Paper Review: Funnel Activation for Visual Recognition
Code link PyTorch
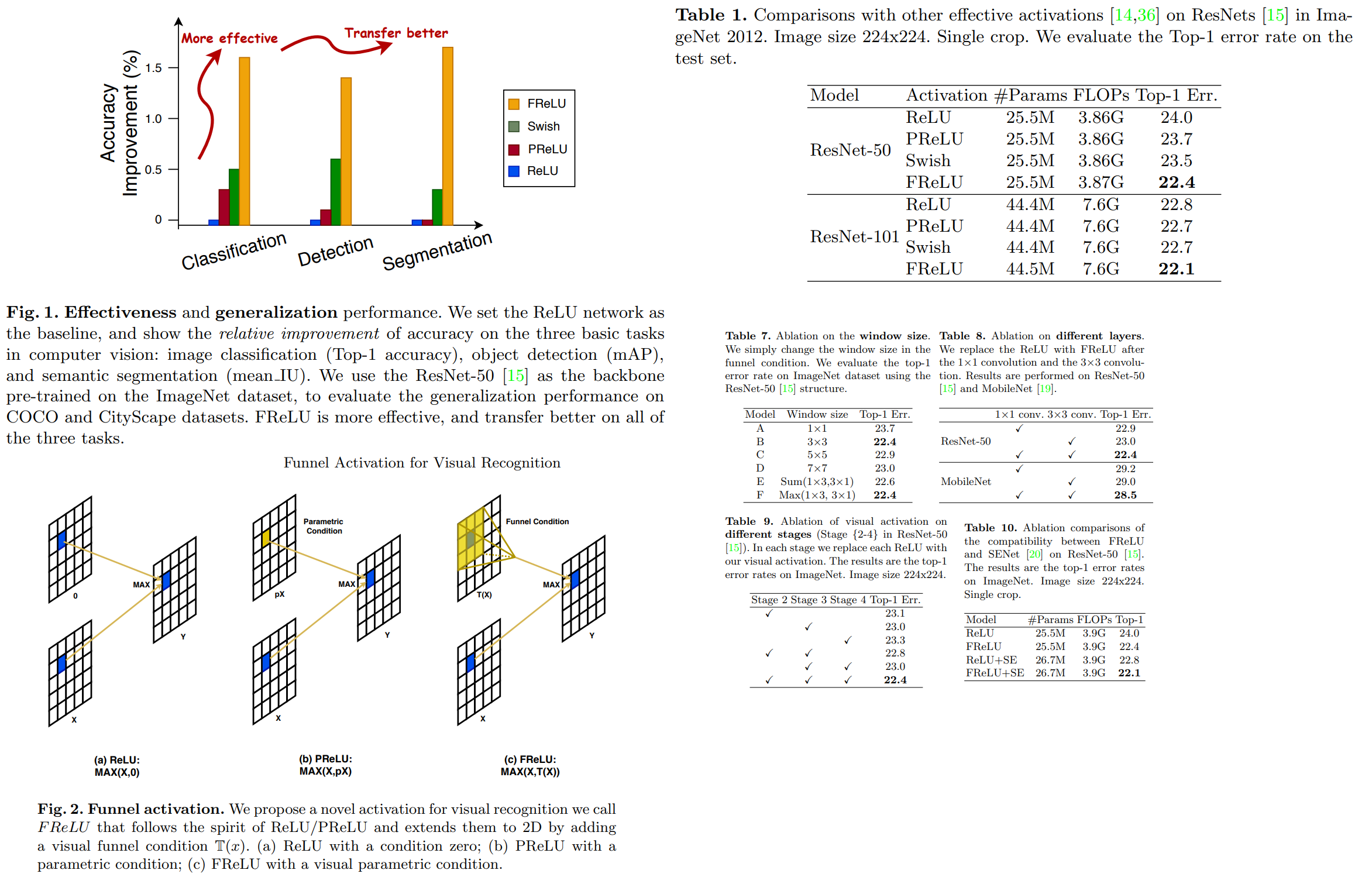
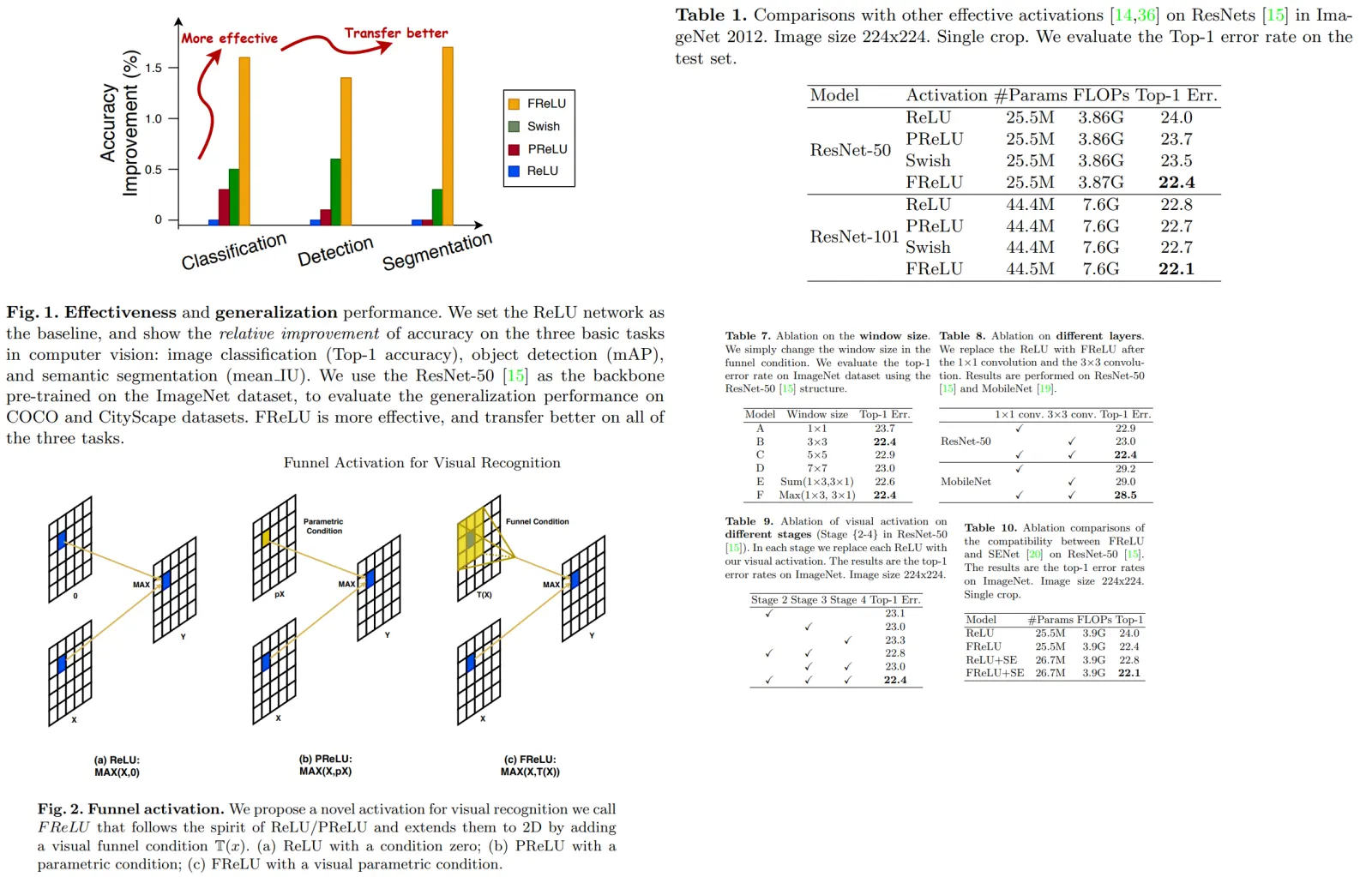
Authors offer a new activation function - a combination of Conv2D and ReLU.
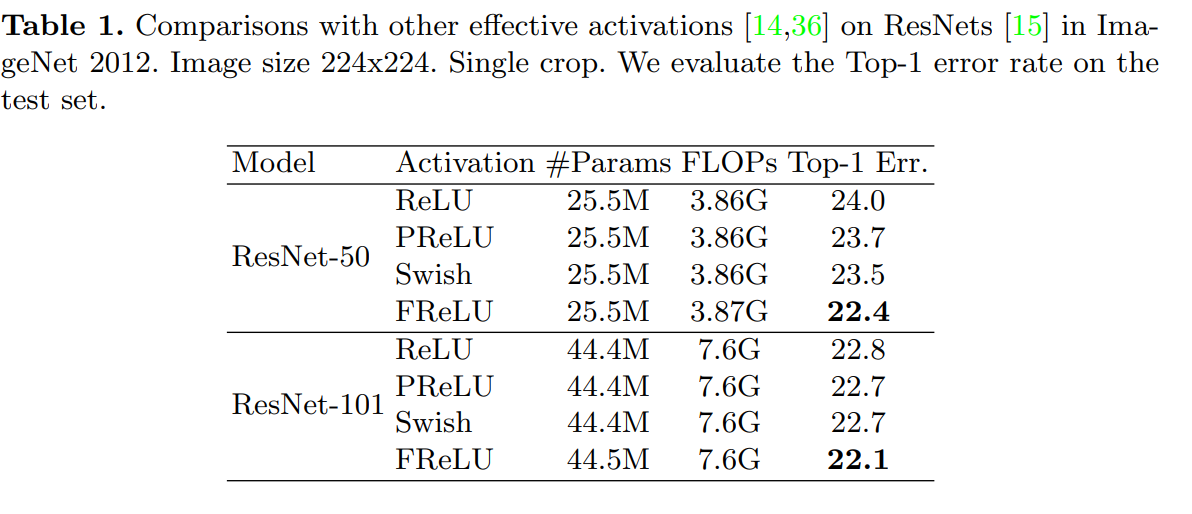
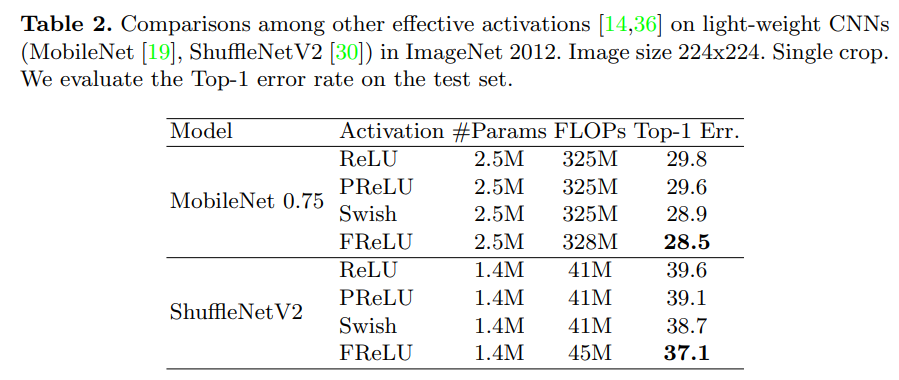
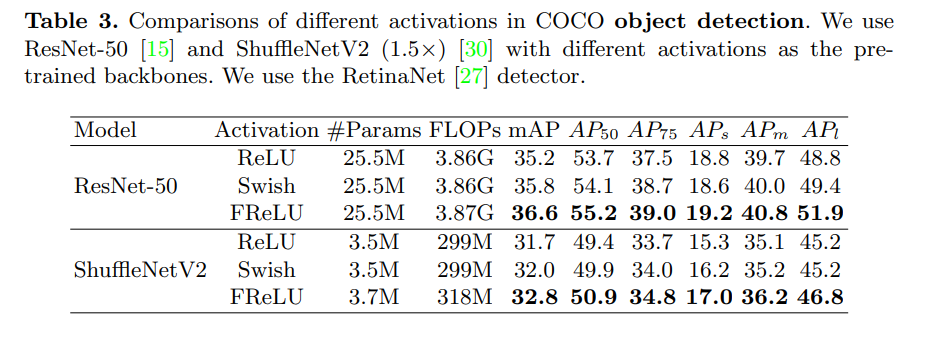
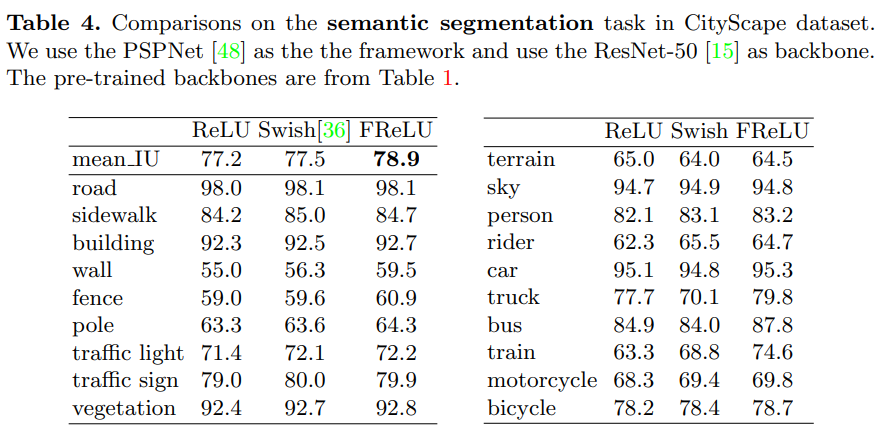
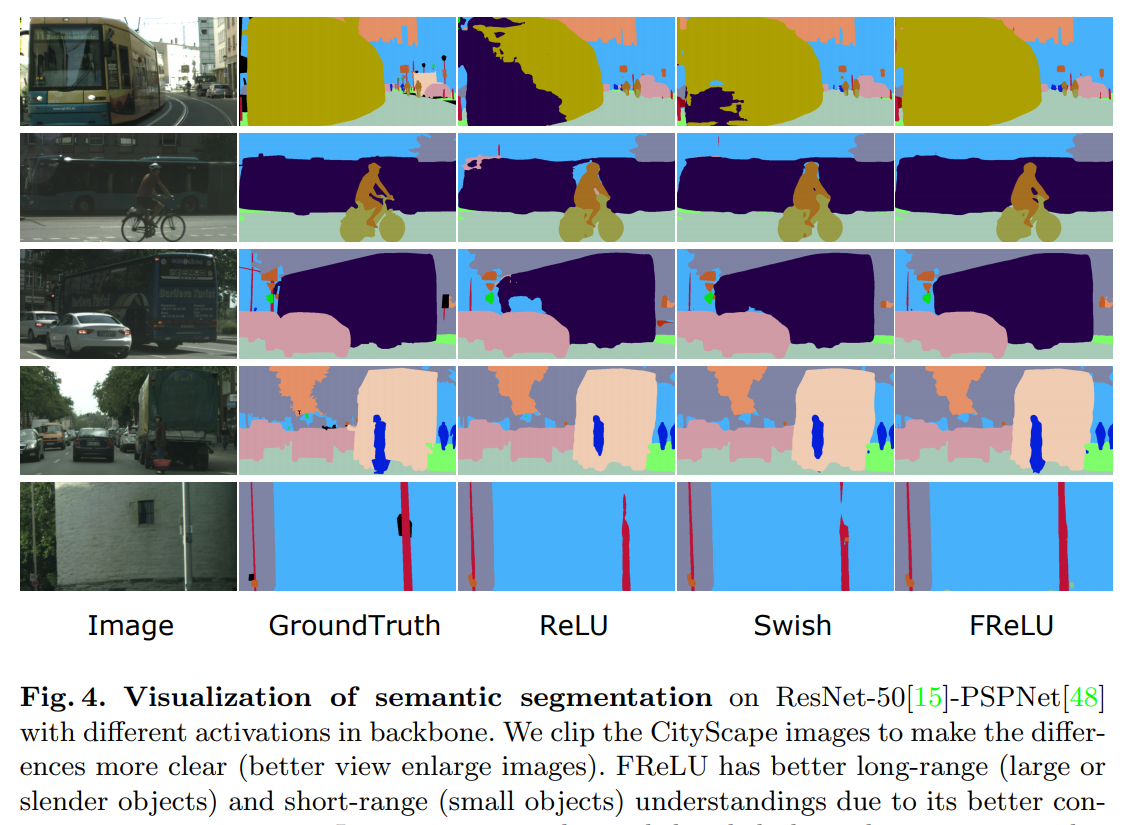
