Paper Review: Fast Segment Anything

This paper presents a more efficient alternative to the Segment Anything Model (SAM). The proposed method addresses SAM’s major limitation: its high computational cost due to its Transformer architecture with high-resolution inputs. The authors reconfigure the task as segment generation and prompting, utilizing a conventional Convolutional Neural Network (CNN) detector with an instance segmentation branch. By converting the task to the well-known instance segmentation task and using only 1/50th of the SA-1B dataset published by the SAM authors, the new method matches SAM’s performance while achieving 50 times faster runtime, as supported by extensive experimental results.
Methodology
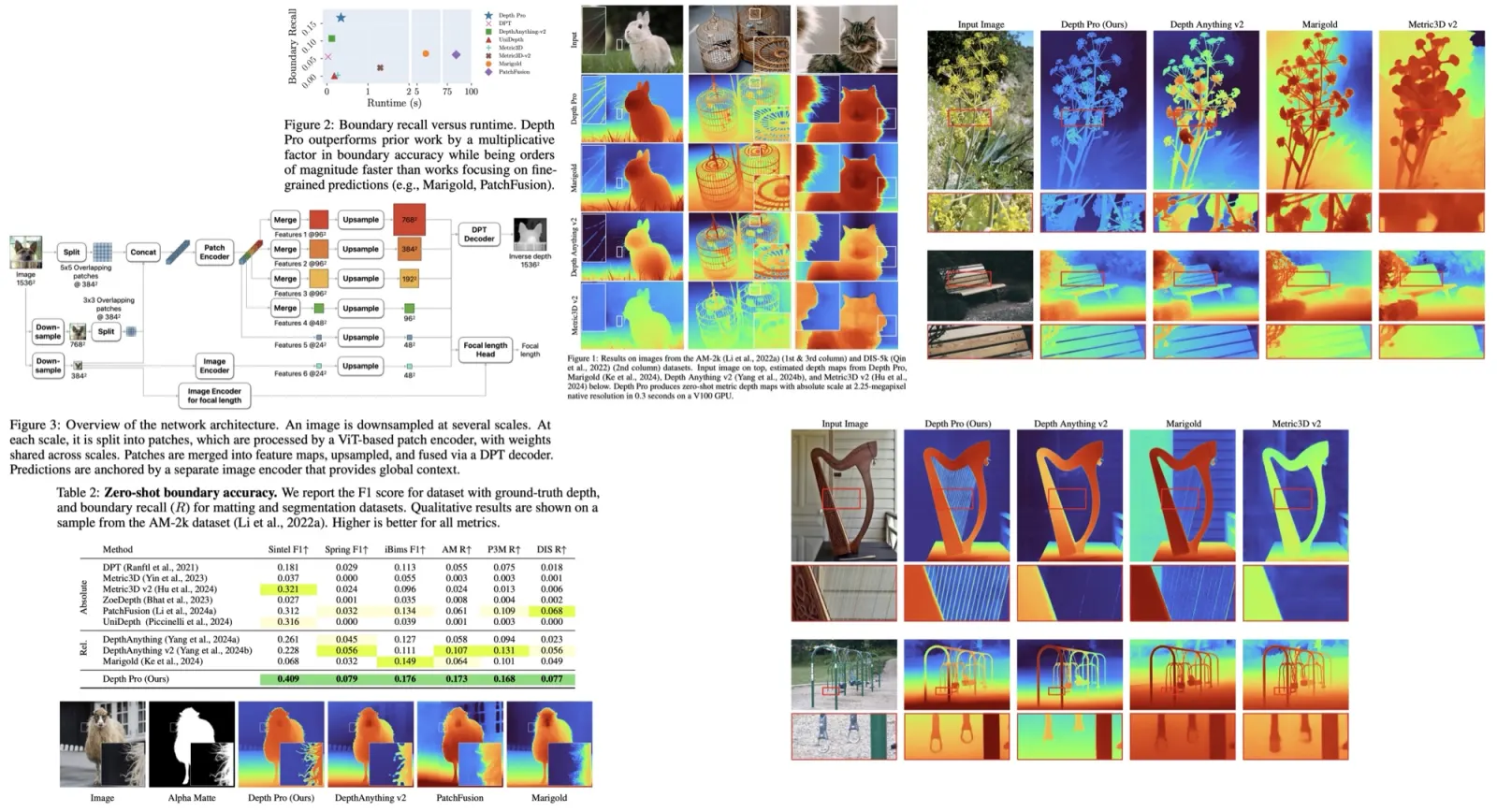
The FastSAM method is composed of two stages: All-instance Segmentation and Prompt-guided Selection. The first stage serves as the foundation, while the second is essentially task-oriented post-processing. Unlike end-to-end transformers, FastSAM incorporates numerous human priors fitting vision segmentation tasks, such as the local connections of convolutions and receptive-field-relevant object assigning strategies. These aspects make FastSAM specifically tailored for vision segmentation tasks, enabling it to converge faster with fewer parameters.
