Paper Review: EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
EfficientSAM is a new, lightweight version of the Segment Anything Model, aimed at reducing computational costs while still delivering high performance. Originally, SAM, a substantial Transformer model, was trained on the extensive SA-1B dataset and excelled in zero-shot transfer and versatility. However, its high computational demands limited wider application.
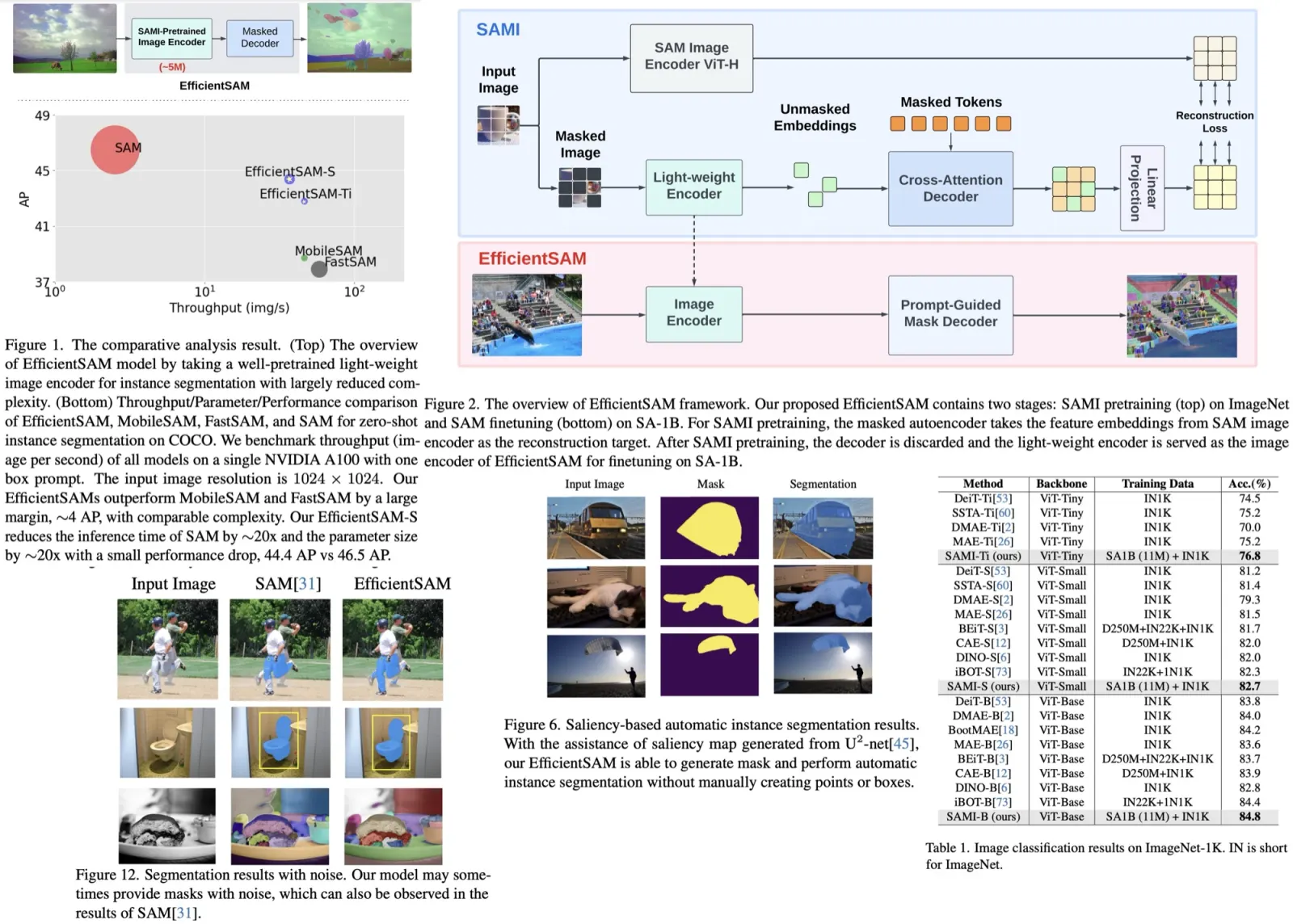
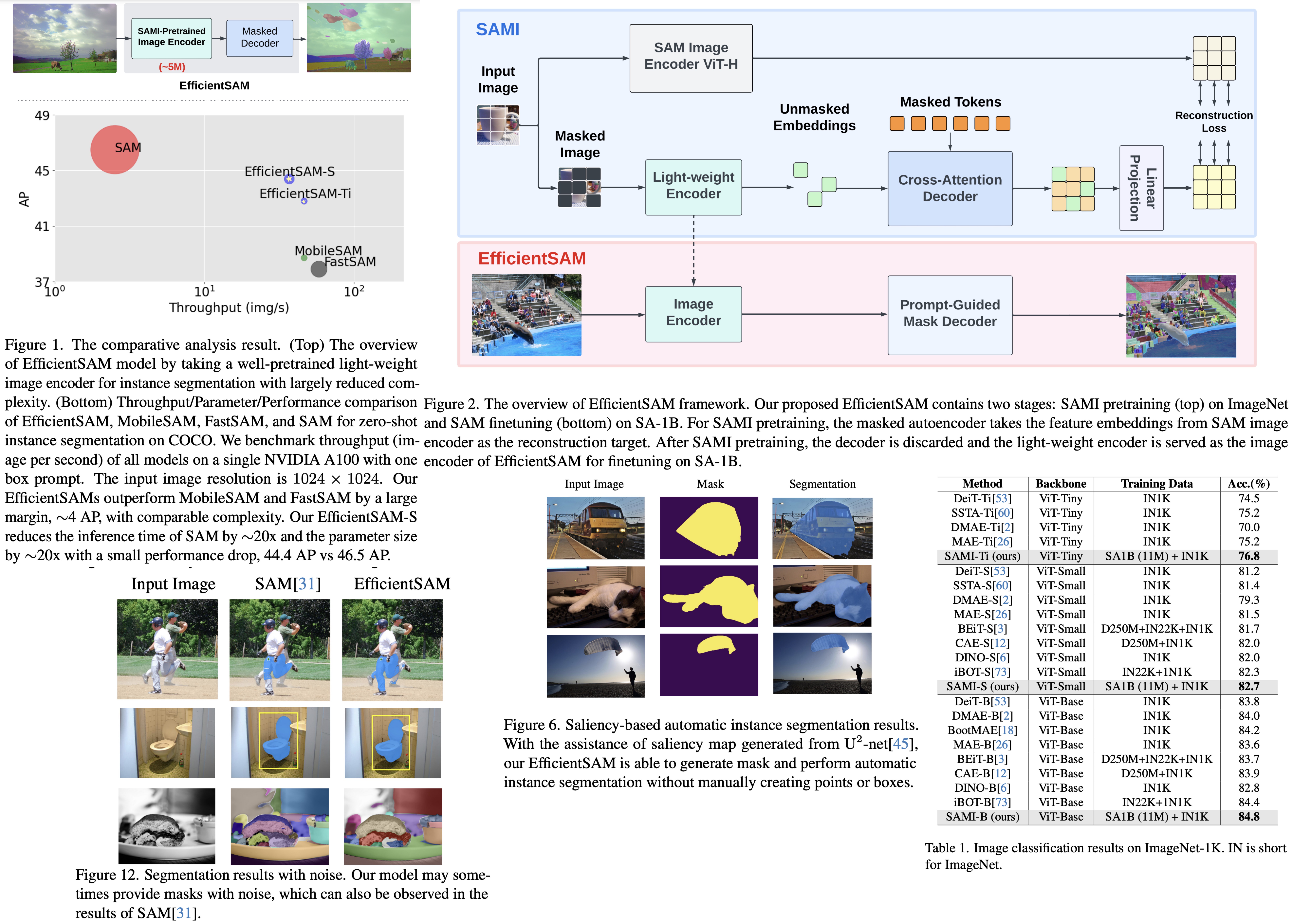
The authors use SAMI (masked image pretraining) to train EfficientSAMs. This involves reconstructing features from SAM’s image encoder to enhance visual representation learning. By combining SAMI-pretrained lightweight image encoders with a mask decoder, EfficientSAMs achieve efficiency and effectiveness.
After fine-tuning on the SA-1B dataset, EfficientSAMs show impressive results in various vision tasks, including image classification, object detection, instance segmentation, and semantic object detection. SAMI outperforms other masked image pretraining methods, especially in zero-shot instance segmentation tasks, where EfficientSAMs demonstrate significant improvements over other fast SAM models with a 4 AP gain on COCO/LVIS.
