Paper Review: ImageBind: One Embedding Space To Bind Them All

ImageBind is a novel approach that enables learning of a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. This method asserts that training does not require all combinations of paired data, but only image-paired data is needed to bind all the modalities together. ImageBind can utilize large scale vision-language models to extend their zero-shot capabilities to new modalities through their natural pairing with images. The system enables new applications such as cross-modal retrieval, modality arithmetic, cross-modal detection, and generation.
It has set a new standard in emergent zero-shot recognition tasks across modalities, outperforming specialized supervised models. ImageBind also demonstrates strong few-shot recognition results, surpassing previous work, and provides a new method to assess vision models for both visual and non-visual tasks.
Method

The objective is to create a single joint embedding space for all modalities, utilizing images as the binding factor. Each modality’s embedding is aligned with image embeddings, for instance, text is aligned with images using web data, and IMU data is aligned with video using footage from egocentric cameras with IMU. The resultant embedding space exhibits a potent emergent zero-shot behavior, which can automatically associate pairs of modalities even without any specific training data for that particular pair.
Preliminaries
Contrastive learning, a technique that uses pairs of related and unrelated examples, can align pairs of different modalities such as image-text, audio-text, image-depth, and video-audio. However, these joint embeddings are only applicable for the same pairs of modalities they were trained on. For instance, video-audio embeddings aren’t useful for text-based tasks, while image-text embeddings aren’t useful for audio tasks.
CLIP popularized a “zero-shot” classification task using an aligned image-text embedding space, classifying an image based on its similarity to text descriptions in the embedding space. To extend zero-shot classification to other modalities, specific training with paired text data is typically required, such as audio-text or point-clouds-text.
Unlike these methods, ImageBind allows for zero-shot classification across different modalities without the need for paired text data. This makes it a more flexible and versatile tool for tasks involving multiple data modalities.
Binding modalities with images
ImageBind employs pairs of modalities (I,M), where I signifies images and M is another modality, to learn a single joint embedding. This is achieved using large-scale web datasets with image-text pairings that cover a broad spectrum of semantic concepts. It also leverages the natural, self-supervised pairing of other modalities – audio, depth, thermal, and Inertial Measurement Unit (IMU) – with images.
Each pair of modalities (I,M) with aligned observations is encoded into normalized embeddings using deep networks. The embeddings and encoders are then optimized using an InfoNCE loss. This process brings the embeddings of the image and the other modality closer together in the joint embedding space, effectively aligning them.
Interestingly, ImageBind has shown an emergent behavior that aligns two different modalities (M1,M2) even though it is trained using only the pairs (I,M1) and (I,M2). This behavior enables the system to perform a range of zero-shot and cross-modal retrieval tasks without specifically being trained for them. For instance, it achieves state-of-the-art zero-shot text-audio classification results without being exposed to any paired audio-text samples.
Implementation Details
ImageBind is a versatile approach with a straightforward implementation designed for effective study and easy adoption.
- The modality encoders are based on a Transformer architecture, including the Vision Transformer (ViT) for images and videos.
- Audio is encoded by converting a 2-second audio sample into spectrograms, which are treated as 2D signals and encoded using a ViT.
- Thermal images and depth images are treated as one-channel images and also encoded using a ViT.
- Depth is converted into disparity maps for scale invariance.
- IMU signals are projected using a 1D convolution, and the resulting sequence is encoded with a Transformer.
- Text encoding follows the design from CLIP.
Each modality - images, text, audio, thermal images, depth images, and IMU - has its own encoder, and a modality-specific linear projection head is added to each encoder to obtain a fixed size dimensional embedding. This embedding is normalized and used in the InfoNCE loss calculation. This setup not only simplifies learning, but also allows initialization of a subset of the encoders using pretrained models like CLIP or OpenCLIP.
