Paper Review: In-Context Instruction Learning
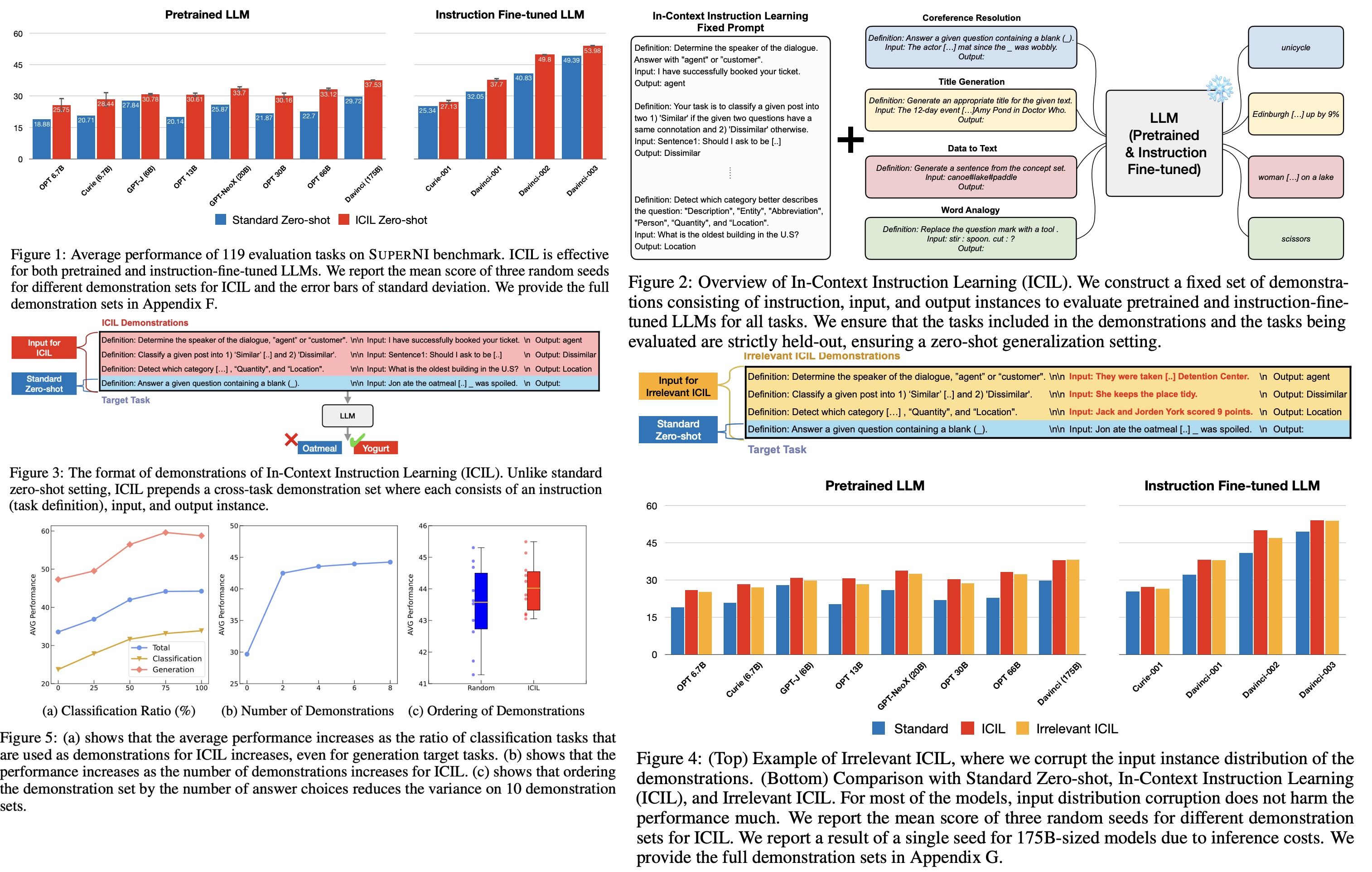
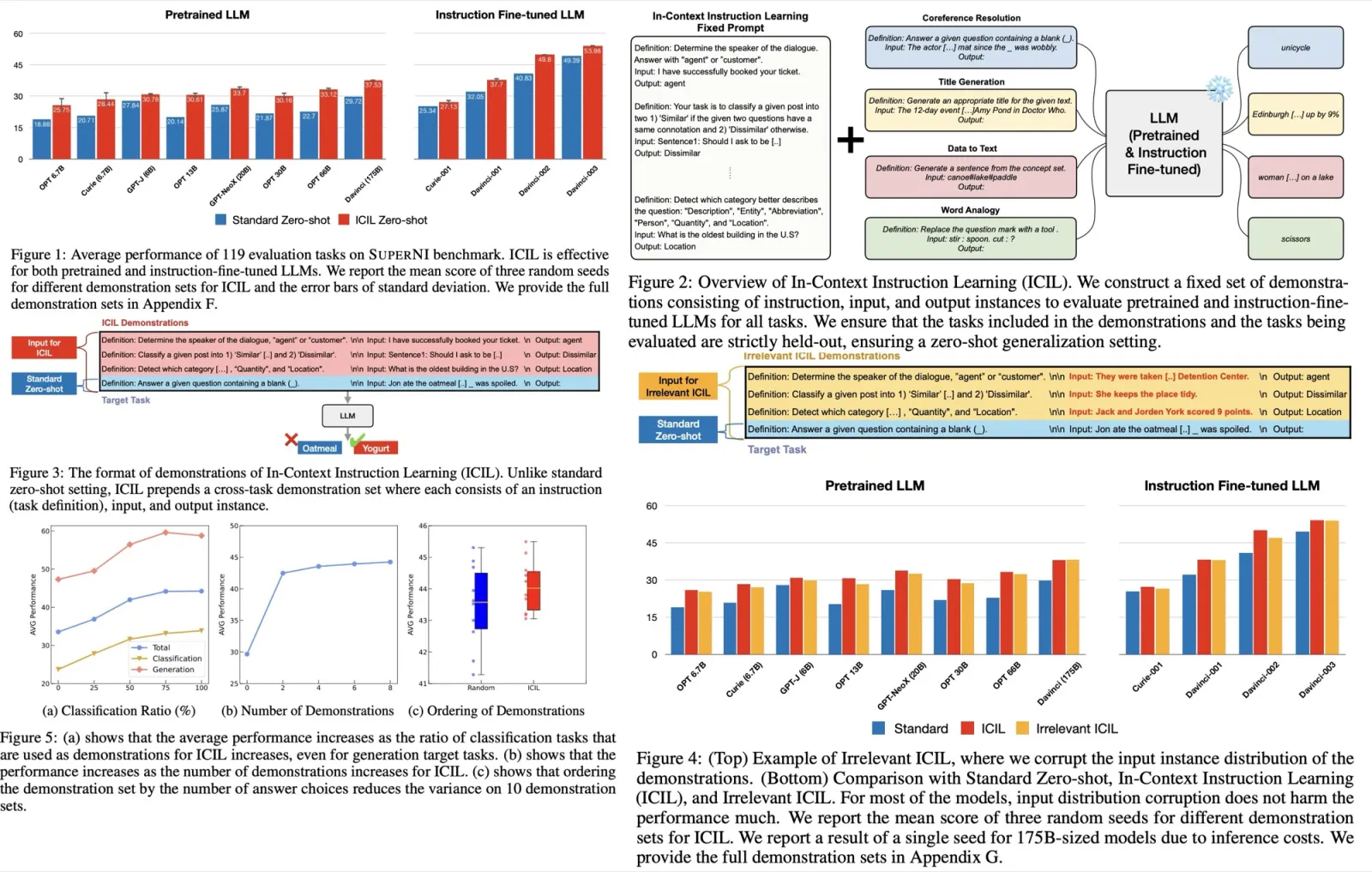
The authors present a new approach called In-Context Instruction Learning (ICIL) which significantly improves the zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL uses a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that the most powerful instruction-fine-tuned baseline (text-davinci-003) also benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
