Paper Review: Generating Furry Cars: Disentangling Object Shape and Appearance across Multiple Domains

Let’s talk about furries!
I mean: this is an exciting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don’t exist in a single domain. The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
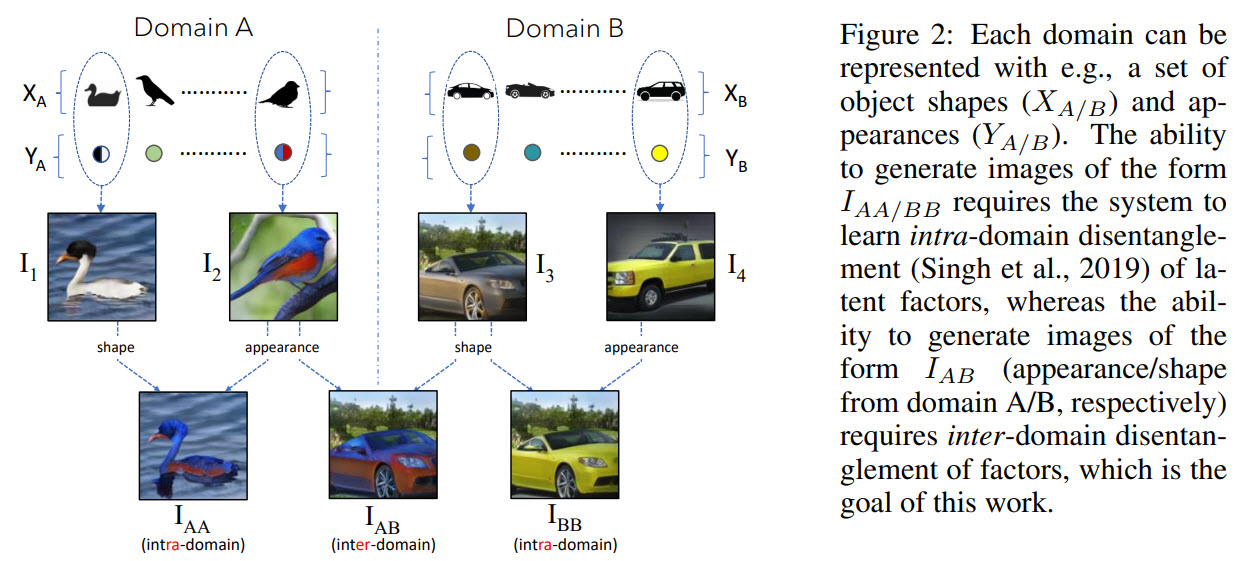
There were works disentangling representations of the share and appearance, but they were usually intra-domain - for example, combining a sparrow’s appearance with a duck’s shape (domain of birds).
The main challenge of combining shapes and appearances from different domains is that there won’t be ground-truth for this in our dataset - so the model will penalize such images while training.
FineGAN
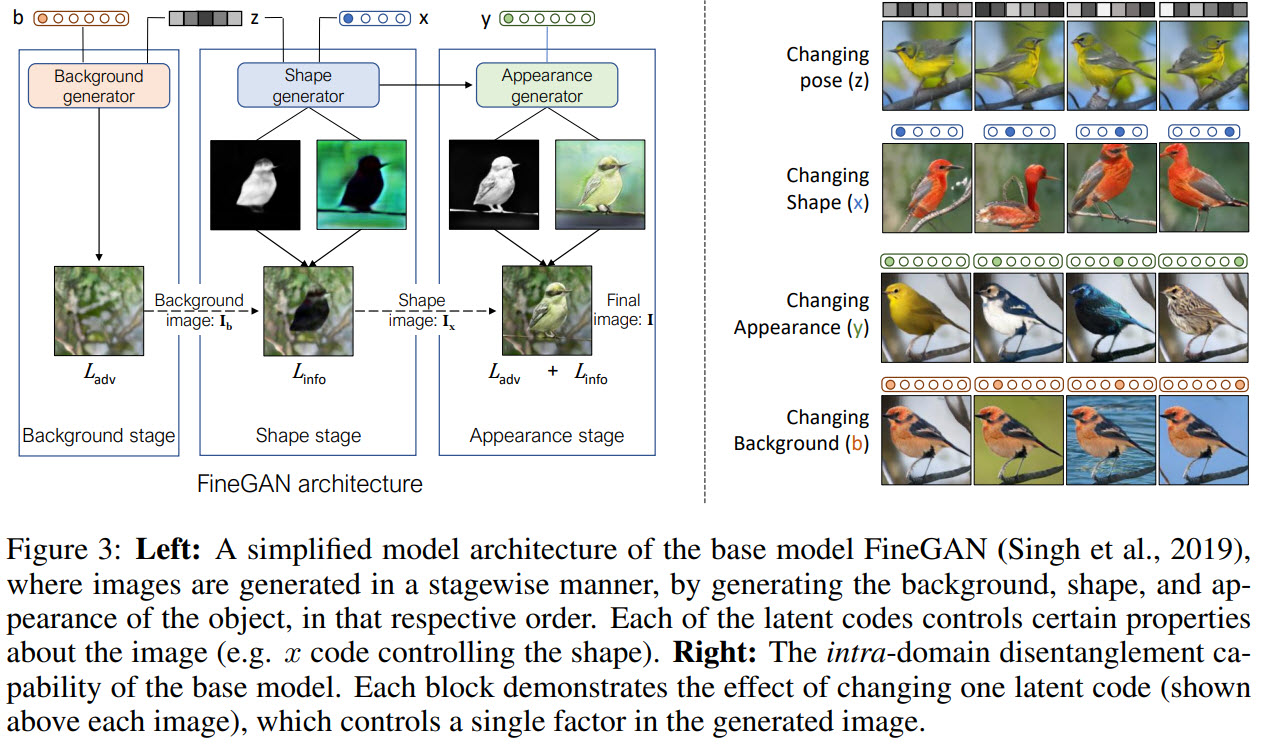
The base model is FineGAN; its main ideas are:
- 4 latent variables as input: noise vector and one-hot vectors for shapes, appearances, and backgrounds;
- the model generates images in several stages: generate background, draw a silhouette of the shape on the background, generate texture/details inside it;
- the model requires bounding boxes around the objects as an input;
- the model learns constraints: it pairs appearances with shapes, so that, for example, duck shapes are associated with duck appearances, sparrow shapes are associates with sparrow appearances, and so on;
Combining factors from multiple domains
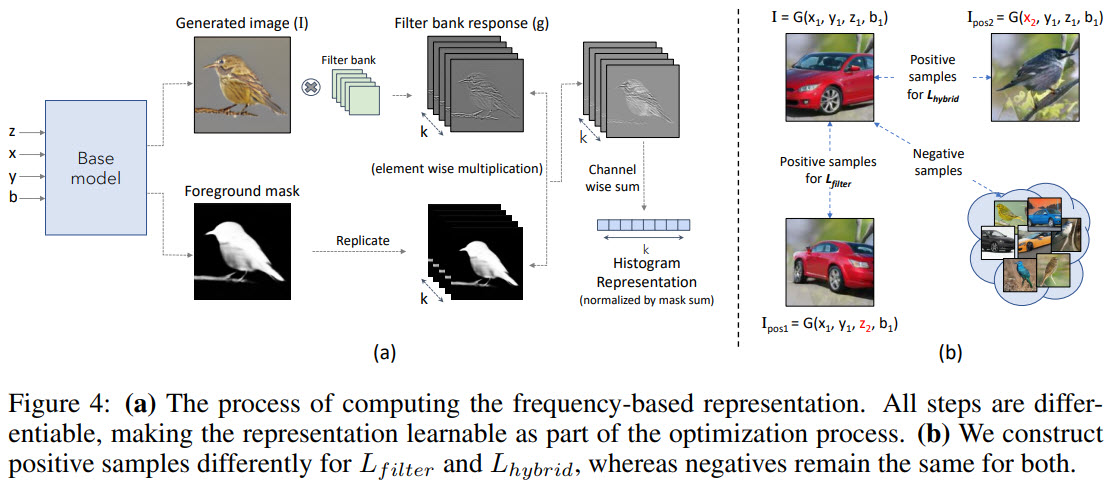
As it was already said: if we generate images with shapes and appearances from different domains, the new images would have a different distribution than the training data and would be penalized.
