Paper Review: Unveiling Encoder-Free Vision-Language Models

Existing VLMs typically use vision encoders to extract visual features before applying LLMs for visual-language tasks. However, these encoders impose constraints on visual representation, potentially hindering the flexibility and efficiency of VLMs. Training VLMs without vision encoders is challenging, often leading to slow convergence and large performance gaps. This paper addresses this challenge by presenting a training recipe for pure VLMs that accept seamless vision and language inputs. The key is unifying vision-language representation within one decoder and enhancing visual recognition with extra supervision.
The resulting model, EVE, is an encoder-free VLM trained efficiently on 35M publicly accessible data, rivaling encoder-based VLMs and outperforming the Fuyu-8B model.
The approach
Architecture
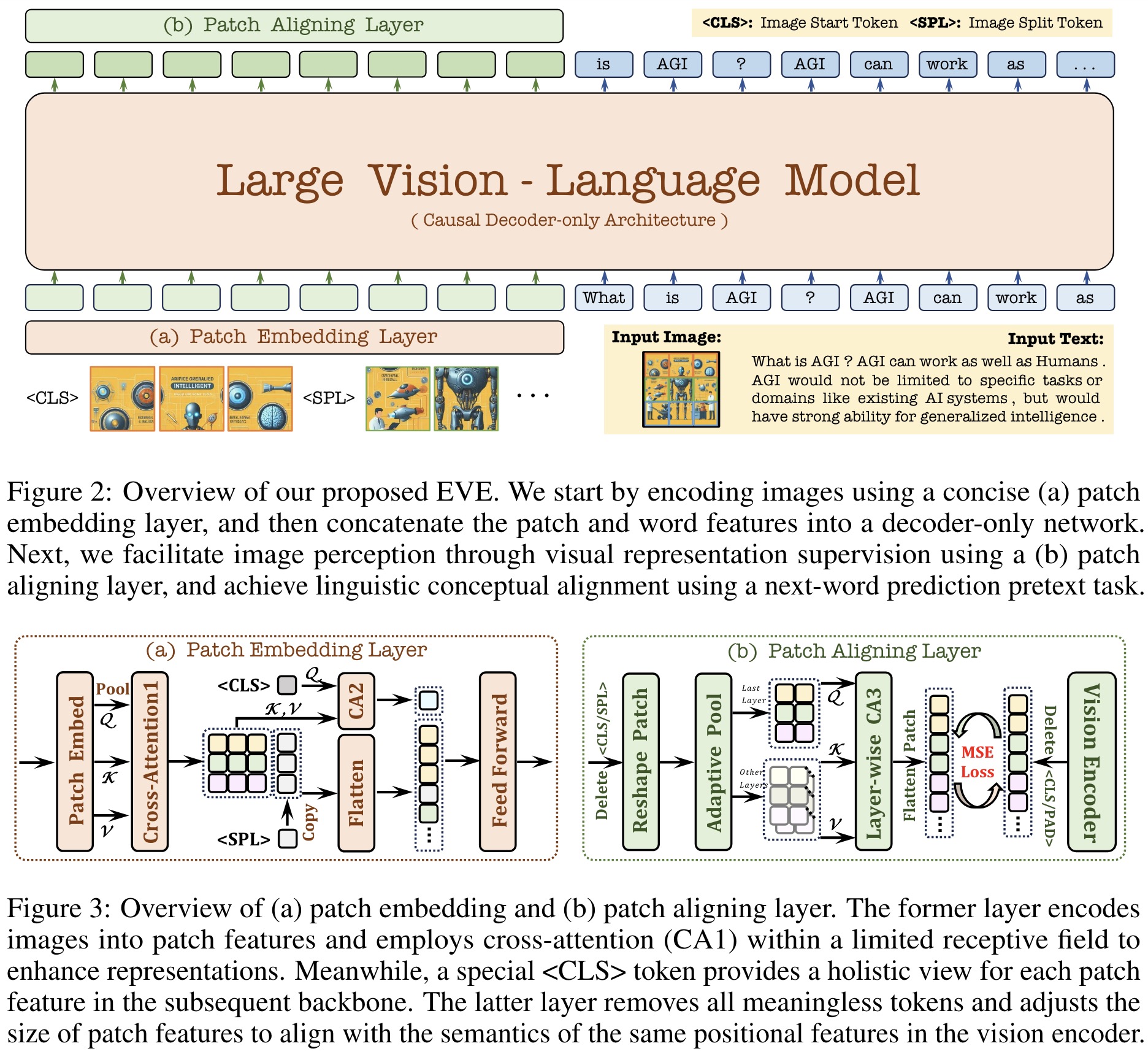
EVE is initialized with Vicuna-7B for its linguistic capabilities and incorporates a lightweight patch embedding layer to encode image and text inputs efficiently. The model aligns patch features with those from a vision encoder using a hierarchical patch aligning layer while predicting next-word labels through Cross-Entropy loss.
