Paper Review: Paper Review: EfficientNetV2: Smaller Models and Faster Training

A new impressive paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new group of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved NAS with new building blocks and ideas;
- a new approach to progressive learning that adjusts regularization along with the image size;
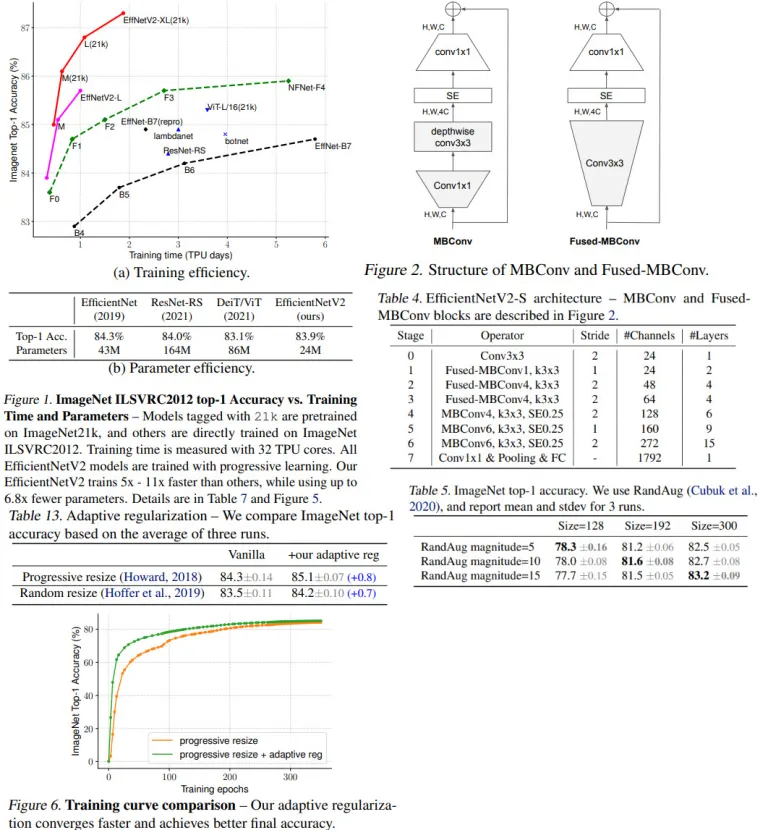
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Problems of efficientnets
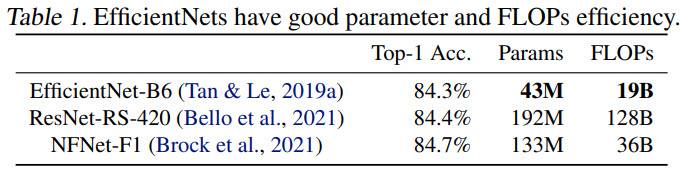
EfficientNets were developed in 2019, and they are still quite good in terms of parameters and FLOPs efficiency nowadays.
Nevertheless, there are some bottlenecks, and solving them could significantly improve the training speed:
Training with very large image sizes is slow.
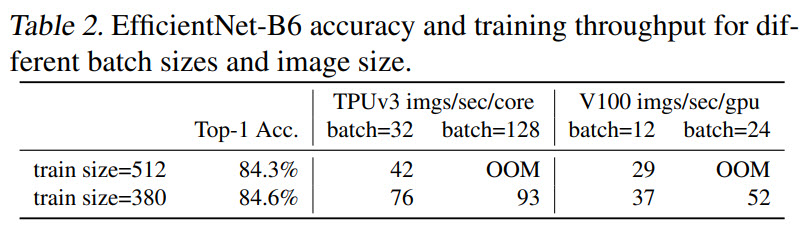
Large EfficientNets are trained on large images, and thus it is necessary to use smaller batch sizes to fit into GPU memory.
Depthwise convolutions are slow in early layers
While depthwise convolutions have fewer parameters, they usually can’t be fully utilized by modern hardware. The authors suggest replacing some of the MBConv layers with newer Fused-MBConv layers. But we can’t simply replace all the old layers with the new ones because the tradeoff between accuracy and model size suffers.
