Paper Review: Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes

The authors introduce a new mechanism called Distilling step-by-step to train smaller models that outperform large language models (LLMs) while requiring less training data. This method uses LLM rationales in a multi-task training framework, providing additional supervision for small models. The study presents three key findings: 1) their mechanism achieves better performance with fewer labeled/unlabeled examples than finetuning and distillation, 2) they outperform LLMs using substantially smaller model sizes, and 3) their 770M T5 model surpasses the 540B PaLM model on a benchmark task using only 80% of available data, reducing both model size and data requirements.
Distilling step-by-step
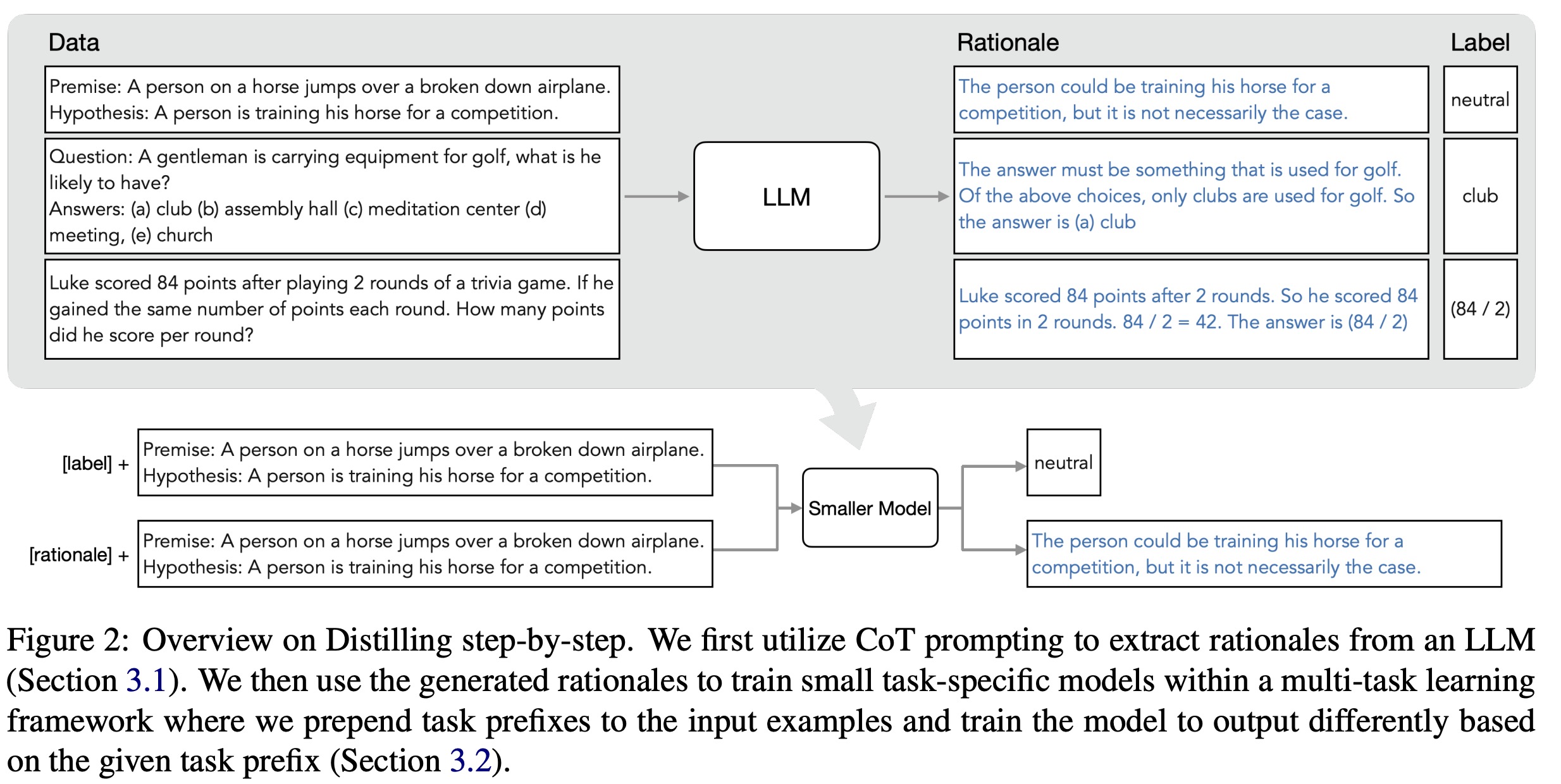
Extracting rationales from LLMs

Recent studies have highlighted the emerging ability of large language models (LLMs) to generate rationales supporting their predictions. The authors of this paper use these rationales to train smaller downstream models. They employ Chain-of-Thought (CoT) prompting to elicit and extract rationales from LLMs. Given an unlabeled dataset, they create a prompt template that outlines how the task should be solved. The prompt includes an example input, its corresponding label, and a user-provided rationale. By appending each input to the prompt, the LLM is guided to generate rationales and labels for the entire dataset, effectively utilizing the demonstrations in the prompt to generate the desired output.
