Paper Review: Dual PatchNorm
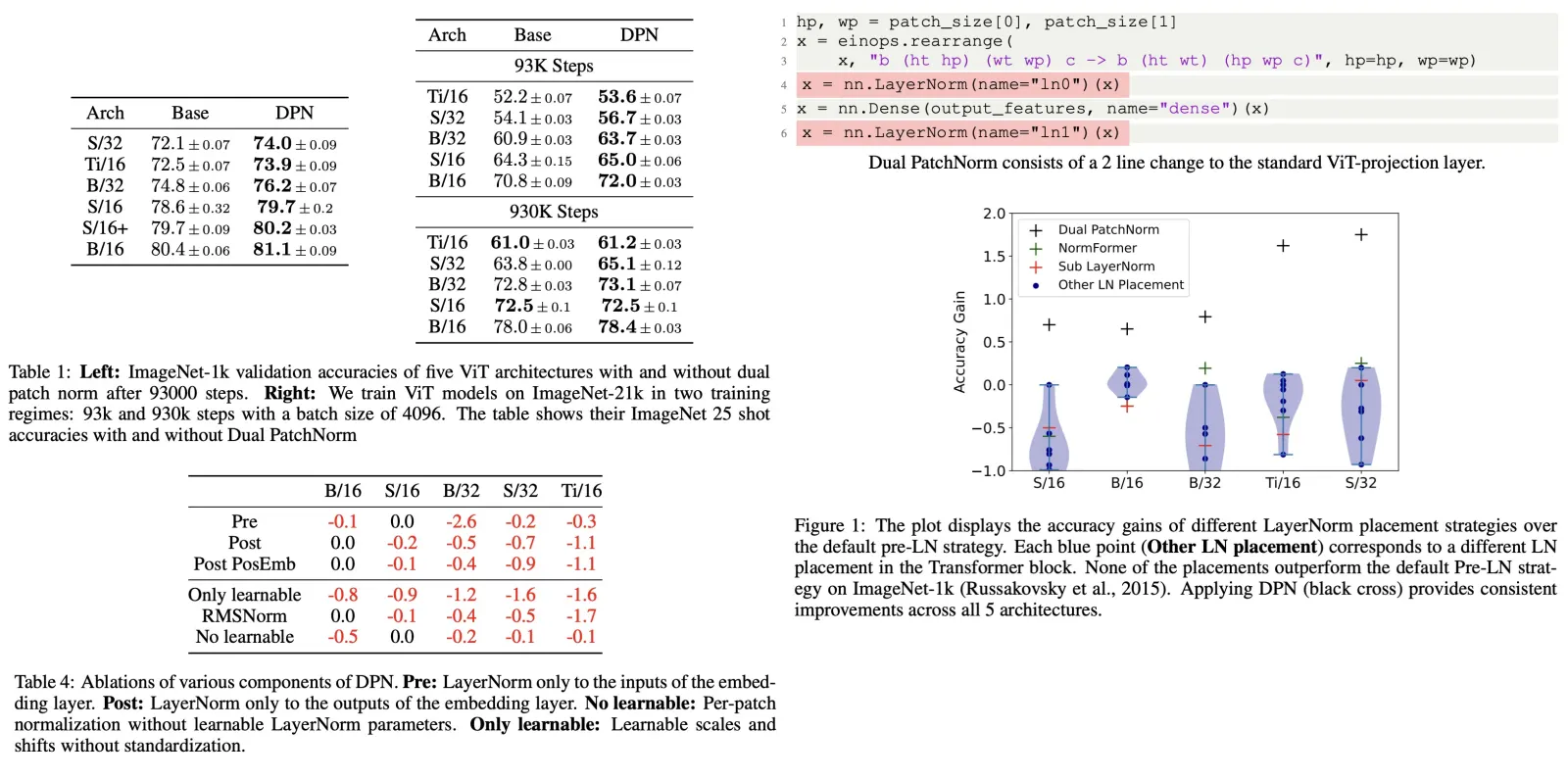
The authors propose a new method called Dual PatchNorm for Vision Transformers, which involves adding two Layer Normalization layers before and after the patch embedding layer. The results show that Dual PatchNorm outperforms other LayerNorm placement strategies and often leads to improved accuracy while never decreasing performance.
