Paper Review: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
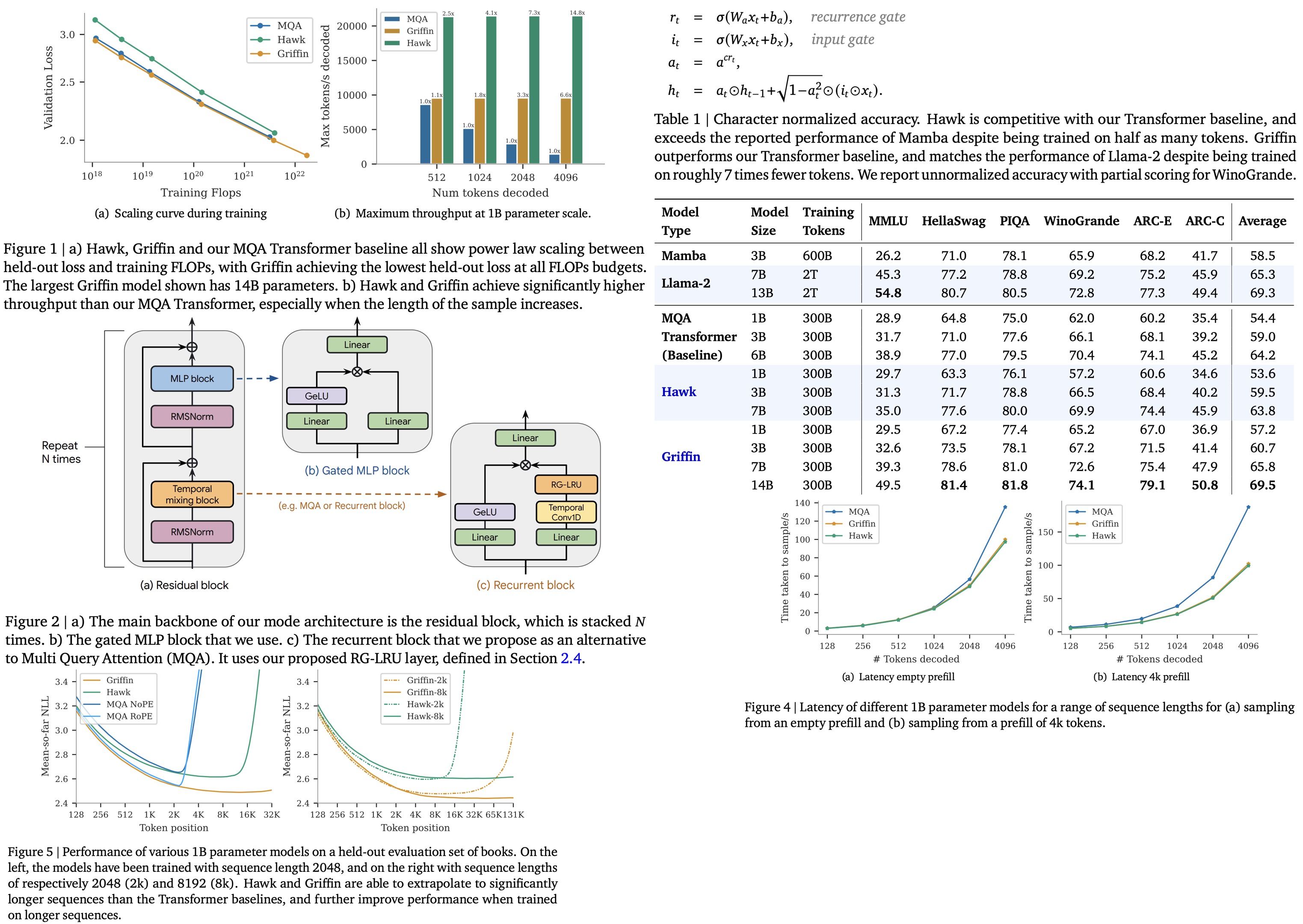
Hawk and Griffin are new RNNs by DeepMind. Hawk surpasses Mamba’s performance using gated linear recurrences, while Griffin, a hybrid combining gated linear recurrences and local attention, matches Llama-2’s performance with significantly less training data. Griffin also excels in processing longer sequences than seen during training. Both models are as hardware efficient as Transformers but offer lower latency and higher throughput during inference. Griffin is scaled to 14 billion parameters.
Model Architecture
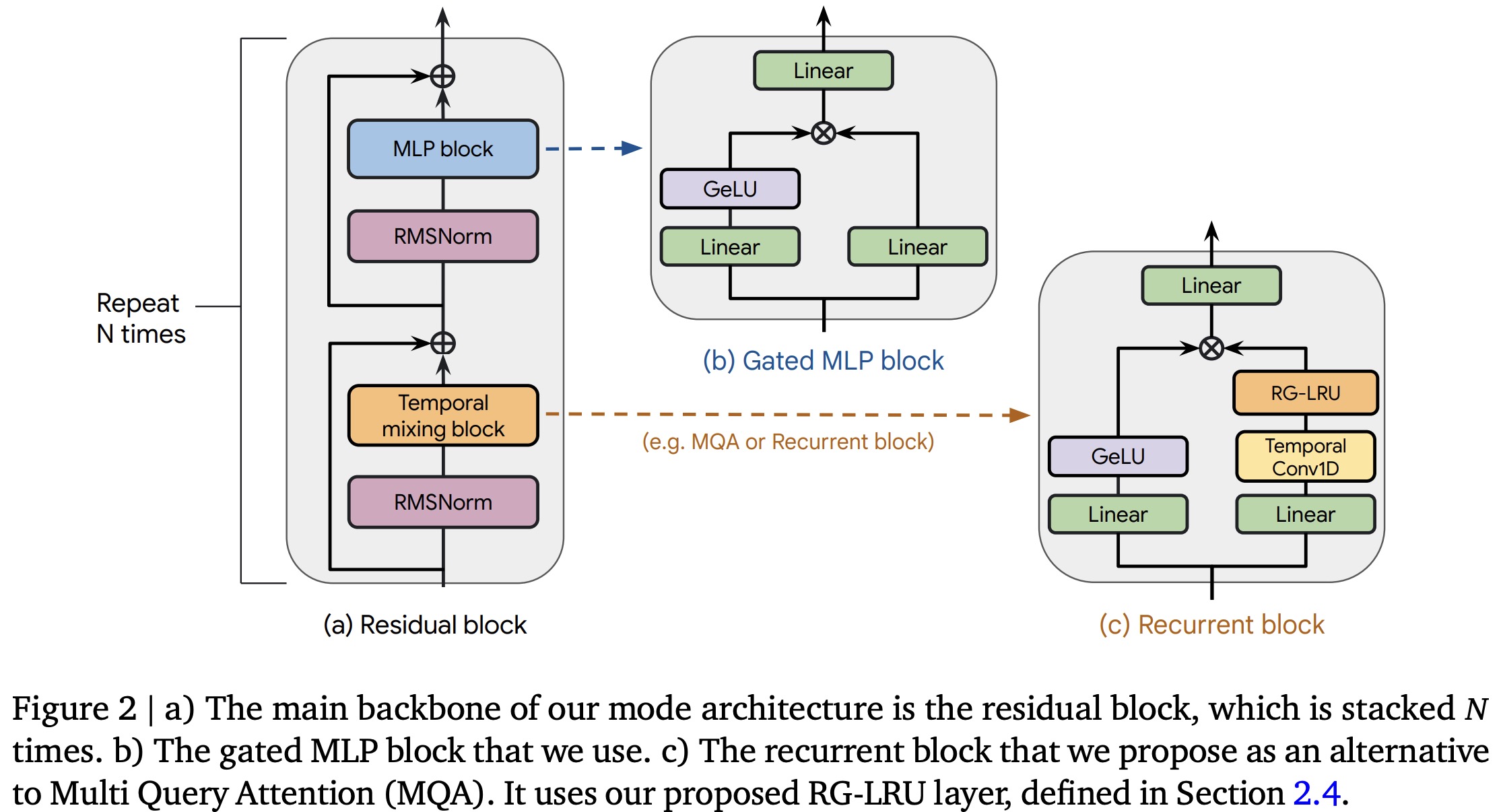
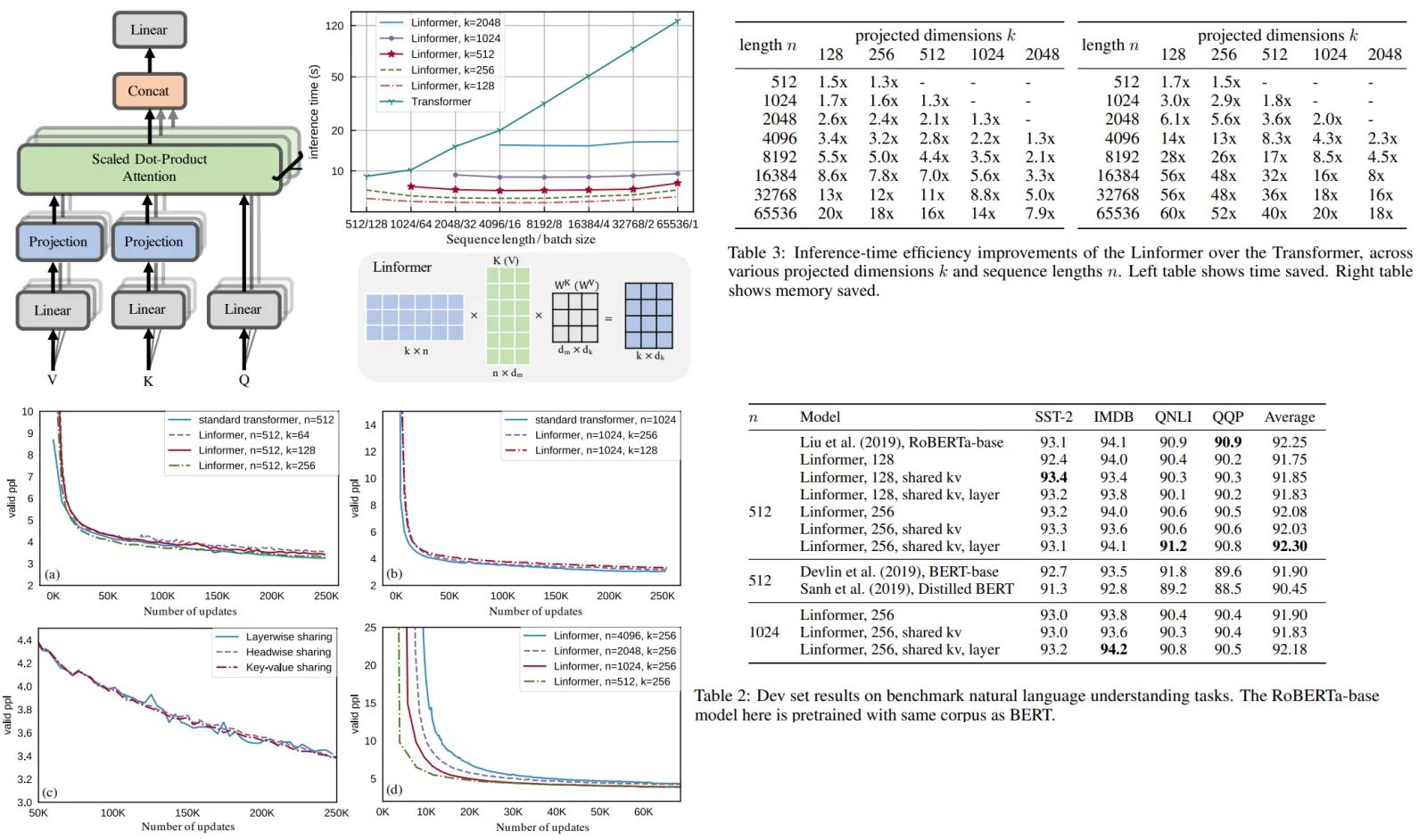
The architecture has three main components: a residual block, an MLP block, and a temporal-mixing block. The residual and MLP blocks are consistent across models, while three types of temporal-mixing blocks are considered: global Multi-Query Attention (MQA), local MQA, and a novel recurrent block.
Residual Block: Inspired by pre-norm Transformers, it processes input sequences through several layers, applying RMSNorm for final activations and using a shared linear layer for token probabilities.
MLP Block: Uses a gated mechanism with an expansion factor, applying linear layers and a GeLU non-linearity, followed by element-wise multiplication and a final linear layer.
Temporal-Mixing Blocks:
- Global MQA aims to enhance inference speeds (compared to Multi-Head Attention) by using the head dimension of 128 and requiring the model dimension to be a multiple of 128. Uses Rotary Position Embedding (RoPE) instead of absolute positional embeddings.
- Local Sliding Window Attention addresses the computational inefficiency of global attention by limiting attention to a fixed window of past tokens.