The authors suggest the following:
- represent the low-level visual concepts (color/texture) using a set of learnable convolutional filters. This representation approximates the frequency of visual concepts represented by the set of filters;
- use contrastive learning: positive sample are pair of images that have the same shape, appearance, and background, but different poses; negative samples are all the others;
- conditional generator, that has positive pairs with different shapes and similar appearances and backgrounds
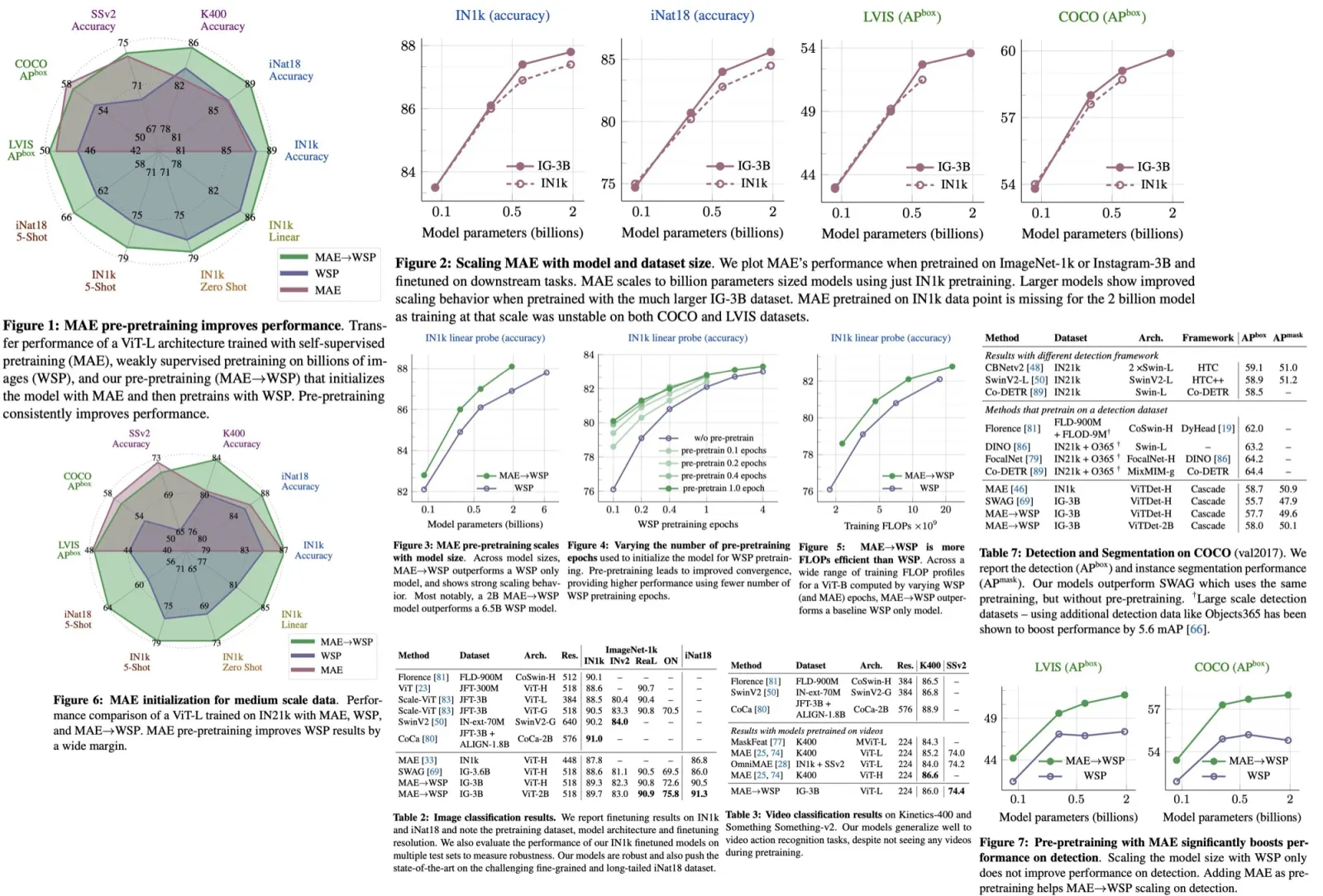
Results

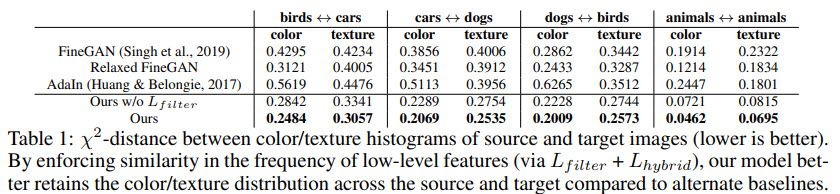
They also show that this approach works better than CycleGAN or some other models:

The authors also talk about limitations:
- the model assumes that there is a hierarchy between shapes and appearances;
- the more domains there are, the longer is training (as there are more combinations)