Paper Review: Tracking Anything in High Quality
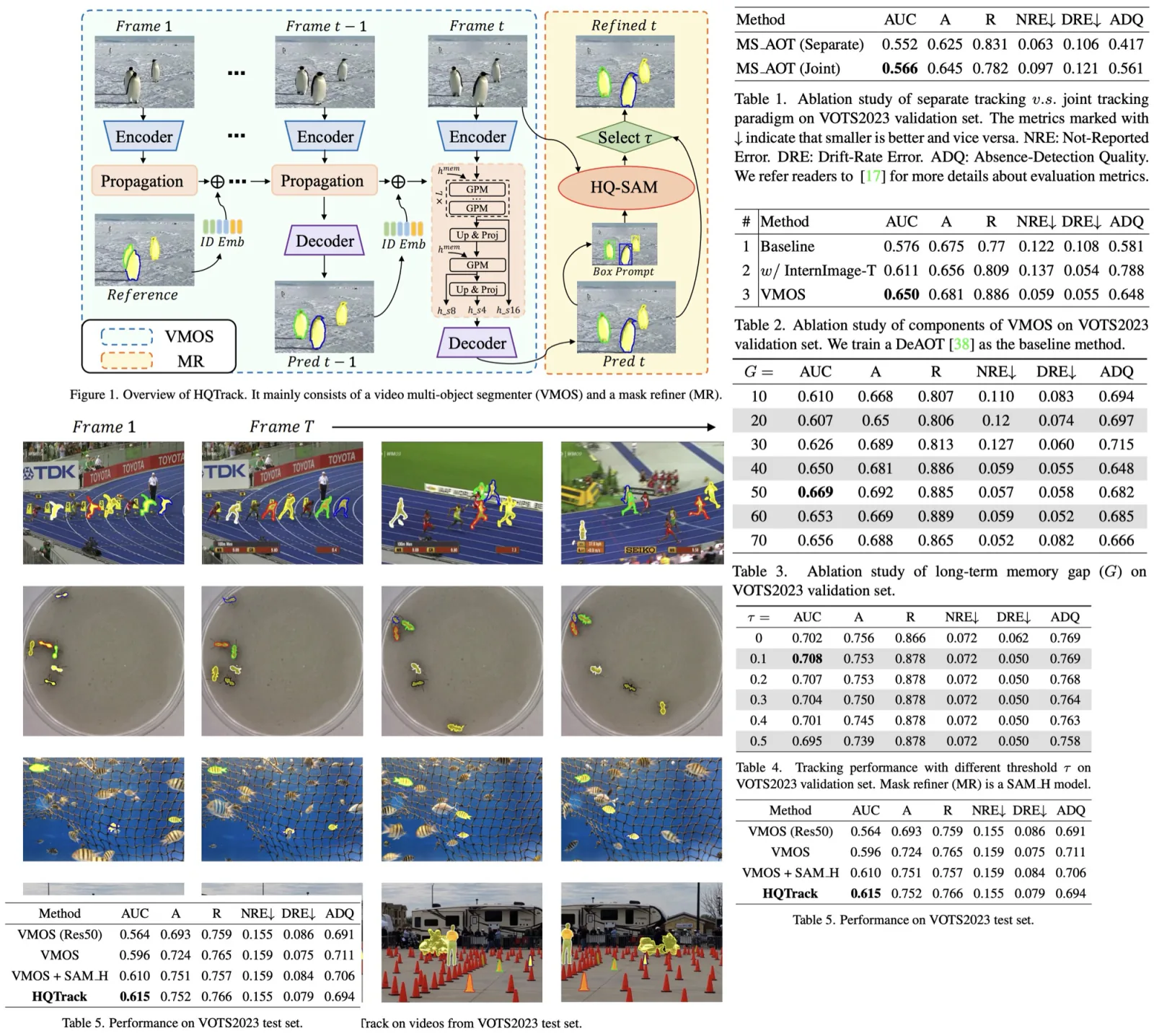
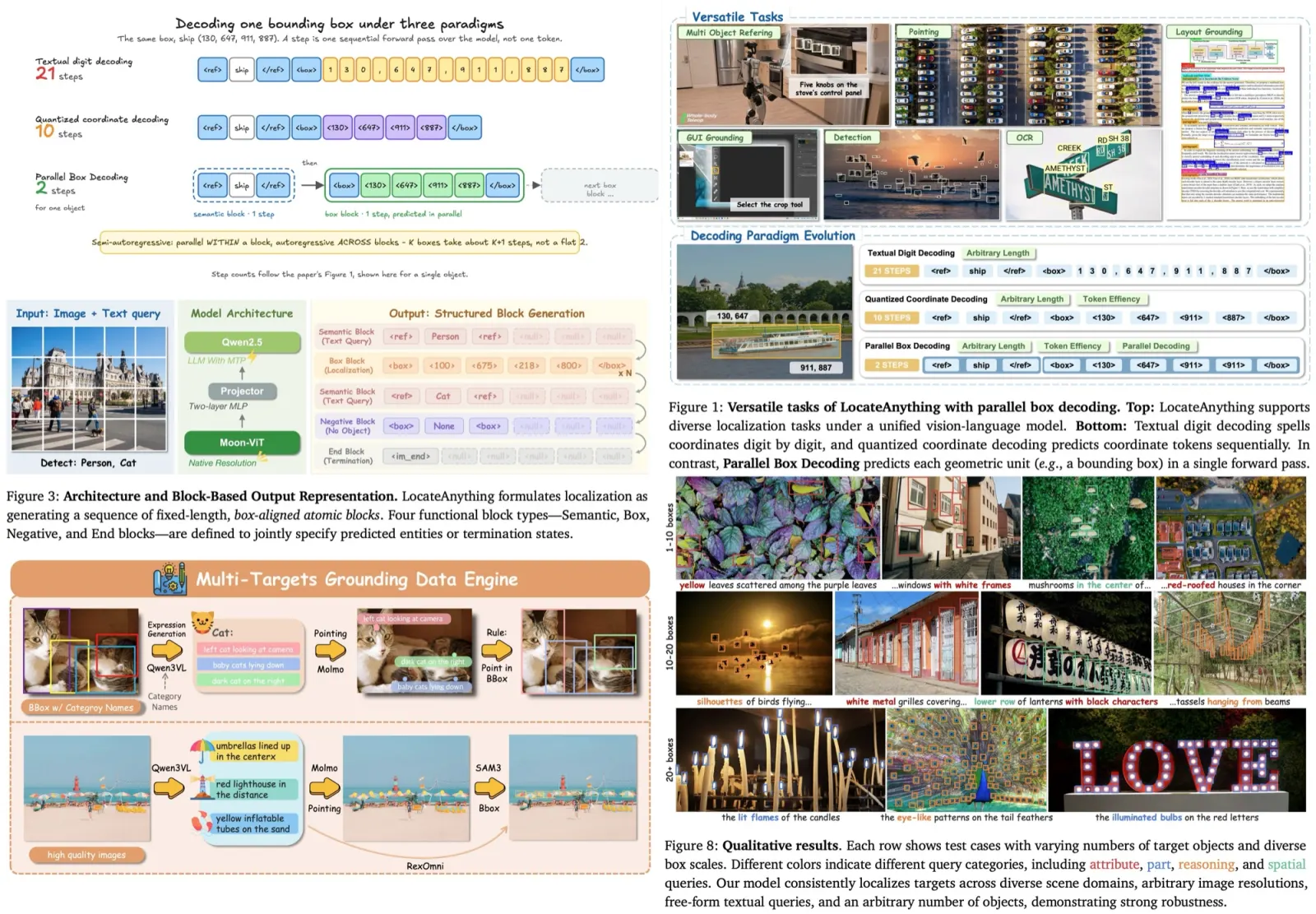
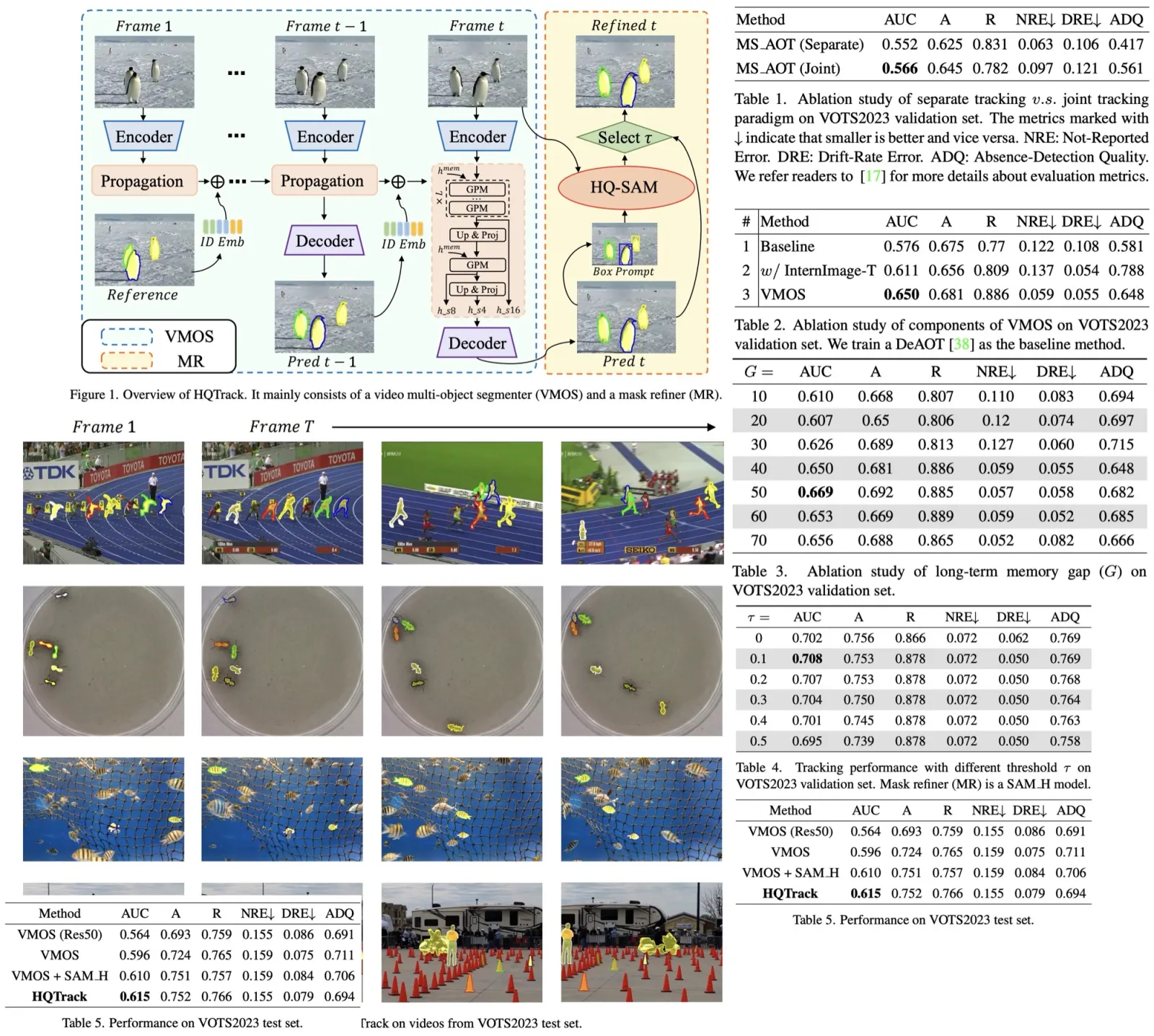
This paper introduces HQTrack, a new high-quality tracking framework for video objects. Combining a video multi-object segmenter (VMOS) and a mask refiner (MR), HQTrack tracks the object specified in the initial frame of a video and refines the tracking results for greater accuracy. Although VMOS’s training on several video object segmentation (VOS) datasets limits its capacity to adapt to complex scenes, the MR model aids in refining the tracking results. Without the use of extra enhancements such as test-time data augmentations and model ensemble, HQTrack has proved its efficacy by securing the 2nd place in the Visual Object Tracking and Segmentation (VOTS2023) challenge.