- Recurrent Block is inspired by existing blocks like the GSS block and Mamba’s block, applying two parallel linear layers to the input. A small Conv1D layer followed by the novel RG-LRU layer is used on one branch, and a GeLU nonlinearity on the other, before merging them through element-wise multiplication and applying a final linear layer.
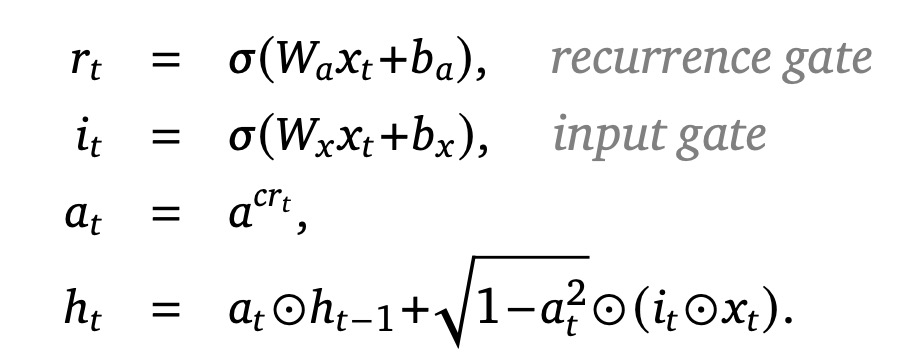
The Real-Gated Linear Recurrent Unit (RG-LRU) features a recurrence gate and an input gate, both using the sigmoid function for non-linearity, and performs element-wise operations for stable recurrence. The RG-LRU uses a learnable parameter to ensure stable gating values between 0 and 1. The gates don’t depend on the recurrent state, which allows efficient computation.
