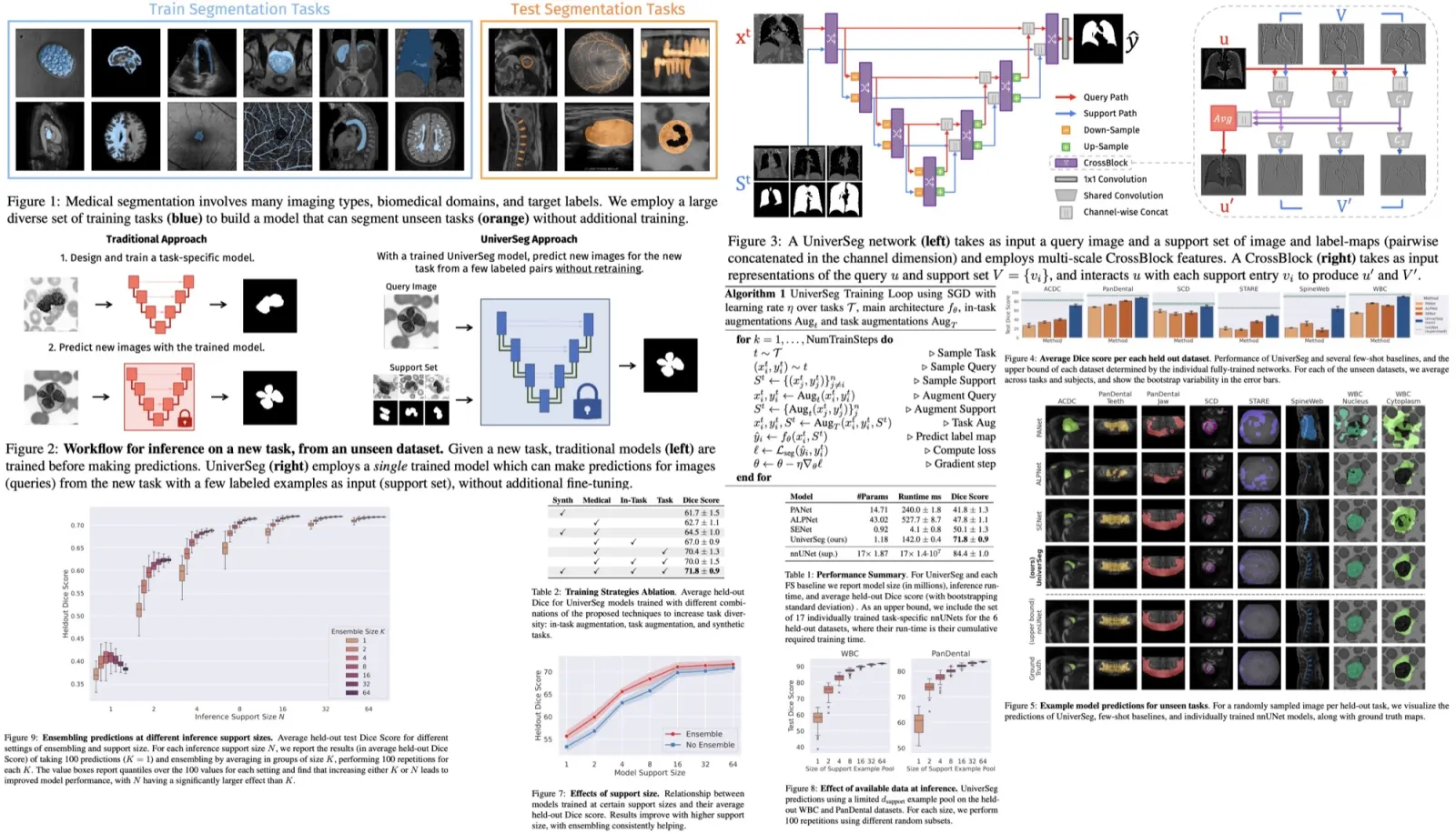
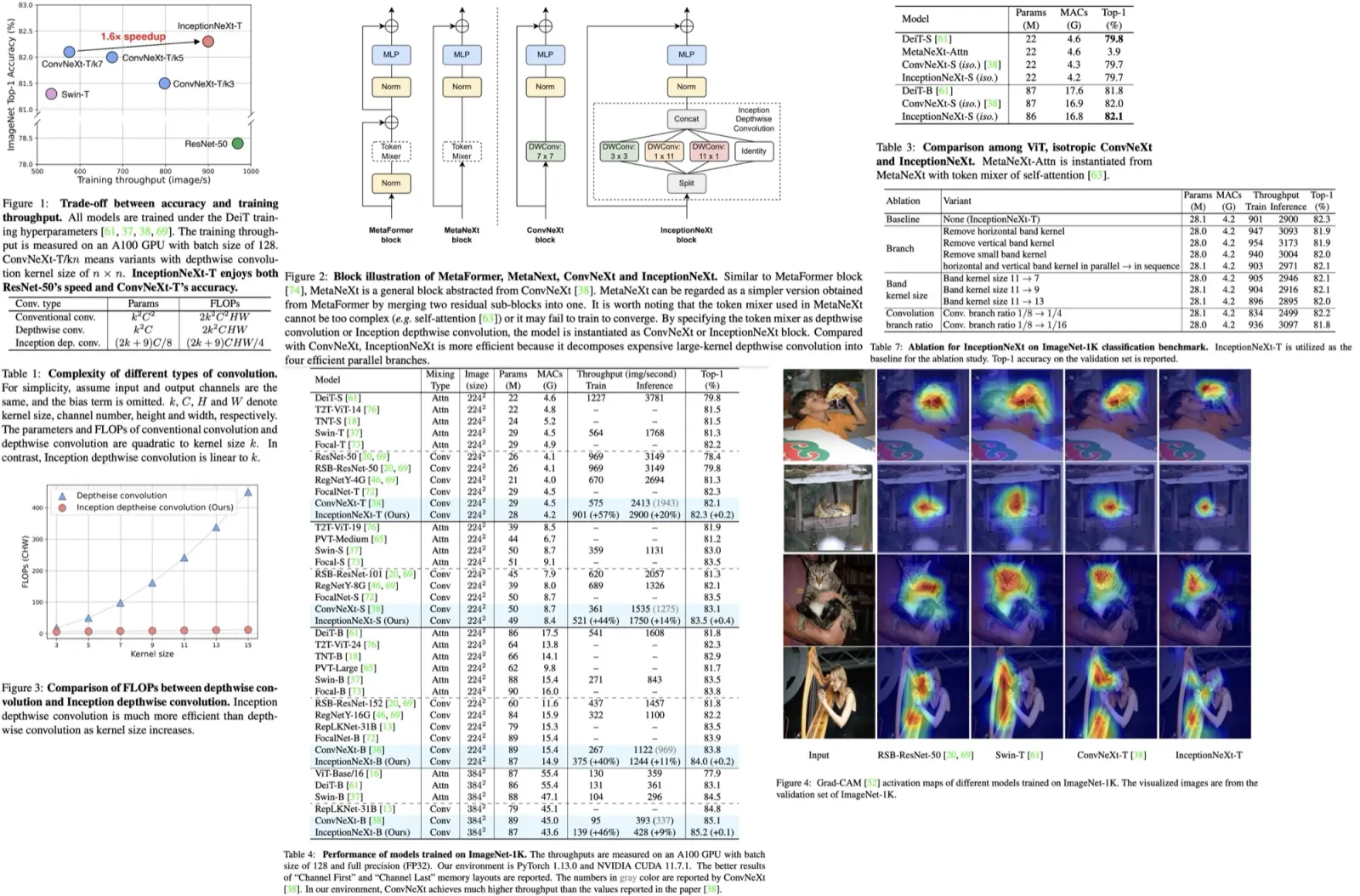
The users can interact with any image generated by a GAN using a set of handle points and corresponding target points, which define the movements they want to see in the image. For instance, users might adjust the location of a nose or jaw in a face. They can also specify a binary mask to define which region of the image is movable.
The image manipulation process involves two steps: motion supervision and point tracking. In motion supervision, a loss function encourages the handle points to move towards their target points, leading to an update in the latent code that defines the image. This results in a new image where the object has moved slightly.
However, the exact movement is subject to complex optimization dynamics and can vary depending on the object or part in question. To maintain accurate control, the researchers use a point tracking step to update the positions of the handle points on the new image. This process ensures the correct points are being manipulated in subsequent iterations.
This iterative optimization process continues until the handle points reach their target positions, typically after 30-200 iterations in their experiments. Users can halt the optimization at any time, and once they’re done with one round of edits, they can define new handle and target points to further refine the image until they’re satisfied with the results.