Experiments
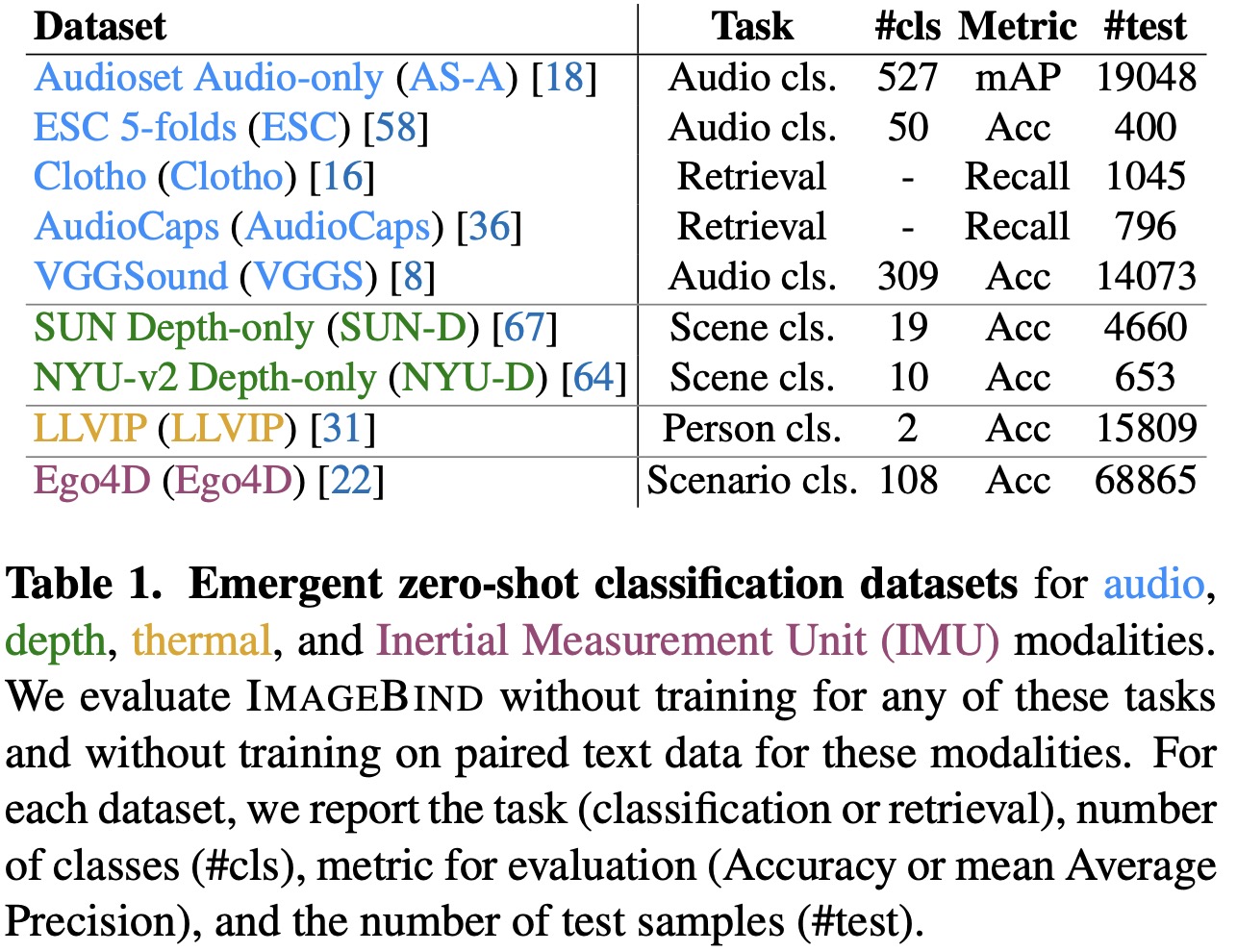
Emergent zero-shot classification
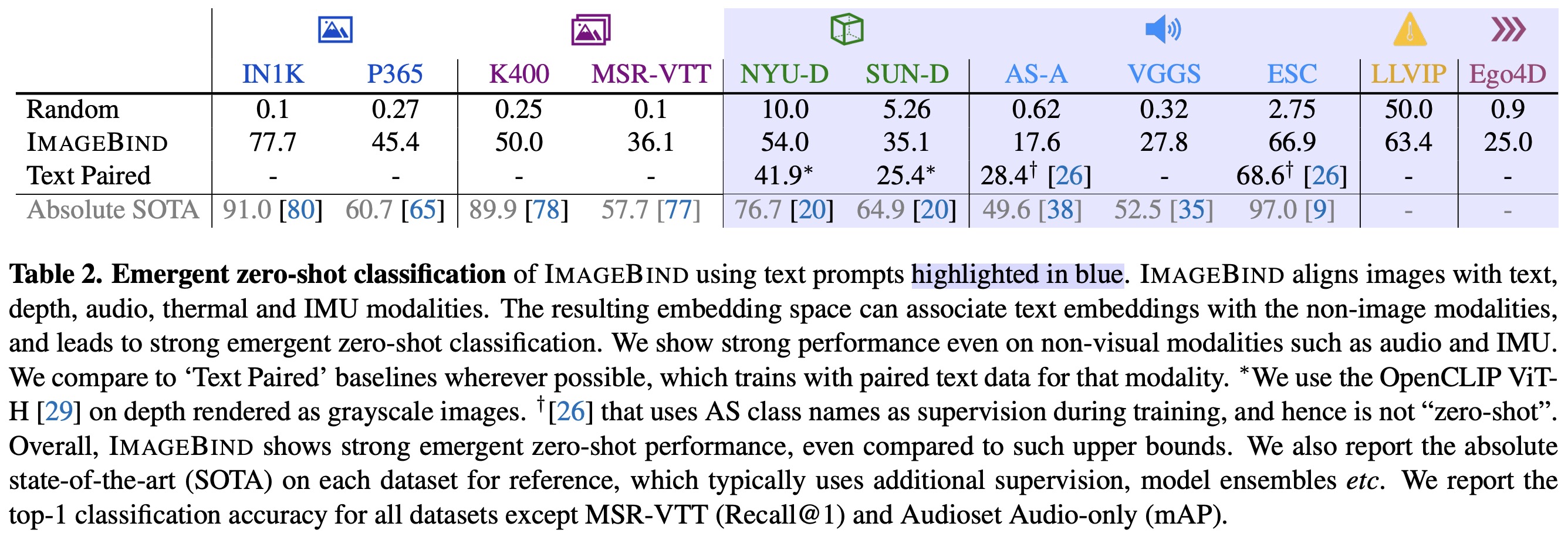
ImageBind is evaluated on emergent zero-shot classification tasks, using text prompt templates from prior work. Given the novelty of ImageBind’s problem setting, there are no directly comparable baselines, but it is compared to prior work that uses text paired with certain modalities. For “visual-like” modalities such as depth and thermal, the CLIP model is used for comparison. The best reported supervised upper bound per benchmark is also reported.
ImageBind exhibits high emergent zero-shot classification performance, achieving significant gains on each benchmark and comparing favorably to supervised specialist models trained specifically for each modality and task. This suggests that ImageBind effectively aligns modalities and transfers the text supervision associated with images to other modalities like audio. It shows strong alignment for non-visual modalities like audio and IMU, indicating the power of their natural pairing with images.
