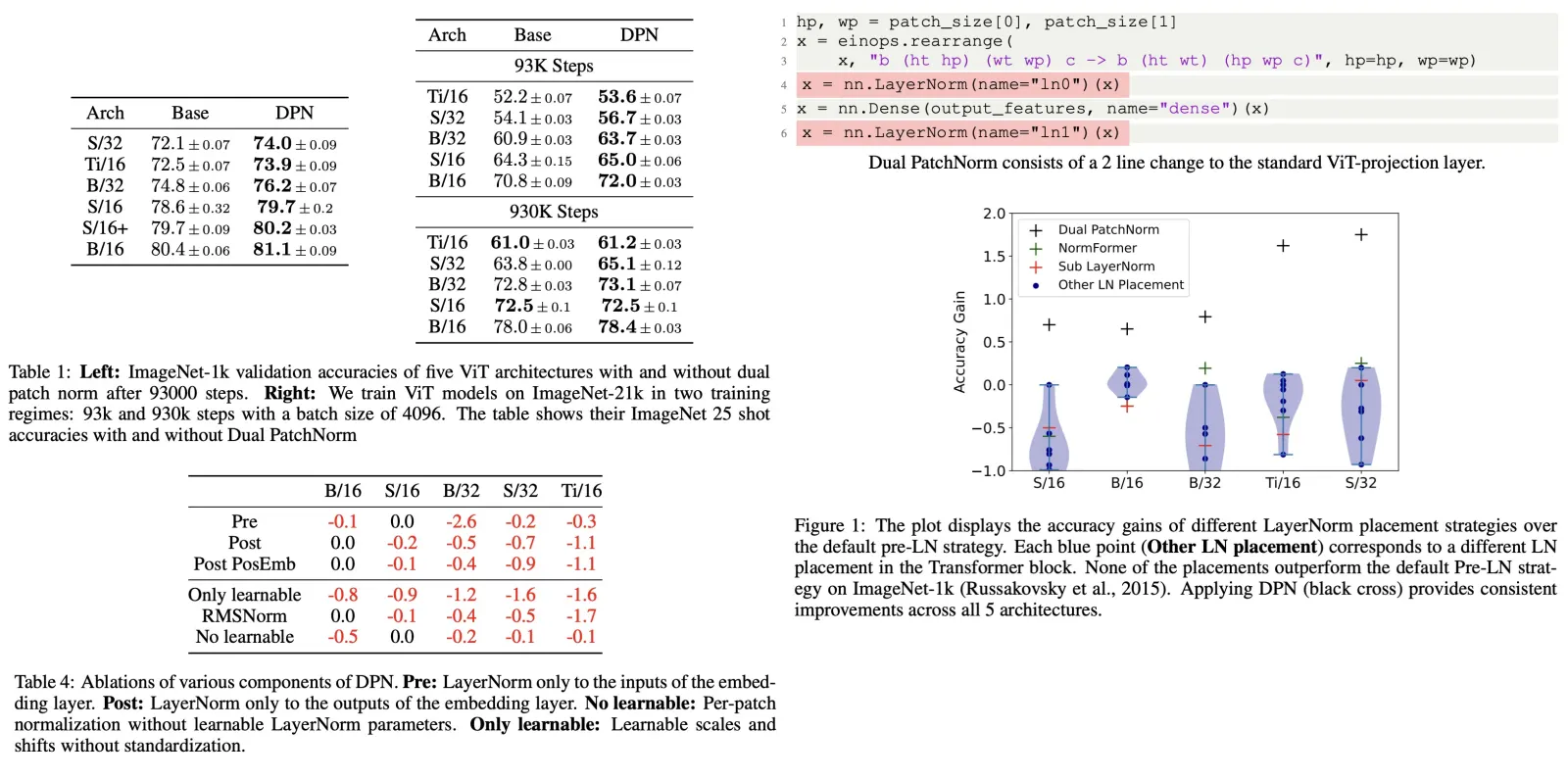
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles

This paper introduces Hiera, a novel, simplified hierarchical vision transformer. Despite the common practice of adding vision-specific components to improve supervised classification performance in vision transformers, these additions often result in increased complexity and slower speed compared to original Vision Transformers (ViT). The authors argue that this added complexity is unnecessary and can be eliminated through pretraining with a strong visual pretext task (MAE). The resulting model, Hiera, retains the accuracy of state-of-the-art multi-stage vision transformers but is significantly faster both during training and inference.