Motion Supervision
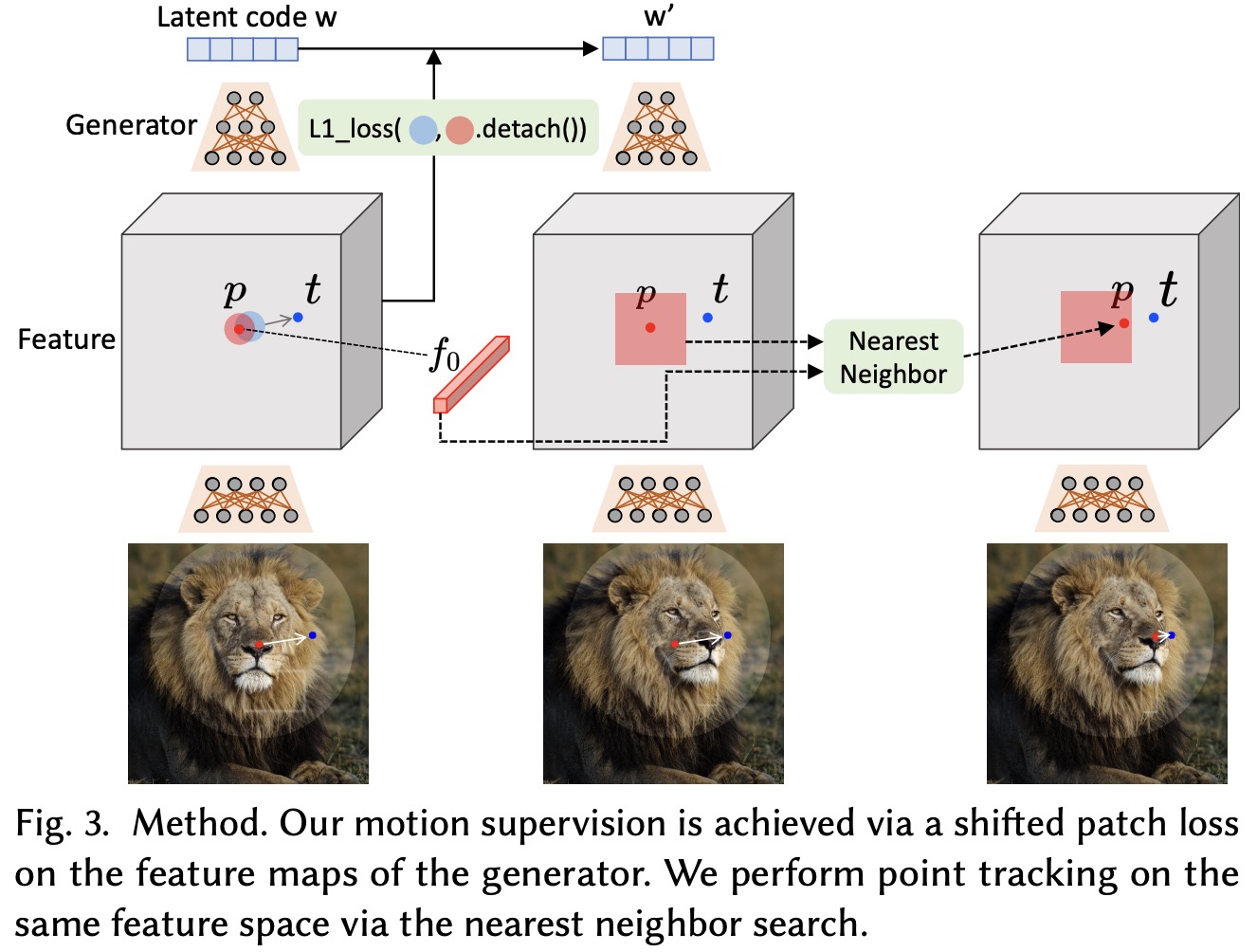
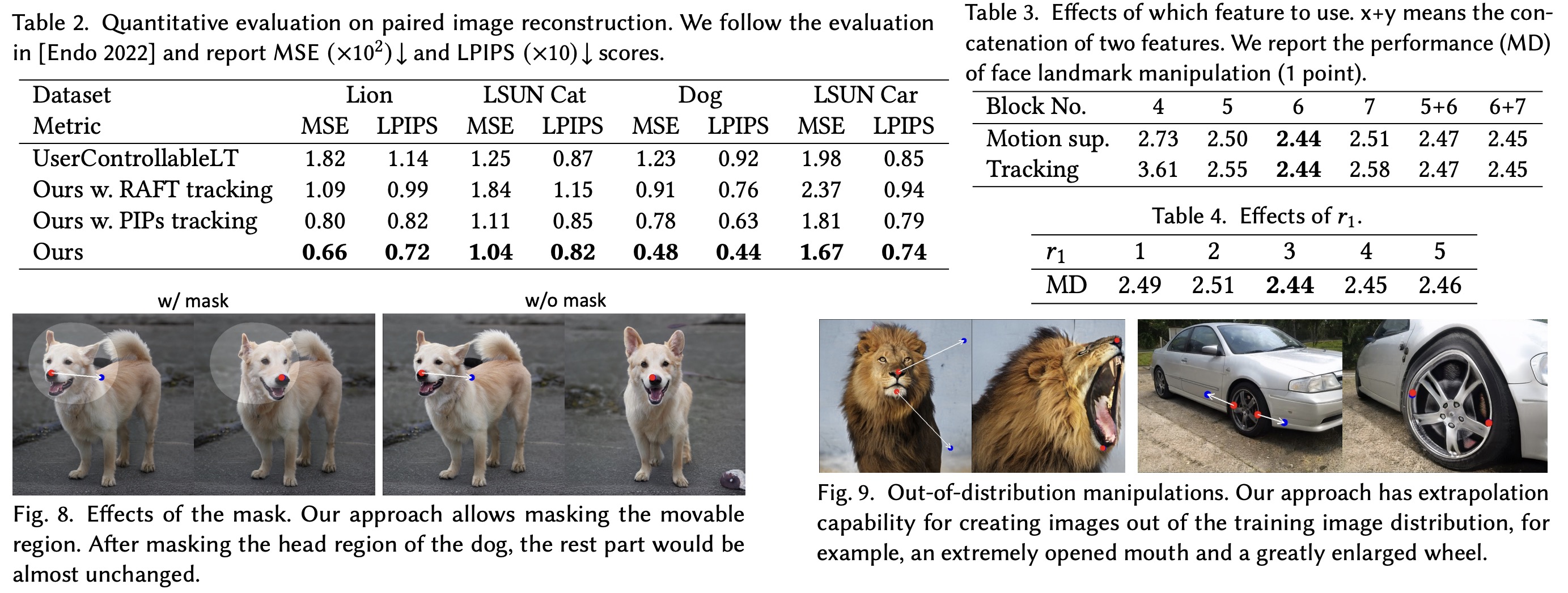
Motion Supervision is based on the premise that the generator’s intermediate features are very discriminative, allowing for simple supervision of motion. Specifically, they use the feature maps after the 6th block of StyleGAN2, which offers the best balance between resolution and discriminativeness.
To move a handle point to a target point, the researchers supervise a small patch around the handle point to move towards the target by a small step. This is achieved through a specific motion supervision loss function that measures the difference between the feature values at the handle and target points.
During back-propagation, the gradient is not back-propagated through the handle point feature values. This ensures that the handle point is motivated to move towards the target, and not the other way around. If a binary mask is provided, the unmasked region of the image is kept fixed with a reconstruction loss.
For optimal results, they found that only the latent codes corresponding to the first 6 layers need to be updated, as these mainly affect the spatial attributes of the image. The remaining layers primarily influence the appearance, so they are kept fixed to preserve this aspect of the image. This selective optimization results in a slight but desirable movement of the image content.
Point Tracking
After the motion supervision step, we have a new latent code, feature maps, and a new image. However, this does not provide the precise new locations of the handle points. To solve this issue, the authors propose a new point tracking approach specifically designed for GANs, which does not rely on optical flow estimation models or particle video approaches that can harm efficiency and accumulate error.
The tracking approach is based on the idea that the discriminative features of GANs accurately capture dense correspondence, and thus, tracking can be performed via nearest neighbor search in a feature patch. To track a handle point, they find the feature of the handle point in the initial feature map and locate the nearest neighbor to this feature in the new feature map within a specific area around the handle point. The point with the closest feature in this area is then identified as the new location of the handle point.