The recurrence gate allows to discard the input and preserve all information from the previous history.
Recurrent Models Scale as Efficiently as Transformers
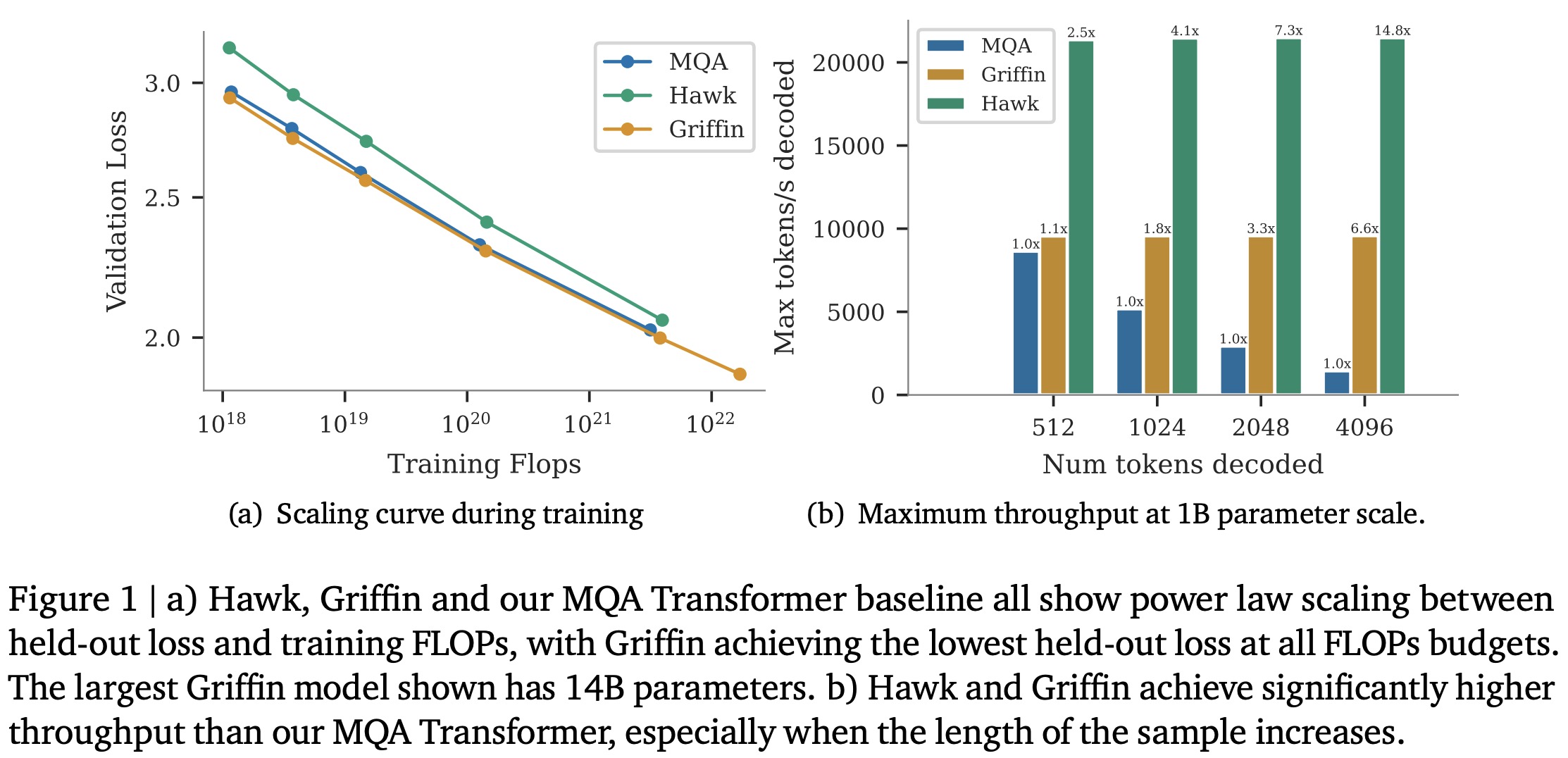
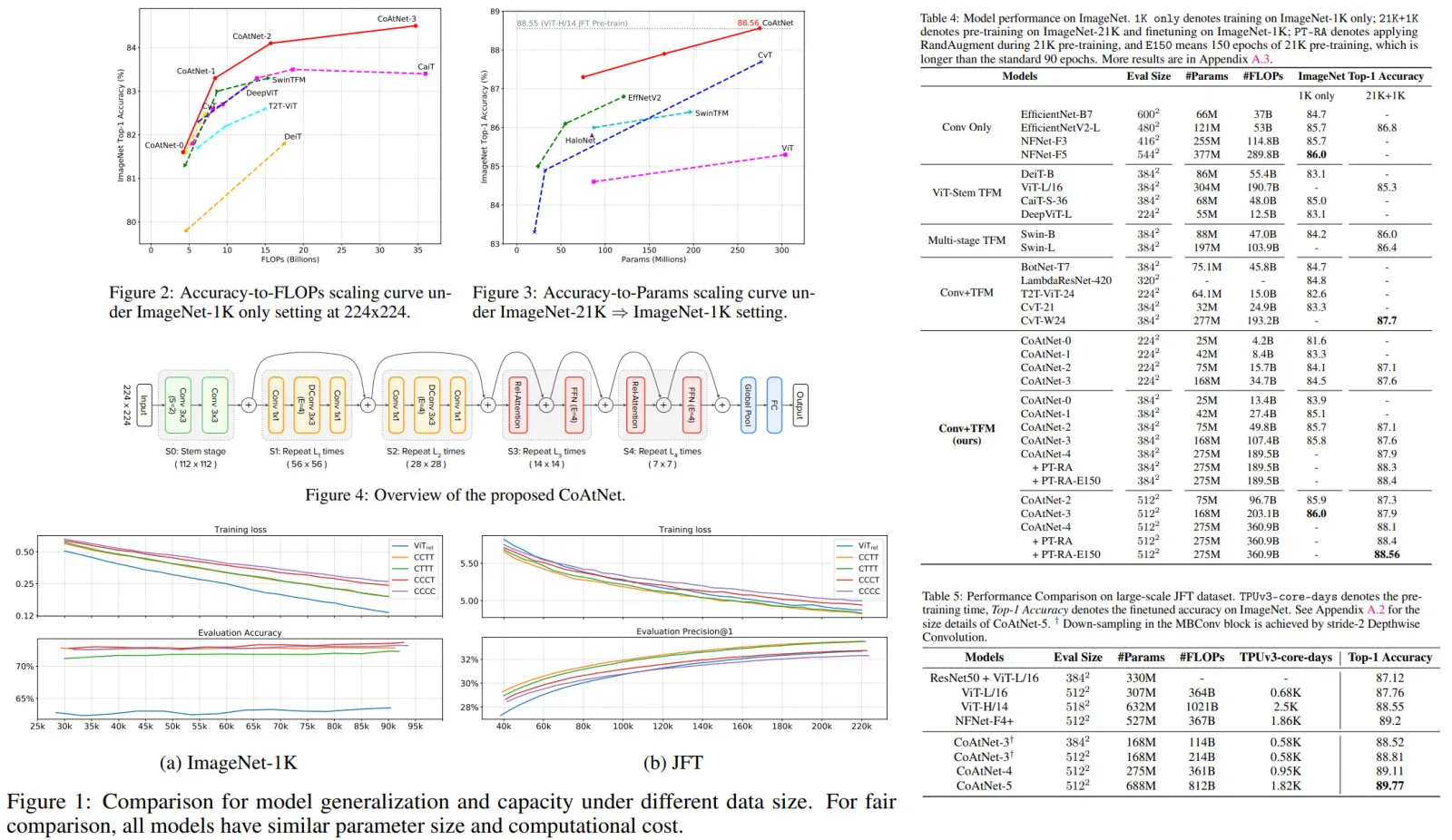
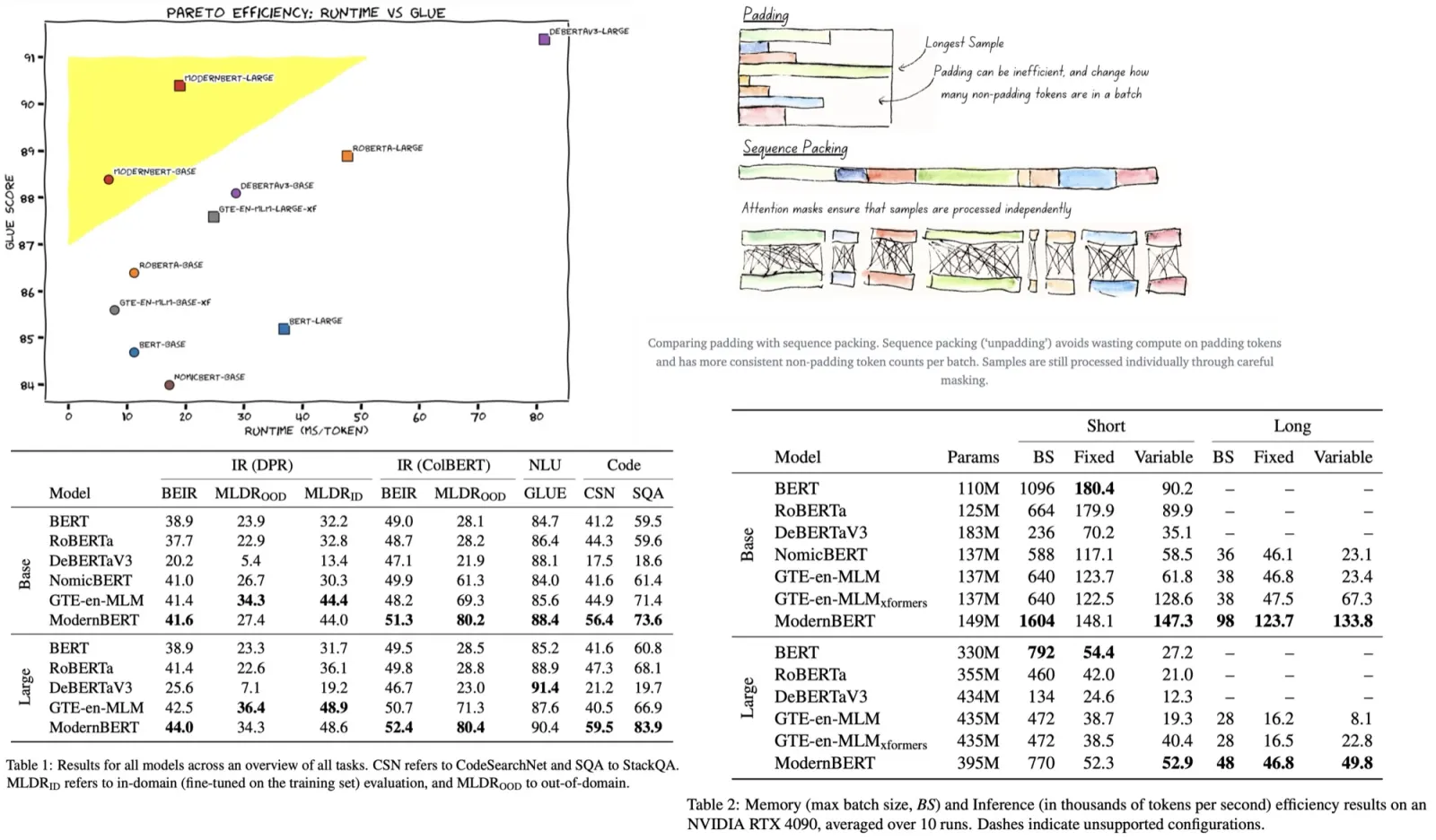
All three model families are trained across a range of scales from 100M to 14B parameters, adhering to the Chinchilla scaling laws and using the MassiveText dataset. All models show a linear scaling relationship between validation loss and training FLOPs. Griffin notably achieves a lower validation loss than a Transformer baseline across all FLOP budgets without using global attention layers, whereas Hawk shows slightly higher validation loss, which narrows with increased training budget.