Approach
The authors aim to design a simplified, efficient multiscale vision transformer that achieves high accuracy on vision tasks without the need for specialized modules like convolution, shifted windows, or attention bias. They suggest that the spatial biases provided by these modules, which are absent in vanilla transformers, can be learned through a strong pretext task instead of complicated architectural modifications.
For this purpose, they use Masked Autoencoders (MAE) as their pretext task, which has proven effective in teaching ViTs localization abilities for downstream tasks. MAE pretraining involves deleting masked tokens, unlike other masked image modeling approaches (which usually overwrite them). This method, while efficient, presents a challenge for hierarchical models since it disrupts the 2D grid they depend on.
To overcome this, the authors introduce a distinction between tokens and “mask units”, where mask units represent the resolution of MAE masking and tokens are the internal resolution of the model. They mask 32×32 pixel regions, which equates to 8 × 8 tokens at the network’s start.
Using a novel trick, the authors can evaluate hierarchical models by treating mask units as contiguous and separate from other tokens. This allows them to successfully use MAE with an existing hierarchical vision transformer.
Preparing MViTv2

The authors select MViTv2 as the base architecture for their experiments, citing its small 3x3 kernels are least affected by their unique masking technique, though they believe other transformers could potentially yield similar results.
MViTv2 is a hierarchical model that learns multi-scale representations across four stages. It begins by modeling low-level features with a small channel capacity but high spatial resolution, and then trades channel capacity for spatial resolution in each stage to model more complex high-level features in deeper layers.
A key aspect of MViTv2 is pooling attention where features are locally aggregated—typically using 3x3 convolution—before computing self-attention. In the first two stages, K and V are pooled to decrease computation, and Q is pooled to transition from one stage to the next by reducing spatial resolution.
When applying Masked Autoencoders (MAE), the authors note that MViTv2 downsamples by 2x2 three times and uses a token size of 4x4 pixels, hence, they use a mask unit size of 32x32. This ensures each mask unit corresponds to varying numbers of tokens across different stages. The mask units are then manipulated to ensure convolution kernels do not interfere with deleted tokens, treating each mask unit as an individual “image,” while ensuring that self-attention remains global.
Simplifying MViTv2

The authors experiment with removing non-essential components of MViTv2 while training with Masked Autoencoders (MAE). Their findings show that these components can be removed or simplified while maintaining high image classification accuracy on ImageNet-1K:
- Firstly, they replaced the relative position embeddings in MViTv2 with absolute position embeddings. This simplification resulted in no significant loss of accuracy when training with MAE and was much faster.
- Next, they replaced every convolution layer, a vision-specific module, with maxpools. Although this replacement initially dropped the accuracy, deleting additional stride=1 maxpools returned the model close to its previous accuracy.
- They also removed the overlap in the remaining maxpool layers by setting the kernel size equal to stride for each maxpool. This action eliminated the need for a padding trick, resulting in a model that was faster and more accurate.
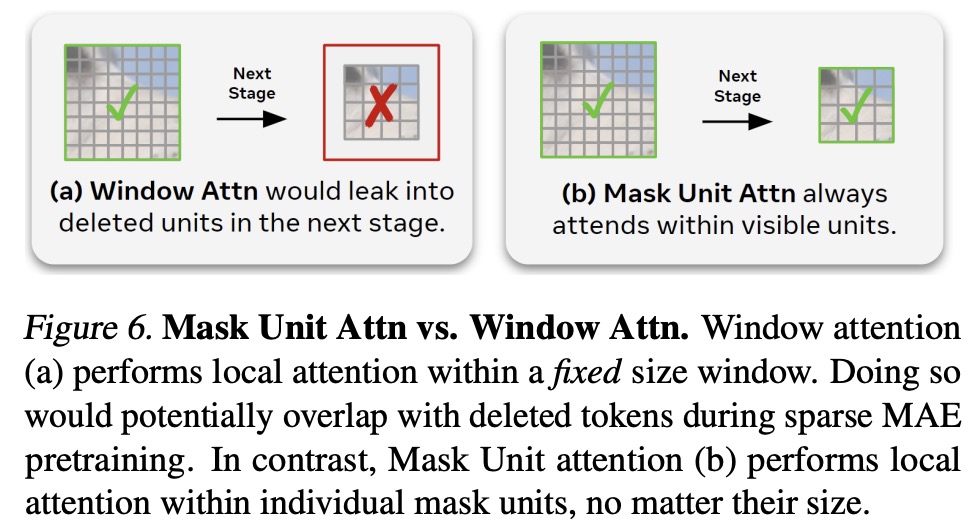
- Furthermore, they removed the attention residual from MViTv2 and introduced “Mask Unit attention,” a local attention within a mask unit, replacing KV pooling in the first two stages. This change resulted in no accuracy loss and increased throughput significantly—up to 32% on video.
