Paper Review: Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning

Husky is an open-source language agent designed to handle diverse complex tasks, including numerical, tabular, and knowledge-based reasoning. Unlike many existing agents that are proprietary or task-specific, Husky operates in a unified action space, alternating between generating actions and executing them with expert models to solve tasks. It uses a comprehensive set of actions and high-quality training data for expert models. Experiments demonstrate that Husky outperforms previous agents across 14 datasets and performs exceptionally well on a new evaluation set, HuskyQA, which tests mixed-tool reasoning and numerical tasks. Notably, Husky’s performance is comparable to leading models like GPT-4, even with 7B size.
The approach
Training

Husky lacks existing training data for next step prediction, tool calls, and generation of code, math, or search queries as it is a new framework. To address this, it leverages a teacher language model to create tool-integrated solution trajectories for training tasks. These trajectories are used to build training sets for various modules within Husky. The framework consists of an Action Generator, which determines the next step and tool to use, and Expert Models for code, math, and query generation.
Each module is trained on data extracted and formatted from the solution trajectories, using the task instruction, solution history, and current step as inputs. The modules are fine-tuned independently using a standard next token prediction objective.
Inference
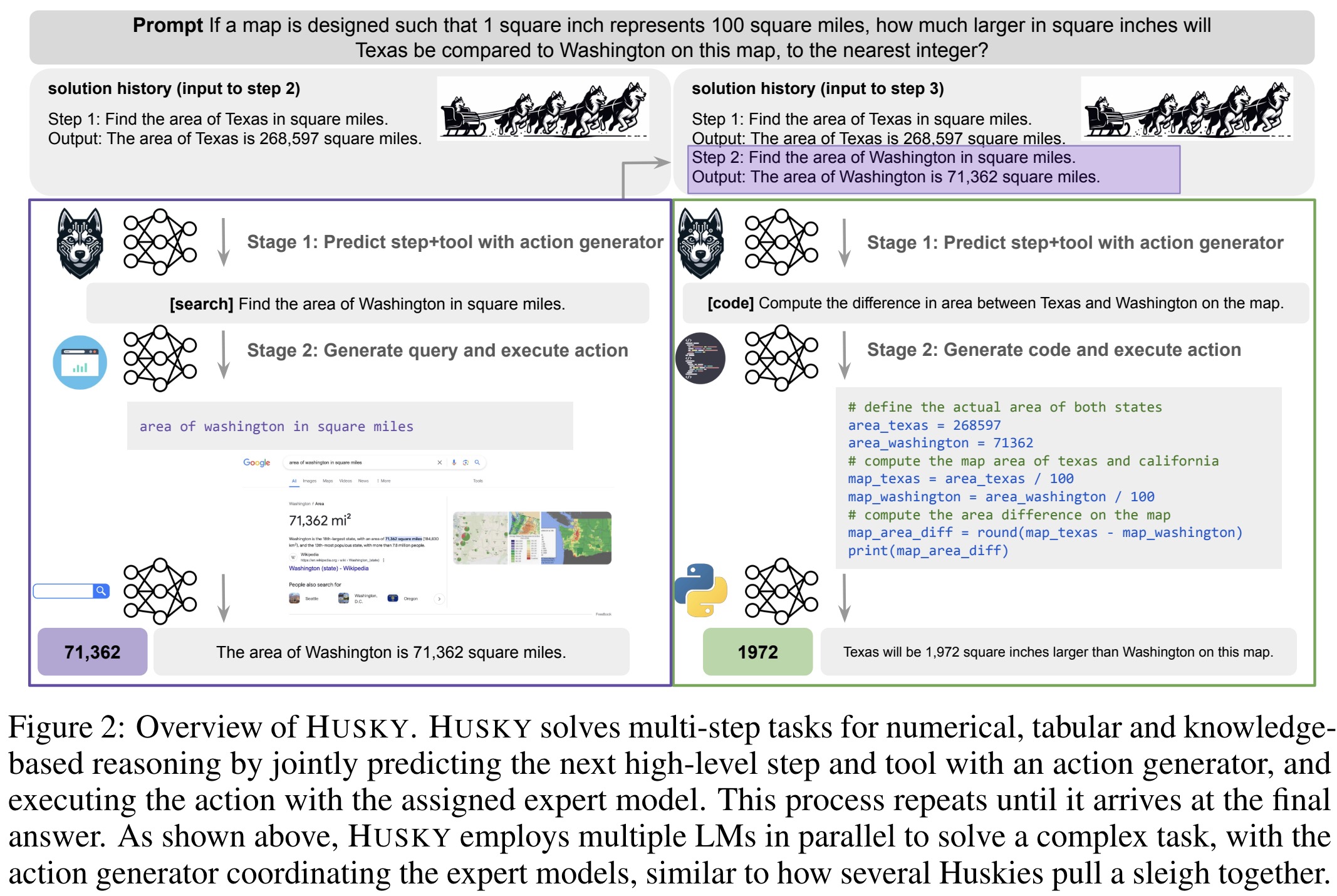
Husky performs inference in the following steps:
- Action generator determines the next step and appropriate tool for each stage of problem-solving
- Based on the selected tool, the corresponding Expert Model is activated: Code Generator for coding tasks, Math Reasoner for mathematical problems, Query Generator for search queries, Commonsense Reasoner for general reasoning and output rewriting
