Paper Review: DreamLLM: Synergistic Multimodal Comprehension and Creation

DreamLLM is a new learning framework designed for Multimodal Large Language Models. It emphasizes the synergy between understanding and generating both text and images. Its two main principles are generative modeling in the raw multimodal space, avoiding the constraints of external feature extractors, and generating raw, interleaved content of both text and images, including unstructured layouts. This enables DreamLLM to understand and produce multimodal content in a more integrated manner. Experiments show that DreamLLM excels as a zero-shot multimodal model, benefiting from its enhanced learning approach.
Background & problem statement
Autoregressive Generative Modeling predicts tokens in a sequence based on preceding tokens. When applied to multimodal data (like images interleaved with words), images are processed into visual embeddings through a series of encoders and projectors. The objective is to maximize the likelihood of predicting the next token given previous ones.
Diffusion Models are probabilistic generative models that understand data structure through a process of continuous diffusion. This method involves a process that smoothly changes data to Gaussian noise and then a reverse process to generate data from that noise. The key idea is to use a denoising function that estimates the noise level in the data.
MLLMs for Diffusion Synthesis. While deep language models can enhance cross-modal image generation, the potential of using multimodal creation to improve comprehension hasn’t been much explored. Current strategies integrate DMs with Multimodal Large Language Models by aligning their semantic spaces. However, these integrations might be problematic as they may force MLLMs to produce semantically reduced information.
The goal of the paper is to use MLLMs to directly sample distributions in pixel space. The methodology resembles Score Distillation Sampling. The authors suggest a shift from aligning MLLMs output with models like CLIP to querying MLLMs using learned embeddings. This way, MLLMs’ semantics can serve as a basis for diffusion conditioning, modeling distributions through synthesis sampling.
DreamLLM
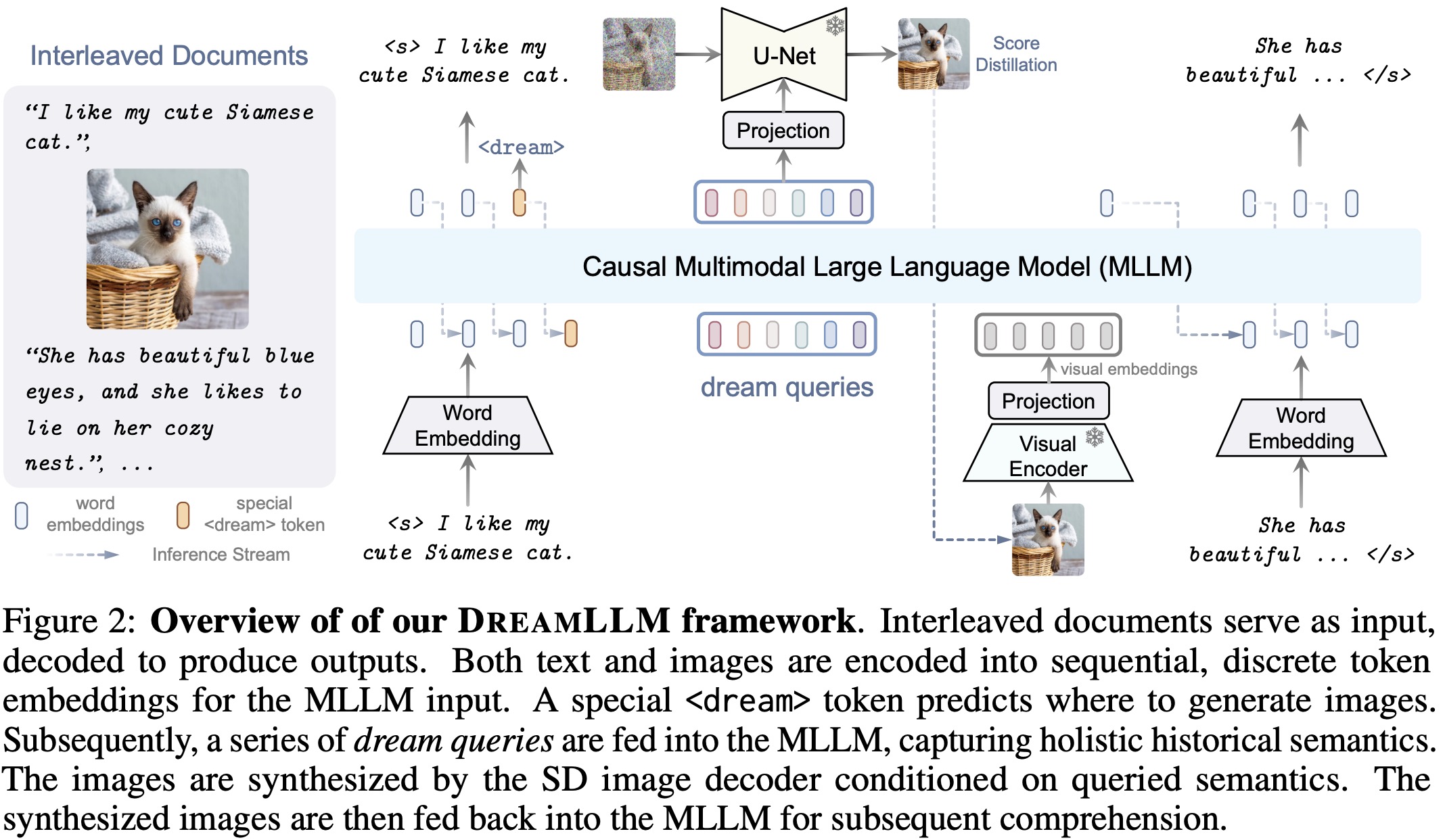
End-to-end interleaved generative pretraining (I-GPT)
All natural documents can be seen as carriers of both text and image information, while text-only or image-only documents are just special cases. It’s essential for models to understand and generate such interleaved documents encompassing a variety of modality compositions.
Interleaved Structure Learning:
- The model learns to generate documents with both text and images. A special
<dream>token is introduced to indicate where an image should emerge. - DreamLLM is trained to predict this token during training, enabling conditional image synthesis.
Conditional Synthesis through Score Distillation:
- Learnable dream queries are incorporated for conditional embeddings. When a
<dream>token is predicted, the model can causally query previous sequences to perform image synthesis. - This method involves denoising score matching with latent variables, with the objective of minimizing the difference between the model’s conditional expectations and actual noise in the data.
Universal Multimodal Generative Modeling:
- The model handles interleaved document sequences containing words and images, with the autoregressive approach enabling it to predict words from images and synthesize images from words.
- The images are processed as visual embeddings for causal comprehension, allowing for optimized synthesis posterior.
- The model seeks to unify the learning objective to the maximum likelihood estimation of all causally-conditioned posteriors in any form, whether encoded images or words, providing a more comprehensive and versatile approach to multimodal learning.
Model training
- Alignment Training: This phase focuses on lessening the multimodality gap and aiding LLMs in adapting to multimodal inputs. It uses approximately 30 million image-text pairs for training and focuses on both comprehension and synthesis of image-to-text. In this stage, certain components are pretrained for aligning different modalities, such as linear visual and condition projectors and learnable dream embeddings, while others, like LLMs, visual encoders, and SD, are kept frozen.
- I-GPT Pretraining: Post alignment, the LLM is unfrozen for further pretraining. This crucial step aids in learning the combined vision-language distributions through generative modeling, using around 2 million selectively filtered documents and an additional 2 million paired data samples captioned by BLIP. This step aims to boost text-to-image training and potentially reduce the effects of lower-quality images and texts.
- Supervised Fine-tuning: The last stage aims to fine-tune the model, enabling it to perform a variety of multimodal comprehension and creative tasks in response to human instructions. Approximately 80,000 visual instruction tuning data are utilized, and GPT-4 is prompted with summaries or image captions for collecting instruction-following synthesis data, ensuring the model’s proficiency in content creation following instructions.