Finally, the authors clarify that mask unit attention is distinct from window attention because it adapts the window size to the size of mask units at the current resolution, avoiding potential issues with deleted tokens after downsampling.
Hiera
The culmination of the described changes is a model named “Hiera”. Hiera is 2.4 times faster on images and 5.1 times faster on video than the original MViTv2. In addition to the increased speed, Hiera actually boasts improved accuracy due to the implementation of MAE.
Hiera also supports sparse pretraining, resulting in rapid results. In terms of image accuracy, Hiera-L is three times faster to train than a supervised MViTv2-L. Comparing with a modified version of MViTv2 used in video tasks, Hiera-L achieves 85.5% accuracy in 800 pretrain epochs, making it 2.1 times faster to train.
All benchmarks in the study are performed on an A100 GPU with fp16 precision, as this setup is deemed the most practical.

MAE Ablations
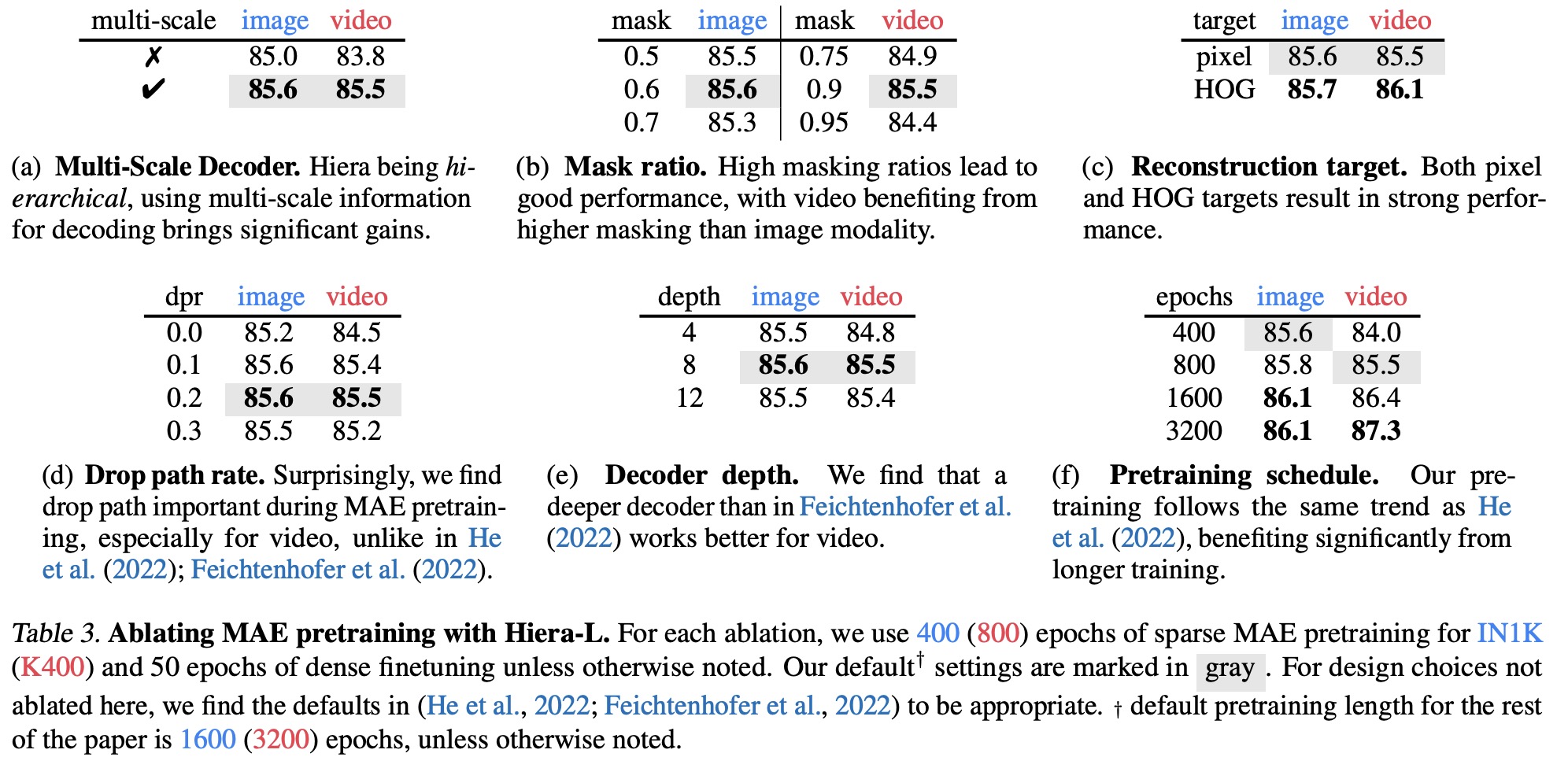
In this section, various Masked Autoencoders (MAE) pretraining settings for Hiera were studied for both images and video using ImageNet-1K and Kinetics-400 datasets.
