Paper Review: FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization

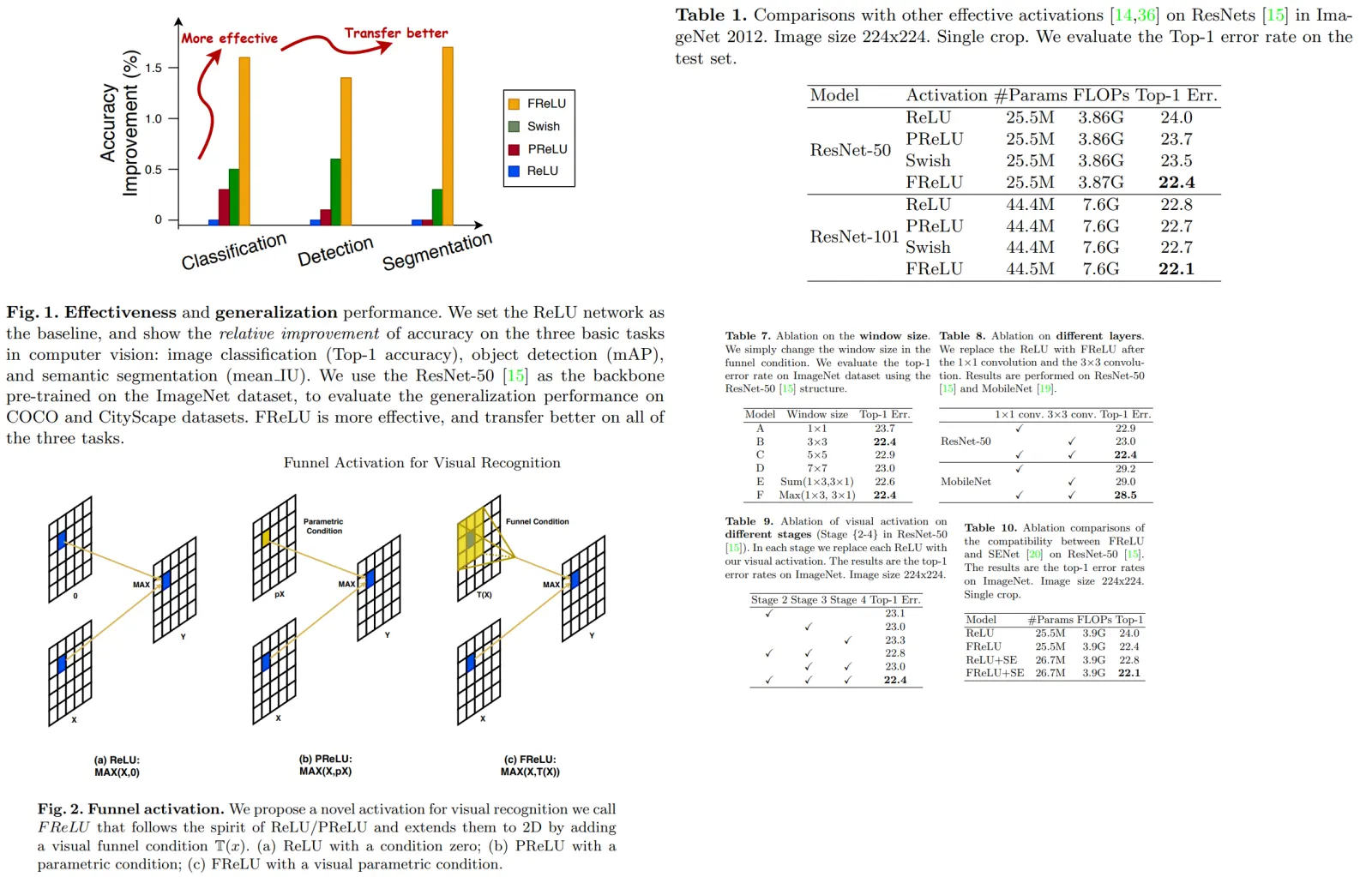
FastViT is a new hybrid vision transformer architecture that combines elements of transformer and convolutional designs, providing an optimal balance between accuracy and efficiency. It introduces a novel token mixing operator called RepMixer, which lowers memory access costs by eliminating skip-connections. The model also uses train-time overparametrization and large kernel convolutions to enhance accuracy without significantly affecting latency.
