Paper Review: Giraffe: Adventures in Expanding Context Lengths in LLMs
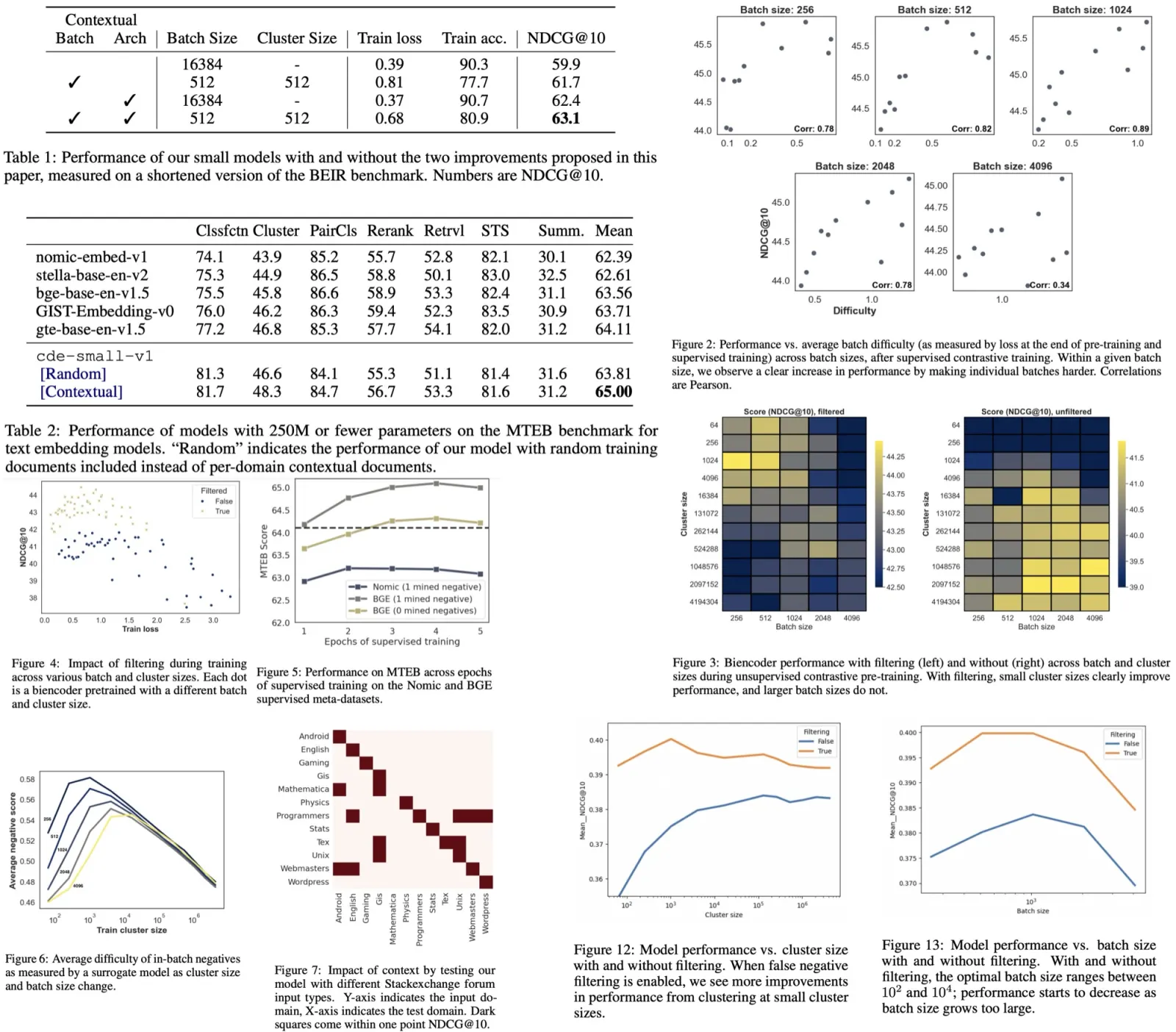
Modern LLMs with attention mechanisms have a fixed context length, limiting the length of input sequences they can process. To handle longer sequences, researchers are exploring various context length extrapolation methods, mainly focusing on adjusting positional encodings in the attention mechanism. The paper experiments existing methods on LLaMA and LLaMA 2 models and introduces the new design, specifically a novel truncation strategy for position encoding. Three new evaluation tasks (FreeFormQA, AlteredNumericQA, LongChat-Lines) and perplexity were used for testing.