ImageBind also reports results on standard zero-shot image and video tasks. Since the image and text encoders are initialized and frozen using OpenCLIP, these results match those of OpenCLIP.
Comparison to prior work
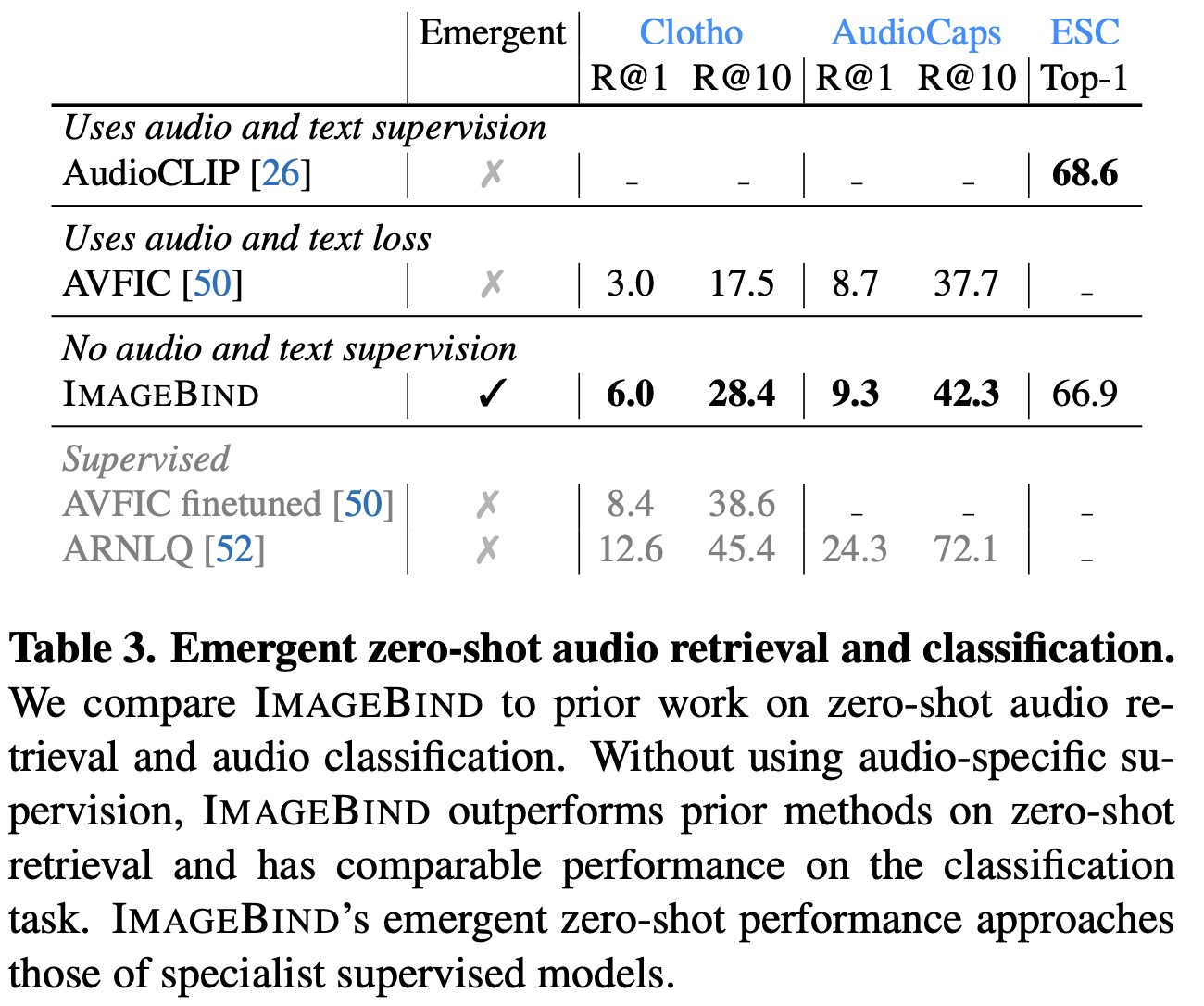
On the Clotho dataset, ImageBind’s performance is double that of AVFIC, even though it doesn’t use any text pairing for audio during training. Against the supervised AudioCLIP model, ImageBind achieves similar audio classification performance on ESC. This strong performance validates ImageBind’s ability to align the audio and text modalities using images as a bridge.
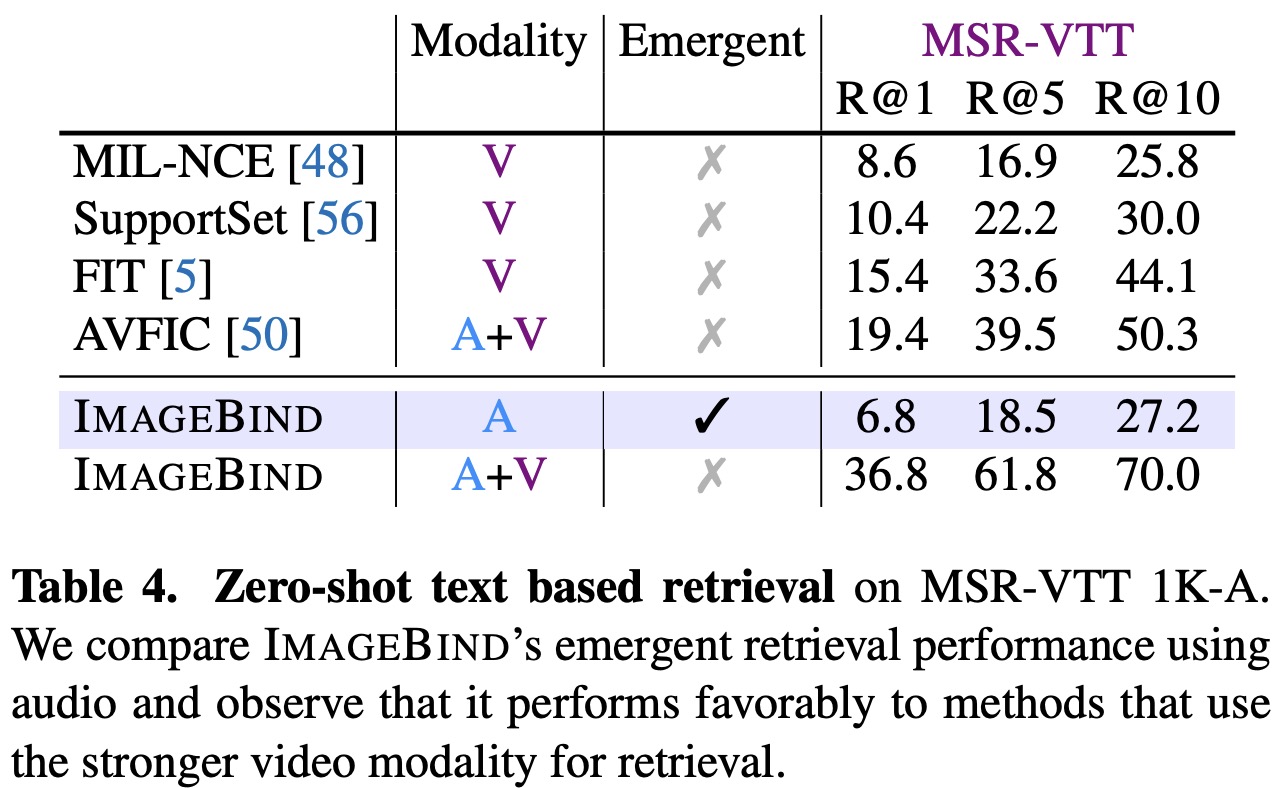
For text to audio and video retrieval, ImageBind’s performance on the MSR-VTT 1k-A benchmark is strong, even when using only audio. It outperforms many prior methods, such as MIL-NCE. When combining audio and video modalities, ImageBind’s performance is further boosted, demonstrating its utility over other existing retrieval models.
Few-shot classification

