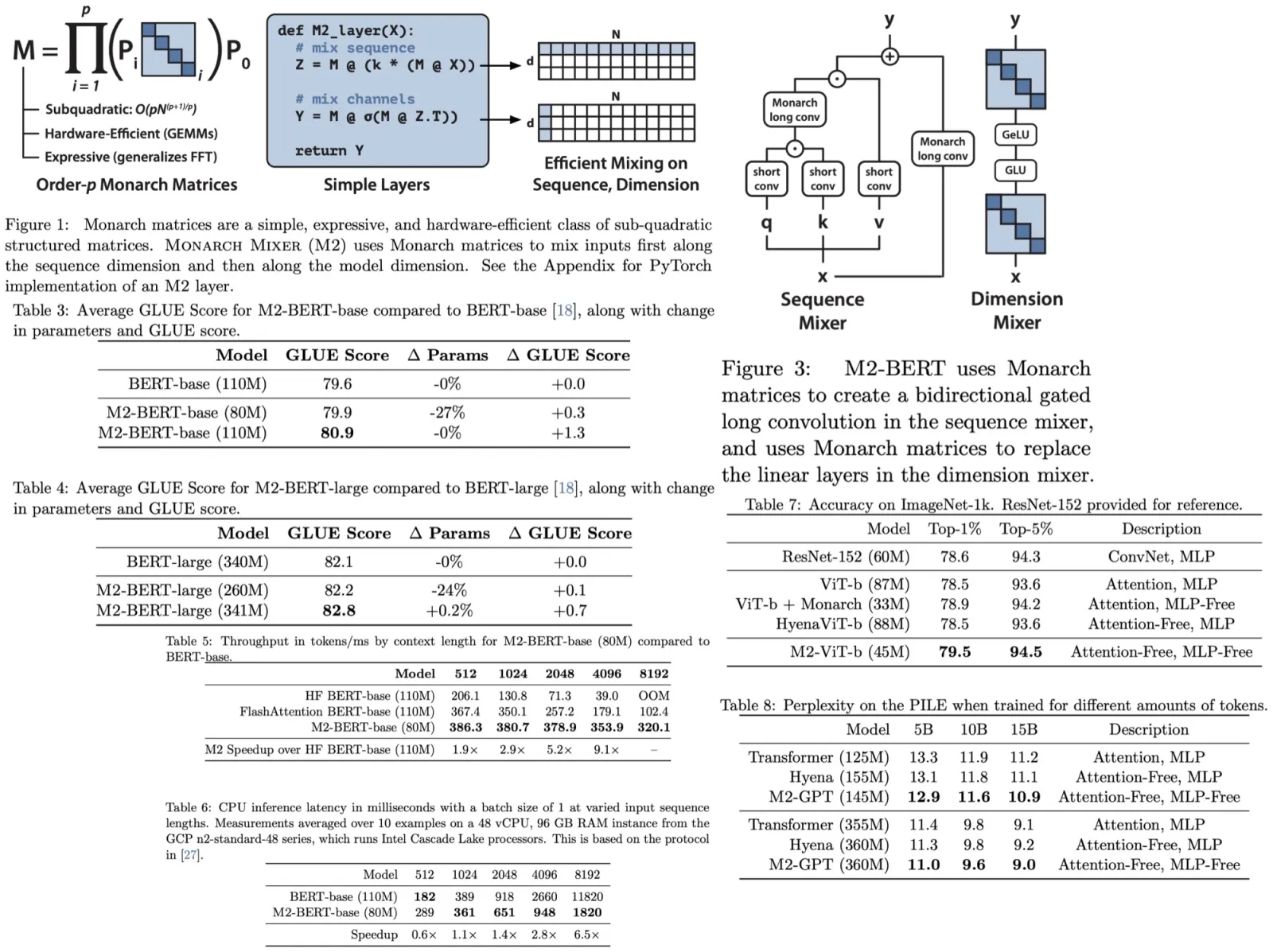
Paper Review: FreeU: Free Lunch in Diffusion U-Net
In this paper, the authors explore the potential of diffusion U-Net for improved generation quality. While the U-Net’s main structure aids in denoising, its skip connections add high-frequency features, sometimes overshadowing the main backbone’s semantics. Based on this understanding, the authors introduce “FreeU”, a method that enhances generation quality without requiring extra training. This approach strategically balances the influence of skip connections and the backbone of the U-Net. When implemented into existing diffusion models like Stable Diffusion, DreamBooth, ModelScope, Rerender, and ReVersion, FreeU improves the generation quality by merely adjusting two scaling factors during the inference phase.
Methodology
Diffusion models like Denoising Diffusion Probabilistic Models are fundamental for data modeling and involve two key processes: diffusion and denoising:
- Diffusion Process: Gaussian noise is progressively introduced to the data distribution through a Markov chain following a variance schedule.