Performance-wise, FastViT is faster than several leading architectures like CMT, EfficientNet, and ConvNeXt, especially on mobile devices, when compared to similar accuracy levels on the ImageNet dataset. Moreover, it surpasses MobileOne by 4.2% in Top-1 accuracy on ImageNet. The model is versatile, proving superior in various tasks like image classification, detection, segmentation, and 3D mesh regression, both on mobile devices and desktop GPUs. Additionally, FastViT exhibits robustness against out-of-distribution samples and corruptions.
Architecture
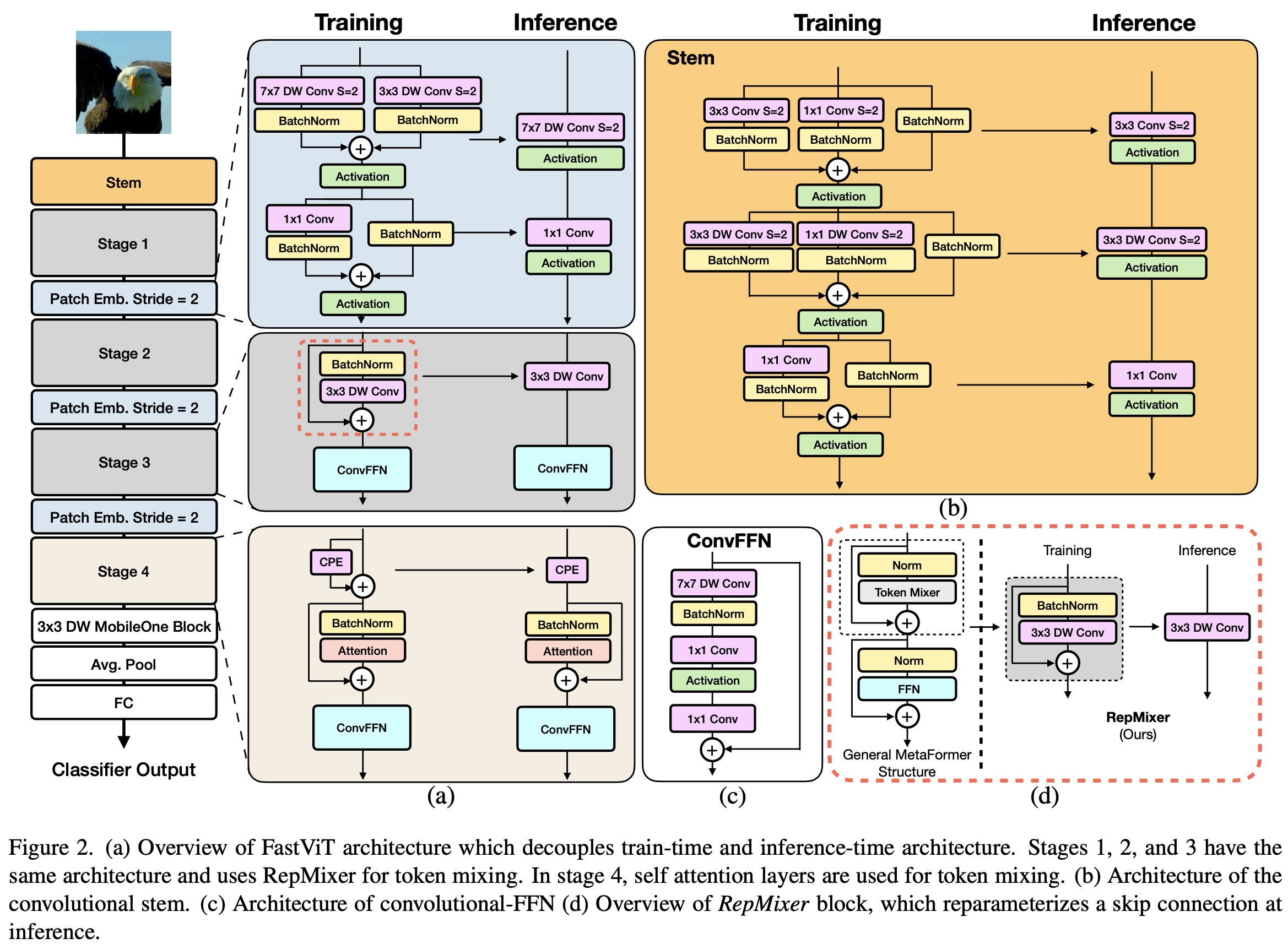
Reparameterizing Skip Connections
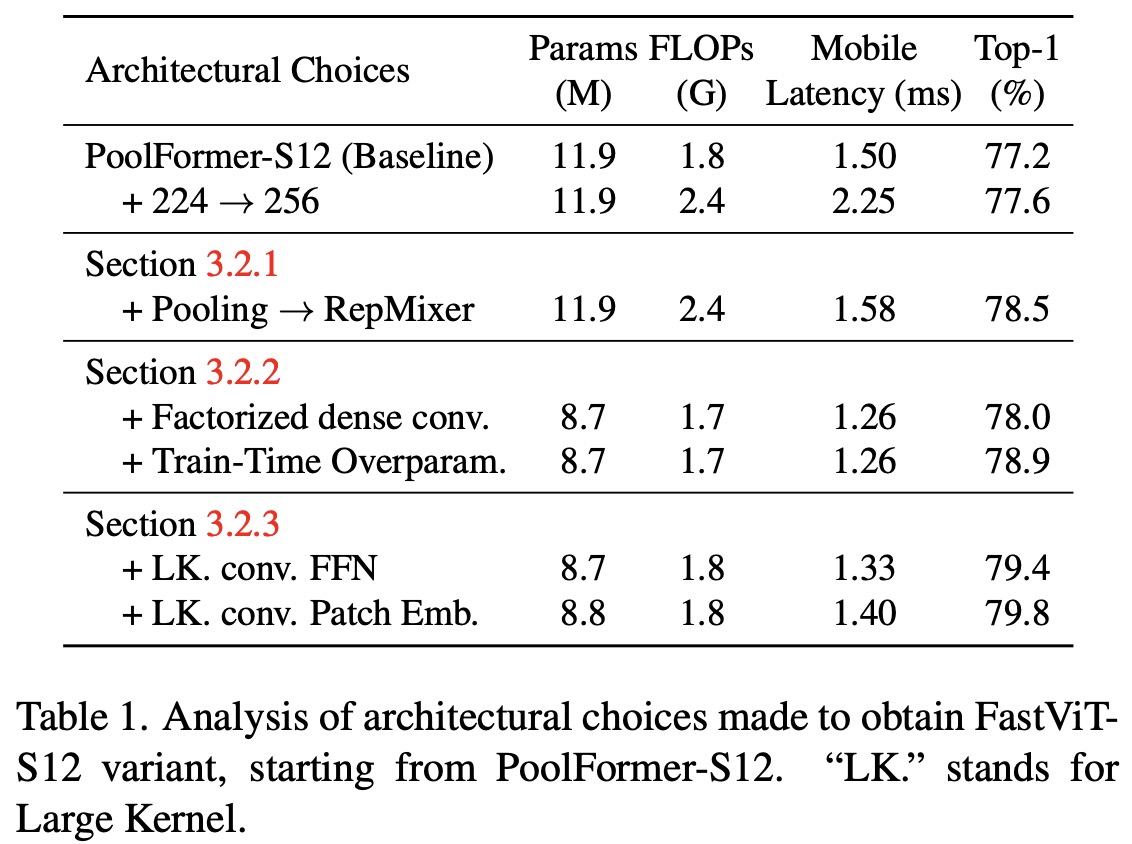
RepMixer is a novel convolutional mixing approach inspired by ConvMixer. Instead of the earlier design Y = BN(σ(DWConv(X))) + X, RepMixer rearranges operations and eliminates the non-linear activation function, resulting in Y = DWConv(BN(X) + X. This design can be further simplified during inference to just Y = DWConv(X). This makes the model faster and more efficient.
The model uses conditional positional encodings, which are dynamic and depend on the local input tokens. These encodings are derived from a depth-wise convolution operation and combined with patch embeddings. Notably, no non-linearities are used in this process, allowing this block to be reparameterized.
