Paper Review: Hyena Hierarchy: Towards Larger Convolutional Language Models
Transformers are currently widely used in deep learning thanks to their ability to learn at scale. However, attention exhibits quadratic cost in sequence length, limiting the amount of context accessible. Current subquadratic methods, like low-rank and sparse approximations, require dense attention layers to achieve comparable performance.
The authors introduce Hyena, a subquadratic drop-in replacement for attention, which combines implicitly parametrized long convolutions and data-controlled gating. Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
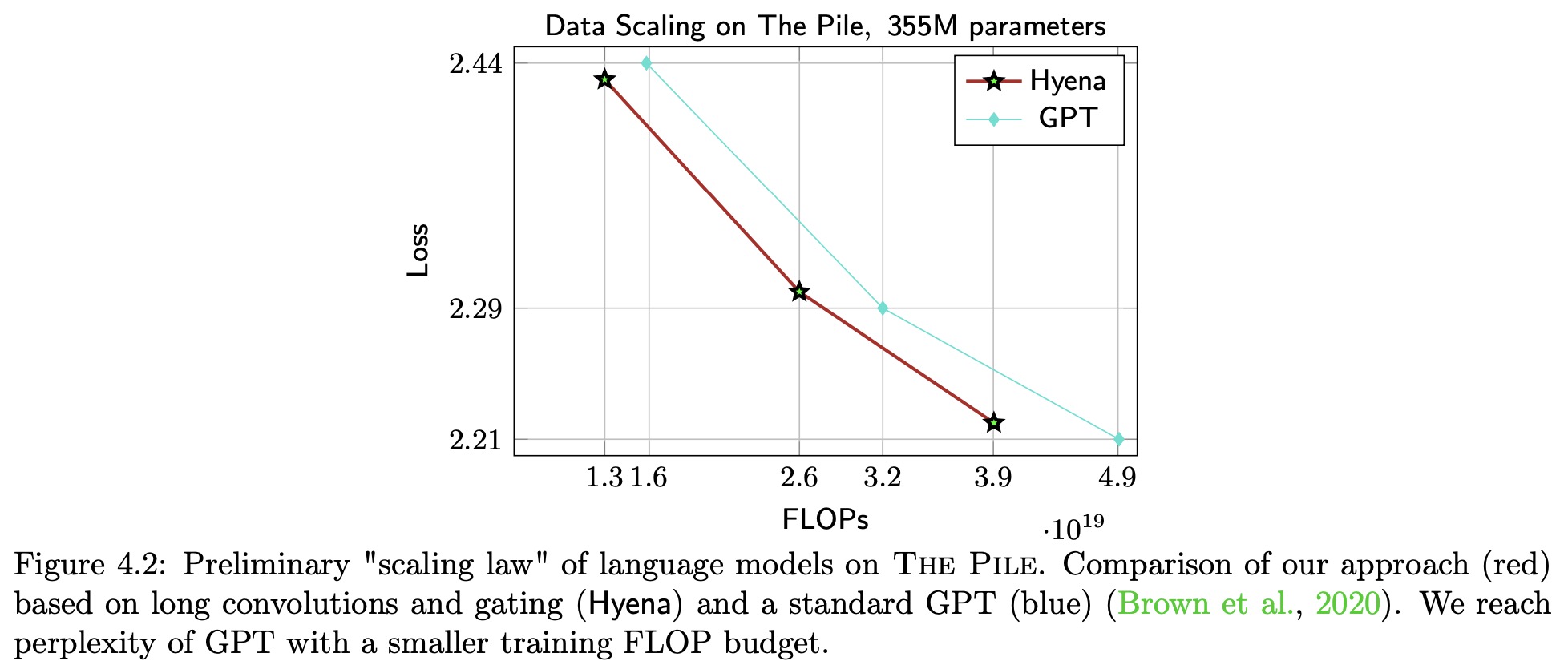
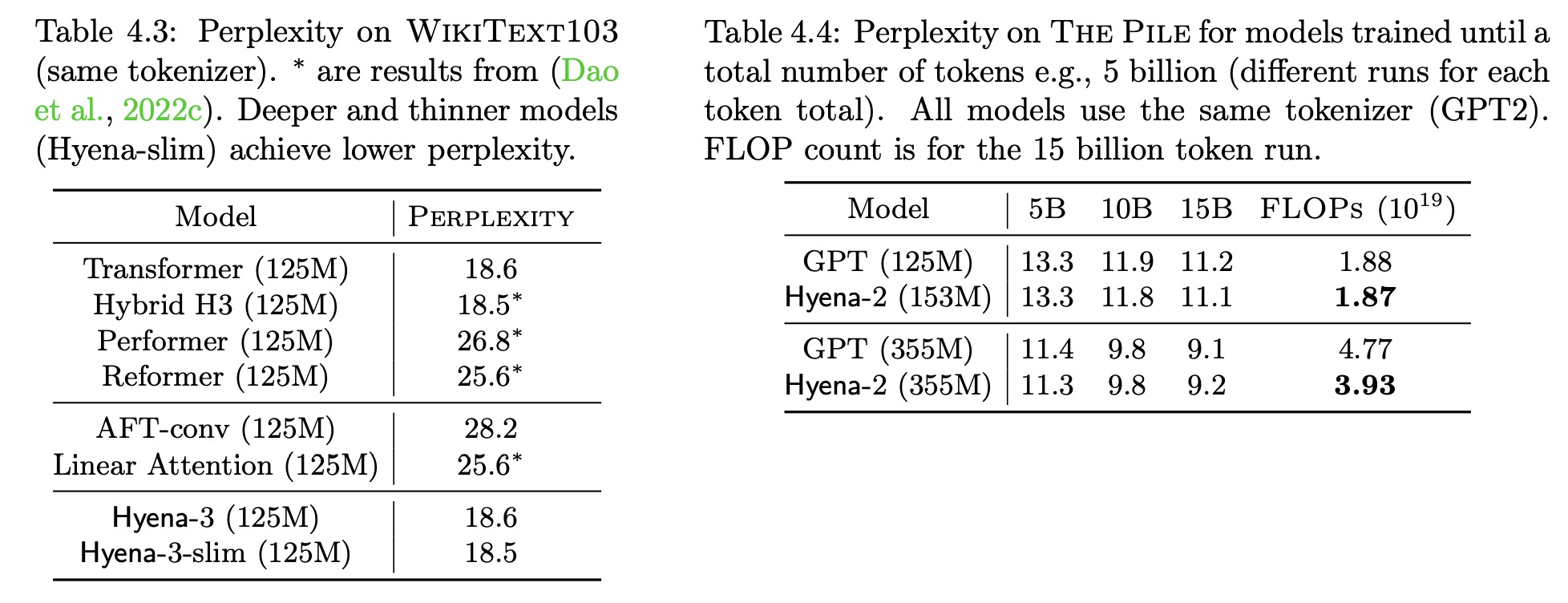
It sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. Furthermore, Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
General approach

While attention mechanisms are effective for language processing, the paper suggests that there may be subquadratic operators that can match its quality at scale. Based on targeted reasoning tasks, the authors distill three properties of attention that contribute to its performance: data control, sublinear parameter scaling, and unrestricted context. Then they introduce the Hyena hierarchy, a new operator that combines long convolutions and element-wise multiplicative gating to match the quality of attention at scale while reducing computational cost. Empirically, the Hyena hierarchy is shown to significantly shrink the quality gap with attention, reaching similar performance with a smaller computational budget and without hybridization.