All-instance Segmentation
The architecture used is YOLOv8; it replaces YOLOv5’s C3 module with the C2f module and introduces a decoupled structure for the Head module, separating classification and detection heads, and moving from Anchor-Based to Anchor-Free.
In YOLOv8-seg, instance segmentation is performed using YOLACT principles. The process starts with feature extraction from an image using a backbone network and the Feature Pyramid Network (FPN), merging diverse size features. The detection branch outputs category and bounding box information, while the segmentation branch outputs k prototypes and mask coefficients.
Segmentation and detection tasks are executed in parallel. The segmentation branch processes a high-resolution feature map through several convolution layers to output the masks. Instance segmentation results are achieved by multiplying the mask coefficients with the prototypes and summing them.
With the instance segmentation branch, YOLOv8-Seg is applicable for the segment anything task, aiming to detect and segment every object or region in an image, regardless of the object category. The prototypes and mask coefficients provide extensive flexibility for prompt guidance, with a simple prompt encoder and decoder structure trained additionally.
Prompt-guided Selection
The second stage of the FastSAM method, following the segmentation of all objects or regions in an image using YOLOv8, involves using various prompts to identify specific objects of interest. These prompts include point prompts, box prompts, and text prompts.
- The point prompt matches selected points to various masks obtained from the first stage. In cases where a foreground point is located in multiple masks, background points are used to filter out irrelevant masks. Selected masks within the region of interest are then merged into a single mask marking the object of interest.
- The box prompt performs Intersection over Union (IoU) matching between a selected box and the bounding boxes from the various masks of the first phase. The aim is to identify the mask with the highest IoU score with the selected box and select the object of interest.
- The text prompt involves extracting text embeddings of the text using the CLIP model. Image embeddings are then determined and matched to the intrinsic features of each mask using a similarity metric. The mask with the highest similarity score to the image embeddings of the text prompt is selected.