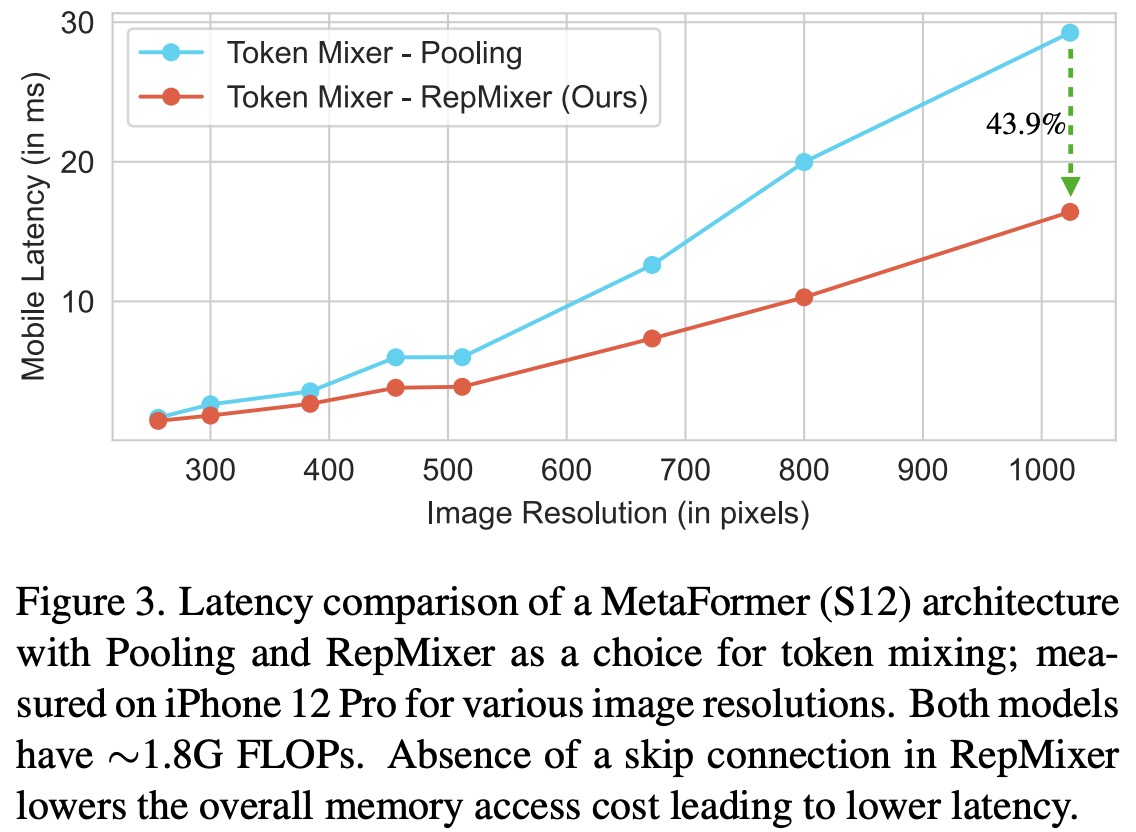
In an empirical study, the RepMixer design was compared with another efficient token mixer, Pooling, in a MetaFormer S12 structure, with both models having approximately 1.8G FLOPs. Tests on an iPhone 12 Pro showed that RepMixer notably reduced latency, particularly at high resolutions. For instance, at a 384×384 resolution, RepMixer reduced latency by 25.1%, and at 1024×1024, the reduction was an impressive 43.9%.
Linear Train-time Overparameterization
To boost efficiency in terms of parameter count, FLOPs, and latency, dense k×k convolutions were replaced with their factorized version, comprising k×k depthwise followed by 1×1 pointwise convolutions. While this reduces the model’s parameter count, which can decrease its capacity, this was countered by implementing linear train-time overparameterization. This overparameterization in specific layers (stem, patch embedding, and projection layers) led to a performance boost.
However, train-time overparameterization adds a computational overhead, leading to a longer training time. In the architecture, overparameterization was limited to layers where dense k×k convolutions were replaced with their factorized form. Since these layers have a lower computational cost than the rest of the network, the increased training time is marginal. For instance, training the FastViT-SA12 model took only 6.7% longer, and FastViT-SA36 took 4.4% longer when overparameterization was applied.