- Multi-Scale Decoder: Unlike previous works, Hiera uses a multi-scale approach by fusing representations from all stages, leading to significant improvements in both images and videos.
- Masking Ratio: Optimal masking ratios were found to be 0.6 for images and 0.9 for videos, suggesting videos have higher information redundancy.
- Reconstruction Target: Both pixel (with normalization) and Histogram of Oriented Gradients (HOG) targets resulted in strong performances. With longer training, HOG targets perform similarly to pixel targets for videos but slightly worse for images.
- Droppath Rate: By applying drop path during pretraining, significant gains were observed, suggesting that Hiera can overfit to the MAE task without it.
- Decoder Depth: For videos, a deeper decoder than what was previously used showed significant benefits.
- Pretraining Schedule: Hiera benefited from longer pretraining schedules and showed more efficient learning than the ViT-L MAE model. On the Kinetics-400 dataset, Hiera achieved state-of-the-art performance with only 800 epochs of pretraining.
Video Results
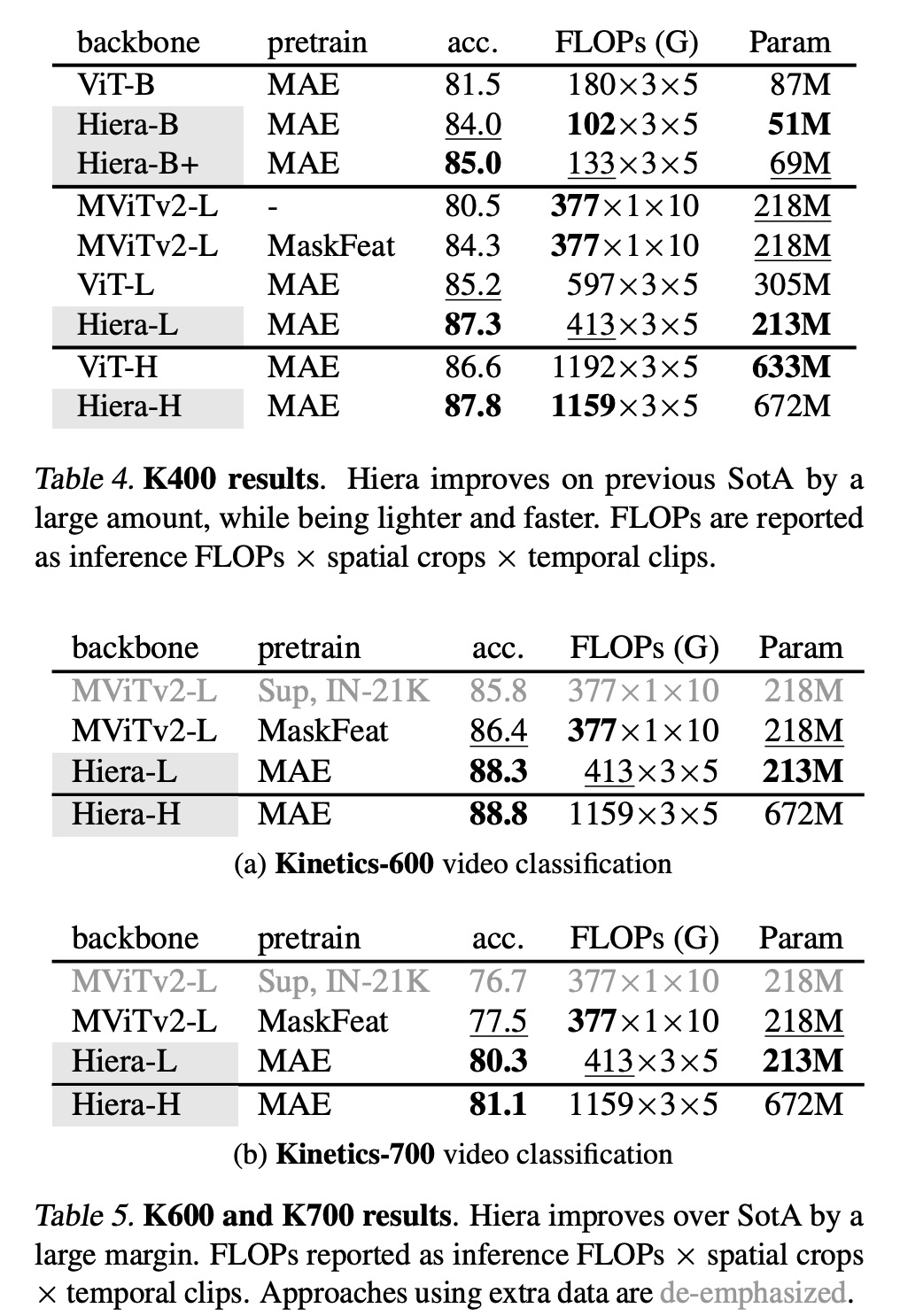
- Kinetics-400,-600,-700: Hiera-L outperformed previous SotA models by 2.1% while using 45% fewer flops, being 43% smaller, and 2.3 times faster. Even when compared with higher tier models, Hiera-L was 3 times smaller and 3.5 times faster.
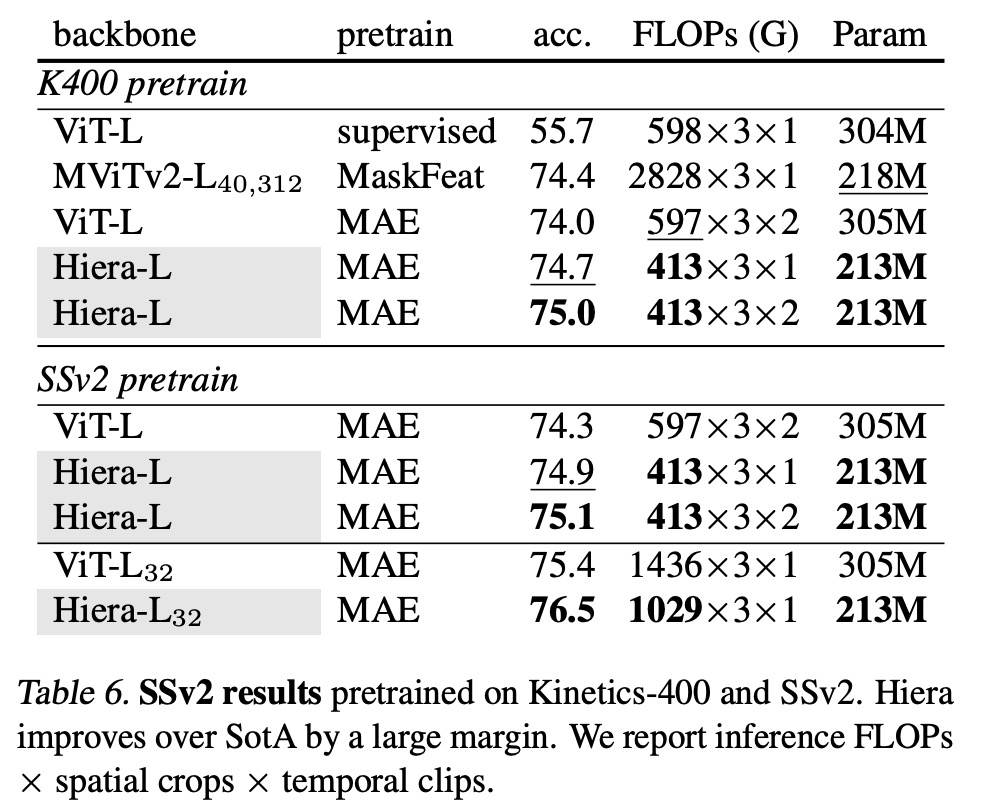
- Something-Something-v2 (SSv2): Hiera-L also demonstrated superior performance on the SSv2 dataset. Pretrained on Kinetics-400, it outperformed the second-best method, MaskFeat, by 0.6% while being dramatically more efficient. When pretrained on SSv2, it outperformed ViT-L by 0.8% while using about 45% fewer flops and being 43% smaller.