Method
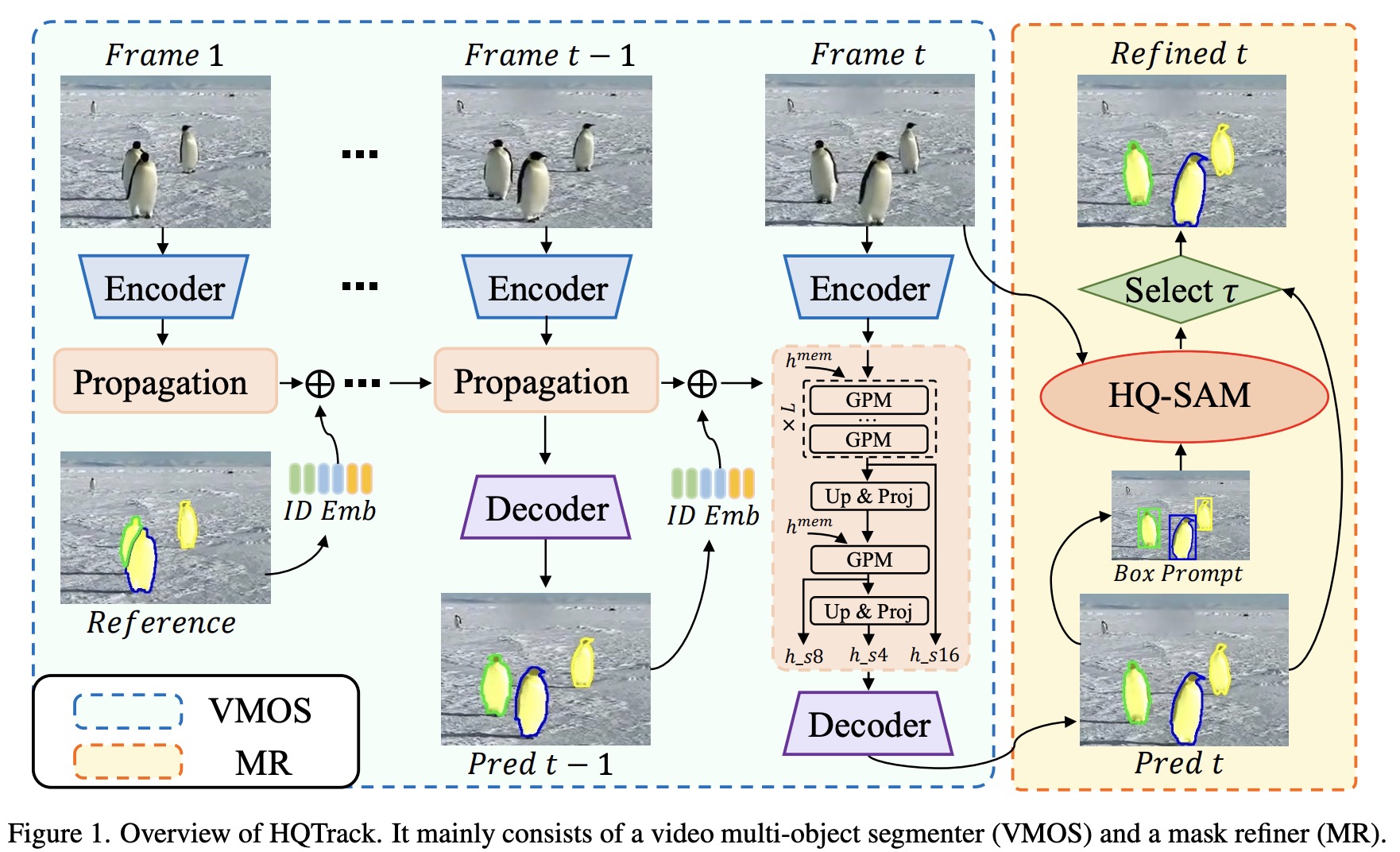
Video Multi-object Segmenter
VMOS, a key component of the HQTrack framework, is a variant of the DeAOT model and is specifically designed to improve segmentation performance. Unlike the original DeAOT, which operates on 16× scale visual and identification features, VMOS employs a Gated Propagation Module (GPM) cascaded with an 8× scale and expands the propagation process to multiple scales. This approach helps preserve detailed object clues that can be lost at larger scales, thus improving the ability to perceive tiny objects. VMOS uses upscaling and linear projection to upscale the propagation features only up to a 4× scale, considering memory usage and model efficiency. These multi-scale propagation features are then input into a simple Feature Pyramid Network (FPN) decoder for mask prediction. Additionally, VMOS incorporates Internimage’s Intern-T, a large-scale CNN-based model that uses deformable convolution, to enhance object discrimination capabilities.