Hyena
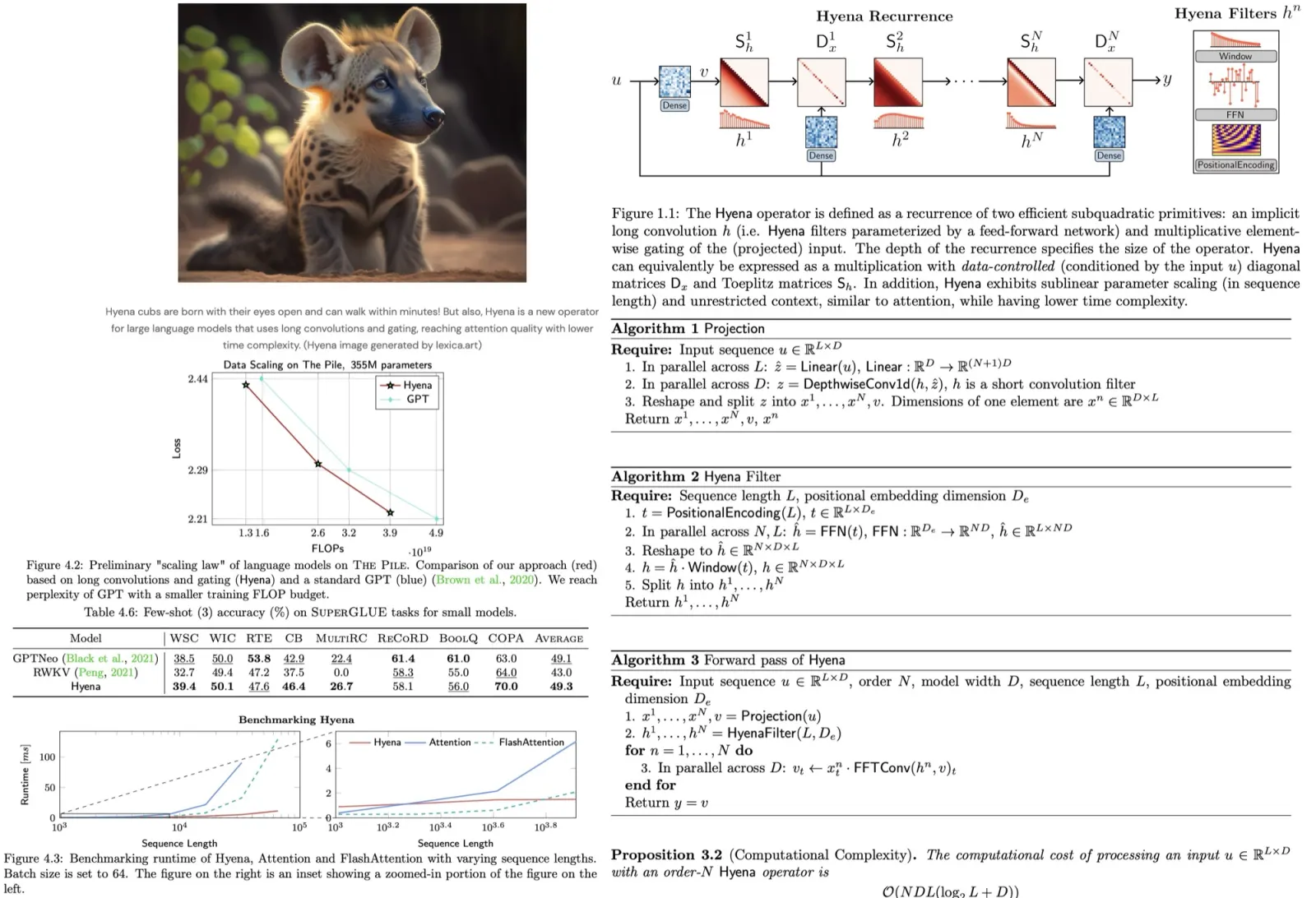
Hyena Recurrencies

The Hyena operator involves taking a set of linear projections of the input, and combining them using long convolutions and element-wise multiplication. The operator alternatively applies convolutions in the time and frequency domain, or element-wise multiplication in the time and frequency domain. This helps the model to better understand the context of the input and select specific parts of it. This new approach is more efficient than the traditional attention mechanism, which is widely used in deep learning models, and can provide similar performance with less computational cost.
Hyena Matrices
The Hyena operator is a new way of processing information in deep learning models that builds on a previous method called H3. The H3 method uses a special kind of matrix to help the model understand relationships between different pieces of information. The Hyena operator extends this approach to an arbitrary number of projections and with implicit long filters for the convolutions. This new approach helps deep learning models to work more efficiently and accurately.
