Paper Review: Ferret: Refer and Ground Anything Anywhere at Any Granularity

Ferret is a new Multimodal Large Language Model adept at understanding and linking detailed descriptions to specific areas within images, regardless of their shape or size. It employs a novel hybrid region representation combining discrete coordinates with continuous features for accurate image region representation. A spatial-aware visual sampler enables it to handle various region inputs, including points, bounding boxes, and free-form shapes. Ferret was trained using GRIT, a comprehensive dataset with over 1.1 million samples, including 95,000 hard negative examples to enhance robustness. It excels in traditional image referring and grounding tasks, outperforms existing MLLMs in region-based multimodal communication, and shows improved capabilities in detailed image description and reduced object hallucination.
Method
Hybrid region representation

Usually, there are three formats for referencing image regions: point, box, and free-form shapes. Points and boxes are represented by simple coordinates, but free-form shapes, which include various types like scribbles and polygons, are more complex. To effectively represent these shapes, the authors propose a hybrid region representation, combining discrete coordinates with continuous visual features: a 2D binary mask is created for the region and visual features are extracted using a spatial-aware visual sampler. Points are represented by their coordinates and a fixed-radius circle, while boxes and free-form shapes use corner coordinates and a feature extracted from the defined region.
Architecture
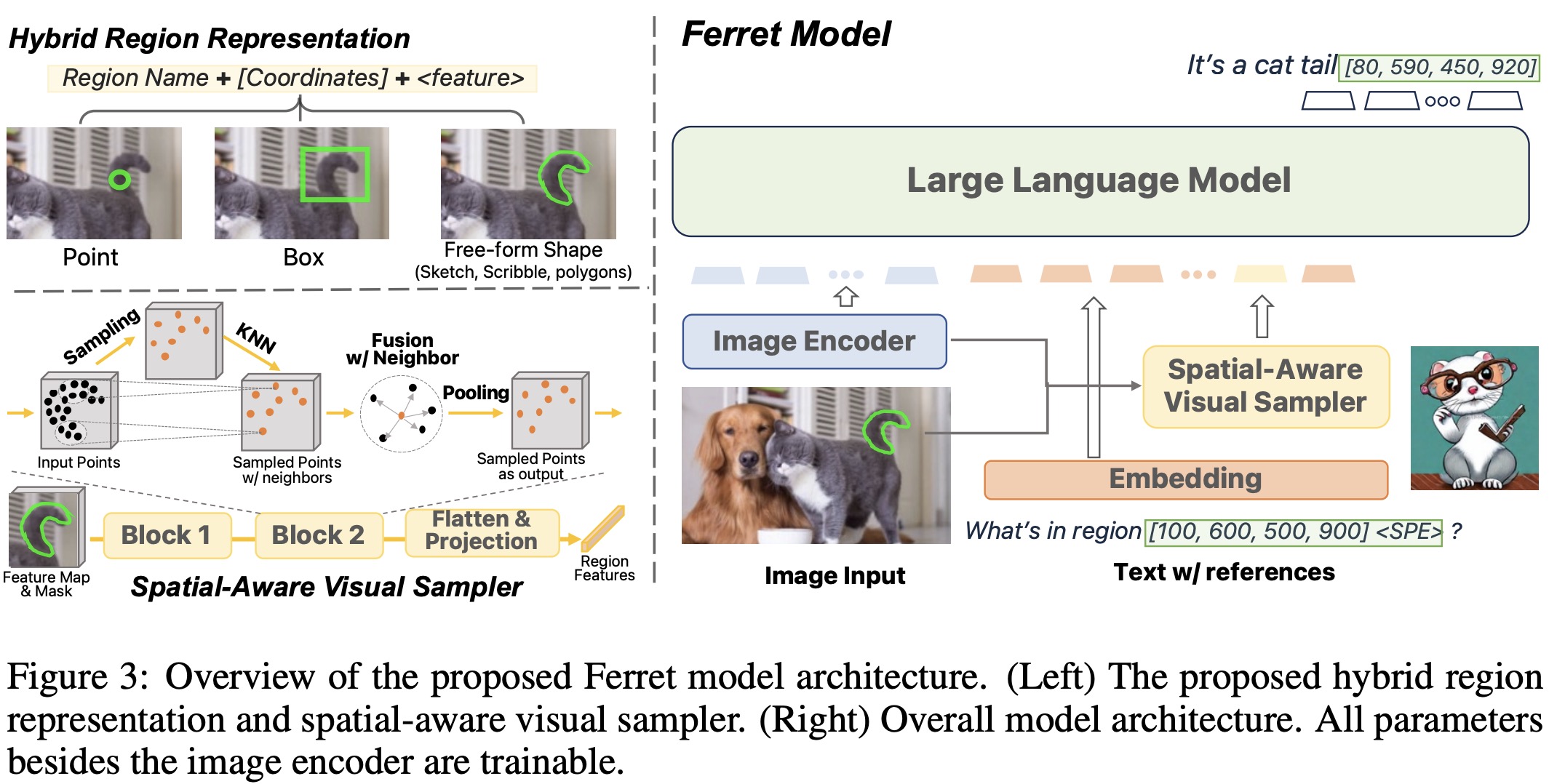
Ferret consists of three main components:
- Image embeddings are extracted with CLIP-ViT-L/14. Text is processed using the LLM’s tokenizer to create text embeddings. Referred regions in images are represented by coordinates and a special token in the text input (
a cat [100, 50, 200, 300] ⟨SPE⟩), which can be combined with ordinary text to form complete sentences. - The spatial-aware visual sampler samples points within a binary region mask and extracts their features through bilinear interpolation. These points are sampled, gathered, and pooled to create a dense feature space. This process is inspired by techniques used in 3D point cloud learning.