The results reveal that linear scaling is the most effective method for context extension, with longer scales at evaluation improving performance. The truncated basis also shows potential. To aid further research, three new long-context models named Giraffe with contexts of 4k, 16k, and 32k were released, built on the LLaMA-13B and LLaMA2-13B bases.
Assessing Long Context Extrapolation

While perplexity is commonly used to evaluate models, it is found to be coarse-grained for assessing how LLMs utilize longer contexts. The authors argue that a model can achieve satisfactory perplexity scores even if it mainly attends to a limited portion of the context. Therefore, the research focuses on more accurate metrics by examining a model’s accuracy when provided with verifiable answers.
Two evaluation tasks are used:
- Key-Value Retrieval Tasks: The authors use the LongChat-Lines task, a fine-grained key-value retrieval method, to determine how well the model memorizes and retrieves data. The task provides the model with a sequence of lines and prompts it to recall specific lines’ values. The paper introduces versions of this task with longer context lengths than previous ones.
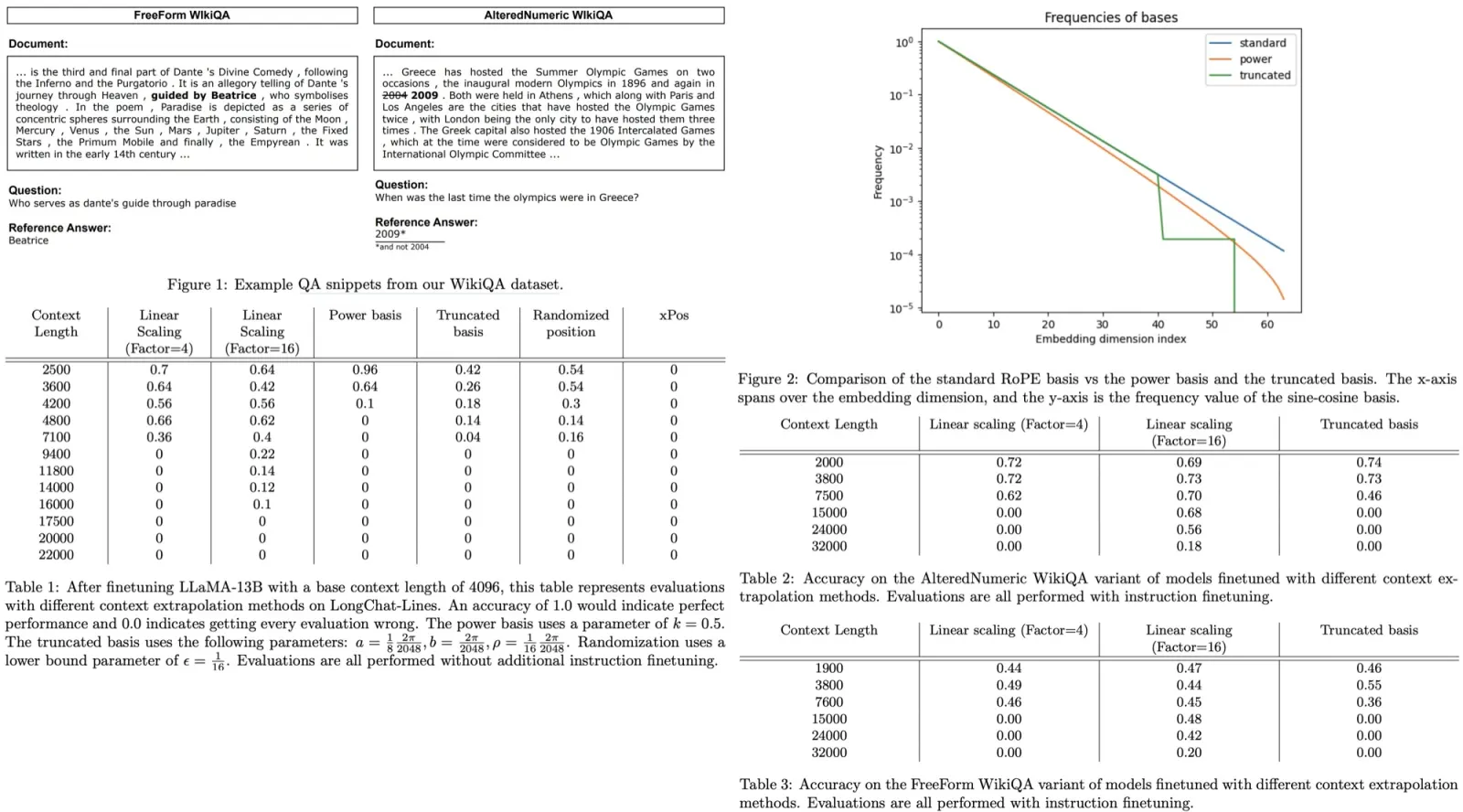
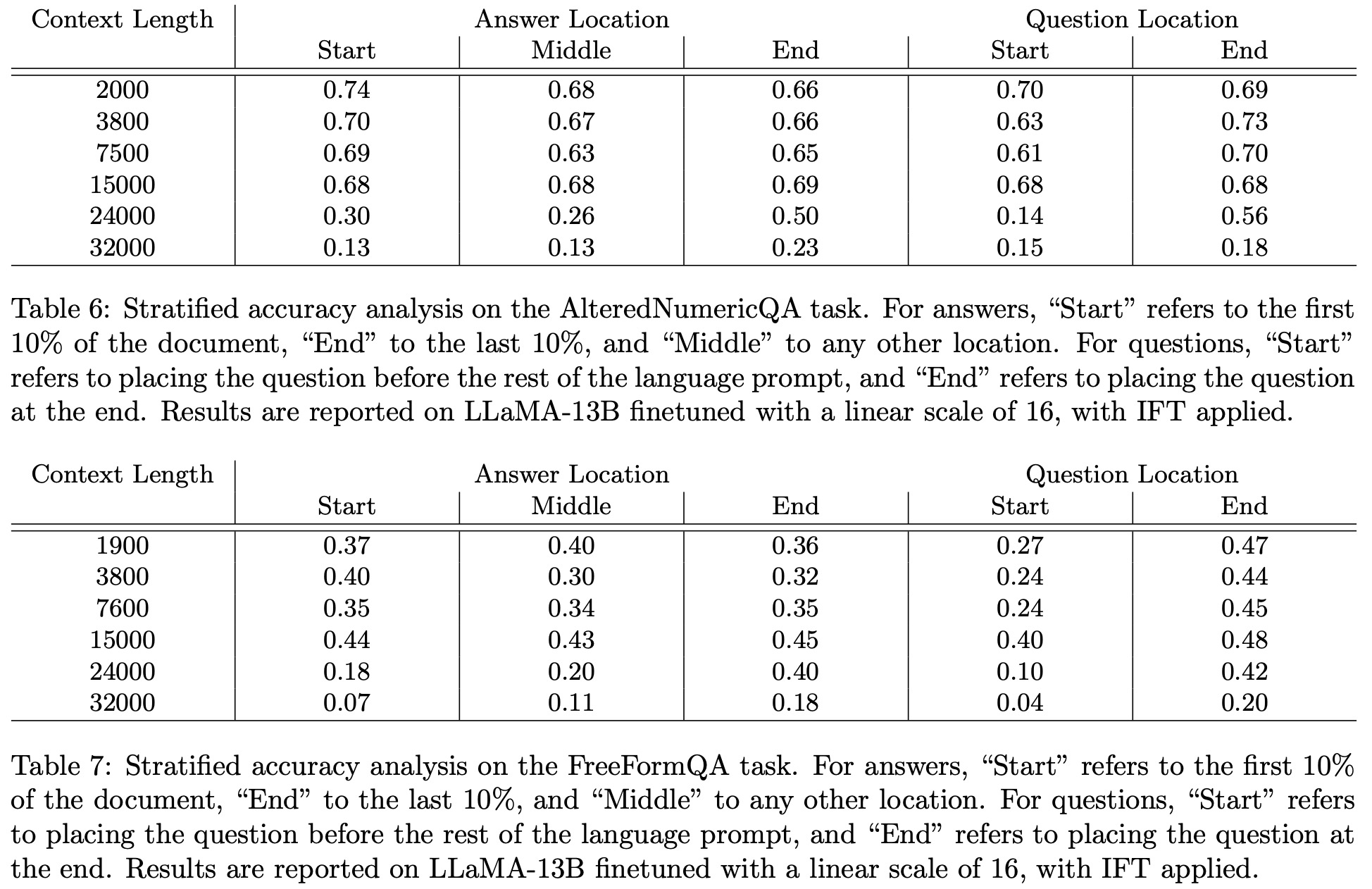
- Question Answering Tasks: The authors use a dataset called WikiQA, derived from the Natural Questions dataset. The LLM is presented with a Wikipedia article followed by a related question. The model’s objective is to locate a concise answer in the article. To ensure that the model relies on the provided context, an “altered” version of the dataset, named Altered Numeric QA (AltQA), was created. In AltQA, numeric answers in the article and questions are changed. For years, a random value within +/- 10 of the original value is used, while for other numbers, a random number with the same digit count is chosen.