- The chosen Expert Model generated the output. For code and search outputs, the result is rewritten into natural language
- The step and its output are added to the solution history, which is used as input for the next iteration.
- This process repeats until the action Generator identifies the final answer.
Experiments
Base models for the modules:
- Action generator - LLAMA-2-7B and 13B, and LLAMA-3-8B.
- Code generator - DeepSeekCoder-7B-Instruct-V1.5
- Math reasoner - DeepSeelMath-7B-Instruct.
- Query generator - LLAMA-2-7B.
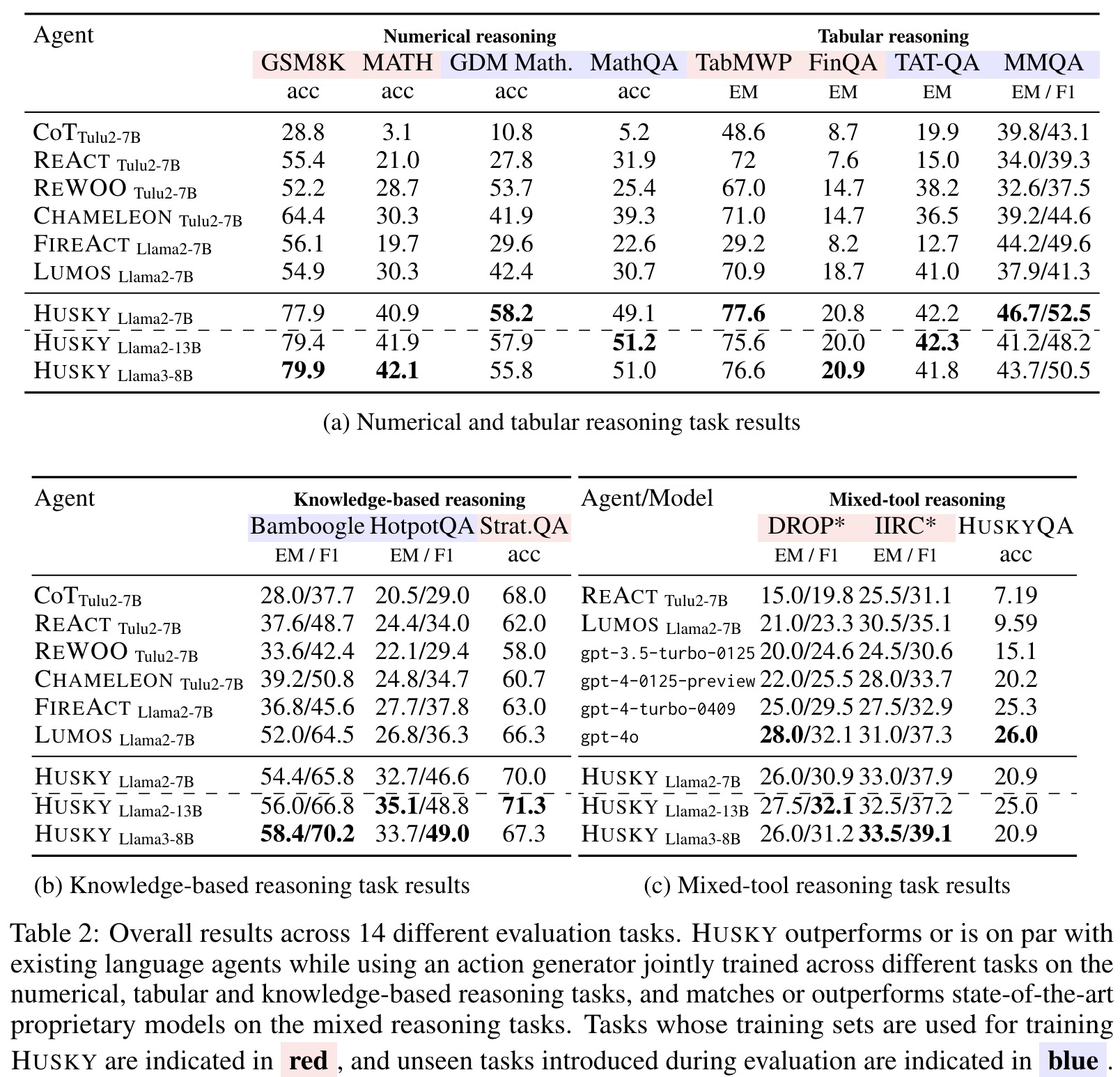
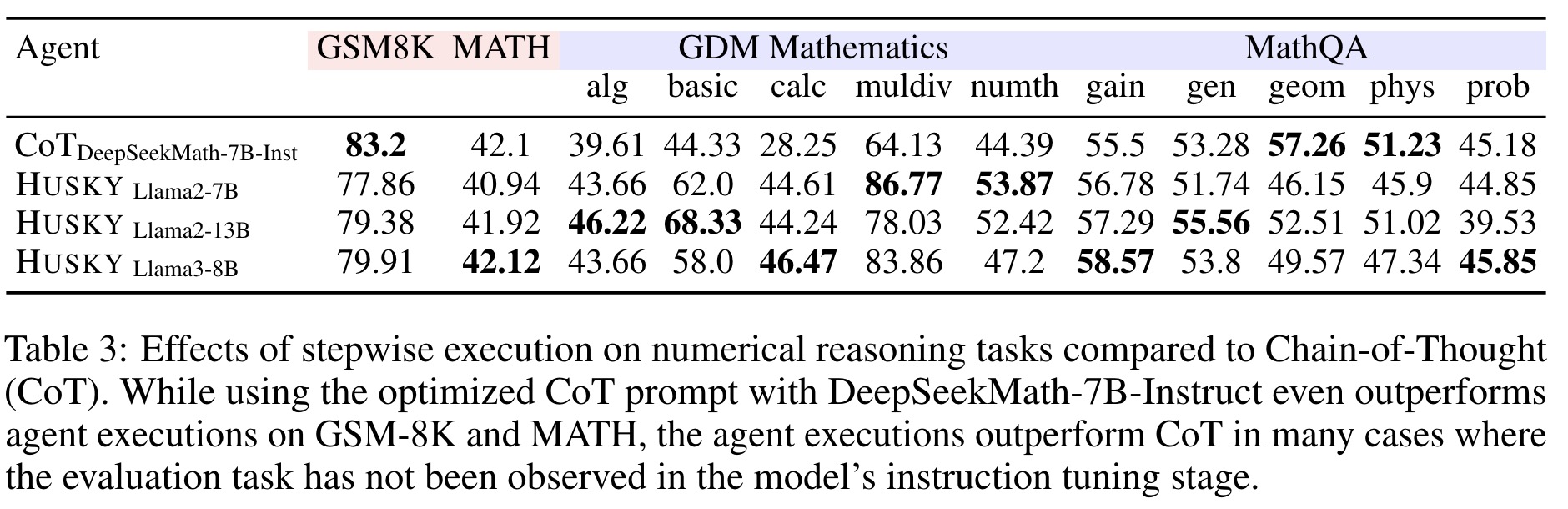
- Numerical Reasoning Tasks: Husky outperforms other agents by 10-20 points on both seen and unseen tasks. Its iterative stepwise execution proves effective for unseen math tasks, even when compared to state-of-the-art CoT prompts.