The patch embedding layer uses a convolutional layer, average pooling, and cross-attention layers to transmit images almost losslessly and understand their 2-D spatial structure. It uses <CLS> and <SPL> (newline) tokens for holistic information and spatial structure. It then concatenates these features with text embeddings into a unified decoder-only architecture.
The patch aligning layer uses a hierarchical aggregation strategy to integrate intermediate features from multiple layers, aligning visual features with the vision encoder’s output using Mean Squared Error loss.
Training
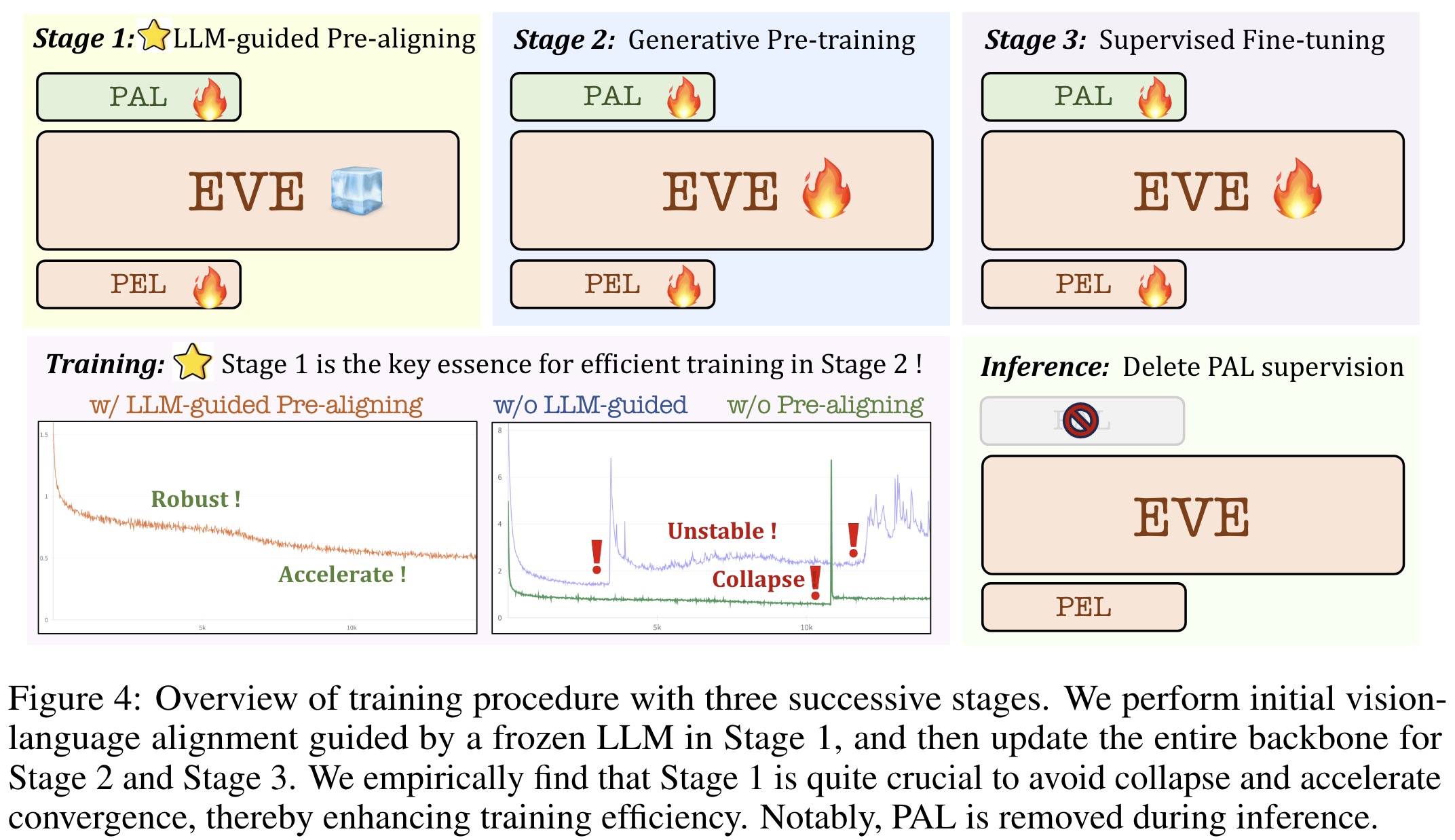
LLM-guided Pre-training:
- The aim is to establish an initial connection between vision and language modalities.
- Publicly available web-scale data is used, with noisy captions removed and high-quality descriptions generated for it. Around one half of the data is used in this stage.