- The output of Ferret includes specific region denotations in its responses, allowing for precise grounding of text in image regions. For example, it can generate coordinates for objects mentioned in the text. The LLM component of Ferret is Vicuna instruction-tuned on top of LLaMA.
Grit: Ground-and-Refer Instruction-Tuning dataset
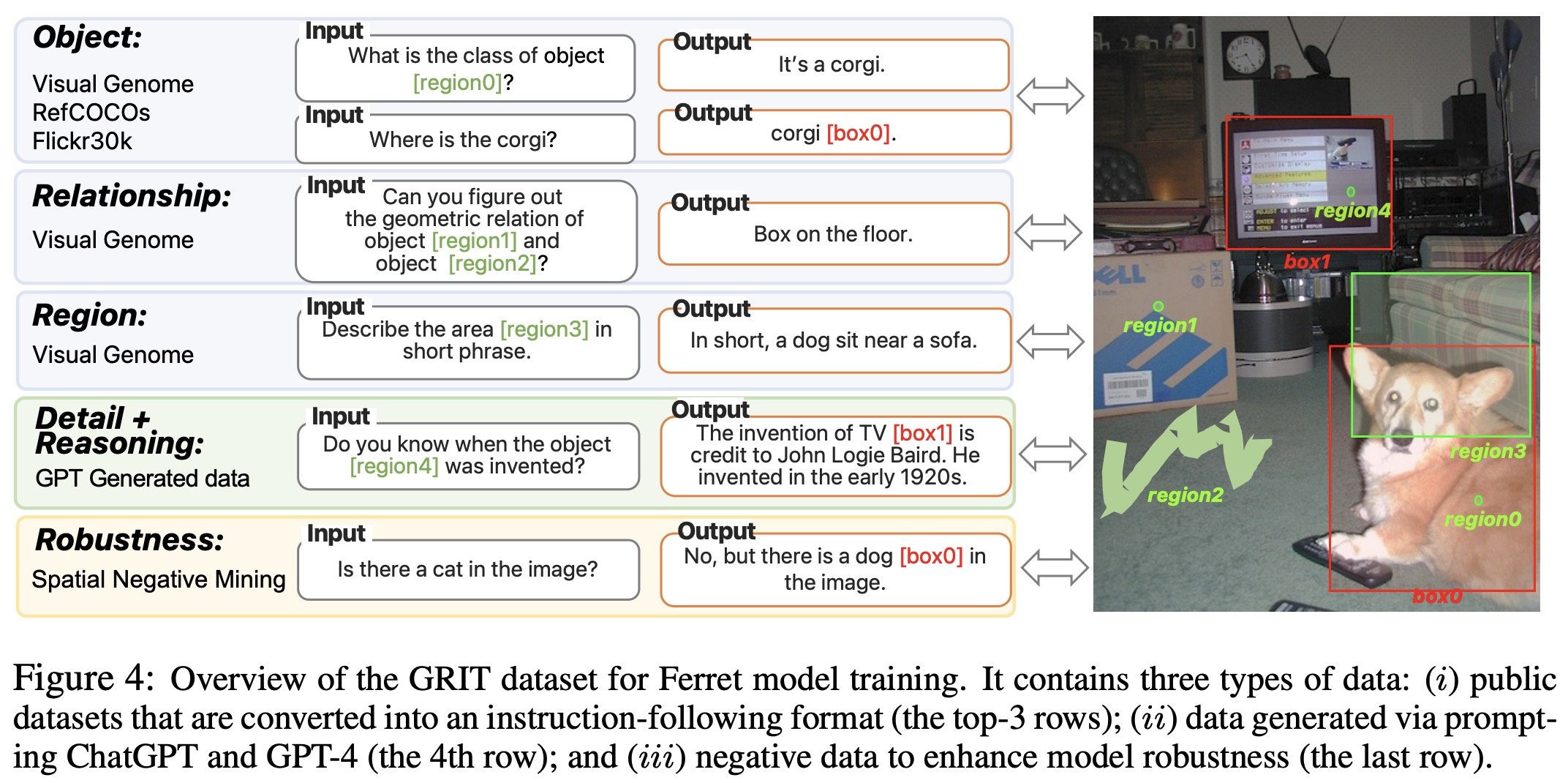
GRIT has ~1.1 million multimodal dialogues for training models. It has three types of data:
- Public Datasets in Instruction Format: Public datasets are reformatted into an instruction-following format. This includes datasets for individual objects, relationships among objects, and descriptions of specific regions, all converted into a Region-in Text-out format.
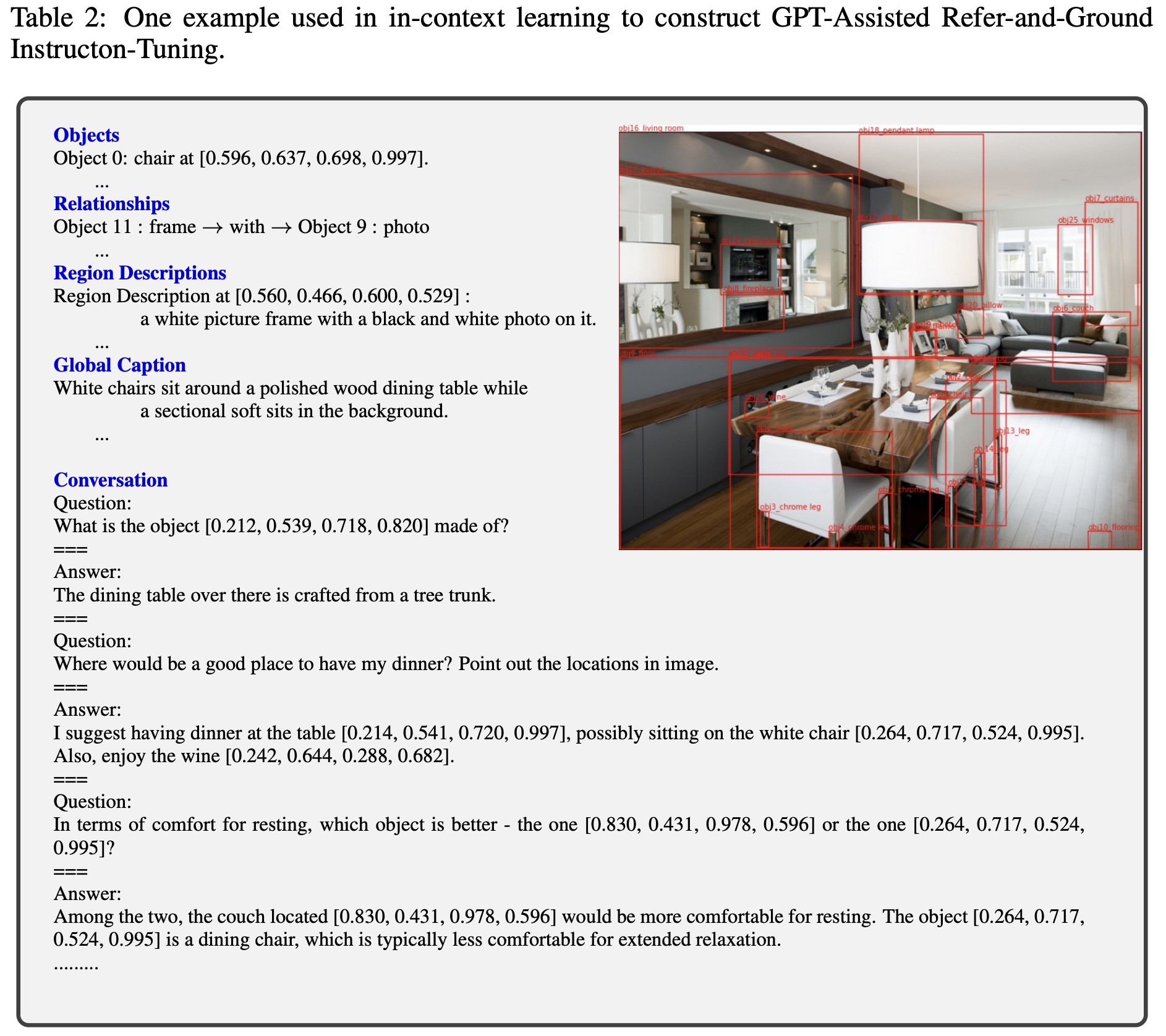
- GPT-Assisted Visual Instruction Data Generation: The authors use few-shot prompting with ChatGPT and GPT-4 to generate new dialogues based on textual scene descriptions of images. The dialogues focus on specific regions, with coordinates added to groundable regions or objects.