The approach
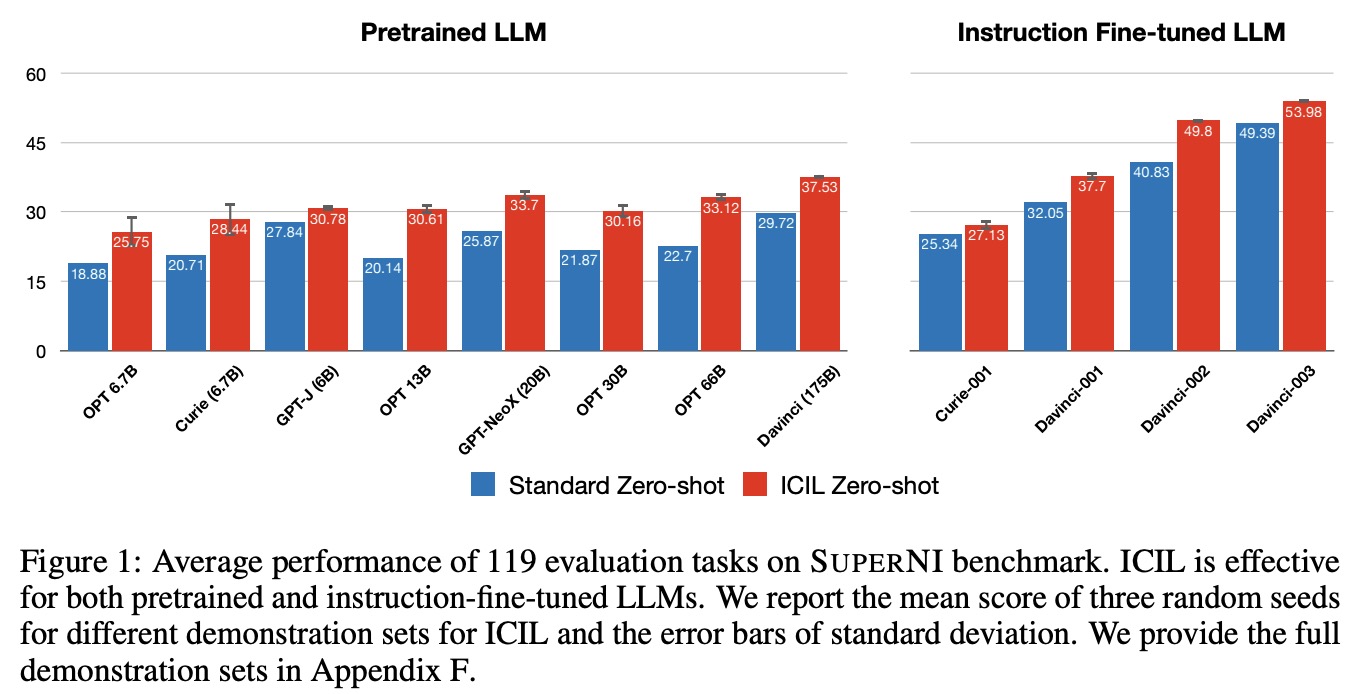
ICIL uses a prompt that consists of multiple cross-task demonstrations and is a zero-shot learning method. ICIL significantly enhances the zero-shot task generalization performance of various pretrained LLMs and improves the zero-shot instruction-following ability of LLMs that are instruction-fine-tuned. The effectiveness of ICIL comes from selecting classification tasks that include explicit answer choice in the instruction, even for generation target tasks. The authors hypothesize that LLMs learn the correspondence between the answer choice included in the instruction and output of each demonstration during inference. ICIL helps LLMs focus on the target instruction to find the cues for the answer distribution of the target task.