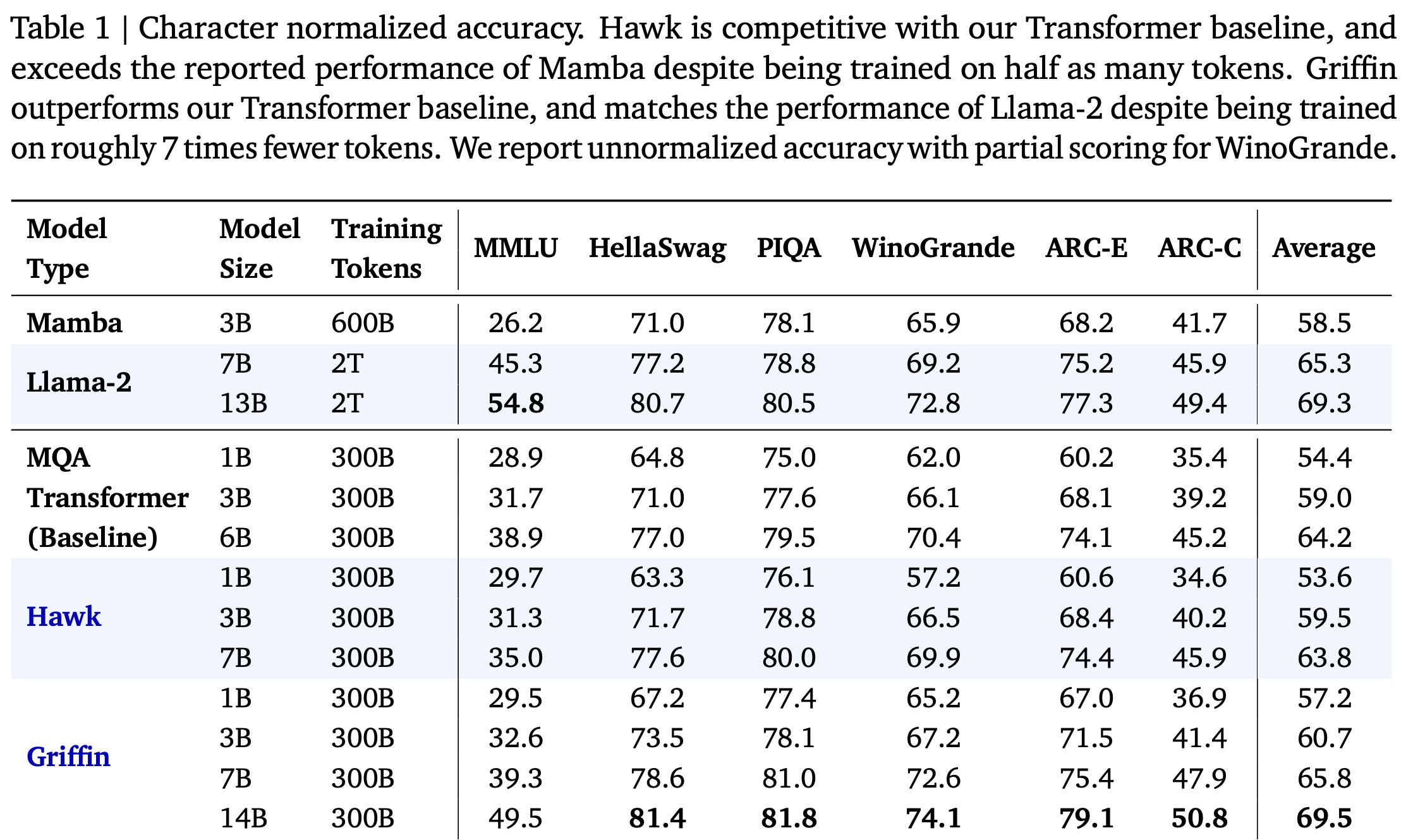
For downstream task evaluation, models were trained for 300B tokens and compared against Mamba-3B and Llama-2, which were trained on significantly more tokens. Despite this, Hawk and Griffin demonstrated very strong performance, with Hawk outperforming Mamba-3B at the 3B scale and Griffin not only surpassing Mamba-3B but also being competitive with Llama-2 at the 7B and 14B scales, despite the vast difference in training data. Griffin also outperforms the MQA Transformer baseline, showing the effectiveness of these models in achieving high performance with fewer training tokens.
Training Recurrent Models Efficiently on Device
For large-scale training, the authors use Megatron-style sharding for MLP and MQA blocks and block-diagonal weights for RG-LRU gates to reduce cross-device communication. ZeRO parallelism and bfloat16 representations are used to manage memory consumption.
To address the computational challenge of the RG-LRU layer’s low FLOPs-to-byte ratio, the authors write a custom kernel in Pallas (JAX) with a linear scan. This resulted in almost 3x speedup.