Training smaller models with rationales
The authors describe their framework for learning task-specific models, which incorporates rationales into the training process. The dataset is denoted as D, with each input xi and its corresponding output label yi. Though the framework supports inputs and outputs of any modality, the experiments focus on natural language inputs and outputs. This text-to-text framework covers a variety of natural language processing tasks, such as classification, natural language inference, and question answering.
Standard finetuning and task distillation. The most common practice to train a task-specific model is to finetune a pretrained model with supervised data. In the absence of human-annotated labels, task-specific distillation uses large language model (LLM) teachers to generate pseudo noisy training labels as a substitute. For both finetuning and distillation scenarios, the smaller model is trained to minimize the label prediction loss, represented by the cross-entropy loss between predicted and target tokens. The loss function accommodates both human-annotated labels for standard finetuning and LLM-predicted labels for model distillation.
Multi-task learning with rationales. The authors propose using extracted rationales as additional supervision when training smaller models. Instead of using rationales as extra inputs, they frame learning with rationales as a multi-task problem. The model is trained to predict both task labels and generate corresponding rationales given text inputs. This is their proposed Distilling step-by-step approach. By including a rationale generation loss, the model learns to generate intermediate reasoning steps for predictions, potentially improving label prediction. The method does not require rationales at test time, removing the need for an LLM during deployment. They prepend “task prefixes” (([label], [rationale])) to input examples, training the smaller model to output the predicted label or rationale based on the provided prefix.
Experiments
In the experiments, the authors use the 540B PaLM model as the large language model and T5 models for task-specific downstream models. They follow the Chain-of-Thought (CoT) prompting technique and curate their own examples for new datasets. They conduct experiments on four popular benchmark datasets across three different NLP tasks: e-SNLI and ANLI for natural language inference, CQA for commonsense question answering, and SVAMP for arithmetic math word problems.
Reducing training data
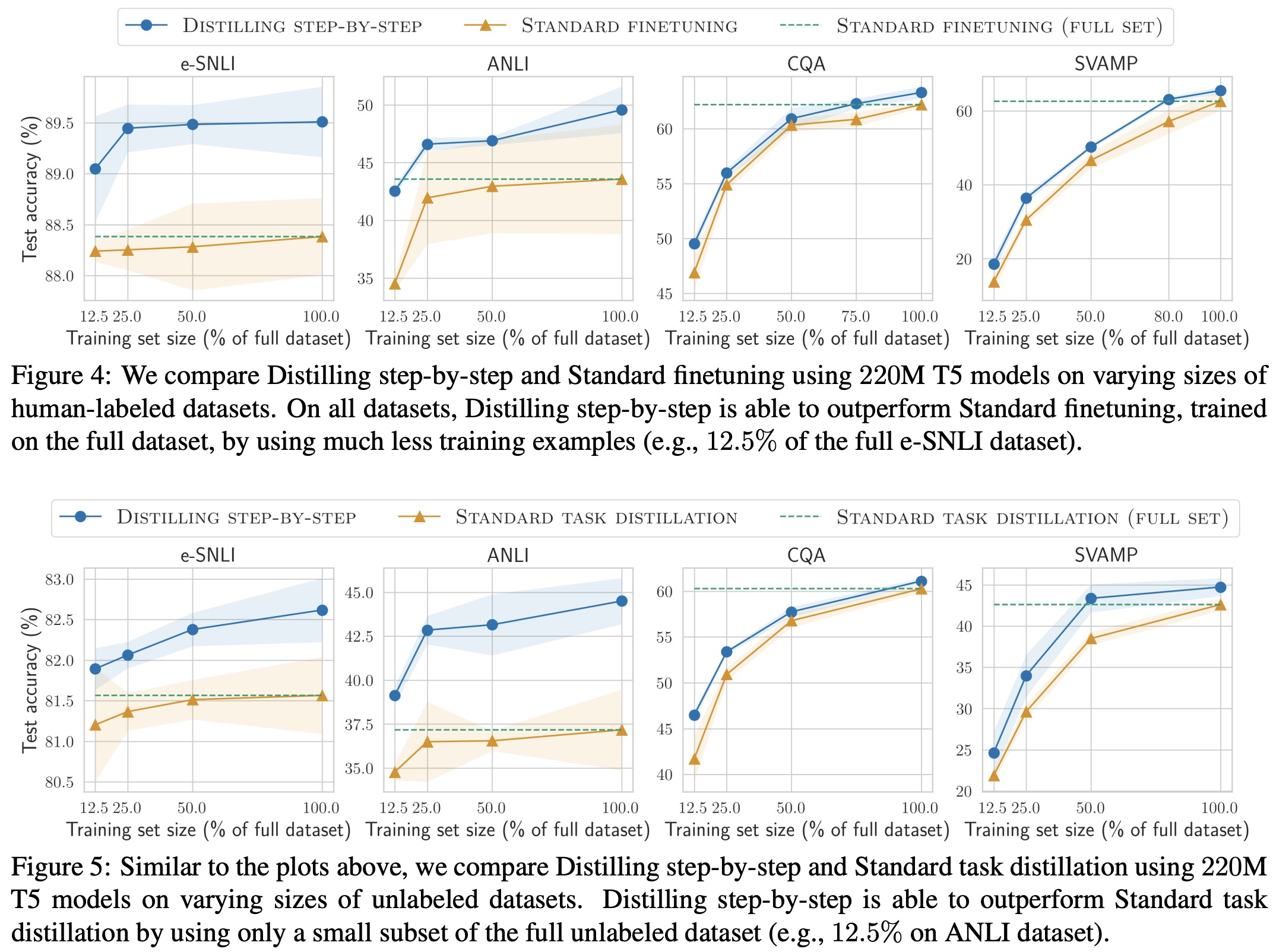
Distilling step-by-step demonstrates better performance than standard finetuning and distillation, requiring fewer labeled and unlabeled examples. The approach outperforms standard finetuning across various numbers of labeled examples and achieves the same performance with significantly less labeled data. For instance, using only 12.5% of the full e-SNLI dataset, it outperforms standard finetuning trained with 100% of the dataset. When only unlabeled data is available, Distilling step-by-step also outperforms standard task distillation across all four datasets, requiring less unlabeled data to achieve better results.