# https://github.com/lucidrains/vit-pytorch/blob/bdaf2d14916500e2978c49833795ed3b599e220d/vit_pytorch/deepvit.py#L106
# an example of using Dual PatchNorm
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim)
)
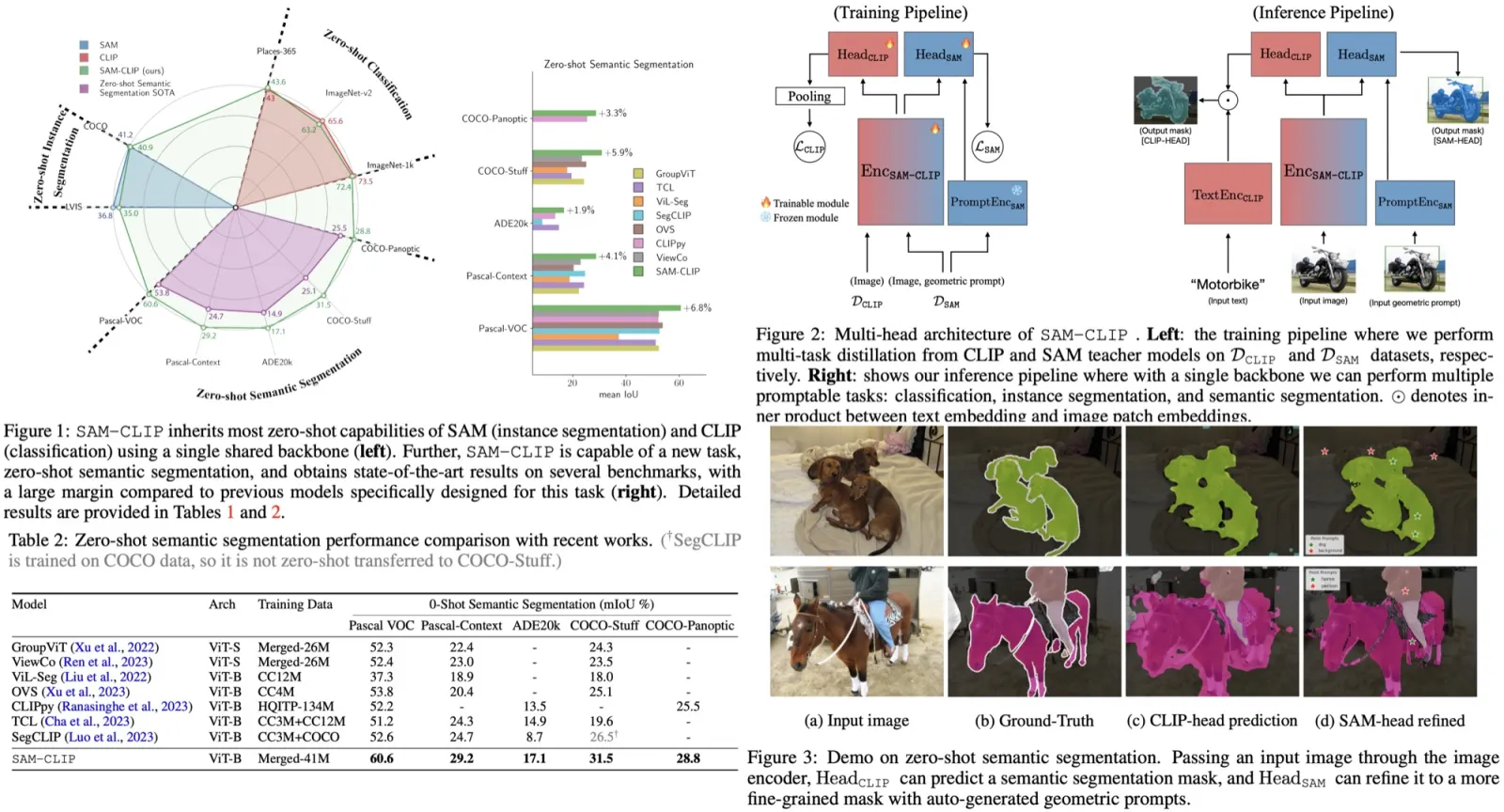
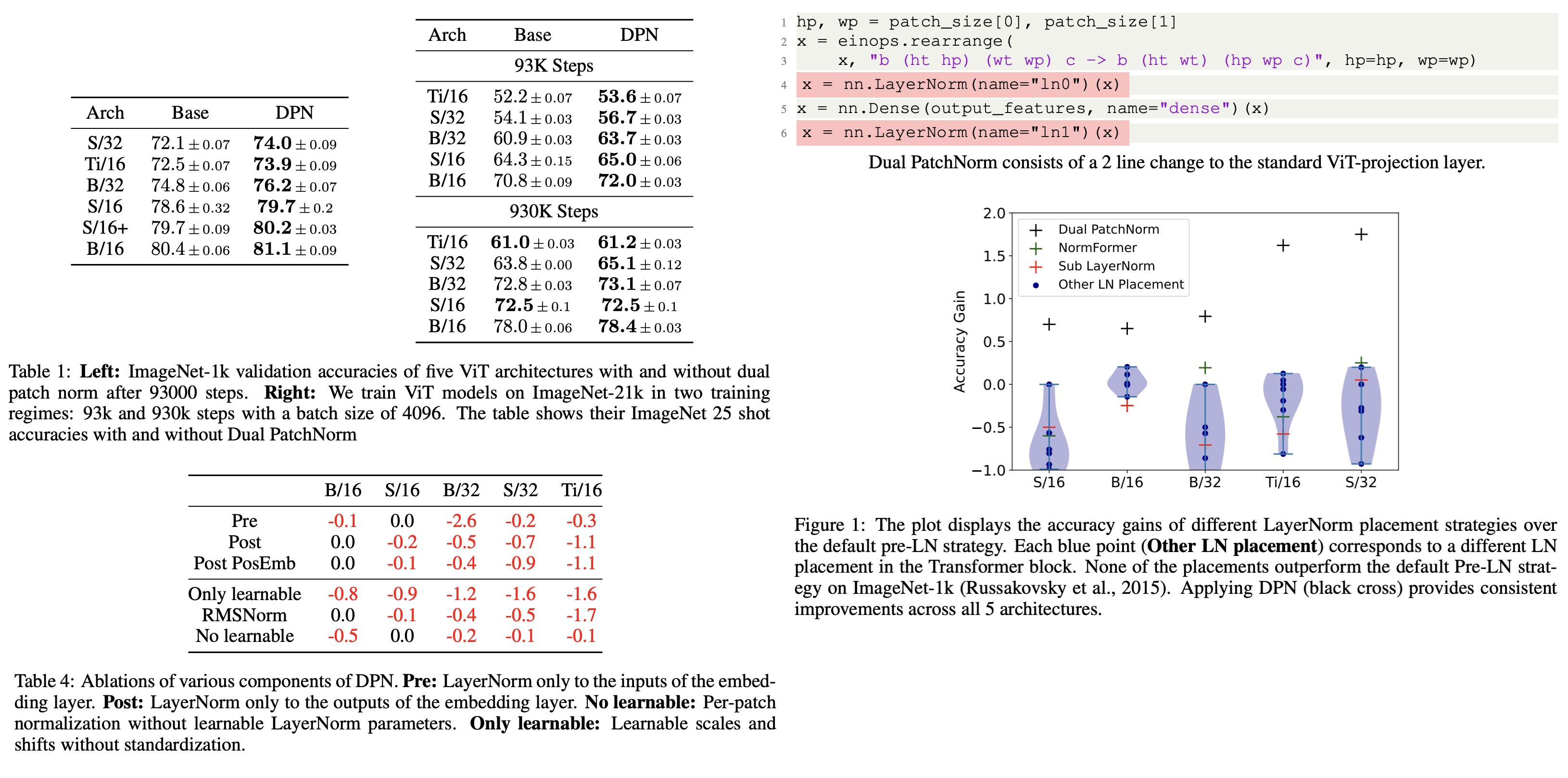
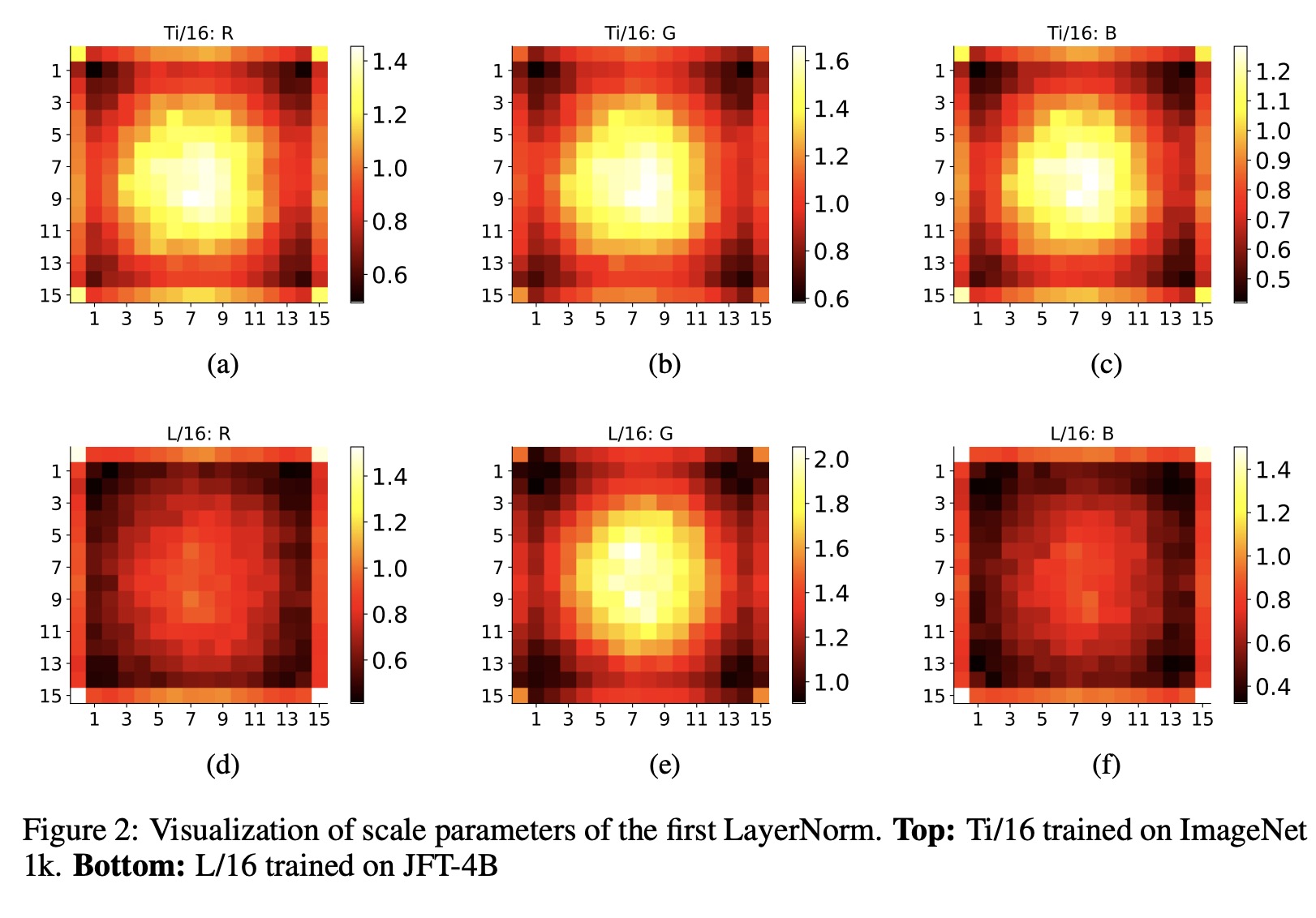
The authors explore the impact of different Layer Normalization (LN) placements on Vision Transformers (ViT) models. They conduct an exhaustive search of LN placements in Transformer blocks over five ViT architectures and find that the existing “pre-LN” strategy is close to optimal and other alternate placements do not improve performance. However, the authors make an observation that placing additional LN layers before and after the standard ViT-projection layer, called Dual PatchNorm (DPN), can significantly improve the performance of well-tuned ViT models. Experiments across three datasets show the efficacy of DPN. Qualitative experiments also support this.