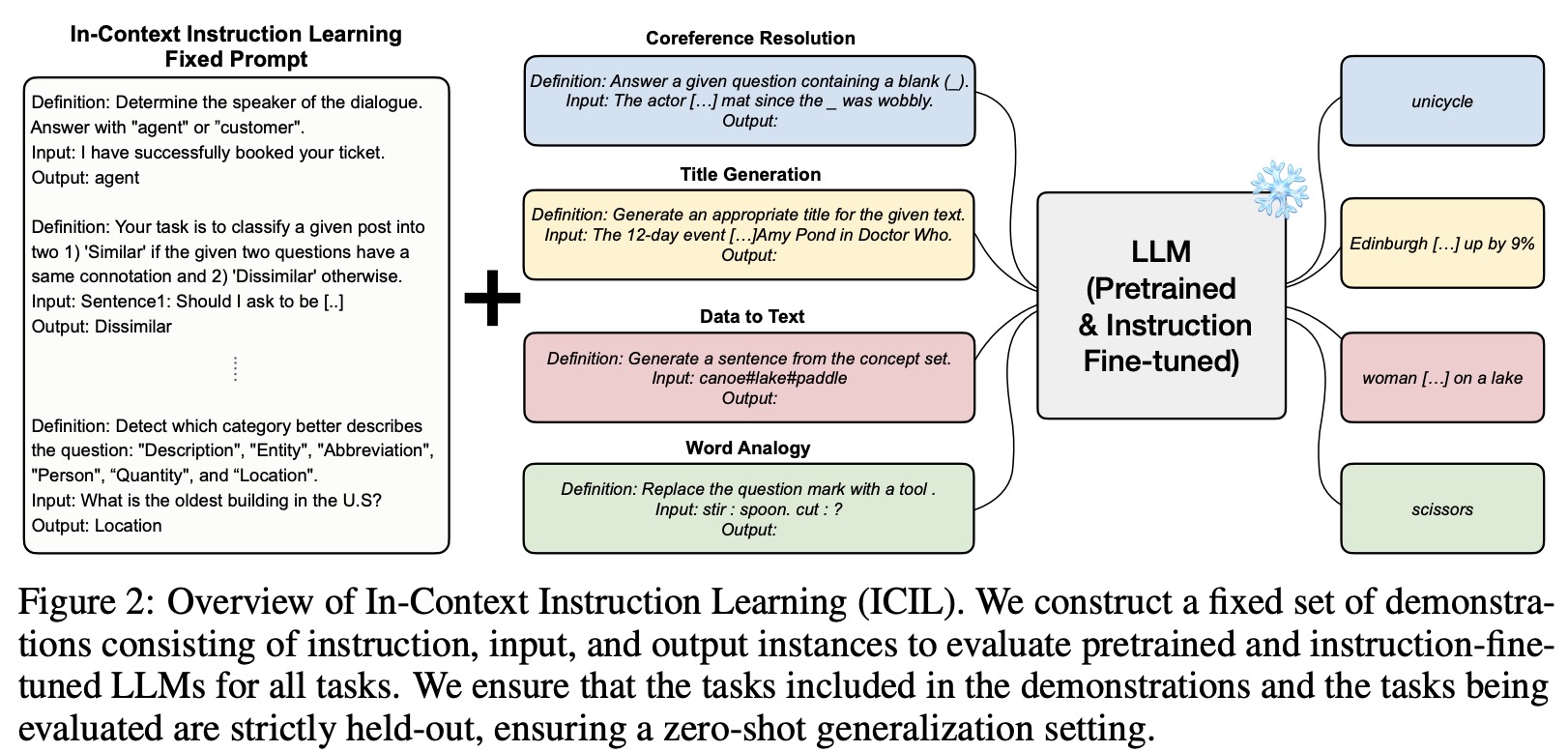
The prompt for In-Context Instruction Learning (ICIL) consists of cross-task demonstrations where each is a concatenation of instruction, input, and output instance.
Demonstration Set Construction
The authors select K tasks from N (8 by default), where each task consists of instruction, input, and output instance. The heuristics for task filtering involve:
- Selecting tasks that are classification tasks with an answer choice in the instruction;
- Ensuring that the answer choices do not overlap between demonstrations;
- Restricting the length of the demonstration to 256 tokens;
- Ordering the demonstrations by the number of answer choices for each task in ascending order;
In-Context Instruction Learning During Inference
After demonstration set sampling, the authors construct the fixed set of demonstrations and append the concatenation of instruction and input instance of the target task to the fixed prompt consisting of demonstrations.