Reducing model size
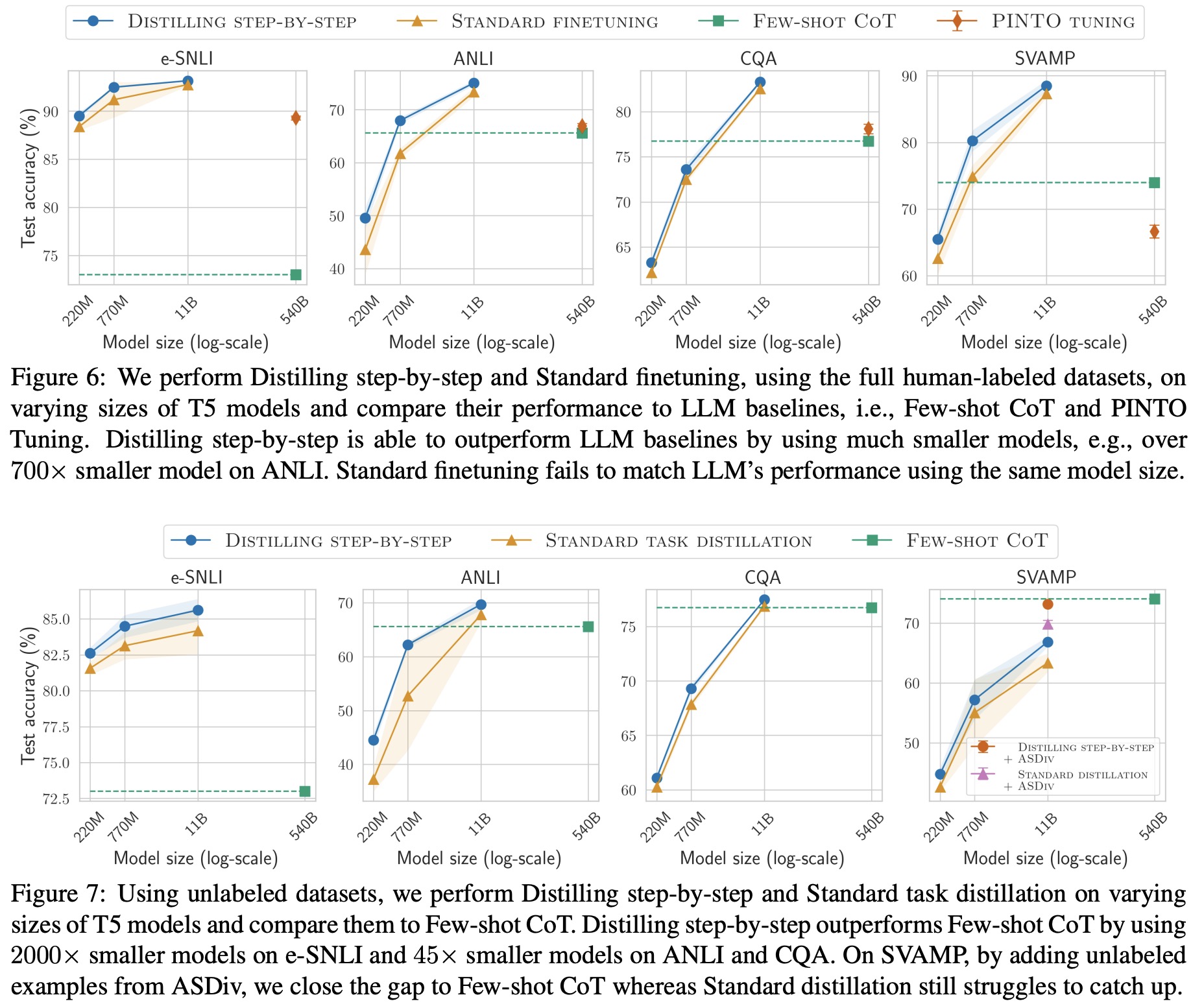
Distilling step-by-step consistently improves over standard finetuning and distillation across various T5 model sizes. It outperforms Large Language Models (LLMs) by using much smaller task-specific models. For example, it achieves better performance than the 540B PaLM model with T5 models that are significantly smaller in size. The approach surpasses the LLM on 3 out of 4 datasets when only utilizing unlabeled examples. Unlabeled data augmentation further improves the performance of Distilling step-by-step. Even with added unlabeled examples, standard task distillation underperforms compared to Few-shot CoT, while Distilling step-by-step efficiently exploits the value of the added examples to achieve the same performance level using a smaller T5 model.