- Tabular Reasoning Tasks: Husky consistently outperforms baselines on both seen and unseen tasks, benefiting from its exposure to tabular data during training.
- Knowledge-based Reasoning Tasks: Husky outperforms other agents, including task-specific ones, even on unseen tasks. It achieves this without using highly specialized tools like Wikipedia passage retrievers.
- Mixed Reasoning Tasks: Husky outperforms most baselines and competes with or outperforms advanced proprietary models like GPT-3.5 and GPT-4 variants. It demonstrates strong generalization across various domains in multi-tool reasoning strategies.
Analysis
Cross-task Generalization
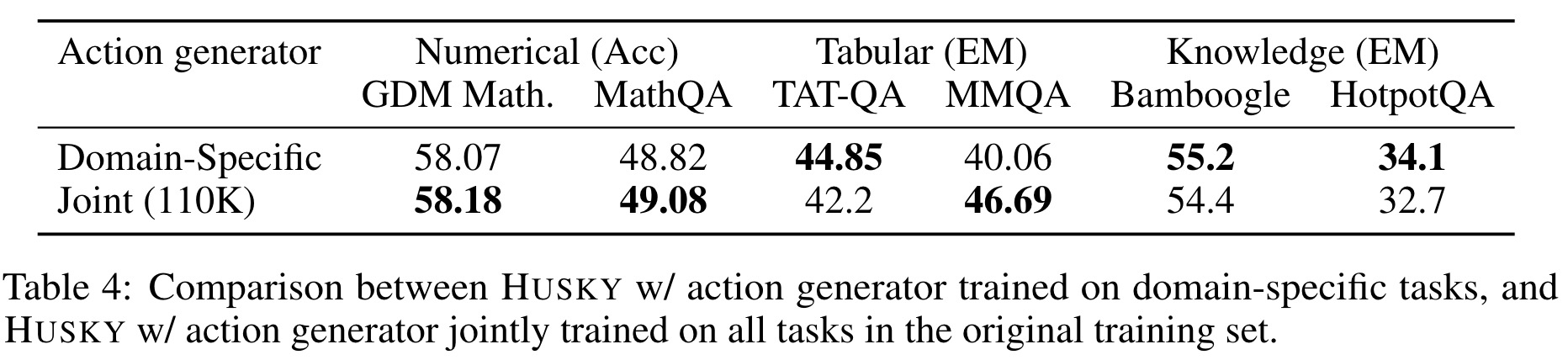
Husky’s action generator, trained jointly across different reasoning tasks, shows comparable performance to domain-specific training. While some tasks slightly benefit from domain-specific training, the differences are generally small, indicating that joint training preserves performance across domains and suggests potential for scaling to more diverse tasks.
Tool Choice
Testing different models for code generation and math reasoning showed that specialized models outperform general language models. However, strong general models like Llama-3-8B also showed competitive performance, especially in coding tasks.