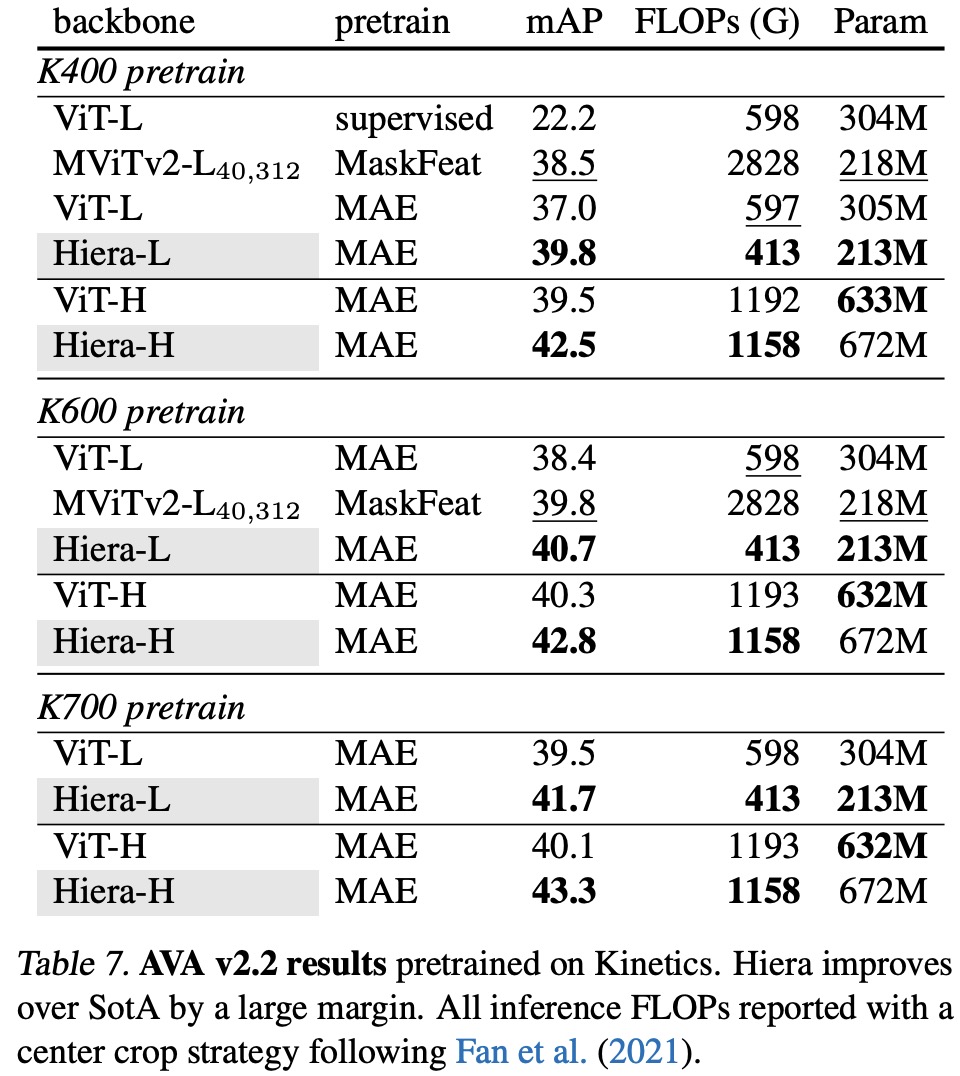
- Action Detection (AVA): Hiera outperformed previous SotA models, with Hiera-L and Hiera-H pretrained on Kinetics-400, -600, and -700 datasets showing better mean average precision (mAP) by up to 3.2%, while being more efficient in terms of FLOPs and parameters. This established a new SotA for the task.