Experiments
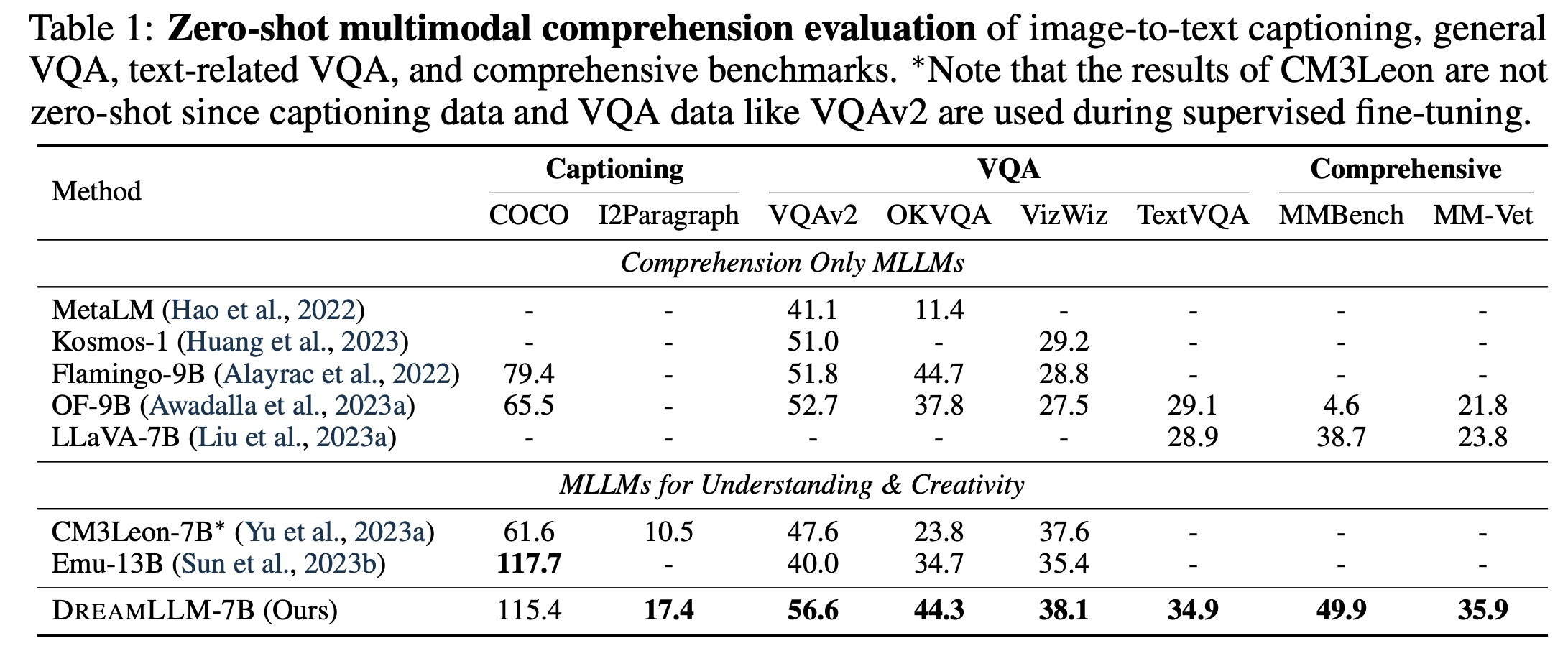
- Multimodal Comprehension: DreamLLM demonstrates superior performance across all benchmarks, notably surpassing other models in accuracy and spatial/relation reasoning capabilities, especially in tasks requiring image synthesis learning.