- Spatial Negative Mining: The model is asked to localize specific object categories that are not present in the image using two methods: Image-conditioned Category Localization and Semantics-conditioned Category Localization. This approach helps the model discern the absence of certain objects and reduces hallucination errors.
Experiments
The training takes ∼5/2.5 days on 8 A100 GPU for a Ferret-13B/7B.
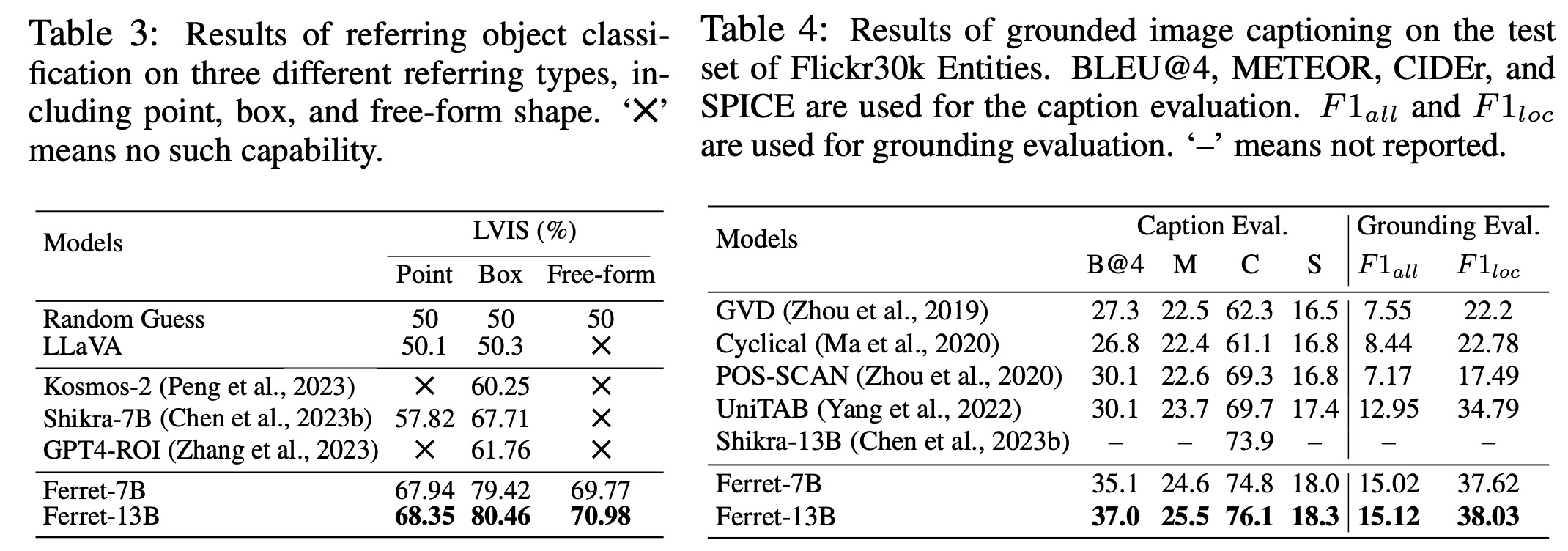
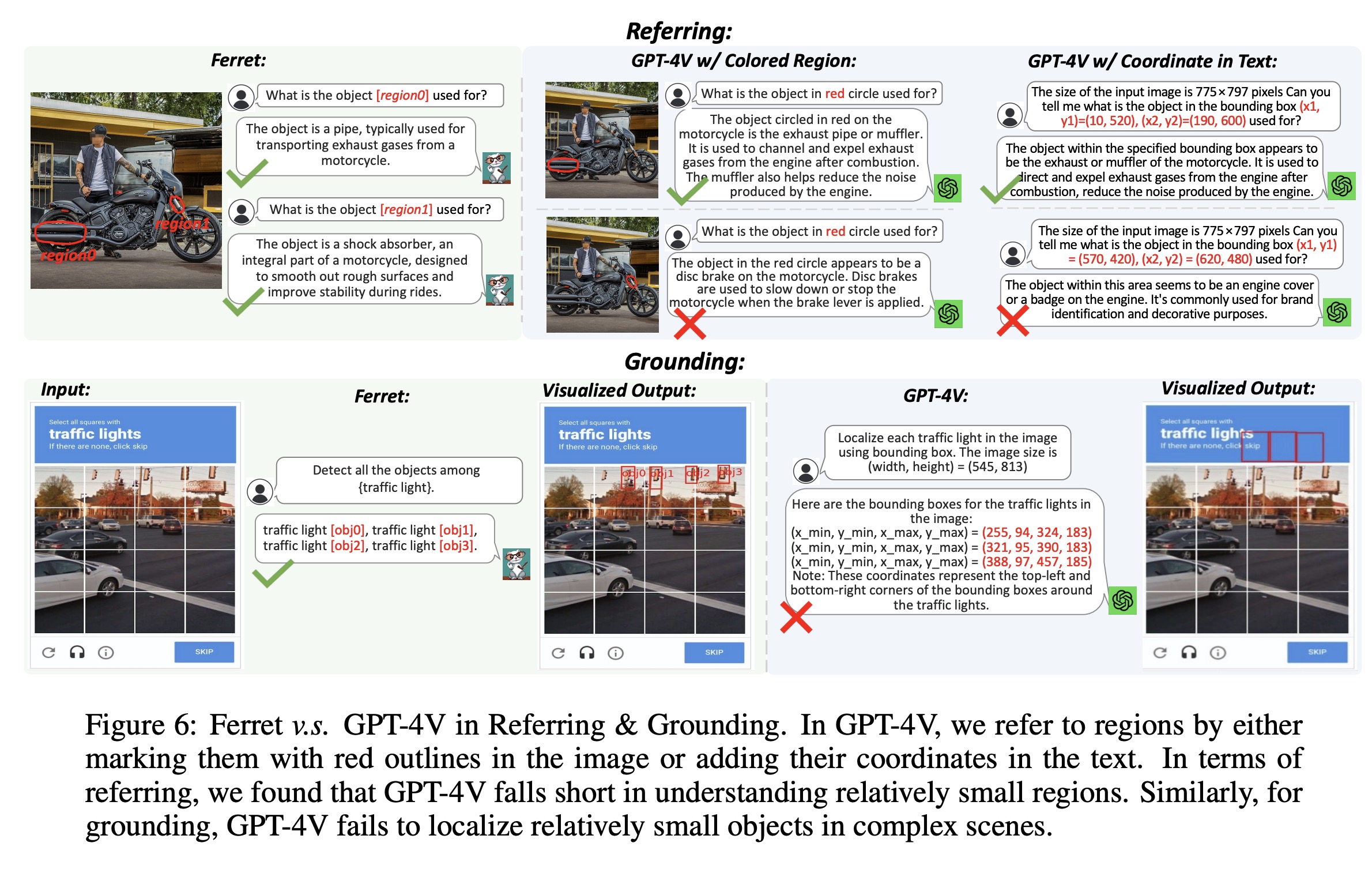
Input Referring: In this task, the model classifies objects in a specified image region, presented as a binary-choice question. The evaluation uses the LVIS dataset, covering over 1000 object categories, and tests three types of referring: point, box, and free-form shape. Ferret outperforms previous models in all referring types.