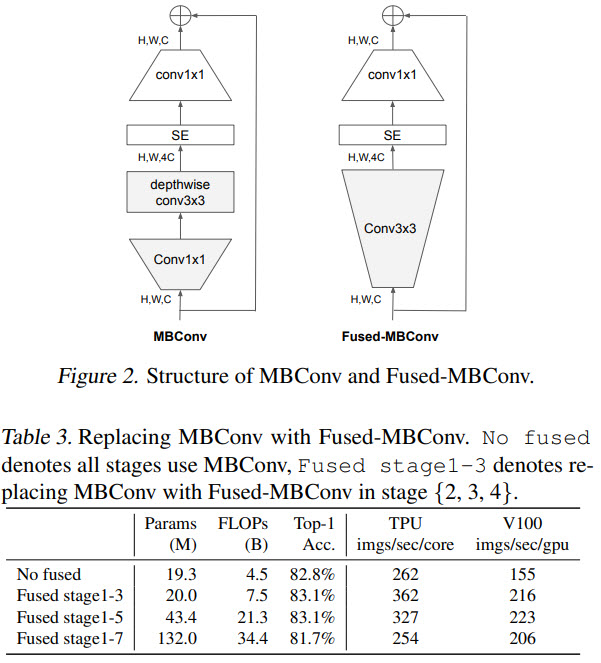
Equally scaling up every stage is sub-optimal
EfficientNets scales all stages equally, but it is more efficient to add layers to later stages gradually. Also, the authors decrease the scaling of image sizes and put a lower limit on maximum image size.
Changes in NAS
- search space consists of different convolutions (MBConv, Fused-MBConv), number of layers, kernel sizes and expansion ratios;
- remove unnecessary hyperparameters;
- sample up to 1000 models and run them for 10 epochs with reduced image size;
EfficientNetV2 Architecture
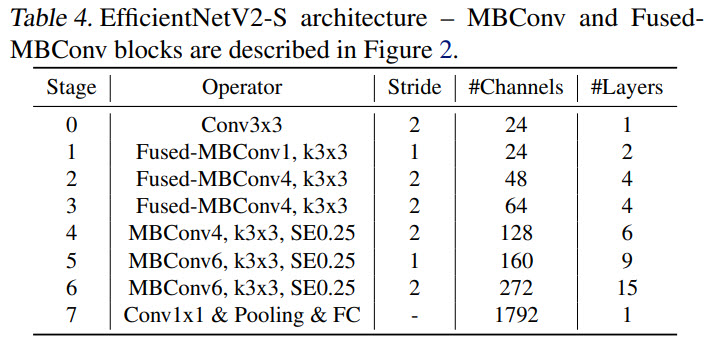
The main changes compared to EfficientNet are:
- using both MBConv and Fused-MBConv in the early layers;
- smaller expansion ratio;
- smaller kernel sizes, but more layers;
EfficientNetV2 Scaling
The main improvements of scaling:
- maximum inference image size is 480;
- gradually add more layers to later stages;
Progressive Learning
Progressive learning means gradually increasing input image sizes while training. The authors show that if we gradually increase regularization along with image size, the result will be much better.


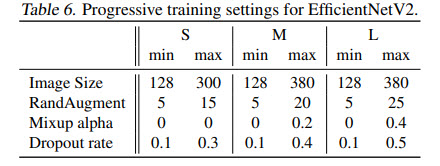
They use Dropout, RandAugment, and Mixup.
Results
They train some models on ImageNet (1000 classes and 1.28m images), and some models are pre-trained on ImageNet21k (21841 classes and 13m images).