- Only the patch embedding and aligning layers are trainable to align with the frozen Vicuna-7B model, using CE loss for text labels and MSE loss for patch-wise alignment.
Generative Pre-training:
- Patch embedding, aligning layers, and full LLM modules are unfrozen for deeper pretraining.
- All 33M image-text pairs are used, the losses are the same.
- A lower learning rate is used to balance vision-language enhancement and linguistic competency.
Supervised Fine-tuning:
- EVE is fine-tuned for following linguistic instructions and learning dialogue patterns, using the same losses.
- For training, the LLaVA-mix-665K dataset is used for EVE-7B, and additional 1.2M SFT conversation data is used to train a high-resolution version EVE-7B (HD).
The model is trained on two 8-A100 (40G) nodes for ~9 days.
Experiments
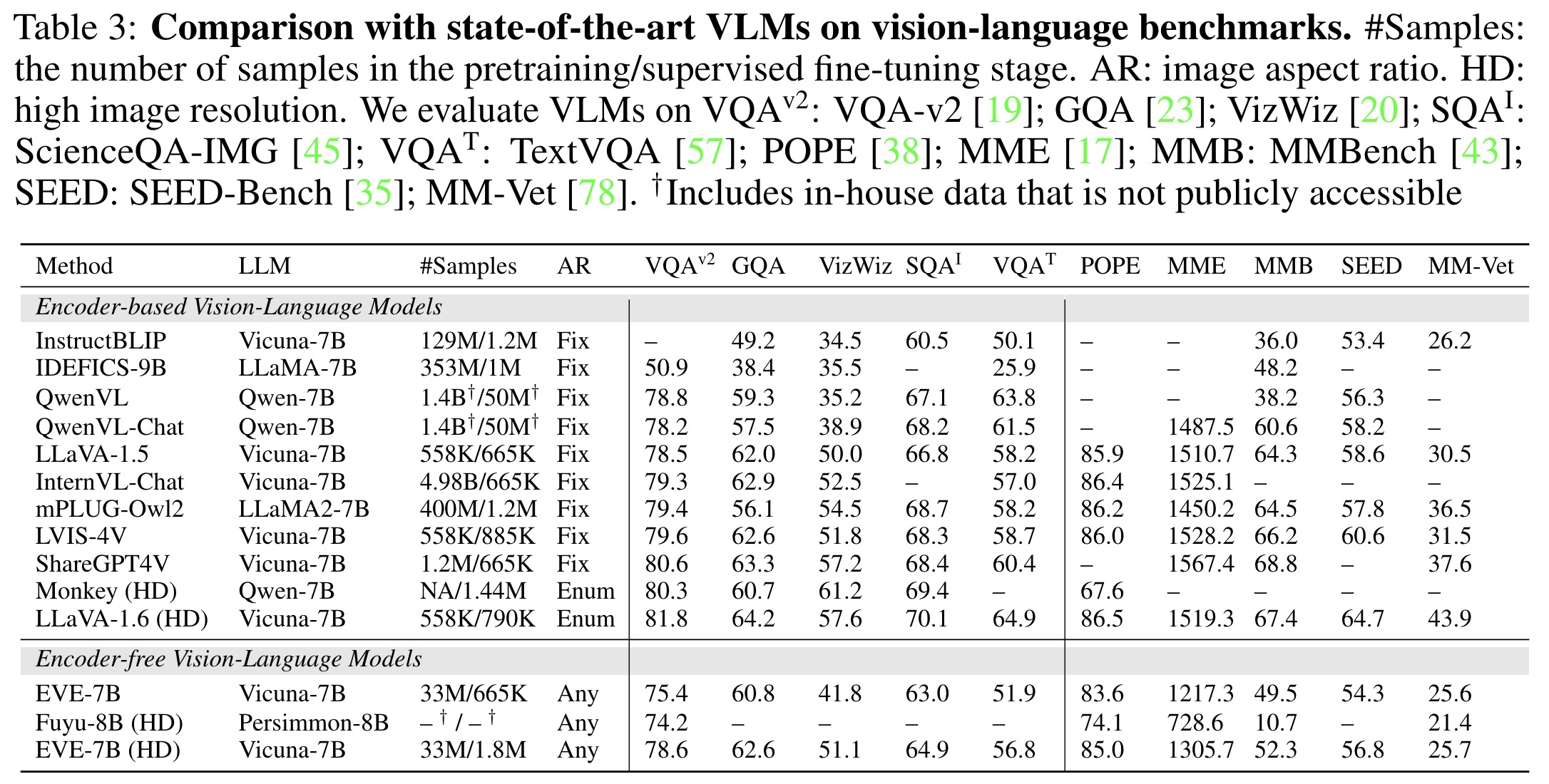
EVE is evaluated on multiple public visual-language benchmarks, demonstrating superior performance compared to its encoder-free counterpart, Fuyu-8B, despite being smaller in size. The use of diverse supervised fine-tuning datasets and larger image sizes in EVE (HD) significantly enhances its image recognition capabilities. EVE (HD) competes well with encoder-based models outperforming some of them and matching the performance of LLaVA-1.5. However, EVE struggles with specific instructions and binary questions, and extensive training with vision-language data has slightly reduced its language competency and instruction-following abilities. Despite these challenges, EVE-7B matches encoder-based VLMs using a simpler architecture and publicly available data, suggesting that encoder-free VLMs, with proper training and high-quality data, can rival or surpass encoder-based models.