Experiments
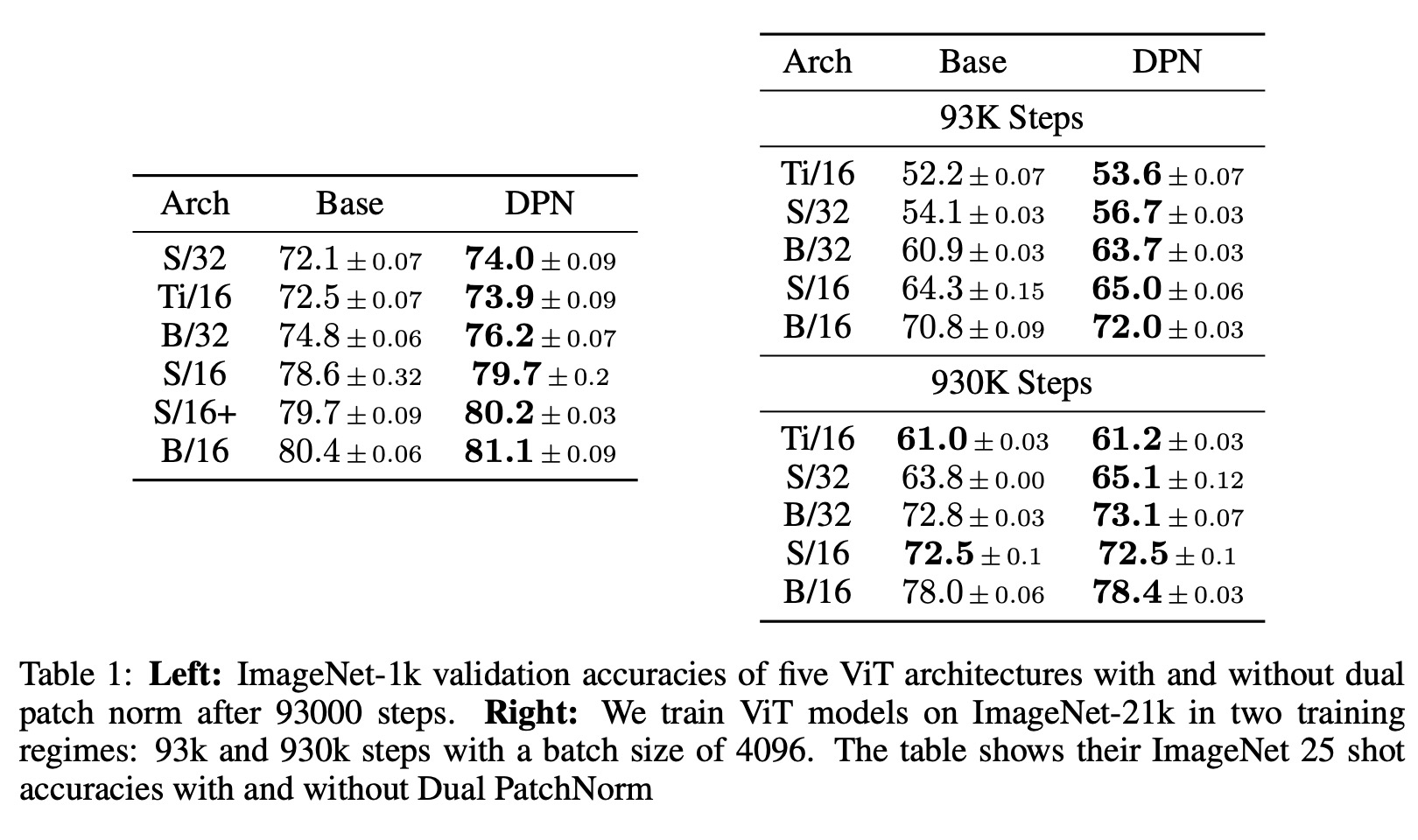
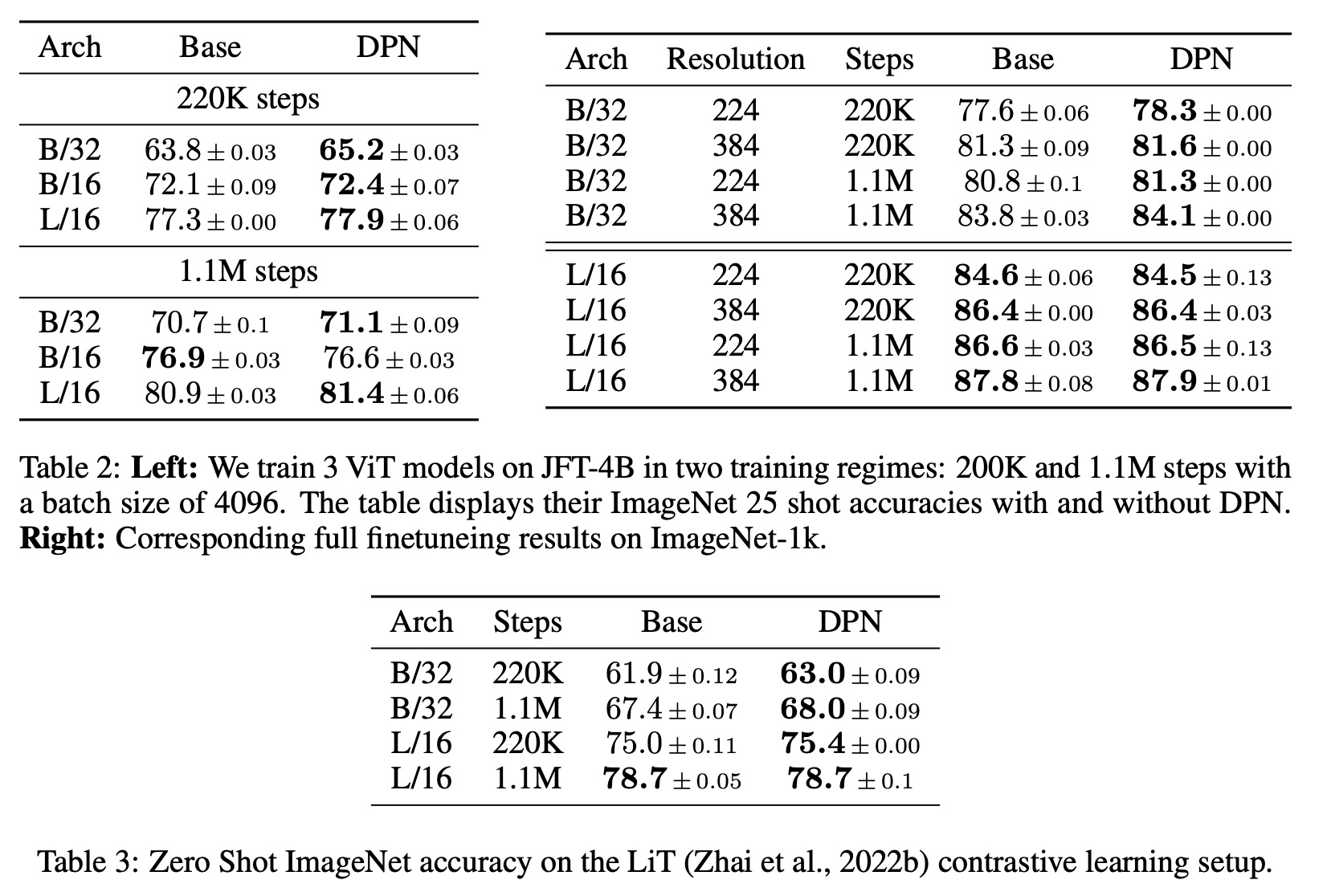
The authors train 5 ViT architectures (Ti/16, S/16, S/32, B/16 and B/32) with and without Dual PatchNorm on 3 datasets (ImageNet 1k, ImageNet 21k, JFT). On ImageNet-1k, they report the 95% confidence interval across 3 independent runs. On ImageNet21k and JFT, because of expensive training runs, they train each model once and report the mean 25 shot accuracy with 95% confidence interval across 3 random seeds.