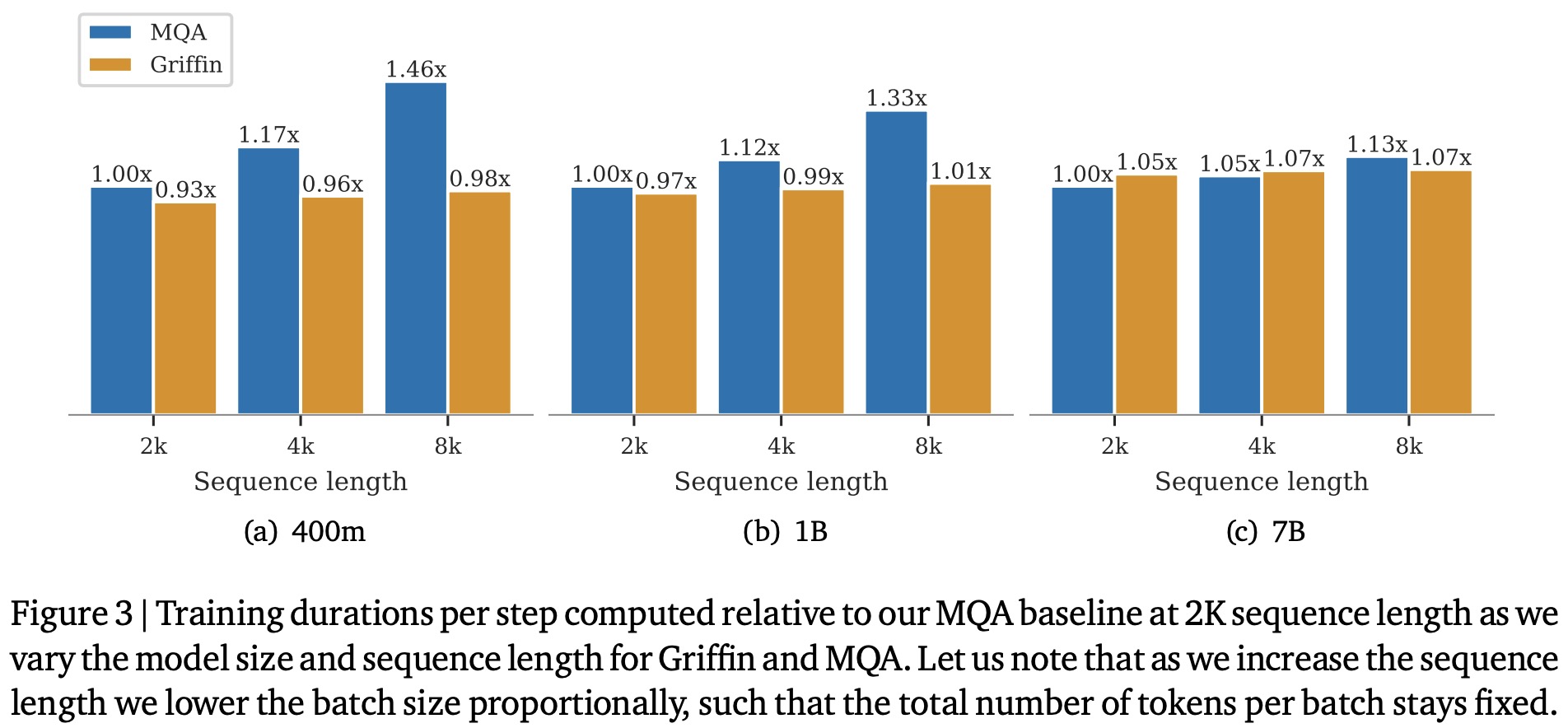
Training speed comparisons across different model sizes and sequence lengths show that as sequence length increases, Griffin maintains consistent training time, contrasting with slower Transformer baseline times, especially at smaller model sizes. This efficiency is attributed to the computational scaling of linear layers versus the RG-LRU and attention mechanisms. However, for short sequences, Griffin trains slightly slower than the MQA baseline due to its slightly higher parameter and FLOP count.
Inference Speed
Inference in LLMs involves two stages: “prefill” where the prompt is processed in parallel, leading to compute-bound operations similar in speed to those during training, and “decode” where tokens are generated auto-regressively, with recurrent models showcasing lower latency and higher throughput, especially at longer sequence lengths due to smaller key-value cache sizes compared to Transformers.