The authors pay special attention to the answer’s location within the context and whether it impacts the model’s ability to respond correctly. Analyses are conducted based on the placement of the answer in the document (e.g., beginning 10%, last 10%) and the position of the question (beginning or end of the prompt).
Context Length Extrapolation Techniques
Existing Context Length Extrapolation Techniques:
- Linear Scaling/Positional Interpolation: In this method, the position vector is divided by a scaling factor. For example, if the original range was [0, 1, …, 2048], the new model will see [0/x, 1/x, …, 2048/x], where x is the scaling factor.
- xPos: xPos has a unique way of transforming keys and queries (scaling the key by numeric values with large exponents, which are later canceled with the query in the dot product) but is sensitive to floating-point precision. For long contexts, large numeric values can exceed the float16 capacity, so float32 was used, doubling the training time.
- Randomized Position Encodings: The position values are randomized uniformly within a specific range, instead of having fixed intervals. This is thought to help the model generalize better during evaluation by exposing it to varied intra-position distances during fine-tuning. An upper bound is set to maintain an expected final position similar to the original one, and a positive, non-zero lower bound is set to avoid issues related to numerical precision.
Newly Proposed Context Length Extrapolation Techniques:
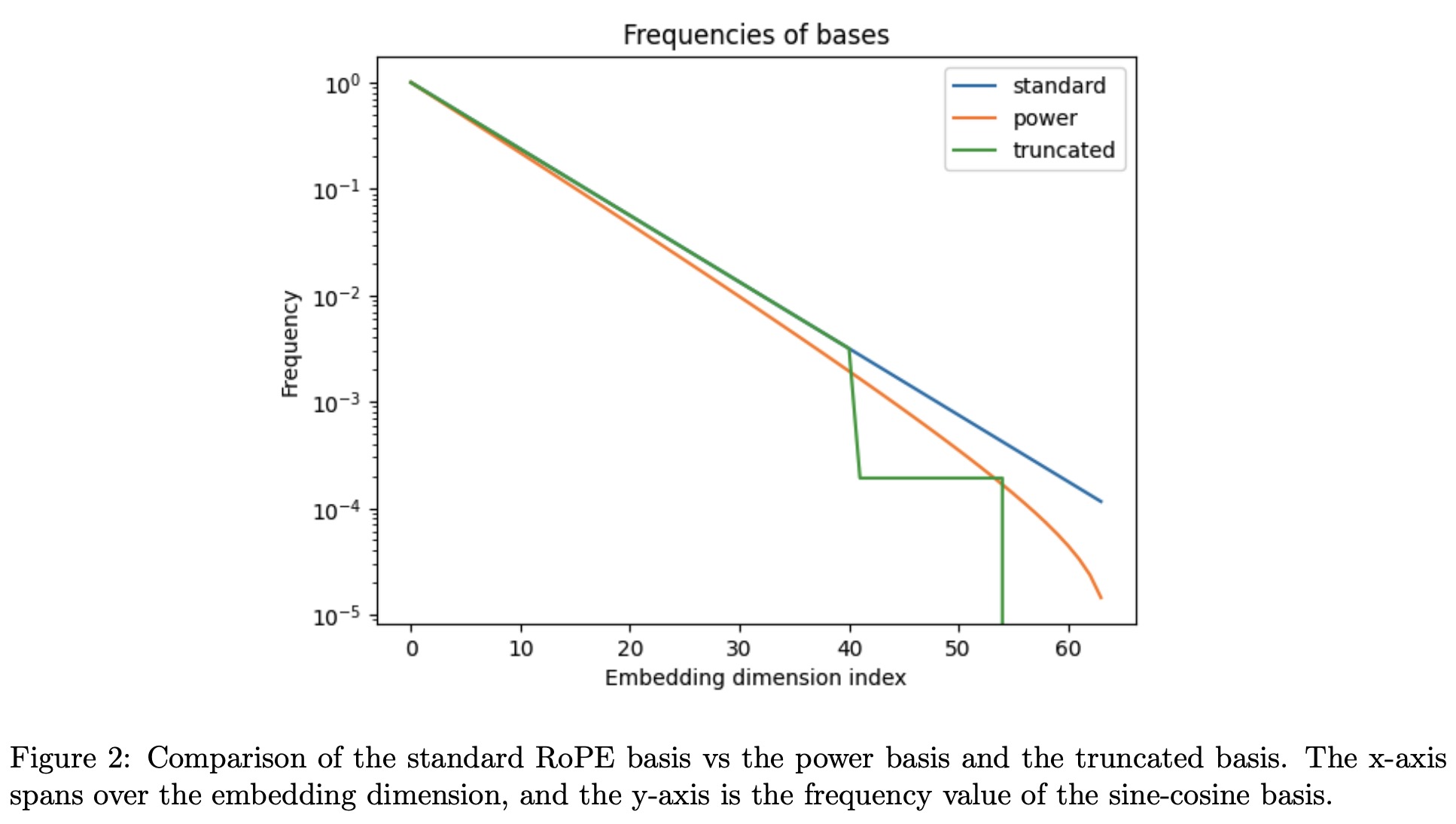
- Power Scaling: In this approach, the standard basis used in Rotary Positional Encoding is modified by applying a transformation controlled by a parameter k. This alteration mainly affects the low-frequency components, making them even lower in frequency. The intention is to reduce the complexity of extrapolation for these low frequencies, where the model hasn’t seen the full range during training. However, the model could rely on specific frequency relationships that a nonlinear transformation might disrupt.