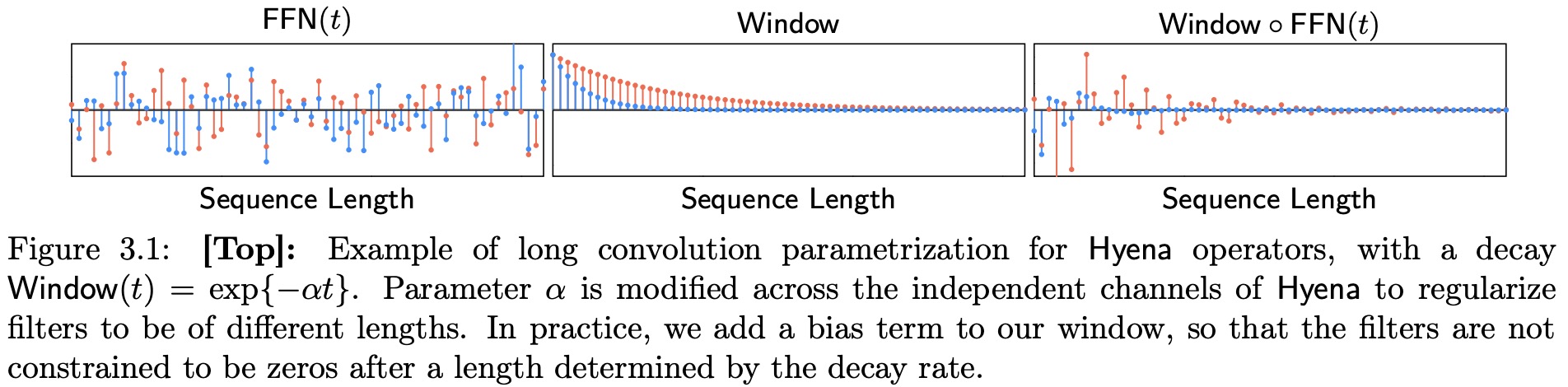
Hyena Filters
The Hyena operator uses a parametrized convolution to help deep learning models understand relationships between different pieces of information. The filters for each Hyena operator are learned with a shallow feed-forward neural network. The use of a window and positional encoding function helps specialize the filters, biasing them towards a specific type. The parametrized causal convolutions ensure that the output at a given position depends only on the past, which is necessary for training autoregressive language models. The evaluation of the filters