Approach
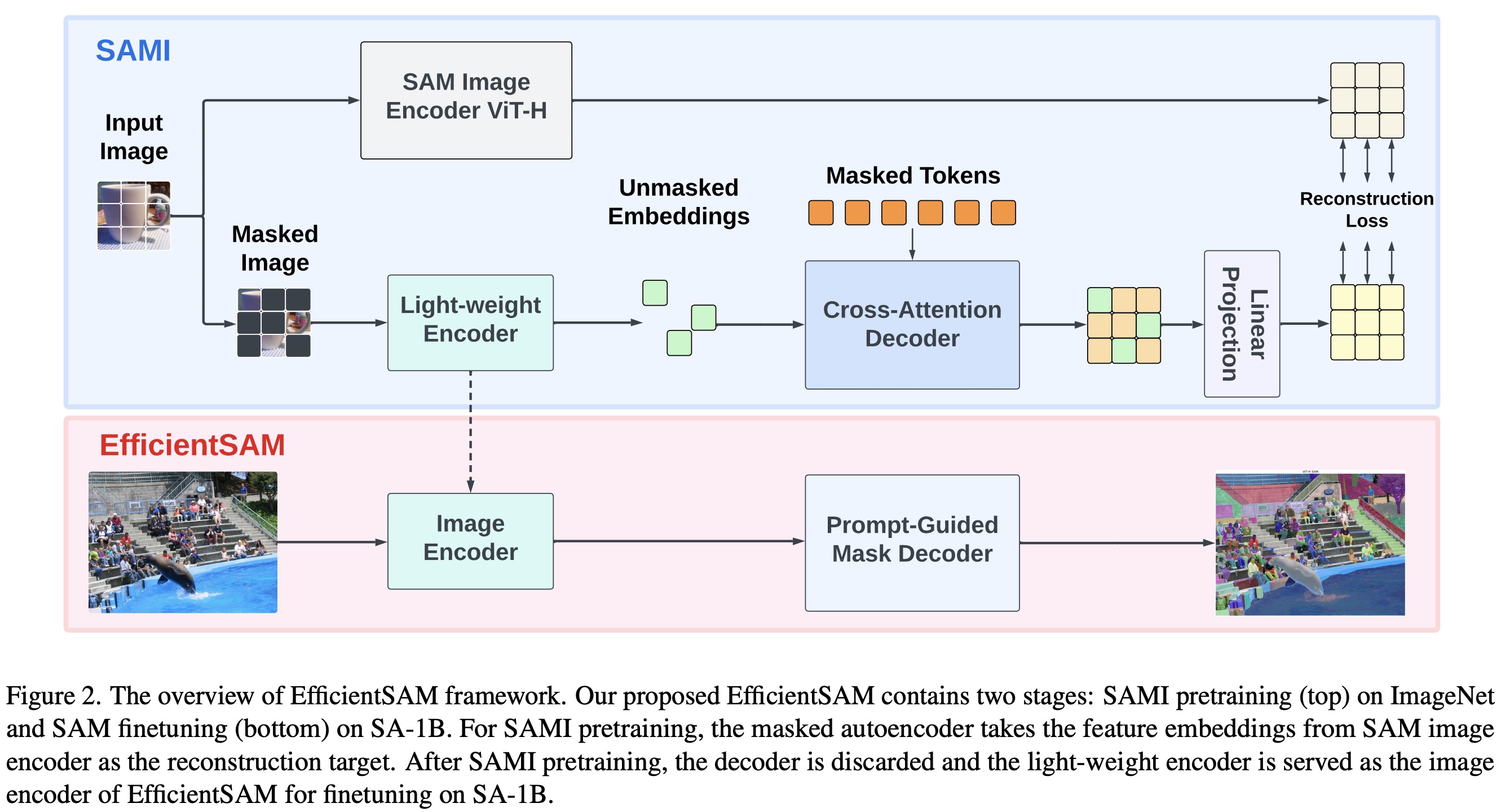
Adapting the Masked Autoencoders framework to enhance the SAM, the SAM-leveraged masked image pretraining method emphasizes transferring knowledge from SAM to MAE. It uses an encoder to transform unmasked tokens into latent feature representations and a decoder to reconstruct the representation of masked tokens, guided by latent features from SAM.
- The cross-attention decoder in this setup reconstructs only masked tokens. The queries come from these masked tokens, while the keys and values are derived from both unmasked and masked features. The output features from the decoder and encoder are merged and reordered to their original positions in the input image tokens.
- The linear projection head aligns the features from the SAM image encoder with those of the MAE, resolving any dimension mismatches.
- The reconstruction loss is calculated by comparing the outputs from the SAM image encoder and the MAE linear projection head, which is crucial for training. The aim is to optimize the MAE encoder to function as an efficient image backbone for extracting features, akin to the SAM image encoder. This process transfers the knowledge embedded in SAM to the encoder, decoder, and linear projection head of MAE.