The advantages of the approach are the following:
- ICIL uses a single fixed prompt to adapt various models to various target tasks, so it is easy to replicate and measure as a zero-shot baseline for new models or datasets;
- ICIL significantly improves the zero-shot task generalization performance for various off-the-shelf pretrained LLMs and also improves the performance of instruction-fine-tuned models;
- ICIL can assist LLMs for zero-shot generalization even after instruction tuning or RLHF, implying the wide applicability of ICIL;
- the model-generated demonstration set is effective for ICIL. This indicates that ICIL is effective even without sampling the demonstration set from a benchmark if the heuristics are applied;
Experiments
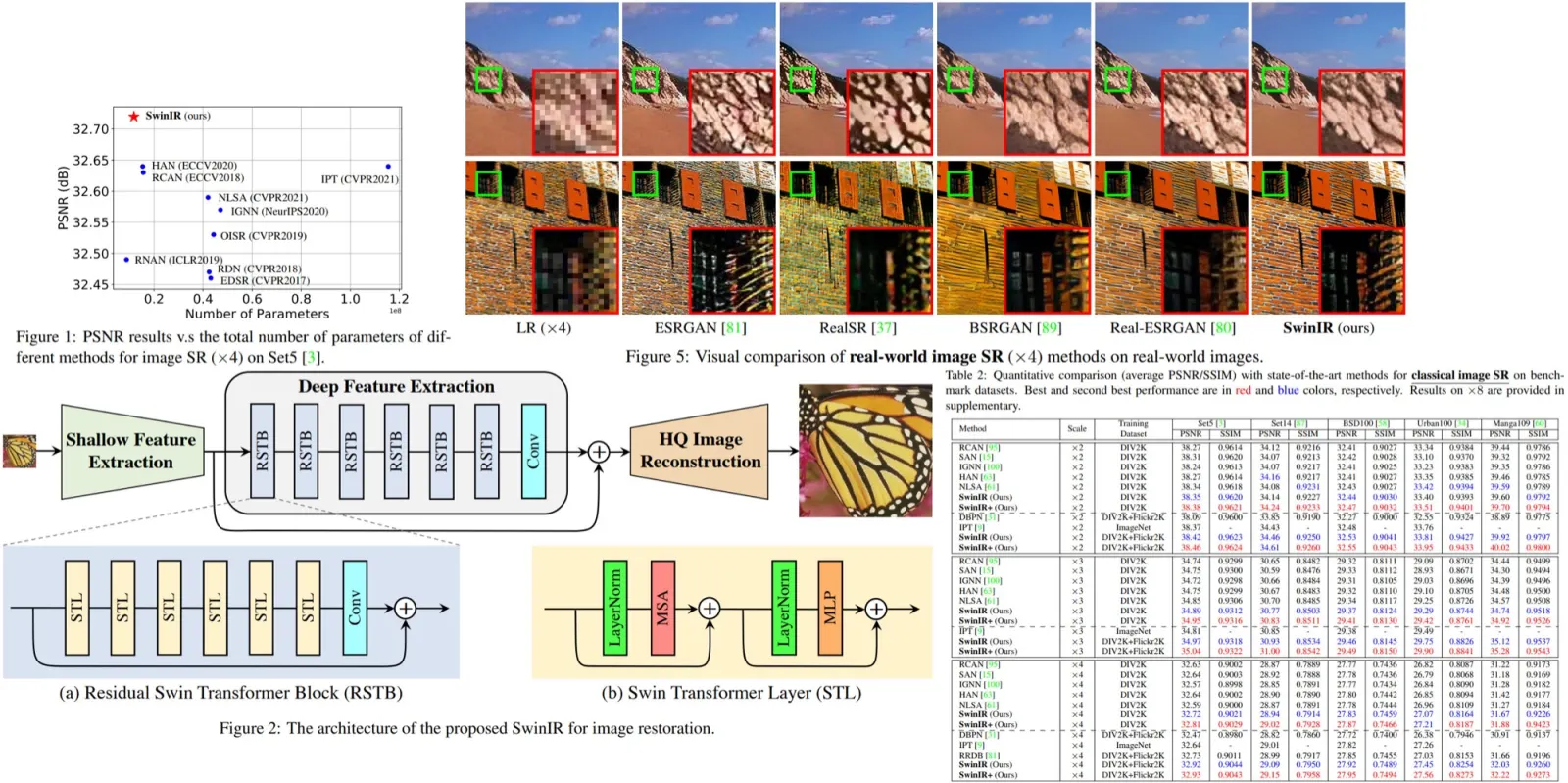
The authors construct demonstrations for ICIL from the English training tasks of the SUPERNATURALINSTRUCTIONS (SUPERNI) benchmark, which includes 756 tasks in total. They use held-out tasks from SUPERNI for testing, consisting of 119 tasks across 12 different categories. They evaluate 4 LLMs with various model sizes: GPT-3, OPT, GPT-NeoX, and GPT-J. For GPT-3, they evaluate pretrained LLMs and LLMs that are fine-tuned to follow instructions and aligned to human preferences through reinforcement learning. They evaluate models with sizes of 6.7B and 175B for GPT-3, models with 6.7B, 13B, and 30B parameters for OPT, and models with 20B and 6B parameters for GPT-NeoX and GPT-J, respectively.