- Denoising Process: Aims to reverse the diffusion process to retrieve the original clean data from the noisy input.
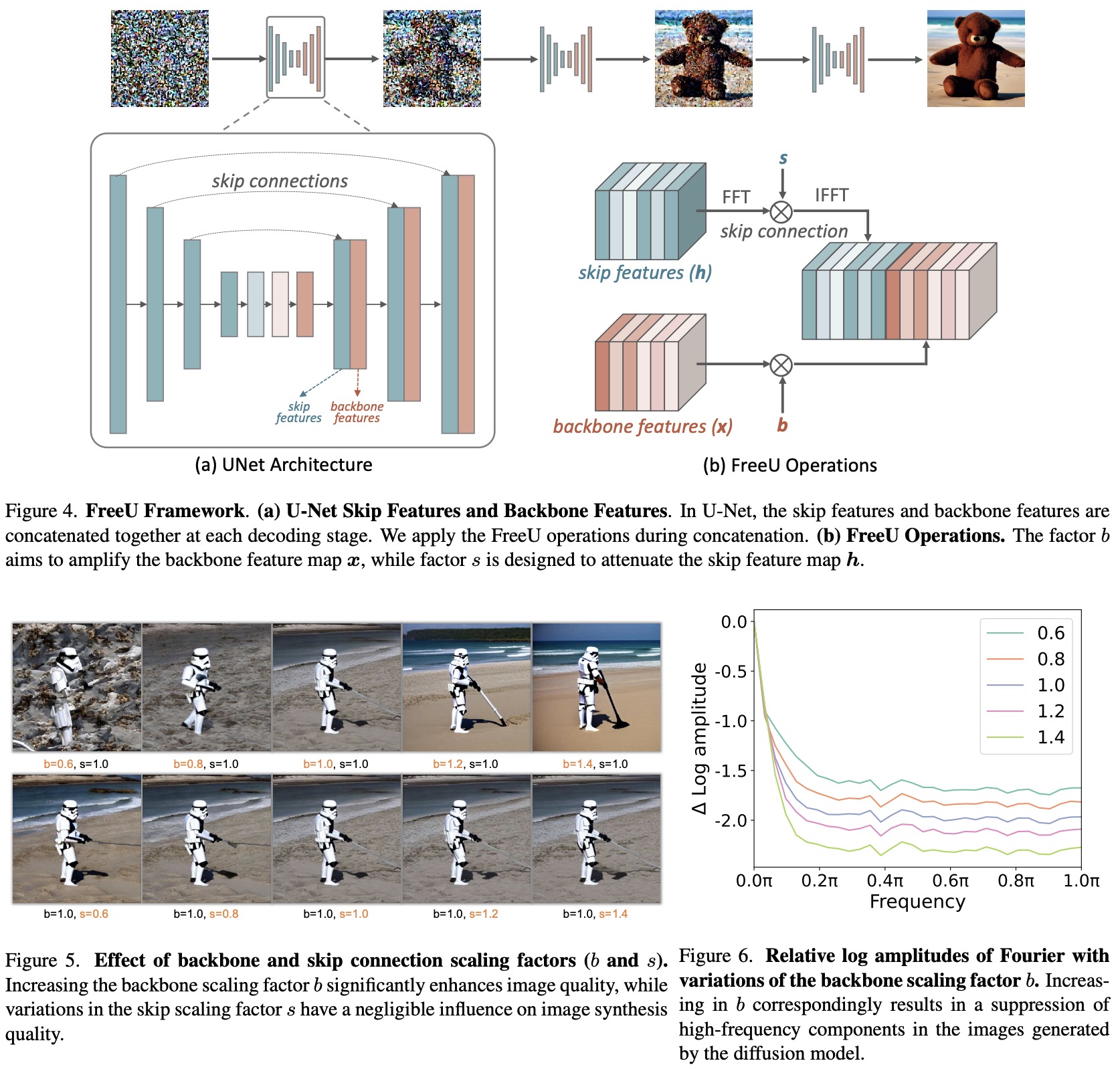
How does diffusion U-Net perform denoising?
