Paper Review: FlowMind: Automatic Workflow Generation with LLMs

FlowMind is a novel system leveraging LLMs to automate workflow generation, addressing limitations of traditional Robotic Process Automation in handling unpredictable tasks. It integrates APIs to ensure data confidentiality, simplifies user interaction, and introduces NCEN-QA, a finance dataset, for benchmarking. Results demonstrate FlowMind’s success and the significance of user feedback in enhancing workflow generation.
The approach
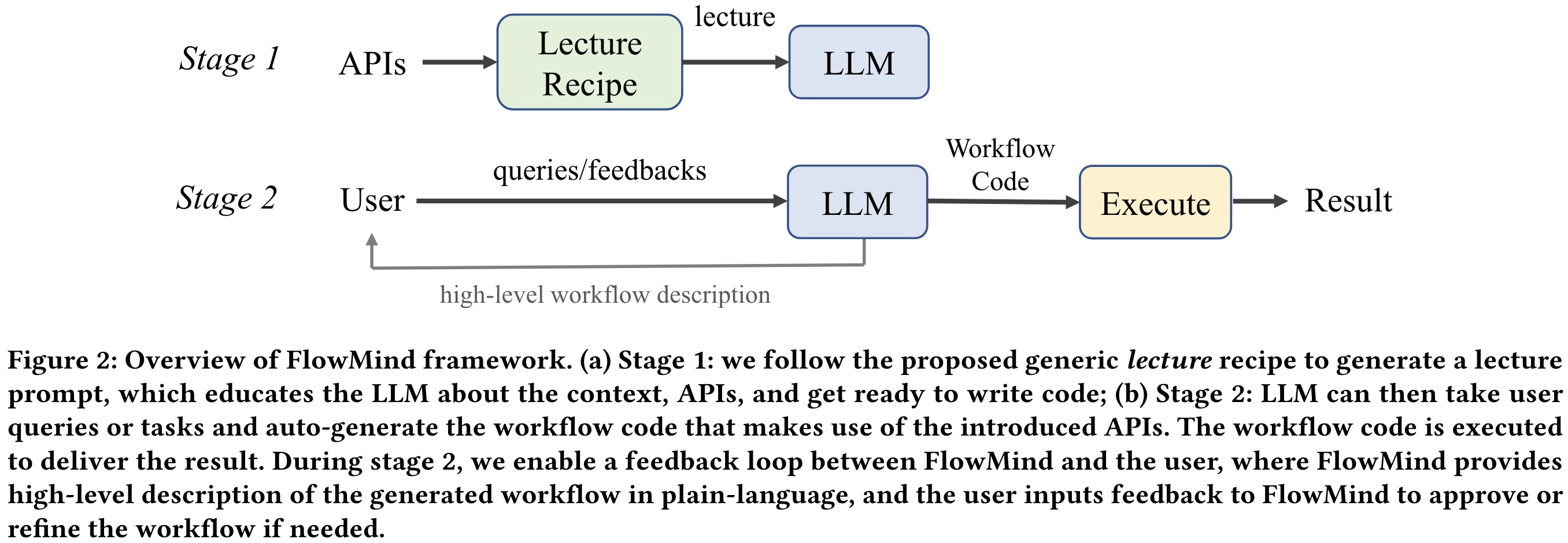
Lecture to LLM