Large Kernel Convolutions
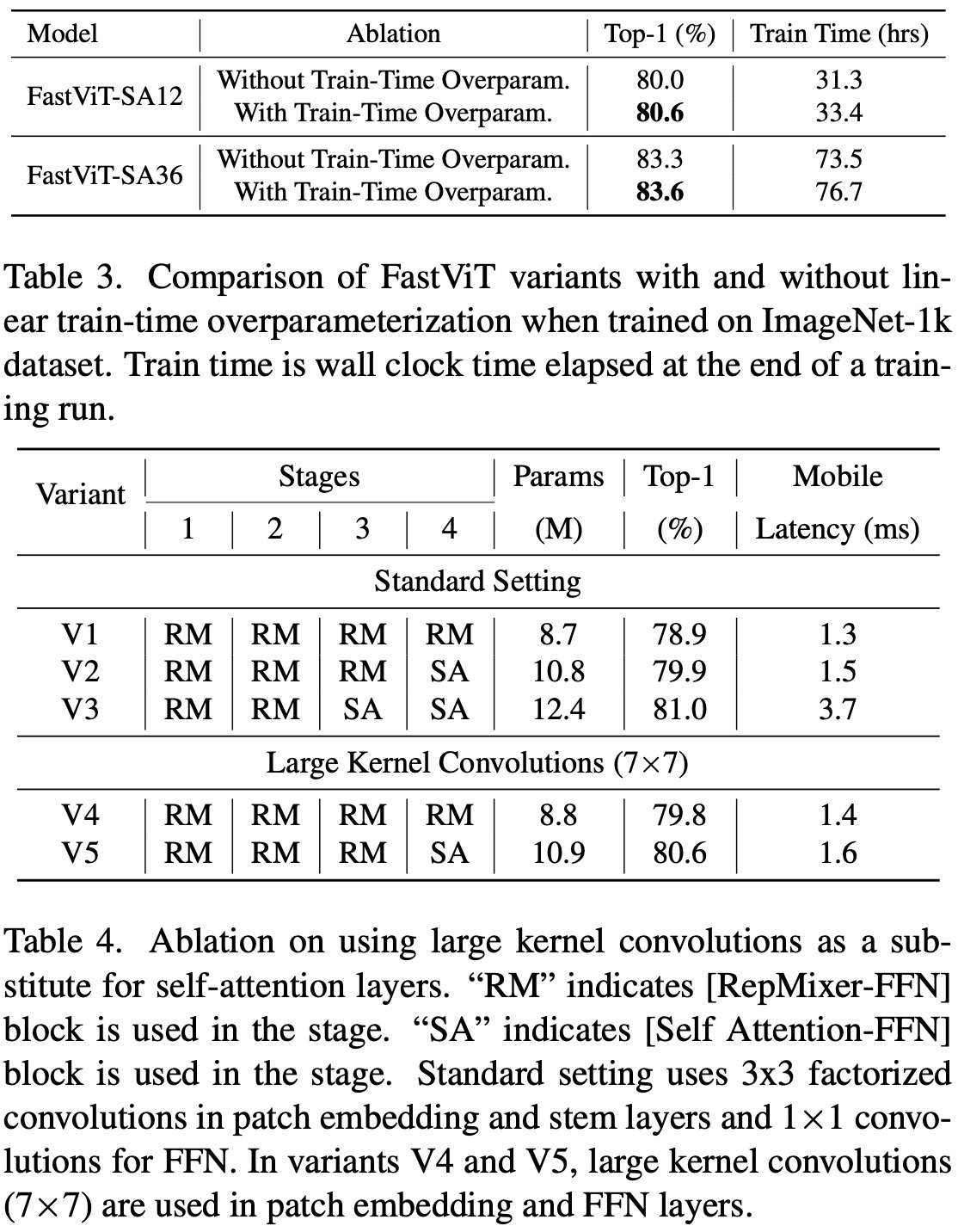
RepMixer has a localized receptive field in contrast to the self-attention token mixers, which are computationally demanding. To enhance the receptive field without using the resource-intensive self-attention, depthwise large kernel convolutions are integrated into FFN and patch embedding layers. Overall, large kernel convolutions lead to a 0.9% enhancement in Top-1 accuracy for FastViT-S12.
Structurally, the FFN block resembles the ConvNeXt block, but Batch Normalization is chosen over Layer Normalization since it fuses better with previous layers during inference. Large kernel convolutions not only widen the receptive field but also amplify model robustness.
Experiments
The models are trained on 8 A100. Inference is done on iPhone12 Pro Max with iOS 16 and on RTX-2080Ti.