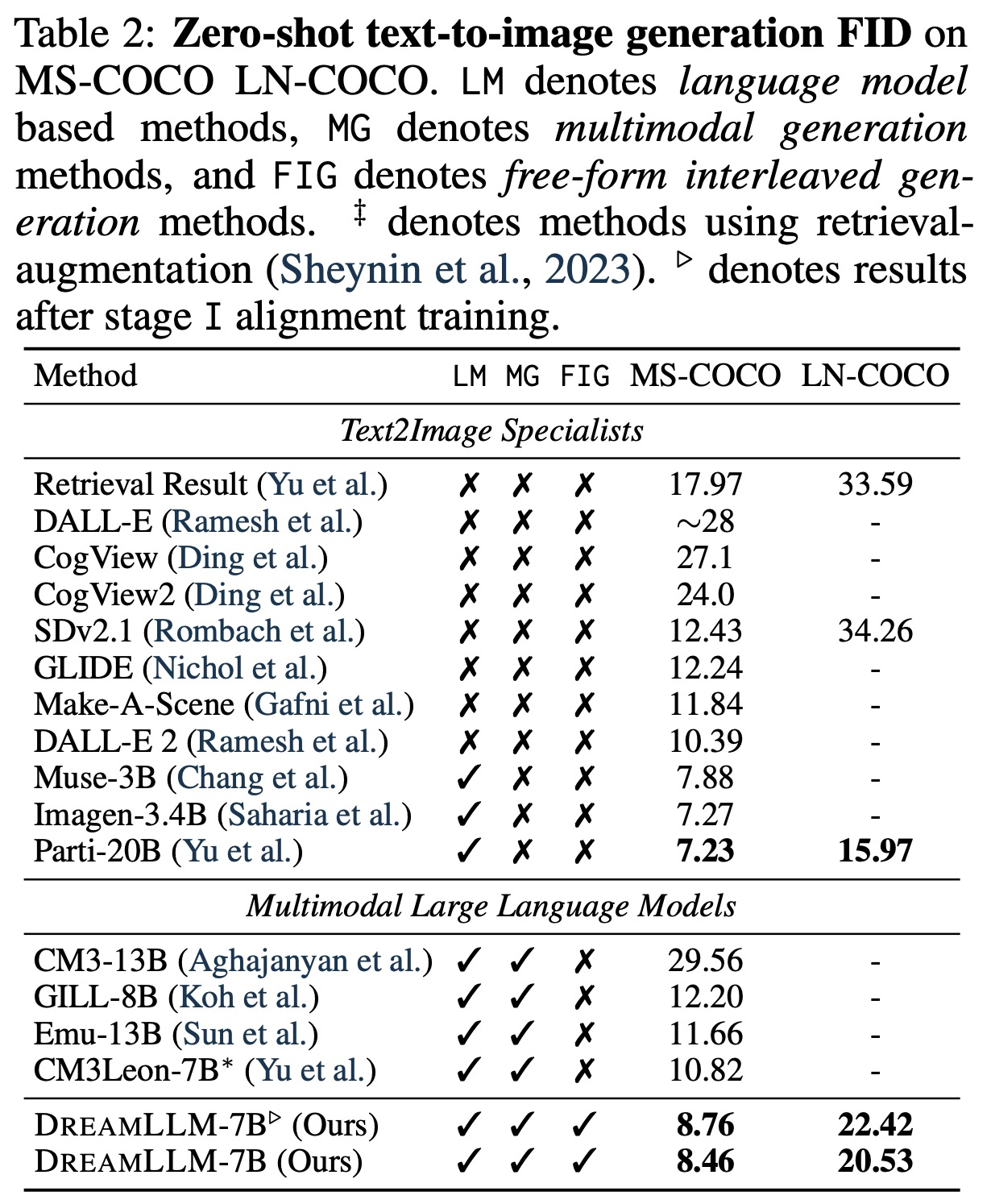
- Text-conditional Image Synthesis: The model exhibits significant improvements in FID scores over the baseline, illustrating enhanced capability in processing long-context information and competitive results with other models, even surpassing them in many instances.