Extensive experiments on COCO, ImageNet, and CityScape show significant improvement.
Personally, I’m not sure whether the improvement is good by itself, or it is mostly due to an additional convolutional layer.
To me, this sounds like “ We have heard you like convolutions and activations, so we put convolution in your activation, so you could convolve while activating”!
import megengine.functional as F
import megengine.module as M
class FReLU(M.Module):
"""
FReLU formulation. The funnel condition has
a window size of kxk. (k=3 by default)
"""
def __init__(self, in_channels):
super().__init__()
self.conv_frelu = M.Conv2d(in_channels,
in_channels,
3,
1,
1,
groups=in_channels)
self.bn_frelu = M.BatchNorm2d(in_channels)
def forward(self, x):
x1 = self.conv_frelu(x)
x1 = self.bn_frelu(x1)
x = F.maximum(x, x1)
return x
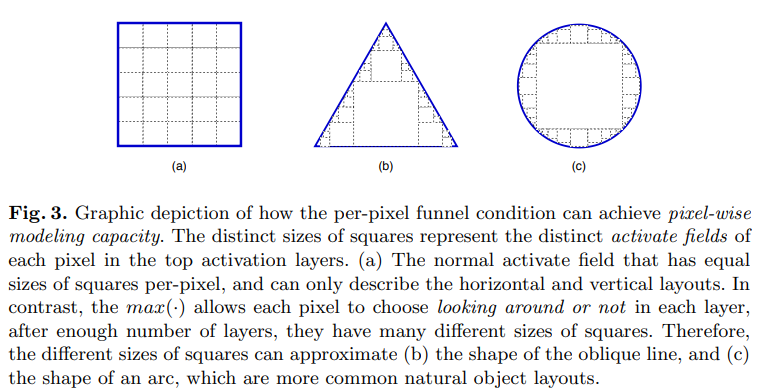
The main idea is that this activation function looks not simply on a value of a certain pixel, but also on the pixels around it. Considering its parameters are trainable, it can “choose” to use other pixels or not, thus using spatial information.

Training
224x224 images. ReLU are replaced with FReLU in all stages except the last in ResNet. Batch 256, 600k iterations, learning rate 0.1 with linear decay schedule. Weight decay 1e-4 and dropout 0.1