is fast and can be performed in parallel, increasing hardware utilization. Low utilization of hardware accelerators and the FFT bottleneck can be partially addressed through blocking and optimization of the underlying routines.
Hyena Algorithm

Experiments
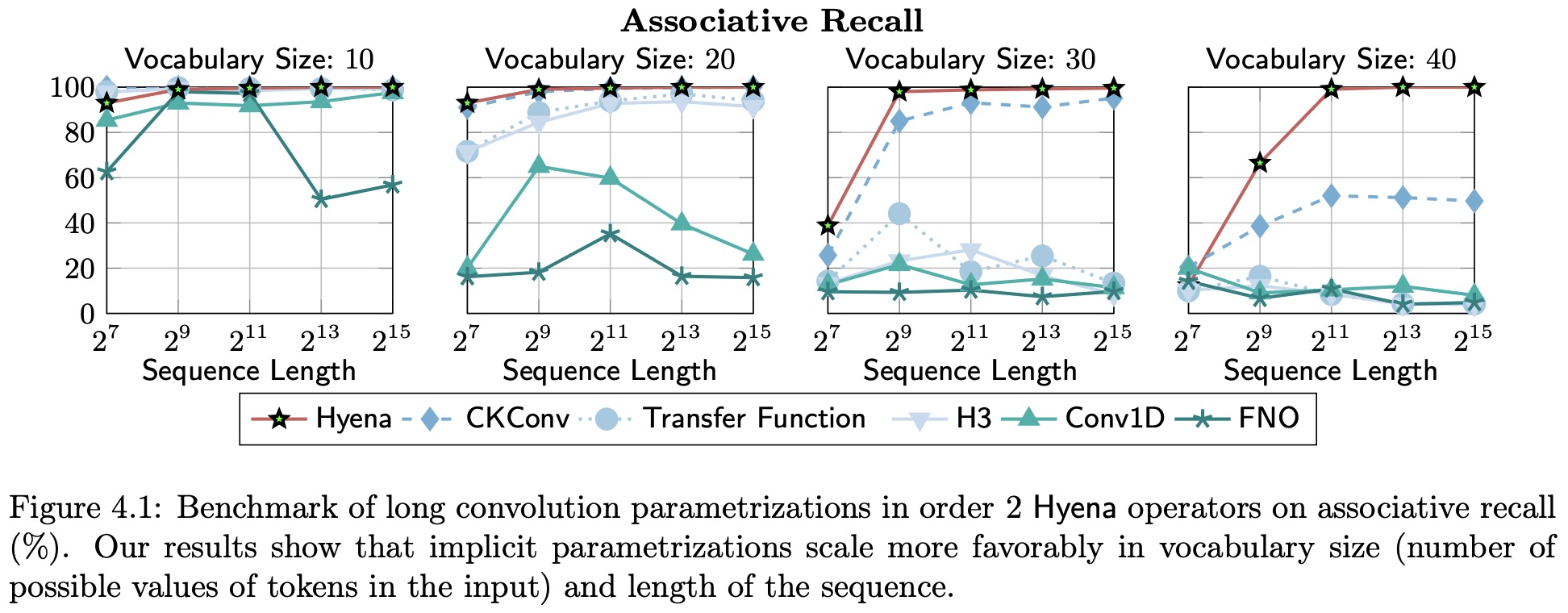
- The authors try different approaches to long convolution parametrization;
- They evaluate associative recall performance on extremely long sequences of length 131k;
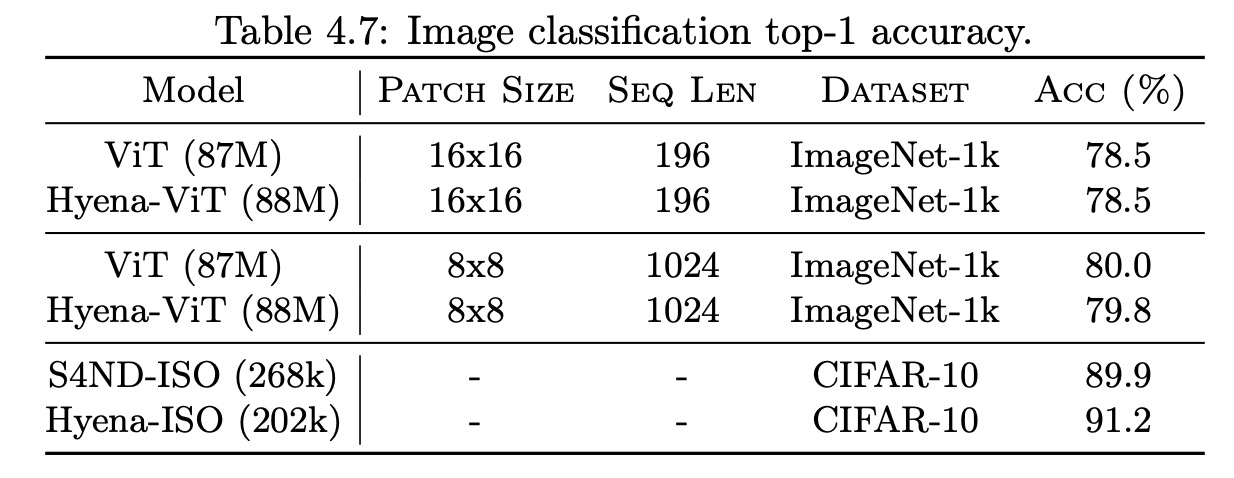
- They apply Hyena to CIFAR dataset proving that it can also be applied successfully beyond language tasks;