Husky Llama3-8B-all
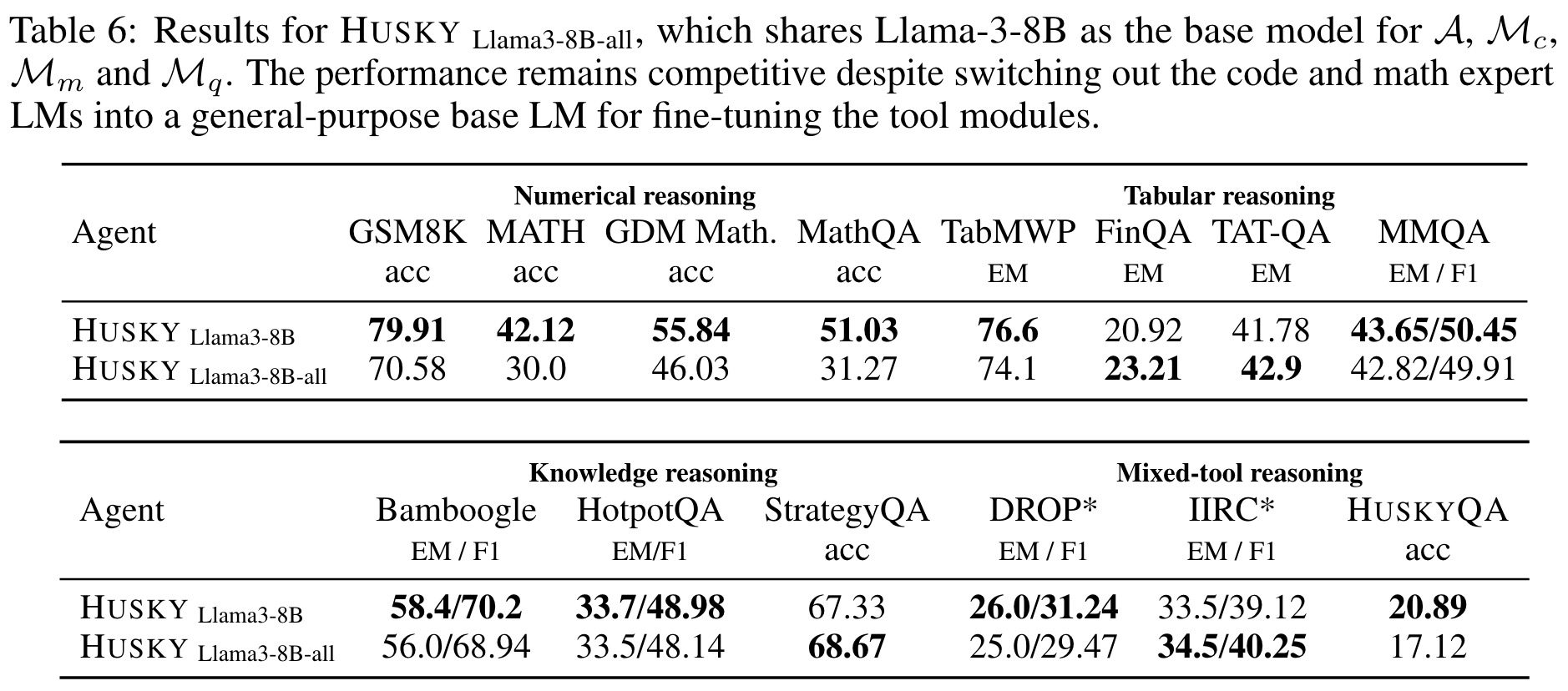
A version of Husky using Llama-3-8B for all components demonstrated similar performance to the specialized version in most tasks, except for numerical reasoning. This suggests that fine-tuning all modules from a single, capable base model can yield robust performance across various tasks, while simplifying development.
paperreview deeplearning llm agent