- Truncated Basis: Another modification starts with the original RoPE basis and introduces two cutoff values and a fixed value. The aim is to preserve high-frequency components while setting low-frequency elements to a constant value, in this case, 0. This is expected to help the model generalize better to larger context lengths. The model is also equipped with a fixed frequency to help it distinguish between distances that span its entire training context.
Results
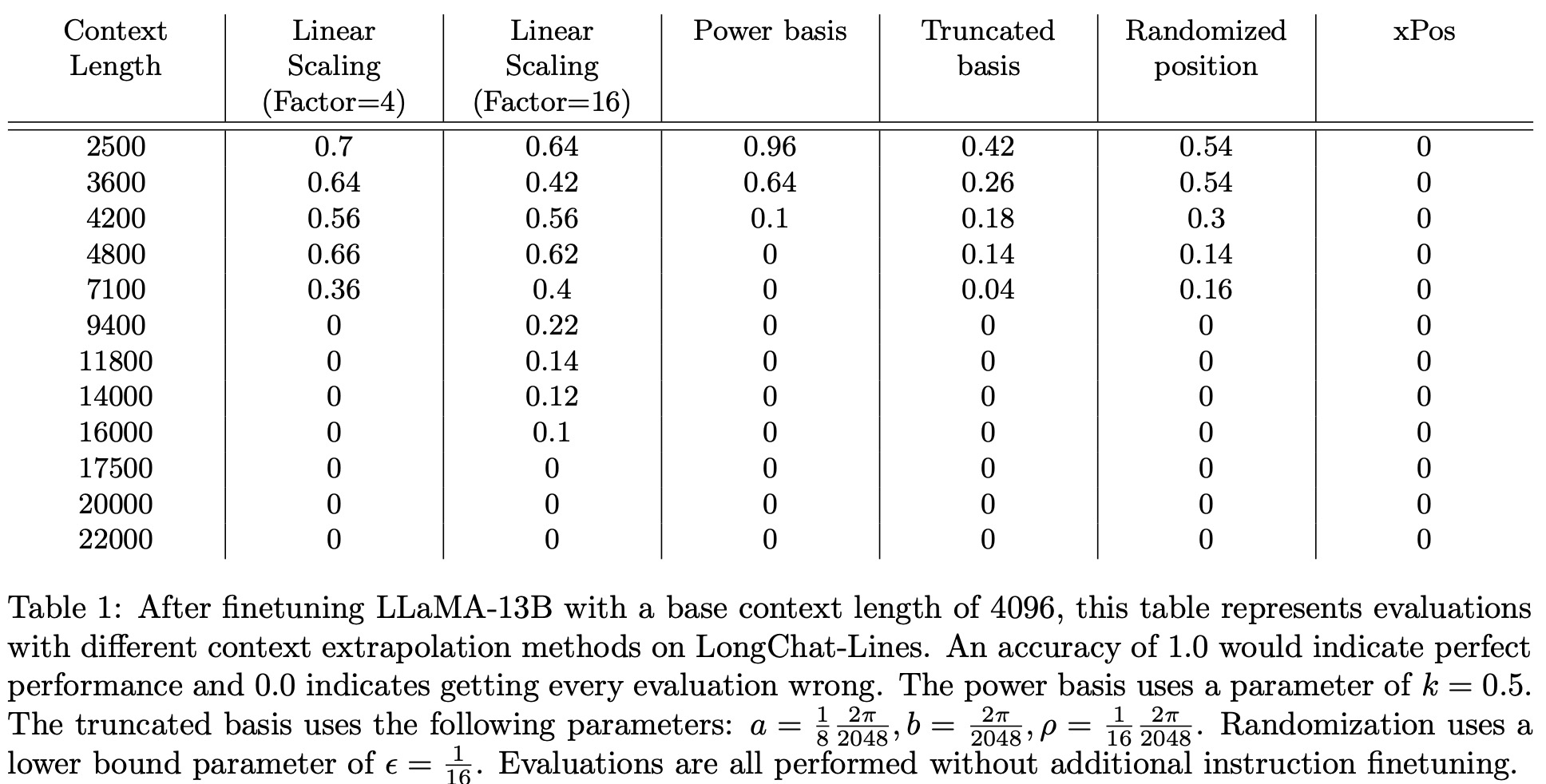
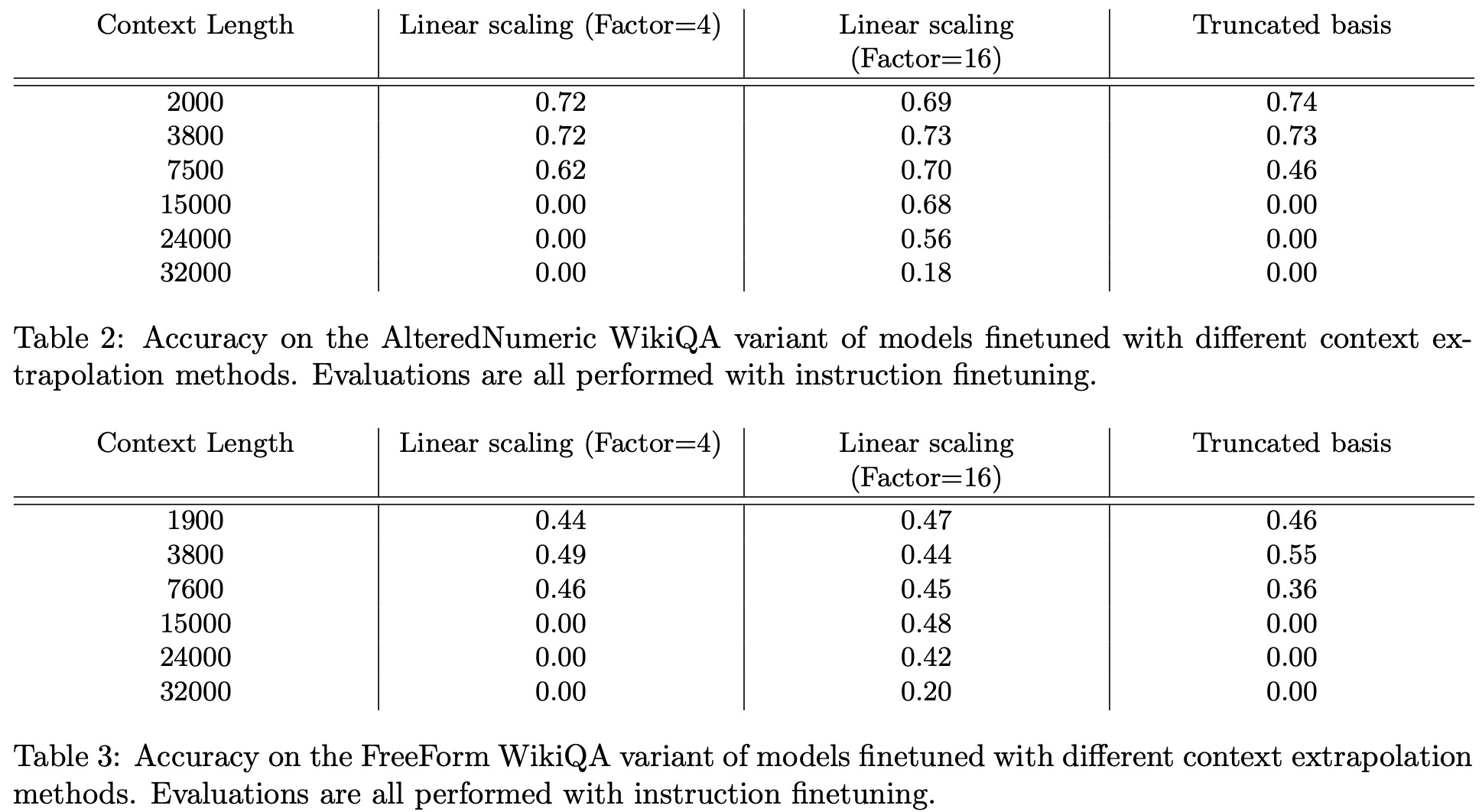
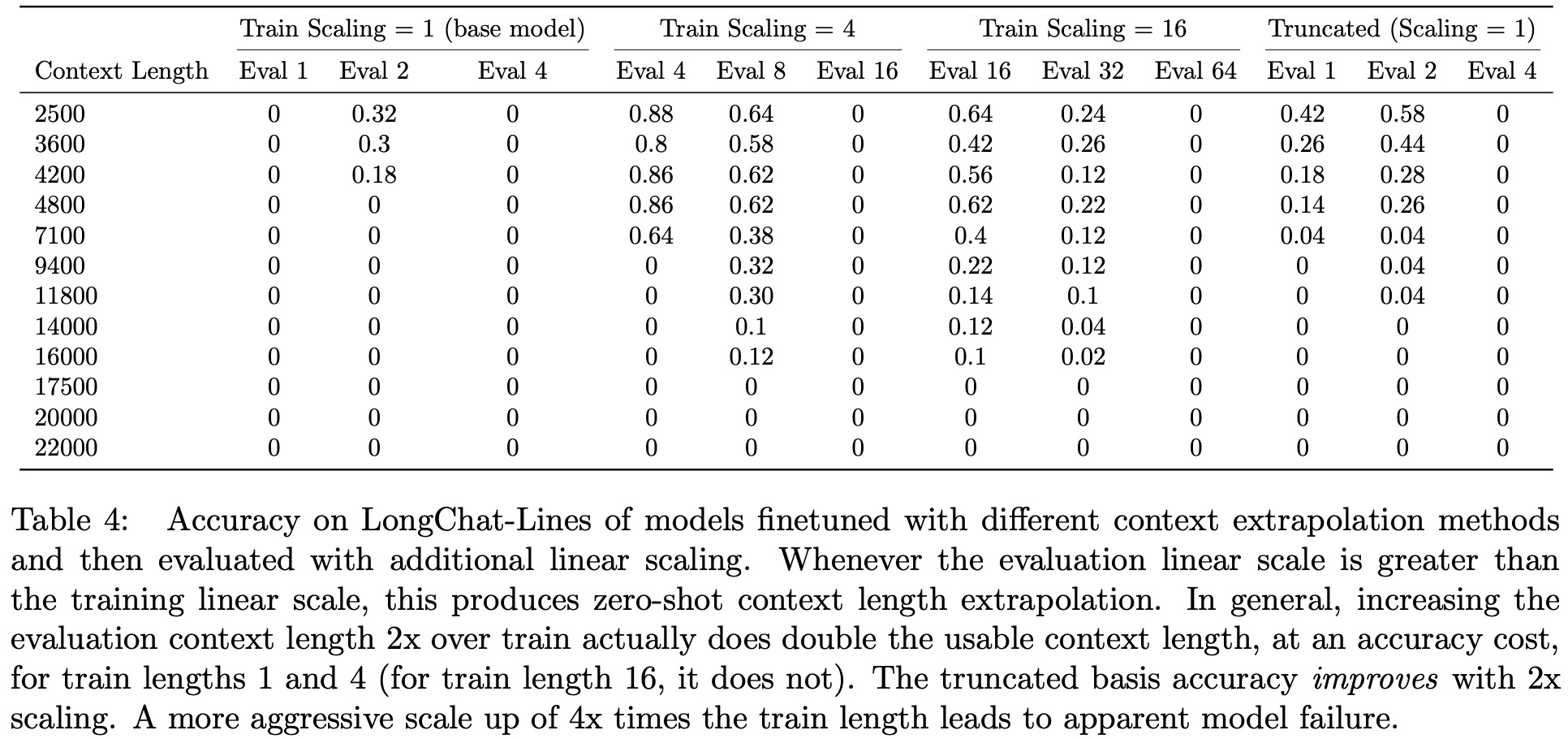
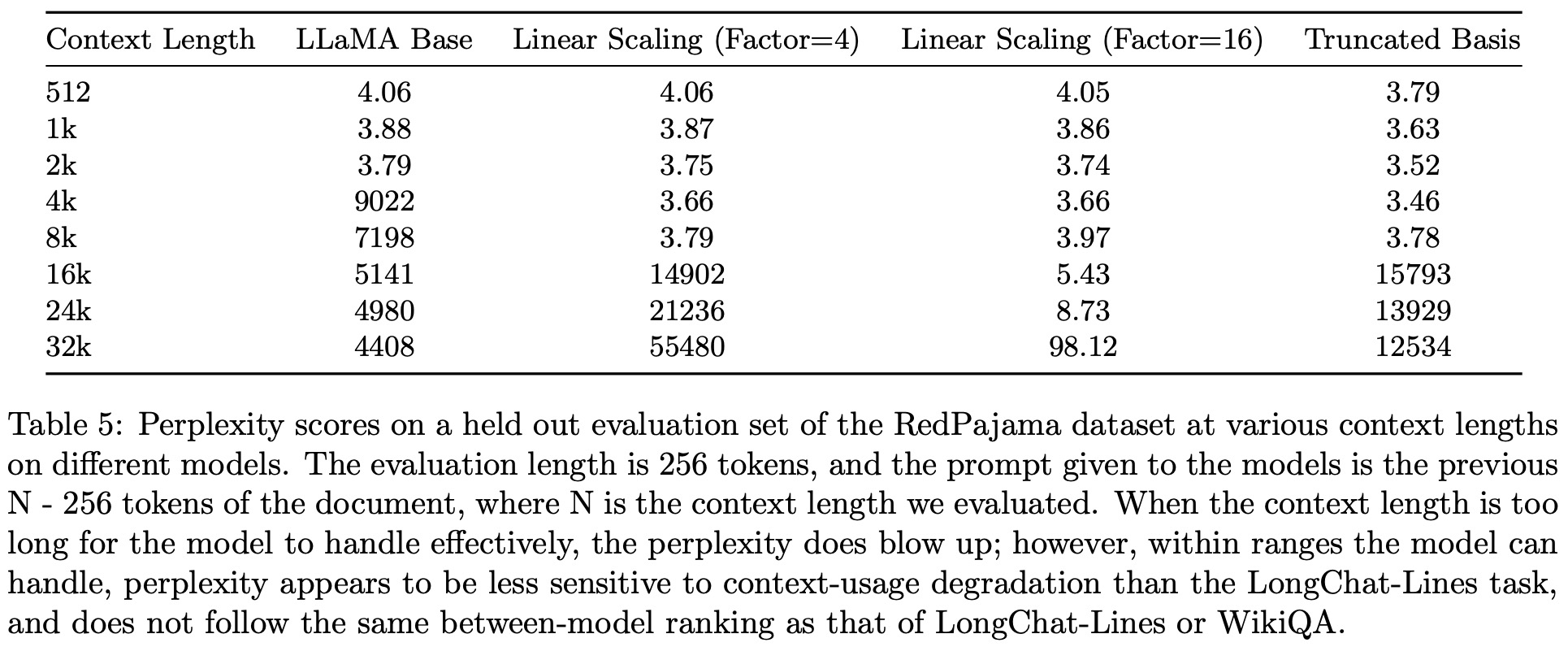