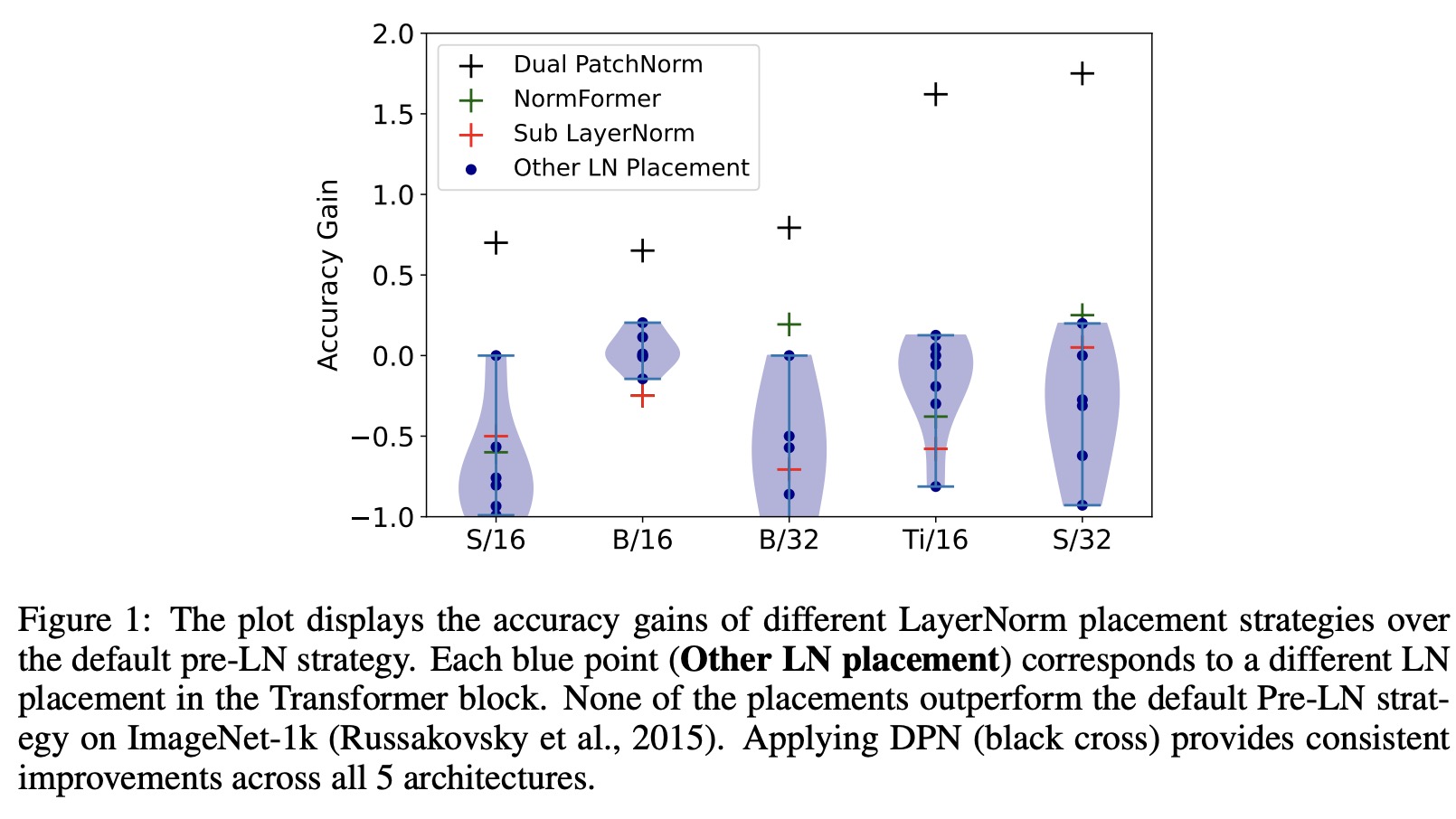
The authors evaluate the impact of different Layer Normalization (LN) placements on Vision Transformers (ViT) models. The default pre-LN strategy in ViT models, which places LN before the self-attention (SA) and MLP layer in each Transformer block, is found to be close to optimal through evaluations of alternate LN placements. The evaluations show that none of the alternate LN placements outperform the default pre-LN strategy. The NormFormer approach provides some improvement on ViT models with a patch size of 32, while the Dual PatchNorm (DPN) approach provides consistent improvement across all 5 ViT architectures.