Latency and throughput are the main metrics for evaluating inference speed.
During decoding, both Transformer and recurrent models are memory bound, particularly when batch sizes are moderate. Recurrent models, with smaller recurrent state sizes compared to the KV cache of Transformers, have lower latency and allow for larger batch sizes, thus improving throughput. This difference becomes particularly notable for longer sequences.
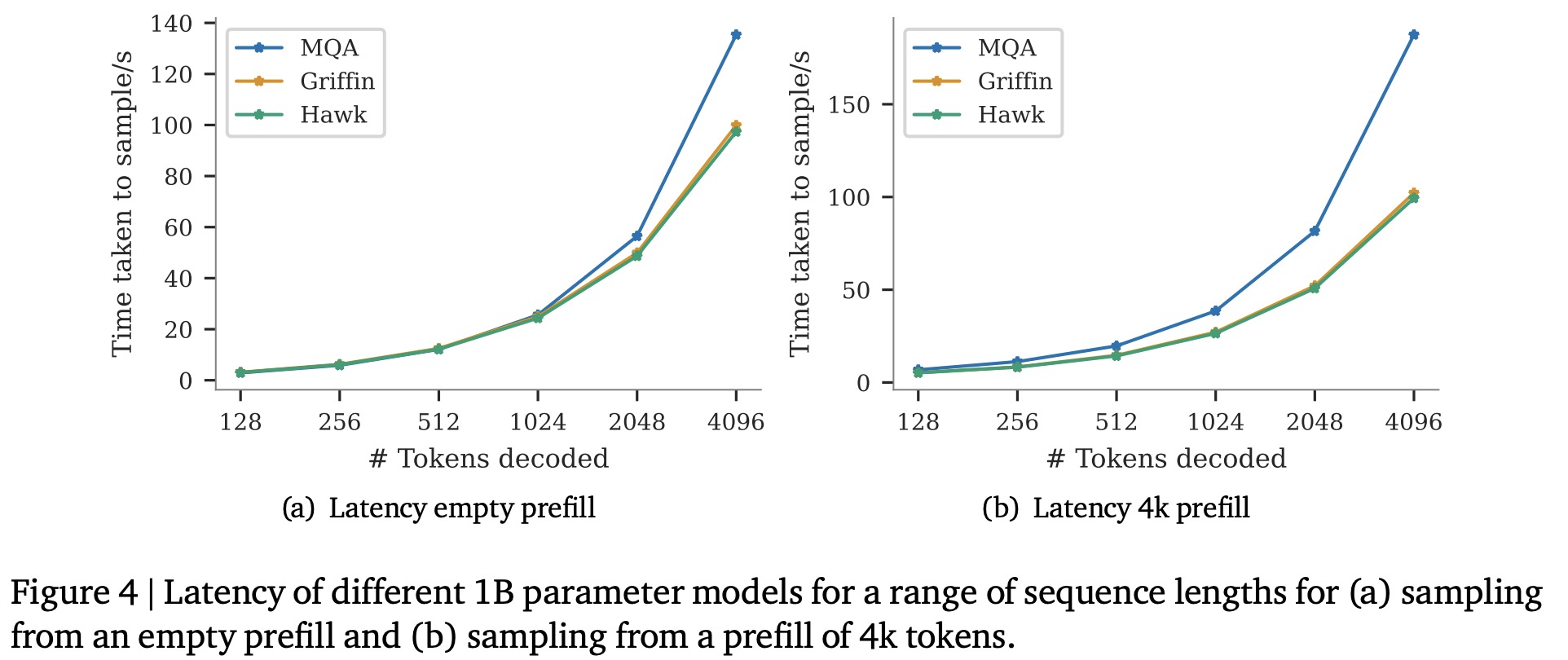
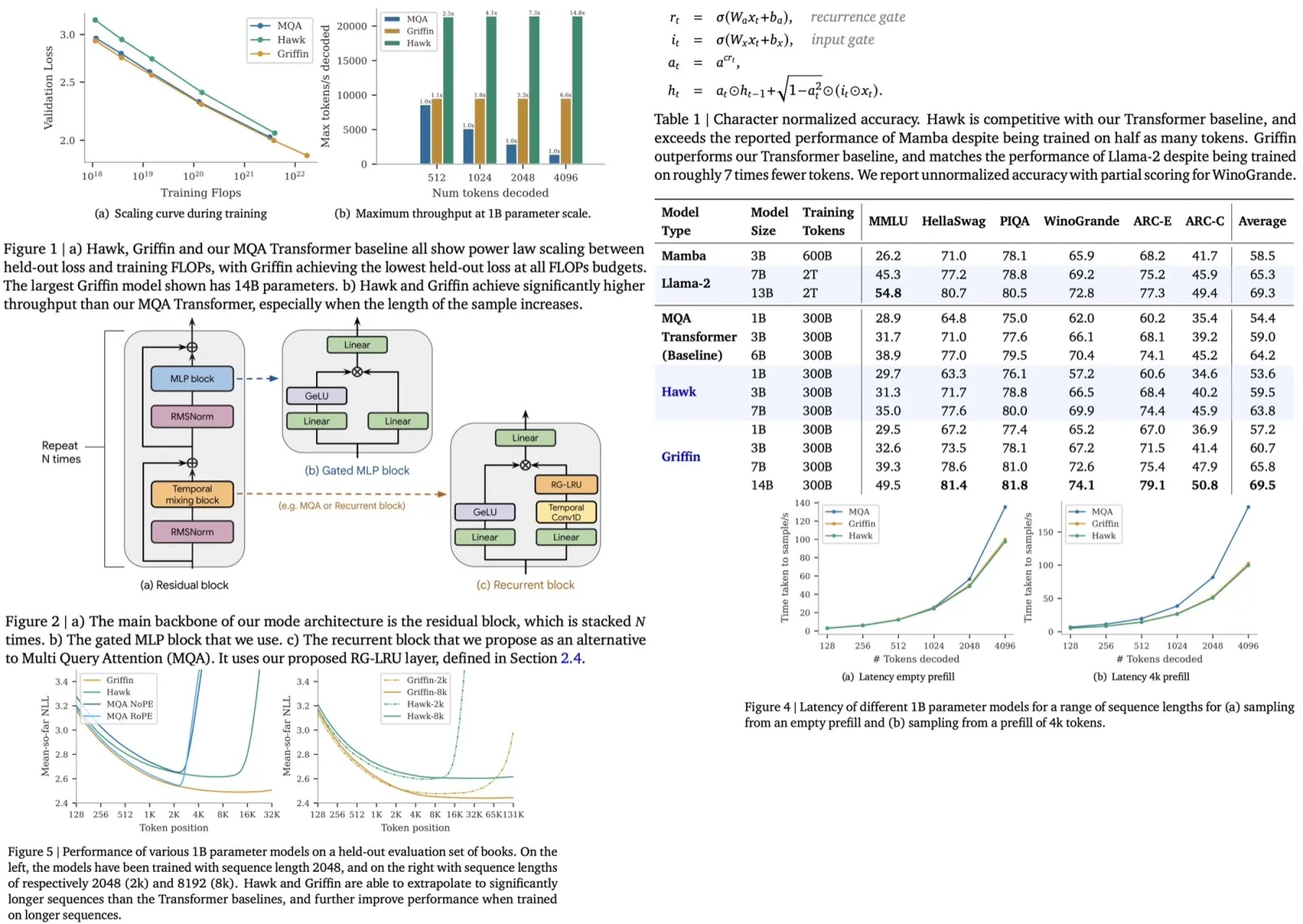
In an inference performance comparison of 1B parameter models, Hawk and Griffin demonstrated superior latency and throughput compared to an MQA Transformer baseline, especially with long sequences. The lower latency of Hawk and Griffin becomes particularly evident with increased prefill lengths, highlighting the efficiency of linear recurrences and local attention mechanisms.