ImageBind’s label-efficiency is evaluated through few-shot classification tasks, using audio and depth encoders on audio and depth classification respectively. When compared to the self-supervised AudioMAE model and a supervised AudioMAE model, both of which use the same capacity ViT-B audio encoder as ImageBind, it outperforms them in all settings. ImageBind shows approximately 40% accuracy gains in top-1 accuracy on ≤4-shot classification. It also matches or surpasses the supervised model on ≥1-shot classification, with its zero-shot performance outdoing the supervised ≤2-shot performance.
For few-shot depth classification, ImageBind is compared to the multimodal MultiMAE ViT-B/16 model, trained on images, depth, and semantic segmentation data. ImageBind significantly outperforms MultiMAE across all few-shot settings. These results demonstrate the strong generalization capabilities of ImageBind’s audio and depth features when trained with image alignment.
Analysis and Applications

ImageBind’s embeddings can be effectively used to combine information across different modalities. This was demonstrated by adding together image and audio embeddings to retrieve an image that contains concepts from both these modalities. For instance, an image of fruits on a table combined with the sound of chirping birds could retrieve an image of fruits on trees with birds. This emergent compositionality may allow for a wide range of compositional tasks.
Additionally, without re-training, existing vision models that use CLIP embeddings can be upgraded to use ImageBind embeddings from other modalities such as audio. This was tested by using a pre-trained text-based detection model, Detic, and replacing its CLIP-based text embeddings with ImageBind’s audio embeddings. Without any training, this created an audio-based detector that can detect and segment objects based on audio prompts.
The same method was applied to a pre-trained DALLE-2 diffusion model, replacing its prompt embeddings with ImageBind’s audio embeddings. This allowed the diffusion model to generate plausible images using different types of sounds.