Experiments

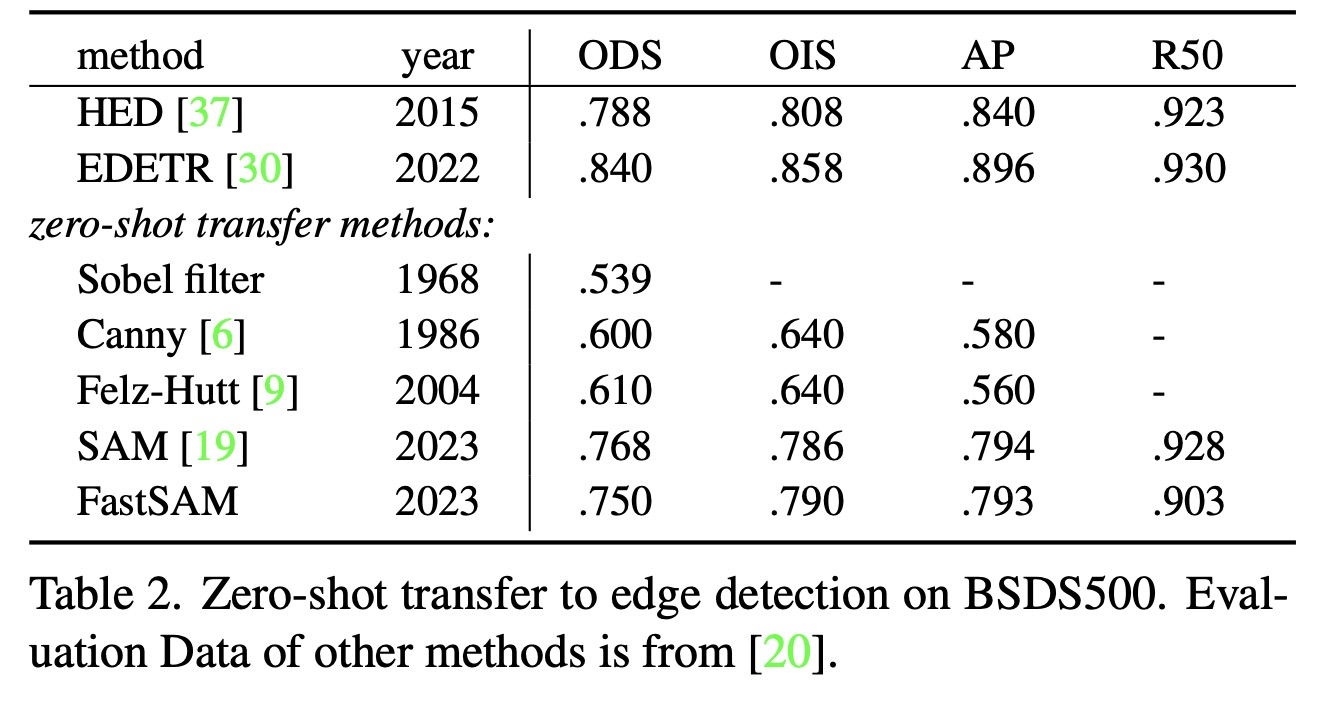
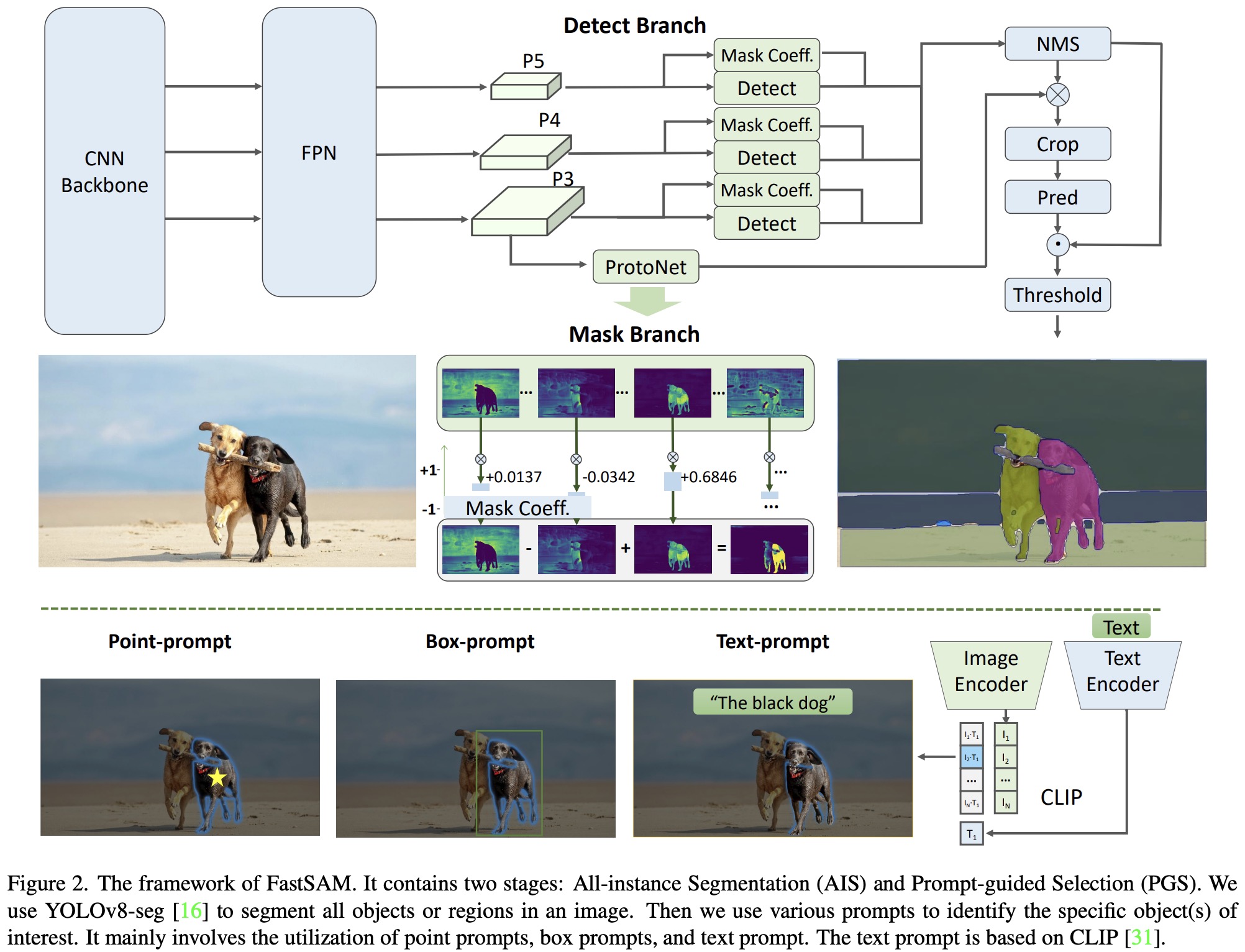
- FastSAM was evaluated for its zero-shot edge detection capabilities using the BSDS500 dataset. The method involved selecting the mask probability map from the all-instance segmentation stage of FastSAM and applying Sobel filtering to generate edge maps. The results were comparable to the SAM method, predicting a larger number of edges and having a similar performance as SAM, despite FastSAM’s significantly fewer parameters.
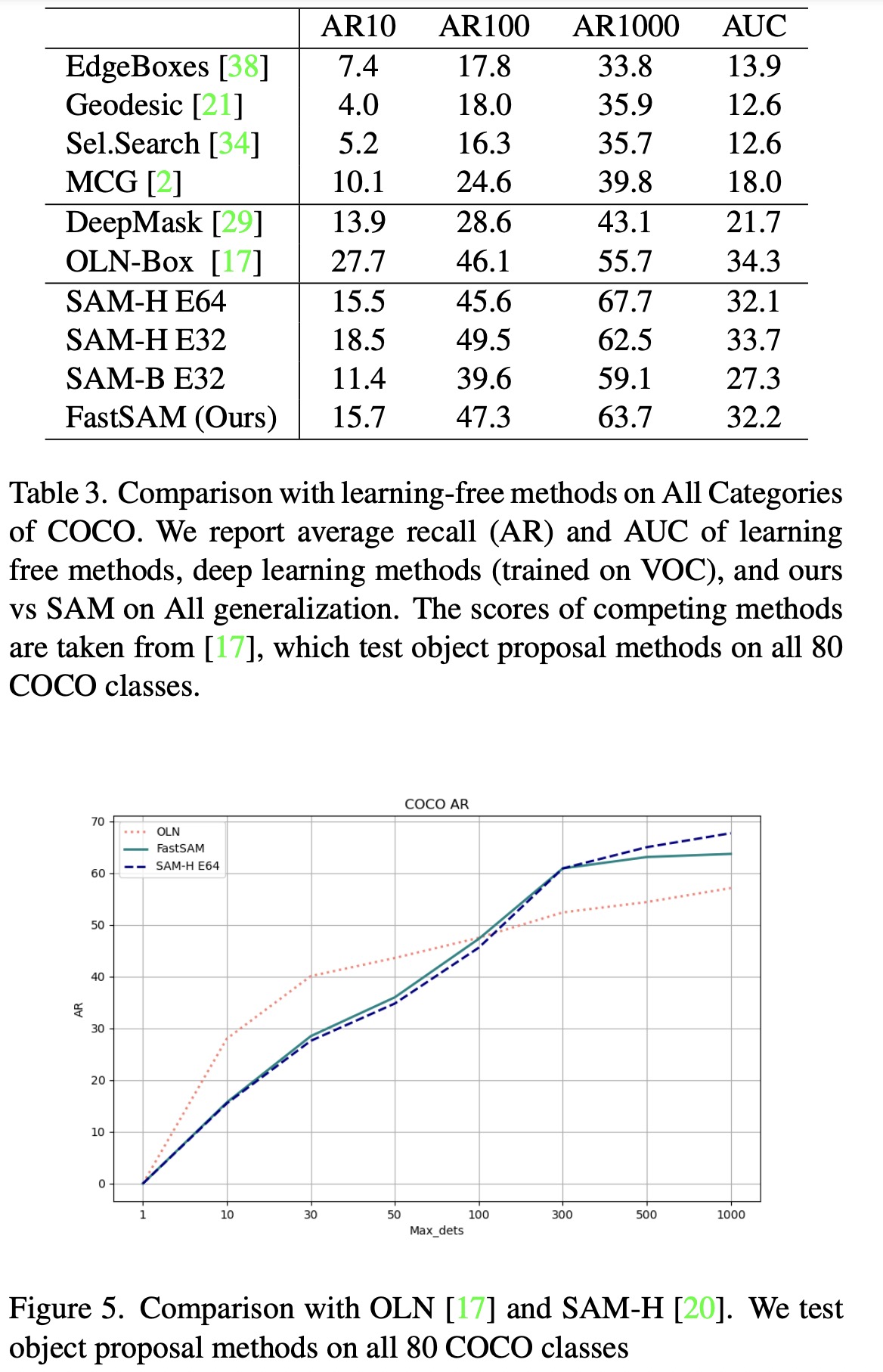
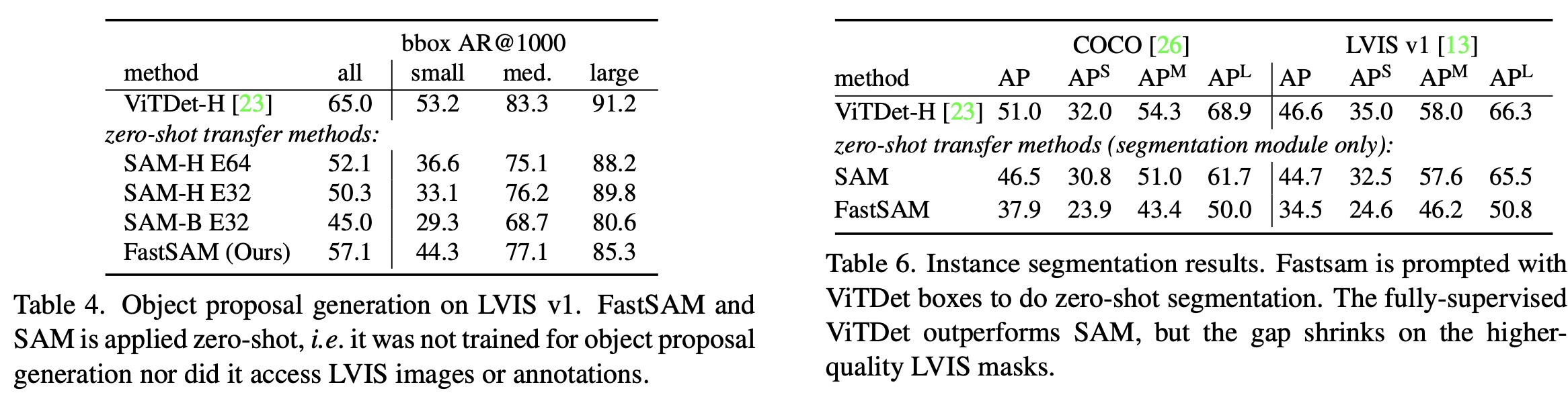
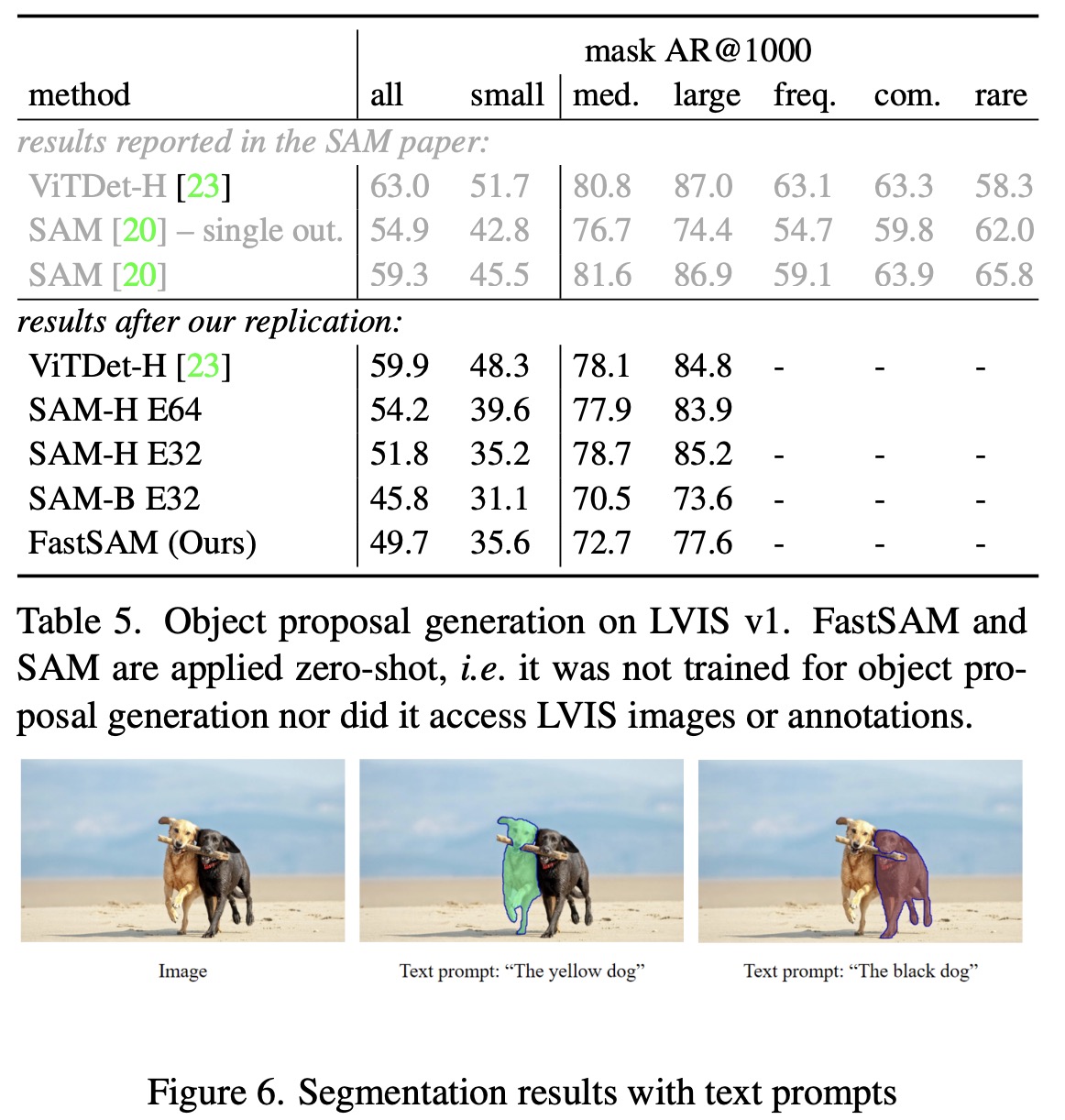
- FastSAM was also tested for zero-shot object proposal generation, a crucial pre-processing step for many computer vision tasks. Bounding boxes generated in the first stage of FastSAM were used as object proposals and evaluated