Mask Refiner
The Mask Refiner in HQTrack is a pre-trained HQ-SAM model, which is a variant of the Segment Anything Model. SAM has gained significant attention for its image segmentation capabilities and zero-shot generalization due to its training on a high-quality dataset containing 1.1 billion masks. However, SAM struggles with images containing complex objects, leading to the development of HQ-SAM. This model improves upon SAM by introducing additional parameters to the pre-trained model, providing higher quality masks.
In HQTrack, the MR refines the prediction mask produced by the VMOS, especially in complex scenarios where the VMOS’s results may be of insufficient quality due to its training on scale-limited close-set datasets. The MR calculates the outer enclosing boxes of the predicted mask from VMOS, feeds these box prompts along with the original image into the HQ-SAM model, and produces refined masks.
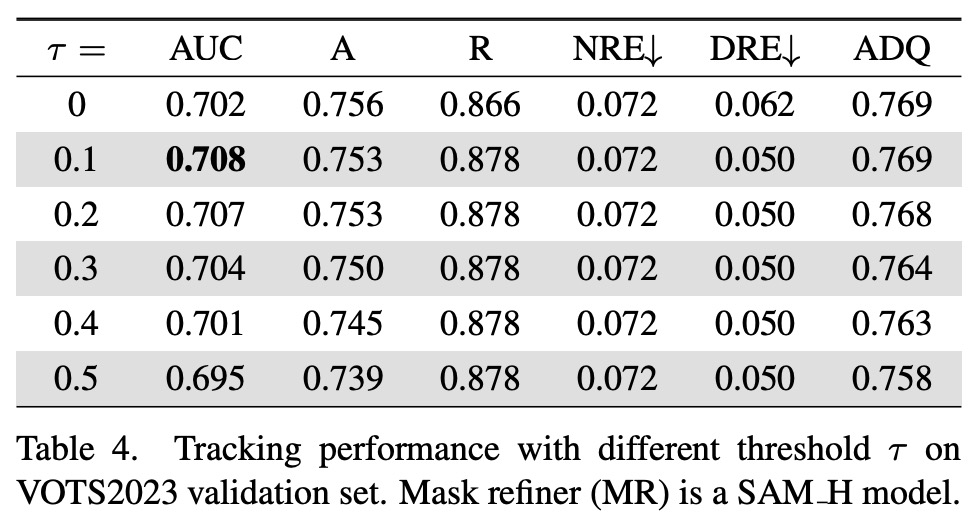
The final output mask for HQTrack is selected from the results of VMOS and HQ-SAM. If the Intersection over Union (IoU) score between the masks from VMOS and HQ-SAM is higher than a certain threshold, the refined mask is chosen. This process encourages HQ-SAM to focus on refining the current object mask rather than re-predicting another target object, thus improving segmentation performance.