Ablation Study
Scaling the Image Encoder
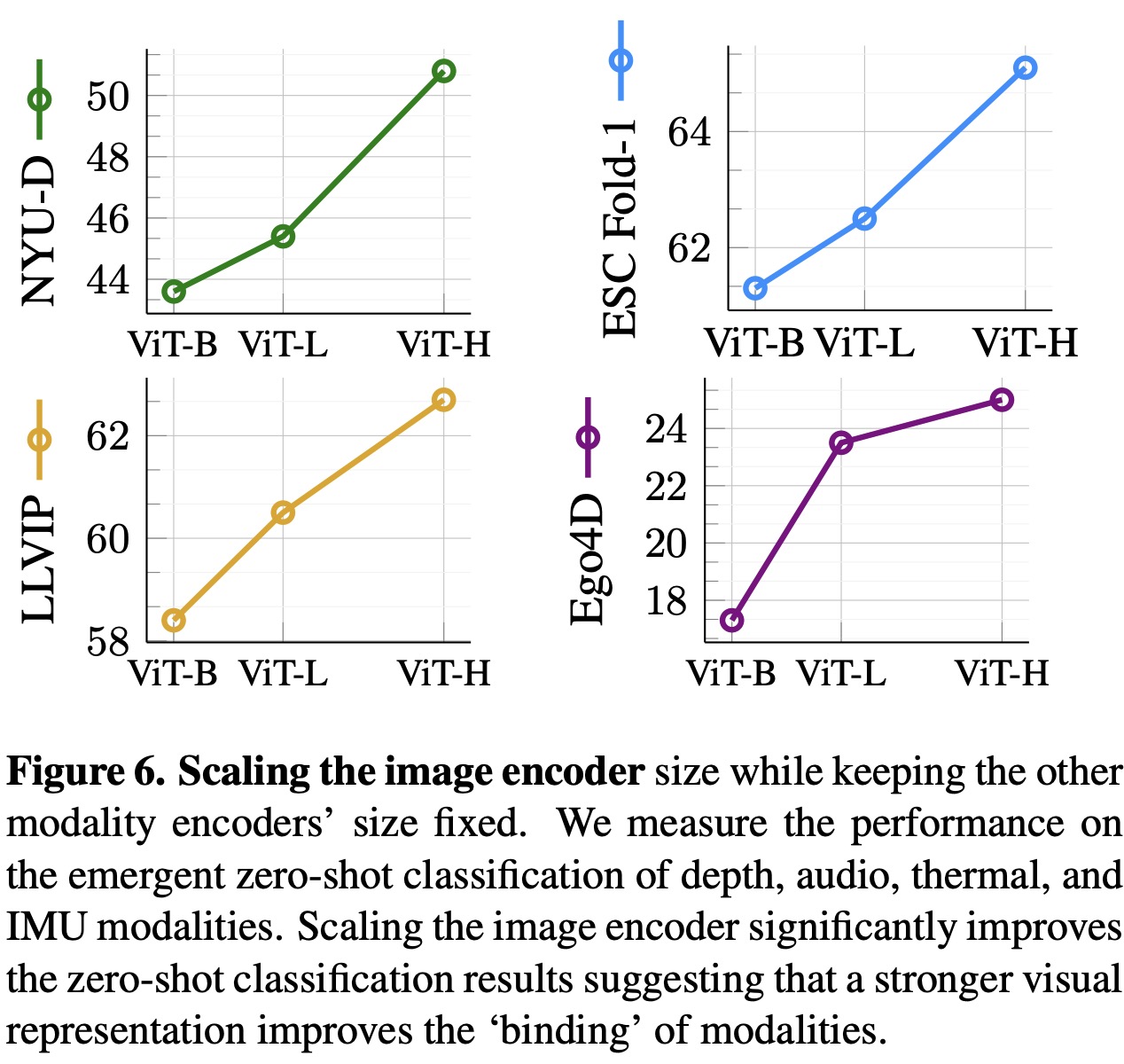
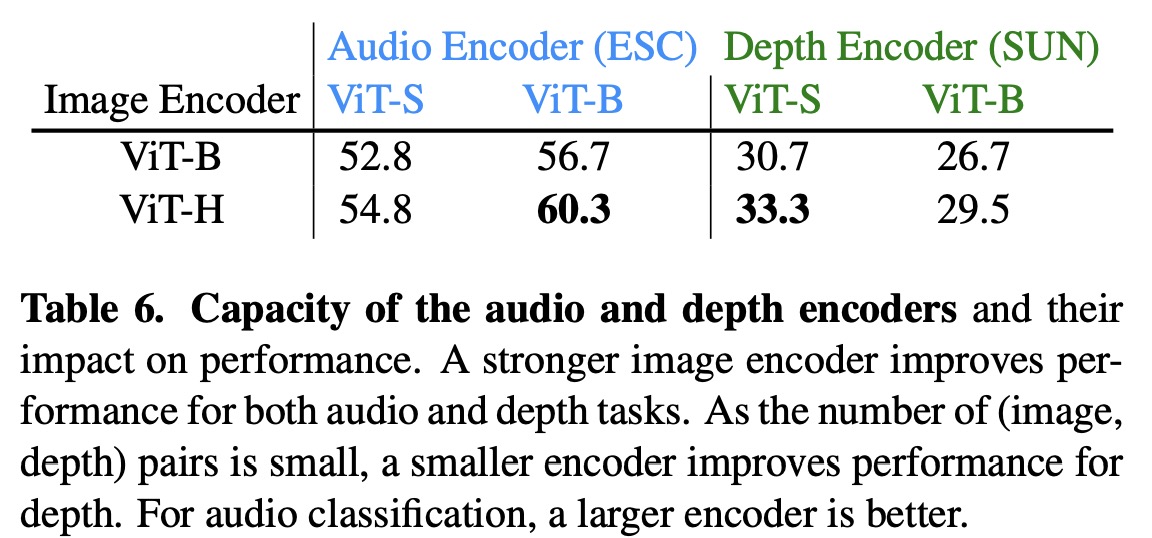
ImageBind centers on aligning the embeddings of all modalities to image embeddings, which plays a critical role in the emergent alignment of unseen modalities. To understand the effect of image embeddings on emergent zero-shot performance, the