using the LVIS and COCO datasets. FastSAM showed a significant advantage in box proposal generation tasks, outperforming several methods in recall metrics. However, it fell short compared to VitDet-H which was trained on the LVIS dataset.
- FastSAM’s zero-shot instance segmentation was accomplished by using the bounding box generated by ViTDet as the prompt, selecting the mask with the highest Intersection over Union (IoU) with the bounding box. However, it didn’t achieve a high AP due to segmentation mask accuracy or the box-based mask selection strategy.
- Finally, FastSAM was assessed for its ability to segment objects using free-form text prompts. This experiment demonstrated FastSAM’s ability to process text prompts similar to SAM, running text through CLIP’s text encoder at inference time to find the most similar mask. The results showed FastSAM can segment objects well based on text prompts, however, the running speed was not satisfactory due to each mask region needing to be fed into the CLIP feature extractor. Integrating the CLIP embedding extractor into FastSAM’s backbone network remains a topic for future research.
Real-world Applications


- For anomaly detection, which distinguishes between normal and defective samples, FastSAM was tested using the MVTec AD dataset. The model could segment nearly all regions, albeit with lower precision compared to the SAM model. It managed to identify defective regions using point- or box-guided selection.
- In the case of salient object segmentation, which targets the most attention-grabbing objects in an image, FastSAM was applied to the ReDWeb-S dataset. The results showed minor differences from SAM under everything mode, with FastSAM segmenting fewer irrelevant background