Ablation studies
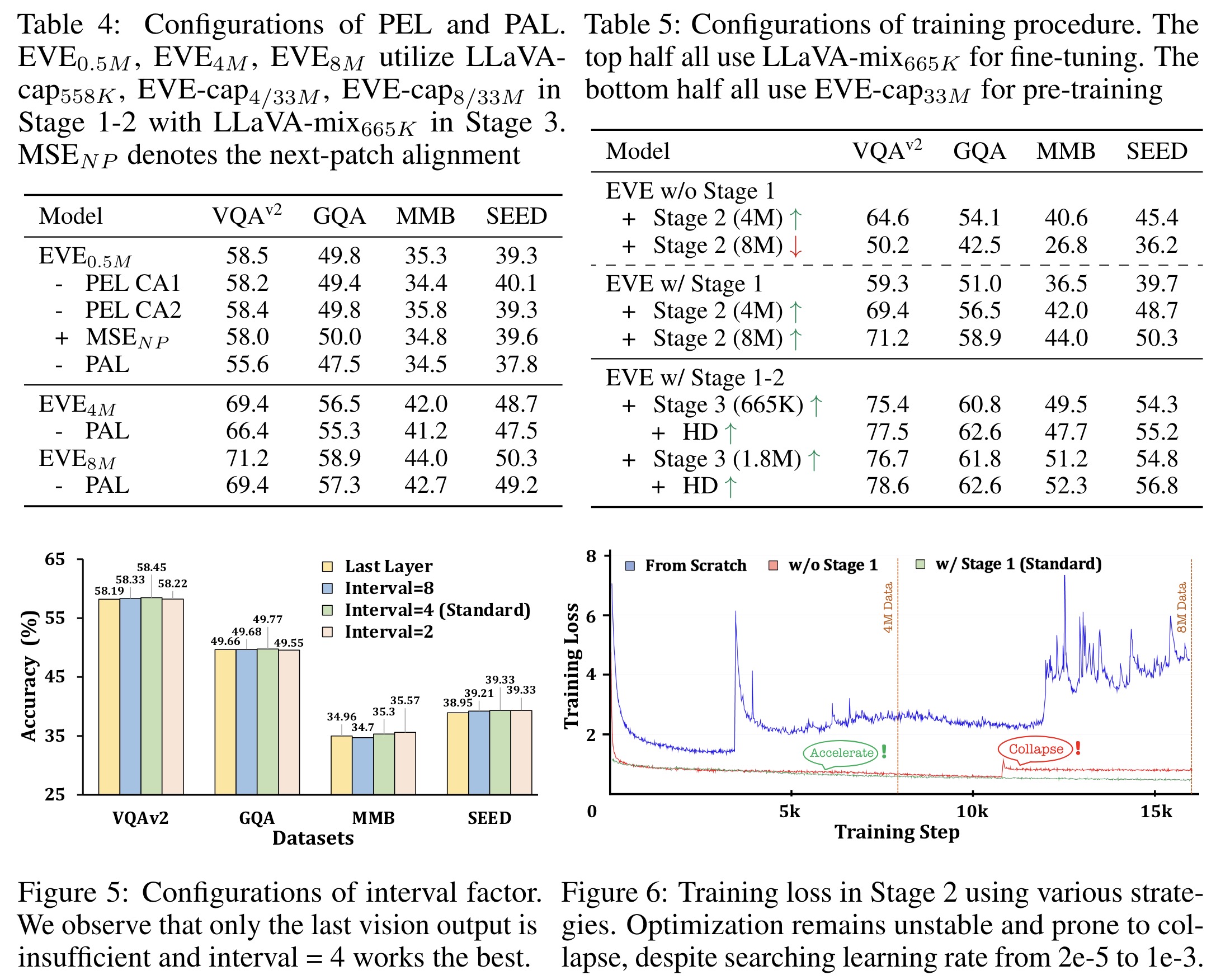
Experiments with various configurations of the patch embedding and aligning layers (PEL and PAL) in EVE show that:
- Removing any cross-attention layer in PEL slightly degrades performance.
- Pairwise patch alignments are more effective than next-patch predictions.
- Visual supervision through PAL enhances image representation and model convergence, regardless of training data size.
- LLM-guided Pre-aligning Stage is essential for stable and efficient training. It stabilizes the training process and facilitates transition into subsequent stages.
- Multi-layer aggregation outperforms relying on the last layer output, with an optimal interval factor of 4 for selecting cross-layer features in PAL.