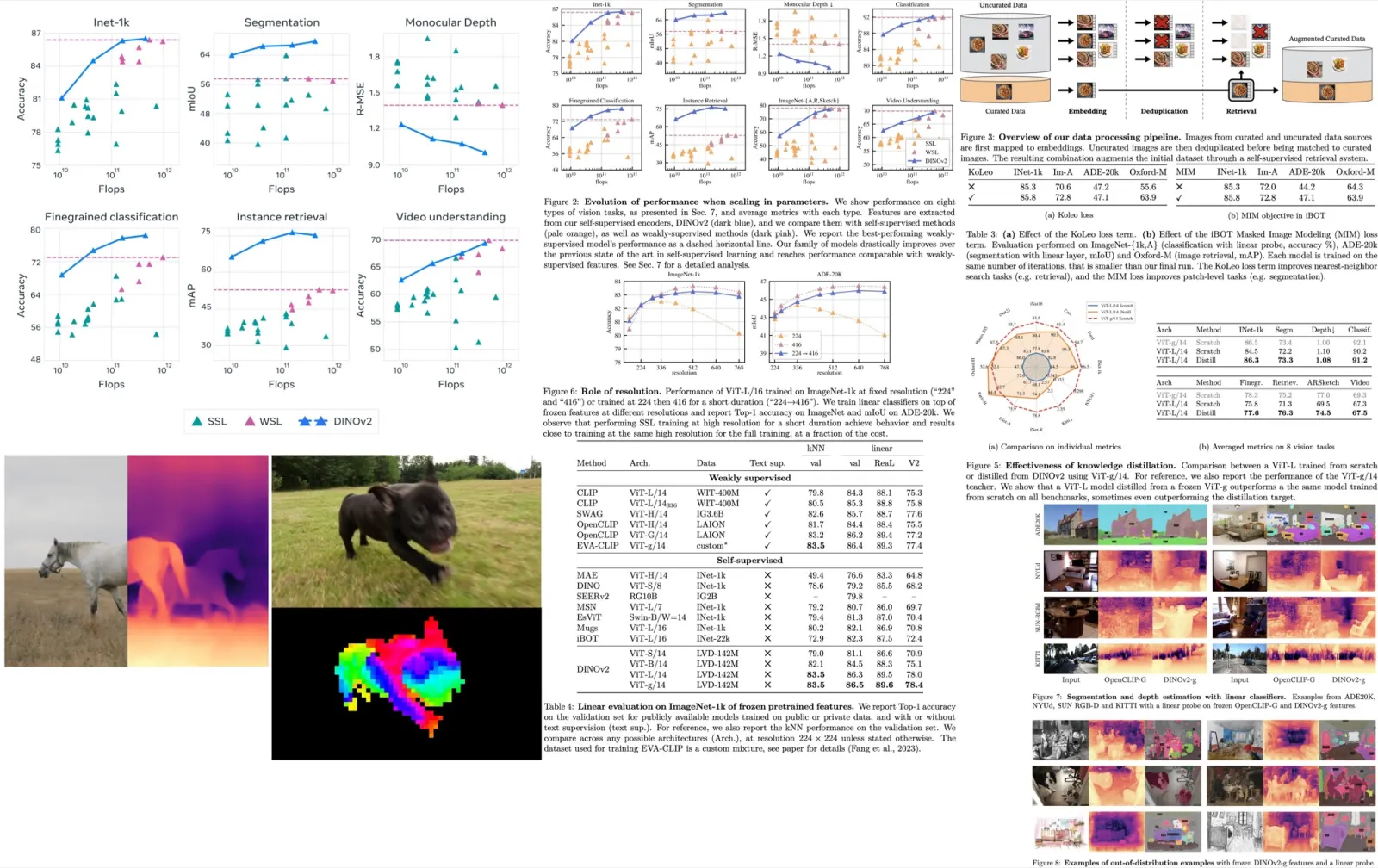
The researchers observed the disparities between low-frequency and high-frequency components in the denoising process, specifically focusing on the U-Net architecture’s contributions. The U-Net architecture includes a main backbone network consisting of an encoder and a decoder and skip connections that facilitate information transfer between corresponding layers.