Experiments
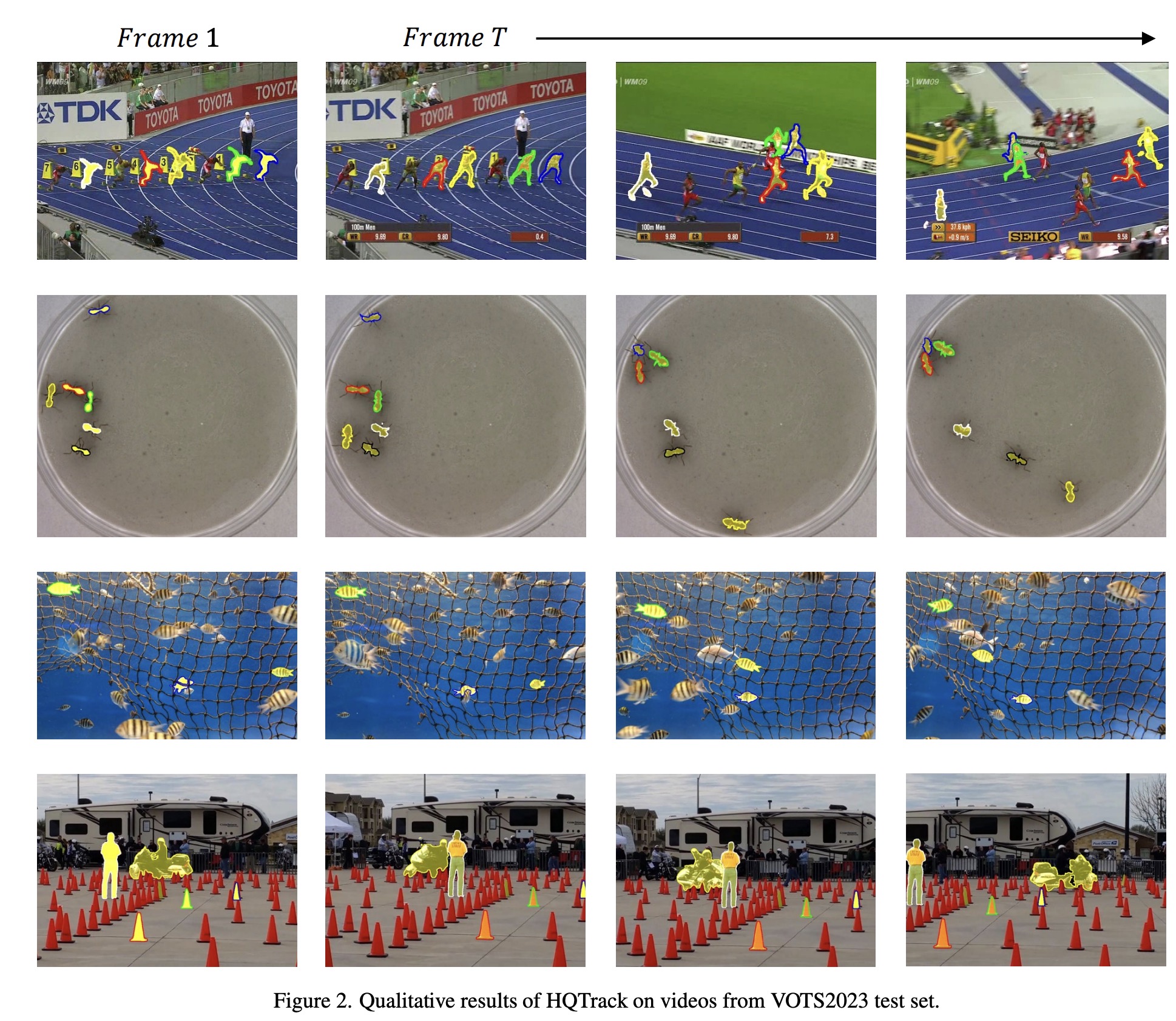
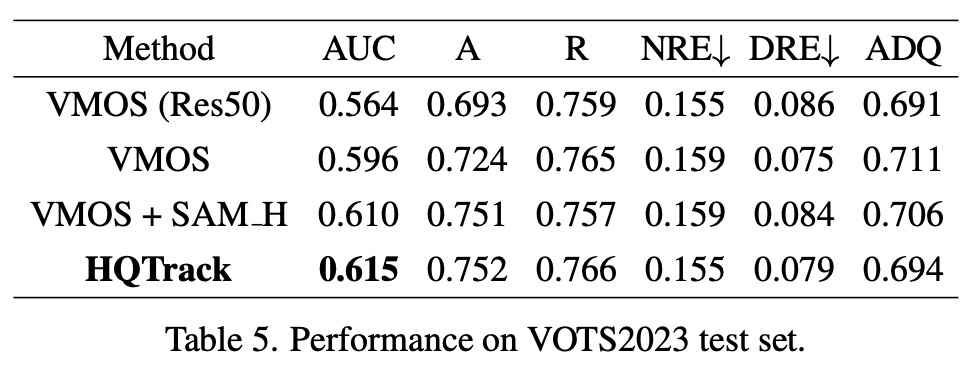
Ablation Study
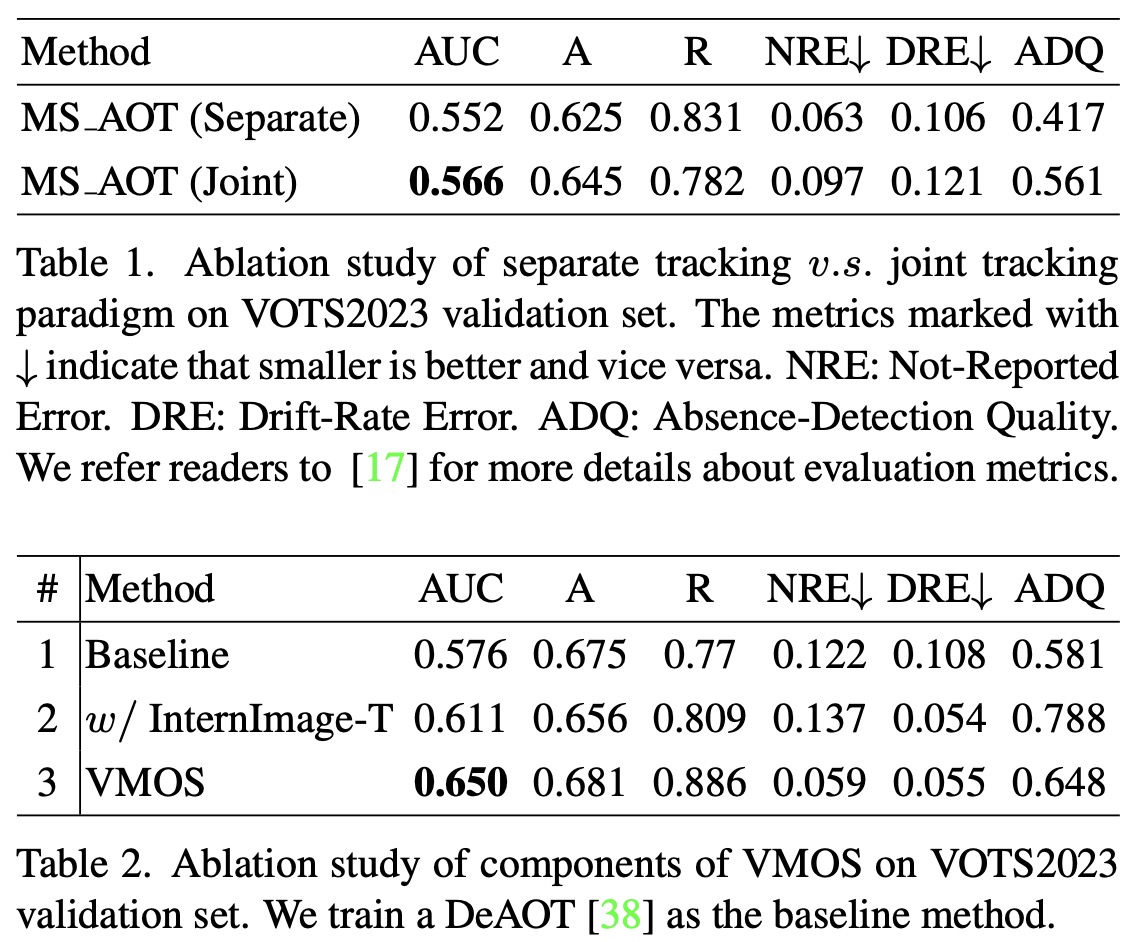
- In an ablation study on different tracking paradigms, it was found that joint tracking, which uses a single tracker for all target objects, performs better than separate tracking, where each target object is tracked separately. The better performance of joint tracking is likely due to the tracker’s understanding of the relationships between target objects, improving robustness against distractor interference.
