Paper Review: Goku: Flow Based Video Generative Foundation Models

Goku is a family of joint image-and-video generation models built on rectified flow Transformers. The authors describe how they curate data, design the model architecture and flow formulation, and set up efficient large-scale training. The approach achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks - new SOTA results.
The approach
During training, videos and images are encoded into a latent space using a 3D image-video joint VAE. These latents are grouped into mini-batches containing both image and video data, enabling a unified cross-modal representation. The model then applies rectified flow and processes the latents using Transformer blocks, capturing spatial and temporal dependencies effectively.
Architecture
The Goku Transformer block extends GenTron by combining self-attention for capturing inter-token correlations, cross-attention for textual embeddings, a feed-forward network for projection, and a layer-wise adaLN-Zero block to guide feature transformations with timestamp information. It has the following additional changes:
- Full Attention: Unlike prior methods that separate spatial and temporal attention, Goku applies full attention for better motion modeling, using FlashAttention and sequence parallelism to optimize efficiency.
- Patch n’ Pack: It packs images and videos into a single minibatch, eliminating the need for separate data buckets.
- 3D RoPE Positional Embeddings: Extends RoPE for images/videos, improving adaptability across resolutions and sequence lengths while additionally leading to faster convergence.
- Q-K Normalization: Uses query-key normalization with RMSNorm to prevent loss spikes, ensuring stable training.
Flow-based Training
The Goku model uses a rectified flow algorithm for joint image-and-video generation, improving convergence speed and conceptual clarity. RF transforms samples from a prior distribution (Gaussian noise) to the target data distribution using linear interpolation. Experiments show that RF converges faster than a denoising diffusion model.
Training Details
To effectively handle both image and video generation, Goku uses a three-stage training approach:
- Text-Semantic Pairing: Pretrains on text-to-image tasks to learn visual semantics and concepts.
- Joint Image-and-Video Learning: Expands training to both images and videos, using a unified token sequence approach to enhance video generation quality.
- Modality-Specific Fine-Tuning: Optimizes text-to-image generation for better visual quality and text-to-video generation by improving temporal smoothness, motion continuity, and stability.
During the second stage, the model is trained using a cascade resolution strategy: initially trained on 288x512, then 480x864 and 720x1280.
Goku incorporates an image condition for video generation by using the first frame of each clip as a reference image, then broadcasting its tokens and concatenating them with the noised video tokens along the channel dimension. A single MLP layer handles channel alignment, while the rest of the Goku-T2V architecture remains unchanged.
Infrastructure Optimization
- Goku uses 3D parallelism to distribute computation across sequences, data, and model parameters. Sequence-Parallelism reduces memory usage by slicing sequences and distributing attention computation, while Fully Sharded Data Parallelism partitions parameters, gradients, and optimizer states to balance memory efficiency and communication overhead.
- Activation Checkpointing minimizes memory usage by storing activations only for necessary layers.
- Goku integrates cluster fault tolerance strategies from MegaScale, including self-check diagnostics, multi-level monitoring, and fast recovery mechanisms, ensuring stable large-scale training despite GPU node failures.
- Goku uses ByteCheckpoint for efficient parallel saving and loading of training states, supporting resharding and seamless adaptation to different cluster sizes. Checkpointing an 8B model across thousands of GPUs takes less than four seconds, minimizing disruptions.