objects. Using points-guided selection, it could capture all objects of interest with results nearly identical to those of SAM and the ground truth.
- Lastly, for building extraction from optical remote sensing imagery FastSAM performed well in segmenting regularly shaped objects, but fell short when it came to shadow-related regions compared to SAM. However, it was able to select regions of interest with point- and box-prompts, demonstrating its resistance to the interference of noise, such as shadows.
Discussion
FastSAM performs comparably to SAM but operates significantly faster, running 50x quicker than SAM (32×32) and 170x faster than SAM (64×64). Its speed makes it suitable for industrial applications like road obstacle detection, video instance tracking, and image manipulation. In some cases, FastSAM even generates superior masks for large objects.
However, despite the advantage in box generation, the model’s mask generation performance lags behind SAM. The identified weaknesses include:
- Low-quality small-sized segmentation masks tend to have high confidence scores due to the bounding box score of YOLOv8, which does not correlate strongly with mask quality. This can be improved by modifying the network to predict the mask IoU or other quality indicators.
- The masks of tiny-sized objects tend to be near square, and large objects’ masks may have artifacts on bounding box borders. These are weaknesses of the YOLACT method, which could be resolved by enhancing mask prototype capacity or reformulating the mask generator.
Lastly, since the model currently only utilizes 1/50 of the available SA-1B datasets, its performance can be further improved with more training data.
paperreview deeplearning cv imagesegmentation video