For the Segment Anything task, SAMI-pretrained lightweight encoders, such as ViT-Tiny and ViT-Small, are combined with SAM’s default mask decoder to create EfficientSAM models. These models are fine-tuned on the SA-1B dataset, targeting efficiency and effectiveness in various visual recognition tasks.
Experiments
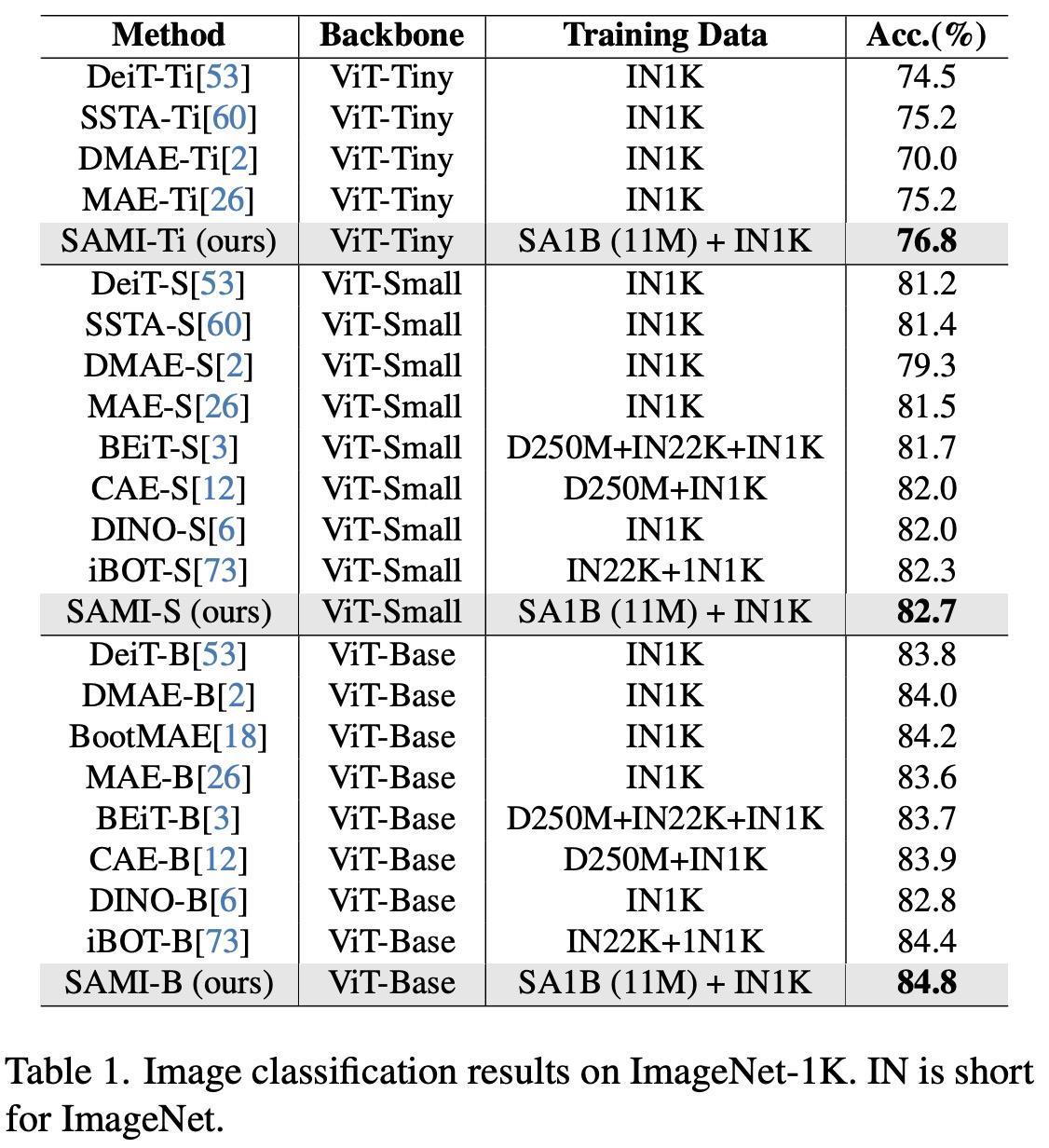
In image classification SAMI outperformed pretraining methods like MAE, iBOT, CAE, and BEiT, as well as distillation methods such as DeiT and SSTA. Specifically, SAMI-B achieved a top-1 accuracy of 84.8%, surpassing other models by margins ranging from 0.4% to 1.2%. SAMI also showed substantial gains in lightweight models like ViT-Tiny and ViT-Small compared to other methods.