Results
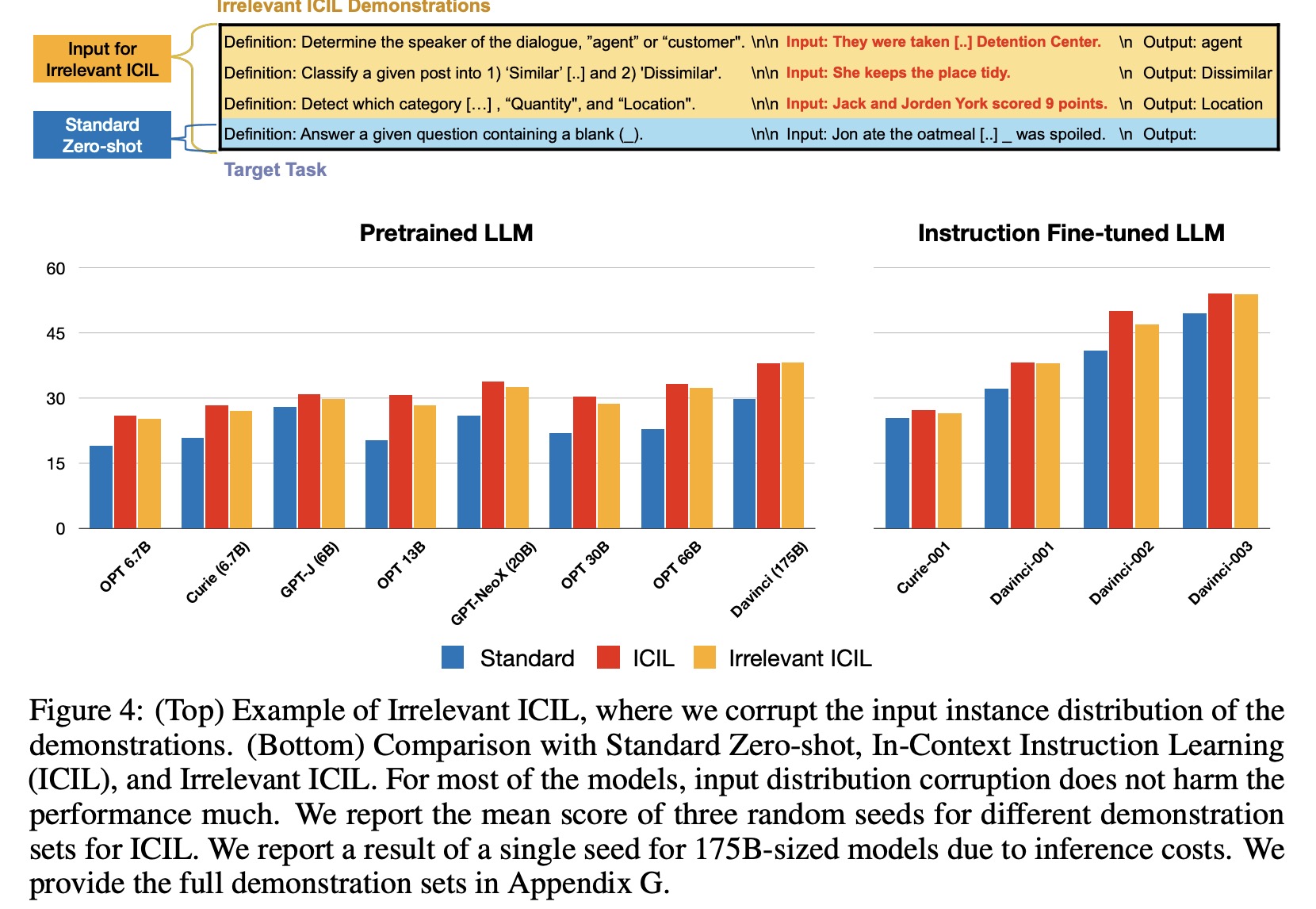
Analysis

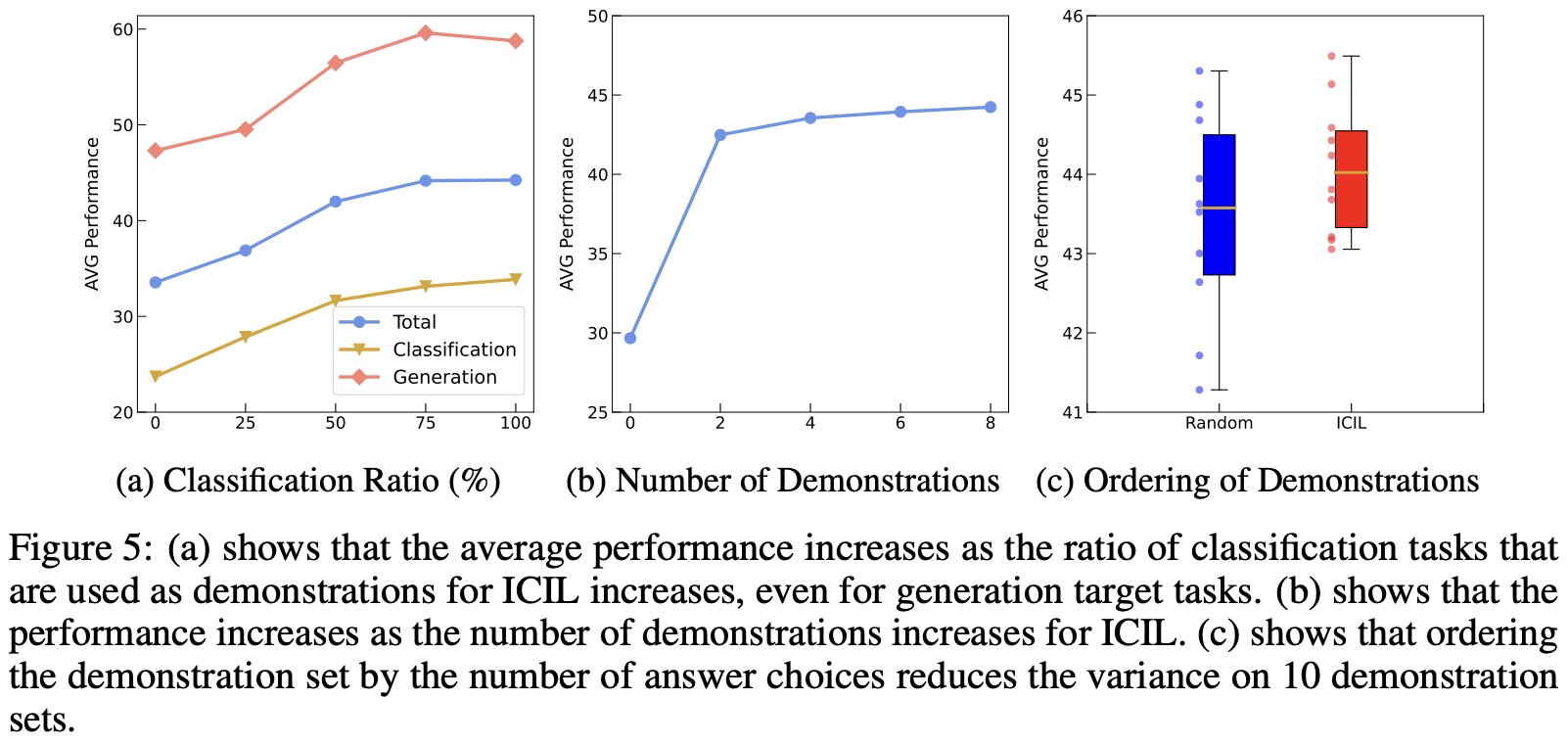
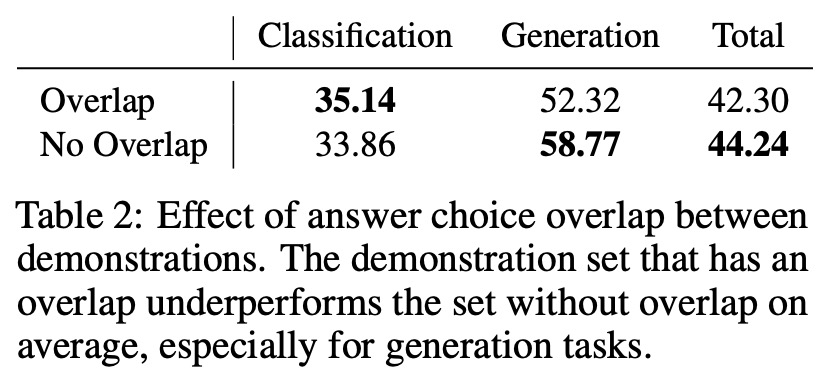
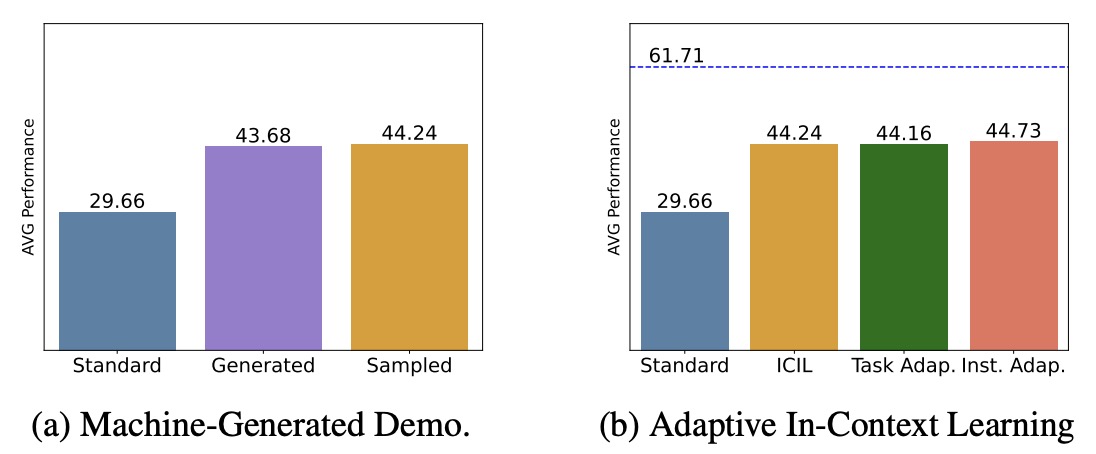
- Instruction and output distribution of the demonstrations matters;
- Constructing the demonstration set with classification tasks is important;
- Increasing the number of demonstrations improves the performance;
- Ordering the demonstrations by the number of answer choices reduces the variance;
- Answer choice overlap between demonstrations harms the performance;
- ICIL shows effectiveness for machine-generated demonstration sets as well;
- The performance of ICIL is comparable to adaptive in-context learning methods;
The authors hypothesize that during inference, LLMs learn the correspondence between the answer choice in the instruction and the label of the demonstrations during ICIL. This is bolstered by the observation that the input distribution of demonstrations for ICIL does not matter much, while instruction and output distribution matter significantly. They suggest that the role of ICIL is to give a signal that makes LLMs focus on the instruction to find the cues of the answer distribution, making LLMs better follow instructions. They hypothesize that ICIL reinforces the correspondence between the instruction and the label of the demonstrations during inference directly. The authors also support their hypothesis by showing that deleting only the sentence that includes answer choices in the instruction leads to a degradation in the performance of ICIL.
paperreview deeplearning nlp transformer sota