The backbone of U-Net:
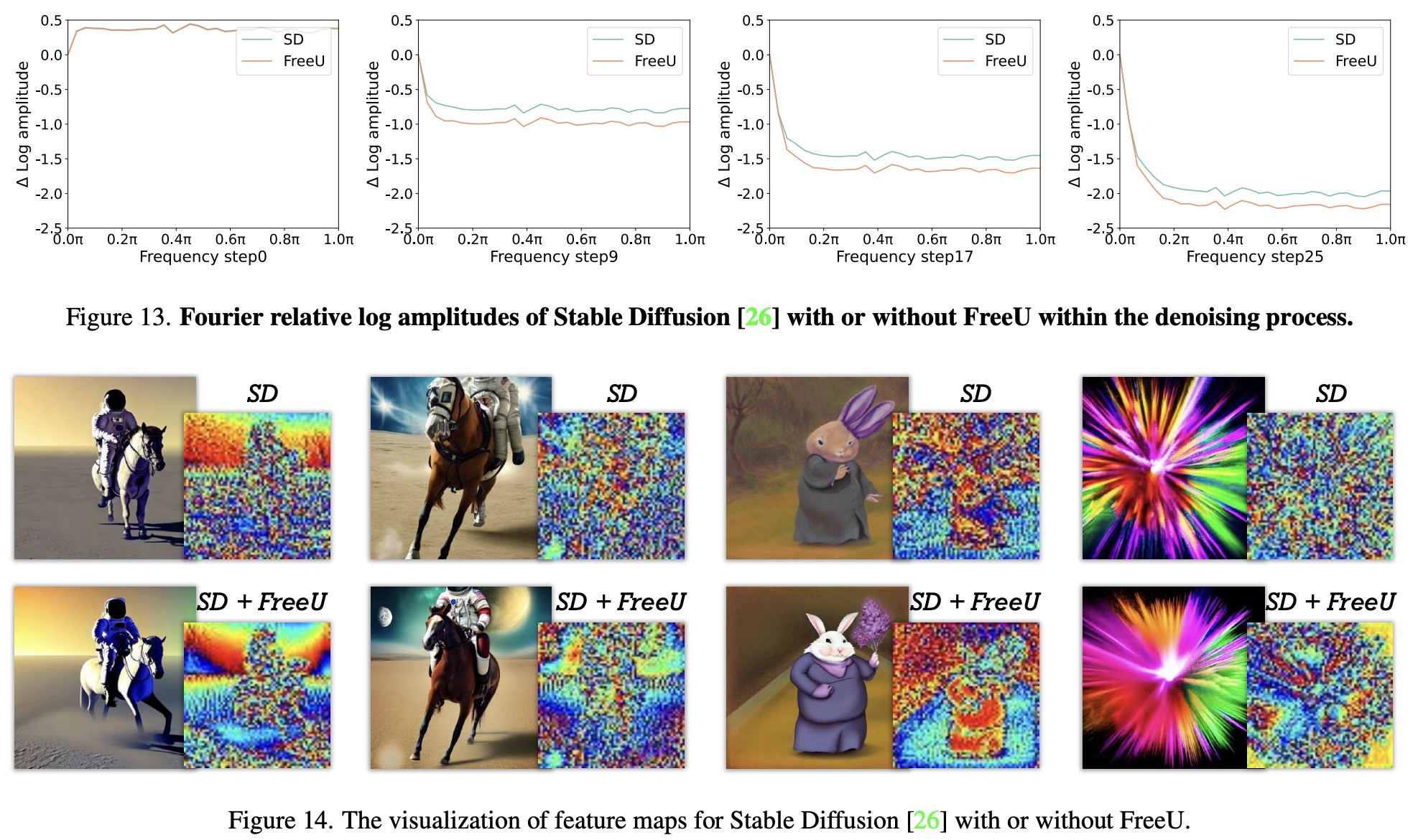
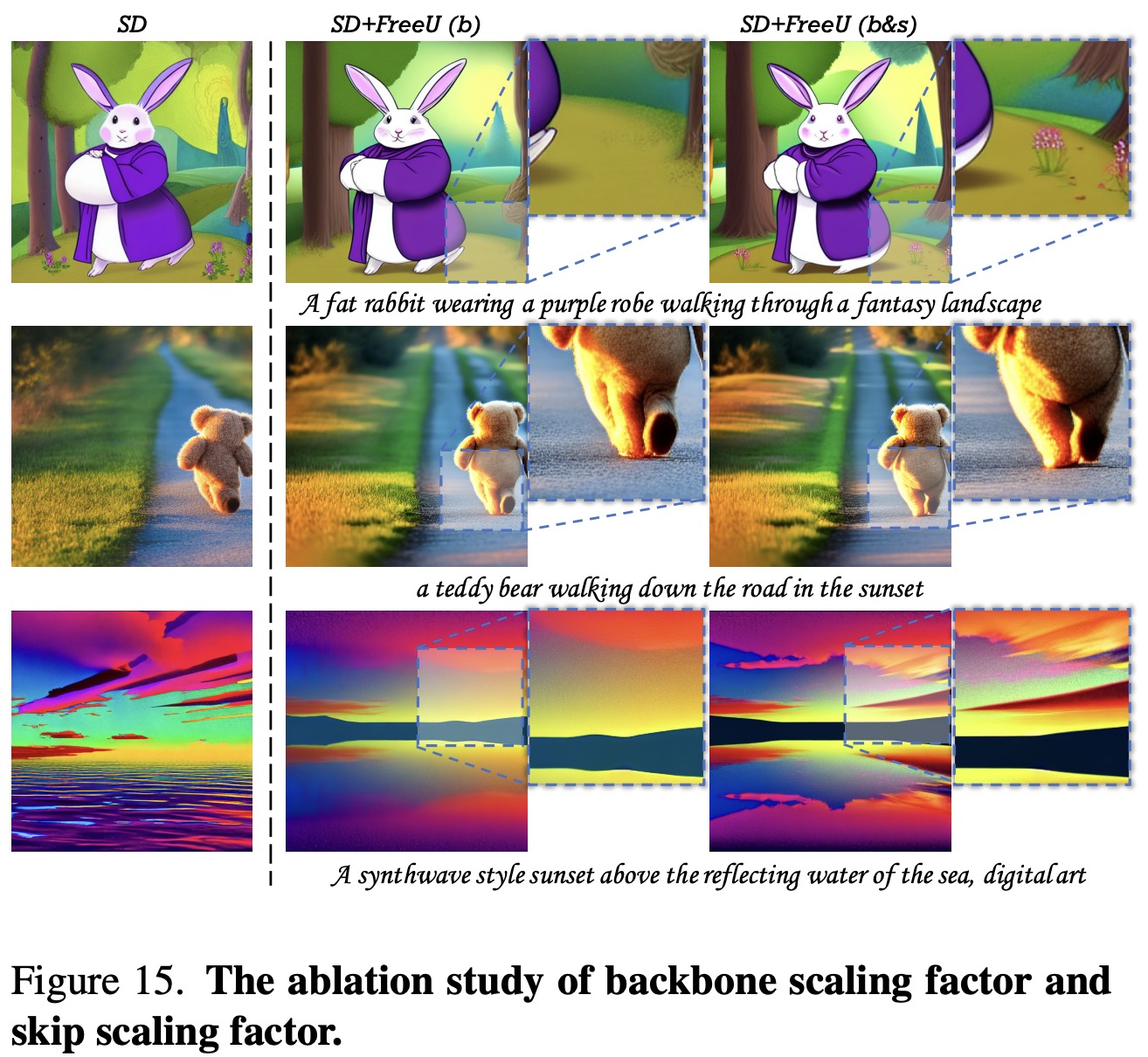
- When the scaling factor, associated with the backbone feature maps, is increased, it distinctly enhances the quality of generated images by amplifying the architecture’s denoising capability.