Outperforming LLMs using minimum model size and least training data
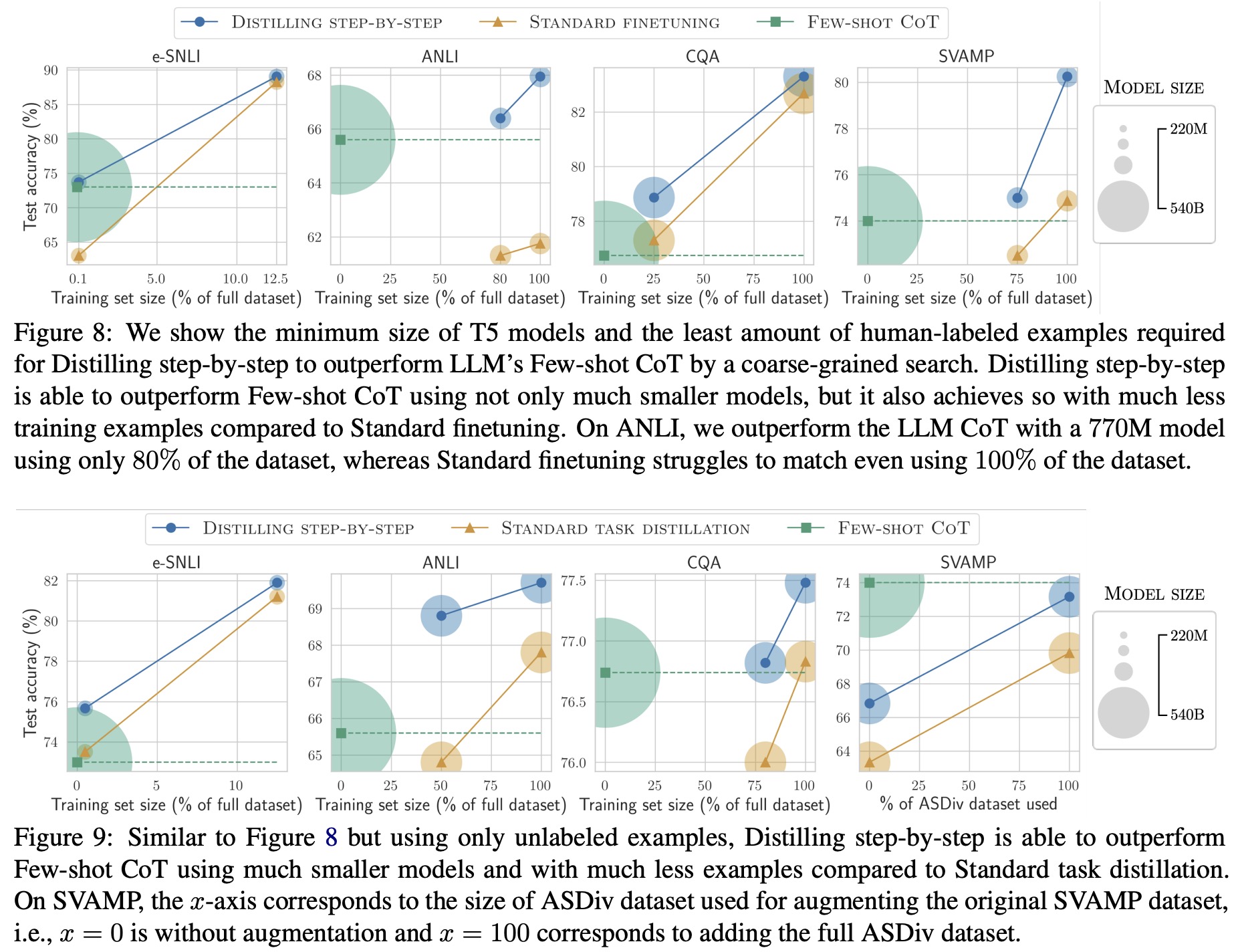
Distilling step-by-step outperforms LLMs using much smaller models and less data. It achieves better performance than PaLM’s Few-shot CoT with significantly smaller T5 models and smaller fractions of the available training examples. Standard finetuning and distillation often require more data or larger models to match LLM’s performance. Distilling step-by-step can outperform the LLM while using less data, whereas standard finetuning struggles to match LLM performance even with full datasets and may need larger models to close the performance gap.
Limitations
The current approach has some limitations. Firstly, it requires users to provide a few example demonstrations to use the few-shot CoT prompting mechanism, which could be improved by utilizing recent advances that elicit rationales without user-annotated demonstrations. Secondly, LLM rationales may exhibit limited reasoning capabilities on more complex tasks, and future work should investigate how rationale quality impacts the performance of Distilling step-by-step.
paperreview deeplearning nlp distillation llm