The first stage of the FlowMind framework involves delivering a lecture to familiarize the LLM with the context, available APIs, and the task of generating workflow code. This lecture follows a structured recipe comprising three components: context, APIs, and code. The context introduces the domain of expected tasks or queries, while the APIs provide detailed descriptions of available functions, including input arguments and output variables. Finally, the LLM is instructed to prepare workflow code using the provided APIs upon receiving user queries.
Workflow Generation and Execution
In the second stage of the FlowMind framework, the LLM utilizes the API knowledge acquired in the first stage to handle user queries or tasks by generating corresponding workflow code. This stage comprises two main components: code generation and code execution. During code generation, the LLM constructs a workflow using the introduced APIs to effectively address the user’s query or task, followed by the execution of the workflow to produce the desired output.
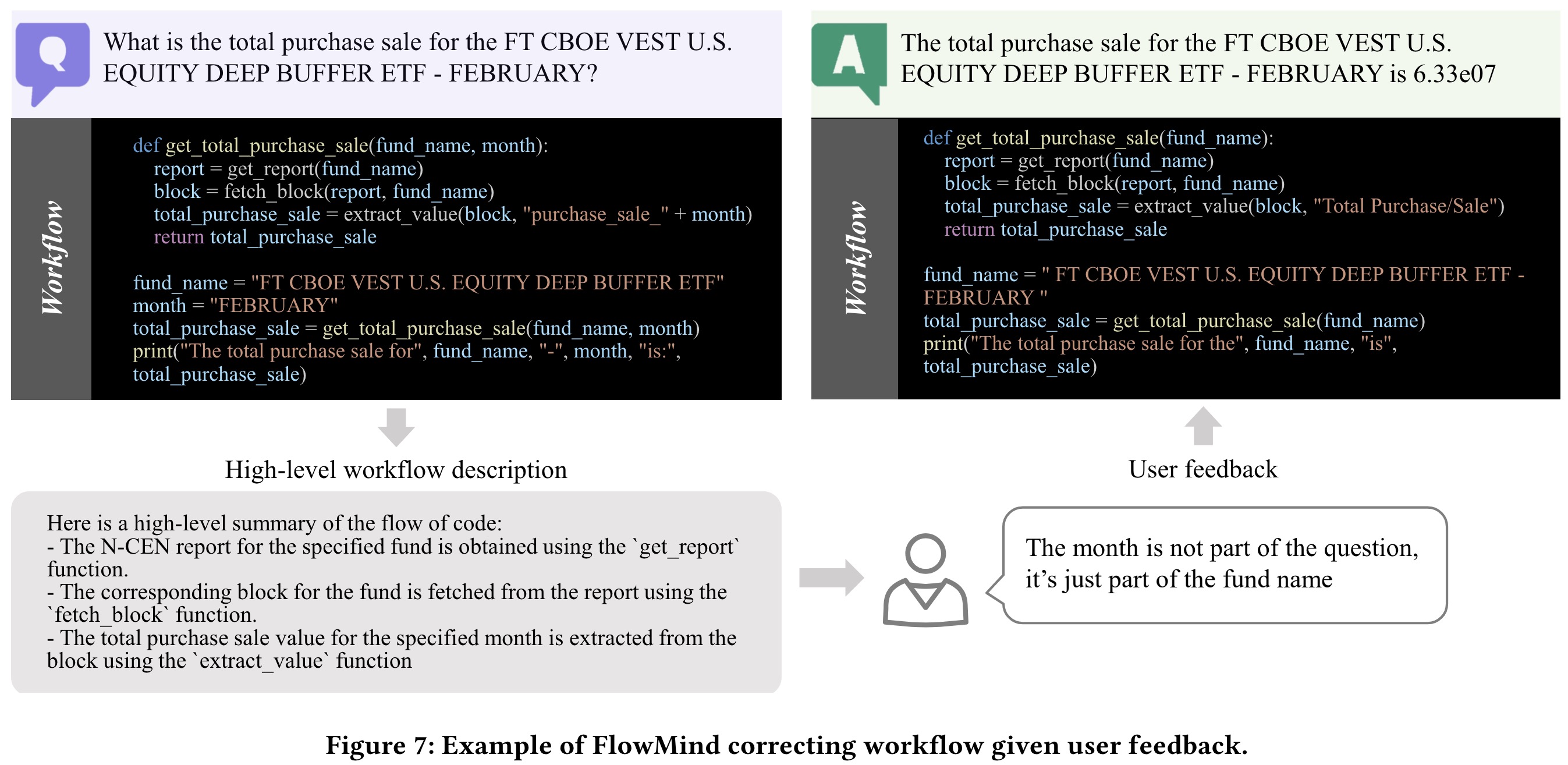
FlowMind allows user feedback during this stage. It presents a high-level description of the generated workflow to the user, enabling them to understand its functionality and structure without delving into the underlying code. This facilitates effective feedback from users, which the LLM can incorporate to refine the workflow as needed, ensuring accurate fulfillment of the user’s needs.
Experiments
NCEN-QA
The new NCEN-QA dataset comprises 600 question-answer pairs centered on fund data from N-CEN reports (mandatory annual filings for US registered investment companies). These reports offer extensive information on various funds, including custodians, pricing services, advisors, and financial figures. The dataset was created by crawling N-CEN reports from the SEC’s Edgar database over three years, resulting in 2,794 reports covering 12k funds. Three difficulty levels were established: NCEN-QA-Easy, NCEN-QA-Intermediate, and NCEN-QA-Hard.
- NCEN-QA-Easy features questions focused on single pieces of fund information, sampled from 200 funds.
- NCEN-QA-Intermediate includes questions requiring mathematical operations on fund data, also sampled from 200 funds.
- NCEN-QA-Hard presents questions focusing on multiple funds, requiring aggregation or investigation across funds, with 200 questions sampled.
Results

Accuracy was measured by comparing output answers to ground truth, considering entity names and numerical precision. FlowMind significantly outperformed the GPT-Context-Retrieval baseline method, particularly in handling complex questions. Ablation study showed each component of the lecture recipe to be crucial for FlowMind’s success. Excluding context or providing poor API descriptions led to decreased performance. Incorporating user feedback improved FlowMind’s accuracy by allowing adjustments to the workflow based on suggestions. User feedback helped correct false assumptions and refine workflows, resulting in near-perfect accuracy across datasets.
paperreview deeplearning llm agent