- This enhancement leads to the suppression of high-frequency components in the images, contributing to better output in terms of fidelity and detail preservation.
Skip Connections of U-Net:
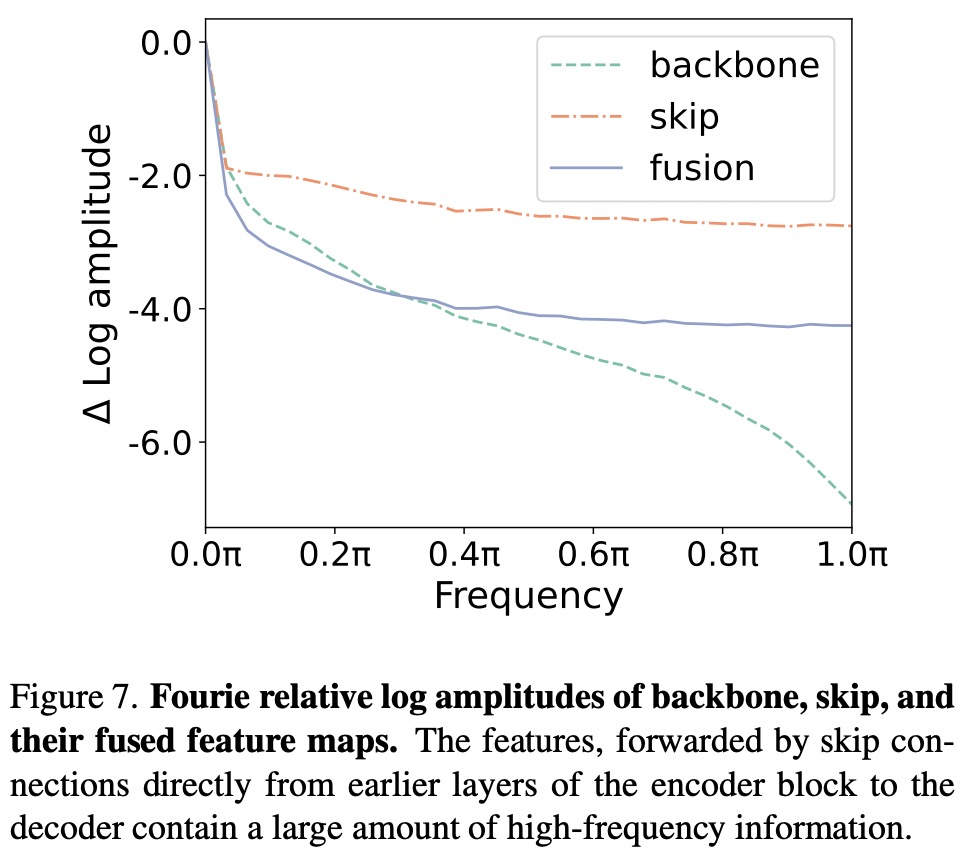
- They forward features from earlier layers of encoder blocks directly to the decoder, primarily constituting high-frequency information.