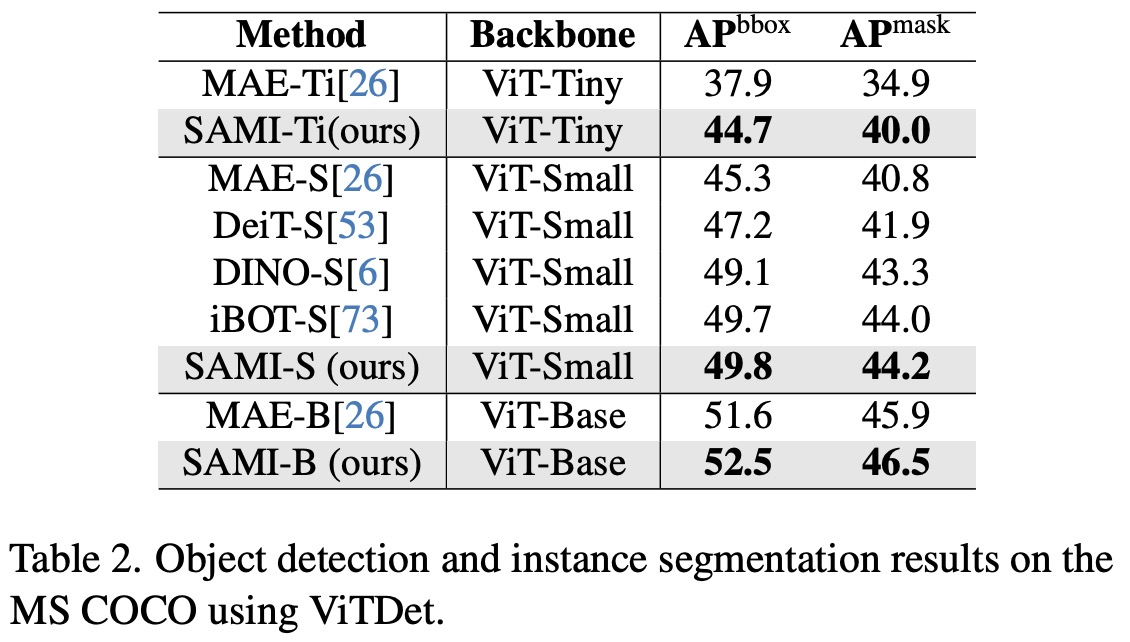
For object detection and instance segmentation, SAMI-pretrained ViT backbones were integrated into a feature pyramid in the Mask R-CNN framework to construct ViTDet. On the COCO dataset, SAMI consistently outperformed other pretraining baselines. SAMI’s lightweight backbones, SAMI-S and SAMI-Ti, also reported significant improvements compared to their MAE counterparts and substantially outperformed DeiT-S.
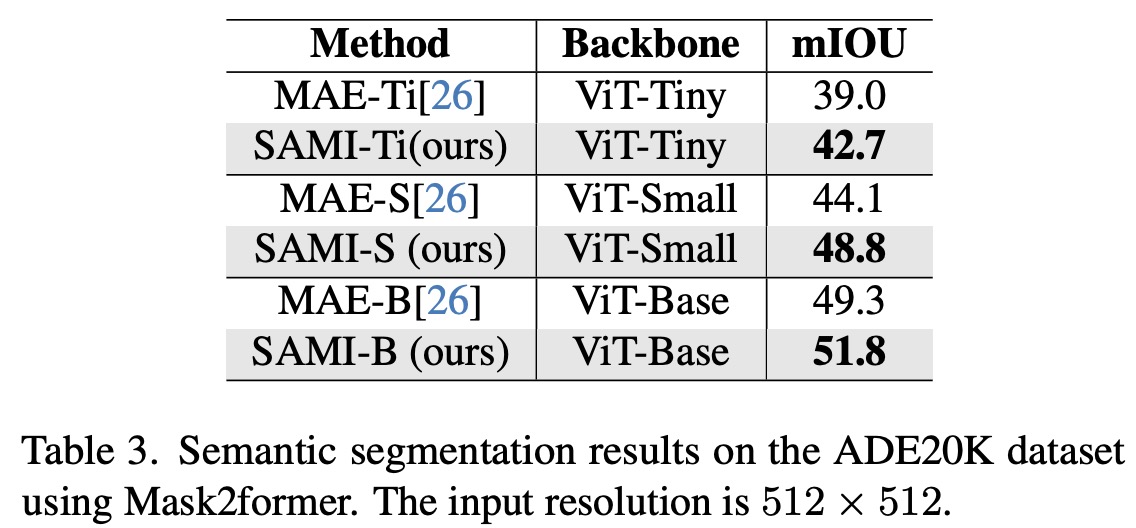
In the semantic segmentation task, SAMI-pretrained backbones were used in the Mask2former framework to benchmark on the ADE20K dataset. The results showed that Mask2former with SAMI-pretrained backbones achieved better mIoU scores compared to backbones with MAE pretraining.