Image Results
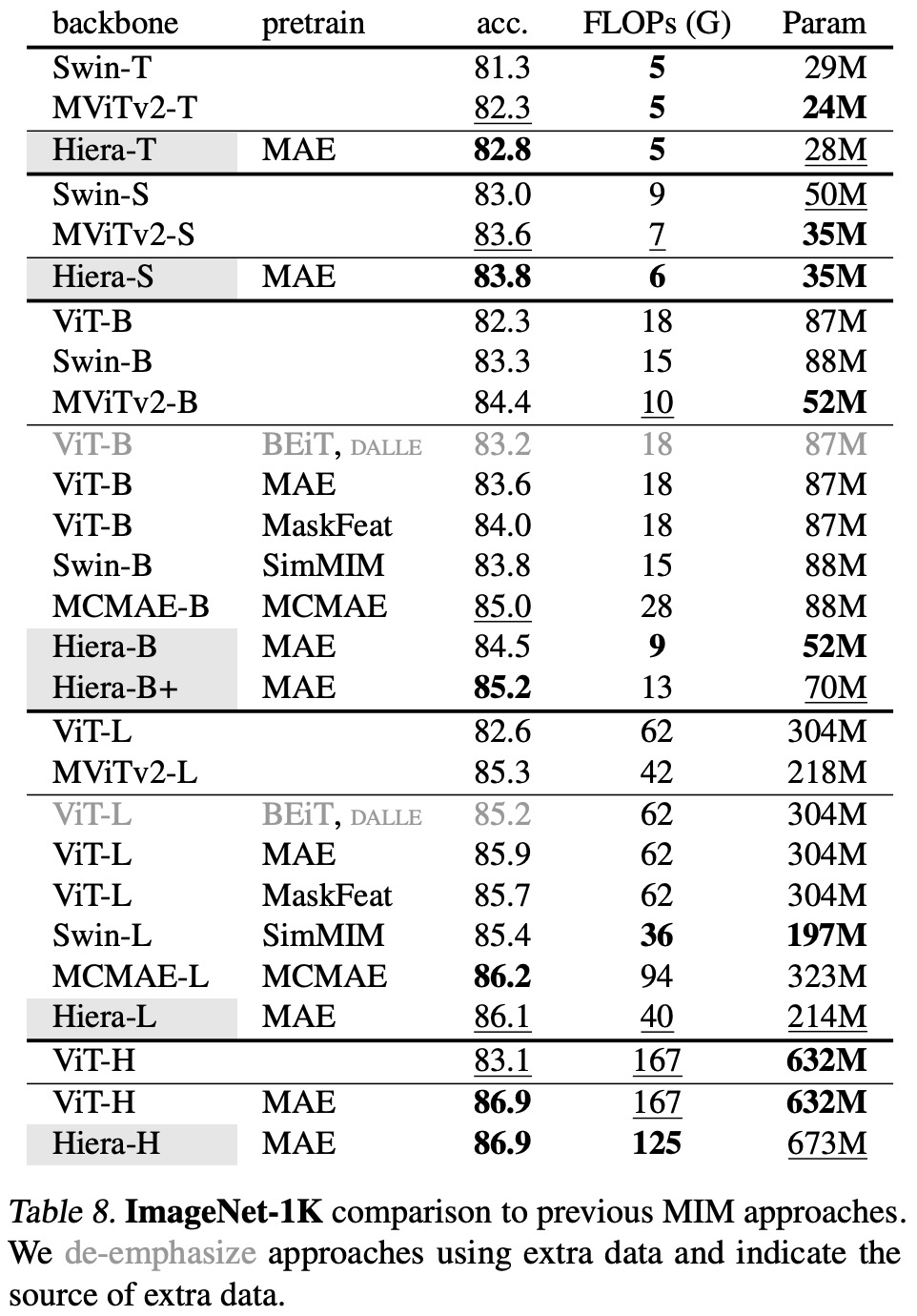
- Hiera exhibits competitive or superior performance across different model scales on the ImageNet-1K dataset, demonstrating its robustness and efficiency.