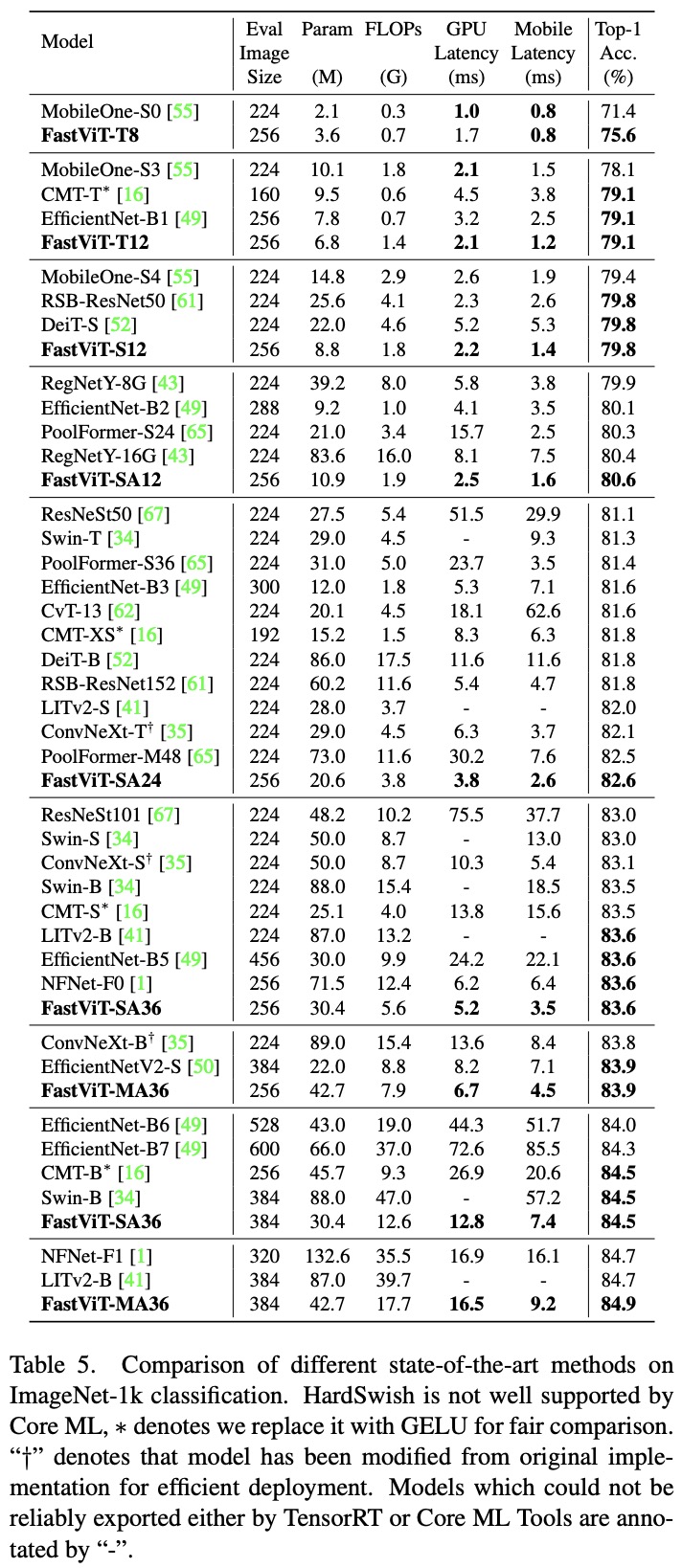
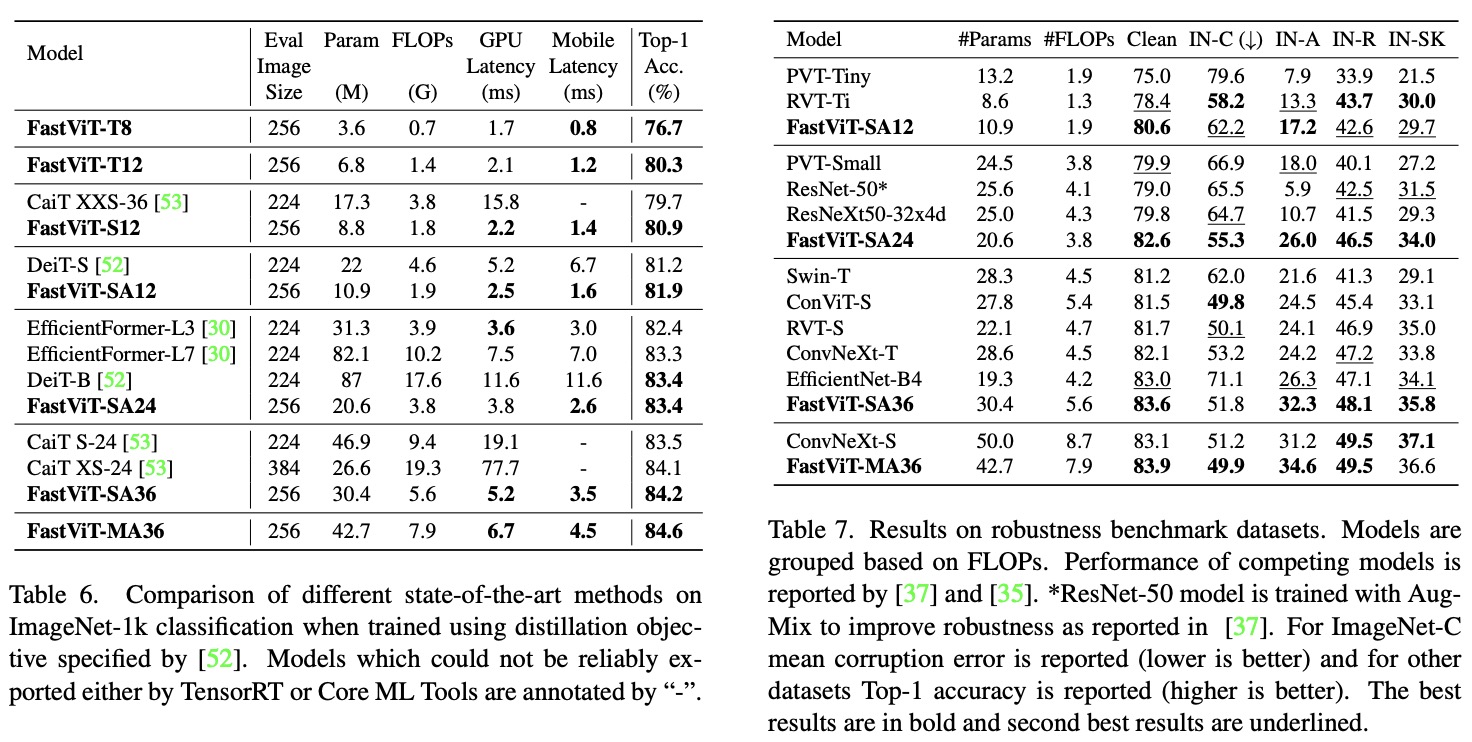
- FastViT demonstrated superior accuracy-latency trade-offs on both desktop-grade GPUs and mobile devices compared to other state-of-the-art models for image classification. For instance, FastViT-MA36 achieved 84.9% Top-1 accuracy while being significantly smaller and consuming fewer FLOPs than LITv2-B.
- The researcher experimented with distillation techniques, training models with a distillation objective using the DeiT setting, with RegNet16GF as the teacher model. FastViT surpassed the performance of the EfficientFormer model while having fewer parameters, less FLOPs, and lower latency.
- FastViT models showcased superior robustness than many recent vision transformers and were faster than some CNN models. Using large kernel convolutions and self-attention layers enhanced the model’s robustness.