- The authors conjecture that during training, these high-frequency features might expedite convergence toward noise prediction within the decoder module.
- The modulation of skip features has a negligible impact on the generated images, indicating that they predominantly contribute to the decoder’s information.
Free lunch in diffusion U-Net
FreeU increases the strength of the backbone feature map using a special scaling factor. However, this increase is applied only to half of the channels to avoid making the resulting images too smooth. This careful approach helps balance reducing noise and keeping texture details.
At the same time, the skip-feature feature map is adjusted to reduce low-frequency components mainly. This adjustment is done in the Fourier domain and helps counteract the excessive smoothness from the increased denoising. The Fourier mask plays a crucial role in applying the frequency-dependent scaling factor, and then, the adjusted secondary feature map is combined with the modified main feature map for the next layers in the U-Net structure.
What’s noteworthy about the FreeU method is its practicality and flexibility. It requires minimal changes and can be easily added with a few lines of code, avoiding the need for specific training or adjustments. It allows on-the-fly adjustments to the architecture’s settings during the inference phase, offering more flexibility in reducing noise without adding extra computational load.
Additionally, FreeU’s ability to work well with existing diffusion models stands out, enhancing their effectiveness. It does this by using the unique strengths of both the main and secondary connections in the U-Net architecture, aiming to provide better noise reduction and higher-quality image generation, all while staying practical and adaptable.
Experiments

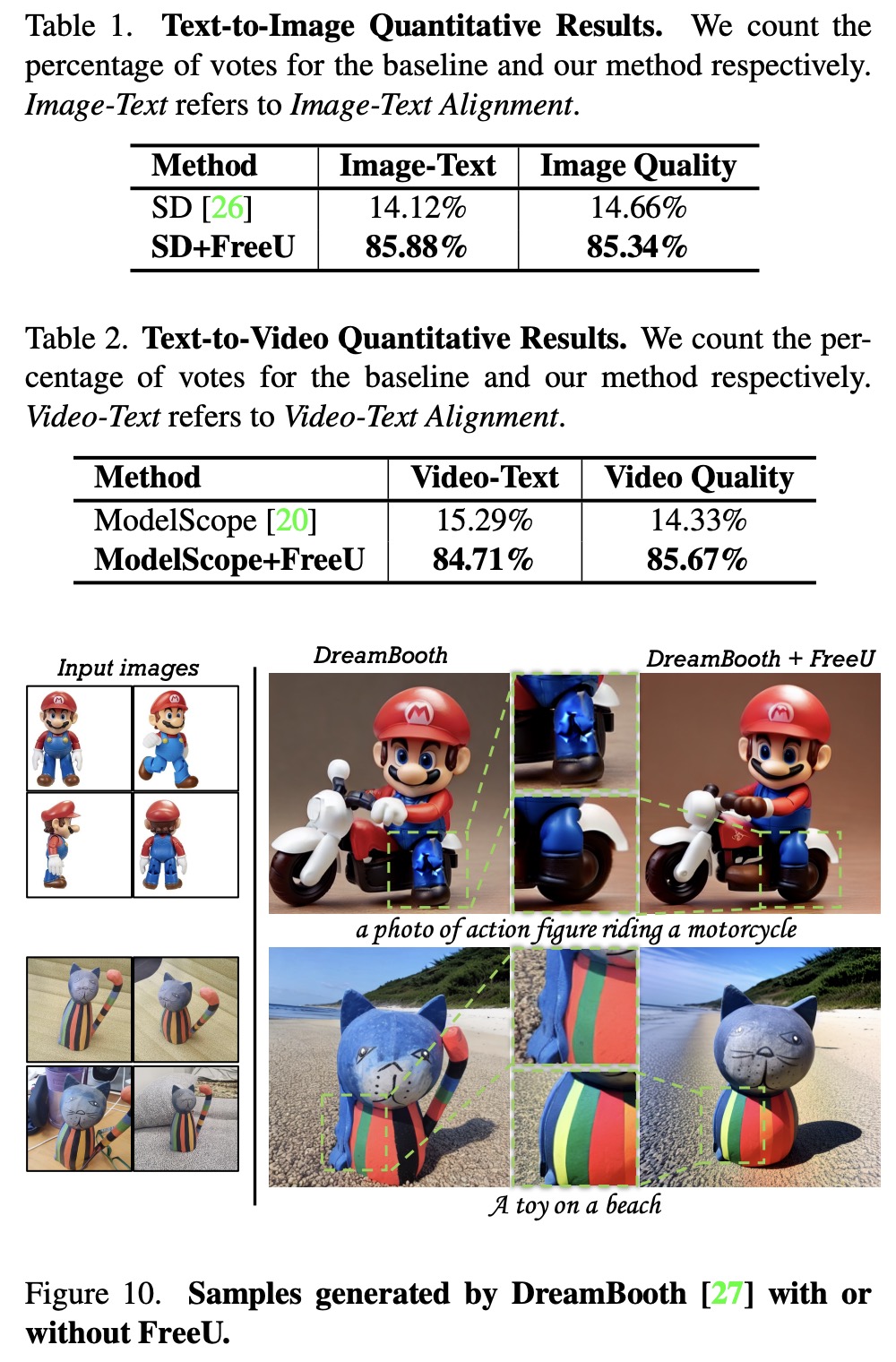


Stable Diffusion (for text-to-image) and ModelScope (for text-to-video) were considerably improved by integrating FreeU, which was confirmed by a quantitative study with 35 participants.