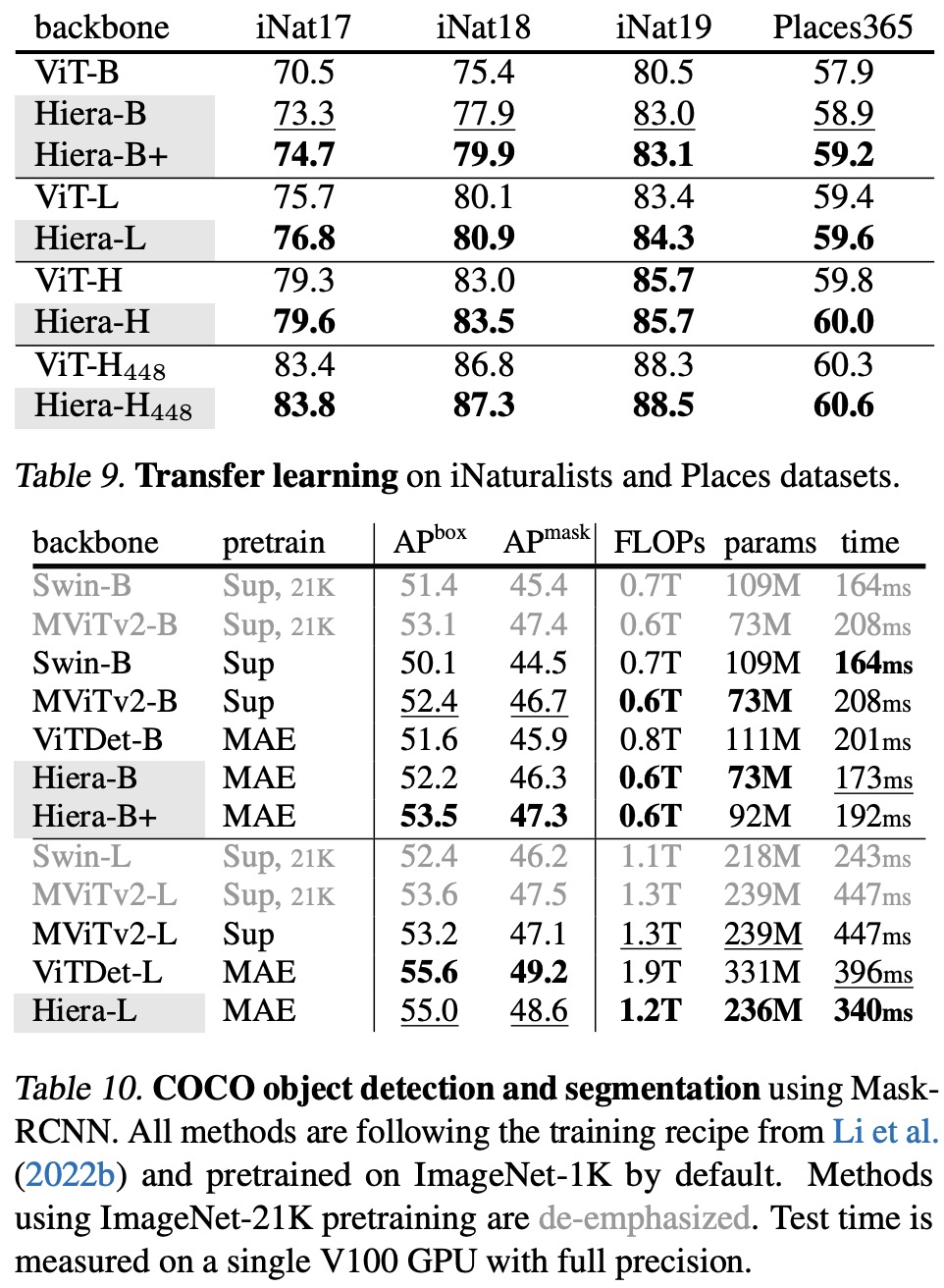
- Classification on iNaturalist and Places: When finetuned on the iNaturalist and Places datasets, Hiera outperformed ViT models pretrained with MAE. This result indicates the effectiveness of the Hiera-L and Hiera-H architectures beyond just the ImageNet dataset.
- Object Detection and Segmentation on COCO: The Hiera models with MAE pretraining demonstrated strong scaling behavior compared to supervised models like MViTv2, while being consistently faster. For instance, Hiera-L achieved higher APbox scores (+1.8) than MViTv2-L while reducing the inference time by 24%. Even when compared to MViTv2 using ImageNet-21K pretraining, Hiera-L still outperformed MViTv2-L.
- Comparison to ViTDet: When compared to the state-of-the-art method, ViTDet, Hiera models achieved similar results but with faster inference times and lower operation counts. For example, Hiera-B achieved higher APbox scores (+0.6) than ViTDet-B, with 34% fewer parameters and a 15% reduction in inference time. Moreover, Hiera-B+ showed improved boxAP scores (+1.9) compared to ViTDetB, with lower inference times and model complexity.