EfficientSAMs for Segment Anything Task
Segment Anything task is a process of promptable segmentation to produce segmentation masks based on any form of the prompt, including point set, rough boxes or mask, freeform text.

In zero-shot single point valid mask evaluations, EfficientSAMs excel in segmenting objects from a single point, box, or multiple points, outperforming models like MobileSAM and SAM-MAE-Ti, especially in single click or box scenarios, and showing strong performance in multiple click scenarios.

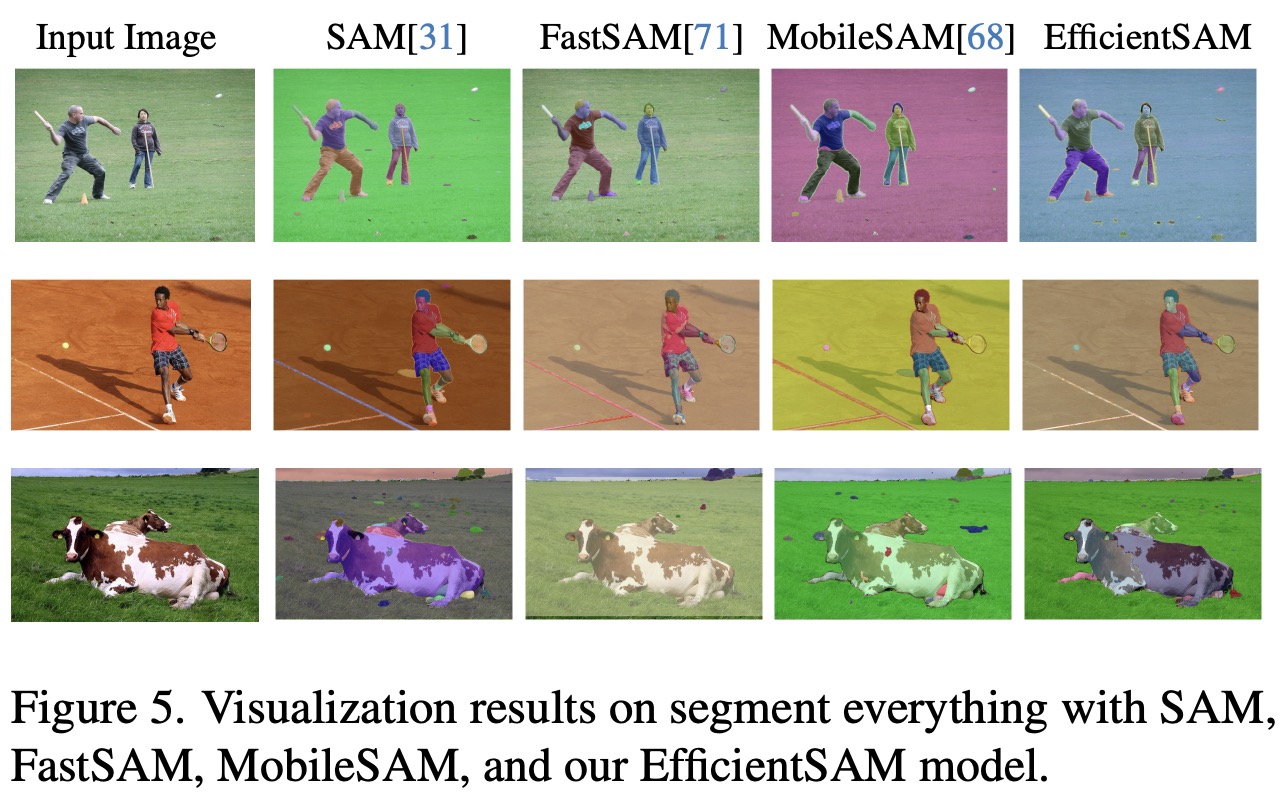
In zero-shot instance segmentation tasks, where bounding boxes are used as prompts, EfficientSAMs significantly surpass FastSAM and MobileSAM on COCO and LVIS datasets, demonstrating greater efficiency with fewer parameters. Qualitative evaluations further highlight their strong segmentation capabilities with different types of prompts, offering competitive performance compared to the original SAM but with substantially reduced complexity.