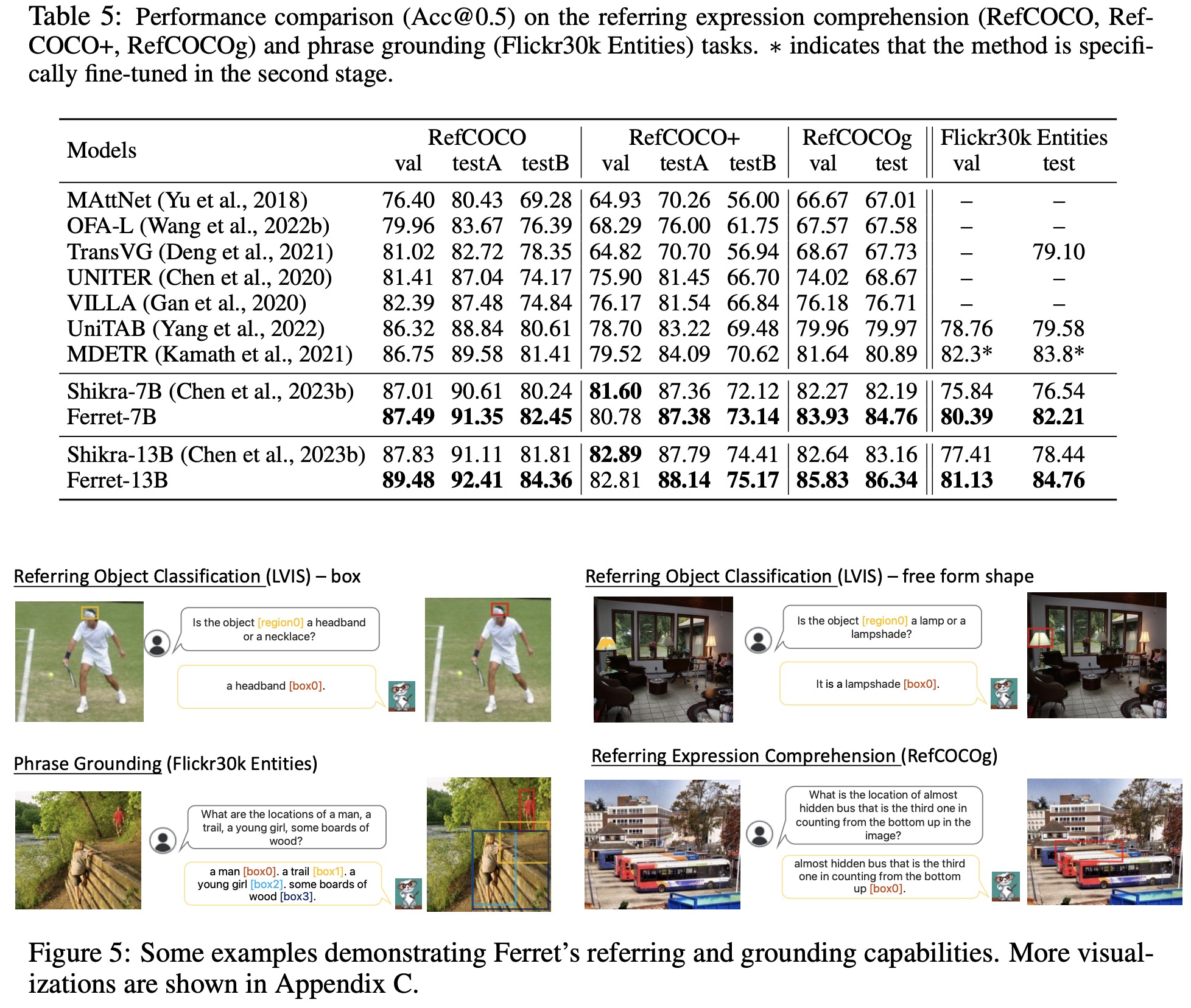
Output Grounding: The model’s grounding capability is evaluated in two sub-tasks: visual grounding and grounded captioning. Visual grounding involves grounding language queries into image regions. Grounded captioning requires generating a caption and grounding all noun phrases to image regions. Ferret demonstrates outstanding performance in these tasks, achieving state-of-the-art results.

Ferret-Bench: Multimodal Chatting with Referring and Grounding: To assess Ferret’s practical application in multimodal chatting, a new benchmark called Ferret-Bench is introduced. It includes three types of region-based questions: Referring Description, Referring Reasoning, and Grounding in Conversation. These tasks test the model’s ability to describe, reason, and accurately ground objects or regions in an image. Ferret significantly outperforms previous models in these tasks, showcasing its strong spatial understanding and reasoning capabilities.