DPN improves all architectures trained on ImageNet-21k and JFT on shorter training regimes with average gains of 1.7 and 0.8, respectively. On longer training regimes, DPN improves the accuracy of the best-performing architectures on JFT and ImageNet-21k by 0.5 and 0.4 respectively. In three cases, Ti/16 and S/32 with ImageNet-21k and B/16 with JFT, DPN matches or leads to marginally worse results than the baseline. Nevertheless, across a large fraction of ViT models, simply employing DPN out-of-the-box on top of well-tuned ViT baselines leads to significant improvements.
Ablations
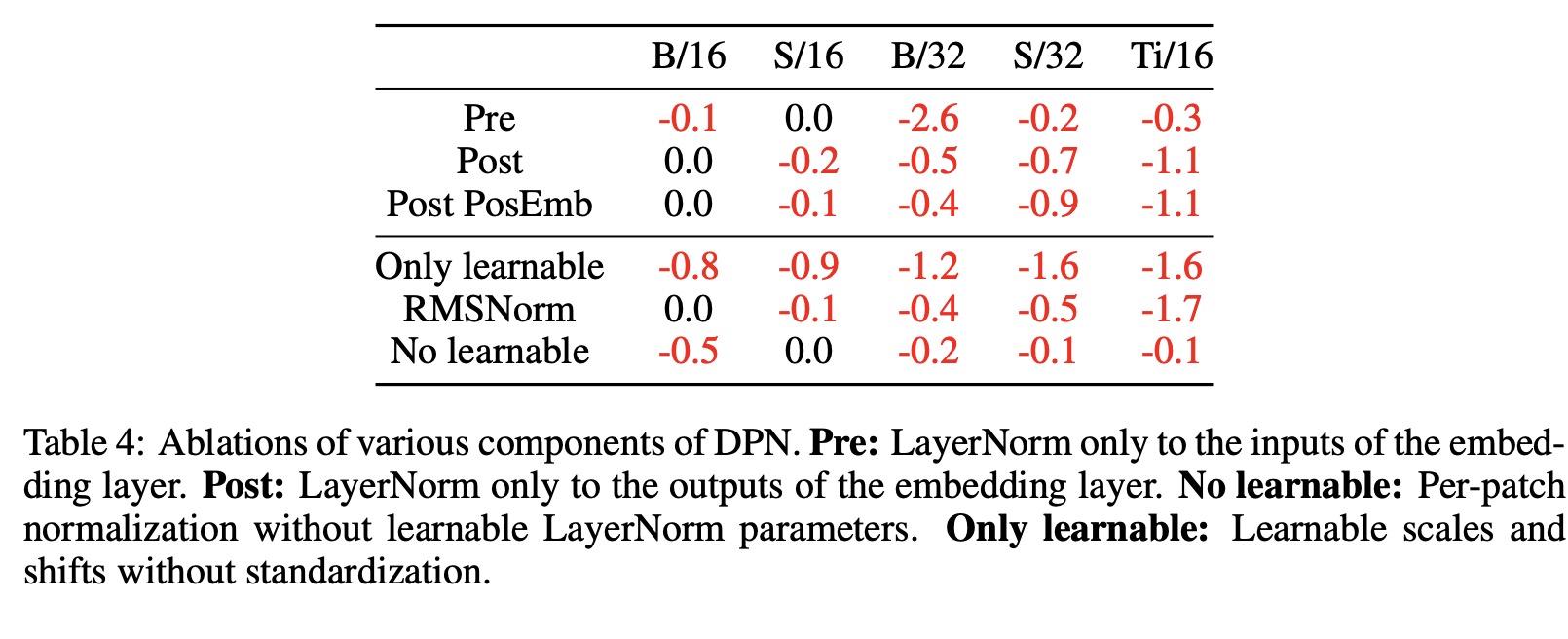
The authors evaluate the impact of applying Layer Normalization (LN) to both the inputs and outputs of the embedding layer in the Dual PatchNorm (DPN) approach. Three alternate strategies (Pre, Post and Post Pos) are assessed, and the results show that applying LN to both inputs and outputs is necessary for consistent improvements in accuracy across all Vision Transformers (ViT) variants. The experiments also show that both normalization and learnable parameters contribute to the success of DPN, with normalization having a higher impact. Removing normalization or learnable parameters leads to a significant decrease in accuracy.
paperreview deeplearning transformer cv