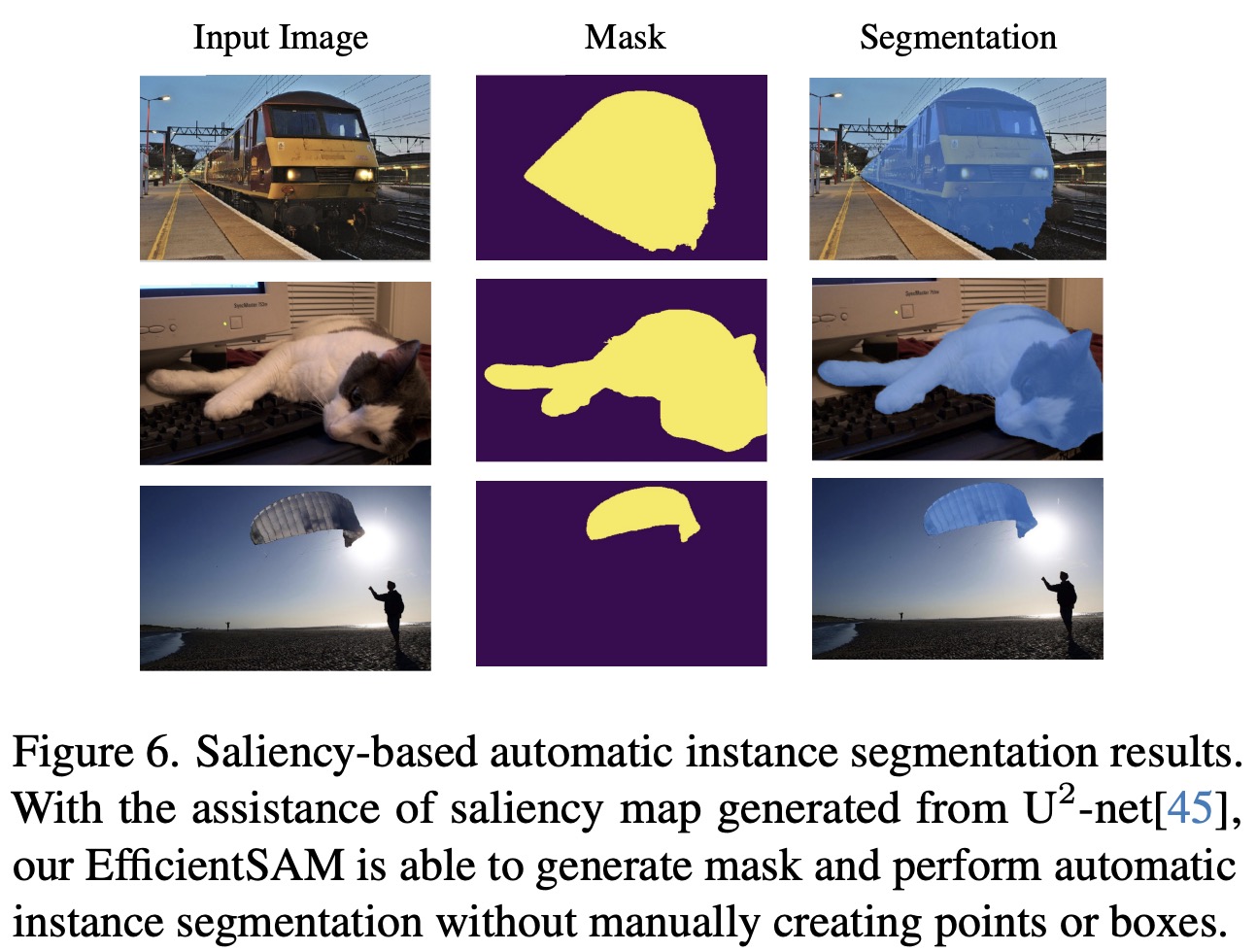
EfficientSAMs are also adept in salient instance segmentation, pairing with a state-of-the-art saliency object detection model to segment visually attractive objects without manual point or box prompts. This application showcases their potential in aiding individuals with hand impairments, highlighting their versatility and practical utility in diverse segmentation scenarios.
Ablations
- Reconstruction Loss: The MSE reconstruction loss was found to be more effective than similarity loss, suggesting that a direct reconstruction of SAM features is preferable over achieving high angular similarity.