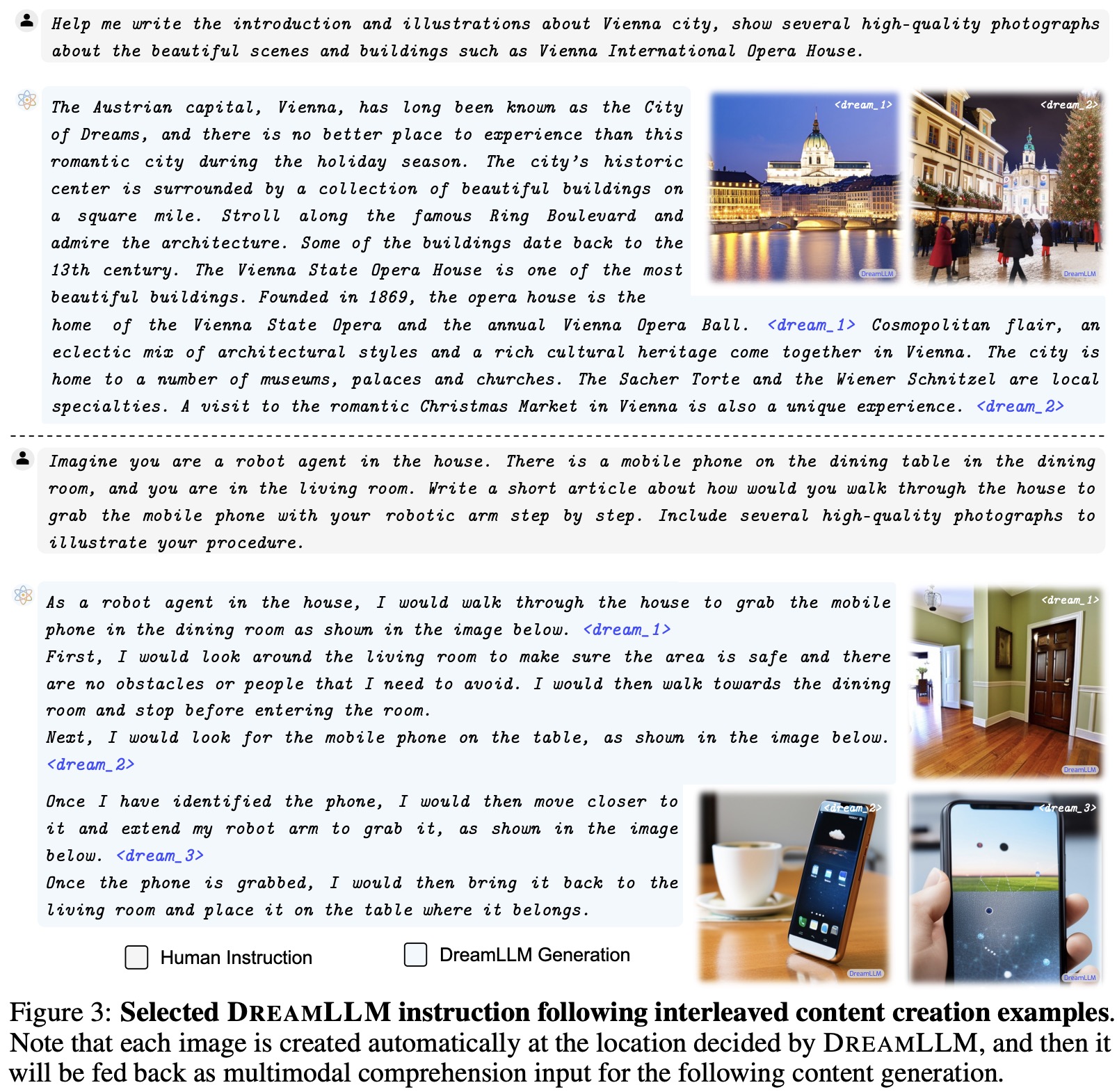
- Multimodal Joint Creation & Comprehension: DreamLLM, empowered with instruction tuning, acts as a multimodal generalist and can generate interleaved documents in a free-form manner and produce meaningful responses following given instructions. The system can autonomously create images at specified locations with accurate correspondence to the associated text, offering a user-friendly approach compared to models like Emu.
- Image Quality & Human Evaluation: DreamLLM significantly outperforms in FID scores, indicating superior image quality and alignment with text. A human evaluation also confirms the quality of the generated samples, with DreamLLM achieving a supportive rate of 60.68%, indicating high-quality and logically placed images in the generated documents, surpassing the Turing test requirement of 30%.