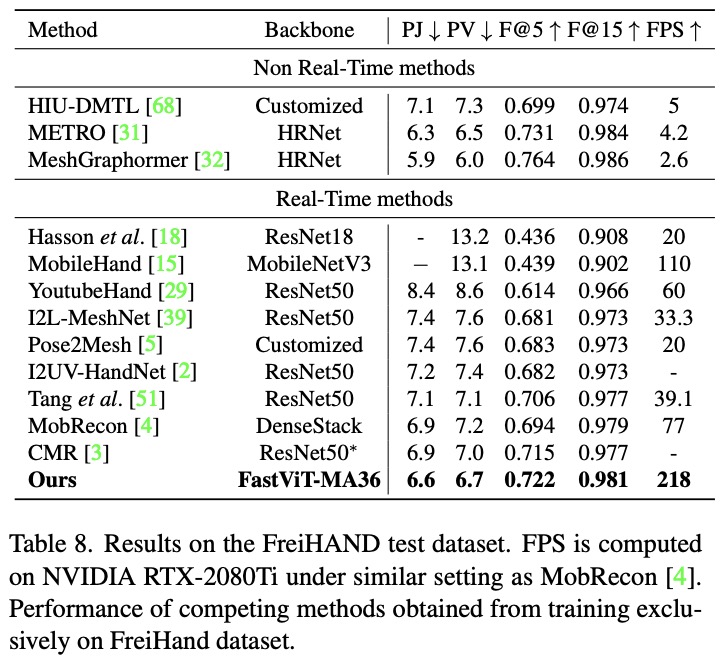
- Most current works on 3D hand mesh estimation employ complex mesh regression layers. In contrast, th authors propose using a high-quality feature extraction backbone combined with a simpler mesh regression layer. The new approach outperformed other methods in real-time assessments on the FreiHand dataset, especially in joint and vertex error metrics, while also being faster than other state-of-the-art methods.
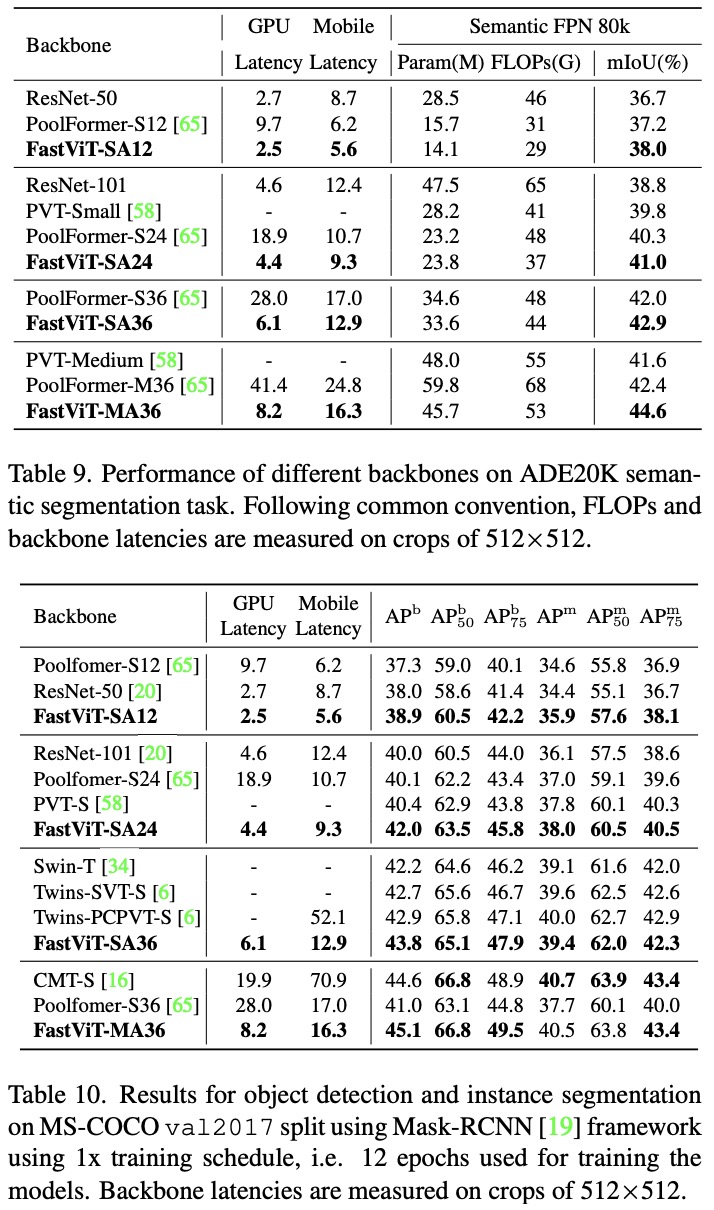
- In semantic segmentation, FastViT-MA36 achieved a better mIoU than PoolFormer-M36 despite the latter having higher computational costs.
- For object detection, FastViT models achieved state-of-the-art performance and demonstrated better efficiency on both desktop and mobile devices compared to models like CMT-S.