- Cross-Attention Decoder: In reconstructing SAM features, the output tokens from the encoder were used directly, with the decoder transforming only the masked tokens using cross-attention. This approach, where masked tokens were queried in the decoder, resulted in SAMI-Ti performing 3% better on ImageNet-1K compared to feeding all tokens into the decoder for target reconstruction. This is analogous to anchor points in AnchorDETR, where encoder output tokens align well with SAM features and serve as anchors for masked tokens in the cross-attention decoder.
- Mask Ratio: Exploring different mask ratios in SAMI showed that, consistent with findings in MAE, a high mask ratio (75%) tends to yield better results.
- Reconstruction Target: An experiment was conducted using a different encoder from CLIP as the reconstruction target in SAMI. Aligning features from the CLIP encoder outperformed MAE by 0.8% for a ViT-Tiny model on ImageNet-1K, indicating that masked image pretraining benefits from powerful guided reconstruction.
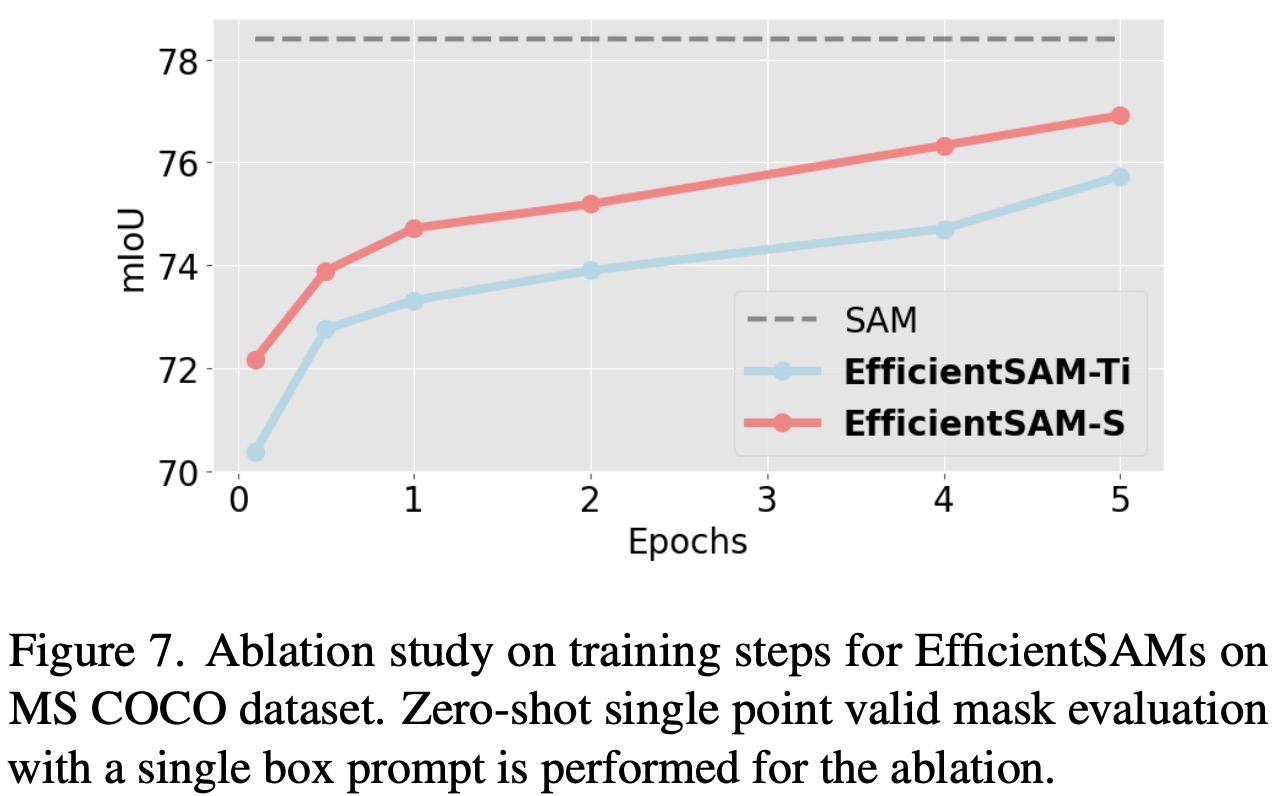
- Finetuning Steps for EfficientSAMs: The impact of finetuning steps on EfficientSAMs was explored. EfficientSAM-Ti and EfficientSAM-S showed decent performance even at 0.1 epoch, with significant gains in performance (over 2.5 mIoU) observed at 1 epoch. The final performance of EfficientSAM-S reached 76.9 mIoU, only 1.5 mIoU lower than SAM.