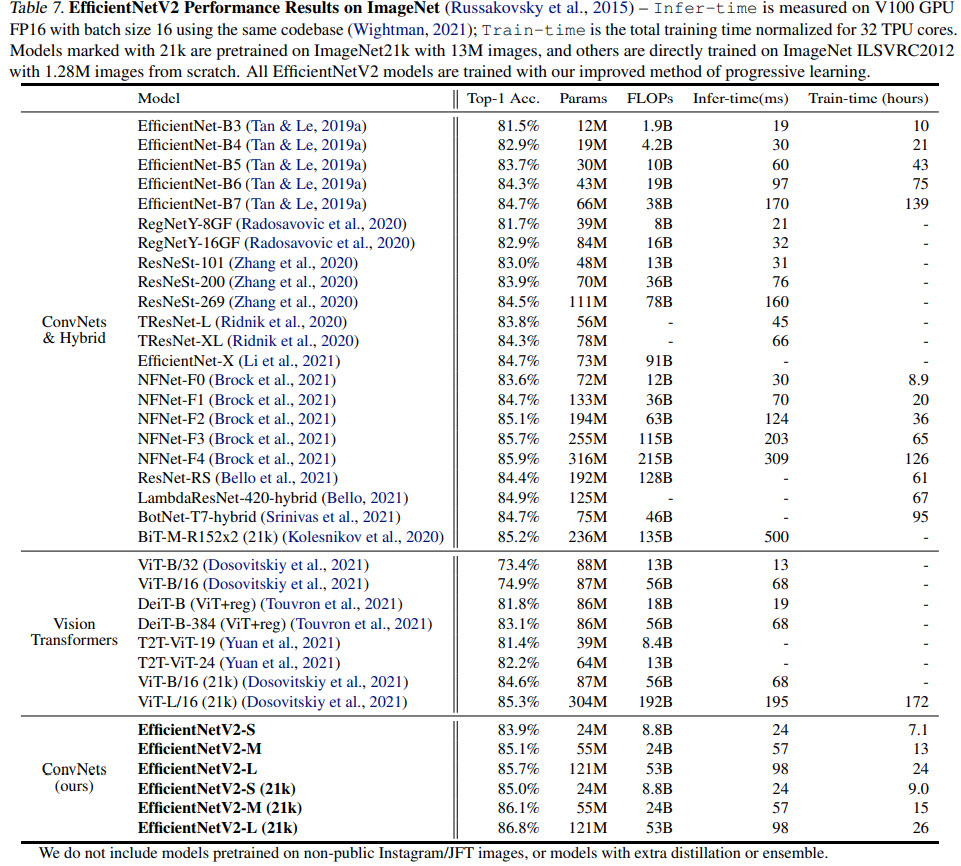
Compared to the recent ViT-L/16(21k), EfficientNetV2-L(21k) improves the top-1 accuracy by 1.5% (85.3% vs. 86.8%), using 2.5x fewer parameters and 3.6x fewer FLOPs, while running 6x - 7x faster in training and inference!
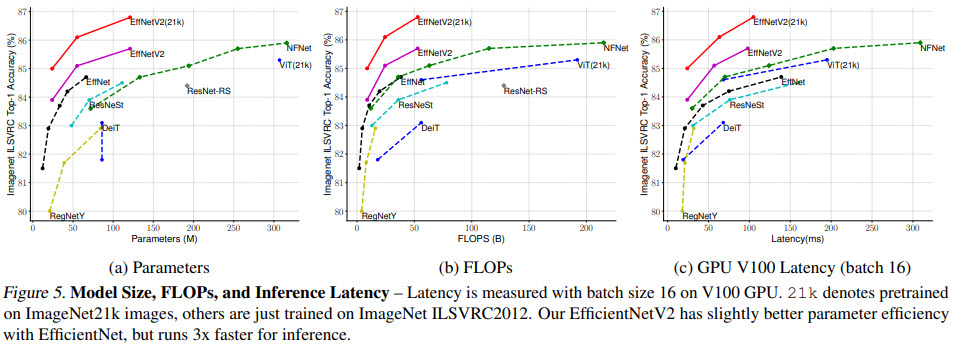
They observe that thanks to their approach, it is possible to utilize ImageNet21k for pre-training efficiently - it takes only two days using 32 TPU cores.