Data Curation Pipeline
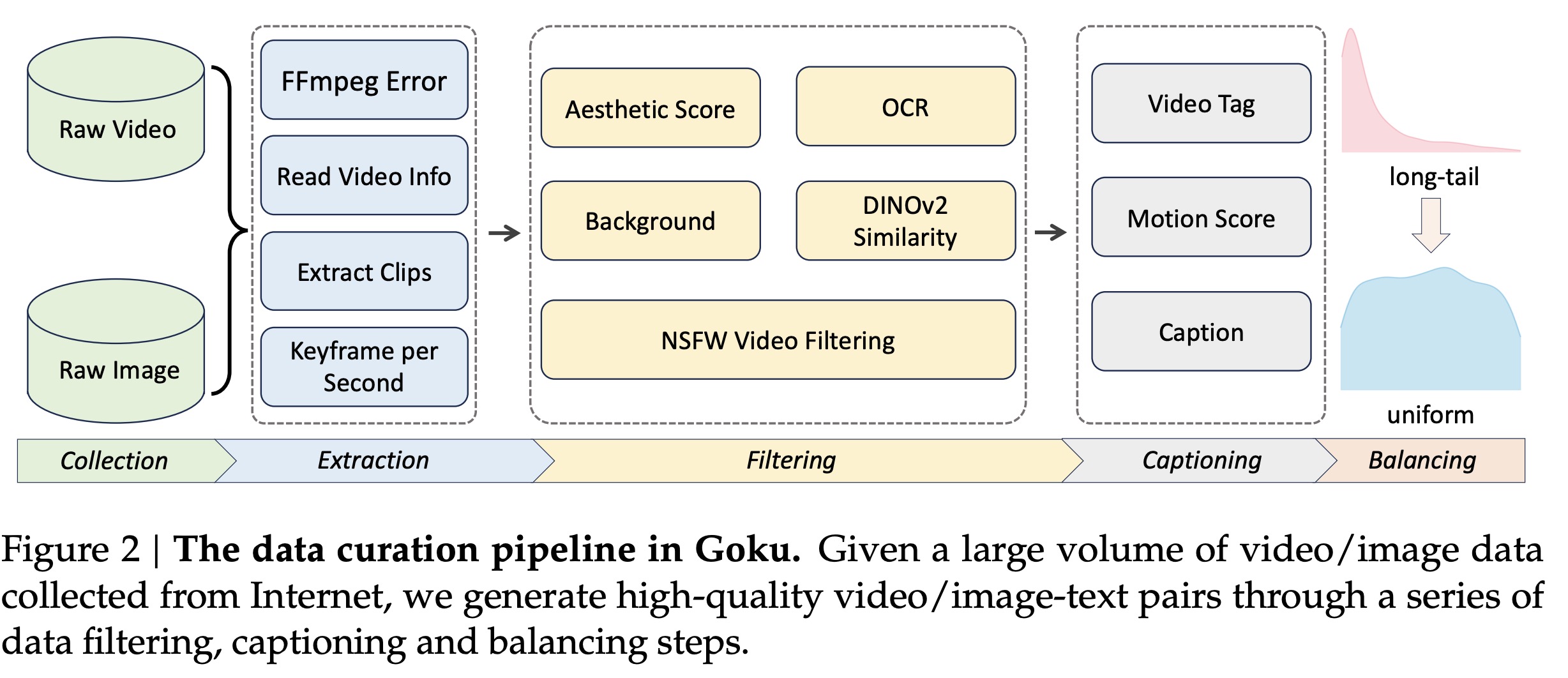
The dataset consists of 160M image-text pairs and 36M video-text pairs.
Data Processing and Filtering
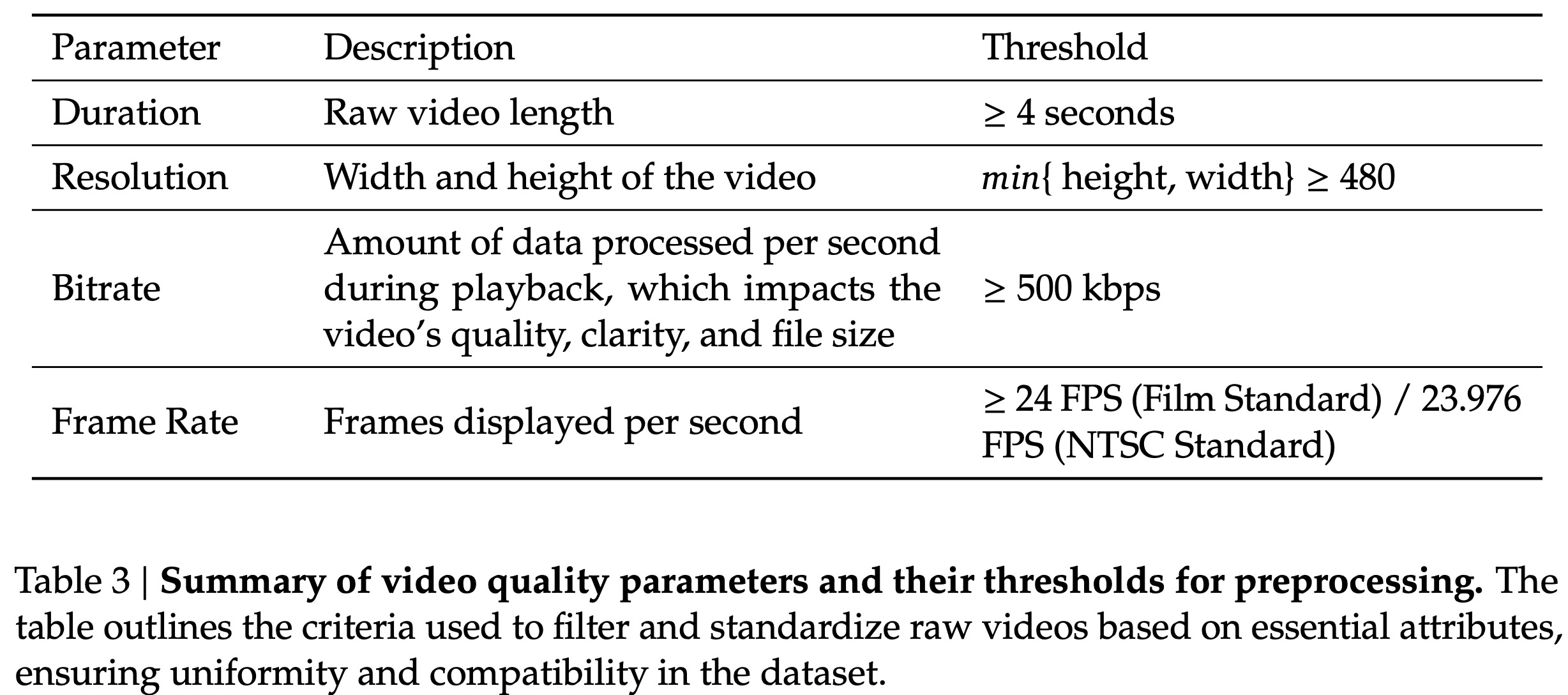
- Video Preprocessing and Standardization: The videos are filtered out using the criteria above and standardized to a consistent coding format H.264.
- Video Clips Extraction: A two-stage clipping method segments videos into meaningful clips: PySceneDetect detects shot boundaries and creates video clips, and DINOv2 refines these clips based on cosine similarity between frames. Clips exceeding 10 seconds are truncated, and perceptual hashing ensures diversity by removing duplicates with lower aesthetic scores.
- Visual Aesthetic Filtering retains only highly photorealistic clips based on an aesthetic score threshold.
- OCR filtering removes clips with excessive text.
- Motion dynamics are assessed using RAFT optical flow, with clips outside an acceptable motion score range being discarded. The motion score is also added to each clip’s metadata to improve motion control.
Captioning
For images, the authors use InternVL2.0 to generate dense captions for each sample. For videos, they start with InternVL2.0 for keyframe captions, followed by Tarsier2 for video-wide descriptions. Tarsier2 inherently recognizes camera motion types, such as zooming or panning, eliminating the need for a separate motion prediction model and simplifying the pipeline compared to previous methods. Qwen2 is then used to merge keyframe and video captions into a unified description, ensuring coherence. Additionally, incorporating motion scores derived from RAFT into captions improves motion control, allowing users to specify different motion dynamics in prompts to guide video generation.
Experiments
Goku achieves state-of-the-art performance in both text-to-image and text-to-video generation across multiple benchmarks.
For text-to-image, Goku-T2I excels in GenEval,T2I-CompBench, and DPG-Bench, outperforming top models like PixArt-α, DALL-E 2/3, and SDXL in text-image alignment and dense prompt following.
For text-to-video, Goku-T2V shows superior performance on UCF-101 and VBench, generating high-fidelity, diverse, and dynamic videos. It achieves state-of-the-art Fréchet Video Distance and excels in human action representation, dynamic motion, and object generation across 16 evaluation dimensions.