This process is repeated for all handle points in the image. Here, too, they use the feature maps after the 6th block of StyleGAN2, which are resized to match the image’s resolution, if necessary.
Experiments



Qualitative Evaluation
The authors demonstrate the effectiveness of their approach, DragGAN, through image manipulation experiments across several object categories. The approach effectively moves handle points to target points, resulting in diverse and natural manipulation effects, such as altering the pose of animals, the shape of a car, and the layout of a landscape. They note that the existing UserControllableLT approach often fails to accurately move the handle points to the target points, leading to undesired changes in the images.
The authors also demonstrate that their approach can be applied to real images by using GAN inversion techniques to embed a real image into the latent space of StyleGAN. They use PTI inversion to convert the real image and then perform a series of manipulations, such as editing the pose, hair, shape, and expression of a face in the image.
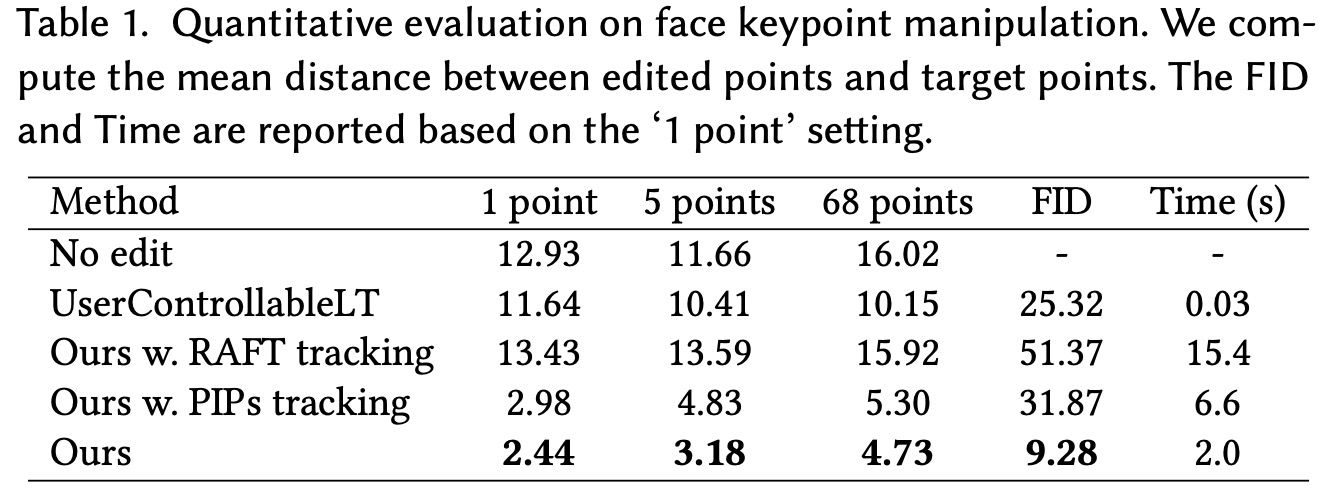
Quantitative Evaluation
The authors quantitatively evaluate their image manipulation method, DragGAN, in two different scenarios: face landmark manipulation and paired image reconstruction. In the face landmark manipulation test, they generate two face images using StyleGAN trained on the FFHQ dataset and detect their landmarks. In the paired image reconstruction test, they sample a latent code, perturb it to get a second code, and generate images from these codes. They then compute the optical flow between the two images and randomly sample 32 pixels as user input. The goal is to reconstruct the second image from the first one and the user input.
Discussions
The authors discuss the effects of masks in their image manipulation approach, DragGAN. If a user inputs a binary mask specifying the movable region, it allows more targeted manipulation. For instance, applying a mask over the head of a dog, only the head moves while other parts remain fixed. However, without the mask, the manipulation impacts the entire body of the dog.
The authors also show the model’s capability to produce out-of-distribution manipulations, creating images outside the training image distribution. However, if users want to keep the image within the training distribution, additional regularization to the latent code can be added.
They also discuss the limitations of DragGAN, including its dependency on the diversity of training data and challenges with handle points in texture-less regions, which sometimes suffer from drift in tracking.
Lastly, the authors discuss potential social impacts, cautioning that this method could be misused to create misleading images of real people with falsified poses, expressions, or shapes. They emphasize the importance of respecting personal rights and privacy regulations in any application of their approach.
paperreview deeplearning cv gan pytorch