size of the image encoder was varied, and an encoder for other modalities like depth and audio was trained to match the image representation.
The results showed that as the quality of the visual features improved, so did ImageBind’s emergent zero-shot performance on all modalities. For example, using a stronger ViT-H encoder instead of a ViT-B for image encoding resulted in a 7% and 4% improvement in depth and audio classification, respectively. This indicates that improving the quality of visual features can enhance recognition performance, even in non-visual modalities.
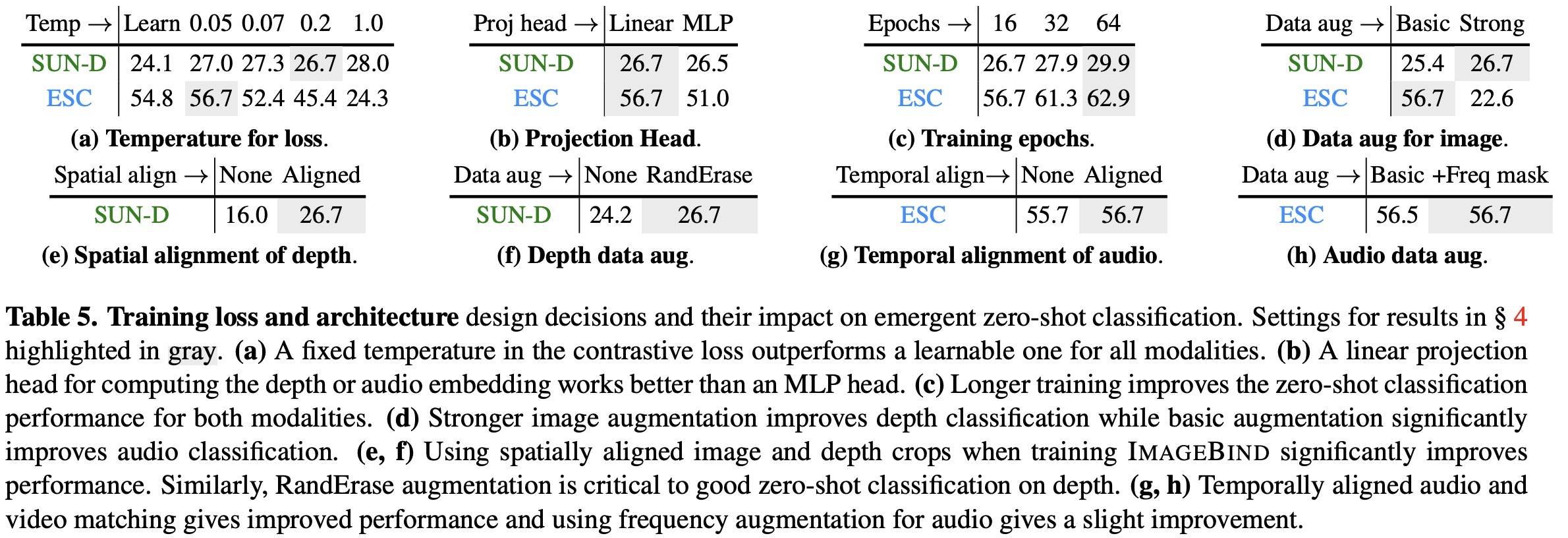
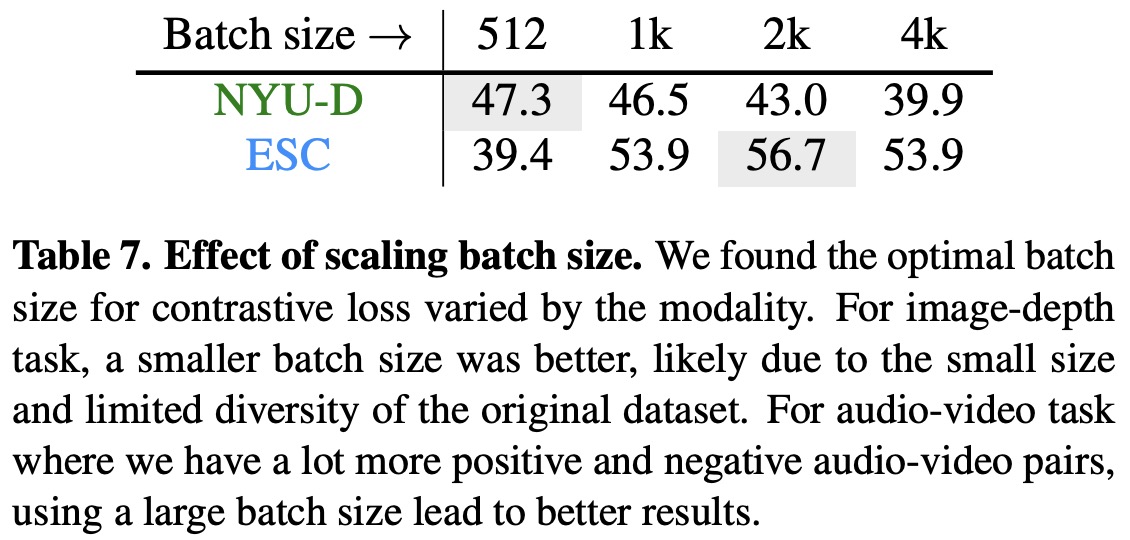
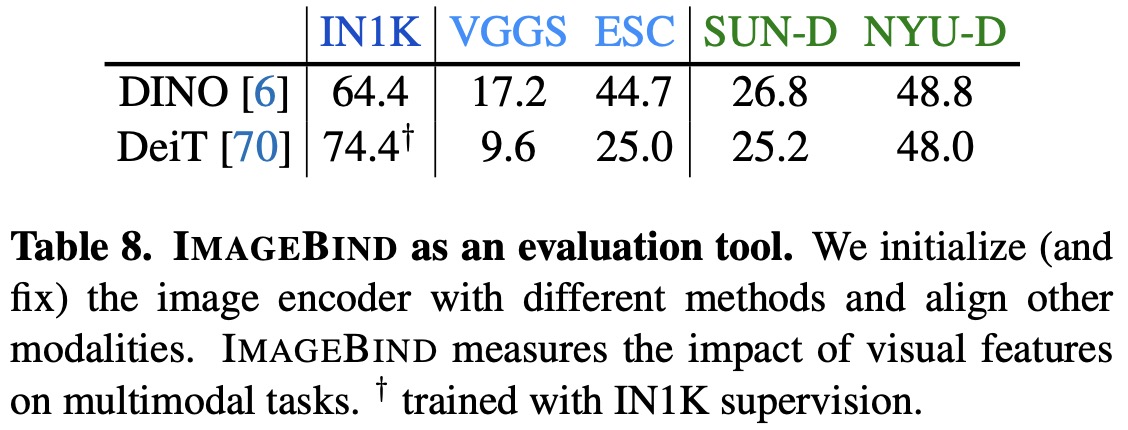
Training Loss and Architecture