The base model used for these experiments is LLaMA-13B, and it is finetuned on a modified RedPajama dataset with fixed token sizes of 4096. The model was further fine-tuned using the Vicuna dataset and LoRA.
Finetuned Context Length Extrapolation:
- xPos failed to adapt during fine-tuning and was unable to perform tasks at all. This was attributed to its sensitivity to numerical precision and its fundamental difference from the Rotary Positional Encoding (RoPE) basis.
- Linear Scaling was successful in extending context lengths but showed limitations, particularly with higher scaling factors (like 16). It lost accuracy much quicker than expected.
- Power Basis initially seemed to be promising, it quickly decayed in performance as context length increased, showing no extrapolation performance beyond 4200 tokens.
- Randomized Position seemed to be extrapolating, but this was likely an artifact of the evaluation process. Performance dropped when the upper bound was reduced further.
- Truncated Basis appeared to offer true context length extrapolation but was inferior in performance to linear scaling. Combining truncation with linear scaling seems promising.
Zero-Shot Linear Scaling: The model can handle a scale factor of 2x at evaluation time if trained on a scale factor of x. However, using a scale factor greater than 2x led to the model breaking.
Limitations
- All methods showed a decline in accuracy as context length increased, even though the models continued to produce coherent outputs. Addressing this is crucial for achieving true long-context extrapolation.
- The analysis is based on a single document dataset, and future work could validate these findings on other datasets.
- The focus has been specifically on LLaMA models using RoPE positional encodings. Future work could investigate the applicability of these findings to other models and positional encoding types.
- Questions remain about the limitations of linear interpolation, particularly around the maximum scale factor that can be effectively used.
- Future research could explore how to improve the truncated basis method to potentially match or exceed the performance of linear interpolation.