Downstream tasks:
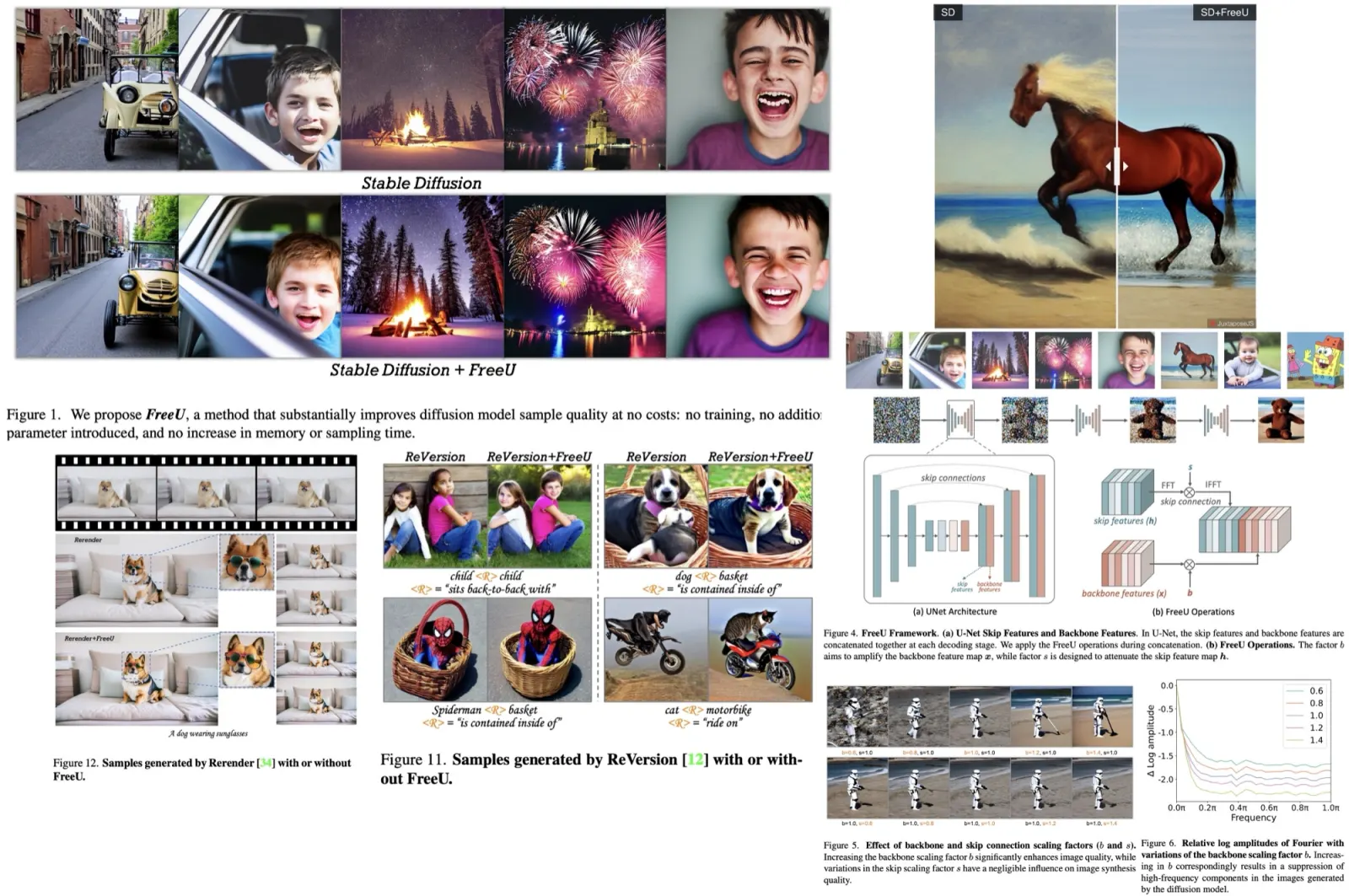
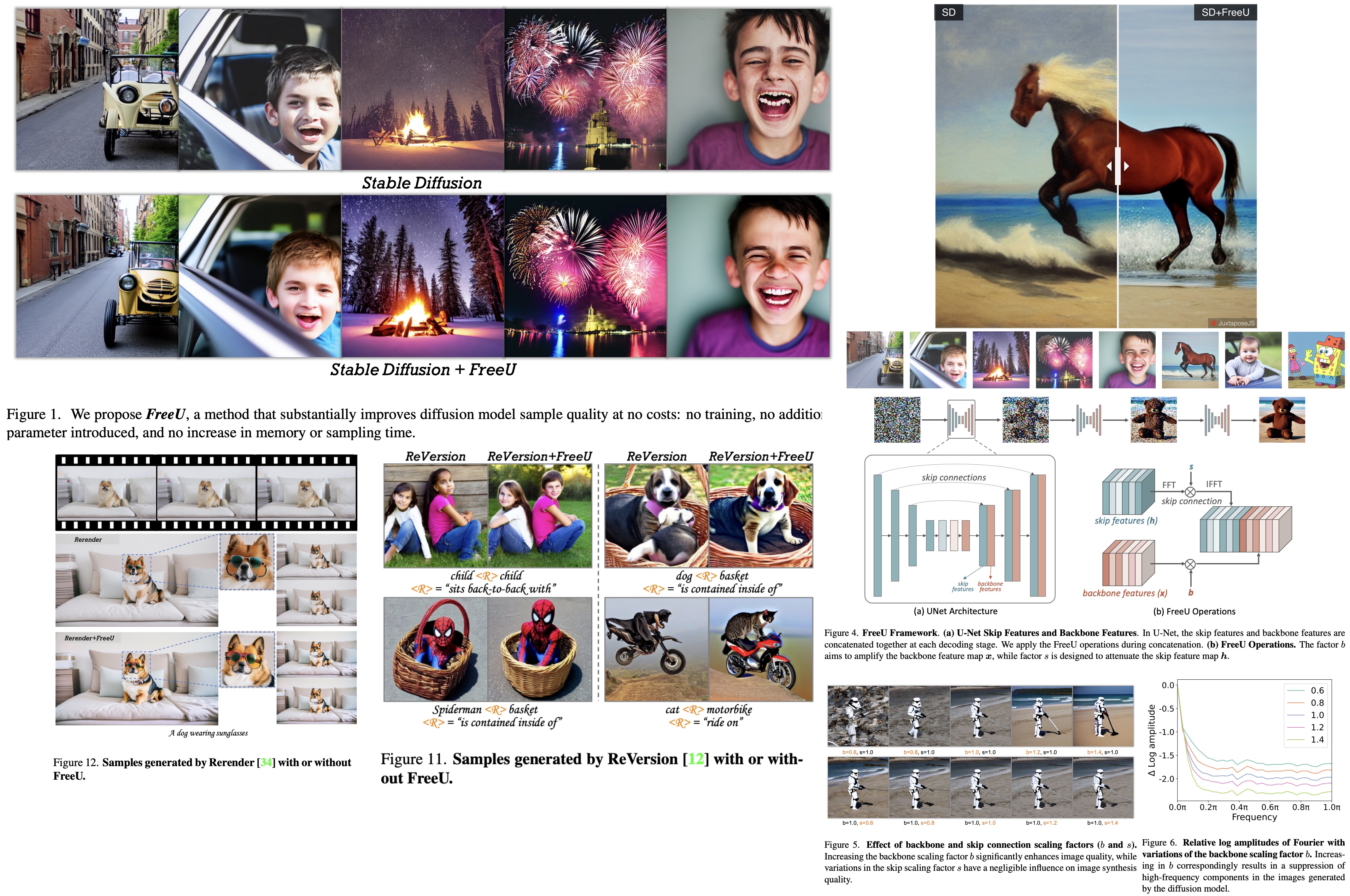
- When incorporated into Dreambooth, a model specialized in personalized text-to-image tasks, FreeU improves realism and refines imperfections in the synthesized images, enhancing the model’s ability to accurately represent prompts, such as action figures and toys in specific scenarios.
- FreeU’s integration into ReVersion, a Stable Diffusion-based relation inversion method, increases its ability to represent relationships accurately and eliminates artifacts in the synthesized content, enhancing both entity and relation synthesis quality. It helps illustrate the relation concepts more precisely, overcoming Stable Diffusion’s limitations due to high-frequency noises.
- FreeU’s incorporation into Rerender, a model for zero-shot text-guided video-to-video translations, makes clear improvements in the detail and realism of the synthesized videos, successfully eliminating artifacts and refining output for prompts like “A dog wearing sunglasses”.