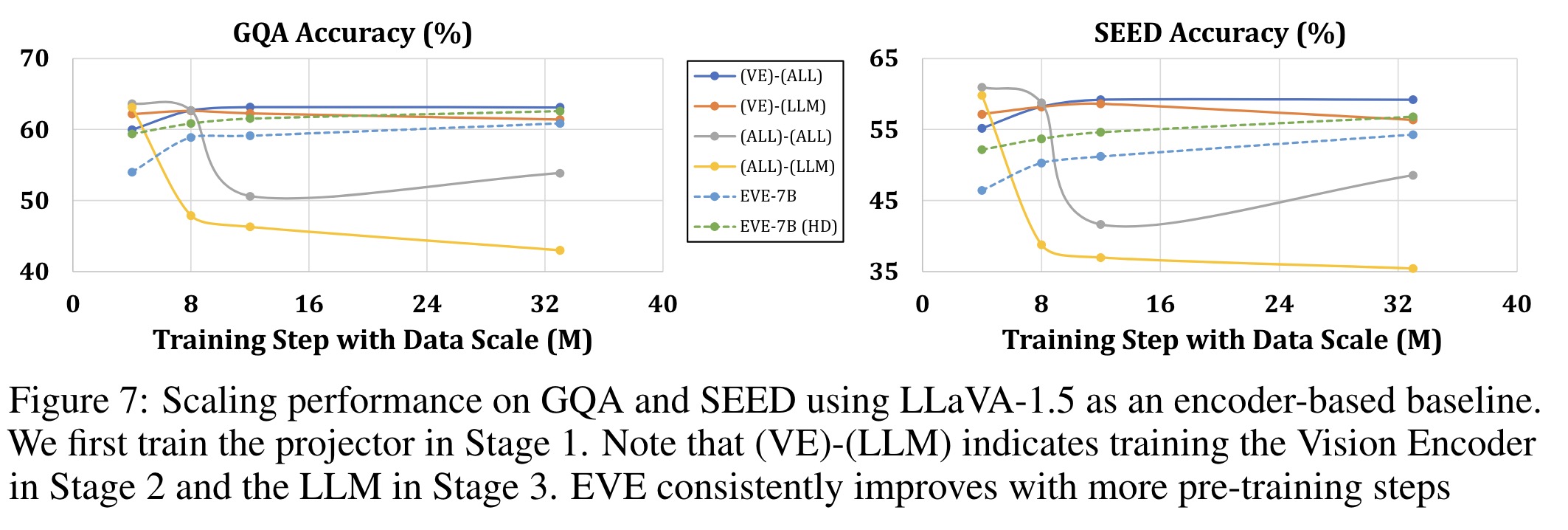
- EVE shows consistent performance gains with scaled-up data, nearing encoder-based models’ performance, and avoiding overfitting.
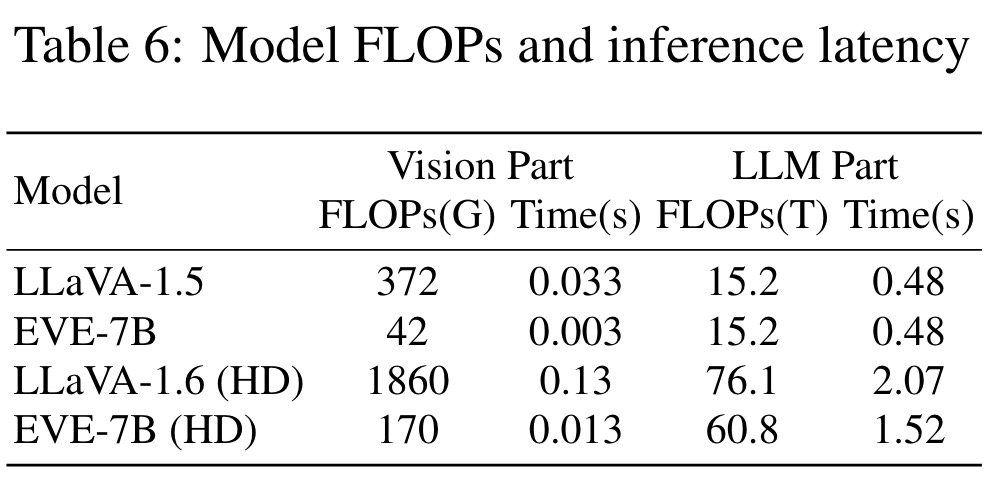
- EVE achieves significant speed improvements by eliminating the deep pre-trained vision encoder, optimizing computational complexity and reducing inference latency.
- EVE (HD) surpasses LLaVA-1.6 in both deployment efficiency and reduced inference delay, demonstrating the practical advantages of encoder-free VLMs over encoder-based ones.