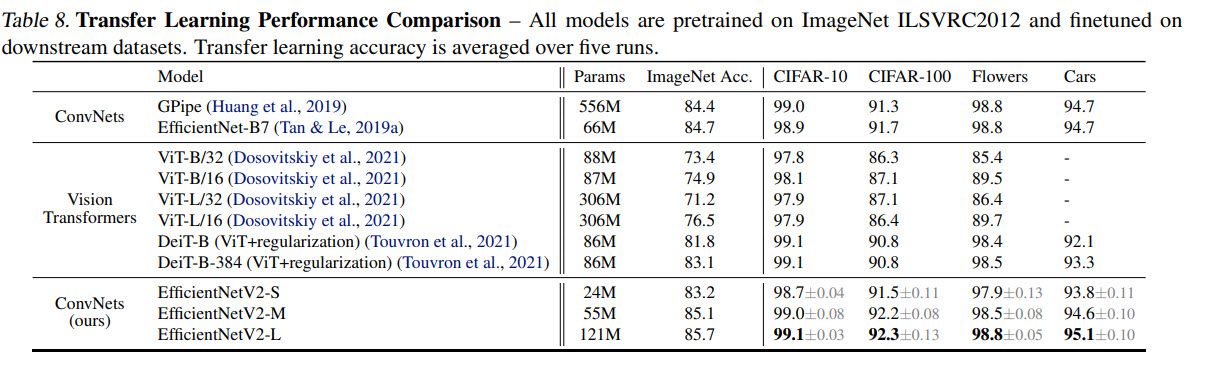
Transfer learning
Ablations
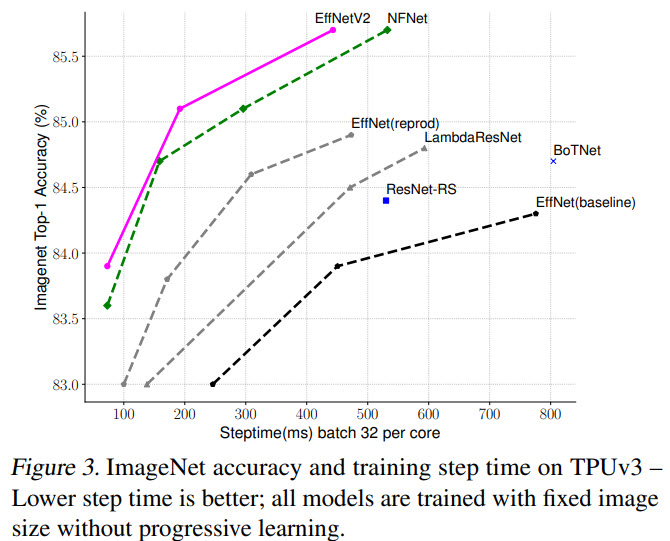
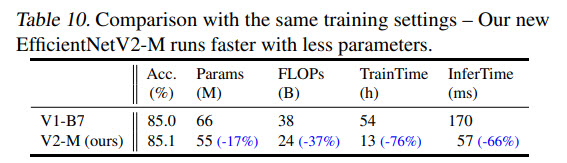
- If EfficientNet is trained with the same progressive learning as EfficientNetV2, its performance improves, but EfficientNetV2 is still better;
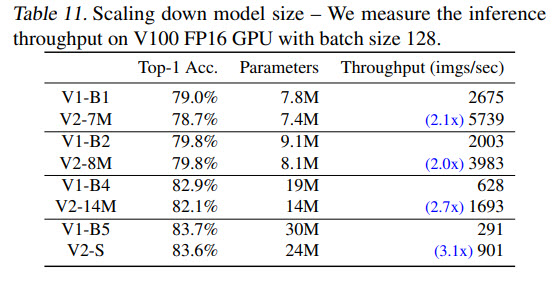
- Scaling down improves inference speed significantly;
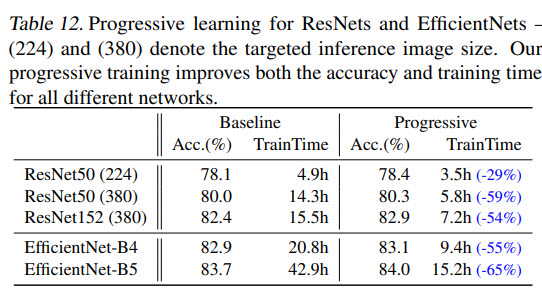
- Applying new progressive learning to other architectures improves the training performance;
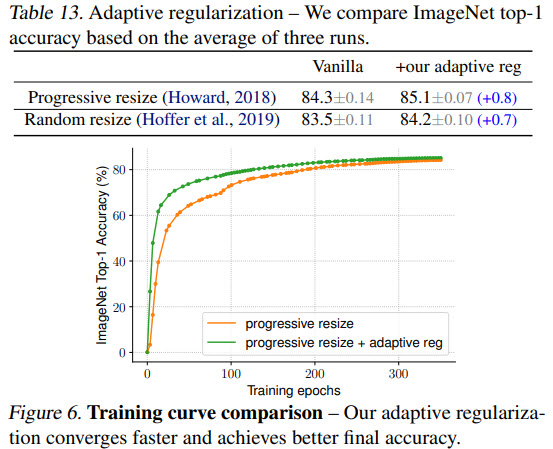
- Adaptive regularization is significantly better;
I think this is an excellent paper, and I’m glad that it improves the model performance and training speed. Maybe soon, all computer vision models will be pre-trained on ImageNet21k?
paperreview cv sota nas deeplearning