Long Context Modeling
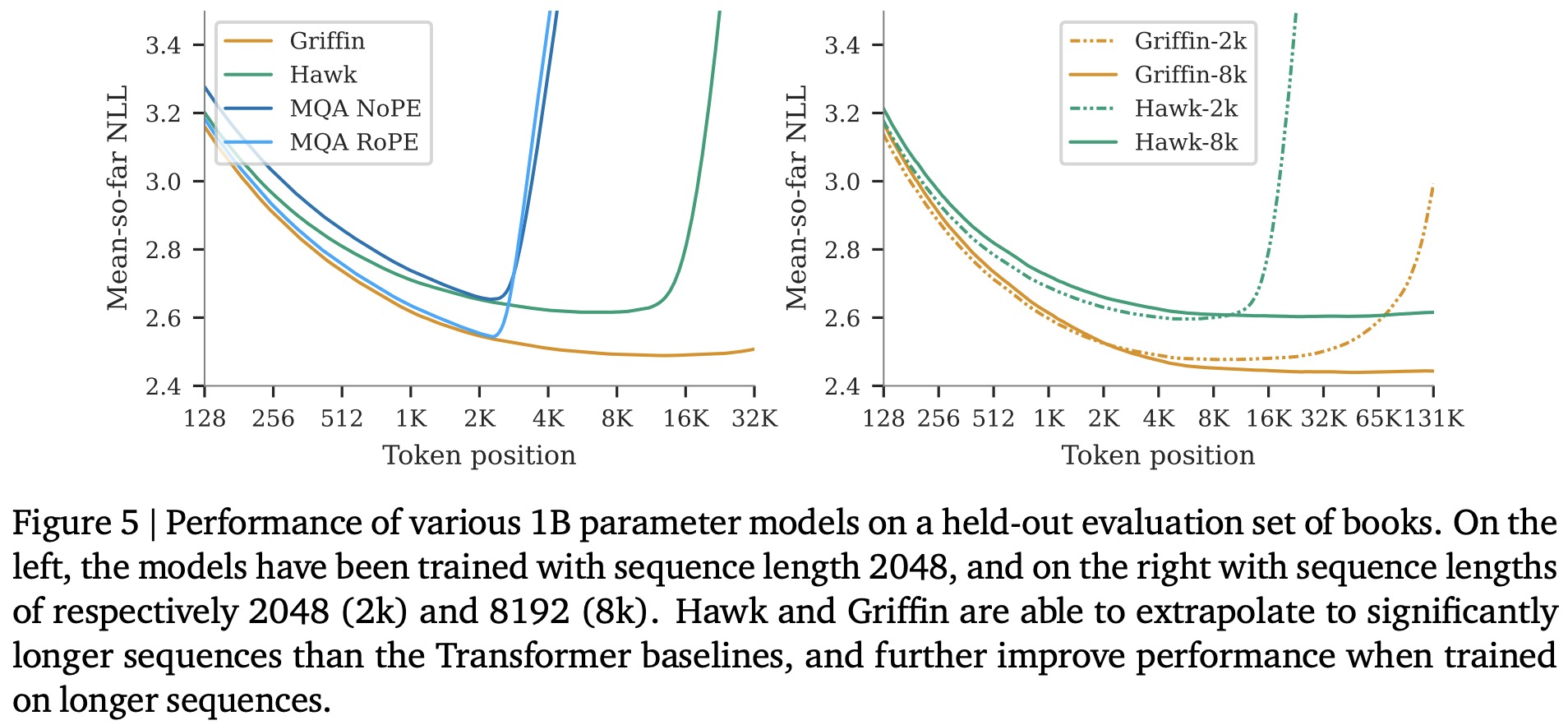
The authors evaluate Hawk and Griffin’s capacity to utilize longer contexts for improved predictions. Both models demonstrate enhanced next-token prediction with extended contexts, with Griffin showing notable extrapolation capability. Further exploration with models trained on 8k token sequences against those trained on 2k token sequences reveals that models adapted to longer contexts (Hawk-8k and Griffin-8k) perform better on longer sequences, showcasing their ability to learn from extended contexts. However, for shorter sequences, models trained on 2k tokens (Hawk-2k and Griffin-2k) slightly outperform, suggesting the importance of aligning training sequence length with the anticipated application needs of the model.
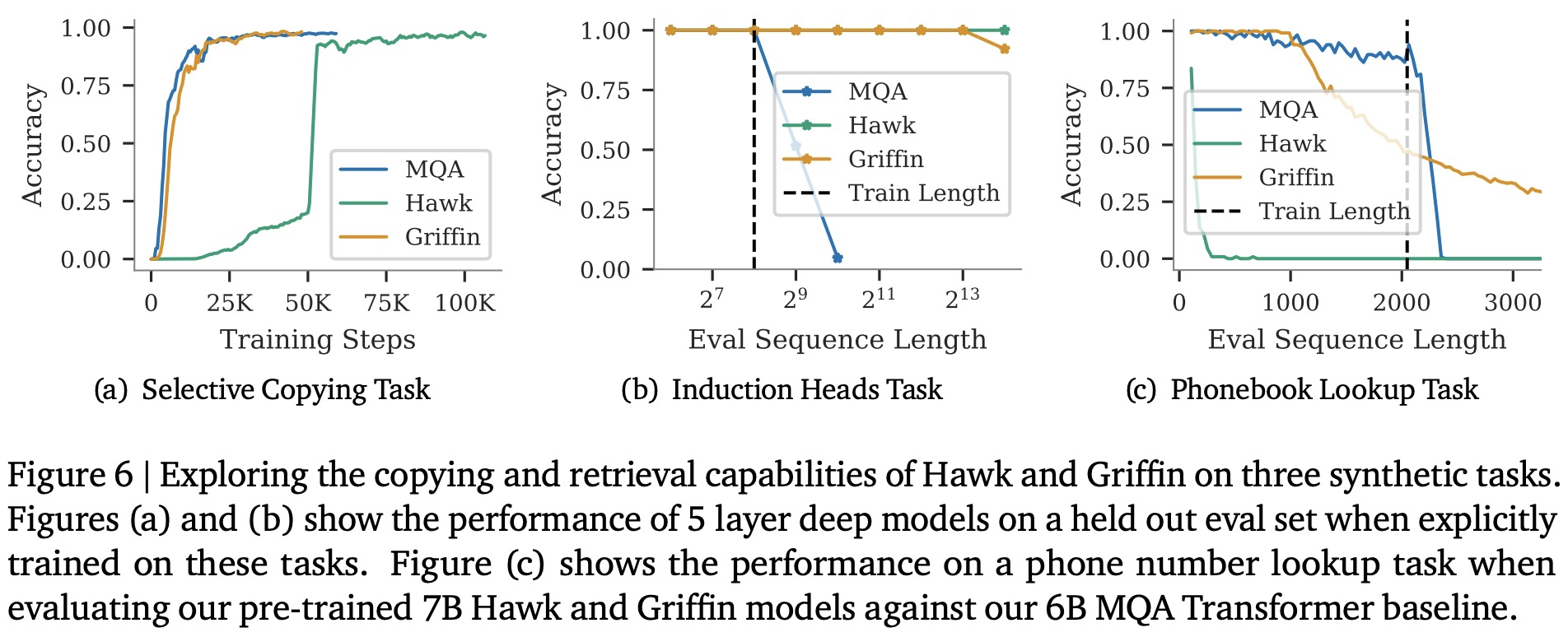
Hawk and Griffin’s capabilities in copying and retrieving tokens from context are explored through synthetic tasks and a practical phone number lookup task, comparing them against a MQA Transformer baseline. In the Selective Copying and Induction Heads tasks, Griffin matches the learning speed of Transformers and demonstrates superior extrapolation abilities on longer sequences, unlike the Transformer baseline which struggles with extrapolation. Hawk, while slower in learning, shows exceptional extrapolation on the Induction Heads task.
In a real-world phonebook lookup task, pre-trained Hawk, Griffin, and the MQA Transformer models were tested for their ability to memorize and retrieve correct phone numbers. Hawk performs well on short phonebook lengths but struggles as length increases due to its fixed-size state. The Transformer baseline succeeds up to its training sequence length but fails beyond that. Griffin stands out by solving the task up to its local attention window size and extrapolating better to longer sequences, though its performance declines once the context exceeds this window.
paperreview deeplearning recurrent attention