- Component-wise studies on the Video Multiple Object Segmenter (VMOS) show that replacing the original ResNet50 backbone with InternImage-T, and adding a multi-scale propagation mechanism, result in a substantial improvement in performance. The Area Under the Curve (AUC) score increased from 0.611 to 0.650, confirming the effectiveness of these modifications.
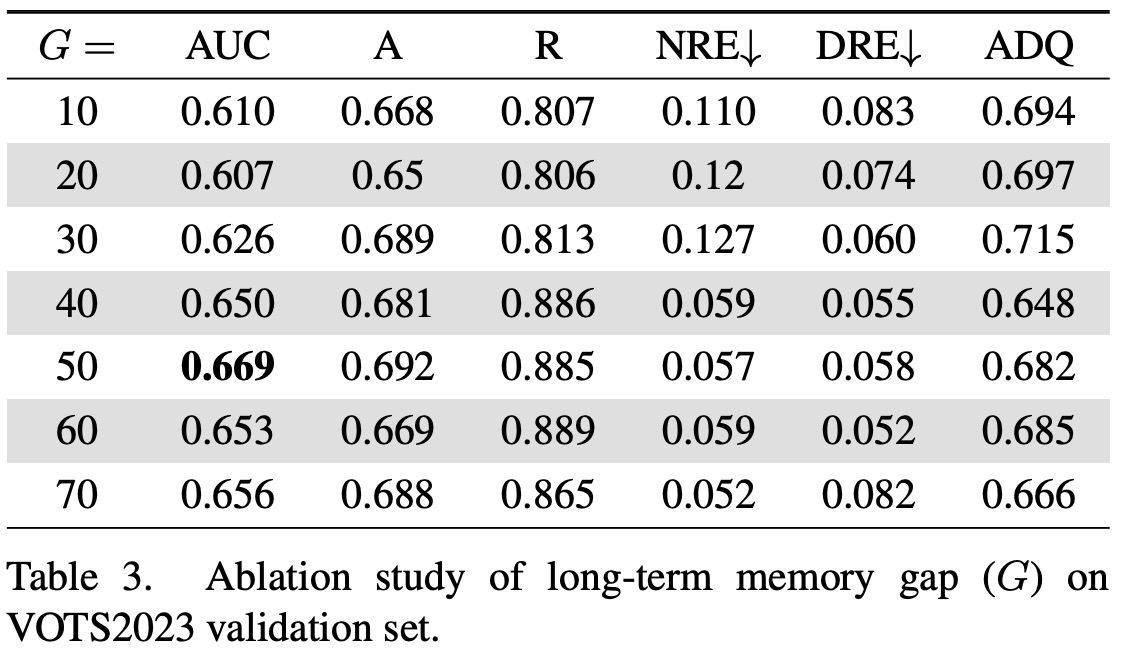
- Considering the long sequences in the Visual Object Tracking and Segmentation (VOTS) videos, the long-term memory gap parameter was reevaluated. The study found that a memory gap of 50 offers the best performance.
- The Mask Refiner (MR), a component of the HQTrack, was also examined. It was found that directly refining all segmentation masks is not optimal. Refining masks with the SAM results in significant improvement, but harms performance for low-quality masks. Therefore, a selection process was proposed: when the Intersection over Union (IoU) score between the masks from VMOS and SAM is higher than a threshold, the refined mask is chosen as the final output.